dom and sax parsers
DESCRIPTION
DOM and SAX ParsersTRANSCRIPT

DOM AND SAX PARSERS

Agenda
• XML PARSING
• DOM PARSER
• SAX PARSER
• SAMPLE EXAMPLE PROGRAM
• ADVANTAGES & DISADVANTAGES

What is XML Parser?
• A program or module that checks a well-formed syntax and provides a capability to manipulate XML data elements.
• Navigate through the XML document
• extract or query data elements
• Add/delete/modify data elements

DOCUMENT OBJECT MODEL(DOM)
• Document Object Model is a standard way to manipulate (read, modify and make sense of) XML documents
• Formally, XML DOM is a programming interface (i.e. an API) that you can use in programs for manipulating XML documents
• XML DOM is designed (by W3C) to be used with any programming language and any operating system
• An object-based, language-neutral API for XML and HTML documents

DOM Contd..
• The XML DOM is the Document Object Model for XML
• The XML DOM is platform- and language-independent
• The XML DOM defines a standard set of objects for XML
• The XML DOM defines a standard way to access XML documents
• The XML DOM defines a standard way to manipulate XML documents
• The XML DOM is a W3C standard

• The W3C has designed three levels of the DOM:
• DOM Level1: DOM Level 1 provides basic functionality for navigating and manipulating HTML and XML documents.
• DOM Level2: It introduces support for XML namespaces, and for stylesheets such as CSS.
• DOM Level 3: It provides a complete mapping between DOM and XML. It supports entity declarations, whereas DOM Level 2 supports only entities.

DOM Contd..
• Reads the whole document and builds DOM tree
• The tree is made up of a hierarchy of nodes, with each node representing an object in the document.
• random access to any of the nodes in a document's DOM tree
• Allows programs and scripts to build documents, navigate their structure, add, modify or delete elements and content
• Powerful document navigation
• large XML documents require more memory

Some XML Parsers which support DOM
• System.Xml –Namespace for parsing XML files in .NET
• MSXML – Microsoft’s XML parser built-into IE 5.5 and later versions (JavaScript, VB, C++, Java)
• JAXP – Sun Mycrosystem’s Java API for XML Parsingjava.sun.com/xml/download.html
• XML4J – IBM’s XML Parser for Java www.alphaworks.ibm.com/tech/xml4j
• Xerces – Apache’s XML Parser for Java/C++/Perl xml.apache.org/
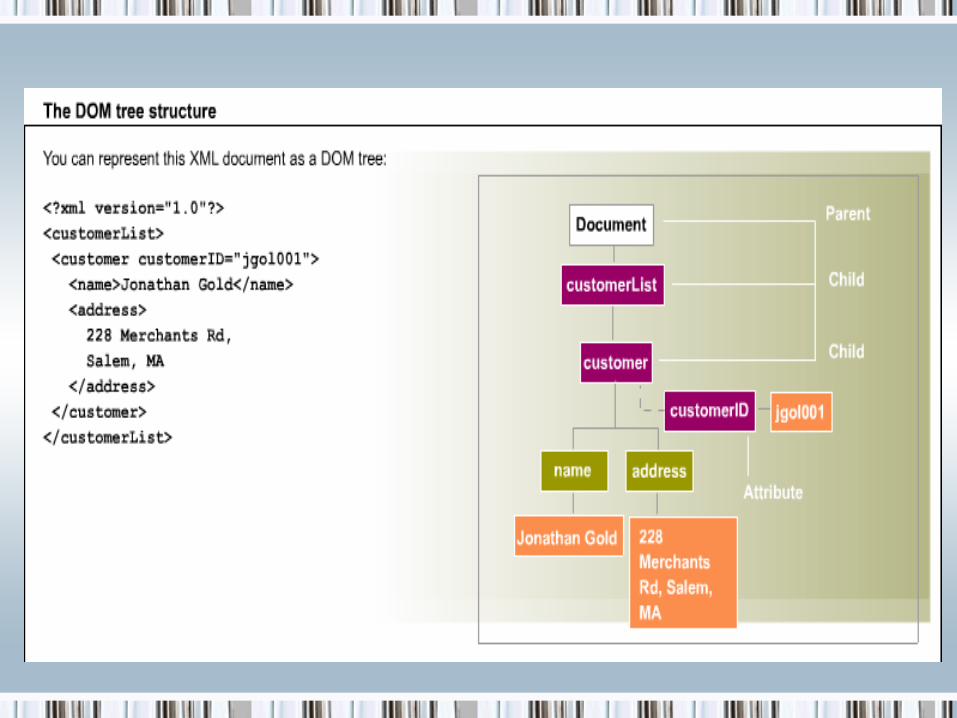

