Download - BigDLでScala × DeepLearning に入門した話

BigDLでScala × DeepLearning に入門した話
nosatohirotaka
Scala Kansai Summit 2017 サブホール2 11:15-11:35

1. 自己紹介
2. 発表動機
3. BigDL
4. DeepLearning
5. 入門
目次

自己紹介

- nosatohirotaka @nosattee MOTEX Inc. Scala歴 3年目
python, C++ Elasticsearch AWS Hololens Lagom
こういう人

• IT資産管理・情報漏洩対策ツール
• スマートデバイス管理ツール
ちょっとだけ会社を紹介
ブースにてお配りしております! 数量限定ですので、お早めに

今日は開発チームメンバー数名でお邪魔させていただいてます!
ブースでは、休憩時間にワイガヤとScalaでモブモブしてるかもです。(休憩時間に)
お気軽にお声掛けくださいませ~
ブース出店中!
写真がまにあえば
・・・

–MOTEXで一緒にScala書きませんか??
“Scalaエンジニア募集中!!”

今日の話

Scalaでこうやって書くんだぜ?
・・的な話はありません。

○○といった課題を DeepLearning で
解決できたぜ!事例紹介するよ!
・・・という話でもありません。

とあるDeepLearning ライブラリについて
サンプルを動かすために うす~く調べてみたりしました。
という話です。

、、というわけで。

あっちのほうがおもしろそうだなぁ・・→今ならまだ間に合いますよ!

発表動機
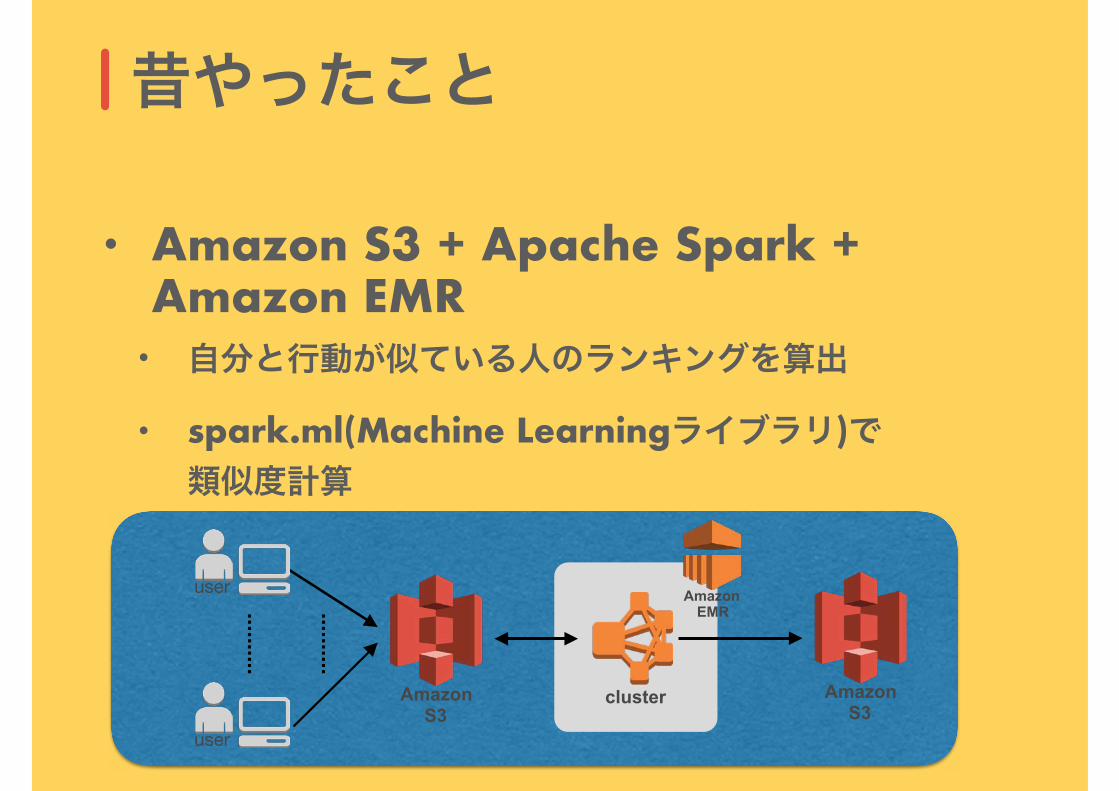
昔やったこと
• Amazon S3 + Apache Spark + Amazon EMR
• 自分と行動が似ている人のランキングを算出
• spark.ml(Machine Learningライブラリ)で類似度計算
Amazon EMR
cluster AmazonS3
user
AmazonS3
user

