dot plot daniel svozil. software choice source: bioinformatics for dummies
TRANSCRIPT

DOT PLOTDaniel Svozil

Software choice
source: Bioinformatics for Dummies

Dotlet• • Learn by example – use the sequence from the Repeated domains

• In this case, the darker the pixel, the lower the score.• There will be a large number of pixels with low scores and
only a few ones with high scores.• Tune the grayscale in order to make the background
noise (low scores) disappear and the similar regions stand out more clearly.
• To do this, use the histogram window.• This represents the frequency of each
score, over all the pixels, on linear (blue) and logarithmic (purple) scales.• lowest possible score on the left and the highest
on the right• If the sequence has some similarity, there will
be a smaller peak of higher scores. Semi-logarithmic plot makes it even more visible.

• With the scrollbars below and above the histogram, respectively, bring the lower threshold just past the first peak, and the higher threshold just past the second peak.
• Now, the background noise has disappeared from the dots window, and the similar regions stand out more clearly.

• Well matching residues – blue.• The cursor can also be moved with the keyboard with the
arrow keys, and with '<' (up left), '>' (down right), '[' (up right), and ']' (down left).
• Now play with all sequences in Dotlet exampes section, read the comment and try to understand:
http://myhits.isb-sib.ch/util/dotlet/doc/dotlet_examples.html

Getting the right window size• Long windows = clean plots.• The size of a window should be within the same range as
the size of the elements you’re looking for. For instance, if you’re looking for conserved domains in proteins, a size of 50 amino acids or higher is appropriate.
• Shorter windows are more sensitive but bring some noise with them.
• Start with a large window and narrow it a little until the signal you’re looking for appears.

More of Dotlet• What is the UniProtKB database?• What are the UniProtKB/Swiss-Prot and
UniProtKB/TrEMBL? What is the difference between them?
• Using Dotlet, compare following two Uniprot sequences: P05049 (1st sequence) and P08246 (2nd sequence).• Are these sequences homologous?• What is the function of P05049?• P05049 is a serine protease. Would you run a wet lab experiment
to check the protease activity of P08246?• You should check if these two sequences are homologous in the
serine protease region. Do you see some homologous regions on the dotplot?

Working with a single DNA sequence

Removing vector sequences• Contamination from your own vector sequence (as a
responsible scientist, you’re expected to have this information) – you may search for the vector sequence you expect
• Cross-contamination by somebody else’s vector – search not only for the sequence you expect, but also for other possible vector sequences.
• Before working with your DNA sequence, you should always clean it with e.g. NCBI VecScreen http://www.ncbi.nlm.nih.gov/VecScreen/VecScreen.html• Basically, it performs a blastn search against UniVec – database of
vector sequences
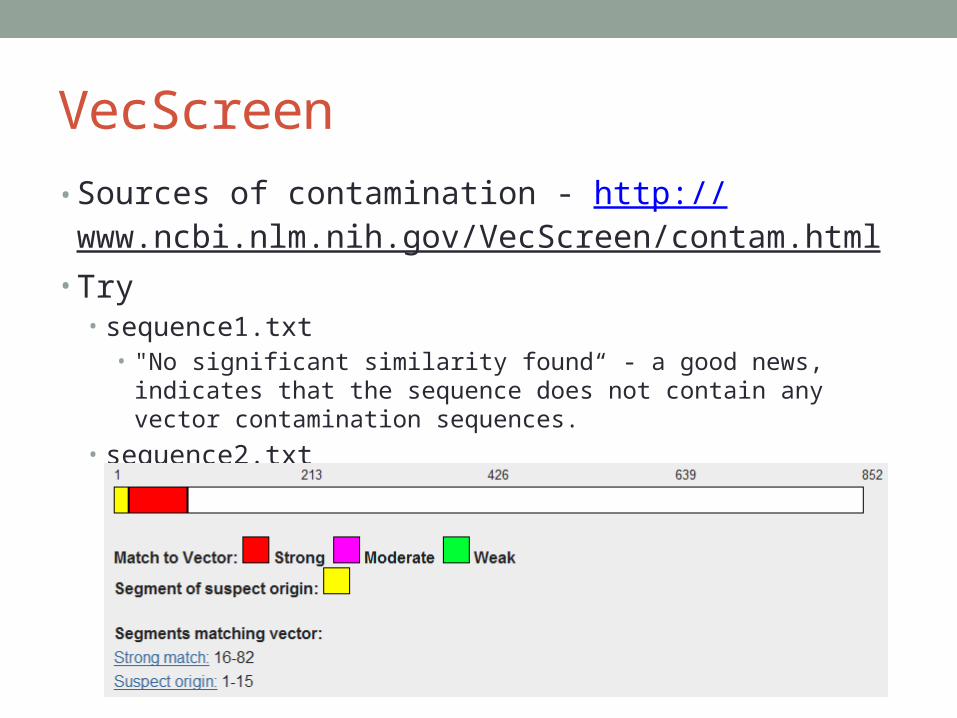
VecScreen• Sources of contamination - http://
www.ncbi.nlm.nih.gov/VecScreen/contam.html • Try
• sequence1.txt• "No significant similarity found“ - a good news, indicates that the
sequence does not contain any vector contamination sequences.
• sequence2.txt