• DOM representation
• Entire DOM represented by a DOMDocument object• Contains root node and all its child nodes
• Any node in a DOM can be represented with the object XMLDOMNODE
• Some DOMDocument properties
Properties Description async Sets the method of code execution. A setting of true
allows code execution to continue even if the XML document has not finished loading. Microsoft specific.
childNodes Contains a list of child nodes. documentElement Retrieves the document’s root element. text Contains the value of the node and its child nodes.
Microsoft specific. xml Contains the XML subtree of a node marked up as text.
Microsoft specific.
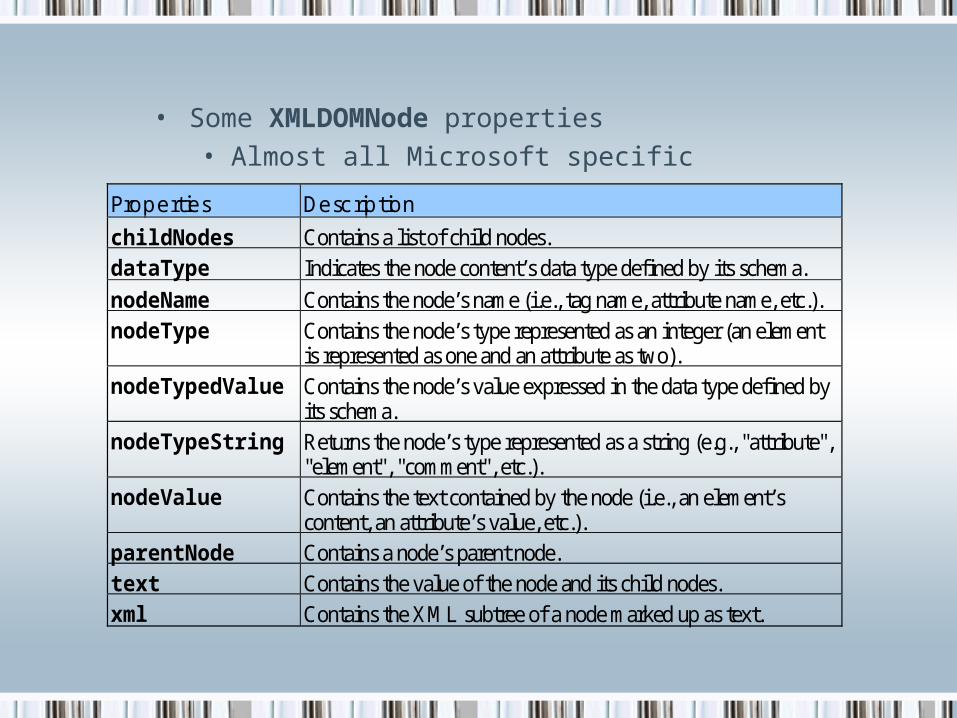
• Some XMLDOMNode properties
• Almost all Microsoft specific
Properties Description
childNodes Contains a list of child nodes.
dataType Indicates the node content’s data type defined by its schema.
nodeName Contains the node’s name (i.e., tag name, attribute name, etc.).
nodeType Contains the node’s type represented as an integer (an element is represented as one and an attribute as two).
