
Biostatistiques et statistiques appliquéesaux sciences expérimentales
Introduction aux statistiques Bayésiennes
Jérémie Mattout
Cogmaster A4 2006-2007

• Introduction
• Rappels sur la théorie des probabilités
• Principes de l’inférence Bayésienne
• Application en Neuroimagerie
• Conclusion
Programme de la séance

INTRODUCTION

Introduction
Statistiques: domaine cousin mais distinct des Mathématiques
Statistiques appliquées
Statistiques théoriques/mathématiques Statistiques descriptivesprésentation, description et résumé des données
Statistiques inférentiellesModélisation et prise en compte du caractère aléatoire et de l’incertitudePour le test d’hypothèse et/ou l’inférence de variables cachées ou inconnues

Introduction
Statistiques: ont connu leur véritable essor au XXème siècle
DéfinitionsA la fois le domaine scientifique et les données collectées
EtymologieMot d’abord allemand, issu du latin moderneet de l’italien (‘relatif à l’Etat’)
Domaines d’applicationDémographie, Santé, Economie, Psychologie,Education, Finances …
S’appuient sur une théorie plus ancienne, celle des probabilités…

Introduction
Probabilité: notion apparue fin XVIème , début XVIIème
Notion bien comprise universellement, pourtant pas d’interprétation unique
A. de Moivre (1667-1754)
B. Pascal (1623-1662)
P. de Fermat (1601-1665)
J. Bernouilli (1654-1705)
C. Huygens (1629-1695)
P-S. Laplace (1749-1827)
A-M. Legendre (1752-1833)AC-F. Gauss (1777-1855)
Interprétation fréquentiste
Interprétation bayésienne

RAPPELS SURLA THEORIE DES PROBILITES

Rappels sur la théorie des probabilités
Qu’est-ce qu’une probabilité ?
Définition classique (Laplace)Si une expérience aléatoire peut résulter en N événements équiprobables et mutuellement exclusifs.Si un nombre Nt de ces événements est de type t, alors la probabilité d’un résultat de type t est:
N
Nt
tP =)(
Définition fréquentisteLa probabilité d’un événement est sa fréquence relative d’occurrence, après avoir répété l’expérience un grandnombre de fois (idéalement un nombre infini de fois).Si Nt est le nombre d’occurrence d’événements de type t parmi N essais:
N
N
N
ttP
!"= lim)(
- Uniquement pour un nombre fini de résultats possibles- Uniquement pour des événements équiprobables
- Approche objective- Il est généralement impossible de répéter unemême expérience un très grand nombre de fois

Qu’est-ce qu’une probabilité ?
Définition bayésienneMesure du degré de croyance ou de l’incertitude qu’un individu assigne à un événement ou une situation
- S’applique à tout type d’événements ou phénomènes- Approche subjective- Nécessite de définir un a priori qui pourra varier selon lesindividus- Peut bien entendu prendre en compte un avis objectif
T. Bayes (1702-1761)
e.g.1: les cotes sont fixées en fonction des paris (subjectifs)
e.g.4: quelle est la probabilité qu’ils diront la vérité ?
e.g.2: quelle est la probabilité d’une chute ?
e.g.3: probabilité d’être contrôlé au prochain coin de rue ?
Rappels sur la théorie des probabilités

Controverse dans la définition/l’interprétation d’une probabilité - Résumé
Approche fréquentiste
- Probabilité = limite de la fréquence relative del’événement, pour un grand nombre d’essais
- N’est défini que dans le cadre d’expériencesaléatoires bien définies
- Recherche de l’objectivité
Approche bayésienne
- Probabilité = degré de croyance, mesure del’incertitude
- S’applique à tout type d’événements ou desituations
- Approche subjective
Statistiques inférentielles classiques Statistiques inférentielles bayésiennes
P-S. Laplace (1749-1827)
R.A. Fisher (1880-1962)
E.S. Pearson (1895-1980)
J. Neyman (1894-1981)
T. Bayes (1702-1761)
H. Jeffreys (1891-1889)
Rappels sur la théorie des probabilités

