dmds winter workshop 2 slides
TRANSCRIPT

Winter 2015: Session #2Programming on the Whiteboard
February 19, 2015(Paige Morgan)

Last week...•The work of creating usable data
•Forms that this data might take:
•markup language
•Spreadsheets (MySQL & relational DBs)
•Graph databases (RDF/Linked Open Data

This week:
•Caveat Curator (challenges of working with data)
•Programming on the Whiteboard, i.e., conceptualizing the specific steps that you need to take to accomplish your goals

Goals/Takeaways
•A better understanding of the workflow for dealing with data
•Greater ability to talk about what you’re trying to do

Why this focus on data?•Understanding your data, and
your intended actions, is a key skill for developing any digital project (big or small).
•You may have one big project – but your data may support several small/intermediary projects.

Caveat Curator

Programming languages (and digital apps) are
like human languages in that they both have
phrases, patterns, and rules.

Programming languages are unlike human
languages in that they aren’t for communicating
with people.

They are also unlike human languages in
that every programming
utterance does something, i.e., causes
an action to occur.

You can get used to patterns – even unfamiliar ones.

The shift is in getting used to
thinking in terms of every single
action.

Today’s subject matter includes actions that you’ll need to think
about before you work with...

Image: Josh Lee, @wtrsld, via Twitter, January 2014.

Even when you’re just experimenting, you need
to prep your data.

You may know your dataset in detail
already, from your research -- but your
computer is concerned with different levels of
detail.

Becoming aware of those levels of detail is not only helpful for your
project ideas...

...it’s also a useful skill for working with
programming languages.
(where a stray /> or ; can break your program/website)

Data only works if your computer can read it.

But my data is just text!
(Doesn’t that make things easy?)

(Remember, your computer is fairly
stupid).

Formatted text is often full of text
your computer
can’t parse correctly.

The┘re┘sÜlt ís that yoÜr te┘xt
might come┘ oÜt looking
like┘this
whe┘n yoÜ ope┘n it in a
programming e┘nvironme┘nt.

So you need to convert it to plain text.
(without any of the fancy details encoded in MS Word
fonts.)

(This is key if you work with newspapers, older
printed texts, or archival material.)

Maybe you want to work with sailing data and
ports of call:

The ship you’re interested in leaves the
Ivory Coast for St. Helena...


But when you create your map, you get this:


The latitude/longitude coordinate is the
significant datum.

The city name is just the human-readable
component.

Each datum needs to be unique.

Figuring out what sort of unique
configuration will work best involves
at least some experimentation.

To experiment effectively, you’ll want to
keep careful records.

If you develop categories of
information, you’ll want to keep a record of what each category means, and what its
limits are.

Cleaning and structuring your data is a
foundation issue that changes, depending on the available format of
your data.

What if your data is crowdsourced?

You can require a particular format for
submissions

You can even put programmatic limits on
the formats available for submission

But in the end, you’re probably still going to need to scrub and/or
format.

This is true even for data from supposedly reputable sources, like government or media
organizations.

Example: Doctor Who Villains dataset
http://tinyurl.com/doctorwhovillains

This step is no fun!

But it’s absolutely necessary.

If you are thinking about your data, and the tasks
that you need to accomplish, then it’s
easier to determine what sort of language or
platform your project needs.

There are countless tutorials, online courses,
etc., for almost any programming language or
platform.
(You can also ask for a Sherman Centre consultation to figure out what you need to learn.)

Learning how to work with any tool can be a
slow process, especially at first.

However, knowing what tasks you’re working
towards makes it easier to understand the
purpose of the introductory lessons.

It’s also easy to think about how the first rules
you learn for any language or platform
might affect your goals.

Pseudocode
•Used by programmers to break down a complex task into manageable steps
•Easily adaptable for use by non-programmers

Pseudocode Example
(Visible Prices)• Computer has a file that contains prices from
different texts.
• Computer must know that each price amount is connected with an object, and with a bibliographical record.
• Users can input a price amount, and computer will retrieve all objects that match the price, and display them to the user, along with bibliographical information.
• (More complex): Computer is able to retrieve prices linked with certain categories (clothing, food, etc.)