Spark+EMR たのしい!

Sparkでもっと
MLっぽいことしてみたい。
とりあえず趣味の幅で何かしよう!

Title Text
* http://scalatimes.com/d47496c4f6
MOOC: Massive Open Online Course=大規模公開オンライン講座
* https://www.coursera.org/learn/scala-spark-big-data

データサイエンスを手軽に始めるならRやPythonとよく言われますよね。
↓ でも扱うデータ量がTooLargeになると、メモリ不足で動かない..
という場合、それらの言語では作り直しが必要になるよ。
↓ データサイエンスでデータがTooLargeではないことなんて、なくない?
↓ Scala(というかFunctionalな言語)なら、簡単にスケールできるし、
Scalaアツイよね!
データサイエンス × Scala はじめに

Sparkは ”表現力豊か”,
”高性能”, ”データサイエンス向き機能充実” Scala × Sparkができる人は、 とても重宝されています!
…などと、導入に書いてました。

This course:
‣ This is a course about distributed data parallelism in Spark.
Not a machine learning or data science course!
‣ Extending familiar functional abstractions like functional lists over
large clusters.
‣ Context: analyzing large data sets.
だけど

This course:
‣ This is a course about distributed data parallelism in Spark.
Not a machine learning or data science course!
‣ Extending familiar functional abstractions like functional lists over
large clusters.
‣ Context: analyzing large data sets.
だけど…
マシンラーニングやデータサイエンスのコースちゃうで。

ちゃうんかい・・
(SparkのRDDやDataFrameの話はあります。)

BigDL: Apache Spark用の分散型DeepLearningライブラリ
Python Supportもある
https://github.com/intel-analytics/BigDL
intel 謹製
でも・・こんなのみつけた。。

Rich deep learning support. Modeled after Torch BigDL provides comprehensive support for deep learning, including numeric computing (via Tensor and high-level neural networks; in addition, you can load pretrained Caffe* or Torch models into the Spark framework, and then use the BigDL library to run inference applications on their data.
Efficient scale out. BigDL can efficiently scale out to perform data analytics at “big data scale” by using Spark as well as efficient implementations of synchronous stochastic gradient descent (SGD) and all-reduce communications in Spark.
Extremely high performance. To achieve high performance, BigDL uses Intel® Math Kernel Library (Intel® MKL) and multithreaded programming in each Spark task. Consequently, it is orders of magnitude faster than out-of-the-box open source Caffe, Torch, or TensorFlow on a single-node Intel® Xeon® processor (i.e., comparable with mainstream graphics processing units).
BigDLとは
https://software.intel.com/en-us/articles/bigdl-distributed-deep-learning-on-apache-spark

Rich deep learning support. Modeled after Torch BigDL provides comprehensive support for deep learning, including numeric computing (via Tensor and high-level neural networks; in addition, you can load pretrained Caffe* or Torch models into the Spark framework, and then use the BigDL library to run inference applications on their data.
Efficient scale out. BigDL can efficiently scale out to perform data analytics at “big data scale” by using Spark as well as efficient implementations of synchronous stochastic gradient descent (SGD) and all-reduce communications in Spark.
Extremely high performance. To achieve high performance, BigDL uses Intel® Math Kernel Library (Intel® MKL) and multithreaded programming in each Spark task. Consequently, it is orders of magnitude faster than out-of-the-box open source Caffe, Torch, or TensorFlow on a single-node Intel® Xeon® processor (i.e., comparable with mainstream graphics processing units).
BigDLとは
https://software.intel.com/en-us/articles/bigdl-distributed-deep-learning-on-apache-spark
Spark上で動かせるDeepLaearningライブラリ
Intel CPUを駆使することで高速に処理可能!
* v0.2.0になってドキュメントがかなり充実しました!

