distributed systems (3rd edition) maarten van steen and ... · distributed systems (3rd edition)...
TRANSCRIPT

Distributed Systems(3rd Edition)
Maarten van Steen and Tanenbaum
Edited by
Ghada Ahmed, PhD
Fall 2017

Introduction: What is a distributed system?
Distributed System
DefinitionA distributed system is a collection of autonomous computing elements thatappears to its users as a single coherent system.
Characteristic features
Autonomous computing elements, also referred to as nodes, be theyhardware devices or software processes.
Single coherent system: users or applications perceive a single system⇒nodes need to collaborate.
2 / 39

Introduction: What is a distributed system? Characteristic 1: Collection of autonomous computing elements
Collection of autonomous nodes
Independent behavior
Each node is autonomous and will thus have its own notion of time: there is noglobal clock. Leads to fundamental synchronization and coordination problems.
Collection of nodes
How to manage group membership?
How to know that you are indeed communicating with an authorized(non)member?
3 / 39

Introduction: What is a distributed system? Characteristic 1: Collection of autonomous computing elements
Organization
Overlay network
Each node in the collection communicates only with other nodes in the system,its neighbors. The set of neighbors may be dynamic, or may even be knownonly implicitly (i.e., requires a lookup).
Overlay types
Well-known example of overlay networks: peer-to-peer systems.
Structured: each node has a well-defined set of neighbors with whom it cancommunicate (tree, ring).
Unstructured: each node has references to randomly selected other nodesfrom the system.
4 / 39

Introduction: What is a distributed system? Characteristic 2: Single coherent system
Coherent system
EssenceThe collection of nodes as a whole operates the same, no matter where, when,and how interaction between a user and the system takes place.
Examples
An end user cannot tell where a computation is taking placeWhere data is exactly stored should be irrelevant to an applicationIf or not data has been replicated is completely hidden
Keyword is distribution transparency
The snag: partial failures
It is inevitable that at any time only a part of the distributed system fails. Hidingpartial failures and their recovery is often very difficult and in generalimpossible to hide.
5 / 39

Introduction: What is a distributed system? Middleware and distributed systems
Middleware: the OS of distributed systems
Local OS 1 Local OS 2 Local OS 3 Local OS 4
Appl. A Application B Appl. C
Distributed-system layer (middleware)
Computer 1 Computer 2 Computer 3 Computer 4
Same interface everywhere
Network
What does it contain?Commonly used components and functions that need not be implemented byapplications separately.
6 / 39

Introduction: Design goals
What do we want to achieve?
Support sharing of resources
Distribution transparency
Openness
Scalability
7 / 39

Introduction: Design goals Supporting resource sharing
Sharing resources
Canonical examples
Cloud-based shared storage and filesPeer-to-peer assisted multimedia streamingShared mail services (think of outsourced mail systems)Shared Web hosting (think of content distribution networks)
Observation
“The network is the computer”
(quote from John Gage, then at Sun Microsystems)
8 / 39

Introduction: Design goals Making distribution transparent
Distribution transparency
Types
Transparency DescriptionAccess Hide differences in data representation and how an
object is accessedLocation Hide where an object is locatedRelocation Hide that an object may be moved to another location
while in useMigration Hide that an object may move to another locationReplication Hide that an object is replicatedConcurrency Hide that an object may be shared by several
independent usersFailure Hide the failure and recovery of an object
Types of distribution transparency 9 / 39

Introduction: Design goals Making distribution transparent
Degree of transparency
ObservationAiming at full distribution transparency may be too much:
There are communication latencies that cannot be hiddenCompletely hiding failures of networks and nodes is (theoretically andpractically) impossible
You cannot distinguish a slow computer from a failing oneYou can never be sure that a server actually performed an operationbefore a crash
Full transparency will cost performance, exposing distribution of thesystem
Keeping replicas exactly up-to-date with the master takes timeImmediately flushing write operations to disk for fault tolerance
Degree of distribution transparency 10 / 39

