
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
1
Designing High Performance Web-Based Computing Services to Promote Telemedicine Database Management System
Ismail Hababeh1, Issa Khalil2, and Abdallah Khreishah3
1: Computer Engineering & Information Technology, German-Jordanian University, Jordan, [email protected]
2: Qatar Computing Research Institute (QCRI), Qatar Foundation, Doha, Qatar, [email protected]
3: Department of Electrical & Computer Engineering, New Jersey Institute of Technology, USA, [email protected]
Corresponding Author: Issa Khalil, Email: [email protected]
Abstract
Many web computing systems are running real time database services where their information change continuously and
expand incrementally. In this context, web data services have a major role and draw significant improvements in
monitoring and controlling the information truthfulness and data propagation. Currently, web telemedicine database
services are of central importance to distributed systems. However, the increasing complexity and the rapid growth of the
real world healthcare challenging applications make it hard to induce the database administrative staff. In this paper, we
build an integrated web data services that satisfy fast response time for large scale Tele-health database management
systems. Our focus will be on database management with application scenarios in dynamic telemedicine systems to
increase care admissions and decrease care difficulties such as distance, travel, and time limitations. We propose three-
fold approach based on data fragmentation, database web sites clustering and intelligent data distribution. This approach
reduces the amount of data migrated between web sites during applications’ execution; achieves cost-effective
communications during applications’ processing and improves applications’ response time and throughput. The proposed
approach is validated internally by measuring the impact of using our computing services’ techniques on various
performance features like communications cost, response time, and throughput. The external validation is achieved by
comparing the performance of our approach to that of other techniques in the literature. The results show that our
integrated approach significantly improves the performance of web database systems and outperforms its counterparts.
Keywords: Web Telemedicine Database Systems (WTDS); database fragmentation; data distribution; sites clustering.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
2
1. Introduction
The rapid growth and continuous change of the real world software applications have provoked researchers to propose
several computing services’ techniques to achieve more efficient and effective management of web telemedicine
database systems (WTDS). Significant research progress has been made in the past few years to improve WTDS
performance. In particular, databases as a critical component of these systems have attracted many researchers. The web
plays an important role in enabling healthcare services like telemedicine to serve inaccessible areas where there are few
medical resources. It offers an easy and global access to patients’ data without having to interact with them in person and
it provides fast channels to consult specialists in emergency situations. Different kinds of patient’s information such as
ECG, temperature, and heart rate need to be accessed by means of various client devices in heterogeneous
communications environments. WTDS enable high quality continuous delivery of patient’s information wherever and
whenever needed. Several benefits can be achieved by using web telemedicine services including: medical consultation
delivery, transportation cost savings, data storage savings, and mobile applications support that overcome obstacles
related to the performance (e.g. bandwidth, battery life, and storage), security (e.g. privacy, and reliability), and
environment (e.g. scalability, heterogeneity, and availability). The objectives of such services are to: (i) develop large
applications that scale as the scope and workload increases, (ii) achieve precise control and monitoring on medical data to
generate high telemedicine database system performance, (iii) provide large data archive of medical data records,
accurate decision support systems, and trusted event-based notifications in typical clinical centers.
Recently, many researchers have focused on designing web medical database management systems that satisfy certain
performance levels. Such performance is evaluated by measuring the amount of relevant and irrelevant data accessed
and the amount of transferred medical data during transactions’ processing time. Several techniques have been proposed
in order to improve telemedicine database performance, optimize medical data distribution, and control medical data
proliferation. These techniques believed that high performance for such systems can be achieved by improving at least
one of the database web management services, namelydatabase fragmentation, data distribution, web sites clustering,
distributed caching, and database scalability. However, the intractable time complexity of processing large number of
medical transactions and managing huge number of communications make the design of such methods a non-trivial task.
Moreover, none of the existing methods consider the three-fold services together which makes them impracticable in the
field of web database systems. Additionally, using multiple medical services from different web database providers may

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
3
not fit the needs for improving the telemedicine database system performance. Furthermore, the services from different
web database providers may not be compatible or in some cases it may increase the processing time because of the
constraints on the network [1]. Finally, there has been lack in the tools that support the design, analysis and cost-effective
deployments of web telemedicine database systems [1].
Designing and developing fast, efficient, and reliable incorporated techniques that can handle huge number of medical
transactions on large number of web healthcare sites in near optimal polynomial time are key challenges in the area of
WTDS. Data fragmentation, web sites clustering, and data allocation are the main components of the WTDS that continue
to create great research challenges as their current best near optimal solutions are all NP-Complete.
