Download - Clustering, k means algorithm

Clustering, K-Means Algorithm
박준영

Clustering
1. Clustering
2. K-Means Algorithm
3. Score & Evaluation

Clustering

Clustering

Clustering
Preprocess Training Score Evaluate
“클러스터링은주어진 데이터를 가장 잘 설명하는클러스터를 찾아내는 것이 목적 (Optimization)”

K-Means Algorithm
K - 평균 알고리즘
‘가장 가까운’ 내부 거리를 가지는 클러스터를 찾는다
클러스터 내부에 속한 데이터들의 거리를 비교

K-Means Algorithm
K - 평균 알고리즘
Output : K개의 클러스터
Input : K (클러스터 수), D (데이터 집합)
K-Means Algorithm
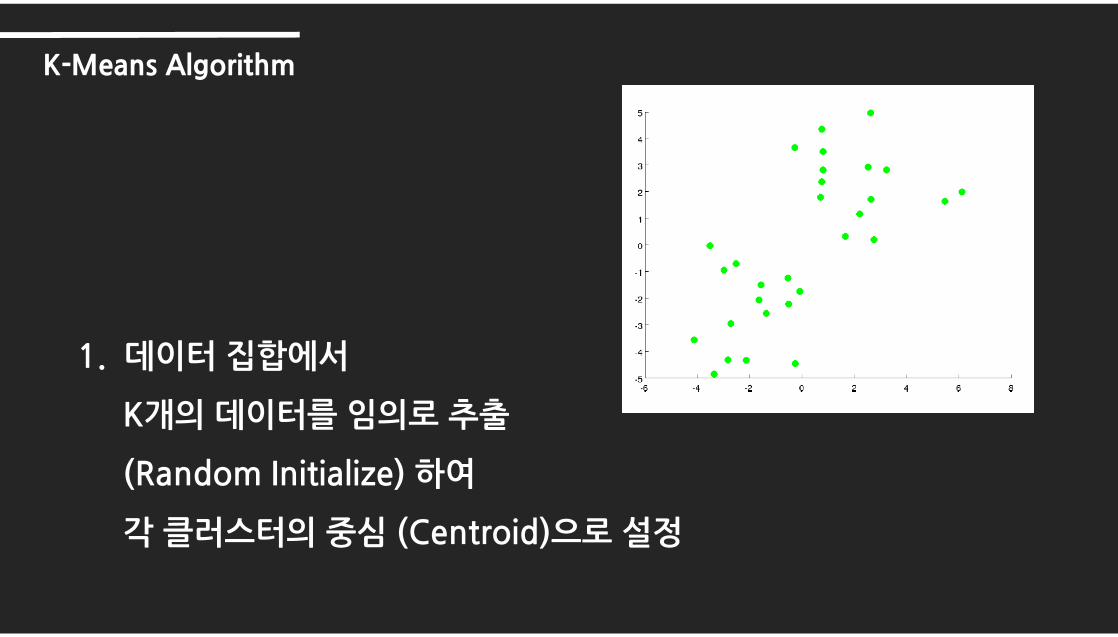
1. 데이터 집합에서
K개의 데이터를 임의로 추출
(Random Initialize) 하여
각 클러스터의 중심 (Centroid)으로 설정
K-Means Algorithm
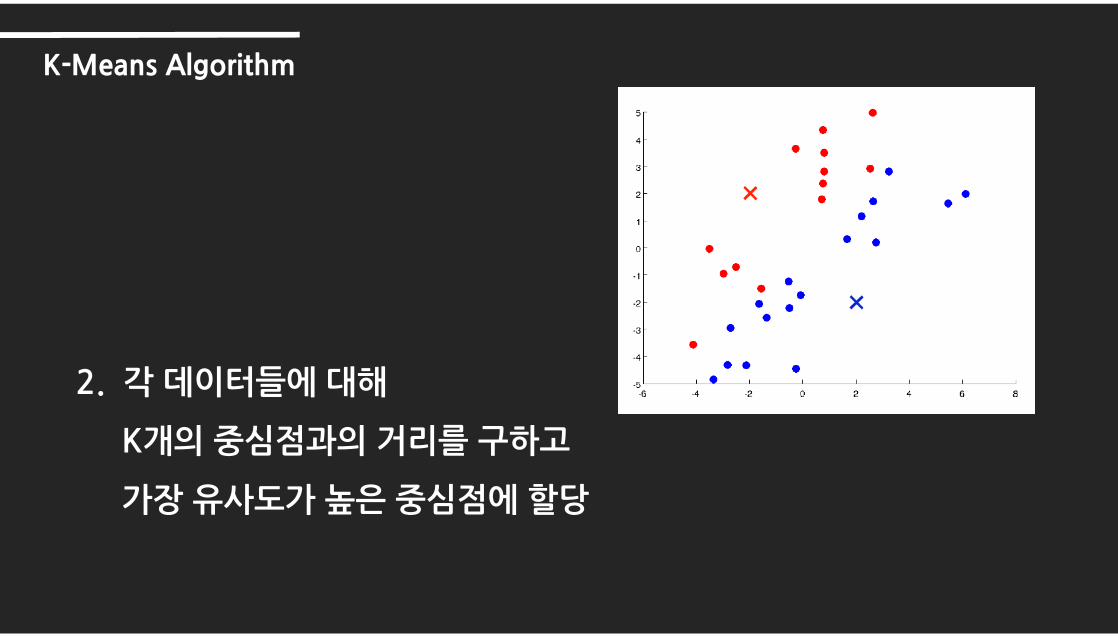
2. 각 데이터들에 대해
K개의 중심점과의 거리를 구하고
가장 유사도가 높은 중심점에 할당
K-Means Algorithm
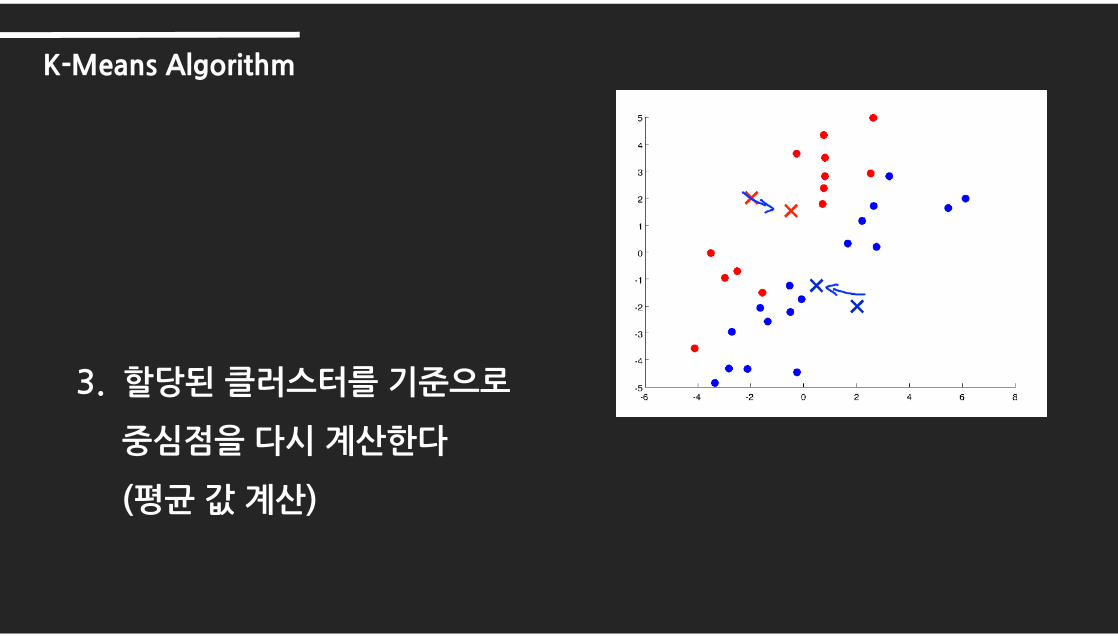
3. 할당된 클러스터를 기준으로
중심점을 다시 계산한다
(평균 값 계산)
K-Means Algorithm
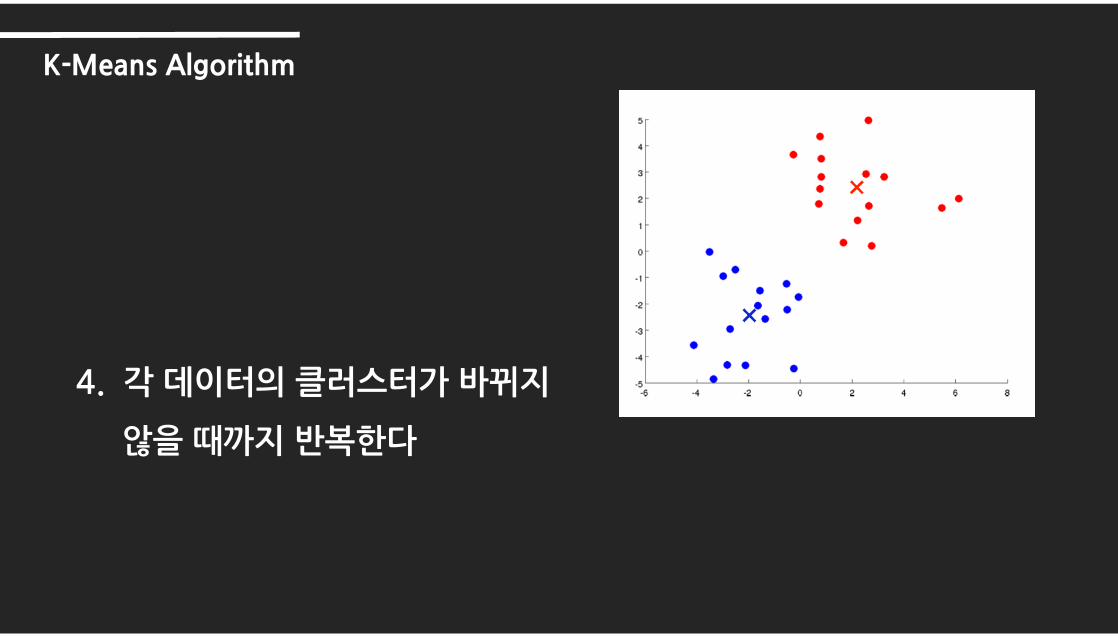
4. 각 데이터의 클러스터가 바뀌지
않을 때까지 반복한다