おもろそうやん

BigDLのサンプルを 手元で動かすために 必要だったことのまとめ
本日の発表内容

まずはカンタンにDeepLearning について
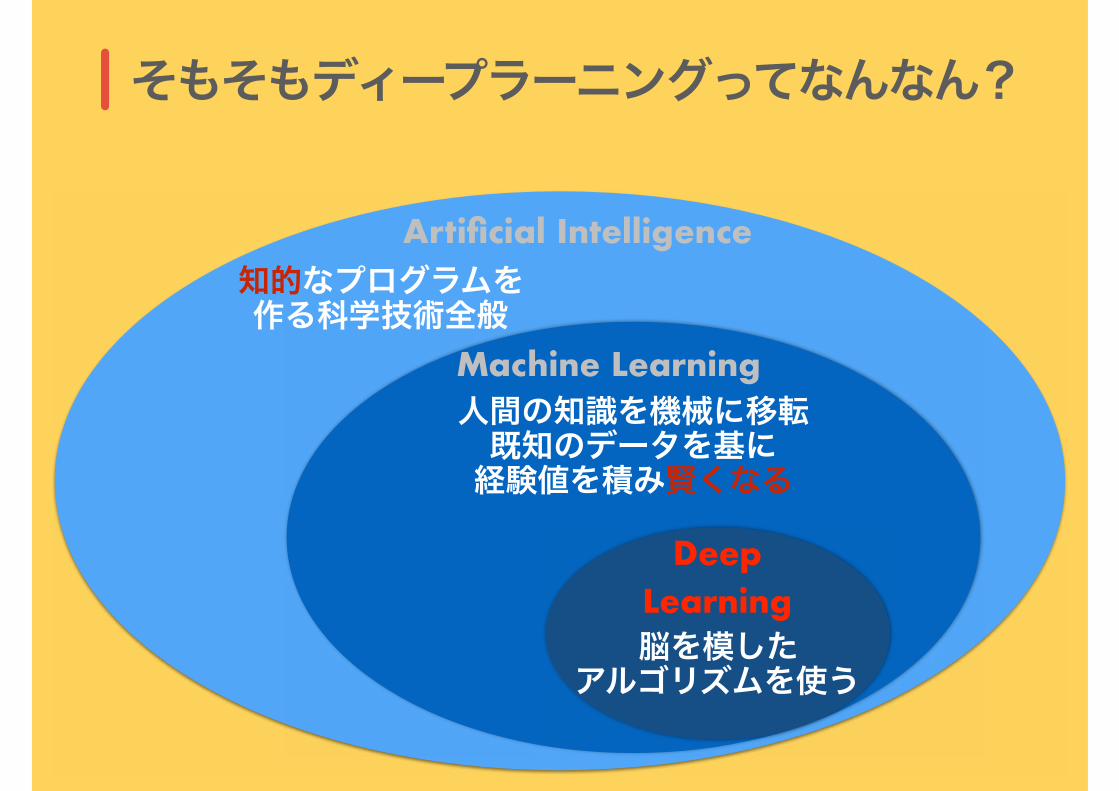
そもそもディープラーニングってなんなん?
Artificial Intelligence
Machine Learning
Deep Learning
知的なプログラムを 作る科学技術全般
脳を模した アルゴリズムを使う
人間の知識を機械に移転 既知のデータを基に 経験値を積み賢くなる
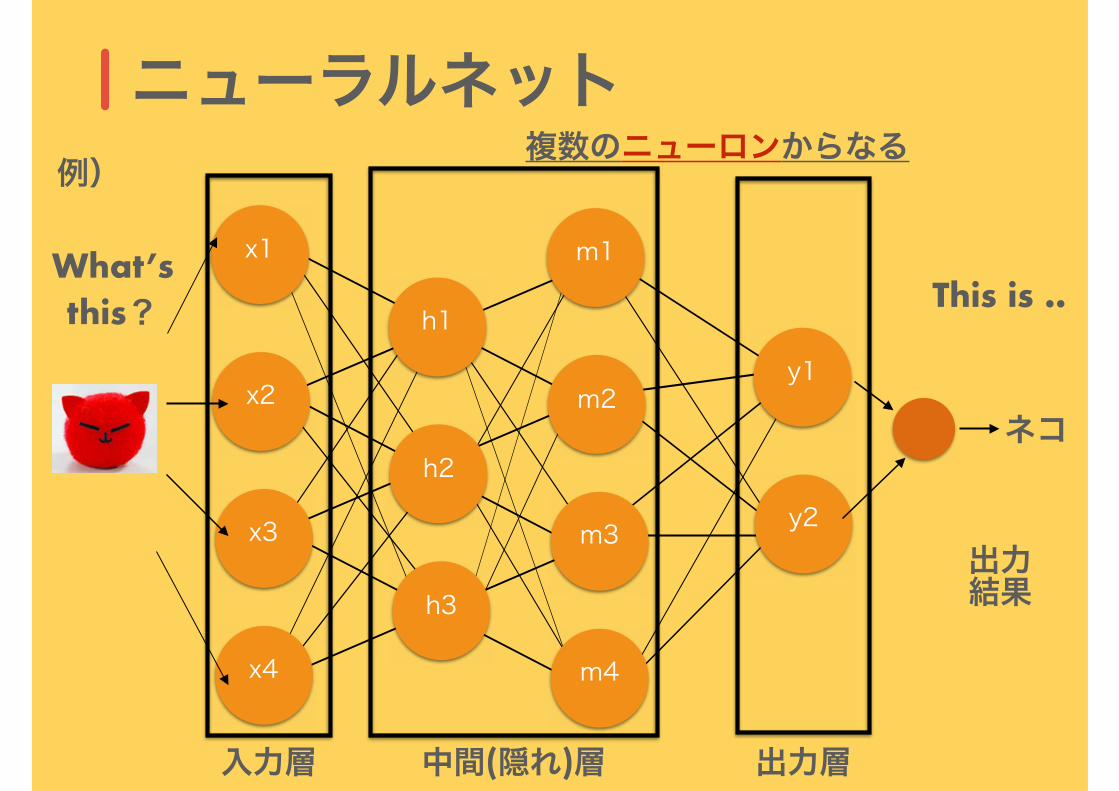
ニューラルネット
x1
x4
x2
x3