nodeTypedValue Contains the node’s value expressed in the data type defined by its schema.
nodeTypeString Returns the node’s type represented as a string (e.g., "attribute", "element", "comment", etc.).
nodeValue Contains the text contained by the node (i.e., an element’s content, an attribute’s value, etc.).
parentNode Contains a node’s parent node.
text Contains the value of the node and its child nodes.
xml Contains the XML subtree of a node marked up as text.
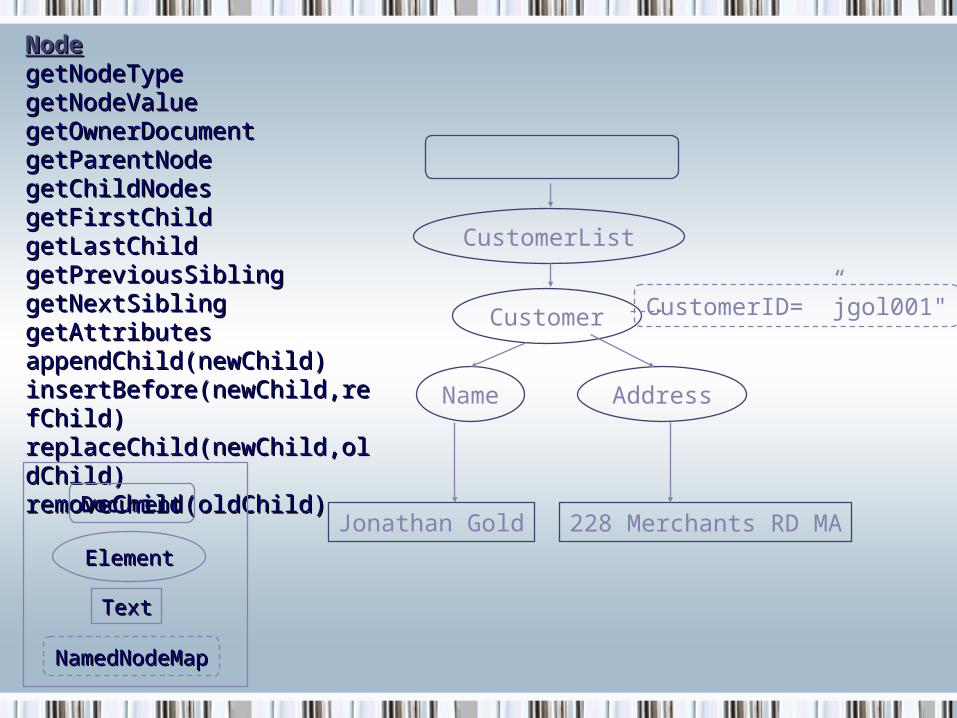
NodeNodegetNodeTypegetNodeTypegetNodeValuegetNodeValuegetOwnerDocumentgetOwnerDocumentgetParentNodegetParentNodegetChildNodesgetChildNodesgetFirstChildgetFirstChildgetLastChildgetLastChildgetPreviousSiblinggetPreviousSiblinggetNextSiblinggetNextSiblinggetAttributesgetAttributesappendChild(newChild)appendChild(newChild)insertBefore(newChild,refChild)insertBefore(newChild,refChild)replaceChild(newChild,oldChild)replaceChild(newChild,oldChild)removeChild(oldChild)removeChild(oldChild)
DocumentDocument
ElementElement
NamedNodeMapNamedNodeMap
TextText
CustomerList
Customer
Name Address
CustomerID= ”jgol001"
Jonathan Gold 228 Merchants RD MA