Approche Mathématique…:Probabilité = vraisemblance qu’une ‘chose’ soit, ait été, existe ou advienne
Indépendamment des débats parfois philosophiques concernant l’interprétation d’uneprobabilité, la théorie mathématique des probabilités s’est construite sur un certain nombred’axiomes concernant les phénomènes aléatoires.
Chances Théorie moderne des probabilités
A.N. Kolmogorov (1903-1987)
Rappels sur la théorie des probabilités

Théorie unifiée des probabilités:
Cas discret Cas continu
Espace des résultats { },...,21xx=! R=!
Propriétés
[ ]1,0)( !xf !"#x
!"#
=x
xf 1)(
)()( xXpxF !=
0)(lim =!"#
xFx
1)(lim =!"
xFx
F: fonction monotone, continue, non décroissante
Pile ou Face ? Température ici, à midi, le 15 Août 2007 ?
Exemple
f : fonction de massedx
dFf = : fonction de densité
Rappels sur la théorie des probabilités

Théorie unifiée des probabilités:
Cas discret Cas continu
10 tirages à Pile ou Face ? Température ici, à midi, le 15 Août 2007 ?Exemple
Loi Binomiale: xxn
x ppCxfxXp !!===
1)1()()( Loi Normale:
!="x
xfxXp0
)()(
!=
=""20
10
)()2010(x
dxxfXp
),(~)( !µNXp ex
xf 2
2
2
)(
2
1)( !
µ
"!
##
=
Rappels sur la théorie des probabilités

La Loi des grands nombres:
Si un événement de probabilité p est observé de façon répétée, lors d’expériences identiques maisindépendantes, la fréquence d’occurrence de cet événement par rapport au nombre d’expériences,converge en probabilité vers p.
iX est une réalisation indépendante d’une variable aléatoire pouvant être égale à 1 avec une probabilité p
et à 0 avec une probabilité 1-p
Alors, n indiquant le nombre d’essais 1lim
1 =
!!!!
"
#
$$$$
%
&
='(
)= pn
X
nP
n
i
i
Pile (0) ou Face (1) ?
# essais
Fréquencerelative
Rappels sur la théorie des probabilités

Le théorème central limite:
Soit une suite de variables aléatoires indépendantes, de même loi, d’espérance et de variancefinies. Alors leur moyenne centrée, réduite, suit une loi normale de moyenne 0 et de variance 1.
( )nXSuite d’espérance et de variance , alors suit une loi normaleµ 2!
n
n
n
XZ
2!
µ"= ( )1,0N
n
X
X
n
i
i
n
!== 1avec
Rappels sur la théorie des probabilités

L’espérance mathématique:
Valeur attendue, somme des gains (et pertes) pondérés par leur probabilité.
Cas discret Cas continu
Formule
Exemple
( ) ( )!=i
ii XpXXE ( ) !+"
"#
= dxxxfXE )(
2 tirages à Pile (1) ou Face (0) ? Température ici, à midi, le 15 Août 2007 ?
( ) 1.0.2.14
1
4
1
2
1 =++=XE ( ) µ!"
"
µ
==#
#+$
$#
% e
xxXE
2
2
2
)(
2
Rappels sur la théorie des probabilités

L’entropie de Shannon:
Mesure de l’incertitude liée à une variable aléatoire, ou encore la quantité moyenne d’informationManquante lorsqu’on ne connaît pas la valeur de cette variable.
Formule
Analogie en physique
( ) ( )( ) ( ) ( )( )!"==i
ii XpXpXIEXH ln
Manque d’information/entropie/incertitude
ordre/structure
Rappels sur la théorie des probabilités

L’entropie de Shannon: Exemple
Pile ou Face
( )XH
( )''FaceXP =
Rappels sur la théorie des probabilités

Axiomes des probabilités (de Kolmogorov):
(1)
(2)
(3)
( ) 10 !! AP
( ) 1=!P
! : ensemble/univers des résultats possibles A : événement quelconque lié a la même expérience aléatoire
( ) ( )!=
=""k
i
ikAPAAAP
1
21L pour des événements deux a deux incompatibles
( )BAP ! : probabilité jointeou ( )BAP ,
Rappels sur la théorie des probabilités