h1
h2
h3
y1
y2
m1
m4
m2
m3
入力層 中間(隠れ)層 出力層
複数のニューロンからなる例)
ネコ
出力結果
What’s this? This is ..
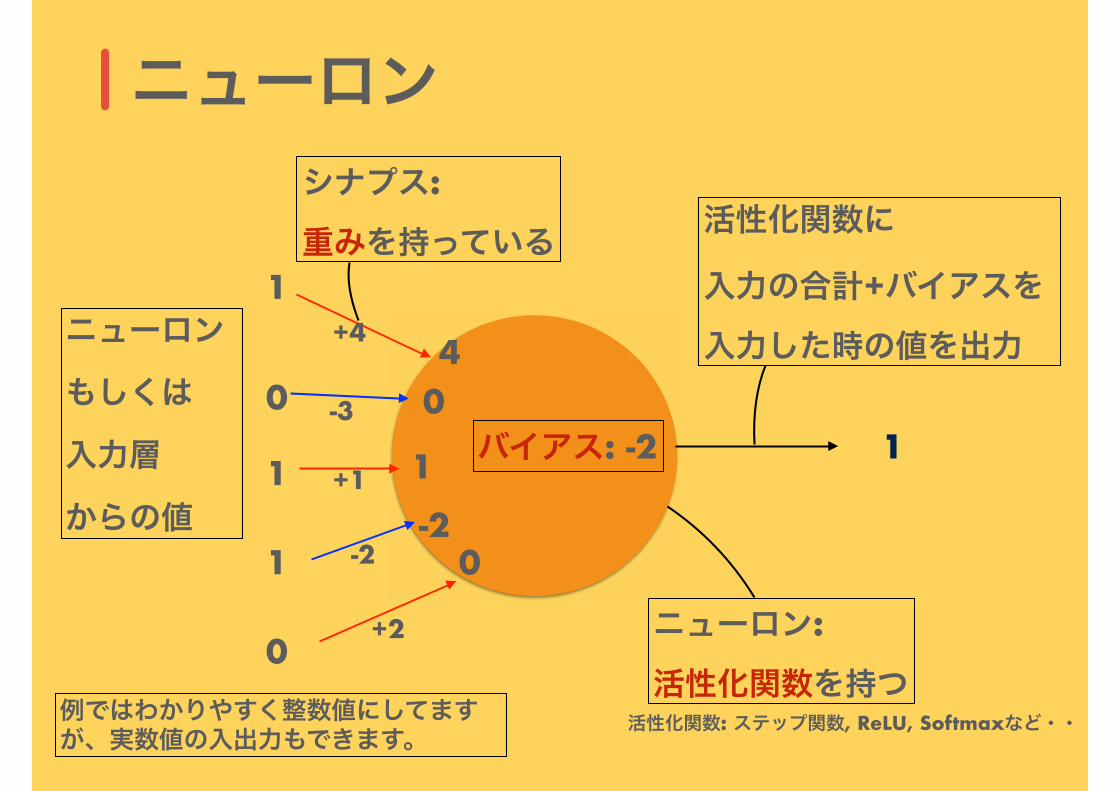
ニューロン
1
シナプス:
重みを持っている
10
1
1
0
ニューロン
もしくは
入力層
からの値
40
1
-20
ニューロン:
活性化関数を持つ
バイアス: -2
+4
+1
+2
-3
-2
活性化関数に
入力の合計+バイアスを
入力した時の値を出力
活性化関数: ステップ関数, ReLU, Softmaxなど・・例ではわかりやすく整数値にしてますが、実数値の入出力もできます。

