
CS 443 Advanced OS
Fabián E. Bustamante, Spring 2005
Porcupine: A Highly Available Cluster-based Mail Service
Y. Saito, B. Bershad, H. Levy
U. Washington
SOSP 1999
Presented by: Fabián E. Bustamante

2
Porcupine – goals & requirements
Use commodity hardware to build a large, scalable mail service
Main goal – scalability in terms of– Manageability - large but easy to manage
• Self-configure w/ respect to load and data distribution• Self-heal with respect to failure & recovery
– Availability – survive failures gracefully• Failure may prevent some users to access email
– Performance – scale linear with cluster size• Target – 100s of machines ~ billions of mail msgs/day

3
Key Techniques and Relationships
Functional Homogeneity“any node can perform any task”
AutomaticReconfiguration
Dynamic SchedulingReplication
ManageabilityPerformanc
eAvailability
Framework
Techniques
Goals

4
Why Email?
Mail is important– Real demand – Saito now works for Google
Mail is hard– Write intensive– Low locality
Mail is easy– Well-defined API– Large parallelism– Weak consistency

5
Conventional Mail Solution
Static partitioning
Performance problems:– No dynamic load balancing
Manageability problems:– Manual data partition
Availability problems:– Limited fault tolerance
SMTP/IMAP/POP
Jeanine’smbox
Luca’smbox
Joe’smbox
Suzy’smbox
NFS servers

6
Porcupine Architecture
Node A ...Node B Node Z...
SMTPserver
POPserver
IMAPserver
Mail mapMailbox storage
User profile
Replication Manager
Membership Manager
RPC
Load Balancer
User map
7
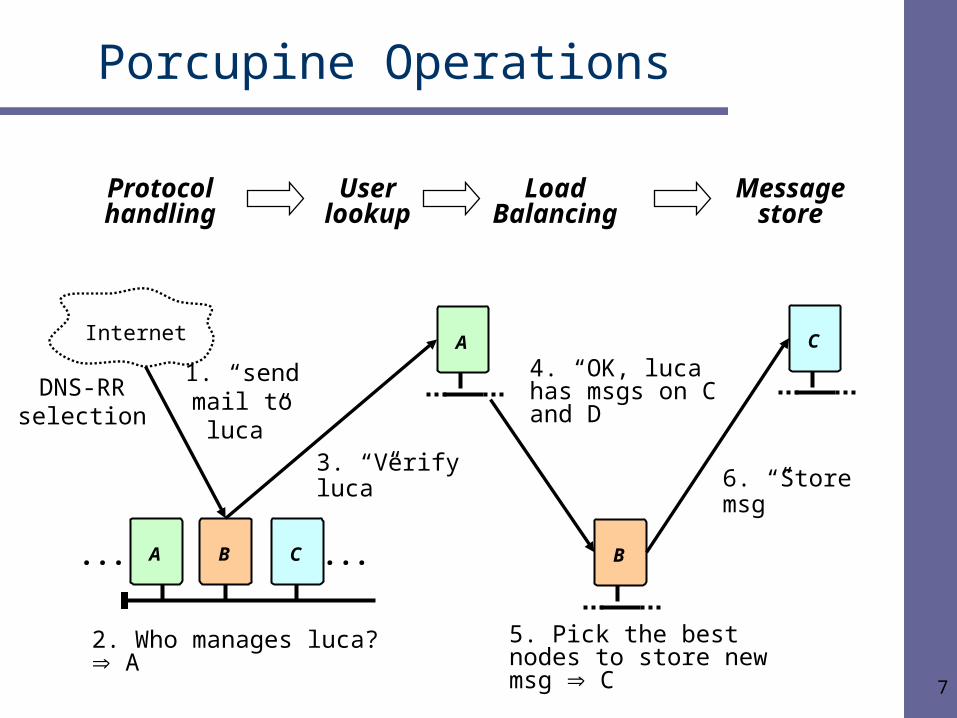
Porcupine Operations
DNS-RR selection
Protocol handling
User lookup
Load Balancing
Message store
Internet
A B...
A
1. “send mail to luca”
2. Who manages luca? A
3. “Verify luca”
5. Pick the best nodes to store new msg C
4. “OK, luca has msgs on C and D
6. “Store msg”
B
C
...C