To improve the performance of medical distributed database systems, we incorporate data fragmentation, web sites
clustering, and data distribution computing services together in a new web telemedicine database system approach. This
new approach intends to decrease data communication, increase system throughput, reliability, and data availability.
The decomposition of web telemedicine database relations into disjoint fragments allows database transactions to be
executed concurrently and hence minimizes the total response time. Fragmentation typically increases the level of
concurrency and, therefore, the system throughput. The benefits of generating telemedicine disjoint fragments cannot be
deemed unless distributing these fragments over the web sites, so that they reduce communication cost of database
transactions. Database disjoint fragments are initially distributed over logical clusters (a group of web sites that satisfy a
certain physical property, e.g. communications cost). Distributing database disjoint fragments to clusters where a benefit
allocation is achieved, rather than allocating the fragments to all web sites, have an important impact on database system
throughput. This type of distribution reduces the number of communications required for query processing in terms of
retrieval and update transactions; it has always a significant impact on the web telemedicine database system
performance. Moreover, distributing disjoint fragments among the web sites where it is needed most, improves database
system performance by minimizing the data transferred and accessed during the execution time, reducing the storage
overheads, and increasing availability and reliability as multiple copies of the same data are allocated.
Database partitioning techniques aim at improving database systems throughput by reducing the amount of irrelevant
data packets (fragments) to be accessed and transferred among different web sites. However, data fragmentation raises
some difficulties; particularly when web telemedicine database applications have contradictory requirements that avert
breakdown of the relation into mutually exclusive fragments. Those applications whose views are defined on more than

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
4
one fragment may suffer performance ruin. In this case, it might be necessary to retrieve data from two or more
fragments and take their join, which is costly [31]. Data fragmentation technique describes how each fragment is derived
from the database global relations. Three main classes of data fragmentation have been discussed in the literature;
horizontal [2][3], vertical [4][5], and hybrid [6][7]. Although there are various schemes describing data partitioning, few
are known for the efficiency of their algorithms and the validity of their results [33].
The Clustering technique identifies groups of network sites in large web database systems and discovers better data
distributions among them. This technique is considered to be an efficient method that has a major role in reducing the
amount of transferred and accessed data during processing database transactions. Accordingly, clustering techniques help
in eliminating the extra communications costs between web sites and thus enhances distributed database systems
performance [32]. However, the assumptions on the web communications and the restrictions on the number of network
sites, make clustering solutions impractical [16][31]. Moreover, some constraints about network connectivity and
transactions processing time bound the applicability of the proposed solutions to small number of clusters [9][10].
Data distribution describes the way of allocating the disjoint fragments among the web clusters and their respective sites
of the database system. This process addresses the assignment of each data fragment to the distributed database web
sites [8][17][18][21]. Data distribution related techniques aim at improving distributed database systems performance.
This can be accomplished by reducing the number of database fragments that are transferred and accessed during the
execution time. Additionally, Data distribution techniques attempt to increase data availability, elevate database
reliability, and reduce storage overhead [11][27]. However, the restrictions on database retrieval and update frequencies
in some data allocation methods may negatively affect the fragments distribution over the web sites [20].
In this work, we address the previous drawbacks and propose a three-fold approach that manages the computing web
services that are required to promote telemedicine database system performance. The main contributions are:
Develop a fragmentation computing service technique by splitting telemedicine database relations into small disjoint
fragments. This technique generates the minimum number of disjoint fragments that would be allocated to the web
servers in the data distribution phase. This in turn reduces the data transferred and accessed through different web
sites and accordingly reduces the communications cost.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
5
Introduce a high speed clustering service technique that groups the web telemedicine database sites into sets of
clusters according to their communications cost. This helps in grouping the web sites that are more suitable to be in
one cluster to minimize data allocation operations, which in turn helps to avoid allocating redundant data.
Propose a new computing service technique for telemedicine data allocation and redistribution services based on
transactions’ processing cost functions. These functions guarantee the minimum communications cost among web
sites and hence accomplish better data distribution compared to allocating data to all web sites evenly.
Develop a user-friendly experimental tool to perform services of telemedicine data fragmentation, web sites
clustering, and fragments allocation, as well as assist database administrators in measuring WTDS performance.