学習 = パラメータの最適化
1) ラベル付けした大量のデータを準備
2) ニューラルネットに放り込む
3) 入力と結果の誤差が少なくなるように、パラメータ(重み, バイアス)の調整
* BackPropagation : 出力結果を見て、前の層に向かって順次調整する。
* Loss Function : 出力結果と正解のズレを数値化して、パラメータ修正の指標にする。
* Gradient Descent : パラメータ修正によって正解のズレの値がどれだけ変化するかを見ながら、最適な調整をしていく。
4) 2, 3を繰り返して誤差を少なくしていく

ほかにもいろいろとありますが、割愛。というか勉強中です:)

BigDLとは

BigDL
https://github.com/intel-analytics/BigDL
Sparkのディストリビューション
図: https://software.intel.com/en-us/articles/bigdl-distributed-deep-learning-on-apache-spark

ここが良さそうBigDL
intelCPUで高速に動作!
とかいうけど・・🤔🤔 がっつり使ってみないとわからん。。
正直、ScalaでMLしたいだけであれば、老舗のdeeplearning4jの方が良さそう..ドキュメントもサンプルも実装例もいっぱいあるし・・
比較的新参+pythonの実装やサンプルの方が先行しているよう(に見える)なので、Scalaでの実装やドキュメントの方面からコントリビュートできるかも!(私見)

BigDLの始め方
0.1.0までは、GettingStartedやドキュメント類が貧弱でした(設定がよくわからん + サンプル通りに実行してもうまくいかない・・)が、
0.2.0になって、進化してました!以下をよむべし。
https://bigdl-project.github.io/master/