(And now for a couple of examples of projects in
process…)

Social Work and Social Change
(Tina Wilson)

Social work + social change
• Recent history of academic social work in Canada; 1960s onward
• Interested in the ways in which academic social work has attempted to advance justice-oriented social change projects, and how political, cultural, and theoretical shifts have influenced this type of disciplinary imagination and work
• Related to disciplinary boundaries and methods and orthodoxies, and the social role of universities
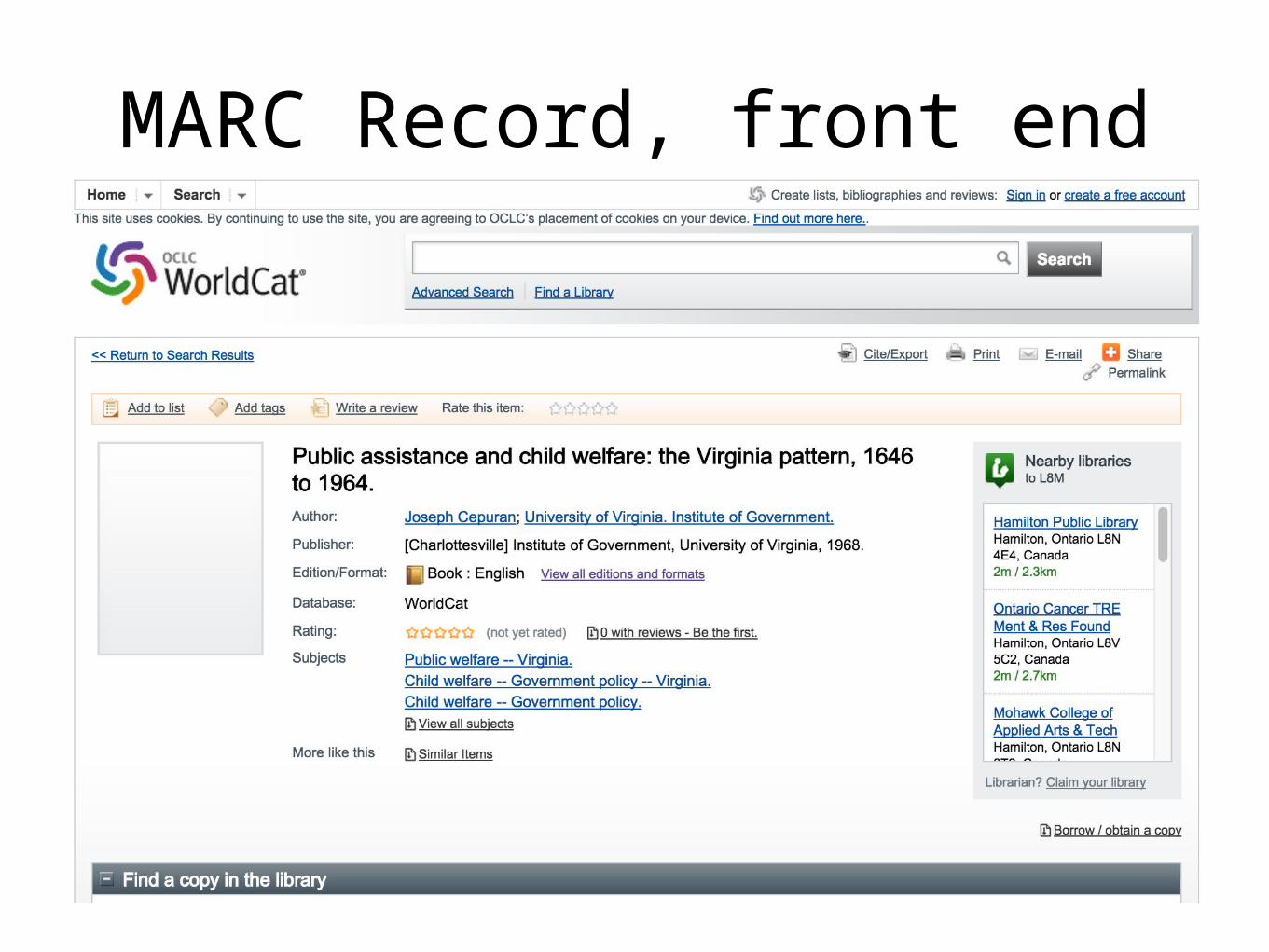
MARC Record, front end

