dn 2017 | reducing pain in data engineering | martin loetzsch | project a
TRANSCRIPT

@martin_loetzsch
Dr. Martin Loetzsch Data Natives 2017
Reducing pain in data engineering

2
Data Engineering
@martin_loetzsch

3
@martin_loetzsch

4
Which technology?
@martin_loetzsch
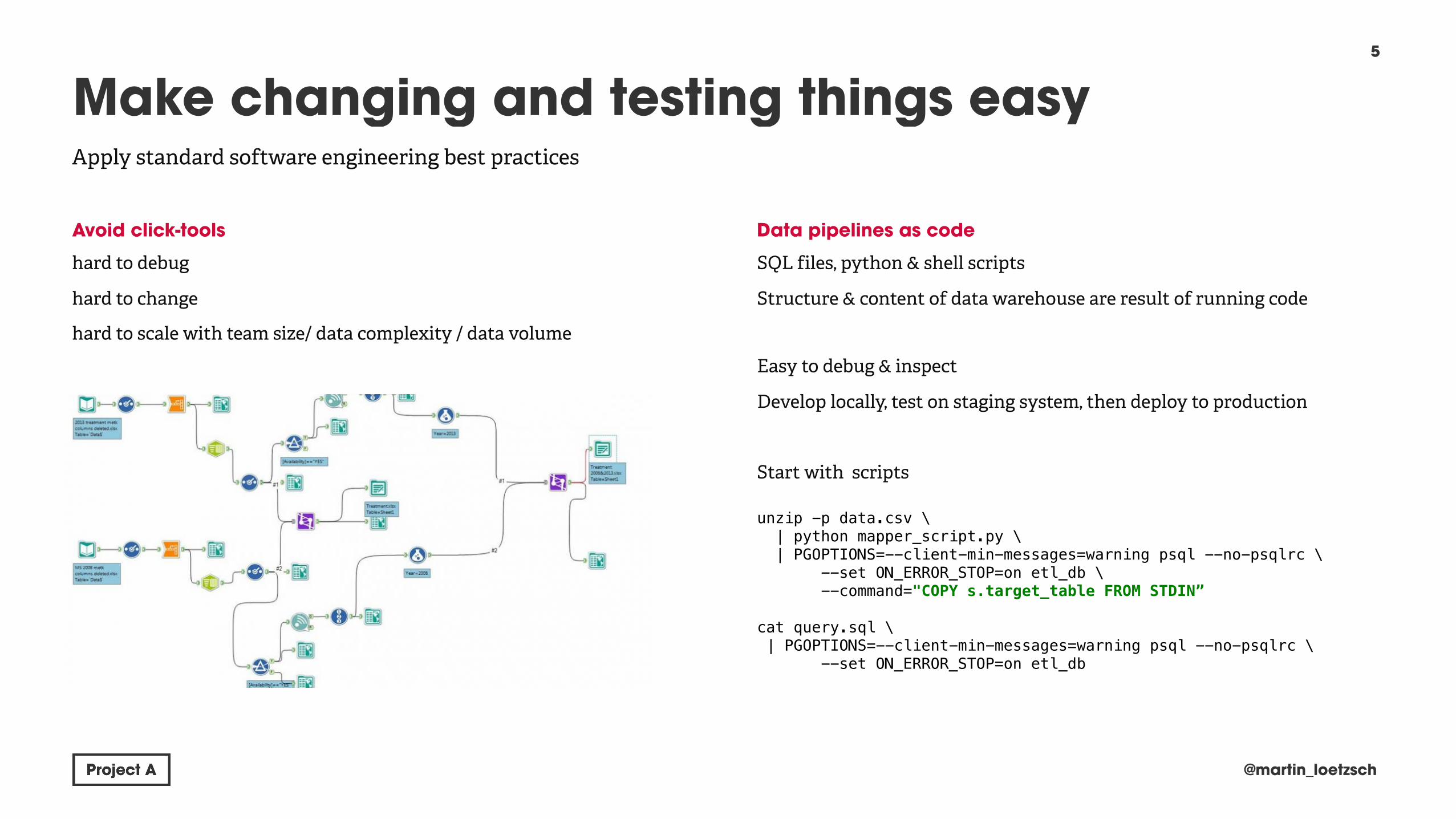
Avoid click-tools
hard to debug
hard to change
hard to scale with team size/ data complexity / data volume
Data pipelines as code
SQL files, python & shell scripts
Structure & content of data warehouse are result of running code
Easy to debug & inspect
Develop locally, test on staging system, then deploy to production
Start with scripts unzip -p data.csv \ | python mapper_script.py \ | PGOPTIONS=--client-min-messages=warning psql --no-psqlrc \ --set ON_ERROR_STOP=on etl_db \ --command="COPY s.target_table FROM STDIN”
cat query.sql \ | PGOPTIONS=--client-min-messages=warning psql --no-psqlrc \ --set ON_ERROR_STOP=on etl_db
5
Make changing and testing things easy
@martin_loetzsch
Apply standard software engineering best practices