DOM Interfaces
• Node: Defines properties & methods for all the nodes in DOM tree• nodeName, nodeType, nodeValue, parentNode• appendChild(), hasChildNodes(), removeChild();
• Document:• CreateElement();• CreateAttribute();• CreateComment();
• Element: Which represesnts Elements• getAttribute();• removeAttribute();• setAttribute();
• Attr: Provides properties for accessing attribute nodes• name and value
• Text: Enables to access text nodes.

DOM Interfaces Contd..
• NodeList for ordered lists of nodes• e.g. getElementsByTagName("name").nodeValue
Output: Jonathan Gold
• Length of a node list:• getElementsByTagName(‘address').length
Output: 1
• NamedNodeMap for unordered sets of nodes accessed by their name:• e.g. var x = xmlDoc.getElementsByTagName(“customer");• var attlist = x.item(0).attributes; • var att = attlist.getNamedItem(“CustomerID"); • document.write(att.value)Output: jgol001

Example XML Document books.xml<?xml version="1.0"?><Books> <Title price =“$23.95”>My Life and Times</Title> <Author>Paul</Author> <Date>July, 1998</Date> <ISBN>94303-12021-43892</ISBN> <Publisher>McMillin Publishing</Publisher>
<Title price=“$19.95”>The Adventures of a Messiah</Title> <Author>Richard</Author> <Date>1977</Date> <ISBN>0-440-34319-4</ISBN> <Publisher>Dell Publishing Co.</Publisher></Books>
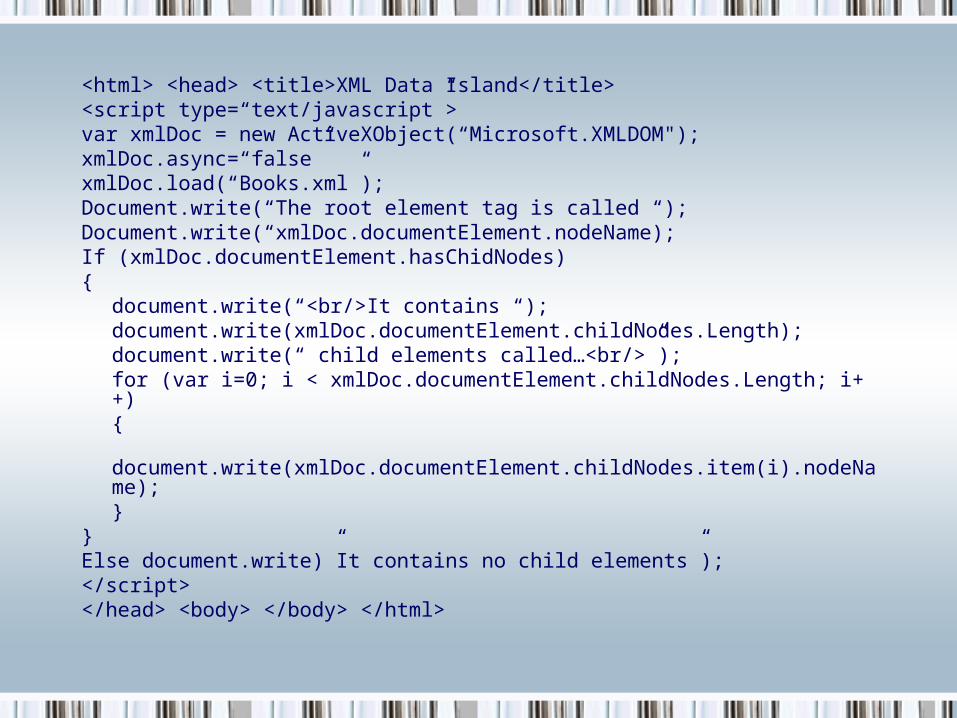
<html> <head> <title>XML Data Island</title><script type=“text/javascript”>var xmlDoc = new ActiveXObject(“Microsoft.XMLDOM");xmlDoc.async=“false”xmlDoc.load(“Books.xml”);Document.write(“The root element tag is called “);Document.write(“xmlDoc.documentElement.nodeName);If (xmlDoc.documentElement.hasChidNodes){
document.write(“<br/>It contains “);document.write(xmlDoc.documentElement.childNodes.Length);document.write(“ child elements called…<br/>”);for (var i=0; i < xmlDoc.documentElement.childNodes.Length; i++){
document.write(xmlDoc.documentElement.childNodes.item(i).nodeName);}
}Else document.write)”It contains no child elements”);</script></head> <body> </body> </html>