the query sequence
matches three vector
sequences
Let’s say we know the vector used for cloning: pCR2.1-TOPO.
Which sequence would you remove?
Remove this sequence and check the results on the cleaned sequence.

• Clean sequence3.txt. What is the result?• Such a sequence is generally considered as the esult of a
chimeric clone – i.e. clone consisting two sequences.• In this case, throwing it away is the safest thing to do!
• In sequence4.txt is a sequence you cloned in the vector pUC19. Is it contaminated? • How would you clean it?• VecScreen reports a strong match with the lactose operon genes
from E. coli. Not from pUC19!• However, this is ok as most commercial vectors are derived from
the same initial natural plasmid and E. coli constructs. Their sequences are identical, and UniVec matches are reported in the ordedr they appear in the database.
• http://www.ncbi.nlm.nih.gov/VecScreen/Interpretation.html

Restriction map
• It is possible to cut DNA sequences using restriction
enzymes.
• Each type of restriction enzyme recognizes and cuts a
different sequence:• EcoR1: GAATTC
• BamH1: GGATCC
• There are more than 900 different restriction enzymes,
each with a different specificity
• The restriction map is the list of all potential cleavage sites
in a DNA molecule
Restriction map• To compute a restriction map is not that difficult. All you
need to do is to look for exact matches of a given restriction-enzyme site within your sequence.
• Enzymes and sites are in the REBASE database - http://rebase.neb.com
• Nebcutter - http://tools.neb.com/NEBcutter2/• Webcutter - http://rna.lundberg.gu.se/cutter2/• VIRS - http://bis.zju.edu.cn/virs/index.html
• Try to construct a restriction map of the sequence5.fasta.
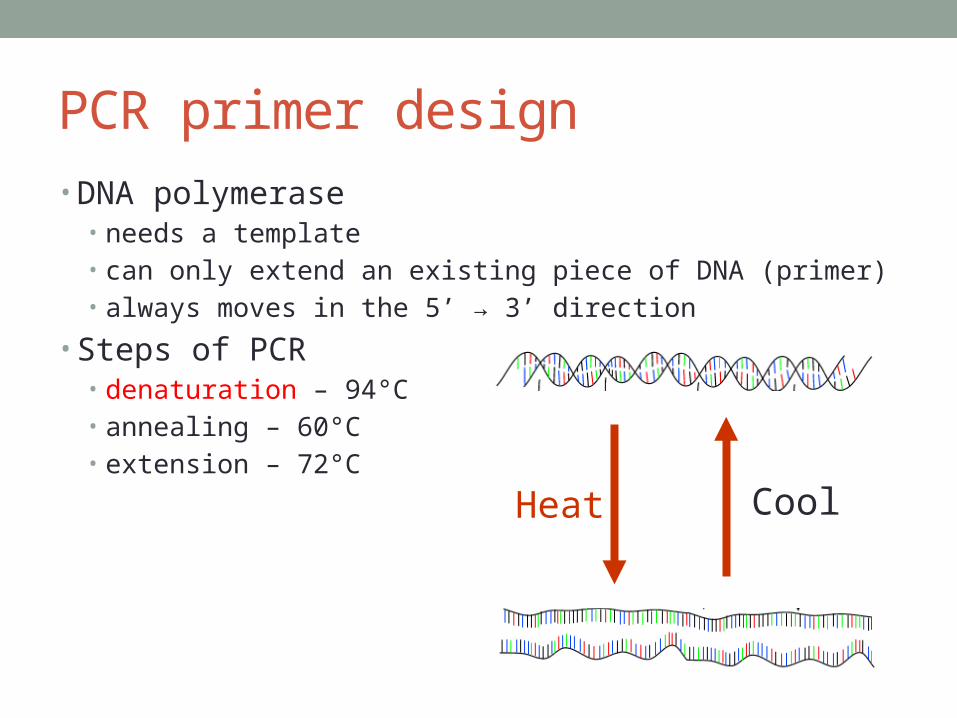
PCR primer design• DNA polymerase
• needs a template• can only extend an existing piece of DNA (primer)• always moves in the 5’ → 3’ direction
• Steps of PCR• denaturation – 94°C• annealing – 60°C• extension – 72°C
Heat Cool

