
1
Big Data The Big Picture
Recolección y tratamiento de datos masivos de orígenes diversos, que representan una fuente constante para el análisis y descubrimiento de
información útil para la toma de decisiones.

2
TECNOLOGÍAS Trabajaremos con las principales tecnologías del mercado, como Apache Hadoop, Spark y Hbase o MapReduce
INFRAESTRUCTURA Llevaremos a cabo proyectos sobre Cloudera, la distribución de Hadoop más utilizada. Pero veremos implementaciones como IBM Big Insights o MapR
ANÁLISIS Y BI Trabajaremos con Python y R como lenguajes y nos
introduciremos en suites como IBM Cognos BI o
herramientas de análisis estadístico como SPSS
VISUALIZACIÓN Nos adentraremos en el
mundo de la visualización avanzada de datos, y
trabajaremos con tableau, R y distintas librerías
python como NetworkX, matplotlib o geoplotlib
entre otras.
ALMACENAMIENTO Tendremos ocasión de trabajar con Apache Cassandra y MongoDB y estudiaremos los Big Data tradeoffs entre Bases de datos relacionales y NoSQL. También estudiaremos la idoneidad de las Graph Databases como Neo4j o GraphDB

3
Data Scientist
Ordena, clasifica y modela los datos y elabora modelos predict ivos. Las matemáticas, y las estadísticas sus armas
Data Architect
Diseña sistemas de gestión de datos e integra, centraliza y gestiona orígenes d e d a t o s . E l modelado de datos y los procesos ETL son su ámbito.
Data Analyst
Recolecta, procesa y realiza análisis estadísticos para llegar a enunciados que representen t e n d e n c i a s o hechos reales.
Data Engineer
C o n s t r u y e n , m a n t i e n e n y evalúan soluciones Big Data diseñadas por el arquitecto.
D e c i s i o n Maker
Apoyan la toma de decisiones con las c o n c l u s i o n e s d e r i v a d a s d e l análisis de datos. Las herramientas BI son su medio
Perfiles
4
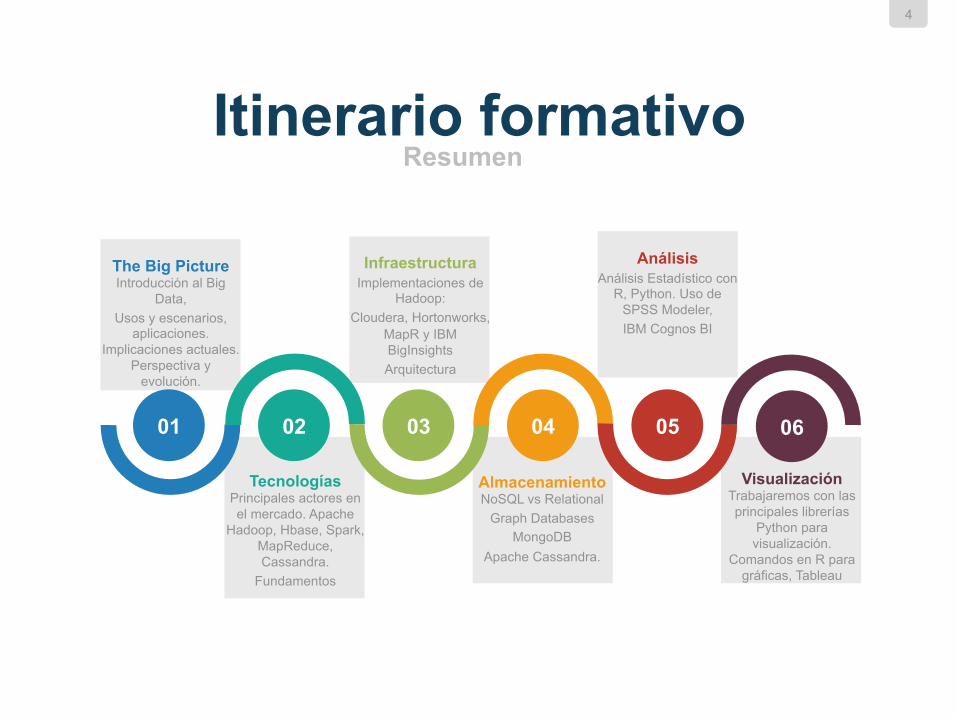
Visualización Trabajaremos con las principales librerías
Python para visualización.
Comandos en R para gráficas, Tableau
Análisis Análisis Estadístico con
R, Python. Uso de SPSS Modeler, IBM Cognos BI
Almacenamiento NoSQL vs Relational
Graph Databases MongoDB
Apache Cassandra.
Infraestructura Implementaciones de
Hadoop: Cloudera, Hortonworks,
MapR y IBM BigInsights Arquitectura
Tecnologías Principales actores en el mercado. Apache
Hadoop, Hbase, Spark, MapReduce, Cassandra.
Fundamentos
Itinerario formativo Resumen
01 02
The Big Picture Introducción al Big
Data, Usos y escenarios,
aplicaciones. Implicaciones actuales.
Perspectiva y evolución.
03 04 05 06