Output
The root element tag is called BooksIt contains 10 child elements called…TitleAuthorDateISBNPublisherTitleAuthorDateISBNPublisher

Getting Element Contentsfor (var i=0; i < xmlDoc. getElementByTagName(“Author”).Length); i++){
if (xmlDoc. getElementByTagName(“Author”).item(i).text == “Paul”){ document.write(“<p>Details of ‘Paul’ matched item:<br/>”);
document.write( “<span style=‘font:bold 16pt’>”); xmlDoc.getElementByTagName(“Title”).item(i).text );
document.write(“ “); document.write(xmlDoc.getElementByTagName(“ISBN”).item(i).text ); document.write(“ “);
document.write(xmlDoc.getElementByTagName(“Publisher”).item(i).text ); document.write(“ “);
document.write(xmlDoc.getElementByTagName(“Date”).item(i).text ); document.write(“</span></p>”);}
}
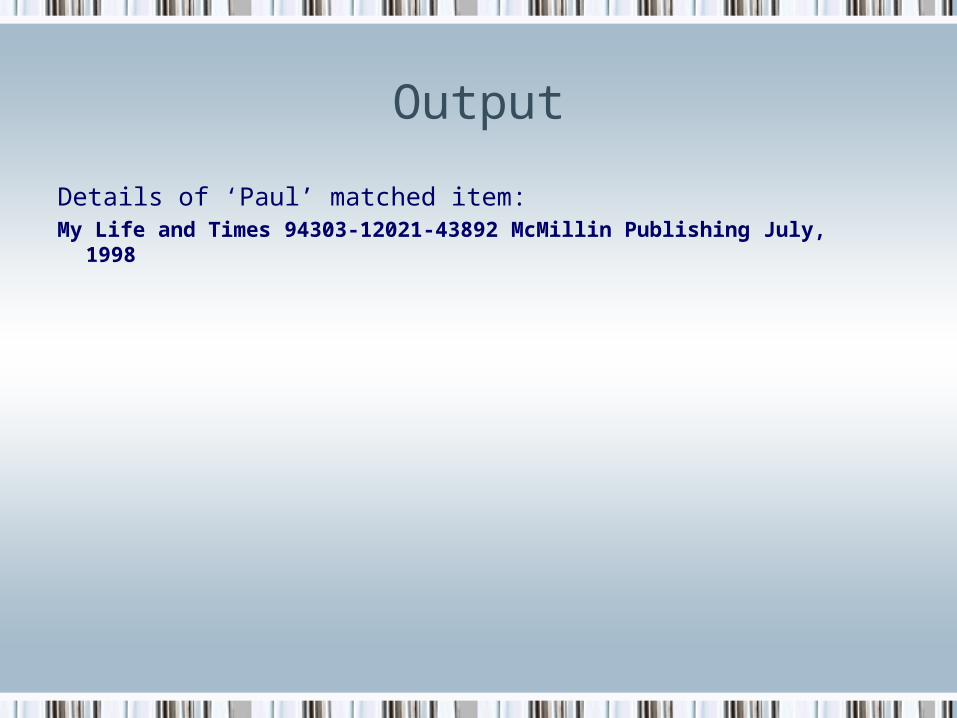
Output
Details of ‘Paul’ matched item:My Life and Times 94303-12021-43892 McMillin Publishing July, 1998

When Should I use DOM
When you need random access to document data If random access to information is crucial, it is better to use the
DOM to create a tree structure for the data in memory.
When you want to implement complex searches maintain data structures holding context information such as
attributes of current element
No SAX implementation in current browsers Microsoft’s Internet Explorer
When you need to perform XSLT transformations
When you want to modify and save XML DOM allows you to create or modify a document in memory, as well
as read a document from an XML source file