Introduction: Design goals Making distribution transparent
Degree of transparency
ObservationAiming at full distribution transparency may be too much:
There are communication latencies that cannot be hidden
Completely hiding failures of networks and nodes is (theoretically andpractically) impossible
You cannot distinguish a slow computer from a failing oneYou can never be sure that a server actually performed an operationbefore a crash
Full transparency will cost performance, exposing distribution of thesystem
Keeping replicas exactly up-to-date with the master takes timeImmediately flushing write operations to disk for fault tolerance
Degree of distribution transparency 10 / 39

Introduction: Design goals Making distribution transparent
Degree of transparency
ObservationAiming at full distribution transparency may be too much:
There are communication latencies that cannot be hiddenCompletely hiding failures of networks and nodes is (theoretically andpractically) impossible
You cannot distinguish a slow computer from a failing oneYou can never be sure that a server actually performed an operationbefore a crash
Full transparency will cost performance, exposing distribution of thesystem
Keeping replicas exactly up-to-date with the master takes timeImmediately flushing write operations to disk for fault tolerance
Degree of distribution transparency 10 / 39

Introduction: Design goals Making distribution transparent
Degree of transparency
ObservationAiming at full distribution transparency may be too much:
There are communication latencies that cannot be hiddenCompletely hiding failures of networks and nodes is (theoretically andpractically) impossible
You cannot distinguish a slow computer from a failing oneYou can never be sure that a server actually performed an operationbefore a crash
Full transparency will cost performance, exposing distribution of thesystem
Keeping replicas exactly up-to-date with the master takes timeImmediately flushing write operations to disk for fault tolerance
Degree of distribution transparency 10 / 39

Introduction: Design goals Making distribution transparent
Degree of transparency
Exposing distribution may be good
Making use of location-based services (finding your nearby friends)
When dealing with users in different time zones
When it makes it easier for a user to understand what’s going on (whene.g., a server does not respond for a long time, report it as failing).
ConclusionDistribution transparency is a nice a goal, but achieving it is a different story,and it should often not even be aimed at.
Degree of distribution transparency 11 / 39

Introduction: Design goals Making distribution transparent
Degree of transparency
Exposing distribution may be good
Making use of location-based services (finding your nearby friends)
When dealing with users in different time zones
When it makes it easier for a user to understand what’s going on (whene.g., a server does not respond for a long time, report it as failing).
ConclusionDistribution transparency is a nice a goal, but achieving it is a different story,and it should often not even be aimed at.
Degree of distribution transparency 11 / 39

Introduction: Design goals Being open
Openness of distributed systems
What are we talking about?
Be able to interact with services from other open systems, irrespective of theunderlying environment:
Systems should conform to well-defined interfacesSystems should easily interoperateSystems should support portability of applicationsSystems should be easily extensible
Interoperability, composability, and extensibility 12 / 39

Introduction: Design goals Being scalable
Scale in distributed systems
ObservationMany developers of modern distributed systems easily use the adjective“scalable” without making clear why their system actually scales.
At least three components
Number of users and/or processes (size scalability)
Maximum distance between nodes (geographical scalability)
Number of administrative domains (administrative scalability)
ObservationMost systems account only, to a certain extent, for size scalability. Often asolution: multiple powerful servers operating independently in parallel. Today,the challenge still lies in geographical and administrative scalability.
Scalability dimensions 13 / 39

Introduction: Design goals Being scalable
Scale in distributed systems
ObservationMany developers of modern distributed systems easily use the adjective“scalable” without making clear why their system actually scales.
At least three components
Number of users and/or processes (size scalability)
Maximum distance between nodes (geographical scalability)
Number of administrative domains (administrative scalability)
ObservationMost systems account only, to a certain extent, for size scalability. Often asolution: multiple powerful servers operating independently in parallel. Today,the challenge still lies in geographical and administrative scalability.
Scalability dimensions 13 / 39