Propriétés essentielles, découlant des axiomes de Kolmogorov:
-
-
-
( ) 0'' =rienP
( ) ( )APAP !=1 !
( ) ( ) ( ) ( )BAPBPAPBAP !"+=# quels que soient les événements et
A A: complémentaire de dans
A B
- Si alorsBA! ( ) ( )BPAP !
- si et sont indépendants( ) ( ) ( )BPAPBAP .=! A B
- ( ) 0=! BAP si et sont mutuellement exclusifsA B
Rappels sur la théorie des probabilités

REGLE DE BAYES

Règle de Bayes
Probabilités conditionnelles:
( )BAP : Probabilité de sachant / connaissant / étant donnéA B
( ) ( )( )BPBAP
BAP!
=
Si et sont indépendants, alorsA B ( ) ( )APBAP =

Règle de Bayes
Probabilités conditionnelles: Exemple
Considérons le test de dépistage d’une grave maladie. Plus tôt la maladie est détectée,meilleur est le pronostic de survie.
Nous savons que dans la population ( ) 01.0=maladeP
etNous savons également que ( ) 01.0=sainpositifP ( ) 01.0=maladenégatifP
( )?positifmaladeP

Règle de Bayes
Probabilités conditionnelles: Exemple
Nous savons que dans la population ( ) 01.0=maladeP
etNous savons également que ( ) 01.0=sainpositifP ( ) 01.0=maladenégatifP
On en déduit que ( ) ( ) 99.01 =!= maladenégatifPmaladepositifP
et
!
P positif( ) = P positif ,sain( ) + P positif ,malade( ) = 0.0198
( ) ( )( )
50.0,
==positifP
positifmaladePpositifmaladeP
( ) ( ) ( ) 0099.0, == maladePmaladepositifPmaladepositifP
Considérons le test de dépistage d’une grave maladie. Plus tôt la maladie est détectée,meilleur est le pronostic de survie.

Règle de Bayes
Probabilités totales ou marginales:
Cas discret
Cas continu
( ) ( ) ( ) ( )k
k
k
k
kBPBAPBAPAP !! == ,
( ) ( ) ( ) ( )!! == dYYPYXPdYYXPXP ,

Règle de Bayes
Probabilités totales ou marginales:
Cas discret
Exemple
Pile ou Face (résultats équiprobables)
Sur deux essais indépendants, quelle est la probabilitéd’obtenir ‘Face’ au deuxième essai ?
!
P T2
= Face( ) = P T2
= FaceT1
= Face( )P T1
= Face( )
+P T2
= FaceT1
= Pile( )P T1
= Pile( )
= 0.5*0.5 + 0.5*0.5 = 0.5

Règle de Bayes
Théorème/Règle de Bayes
( )( ) ( )( )YP
XPXYPYXP =
Cas discret Cas continu
( )( ) ( )( ) ( )!
=
k
kk
kk
k
BPBAP
BPBAPABP ( )
( ) ( )
( ) ( )!=
dXXPXYP
XPXYPYXP
( )( ) ( )
( )APBPBAP
ABPkk
k=

PRINCIPES DEL’INFERENCE BAYESIENNE

Principes de l’inférence Bayésienne
Notion de modélisation:
- Formalisation mathématique d’un processus ou système réel/physique(repose sur un ensemble d’hypothèses et d’approximations)
Importance de la modélisation:
- Permet de simuler des données
- Permet l’estimation de paramètres non observés
- Permet de prédire de futures observations
- Permet de tester des hypothèses
entrée observations
modèle

Principes de l’inférence Bayésienne
Analyse/inférence Bayésienne:
- Appliquer un modèle probabiliste des observations comme des quantités à estimer
- Les quantités à estimer sont non observées
- Une caractéristique essentielle de l’inférence Bayésienne réside dans l’utilisationexplicite de distributions de probabilités pour quantifier l’incertitude de l’inférence
Paramètresdu modèles
Futuresobservations
prédictionap
prenti
ssag
e
ourec
onna
issan
ce

Principes de l’inférence Bayésienne
Notations:
Y : observations
: paramètres du modèle
: données manquantes ou encore non observées
!
Y~