MARC Record, back end<?xml version="1.0"?><record xmlns="http://www.loc.gov/MARC21/slim" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.loc.gov/MARC21/slim http://www.loc.gov/standards/marcxml/schema/MARC21slim.xsd"> <leader>00000cam a000001</leader> <controlfield tag="001">468966</controlfield> <controlfield tag="008">710913s1968vaub000 0 eng c</controlfield> <datafield tag="010" ind1=" " ind2=" "> <subfield code="a">a68007753 </subfield> </datafield> <datafield tag="040" ind1=" " ind2=" "> <subfield code="a">Virginia. Univ. Libr.</subfield> <subfield code="b">eng</subfield> <subfield code="c">DLC</subfield> <subfield code="d">OCLCQ</subfield> <subfield code="d">CLU</subfield> <subfield code="d">OCLCO</subfield> <subfield code="d">OCLCF</subfield> <subfield code="d">OCLCQ</subfield> </datafield> <datafield tag="043" ind1=" " ind2=" "> <subfield code="a">n-us-va</subfield> </datafield> <datafield tag="050" ind1="0" ind2="4"> <subfield code="a">HV98.V8</subfield> <subfield code="b">C46</subfield> </datafield> <datafield tag="082" ind1=" " ind2=" "> <subfield code="a">361/.9/755</subfield> </datafield> <datafield tag="100" ind1="1" ind2=" "> <subfield code="a">Cepuran, Joseph.</subfield> </datafield>
<datafield tag="245" ind1="1" ind2="0">
<subfield code="a">Public assistance and child welfare:</subfield>
<subfield code="b">the Virginia pattern, 1646 to 1964.</subfield> </datafield> <datafield tag="260" ind1=" " ind2=" "> <subfield code="a">[Charlottesville]</subfield> <subfield code="b">Institute of Government, University of Virginia,</subfield> <subfield code="c">1968.</subfield> </datafield> <datafield tag="300" ind1=" " ind2=" "> <subfield code="a">vii, 120 pages</subfield> <subfield code="c">28 cm</subfield> </datafield> <datafield tag="336" ind1=" " ind2=" "> <subfield code="a">text</subfield> <subfield code="b">txt</subfield> <subfield code="2">rdacontent</subfield> </datafield> <datafield tag="337" ind1=" " ind2=" "> <subfield code="a">unmediated</subfield> <subfield code="b">n</subfield> <subfield code="2">rdamedia</subfield> </datafield> <datafield tag="338" ind1=" " ind2=" "> <subfield code="a">volume</subfield> <subfield code="b">nc</subfield> <subfield code="2">rdacarrier</subfield> </datafield> <datafield tag="504" ind1=" " ind2=" "> <subfield code="a">Includes bibliographical references.</subfield>
</datafield>
<datafield tag="650" ind1=" " ind2="0">
<subfield code="a">Public welfare</subfield>
<subfield code="z">Virginia.</subfield> </datafield> <datafield tag="650" ind1=" " ind2="0"> <subfield code="a">Child welfare</subfield> <subfield code="x">Government policy</subfield> <subfield code="z">Virginia.</subfield> </datafield> <datafield tag="650" ind1=" " ind2="7"> <subfield code="a">Child welfare</subfield> <subfield code="x">Government policy.</subfield> <subfield code="2">fast</subfield> <subfield code="0">(OCoLC)fst00854729</subfield> </datafield> <datafield tag="650" ind1=" " ind2="7"> <subfield code="a">Public welfare.</subfield> <subfield code="2">fast</subfield> <subfield code="0">(OCoLC)fst01083250</subfield> </datafield> <datafield tag="651" ind1=" " ind2="7"> <subfield code="a">Virginia.</subfield> <subfield code="2">fast</subfield> <subfield code="0">(OCoLC)fst01204597</subfield> </datafield> <datafield tag="710" ind1="2" ind2=" "> <subfield code="a">University of Virginia.</subfield> <subfield code="b">Institute of Government.</subfield> </datafield></record>
MARC 21 Format

Things to count• Social problems: child abuse, unemployment, inequality
• Concepts: mental hygiene, non-voluntary clients, culture of poverty, consciousness raising, privilege
• Sub-populations: immigrants, unwed mothers, the oppressed
• Institutions: work houses, shelters, detention, the non-profit industrial complex
• Interventions: motivational interviewing, case management, urban planning, life skills education, community organizing
• Types of social work: case work, radical social work, community development, clinical social work
• SW books in Canadian Libraries

Project: People, Persons and Individuals: Is the DSM
Dehumanizing?
(Mackenzie Salt)

Objective
To analyze the diagnostic chapters of five volumes of the DSM to determine whether the referring expressions used therein are dehumanizing and if so, determine if the usages have changed over time.