Integrate telemedicine database fragmentation, web sites clustering, and data fragments allocation into one scenario
to accomplish ultimate web telemedicine system throughput in terms of concurrency, reliability, and data availability.
We call this scenario Integrated-Fragmentation-Clustering- Allocation (IFCA) approach. Figure 1 depicts the
architecture of the proposed telemedicine IFCA approach.
Figure 1: IFCA Computing Services Architecture
In Figure 1, the data request is initiated from the telemedicine database system sites. The requested data is defined as
SQL queries that are executed on the database relations to generate data set records. Some of these data records may be
overlapped or even redundant, which increase the I/O transactions’ processing time and so the system communications
overhead. To solve this problem, we execute the proposed fragmentation technique which generates telemedicine
disjoint fragments that represent the minimum number of data records. The web telemedicine database sites are
grouped into clusters by using our clustering service technique in a phase prior to data allocation. The purpose of this
clustering is to reduce the communications cost needed for data allocation. Accordingly, the proposed allocation service
Web Telemedicine Database System Administrator
Phase 6: Executing Allocation Technique on Clusters &
Allocate Fragments to Clusters
Phase 4: Executing
Fragmentation Technique & Generating
Disjoint Fragments
DSR1DSR2
QR3….QR2
QR1
DSR3DSR4…
DF1 DF2 DF3….
WS1
WS 2
WS3…..
Phase 2: Defining Queries
Phase 5: Executing Clustering Technique &
Generating Clusters
Phase 1: Requesting Data for Processing
Phase 7: Executing Allocation Technique on Sites & Allocate Fragments to Sites
Phase 3: Executing Queries &
Generating Data Set of
Records
Web Telemedicine Database Sites

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
6
technique is applied to allocate the generated disjoint fragments at the clusters that show positive benefit allocation.
Then the fragments are allocated to the sites within the selected clusters. Database administrator is responsible for
recovering any site failure in the WTDS.
The remainder of the paper is organized as follows. Section 22 summarizes the related work. Basic concepts of the web
telemedicine database settings and assumptions are discussed in Section 3. Telemedicine computation services and
estimation model are discussed in Section 4. Experimental results and performance evaluation are presented in
Section 35. Finally, in Section 6, we draw conclusions and outline the future work.
2. Related Work
Many research works have attempted to improve the performance of distributed database systems. These works have
mostly investigated fragmentation, allocation and sometimes clustering problems. In this section, we present the main
contributions related to these problems, discuss and compare their contributions with our proposed solutions.
2.1. Data Fragmentation
With respect to fragmentation, the unit of data distribution is a vital issue. A relation is not appropriate for distribution as
application views are usually subsets of relations *31+. Therefore, the locality of applications’ accesses is defined on the
derivative relations subsets. Hence it is important to divide the relation into smaller data fragments and consider it for
distribution over the network sites. The authors in [8] considered each record in each database relation as a disjoint
fragment that is subject for allocation in a distributed database sites. However, large number of database fragments is
generated in this method, causing a high communication cost for transmitting and processing the fragments. In contrast
to this approach, the authors in [11] considered the whole relation as a fragment, not all the records of the fragment have
to be retrieved or updated, and a selectivity matrix that indicates the percentage of accessing a fragment by a transaction
is proposed. However, this research suffers from data redundancy and fragments overlapping.
2.2. Clustering Web Sites
Clustering service technique identifies groups of networking sites and discovers interesting distributions among large web
database systems. This technique is considered as an efficient method that has a major role in reducing transferred and
accessed data during transactions processing [9]. Moreover, grouping distributed network sites into clusters helps to

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
7
eliminate the extra communication costs between the sites and then enhances the distributed database system
performance by minimizing the communication costs required for processing the transactions at run time.
In a web database system environment where the number of sites has expanded tremendously and amount of data has
increased enormously, the sites are required to manage these data and should allow data transparency to the users of the
database. Moreover, to have a reliable database system, the transactions should be executed very fast in a flexible load
balancing database environment. When the number of sites in a web database system increases to a large scale, the
problem of supporting high system performance with consistency and availability constraints becomes crucial. Different
techniques could be developed for this purpose; one of them is web sites clustering.
Grouping web sites into clusters reduces communications cost and then enhances the performance of the web database
system. However, clustering network sites is still an open problem and the optimal solution to this problem is NP-
Complete [12]. Moreover, in case of a complex network where large numbers of sites are connected to each other, a huge
number of communications are required, which increases the system load and degrades its performance.