Introduction: Design goals Being scalable
Scale in distributed systems
ObservationMany developers of modern distributed systems easily use the adjective“scalable” without making clear why their system actually scales.
At least three components
Number of users and/or processes (size scalability)
Maximum distance between nodes (geographical scalability)
Number of administrative domains (administrative scalability)
ObservationMost systems account only, to a certain extent, for size scalability. Often asolution: multiple powerful servers operating independently in parallel. Today,the challenge still lies in geographical and administrative scalability.
Scalability dimensions 13 / 39

Introduction: Design goals Being scalable
Size scalability
Root causes for scalability problems with centralized solutions
The computational capacity, limited by the CPUs
The storage capacity, including the transfer rate between CPUs and disks
The network between the user and the centralized service
Scalability dimensions 14 / 39

Introduction: Design goals Being scalable
Problems with geographical scalability
Cannot simply go from LAN to WAN: many distributed systems assumesynchronous client-server interactions: client sends request and waits foran answer. Latency may easily prohibit this scheme.
WAN links are often inherently unreliable: simply moving streaming videofrom LAN to WAN is bound to fail.
Lack of multipoint communication, so that a simple search broadcastcannot be deployed. Solution is to develop separate naming and directoryservices (having their own scalability problems).
Scalability dimensions 15 / 39

Introduction: Design goals Being scalable
Problems with administrative scalability
EssenceConflicting policies concerning usage (and thus payment), management, andsecurity
Examples
Computational grids: share expensive resources between differentdomains.
Shared equipment: how to control, manage, and use a shared radiotelescope constructed as large-scale shared sensor network?
Exception: several peer-to-peer networks
File-sharing systems (based, e.g., on BitTorrent)Peer-to-peer telephony (Skype)Peer-assisted audio streaming (Spotify)
Note: end users collaborate and not administrative entities.
Scalability dimensions 16 / 39

Introduction: Design goals Being scalable
Techniques for scaling
Hide communication latencies
Make use of asynchronous communication
Have separate handler for incoming response
Problem: not every application fits this model
Scaling techniques 17 / 39

Introduction: Design goals Being scalable
Techniques for scaling
Facilitate solution by moving computations to client
MA
AR
TE
N
FIRST NAME
LAST NAME
ServerClient
Check form Process form
MAARTEN
MVS VAN-STEEN.NET@
VAN STEEN
FIRST NAME
LAST NAME
ServerClient
Check form Process form
MAARTEN
VAN STEENMAARTENVAN [email protected]
Scaling techniques 18 / 39

Introduction: Design goals Being scalable
Techniques for scaling
Partition data and computations across multiple machines
Move computations to clients (Java applets)
Decentralized naming services (DNS)
Decentralized information systems (WWW)
Scaling techniques 19 / 39

Introduction: Design goals Being scalable
Techniques for scaling
Replication and caching: Make copies of data available at different machines
Replicated file servers and databases
Mirrored Web sites
Web caches (in browsers and proxies)
File caching (at server and client)
Scaling techniques 20 / 39

Introduction: Design goals Being scalable
Scaling: The problem with replication
Applying replication is easy, except for one thing
Having multiple copies (cached or replicated), leads to inconsistencies:modifying one copy makes that copy different from the rest.
Always keeping copies consistent and in a general way requires globalsynchronization on each modification.
Global synchronization precludes large-scale solutions.
ObservationIf we can tolerate inconsistencies, we may reduce the need for globalsynchronization, but tolerating inconsistencies is application dependent.
Scaling techniques 21 / 39

Introduction: Design goals Being scalable
Scaling: The problem with replication
Applying replication is easy, except for one thing
Having multiple copies (cached or replicated), leads to inconsistencies:modifying one copy makes that copy different from the rest.
Always keeping copies consistent and in a general way requires globalsynchronization on each modification.
Global synchronization precludes large-scale solutions.
ObservationIf we can tolerate inconsistencies, we may reduce the need for globalsynchronization, but tolerating inconsistencies is application dependent.
Scaling techniques 21 / 39

Introduction: Design goals Being scalable
Scaling: The problem with replication
Applying replication is easy, except for one thing
Having multiple copies (cached or replicated), leads to inconsistencies:modifying one copy makes that copy different from the rest.
Always keeping copies consistent and in a general way requires globalsynchronization on each modification.
Global synchronization precludes large-scale solutions.
ObservationIf we can tolerate inconsistencies, we may reduce the need for globalsynchronization, but tolerating inconsistencies is application dependent.
Scaling techniques 21 / 39