5
Distribución del conocimiento Cómo se organiza el contenido
F u n d a m e n t o s y Conceptos El objetivo será fundar una base só l ida donde los conceptos estén claros y se obtenga una visión actual y holística del Big Data.
Experiencia Real Nuestros expertos están trabajando en proyectos de Big Data en empresas de primer nivel. Compartirán con nosotros los casos a los que se enfrentan día a día, y analizaremos juntos las lecciones que han obtenido.
Clases Únicas Una vez a la semana recibiremos una master class de un experto en diferentes áreas que nos desvelarán los secretos y conocimientos avanzados que de otra manera tardaríamos años en adquirir.
E m i n e n t e m e n t e práctico La mayor parte del programa se dedicará a la realización tutorizada de ejercicios prácticos. Estos ejercicios serán guiados al principio pero muchos ejercicios se real izarán en equipo y podrán tener más de una solución.
Teoría Casos Reales
Master Class
Ejercicios
10% 20% 20% 50%

6
Habilidades Qué habilidades adquiriremos
Big Data Fundamentals
Analítica, Estadística y Business Intelligence Los datos necesitan un análisis para convertirse en enunciados, trabajaremos con Python, R, SPSS y Cognos
La base Una visión holística del Big
Data y las tecnologías y Soluciones a su alcance.
Tendencias y futuro.
Hadoop e implementaciones Adquiriremos dominio de la plataforma y estudiaremos las distribuciones más utilizadas, así como su idoneidad en cada tipo de proyecto.
Big Data Storage Estudiaremos los motores de bases de datos en tres
enfoques, noSQL, Relacionales y Graph
Databases. Trabajaremos con MongoDB
La representación del dato
Adquiriremos destreza en la representación de los
datos de una forma exhaustiva e intuitiva
Plataforma Hadoop
Big Data Storage
Analytics y BI
Visualization

7
Cómo nos gusta enseñar Nuestra metodología
El conocimiento se transmite. Nos apasiona nuestro trabajo y deseamos que n u e s t r o s a l u m n o s part ic ipen de nuestra ilusión. El aprendizaje se p o t e n c i a c u a n d o t e diviertes… Esto es un hecho,
Elconocimiento se adquiere Nues t ra f i l oso f ía es a p r e n d e r h a c i e n d o . Sabemos que es ahí donde necesitas nuestra guía. No te vamos a enseñar nada que puedas buscar tu mismo en Google.

8
Herramientas
01
02
03
04
05 MASTER CLASSES Y CASOS REALES
PRUEBAS DE NIVEL Y APROVECHAMIENTO
VIRTUAL & REMOTE TRAINING
LABORATORIOS ESCRITORIOS VIRTUALES
LEARN BY DOING

9
Cómo seleccionamos a los candidatos Proceso de selección
Hemos puesto mucho esfuerzo en crear estos másteres. Deseamos que todos los part icipantes disfruten aprediendo tanto como nosotros vamos a disfrutar enseñando. Necesitamos asegurarnos que todos los candidatos tienen las características y capacidades necesarias para aprovechar y asimilar los conocimientos.
Buscamos a los mejores
www.digitaltechinstitute.com/apply
10
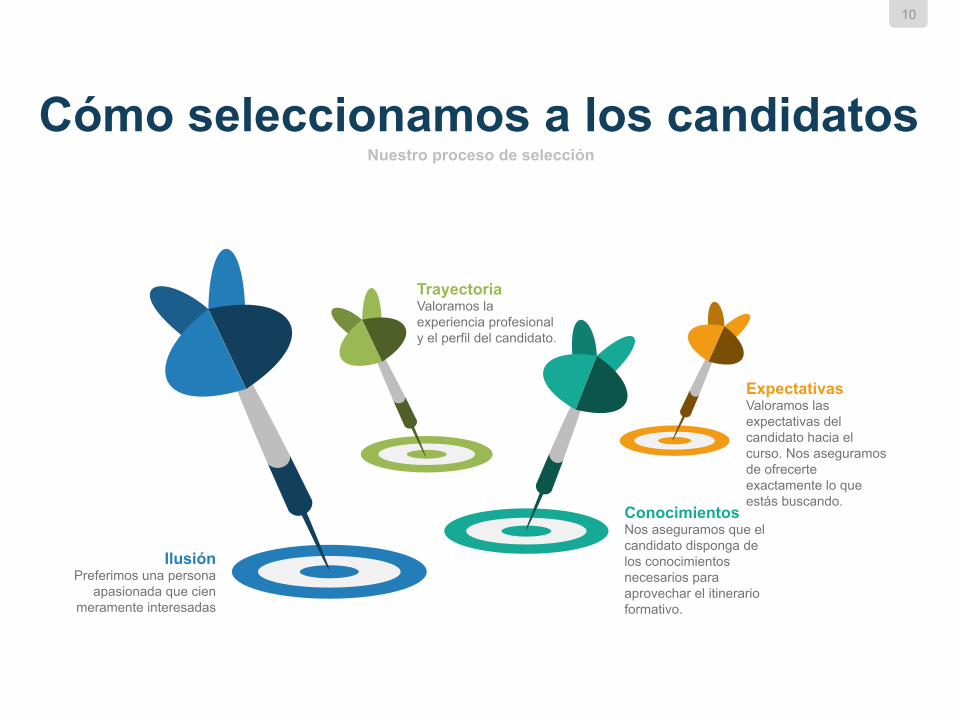
Cómo seleccionamos a los candidatos Nuestro proceso de selección
Ilusión Preferimos una persona
apasionada que cien meramente interesadas
Conocimientos Nos aseguramos que el candidato disponga de los conocimientos necesarios para aprovechar el itinerario formativo.
Expectativas Valoramos las expectativas del candidato hacia el curso. Nos aseguramos de ofrecerte exactamente lo que estás buscando.
Trayectoria Valoramos la experiencia profesional y el perfil del candidato.