The authors in [13] have proposed a hierarchical clustering algorithm that uses similarity upper approximation derived
from a tolerance(similarity) relation and based on rough set theory that does not require any prior information about the
data. The presented approach results in rough clusters in which an object is a member of more than one cluster. Rough
clustering can help researchers to discover multiple needs and interests in a session by looking at the multiple clusters
that a session belongs to. However, in order to carry out rough clustering, two additional requirements, namely, an
ordered value set of each attribute and a distance measure for clustering need to be specified [14]. Clustering coefficients
are needed in many approaches in order to quantify the structural network properties. In [15], the authors proposed
higher order clustering coefficients defined as probabilities that determine the shortest distance between any two
nearest neighbors of a certain node when neglecting all paths crossing this node. The outcomes of this method declare
that the average shortest distance in the node’s neighborhood is smaller than all network distances. However,
independent constant values and natural logarithm function are used in the shortest distance approximation function to
determine the clustering mechanism, which results in generating small number of clusters.
2.3. Data Allocation (Distribution)
Data allocation describes the way of distributing the database fragments among the clusters and their respective sites in
distributed database systems. This process addresses the assignment of network node(s) to each fragment [8]. However,

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
8
finding an optimal data allocation is NP-complete problem [12]. Distributing data fragments among database web sites
improves database system performance by minimizing the data transferred and accessed during execution, reducing the
storage overhead, and increasing availability and reliability where multiple copies of the same data are allocated.
Many data allocation algorithms are described in the literature. The efficiency of these algorithms is measured in term of
response time. Authors in [19] proposed an approach that handles the full replication of data allocation in database
systems. In this approach, a database file is fully copied to all participating nodes through the master node. This approach
distributes the sequences through fragments with a round-robin strategy for sequence input set already ordered by size,
where the number of sequences is about the same and number of characters at each fragment is similar. However, this
replicated schema does not achieve any performance gain when increasing the number of nodes. When a non-previously
determined number of input sequences are present, the replication model may not be the best solution and other
fragmentation strategies have to be considered. In [20], the author has addressed the fragment allocation problem in web
database systems. He presented an integer programming formulations for the non-redundant version of the fragment
allocation problem. This formulation is extended to address problems, which have both storage and processing capacity
constraints. In this method, the constraints essentially state that there has been exactly one copy of a fragment across all
sites, which increase the risk of data inconsistency and unavailability in case of any site failure. However, the fragment
size is not addressed while the storage capacity constraint is one of the major objectives of this approach. In addition, the
retrieval and update frequencies are not considered in the formulations, they are assumed to be the same, which affects
the fragments distribution over the sites. Moreover, this research is limited by the fact that none of the approaches
presented have been implemented and tested on a real web database system.
A dynamic method for data fragmentation, allocation, and replication is proposed in [25]. The objective of this approach is
to minimize the cost of access, re-fragmentation, and reallocation. DYFRAM algorithm of this method examines accesses
for each replica and evaluates possible re-fragmentations and reallocations based on recent history. The algorithm runs at
given intervals, individually for each replica. However, data consistency and concurrency control are not considered in
DYFRAM. Additionally, DYFRAM doesn’t guarantee data availability and system reliability when all sites have negative
utility values. In [28], the authors present a horizontal fragmentation technique that is capable of taking a fragmentation
decision at the initial stage, and then allocates the fragments among the sites of DDBMS. A modified matrix MCRUD is
constructed by placing predicates of attributes of a relation in rows and applications of the sites of a DDBMS in columns.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
9
Attribute locality precedence ALP; the value of importance of an attribute with respect to sites of distributed database is
generated as a table from MCRUD. However, when all attributes have the same locality precedence, the same fragment
has to be allocated in all sites, and a huge data redundancy occurs. Moreover, the initial values of frequencies and weights
don’t reflect the actual ones in real systems, and this may affect the number of fragments and their allocation accordingly.
The authors in [29] presented a method for modeling the distributed database fragmentation by using UML 2.0 to
improve applications performance. This method is based on a probability distribution function where the execution
frequency of a transaction is estimated mainly by the most likely time. However, the most likely time is not determined to
distinguish the priorities between transactions. Furthermore, no performance evaluations are performed and no
significant results are generated from this method. A database tool shown in [30] addresses the problem of designing
DDBs in the context of the relational data model. Conceptual design, fragmentation issues, as well as the allocation
problem are considered based on other methods in the literature. However, this tool doesn’t consider the local
optimization of fragment allocation problem over the distributed network sites. In addition, many design parameters
need to be estimated and entered by designers where different results may be generated for the same application case.