入門

Sparkも BigDLも
わかりやすくなった ドキュメントを見ながら うまく導入できた!
という前提でいきます。

学習用データセットいくつか
• MNIST 0-9の手書き数字
• CIFAR-10 • 10カテゴリの画像データ
• COCO (Common Objects in Context) • 1枚の写真の中に複数の物体が写っている
https://www.cs.toronto.edu/~kriz/cifar.html
http://cocodataset.org/

bigDLのMNIST example
https://github.com/intel-analytics/BigDL/tree/master/spark/dl/src/main/scala/com/intel/analytics/bigdl/example/lenetLocal
* ローカル動作用のサンプルコード
* Lenet-5という5層構造の畳み込みニューラルネットワークが用いられている
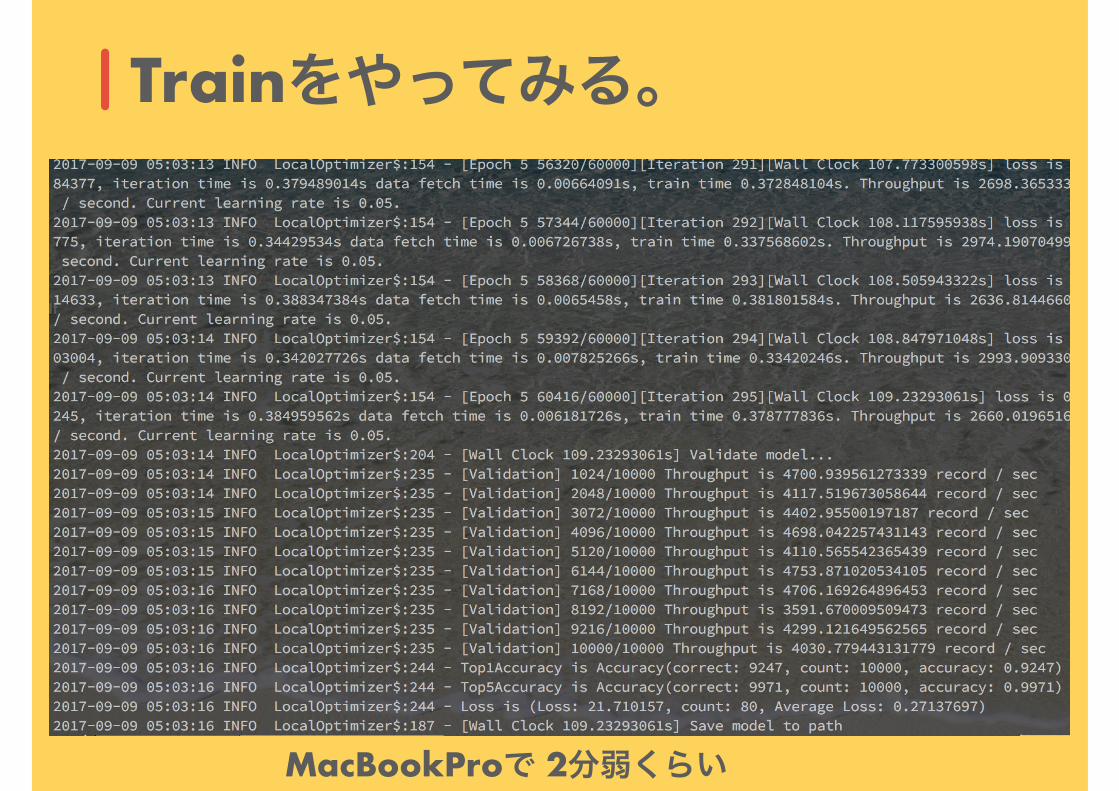
Trainをやってみる。
MacBookProで 2分弱くらい
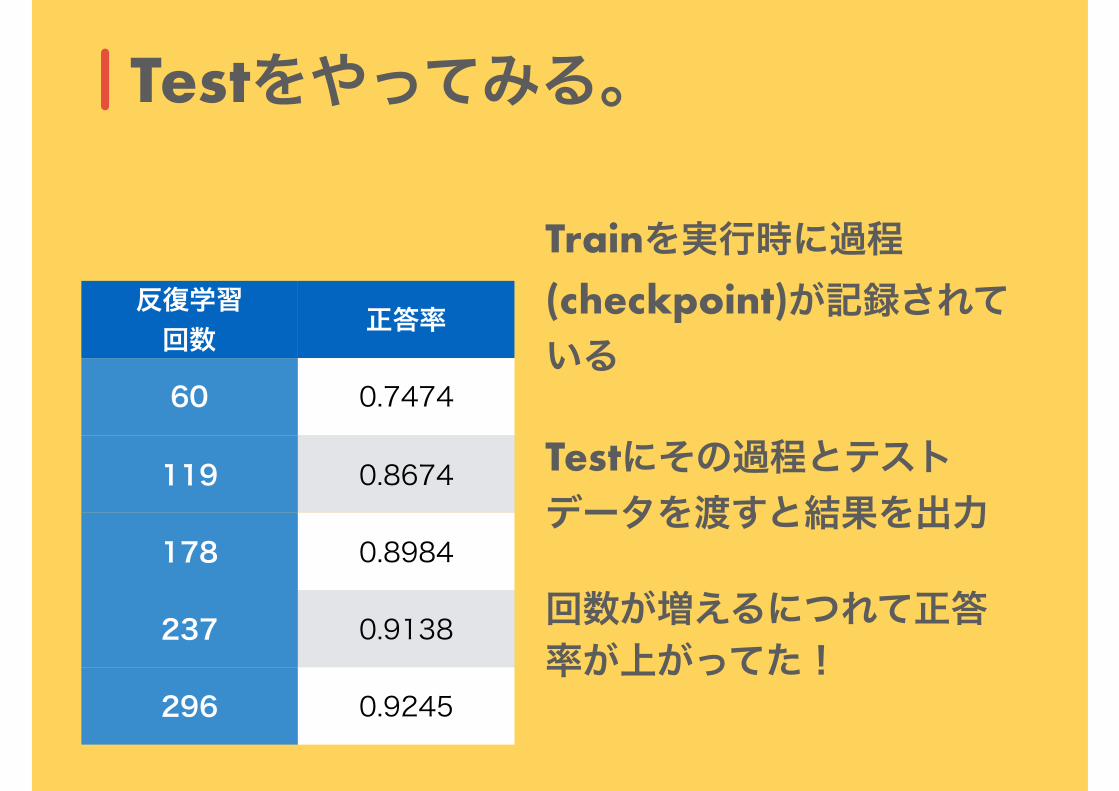
Testをやってみる。
Trainを実行時に過程(checkpoint)が記録されている
Testにその過程とテストデータを渡すと結果を出力
回数が増えるにつれて正答率が上がってた!
反復学習 回数 正答率
60 0.7474
119 0.8674
178 0.8984
237 0.9138
296 0.9245