Principes de l’inférence Bayésienne
Trois étapes de l’inférence Bayésienne:
(1) Définition du modèle probabiliste complet, pour l’ensemble des quantitésobservables et non observables: spécification de la probabilité jointe
(2) Calculer et interpréter les distributions de probabilités a posteriori(conditionnellement aux observations) des quantités non observées d’intérêt
(3) Evaluer la qualité des interprétations et du modèle, ainsi que la sensibilité desrésultats aux hypothèses du modèle
( )!,YP

Principes de l’inférence Bayésienne
Modèle général:
Apprentissage/Reconnaissance
Probabilité jointe
Distribution a posteriori
S’écrit parfois car ne dépend pas de
( ) ( ) ( )!!! PYPYP =,
( )( ) ( )( )YPPYP
YP!!
! =
dist. a priori
vraisemblance des données
loi marginale ou évidence
( ) ( ) ( )!!! PYPYP " ( )YP !

Principes de l’inférence Bayésienne
Modèle général:
Prédiction
Distribution prédictive a priori
Distribution prédictive a posteriori
Mise à jour de l’a priori dans le cadre d’une analyse séquentielle: à l’arrivée de nouvellesdonnées, la distribution a posteriori devient la nouvelle distribution a priori
( )YP
( ) ( ) ( ) !!! dYPYPYYP "=~~

MISE EN PRATIQUE

Mise en pratique
Exercice n°1: exemple de démarche Bayésienne
Exercice n°2: exemple de modèle Bayésien
Exercice n°3: illustration des limites de l’approche classique

DISTRIBUTIONS A PRIORI

Distributions a priori
Un aspect central et critique de l’approche Bayésienne est laformulation d’une distribution de probabilité a priori sur lesquantités non observées que l’on souhaite estimer.
Différentes stratégies possibles:
- A priori informatif permettant de guider au mieux l’estimation
- A priori non informatif afin de ne pas biaiser l’estimation et de ‘laissers’exprimer’ les données
- Un compromis entre les deux…

Distributions a priori
Construction d’un a priori
- Approche ‘pragmatique’: considérer les différentes valeurs possibles de θ etleur assigner une probabilité telle que leur somme sera égale à 1.
ATTENTION: le support de la distribution a posteriori sera un sous-espace de celui de l’a priori.Autrement dit, l’estimée a posteriori ne pourra pas prendre de valeurs non prévues par l’a priori.
- Approche paramétrique: on attribue une distribution de forme connue à notrea priori sur θ. Alors l’a priori se résume à un petit nombre de paramètres (e.g.moyenne et variance) et le support n’est plus fini.
ATTENTION: pas toujours applicable. Certaines distributions peuvent avoir des propriétés trèssimilaires mais conduire à des estimations a posteriori très différentes. Que choisir ?

Distributions a priori
A priori conjugué
- Etant donnée une loi de vraisemblance, un a priori conjugué est un a prioridont la distribution est telle que la distribution a posteriori appartiendra à lamême famille de loi.
- Approche très utile et très employée, notamment dans le cadre d’unapprentissage séquentiel.
Exemples
Cas discret Cas continuVraisemblance A priori conjugué Vraisemblance A priori conjugué
Binomiale Beta
Multinomiale Dirichlet
Poisson Gamma
Exponentielle
Normal
Gamma
Gamma
Normal
Gamma

Distributions a priori
A priori non-informatif
Se dit d’une distribution qui ne favorise aucune valeur de θ par rapport aux autres.Ainsi toute l’information nécessaire à l’estimation est fournie par les données. Onse rapproche alors de l’inférence classique, s’appuyant uniquement sur le termede vraisemblance (approche objective).
Cas discret Cas continu
( ) nPi
/1=!{ }n!! ,,
1K="
( ) ( )abP != /1"[ ]ba,=!‘’propre’’
( ) cP /1=![ ]+!!"=# ,‘’impropre’’
L’a priori non-informatif est parfois aussi appelé a priori de référence (voir plusloin, évaluation de modèle)
ATTENTION: un a priori informatif est parfois nécessaire, lorsque les données ne suffisent paspour estimer les paramètres du modèles (cf. exemple en Neuroimagerie)

EXEMPLES D’INFERENCE BAYESIENNE

Exemples d’inférences Bayésienne
- Ayant défini un a priori, le théorème de Bayes nous permet de combiner cetteinformation avec des observations afin de calculer la distribution a posteriori desparamètres ou prédictions.
- L’inférence Bayésienne permet d’obtenir une information complète sur les quantités àestimer: leur entière distribution de probabilité.
- Toutefois, il nous faudra le plus souvent résumer/interpréter cette information,notamment pour permettre un choix ou une réponse quantitative. Typiquement et demanière analogue à l’approche classique: une estimation ponctuelle, d’un intervalle oule test d’une hypothèse.