Our fragmentation approach circumvents the problems associated with the aforementioned studies by introducing a
computing service technique that generates disjoint fragments, avoids data redundancy and considers that all records of
the fragment are retrieved or updated by a transaction. By such a technique, less communication costs are required to
transmit and process the disjoint database fragments. In addition, by applying the clustering service technique, the
complexity of allocation problem is significantly reduced. Therefore, the intractable solution of fragment allocation is
turned out into fragment distribution among the clusters and then replicating it among the related sites.
2.4. Commercial Outsource Databases
This section investigates current commercial outsource databases and compares them with our IFCA. The commercial
outsource databases support enormous data storage architecture that distributes storage and processing across several
servers. It can be used to address web database system performance and scalability requirements.
Amazon Dynamo [34] is a cloud distributed database system with high available and scalable capabilities. In contrast to
traditional relational distributed database management systems, Dynamo only supports database applications with
simple read and write queries on data records. However, in Dynamo availability is more important than consistency.
Accordingly, in certain times, data consistency can’t be guaranteed. MongoDB [35] is an open source, document oriented
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
10
cloud distributed database developed by the 10gen software company. MongoDB is highly available and scalable system
that supports search by fields in the documents. However, MongoDB uses a special query optimizer to make queries more
efficient, and executes different query plans concurrently, which increases the search time complexity.
Google BigTable [36] is a cloud distributed database system built on Google file system and a highly available and
persistent distributed lock service. The BigTable data model is designed as a distributed multidimensional (row key,
column key, timestamps) sorted map, and implemented on three parts: tablet servers, client library, and master server.
However, as the failure of the master server results in the failure of the whole database system, and thus another server
usually backs up the master server. This incurs additional costs to the cloud distributed database system in addition to
the costs of operating and maintaining the new servers.
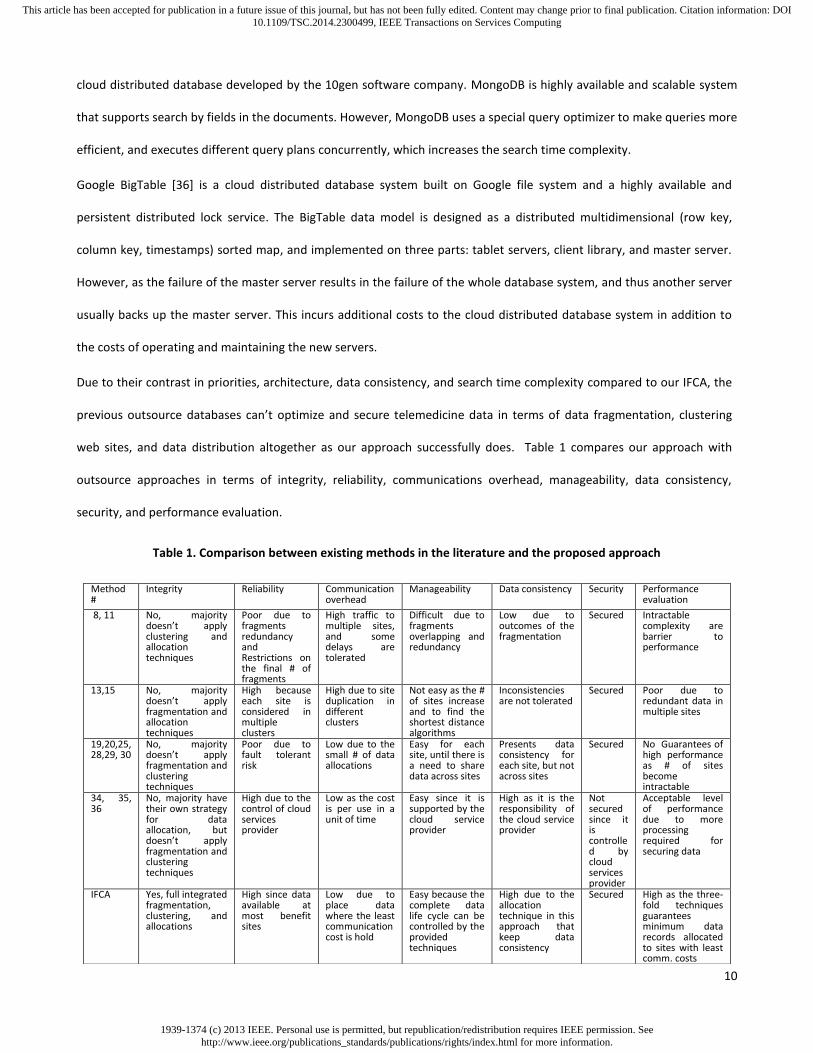
Due to their contrast in priorities, architecture, data consistency, and search time complexity compared to our IFCA, the
previous outsource databases can’t optimize and secure telemedicine data in terms of data fragmentation, clustering
web sites, and data distribution altogether as our approach successfully does. Table 1 compares our approach with
outsource approaches in terms of integrity, reliability, communications overhead, manageability, data consistency,
security, and performance evaluation.