8
Basic Data Structures
“luca”
B C A C A B A C
Luca: {A,C}ann: {B}
B C A C A B A C
suzy: {A,C} joe: {B}
B C A C A B A C
Apply hash function
User map
Mail map/user info
Mailbox storage
A B C
Luca’s MSGs
Suzy’s MSGs
Bob’s MSGs
Joe’s MSGs
Ann’s MSGs
Suzy’s MSGs

9
Porcupine Advantages
Advantages:– Optimal resource utilization– Automatic reconfiguration and task re-distribution
upon node failure/recovery– Fine-grain load balancing
Results:– Better Availability– Better Manageability– Better Performance

10
Performance
Goals– Scale performance linearly with cluster size
Strategy: Avoid creating hot spots– Partition data uniformly among nodes– Fine-grain data partition

11
Measurement Environment
30 node cluster of not-quite-all-identical PCs– 100Mb/s Ethernet + 1Gb/s hubs– Linux 2.2.7– 42,000 lines of C++ code
Synthetic load
Compare to sendmail+popd

12
How does Performance Scale?
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Messages/second
Porcupine
sendmail+popd68m/day
25m/day

13
Availability
Goals:– Maintain function after failures– React quickly to changes regardless of cluster size– Graceful performance degradation / improvement
Strategy: Two complementary mechanisms– Hard state: email messages, user profile– Optimistic fine-grain replication– Soft state: user map, mail map – Reconstruction after membership
change

14
Soft-state Reconstruction
1. Membership protocolUsermap recomputation
2. Distributed disk scan
Timeline
A
B
B C A B A B A C
luca: {A,C}
joe: {C}
B C A B A B A C
ann: {B}
B C A B A B A C
suzy: {A,B}C
B A A B A B A B
luca: {A,C}
joe: {C}
B A A B A B A B
suzy:
ann:
ann: {B}
B C A B A B A C
suzy: {A,B}
A C A C A C A C
luca: {A,C}
joe: {C}
A C A C A C A C
suzy: {A,B}
ann: {B}
ann: {B}
B C A B A B A C
suzy: {A,B}

15
Reaction to Configuration Changes
300
400
500
600
700
0 100 200 300 400 500 600 700 800Time(seconds)
Messages/second
No failure
One nodefailureThree nodefailuresSix nodefailures
Nodes fail
New membership determined
Nodes recover
New membership determined

16
Hard-state Replication
Goals:– Keep serving hard state after failures– Handle unusual failure modes
Strategy: Exploit Internet semantics– Optimistic, eventually consistent replication– Per-message, per-user-profile replication– Efficient during normal operation– Small window of inconsistency

17
Replication Efficiency
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Me
ss
ag
es
/se
co
nd
Porcupine no replication
Porcupine with replication=2 68m/day
24m/day

18
Replication Efficiency
0
100
200
300
400
500
600
700
800
0 5 10 15 20 25 30Cluster size
Me
ss
ag
es
/se
co
nd
Porcupine no replication
Porcupine with replication=2
Porcupine with replication=2, NVRAM 68m/day
24m/day
33m/day
Pretending – remove disk flushing from disk
logging routines.

19
Load balancing: Storing messages
Goals:– Handle skewed workload well– Support hardware heterogeneity– No voodoo parameter tuning
Strategy: Spread-based load balancing– Spread: soft limit on # of nodes per mailbox
• Large spread better load balance• Small spread better affinity
– Load balanced within spread– Use # of pending I/O requests as the load
measure

20
Support of Heterogeneous Clusters
0%
10%
20%
30%
0% 3% 7% 10%Number of fast nodes (% of total)
Th
rou
gh
pu
t in
crea
se(%
)
Spread=4
Static+16.8m/day (+25%)
+0.5m/day (+0.8%)
Node heterogeneity – 0% all nodes ~ at same speed, 3,7 & 10% - percentage of nodes w/ very fast disks
Relative performance improvement.

21
Conclusions
Fast, available, and manageable clusters can be built for write-intensive serviceKey ideas can be extended beyond mail– Functional homogeneity– Automatic reconfiguration– Replication– Load balancing
Ongoing work– More efficient membership protocol– Extending Porcupine beyond mail: Usenet,
Calendar, etc – More generic replication mechanism