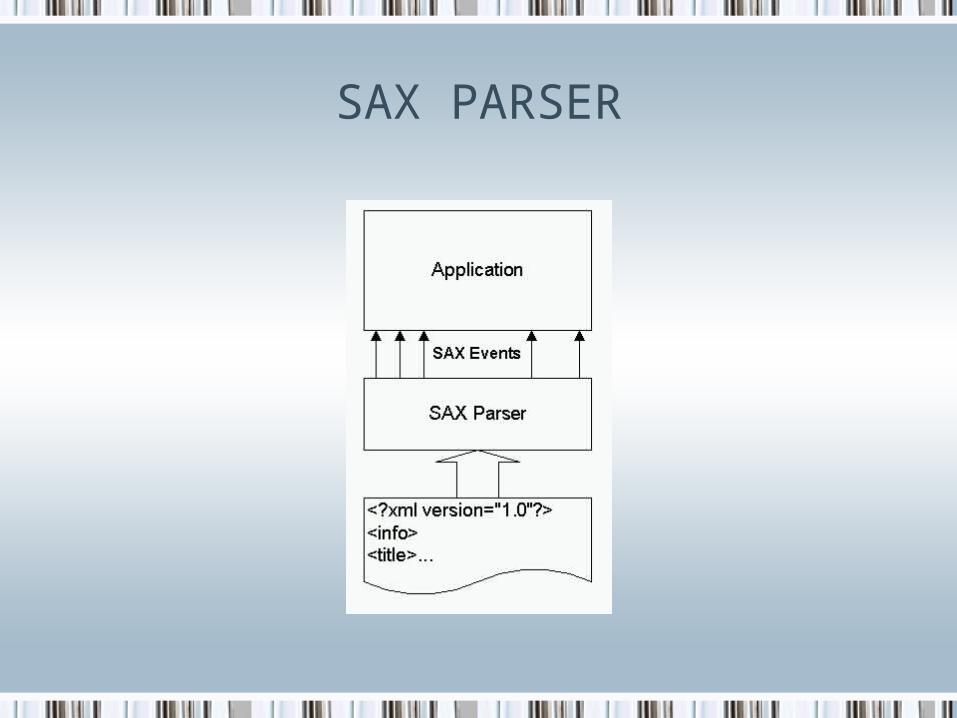
SAX PARSER
• Simple API for XML- SAX
• Fast and Efficient
• Fires Event handlers at each:
• Start Tag
• Tag Body
• End Tag
• Read Only API
• Cannot be used to Update XML
• Good for large documents
• Requires less memory
• Process the document sequentially
• Java Specific
SAX PARSER
SAX XML Reader vs .NET XML Reader