Table 1. Comparison between existing methods in the literature and the proposed approach
Method #
Integrity Reliability Communication overhead
Manageability Data consistency Security Performance evaluation
8, 11 No, majority doesn’t apply clustering and allocation techniques
Poor due to fragments redundancy and Restrictions on the final # of fragments
High traffic to multiple sites, and some delays are tolerated
Difficult due to fragments overlapping and redundancy
Low due to outcomes of the fragmentation
Secured Intractable complexity are barrier to performance
13,15 No, majority doesn’t apply fragmentation and allocation techniques
High because each site is considered in multiple clusters
High due to site duplication in different clusters
Not easy as the # of sites increase and to find the shortest distance algorithms
Inconsistencies are not tolerated
Secured Poor due to redundant data in multiple sites
19,20,25,28,29, 30
No, majority doesn’t apply fragmentation and clustering techniques
Poor due to fault tolerant risk
Low due to the small # of data allocations
Easy for each site, until there is a need to share data across sites
Presents data consistency for each site, but not across sites
Secured No Guarantees of high performance as # of sites become intractable
34, 35, 36
No, majority have their own strategy for data allocation, but doesn’t apply fragmentation and clustering techniques
High due to the control of cloud services provider
Low as the cost is per use in a unit of time
Easy since it is supported by the cloud service provider
High as it is the responsibility of the cloud service provider
Not secured since it is controlled by cloud services provider
Acceptable level of performance due to more processing required for securing data
IFCA Yes, full integrated fragmentation, clustering, and allocations
High since data available at most benefit sites
Low due to place data where the least communication cost is hold
Easy because the complete data life cycle can be controlled by the provided techniques
High due to the allocation technique in this approach that keep data consistency
Secured High as the three-fold techniques guarantees minimum data records allocated to sites with least comm. costs

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
11
3. Telemedicine IFCA Assumptions and Definitions
Incorporating database fragmentation, web database sites’ clustering, and data fragments computing services’ allocation
techniques in one scenario distinguishes our approach from other approaches. The functionality of such approach
depends on the settings, assumptions, and definitions that identify the WTDS implementation environment, to guarantee
its efficiency and continuity. Below are the description of the IFCA settings, assumptions, and definitions.
3.1. Web Architecture and Communications Assumptions
The telemedicine IFCA approach is designed to support web database provider with computing services that can be
implemented over multiple servers, where the data storage, communication and processing transactions are fully
controlled, costs of communication are symmetric, and the patients’ information privacy and security are met. We
propose fully connected sites on a web telemedicine heterogeneous network system with different bandwidths; 128 kbps,
512 kbps, or multiples. In this environment, some servers are used to execute the telemedicine queries triggered from
different web database sites. Few servers are run the database programs and perform the fragmentation-clustering-
allocation computing services while the other servers are used to store the database fragments. Communications cost
(ms/byte) is the cost of loading and processing data fragments between any two sites in WTDS. To control and simplify
the proposed web telemedicine communication system, we assume that communication costs between sites are
symmetric and proportional to the distance between them. Communication costs within the same site are neglected.