Target of computation CREATE TABLE m_dim_next.region ( region_id SMALLINT PRIMARY KEY, region_name TEXT NOT NULL UNIQUE, country_id SMALLINT NOT NULL, country_name TEXT NOT NULL, _region_name TEXT NOT NULL);
Do computation and store result in table WITH raw_region AS (SELECT DISTINCT country, region FROM m_data.ga_session ORDER BY country, region)INSERT INTO m_dim_next.region SELECT row_number() OVER (ORDER BY country, region ) AS region_id,
CASE WHEN (SELECT count(DISTINCT country) FROM raw_region r2 WHERE r2.region = r1.region) > 1 THEN region || ' / ' || country ELSE region END AS region_name, dense_rank() OVER (ORDER BY country) AS country_id, country AS country_name, region AS _region_name FROM raw_region r1;
INSERT INTO m_dim_next.region VALUES (-1, 'Unknown', -1, 'Unknown', 'Unknown');
Speedup subsequent transformations SELECT util.add_index( 'm_dim_next', 'region', column_names := ARRAY ['_region_name', ‘country_name', 'region_id']);SELECT util.add_index( 'm_dim_next', 'region', column_names := ARRAY ['country_id', 'region_id']);ANALYZE m_dim_next.region;
6
SQL as data processing language
@martin_loetzsch
Tables as (intermediate) results of processing steps

Recommended: your own, Apache Airflow, Mara (Project A)
Transformations are transparent to stakeholders
7
Task orchestration
@martin_loetzsch
Invest in transparency, parallel execution

8
Consistency & correctness
@martin_loetzsch

It’s easy to make mistakes during ETL DROP SCHEMA IF EXISTS s CASCADE; CREATE SCHEMA s;
CREATE TABLE s.city ( city_id SMALLINT, city_name TEXT, country_name TEXT );
INSERT INTO s.city VALUES (1, 'Berlin', 'Germany'), (2, 'Budapest', 'Hungary');
CREATE TABLE s.customer ( customer_id BIGINT, city_fk SMALLINT );
INSERT INTO s.customer VALUES (1, 1), (1, 2), (2, 3);
Customers per country? SELECT country_name, count(*) AS number_of_customers FROM s.customer JOIN s.city ON customer.city_fk = s.city.city_id GROUP BY country_name;
Back up all assumptions about data by constraints ALTER TABLE s.city ADD PRIMARY KEY (city_id); ALTER TABLE s.city ADD UNIQUE (city_name); ALTER TABLE s.city ADD UNIQUE (city_name, country_name); ALTER TABLE s.customer ADD PRIMARY KEY (customer_id);
[23505] ERROR: could not create unique index "customer_pkey" Detail: Key (customer_id)=(1) is duplicated.
ALTER TABLE s.customer ADD FOREIGN KEY (city_fk) REFERENCES s.city (city_id); [23503] ERROR: insert or update on table "customer" violates foreign key constraint "customer_city_fk_fkey" Detail: Key (city_fk)=(3) is not present in table "city"
9
Referential consistency
@martin_loetzsch
Only very little overhead, will save your ass