Introduction: Design goals Being scalable
Scaling: The problem with replication
Applying replication is easy, except for one thing
Having multiple copies (cached or replicated), leads to inconsistencies:modifying one copy makes that copy different from the rest.
Always keeping copies consistent and in a general way requires globalsynchronization on each modification.
Global synchronization precludes large-scale solutions.
ObservationIf we can tolerate inconsistencies, we may reduce the need for globalsynchronization, but tolerating inconsistencies is application dependent.
Scaling techniques 21 / 39

Introduction: Design goals Being scalable
Scaling: The problem with replication
Applying replication is easy, except for one thing
Having multiple copies (cached or replicated), leads to inconsistencies:modifying one copy makes that copy different from the rest.
Always keeping copies consistent and in a general way requires globalsynchronization on each modification.
Global synchronization precludes large-scale solutions.
ObservationIf we can tolerate inconsistencies, we may reduce the need for globalsynchronization, but tolerating inconsistencies is application dependent.
Scaling techniques 21 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Design goals Pitfalls
Developing distributed systems: Pitfalls
ObservationMany distributed systems are needlessly complex caused by mistakes thatrequired patching later on. Many false assumptions are often made.
False (and often hidden) assumptions
The network is reliable
The network is secure
The network is homogeneous
The topology does not change
Latency is zero
Bandwidth is infinite
Transport cost is zero
There is one administrator
22 / 39

Introduction: Types of distributed systems
Three types of distributed systems
High performance distributed computing systems
Distributed information systems
Distributed systems for pervasive computing
23 / 39
Introduction: Types of distributed systems High performance distributed computing
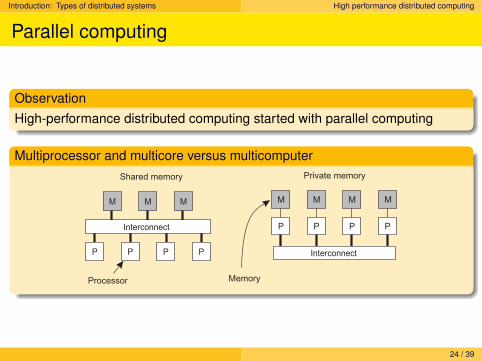
Parallel computing
ObservationHigh-performance distributed computing started with parallel computing
Multiprocessor and multicore versus multicomputerShared memory
Processor
P P P P
M M M
Interconnect
Private memory
Memory
P P P P
M M M M
Interconnect
24 / 39

Introduction: Types of distributed systems High performance distributed computing
Distributed shared memory systems
ObservationMultiprocessors are relatively easy to program in comparison tomulticomputers, yet have problems when increasing the number of processors(or cores). Solution: Try to implement a shared-memory model on top of amulticomputer.
Example through virtual-memory techniques
Map all main-memory pages (from different processors) into one single virtualaddress space. If process at processor A addresses a page P located atprocessor B, the OS at A traps and fetches P from B, just as it would if P hadbeen located on local disk.
ProblemPerformance of distributed shared memory could never compete with that ofmultiprocessors, and failed to meet the expectations of programmers. It hasbeen widely abandoned by now.
25 / 39

Introduction: Types of distributed systems High performance distributed computing
Cluster computing
Essentially a group of high-end systems connected through a LAN
Homogeneous: same OS, near-identical hardwareSingle managing node
Local OSLocal OS Local OS Local OS
Standard network
Component
of
parallel
application
Component
of
parallel
application
Component
of
parallel
applicationParallel libs
Management
application
High-speed network
Remote access
network
Master node Compute node Compute node Compute node
Cluster computing 26 / 39