3.2. Fragmentation and Clustering Assumptions
Telemedicine queries are triggered from web servers as transactions to determine the specific information that should be
extracted from the database. Transactions include but not limited to: read, write, update, and delete. To control the
process of database fragmentation and to achieve data consistency in the telemedicine database system, IFCA
fragmentation service technique partitions each database relation according to the Inclusion-Integration-Disjoint
assumptions where the generated fragments must contain all records in the database relations, the original relation
should be able to be formed from its fragments, and the fragments should be neither repeated nor intersected. The
logical clustering decision is defined as a Logical value that specifies whether a web site is included or excluded from a
certain cluster, based on the communications cost range. The communications cost range is defined as a value (ms/byte)
that specifies how much time is allowed for the web sites to transmit or receive their data to be considered in the same
cluster, this value is determined by the telemedicine database administrator.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
12
3.3. Fragments Allocation Assumptions
The allocation decision value ADV is defined as a logical value (1, 0) that determines the fragment allocation status for a
specific cluster. The fragments that achieve allocation decision value of (1) are considered for allocation and replication
process. The advantage that can be generated from this assumption is that, more communications costs are saved due to
the fact that the fragments’ locations are in the same place where it is processed, hence improve the WTDS performance.
On the other hand, the fragments that carry out allocation decision value of (0) are considered for allocation process only
in order to ensure data availability and fault-tolerant in the WTDS. In this case, each fragment should be allocated to at
least one cluster and one site in this cluster. The allocation decision value ADV is assumed to be computed as the result of
the comparison between the cost of allocating the fragment to the cluster and the cost of not allocating the fragment to
the same cluster. The allocation cost function is composed of the following sub-cost functions that are required to
perform the fragment transactions locally: cost of local retrieval, cost of local update to maintain consistency among all
the fragments distributed over the web sites, and cost of storage, or cost of remote update and remote communications
(for remote clusters that do not have the fragment and still need to perform the required transactions on that fragment).
The not allocation cost function consists of the following sub-cost functions: cost of local retrieval and cost of remote
retrievals required to perform the fragment transactions remotely when the fragment is not allocated to the cluster.
4. Telemedicine IFCA Computation Services and Estimation Model
In the following subsections, we present our IFCA and provide mathematical models of its computations’ services.
4.1. Fragmentation Computing Service
To control the process of database fragmentation and maintain data consistency, the fragmentation technique partitions
each database relation into data set records that guarantee data inclusion, integration and non-overlapping. In a WTDS,
neither complete relation nor attributes are suitable data units for distribution, especially when considering very large
data. Therefore, it is appropriate to use data fragments that would be allocated to the WTDS sites. Data fragmentation is
based on the data records generated by executing the telemedicine SQL queries on the database relations. The
fragmentation process goes through two consecutive internal processes: (i) Overlapped and redundant data records
fragmentation and (ii) Non-overlapped data records fragmentation.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
13
The fragmentation service generates disjoint fragments that represent the minimum number of data records to be
distributed over the web sites by the data allocation service. The proposed fragmentation Service architecture is
described through Input-Processing-Output phases depicted in Figure 2. Based on this fragmentation service, the global
database is partitioned into disjoint fragments. The overlapped and redundant data records fragmentation process is
described in Table 2. In this algorithm, database fragmentation starts with any two random data fragments (i,j) with
intersection records and proceeds as follows: If intersection exists between the two fragments, three disjoint fragments
will be generated: Fk= Fi ∩ Fj, Fk+1 = Fi –Fk, and Fk+2 = Fj- F. The first contains the common records, the second contains the
records in the first fragment but not in the second fragment, and the third contains the records in the second fragment
but not in the first. The intersecting fragments are then removed from the fragments list. This process continues until no
more intersecting fragments or data set records still exist for this telemedicine relation, and so for the other relations.