Exemples d’inférences Bayésienne
Estimation ponctuelle θ
« Comment résumer le résultat par une valeur statistique a posteriori ? »
moyenne - Estimateur ponctuel de variance a posteriori minimale - Sensible aux valeurs extrêmes- Peu représentatif si distribution multimodale
médiane - Insensible aux valeurs extrêmes- Identique à la moyenne si la distribution est symétrique- Sensible aux valeurs extrêmes- Peu représentatif si distribution multimodale
mode - Facile à calculer- Equivalent au maximum de vraisemblance lors de l’utilisationd’un a priori uniforme- Reflète seulement la valeur la plus probable- Aussi appelé Maximum A posteriori (MAP)
^

Exemples d’inférences Bayésienne
Estimation d’intervalle C
« Intervalle C de confiance Bayésien »
Définition fréquentiste
Définition Bayésienne
Si on recalculait C pour un grand nombre de jeux de données obtenus de manièreindépendante et selon le même protocole expérimental, (1-α).100% d’entre eux contiendraitla valeur de θ.
La probabilité que la valeur θ appartienne à l’intervalle C, étant donné les observations Y, estsupérieure ou égale à (1-α).
( ) ( )!="#C
dYPYCP $$%1

Exemples d’inférences Bayésienne
Test d’hypothèse
Définition fréquentiste Définition Bayésienne
- H0 versus H1
- p = Probabilité que la statistique de test T(Y) soitplus extrême (vers H1) que T(Y|θ,H0)
- Ne permet pas d’accepter H0
- La valeur p ne peut pas être interprétée comme undegré de significativité
- Autant d’hypothèses concurrentes que de modèlespossibles, notés M1, M2, …, Mk
- Pour chaque hypothèse, on peut calculer
( ) ( ) ( )!= """ dPMYPMYPii
,

EVALUATION DE MODELE

Evaluation de modéle
Sélection/comparaison de modèles
Bayes Factor (BF): comparaison de deux modèles/hypothèses M1 et M2
( ) ( )( ) ( )
( )( )
2
1
21
21
MYP
MYP
MPMP
YMPYMPBF ==
( ) ( )21
MPMP =Si les modèles sont a priori équiprobables
( )( )YMP
YMPBF
2
1=alors

Evaluation de modéle
Principe de parsimonie
y=f(x
)y
= f(
x)
x
évid
ence
du
mod
èle
p(Y|
M)
Espace des données
trop simple
trop complexe
‘juste bien’
Bayesian Information Criterion (BIC)
( )( )
( ) NnnMYP
MYPBIC log12
,sup
,suplog2
2
1 !!""#
$
%%&
'!=(
)
)
Akaike Information Criterion (AIC)
( )( )
( )122,sup
,suplog2
2
1nn
MYP
MYPAIC !!
""#
$
%%&
'!=(
)
)
n1: # paramètres du modèle M1n2: # paramètres du modèle M2N: taille de l’échantillon

Evaluation de modéle
Moyenne de modèles
Plutôt que d’estimer θ à partir d’une seule hypothèse, il se peut que plusieurs hypothèsesconduisent à différentes solution tout aussi plausibles. Alors il peut être intéressant demoyenner sur plusieurs modèles.
( ) ( ) ( )!=i
iiYMPYMPYP ,""

Evaluation de modéle
Modèles hiérarchiquesReprésentation sous la forme de graphe (Réseau Bayésien)