K-Means Algorithm
K - 평균 알고리즘 이슈
1. 거리 (유사도) 측정 방법?
2. 초기 클러스터의 중심점을 설정하는 방식? (K-Means의 약점)
3. K의 개수를 몇으로 설정해야 하는가?
4. 클러스터링이 얼마나 잘 되었는지 평가를 어떻게?
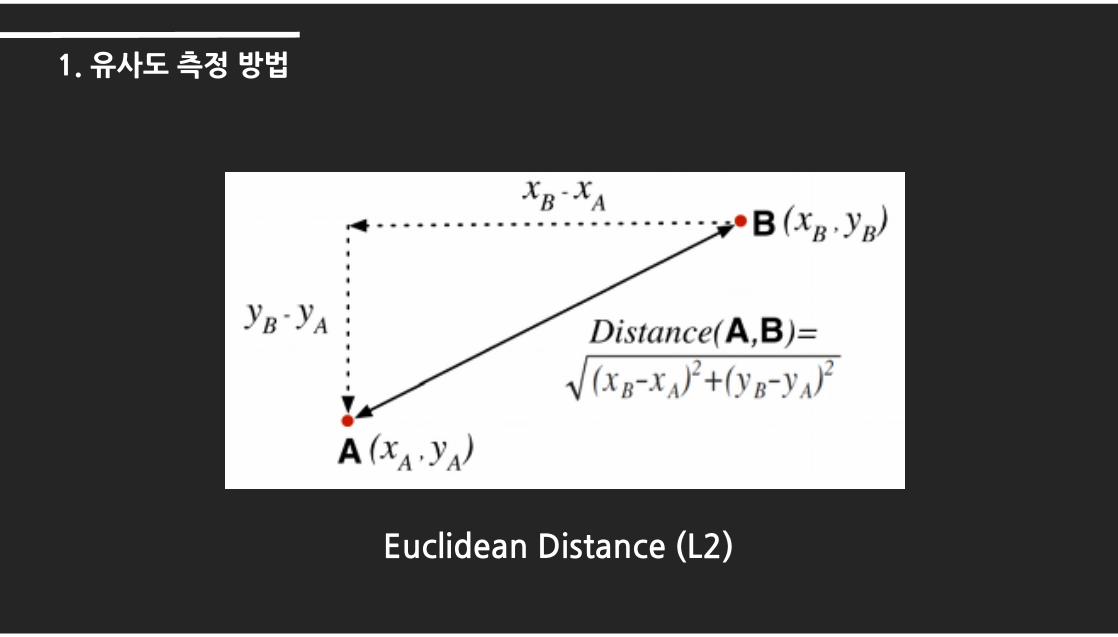
1. 유사도 측정방법
Euclidean Distance (L2)