Introduction: Types of distributed systems High performance distributed computing
Grid computing
The next step: lots of nodes from everywhere
Heterogeneous
Dispersed across several organizations
Can easily span a wide-area network
NoteTo allow for collaborations, grids generally use virtual organizations. Inessence, this is a grouping of users (or better: their IDs) that will allow forauthorization on resource allocation.
Grid computing 27 / 39
Introduction: Types of distributed systems High performance distributed computing
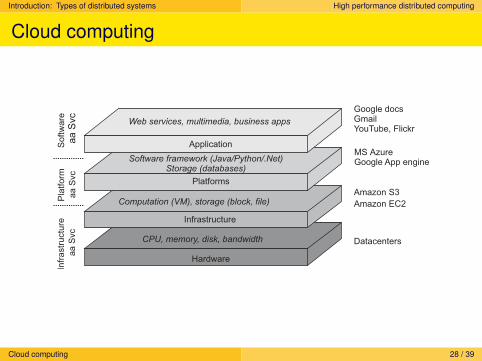
Cloud computing
Application
Infrastructure
Computation (VM) torage (block ), s , file
Hardware
Platforms
Software framework (Java/Python/.Net)Storage ( )databases
Infr
astr
uctu
re
aa S
vc
Pla
tform
aa S
vc
Softw
are
aa
Svc
MS AzureGoogle App engine
Amazon S3
Amazon EC2
DatacentersCPU, memory, disk, bandwidth
Web services, multimedia, business apps
Google docsGmailYouTube, Flickr
Cloud computing 28 / 39

Introduction: Types of distributed systems High performance distributed computing
Cloud computing
Make a distinction between four layers
Hardware: Processors, routers, power and cooling systems. Customersnormally never get to see these.
Infrastructure: Deploys virtualization techniques. Evolves aroundallocating and managing virtual storage devices and virtual servers.
Platform: Provides higher-level abstractions for storage and such.Example: Amazon S3 storage system offers an API for (locally created)files to be organized and stored in so-called buckets.
Application: Actual applications, such as office suites (text processors,spreadsheet applications, presentation applications). Comparable to thesuite of apps shipped with OSes.
Cloud computing 29 / 39

Introduction: Types of distributed systems Distributed information systems
Integrating applications
SituationOrganizations confronted with many networked applications, but achievinginteroperability was painful.
Basic approach
A networked application is one that runs on a server making its servicesavailable to remote clients. Simple integration: clients combine requests for(different) applications; send that off; collect responses, and present a coherentresult to the user.
Next step
Allow direct application-to-application communication, leading to EnterpriseApplication Integration.
30 / 39

Introduction: Types of distributed systems Distributed information systems
How to integrate applications
File transfer: Technically simple, but not flexible:
Figure out file format and layoutFigure out file managementUpdate propagation, and update notifications.
Shared database: Much more flexible, but still requires common data schemenext to risk of bottleneck.
Remote procedure call: Effective when execution of a series of actions isneeded.
Messaging: RPCs require caller and callee to be up and running at the sametime. Messaging allows decoupling in time and space.
31 / 39

Introduction: Types of distributed systems Pervasive systems
Distributed pervasive systems
ObservationEmerging next-generation of distributed systems in which nodes are small,mobile, and often embedded in a larger system, characterized by the fact thatthe system naturally blends into the user’s environment.
Three (overlapping) subtypes
Ubiquitous computing systems: pervasive and continuously present, i.e.,there is a continuous interaction between system and user.
Mobile computing systems: pervasive, but emphasis is on the fact thatdevices are inherently mobile.
Sensor (and actuator) networks: pervasive, with emphasis on the actual(collaborative) sensing and actuation of the environment.
32 / 39

Introduction: Types of distributed systems Pervasive systems
Distributed pervasive systems
ObservationEmerging next-generation of distributed systems in which nodes are small,mobile, and often embedded in a larger system, characterized by the fact thatthe system naturally blends into the user’s environment.
Three (overlapping) subtypes
Ubiquitous computing systems: pervasive and continuously present, i.e.,there is a continuous interaction between system and user.
Mobile computing systems: pervasive, but emphasis is on the fact thatdevices are inherently mobile.
Sensor (and actuator) networks: pervasive, with emphasis on the actual(collaborative) sensing and actuation of the environment.
32 / 39