11
Establecemos las bases. Manejamos los términos de manera apropiada y definimos términos
basándonos en ejemplos.
Módulo 1 - Fundamentos
TECNOLOGÍAS Qué es Hadoop, Hive, MaReduce, HDFS. Distributed & Parallel processing y Hadoop clusters. noSQL. NewSQL. Alternativas y ecosistema Big Data.
INTRODUCCIÓN Qué es Big Data y qué no es Big Data. Casos reales de uso. Definiciones. Quién utiliza Big Data. Perfiles. Por qué es importante.
PRESENTACIÓN Presentación y definición de objetivos. Descripción general de la formación. Claves para sacar el máximo provecho. Entorno de trabajo
FUNDAMENTOS Qué necesitamos saber. Fundamentos de estadística. Conceptos relacionados con data management.
INFRAESTRUCTURA Distribuciones Hadoop. Cloudera. Hortonworks. Isotope. IBM BigInsights.
ALMACENAMIENTO Una inmersión en el mundo del almacenamiento. Descripción general del ecosistema. Tipos de motores. Datawarehousing. OLTP vs OLAP. SQL vs NoSQL. HDFS. Cassandra.
ANALÍTICA Y VISUALIZACIÓN Business Intelligence & Analytics. Herramientas. Formas de representar los datos. Herramientas ara visualización de datos.

12
Conoceremos de fondo Apache Hadoop, HDFS, MapReduce y YARN
Módulo 2 - Tecnologías MAPREDUCE Procesando datos con MapReduce. Fases Map y Reduce. Flujo de datos. Implementando MapReduce en Java. Desplegar un jar en Hadoop. Monitorización.
INSTALACIÓN Modos de Instalación. Modo Standalone. Modo pseudo-distribuido. Configurando SSH. Variables de Entorno. Configuración. Iniciando HDFS y YARN. Monitorización.
INTRODUCCIÓN Hablamos de los distintos componentes y la función que cumple cada uno. Computación distribuida. Otras tecnologías en el ecosistema Hadoop.
ALMACENANDO DATOS Almacenando datos con HDFS. Escritura y lectura. Comandos HDFS. Nodos. Replicación y recuperación. ETL. Ingestión de datos. Hbase.
PLANIFICACIÓN Y TAREAS Anatomía de un Job Run en YARN. Parámetros. Cluster resource Allocation. Colas de trabajos. Ejecutando trabajos en colas específicas. Logs.
YARN Gestión de recursos de cluster. Arquitectura. Daemons. Operación, seguridad y gobierno de datos. Fair scheduler. CPU y Memoria.