APPLICATION EN NEUROIMAGRIE
Application en neuroimagerie
His
togr
amm
ede
s do
nnée
s
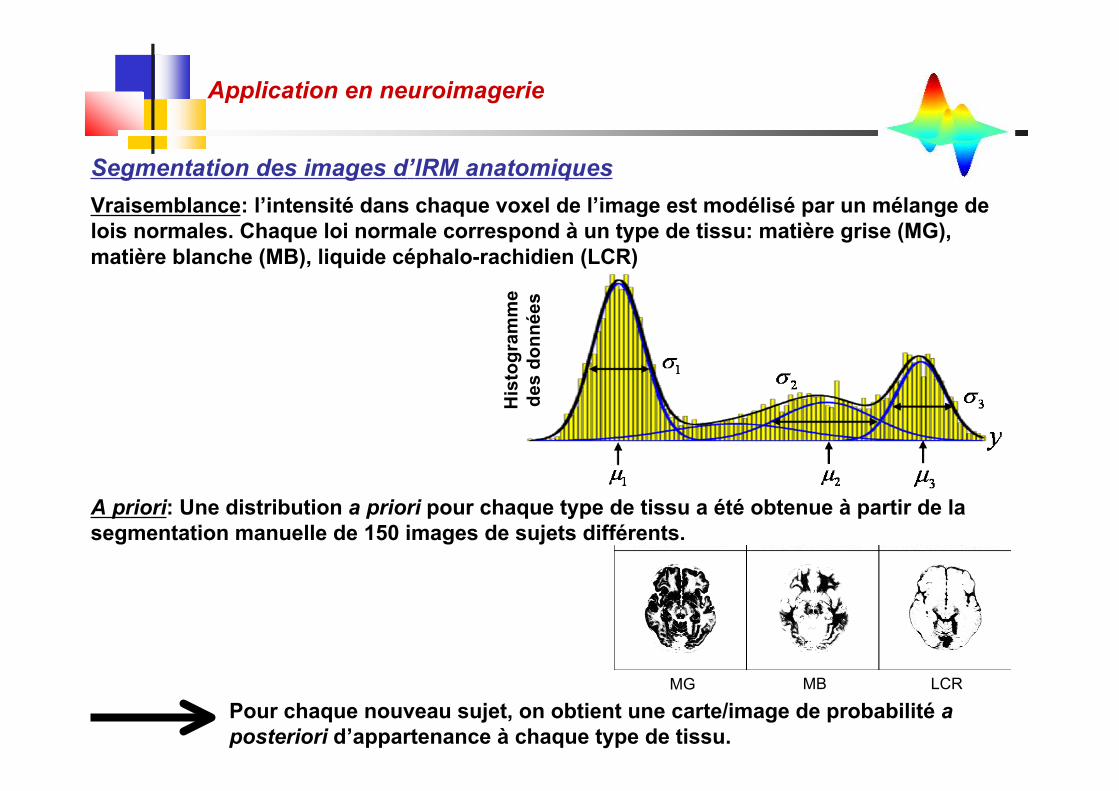
Vraisemblance: l’intensité dans chaque voxel de l’image est modélisé par un mélange delois normales. Chaque loi normale correspond à un type de tissu: matière grise (MG),matière blanche (MB), liquide céphalo-rachidien (LCR)
Segmentation des images d’IRM anatomiques
A priori: Une distribution a priori pour chaque type de tissu a été obtenue à partir de lasegmentation manuelle de 150 images de sujets différents.
MG MB LCR
Pour chaque nouveau sujet, on obtient une carte/image de probabilité aposteriori d’appartenance à chaque type de tissu.

CONCLUSION

Conclusion
Résumé:- décision en termes probabilistes- choix conditionnels (éventuellement par rapport à des covariables ou paramètresconnus x)
Inconvénients:- approche subjective- nécessité de définir une distribution a priori- calculs couteux en mémoire et en temps(approximations asymptotiques, méthodes d’échantillonnage, algorithme EM, approchesvariationelles)
Avantages:- peut poser toutes les questions- interprétations plus intuitives- permet d’accepter l’hypothèse nulle(freq: évaluation rétrospective de la procédure utilisée pour estimer θ, étant donnép(y|θ,H0))- permet l’application de modèles de plus en plus complexes

Conclusion
Références
Numéro spécial, modèles probabilistesen sciences cognitives (2006)