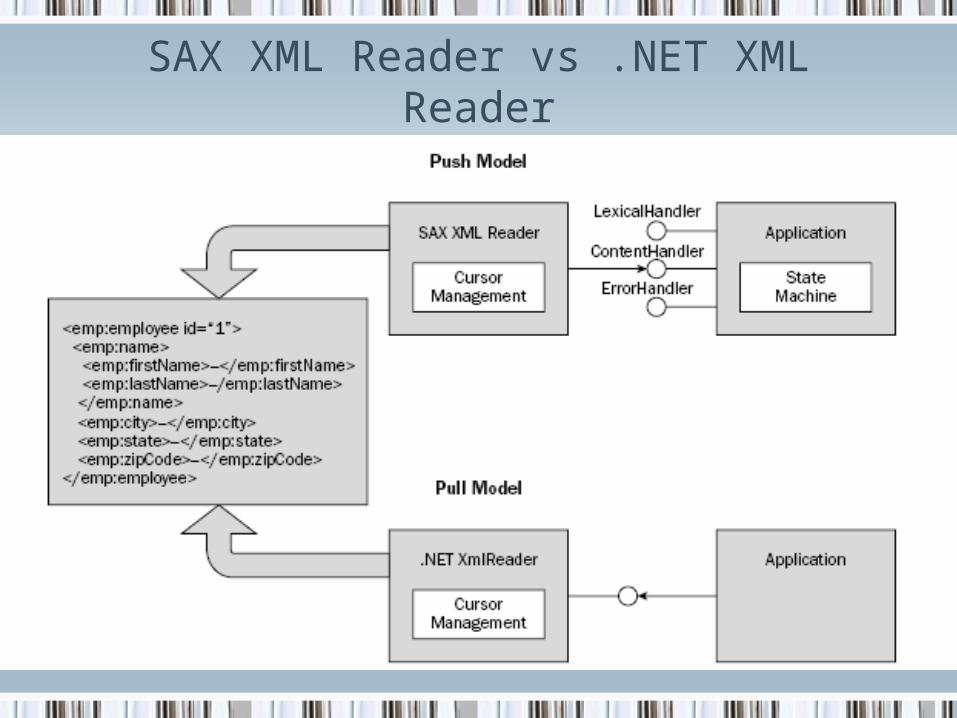
SAX PARSING
• It interprets XML as a stream of events
• you supply event-handling callbacks
• SAX parser invokes your event-handlers as it parses
• .NET framework doesnot provide native SAX implementation support
<?xml version="1.0" encoding="UTF-8"?><parts><part>TurboWidget</part></parts>
StartDocument( )StartElement( "parts" )StartElement( "part" )Characters( "TurboWidget" )EndElement( "part" )EndElement( "parts" )EndDocument( )

Advantages
• Reduced Memory and CPU Usage: SAX reduces memory and CPU usage because it only processes one section of an XML document at a time.
• Customizable: SAX is customizable. When an event is triggered, the associated application receives data about the triggering event
• Streamlined and fast: SAX is streamlined, fast, and supports pipelining. This means that the parser can produce output while the document is being parsed.

Disadvantages
• Uni-directional parsing: The SAX parser is uni-directional. It can only parse forwards in a document, which means some forms of navigation, including certain XPath expressions, cannot be achieved using SAX. DOM should be used in these situations.
• No structure manipulation: Because only a portion of the XML document is in memory at any one time, it is difficult to add or edit nodes using SAX. If this functionality is required, then DOM should be considered.
• Only works with fully formed XML documents: SAX can only work with a fully formed XML document. It cannot be used to process partial XML documents.

Disadvantages Contd..
• No random access to the document: Because the document is not in memory, you must handle data in the order in which it is processed.
• Difficult to implement complex searches: It is your responsibility to maintain data structures holding context information that you must retain, such as the attributes of the current element
• No SAX implementation in current browsers: SAX support is not built into Microsoft® Internet Explorer.

When Should I use SAX• When your documents are large: Perhaps the biggest advantage of
SAX is that it requires significantly less memory to process an XML document than the DOM. With SAX, memory consumption does not increase with the size of the file.
• When you need to abort parsing: Because SAX allows you to abort processing at any time, you can use it to create applications that fetch particular data.
• When you want to retrieve small amounts of information: For many XML-based solutions, it is not necessary to read the entire document to achieve the desired results. Scanning only a small percentage of the document results in a significant savings of system resources.

• When you want to create a new document structure: In some cases, you might want to use SAX to create a data structure using only high-level objects, such as stock symbols and news, and then combine the data from this XML file with other news sources. Rather than build a DOM structure with low-level elements, attributes, and processing instructions, you can build the document structure more efficiently and quickly using SAX.
• When you cannot afford the DOM overhead: For large documents and for large numbers of documents, SAX provides a more efficient method for parsing XML data. For example, consider a remote procedure call (RPC) that returns 10 MB of data to a middle-tier server to be passed to a client. Using SAX, the data can be processed using a small input buffer, a small work buffer, and a small output buffer. Using the DOM, the data structure is constructed in memory, requiring a 10 MB work buffer and at least a 10 MB output buffer for the formatted XML data.

?

• References:
• http://www.w3.org/DOM
• http://msdn.microsoft.com
• http://www.codeproject.com
• http://www.wrox.com