10/18/2017 2017-10-18-dwh-schema-pav.svg
file:///Users/mloetzsch/Downloads/2017-10-18-dwh-schema-pav.svg 1/1
customercustomer_idfirst_order_fkfavourite_product_fklifetime_revenue
productproduct_idrevenue_last_6_months
orderorder_idprocessed_order_idcustomer_fkproduct_fkrevenue
Never repeat “business logic” SELECT sum(total_price) AS revenue FROM os_data.order WHERE status IN ('pending', 'accepted', 'completed', 'proposal_for_change'); SELECT CASE WHEN (status <> 'started' AND payment_status = 'authorised' AND order_type <> 'backend') THEN o.order_id END AS processed_order_fk FROM os_data.order;
SELECT (last_status = 'pending') :: INTEGER AS is_unprocessed FROM os_data.order;
Refactor pipeline
Create separate task that computes everything we know about an order
Usually difficult in real life
Load → preprocess → transform → flatten-fact
10
Computational consistency
@martin_loetzsch
Requires discipline
load-product load-order load-customer
preprocess-product preprocess-order preprocess-customer
transform-product transform-order transform-customer
flatten-product-fact flatten-order-fact flatten-customer-fact

Check for “lost” rows SELECT util.assert_equal( 'The order items fact table should contain all order items', 'SELECT count(*) FROM os_dim.order_item', 'SELECT count(*) FROM os_dim.order_items_fact');
Check consistency across cubes / domains SELECT util.assert_almost_equal( 'The number of first orders should be the same in ' || 'orders and marketing touchpoints cube', 'SELECT count(net_order_id) FROM os_dim.order WHERE _net_order_rank = 1;',
'SELECT (SELECT sum(number_of_first_net_orders) FROM m_dim.acquisition_performance) / (SELECT count(*) FROM m_dim.performance_attribution_model)', 1.0 );
Check completeness of source data SELECT util.assert_not_found( 'Each adwords campaign must have the attribute "Channel"', 'SELECT DISTINCT campaign_name, account_name FROM aw_tmp.ad JOIN aw_dim.ad_performance ON ad_fk = ad_id WHERE attributes->>''Channel'' IS NULL AND impressions > 0 AND _date > now() - INTERVAL ''30 days''');
Check correctness of redistribution transformations SELECT util.assert_almost_equal_relative( 'The cost of non-converting touchpoints must match the' || 'redistributed customer acquisition and reactivation cost', 'SELECT sum(cost) FROM m_tmp.cost_of_non_converting_touchpoints;', 'SELECT (SELECT sum(cost_per_touchpoint * number_of_touchpoints) FROM m_tmp.redistributed_customer_acquisition_cost) + (SELECT sum(cost_per_touchpoint * number_of_touchpoints) FROM m_tmp.redistributed_customer_reactivation_cost);', 0.00001);
11
Data consistency
@martin_loetzsch
Makes changing things easy

Contribution margin 3a
SELECT order_item_id, ((((((COALESCE(item_net_price, 0)::REAL + COALESCE(net_shipping_revenue, 0)::REAL) - ((COALESCE(item_net_purchase_price, 0)::REAL + COALESCE(alcohol_tax, 0)::REAL) + COALESCE(import_tax, 0)::REAL)) - (COALESCE(net_fulfillment_costs, 0)::REAL + COALESCE(net_payment_costs, 0)::REAL)) - COALESCE(net_return_costs, 0)::REAL) - ((COALESCE(item_net_price, 0)::REAL + COALESCE(net_shipping_revenue, 0)::REAL) - ((((COALESCE(item_net_price, 0)::REAL + COALESCE(item_tax_amount, 0)::REAL) + COALESCE(gross_shipping_revenue, 0)::REAL) - COALESCE(voucher_gross_amount, 0)::REAL) * (1 - ((COALESCE(item_tax_amount, 0)::REAL + (COALESCE(gross_shipping_revenue, 0)::REAL - COALESCE(net_shipping_revenue, 0)::REAL)) / NULLIF(((COALESCE(item_net_price, 0)::REAL + COALESCE(item_tax_amount, 0)::REAL) + COALESCE(gross_shipping_revenue, 0)::REAL), 0)))))) - COALESCE(goodie_cost_per_item, 0)::REAL) :: DOUBLE PRECISION AS "Contribution margin 3a" FROM dim.sales_fact;
Use schemas between reporting and database
Mondrian
LookerML
your own
Or: Pre-compute metrics in database
12
Semantic consistency
@martin_loetzsch
Changing the meaning of metrics across all dashboards needs to be easy

Focus on the complexity of data rather than the complexity of technology
@martin_loetzsch
13

14
We are open sourcing our BI infrastructure
@martin_loetzsch
ETL part released end of 2017

@martin_loetzsch
15
Meet us here at DN

16
Refer us a data person, earn 200€
@martin_loetzsch
Also analysts, BI managers

Thank you
@martin_loetzsch
17