Manhattan Distance (L1)
1. 유사도 측정방법
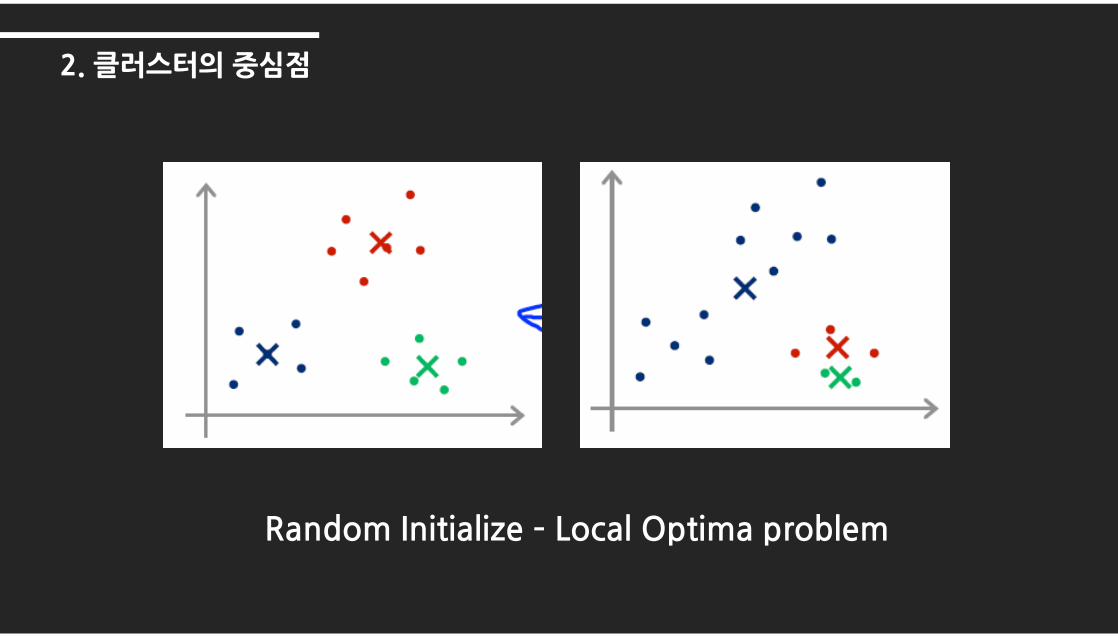
Random Initialize – Local Optima problem
2. 클러스터의중심점