PCR primer design• DNA polymerase
• needs a template• can only extend an existing piece of DNA (primer)• always moves in the 5’ → 3’ direction
• Steps of PCR• denaturation – 94°C• annealing – 60°C• extension – 72°C

PCR primer design• DNA polymerase
• needs a template• can only extend an existing piece of DNA (primer)• always moves in the 5’ → 3’ direction
• Steps of PCR• denaturation – 94°C• annealing – 60°C• extension – 72°C

Primers• primer sequence
• Need to be chosen to uniquely select for a region of DNA, avoiding the possibility of mishybridization to a similar sequence nearby.
• primer length• 18-30 bp (18-22 optimum)• primers longer tha 30 bps are not specific enough
• primer melting temperature Tm
• Temperature at which DNA duplex dissociates to become single stranded
• Pairs of primers should have similar melting temperatures since annealing in a PCR occurs for both simultaneously.
• Itakura’s empirical rule (quick and dirty, works “well” for temperatures 45°C-70°C, Wallace temperature)

Primers• primer melting temperature Tm
• more accurate estimations – nearest neighbor model• OligoCalc - http://www.basic.northwestern.edu/biotools/oligocalc.html
• primer annealing temperature Ta
• depends on the length and composition of primers• Rychlik formula
• Too low Ta – one or both primers will anneal to sequences other than true target, as internal single-base mismatches or partial annealing may be tolerated. This can lead to nonspecific amplification and will consequently reduce the yield of the desired product.
• Too high Ta – may yield little product, as the likelihood of primer annealing is reduced.

Primers• GC content
• Primers with a 40-60% GC content ensure stable binding of primer/template.
• The presence of G or C bases at the 3′ end of primers (GC clamp) helps to promote correct binding at the 3′ end due to the stronger hydrogen bonding of G and C bases.
• However, strings of G and of C can form internal, non-Watson-Crick base pairs that disrupt stable primer binding. Generally, sequences containing more than three repeats of G or of C in sequence should be avoided in the first five bases from the 3′ end of the primer.
• A short run of G’s at or near the 5′ end of a primer will not disrupt stable binding because the 5′ positioning does not lead to involvement in disruptive secondary structures.
• It is best to select primers with a random base distribution.

Primers• no secondary structures
• Presence of the primer secondary structures produced by intermolecular or intramolecular interactions can lead to poor or no yield of the product.
• e,g, hairpins, self dimers, cross dimers
• It is desirable to design specific primer pairs which do not assume secondary structures during the reaction.
• AutoDimer - screens primers for primer-dimer and hairpins http://www.cstl.nist.gov/div831/strbase/AutoDimerHomepage/AutoDimerProgramHomepage.htm
source: http://www.premierbiosoft.com/tech_notes/PCR_Primer_Design.html

PCR Primer Design• Pick some sequence from NCBI nucleotide (<1000 bp)
and play with the primer design tool Primer3 – from http://biotools.umassmed.edu
• After you’ve got your primers, you must verify they will not hybridize anywhere except you intend them to hybridize.• e.g. primer sequences are not outside the gene you’re interested in• or primers do not resemble a frequent repeats in DNA
• Technique for avoiding this problem: BLAST searches against the vector sequences, the genome sequences, their most common repeats.

PCR Primer Design• PrimerBLAST at NCBI - http://
www.ncbi.nlm.nih.gov/tools/primer-blast/• It uses Primer3 to design PCR primers and then submits
them to BLAST search against user-selected database. • The BLAST results are then automatically analyzed to
avoid primer pairs that can cause amplification of targets other than the input template.