13
Trabajaremos con la distribución Hadoop más utilizada Cloudera. También profundizaremos en el
conocimiento de otras distribuciones como Hortonworks , IBM BigInsights o MapR.
Trabajaremos con Impala, Pig, Hue, Spark,..
Módulo 3 - Infraestructura
INTRODUCCIÓN Distribuciones más utilizadas. Cloudera. HortonWorks, MapR. IBM BigInsights. Diferencias, escenarios de idoneidad.
APACHE SPARK Introducción. Instalación. Lenguajes de programación. Appification, RDD. Ingesta de datos, Lambdas. Transformaciones. Acciones. Persistencia. Conversiones implícitas. Java en Spark. Instrumentación y librerías.
IMPALA & PIG Instalación de Impala y pig. Lenguajes de programación. Creando consultas con pig.
CLOUDERA Instalación y VMs. Hardware e infraestructura para un cluster. Cloudera Manager. Montar un cluster de servidor con varios nodos. Seguridad. Monitorización
HUE & OTROS CLIENTES HADOOP Clientes, propósito. Instalando y configurando Hue. Autenticación y autorización.
HDFS Profundizando en HDFS. NameNode. DataNode. Creando, recuperando y manipulando archivos. Comandos HDFS. Copiando datos a Hadoop. Toleranci a fallos.

14
Estudiaremos los distintos sistemas de almacenamiento más utilizados en proyectos Big
Data y sus implicaciones. Trabajaremos con MongoDB como motor noSQL
Módulo 4 - Almacenamiento
INTRODUCCIÓN El almacenamiento en Big Data. Problemática y soluciones. Tipos de bases de datos. noSQL vs SQL. Graph Databases. Bases de datos MPP
MONGODB Introducción e instalación. Escalabilidad. Mongo Shell. Collections, BSON, Operadores. Insert & Updates & Queries. Encontrando documentos. Indexado. Big Data & reporting.
APACHE CASSANDRA Introducción y casos de uso. Arquitectura. Instalación. Replicación y consistencia. Introducción a CQL. Write & read path. Multirow partitions. Compaction. Transacciones, Tipos complejos.
HIVE Arquitectura. Esquema. Hive Warehouse. Lenguaje Hive. HiveQL. Ingesta de datos. Bucketing, joins, distributed cache, UDTFs. Funciones analíticas.
INGESTA DE DATOS. SQOOP Y FLUME Sqoop y Flume. Ingesta de datos desde DB relacionales con Sqoop. Flume network streams. Multi-agent Flows. Sinks, Channels & Interceptors.
HBASE Arquitectura. Diseño de tablas. Relaciones. Nodos de cluster. Hfiles y regions. Scaling y compaction

15
Trabajaremos con los datos para obtener correlaciones y conclusiones que nos ayuden en la toma de decisiones. Trabajaremos con Python pero también tendremos ocasión de profundizar en R y
nos indotrduciremos en SPSS modeler y Cognos BI
Módulo 5 - Análisis
INTRODUCCIÓN La analítica de datos. Herramientas. Introducción al modelado de datos. Relaciones. Normalización. Estadística. Visualización y presentación.
INTRODUCCIÓN A R Introducción e instalación. IDEs para R. Variables, operadores. Estructuras de datos, Funciones, control de flujo. Importando datos. Paquetes. Exploración de datos con R.
ANÁLISIS DE DATOS CON PYTHON Fundamentos de Python. Instalando Python. Ejecutando Programas en Python. Estructuras de datos. Construcciones e iteraciones. Librerías ara análisis. Pandas. NumPy. SciPy. Blaze.
IBM SPSS MODELER Introducción a Data Mining. Trabajando con modeler. Recolección de datos. Entendiendo los datos. Configurando la unidad de análisis. Integrando datos. Derivando y clasificando datos. Relaciones. Modelado.
IBM COGNOS BUSINESS INTELLIGENCE Consumo de datos en Cognos BI. Creación de reportes. Espacio de trabajo. Modelos de Metadata. Framework manger. Cube designer. Extendiendo Cognos.

16
En éste módulo tendremos ocasión de profundizar más en las herramientas de análisis y proceso, con
especial acento en aquellas herramientas y técnicas que nos permiten visualizar los resultados.
Módulo 6 - Visualización
INTRODUCCIÓN La analítica de datos. Herramientas. Introducción al modelado de datos. Relaciones. Normalización. Estadística. Visualización y presentación.
VISUALIZACIÓN DE DATOS CON R Introducción e instalación. IDEs para R. Variables, operadores. Estructuras de datos, Funciones, control de flujo. Importando datos. Paquetes. Exploración de datos con R.
VISUALIZACIÓN DE DATOS CON PYTHON Fundamentos de Python. Instalando Python. Ejecutando Programas en Python. Estructuras de datos. Construcciones e iteraciones. Librerías ara análisis
PENTAHO REPORTING & DASHBOARDS Consumo de datos en Cognos BI. Creación de reportes. Espacio de trabajo. Modelos de Metadata. Framework manger. Cube designer. Extendiendo Cognos.
TABLEAU Introducción a Data Mining. Trabajando con modeler. Recolección de datos. Entendiendo los datos. Configurando la unidad de análisis. Integrando datos. Derivando y clasificando datos. Relaciones. Modelado.