Predictをやってみる。
Trainを実行時に過程(checkpoint)が記録されている
Predicateにその過程とテストデータを渡すと予想結果を出力してくれる。
* 元画像と予測結果の比較を載せれると良かったのですが・・
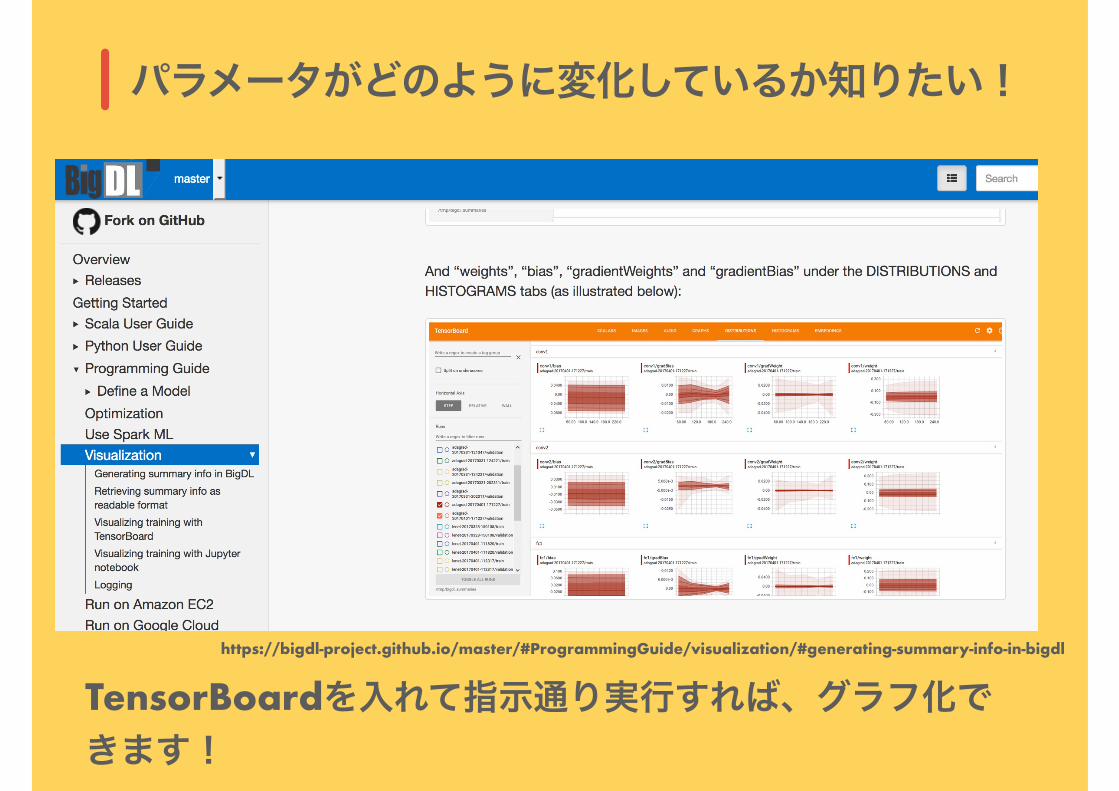
パラメータがどのように変化しているか知りたい!
TensorBoardを入れて指示通り実行すれば、グラフ化できます!
https://bigdl-project.github.io/master/#ProgrammingGuide/visualization/#generating-summary-info-in-bigdl