Introduction: Types of distributed systems Pervasive systems
Distributed pervasive systems
ObservationEmerging next-generation of distributed systems in which nodes are small,mobile, and often embedded in a larger system, characterized by the fact thatthe system naturally blends into the user’s environment.
Three (overlapping) subtypes
Ubiquitous computing systems: pervasive and continuously present, i.e.,there is a continuous interaction between system and user.
Mobile computing systems: pervasive, but emphasis is on the fact thatdevices are inherently mobile.
Sensor (and actuator) networks: pervasive, with emphasis on the actual(collaborative) sensing and actuation of the environment.
32 / 39

Introduction: Types of distributed systems Pervasive systems
Distributed pervasive systems
ObservationEmerging next-generation of distributed systems in which nodes are small,mobile, and often embedded in a larger system, characterized by the fact thatthe system naturally blends into the user’s environment.
Three (overlapping) subtypes
Ubiquitous computing systems: pervasive and continuously present, i.e.,there is a continuous interaction between system and user.
Mobile computing systems: pervasive, but emphasis is on the fact thatdevices are inherently mobile.
Sensor (and actuator) networks: pervasive, with emphasis on the actual(collaborative) sensing and actuation of the environment.
32 / 39

Introduction: Types of distributed systems Pervasive systems
Ubiquitous systems
Core elements1 (Distribution) Devices are networked, distributed, and accessible in a
transparent manner2 (Interaction) Interaction between users and devices3 (Context awareness) The system is aware of a user’s context in order to
optimize interaction4 (Autonomy) Devices operate autonomously without human intervention,
and are thus highly self-managed5 (Intelligence) The system as a whole can handle a wide range of
dynamic actions and interactions
Ubiquitous computing systems 33 / 39

Introduction: Types of distributed systems Pervasive systems
Mobile computing
Distinctive features
An extremely great number of different mobile devices (smartphones,tablets, GPS devices, remote controls, active badges.
Mobile implies that a device’s location is expected to change over time⇒change of local services, reachability, etc. Keyword: discovery.
Communication may become more difficult: no stable route, but alsoperhaps no guaranteed connectivity⇒ disruption-tolerant networking.
Mobile computing systems 34 / 39

Introduction: Types of distributed systems Pervasive systems
Mobility patterns
IssueWhat is the relationship between information circulation and human mobility?Basic idea: an encounter allows for the exchange of information(pocket-switched networks).
A successful strategy
Alice’s world consists of friends and strangers.
If Alice wants to get a message to Bob: hand it out to all her friends
Friend passes message to Bob at first encounter
ObservationThis strategy works because (apparently) there are relatively closedcommunities of friends.
Mobile computing systems 35 / 39

Introduction: Types of distributed systems Pervasive systems
How mobile are people?
Experimental results
Tracing 100,000 cell-phone users during six months leads to:
Moreover: people tend to return to the same place after 24, 48, or 72 hours⇒we’re not that mobile.
Mobile computing systems 36 / 39

Introduction: Types of distributed systems Pervasive systems
Sensor networks
CharacteristicsThe nodes to which sensors are attached are:
Many (10s-1000s)
Simple (small memory/compute/communication capacity)
Often battery-powered (or even battery-less)
Sensor networks 37 / 39

Introduction: Types of distributed systems Pervasive systems
Sensor networks as distributed databases
Two extremes
Operator's site
Sensor network
Sensor datais sent directly
to operator
Operator's site
Sensor network
Query
Sensors
send only
answers
Each sensor
can process and
store data
Sensor networks 38 / 39

Introduction: Types of distributed systems Pervasive systems
Duty-cycled networks
IssueMany sensor networks need to operate on a strict energy budget: introduceduty cycles
DefinitionA node is active during Tactive time units, and then suspended for Tsuspendedunits, to become active again. Duty cycle τ:
τ =Tactive
Tactive +Tsuspended
Typical duty cycles are 10−30%, but can also be lower than 1%.
Sensor networks 39 / 39