Problems
Traditional discourse analysis is done by hand and can be very time consuming.
Volumes of the DSM range from 494 pages to 991 pages.

Solutions
• Digital Corpus Analysis– Computer Software (R)
• Faster• More Efficient• Can handle large amounts of data at once
• Data has to be prepared before it is ready to be used for digital analysis.

Preparation of Data
• Physical data must be converted to digital medium
• Steps– Permission– Scanning to PDF– OCR PDF– Convert OCRed PDF to Plain Text– Clean Plain Text

Permission
• Digital e-book copies of DSM are not available for any of the versions
• American Psychiatric Association holds copyright and is VERY protective

Scanning DSMs
• Physical copies of the DSMs need to be scanned into a digital format (in this case PDF)
• PDFs need to be converted to a text format that a computer can read, edit, and work with
OCR PDFs

Clean Plain Text Files
• Once you have OCRed plain text files, you need to make sure they are accurate– Computers are only as good as their
input• If the data input is messy, the analysis will
be messy
• Made files consisting of only the chapters for analysis
• Checked for and fixed any remaining OCR/Scanning errors

Now To The Project
• Come up with a list of referring expressions based on a visual scan through the DSMs
• Use R to narrow down the list to only the most frequent– Narrows 10K+ unique words to a handful
• Use R to pull out all sentences with the terms in question– Narrows down ~19K sentences to 655 for individual

Benefits of Digital Analysis
• This project still used some manual analysis
• Using digital technologies and corpora sped things up considerably
• Made it easier to break down large corpus to manageable parts
• Now have a corpus on which to do other projects in the future: prep-work already done

Working with Digital Corpora with R
• Pros– Free and Cross-Platform– Powerful, Efficient, Fast– Capable of working with VERY large datasets– Subsequent projects can be much faster as
code can be saved and built on or recycled
• Cons– Code-based command-line style interface
(?)– GIGO– Depending on project, input data may need
substantial preparation

Summary
• Overall, 75% of the time spent doing this project was prepping the data
• Project took only 3-4 months to do, part-time• Corpus analyzed totalled 1.08 million words
from the DSM-III through the DSM-5• Future projects based on this corpus will be
much faster to do as well• Digital technologies made this project feasible• Project was much faster than if done by hand

It is likely that your data will have a longer life span than any specific
project you create.

In many instances, it may be more useful to
focus on the data curation as much as a
single project.

Key DS Values
•Adaptive
•Sustainable/resource-aware
•Collaborative
•Social

Key skill•Thinking flexibly about your
data (and potential project)
•Are there portions of your dataset that could be extracted for use in a particular tool?
•How can you adjust your data in order to show it to people (and be more able to talk/write/present about your research interests?)

And now, it’s your turn...

For this activity, I recommend that you pair up, or form small groups
to work together.

Group Activity•What do you need to do with your
data? (share, aggregate, combine…?)
•What units might that data exist in?
•What categories do you need to create?
•What connections need to exist between the units and the categories?

Next steps•What’s the smallest version of your dataset possible? (useful for testing out tools)
•Possible tools to examine (as ways of presenting your data)• Omeka (http://www.omeka.net)
• Scalar (http://scalar.usc.edu)
• Simile (http://www.simile-widgets.org)
• Google Fusion Tables (https://support.google.com/fusiontables/answer/2571232)

SCDS support for data wrangling•Consultations
http://www.tinyurl.com/scds-consult
•Colloquium slots (opportunities to talk through your project plans for a supportive audience)
•Graduate fellowships (workspace and greater access to SCDS staff expertise)

Spring Workshops!
•Project Ideation and Development; Choosing Tools for Every Part of Your Project
•April 9th and 16th, 2015 (pre-registration available soon)