とりあえず サンプル動かせたぞー!

さいご ハマったりしたこと

spark-submit \--master local[physcial_core_number] \--class com.intel.analytics.bigdl.example.MLPipeline.DLClassifierLeNet \./dist/lib/bigdl-0.1.0-SNAPSHOT-jar-with-dependencies.jar \-f path_to_mnist_folder \-b batch_size
↑こんな感じで実行例書いていることが多いですが、自分の環境(zsh)では、spark-submit \--master “local[physcial_core_number]” \--class com.intel.analytics.bigdl.example.MLPipeline.DLClassifierLeNet \./dist/lib/bigdl-0.1.0-SNAPSHOT-jar-with-dependencies.jar \-f path_to_mnist_folder \-b batch_size
spark-submit での実行時

$ pip install tensorboard==1.0.0a6::Uninstalling numpy-1.8.0rc1:Exception::などと言われ、numpyのアンインストールを試みると、pip uninstall numpy::Exception::OSError: [Errno 1] Operation not permitted::などと言われてしまい、インストールできてない。
!MacOS Xデフォルトのpythonでは、入れられないとかどうとか・・
TensorBoard インストール時

開発したコードのテストを行うには、sbt-assemblyでjarに固めてからspark-submitで実行する方法が早かったです。
sbtでなんとしてもspark呼びたいんだ!という場合には、sbt-spark-submitなどが使えるかもしれません。。
ただ、BigDLも動かせるようにするには、一手間いるかもしれません。
もしかして、g8テンプレートとか作れたら、需要あるのでは・・・?
sbt test / sbt run ! ..あれ?
MacBookProで動かしたが、3日かかっても計算が終わらなかった…orz
CIFAR-10のサンプルコード

これ、AI使ったらおもろそう・・というものがなかなか思い浮かばない…orz
身の回りにくすぶっている良い課題が見つからない

おわり