“K-Means++ Algorithm”
2. 클러스터의중심점
1. Random initial centroid
2. Calculate distance, D(x)
3. Choose next centroid from D(x)2
“2007. k-means++: The Advantages of Careful Seeding” 논문 참조
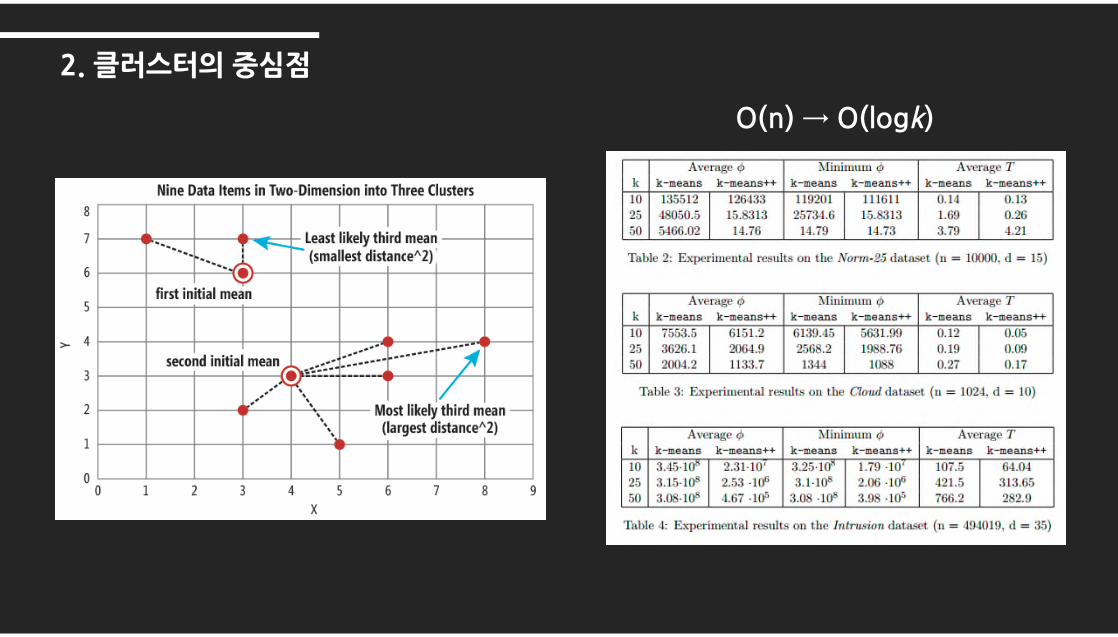
2. 클러스터의중심점
O(n) →�O(logk)

2. 클러스터의중심점
Sklearn.cluster.KMeans는 기본 값으로 K-Means++를 사용

3. K의 개수 설정
Using Elbow Method
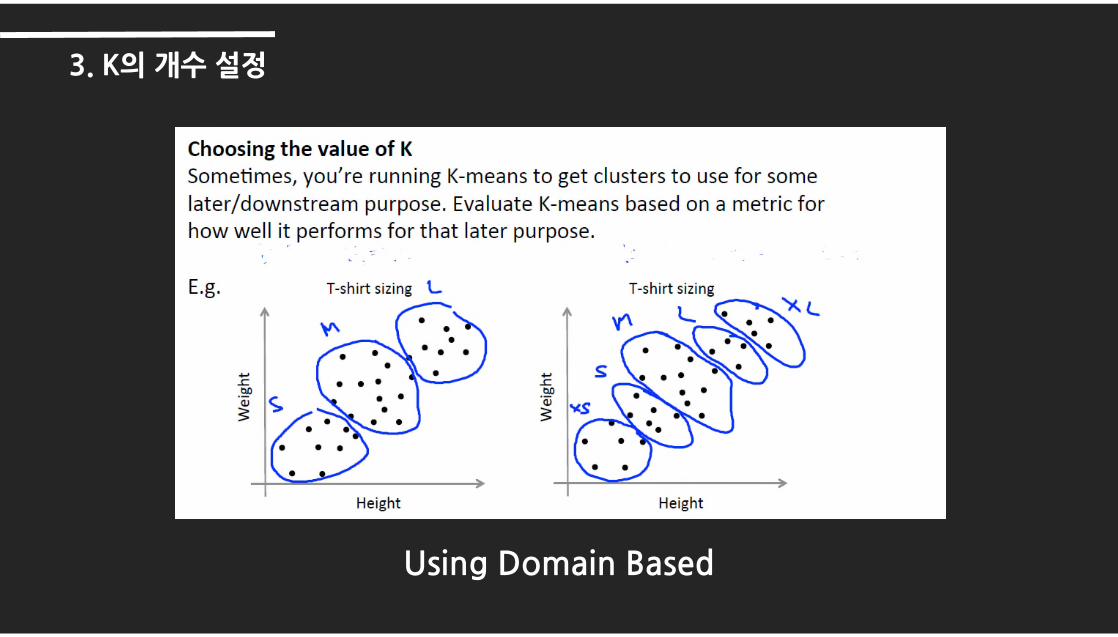
Using Domain Based
3. K의 개수 설정

4. 클러스터링검증방법
1. 내부 평가 (Internal Evaluation)
Davies-Bouldin Index, Dunn Index
2. 외부 평가 (External Evaluation)
Rand Measure, F-Measure, Jaccard Index

4. 클러스터링검증방법
Sklearn.metrics.silhouette_score