Figure 2: Data Fragmentation Service Architecture
Table 2: Overlapped and redundant data records fragmentation Algorithm
Step 1: Set 1 to I; K = F.size()
Step 2: Do steps (3-18) until I >F.size()
Step 3: Set 1 to J
Step 4: Do steps (5-16) until J > F.size()
Step 5: If I J and Fi , Fj Є F go to (6)
Else, Add 1 to J and go to step (15)
Step 6: If Fi ∩ Fj≠ Ø do steps (7-14)
Else, Add 1 to J and go to step (14)
Step 7: Add 1 to K
Step 8: Create new fragment
Fk= Fi ∩ Fjand add it to F
Step 9: Create new fragment
Fk+1 = Fi –Fkand add it to F
Step 10: Create new fragment
Fk+2 = Fj- Fk and add it to F
Step 11: Delete Fi
Step 12: Delete Fj
Step 13: Set F + 1 to J
Step 14: End IF; Step 15: End IF
Step 16: Loop
Step 17: Add 1 to I
Step 18: Loop
Step 19: Add 1 to R
Step 20: Loop
The Non-overlapped data records fragmentation process is shown Table 3. The new derived fragments from Table 2 and
the fragments from non-overlapping fragments resulted in totally disjoint fragments. The non-overlapped fragments that
do not intersect with any other fragment in Table 2 are considered in the final set of the relation disjoint fragments. For
example, consider that the transactions triggered from the telemedicine database sites hold queries that require
extracting records from different telemedicine database relations. Let us assume three transactions for patient relation
(T1, T2, T3) on sites S1, S2, and S3 respectively. T1 defines Patients who medicated by Doctor #1, T2 defines Patients who
took medicine #4, and T3 defines Patients who paid more than $1000. The data set 1 in patient relation intersects with
Set of Telemedicine
database Relations
Set of data records generated by telemedicine
queries
Execute the fragmentation technique for
the overlapped and redundant
data records
Execute the fragmentation technique for
the non-overlapped data
records
Set of disjoint fragments
Start Processing End

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
14
data set 2 in the same relation. This result in new disjoint fragments: F1, F2 and F3. The Data sets 1 and 2 are omitted.
Fragment F1 and data set 3 in the same relation are intersected. This results in the new disjoint fragments F4, F5, and F6.
Then F1 and the data set 3 are omitted, and the next intersection is between F2 and F6. The result is new disjoint
fragments; F7, F8, and F9. Then F2 and F6 are omitted. The final disjoint fragments generated from the transactions over
patient relations are: F3, F4, F5, F7, F8, and F9. Table 4 depicts the fragmentation process over patient relation.
Table 3: Non-overlapped Data Records Fragmentation Algorithm
Step 21: Set 1 to I; K = F.size()
Step 22 Do steps (23-34) until I >F.size()
Step 23: Set 1 to J
Step 24: Do steps (25-32) until J >F.size()
Step 25: If I J and Fi , FjЄ Fgo to (26)
Else Add 1 to J, go to step (32)
Step 26: If Fi ∩ Fj= Ø do steps (27-32)
Step 27: Add 1 to K
Step 28: Create new fragment Fk= Rj- U F
Step 29: End IF
Step 30: If Fk≠ Ø Add FktoF
Step 31: End IF
Step 32: Loop
Step 33: Add 1 to I
Step 34: Loop
Table 4: Fragmentation process over patient relation
4.2. Clustering Computing Service
The benefit of generating database disjoint fragments can’t be completed unless it enhances the performance of the
WTDS. As the number of database sites becomes too large, supporting high system performance with consistency and
availability constraints becomes crucial. Several techniques are developed for this purpose; one of them consists of
clustering web sites. However, grouping sites into clusters is still an open problem with NP-Complete optimal solution
[12]. Therefore, developing a near-optimal solution for grouping web database sites into clusters helps to eliminate the
extra communication costs between the sites during the process of data allocation. Clustering web telemedicine database
sites speeds up the process of data allocation by distributing the fragments at the clusters that accomplish benefit
allocation rather than distributing the fragments once at all web sites. Thus, the communication costs are minimized and
the WTDS performance is improved. In this work, we introduce a high speed clustering service based on the least average
communication cost between sites. The parameters used to control the input/output computations for generating
clusters and determining the set of sites in each are computed as follows:
Communications Cost between sites CC(Si,Sj) = data creation cost + data transmission cost between Si,Sj.
Communication Cost Range CCR (ms/byte) which is determined by the telemedicine database system administrator.
Data Set # Site # Transaction # Relation # Generated Record(s)#
1 S1 T1 Patient (1) 39,41,56,63,72,85,97
2 S2 T2 Patient (1) 31,56,72,85,97
Fragment # Site # Transaction # Relation # Generated Record(s)#
F1 S1,S2 T1∩T2 Patient (1) 56,72,85,97
F2 S1 T1 Patient (1) 39,41,63
F3 S2 T2 Patient (1) 31
Data Set # Site # Transaction # Relation # Generated Record(s)#
3 S3 T3 Patient (1) 17,24,41,63,97
Fragment # Site # Transaction # Relation # Generated Record(s)#
F4 S1,S2,
S3
(T1∩T2) ∩T3 Patient (1) 97
F5 S1,S2 (T1∩T2) Patient (1) 56,72,85
F6 S3 T3 Patient (1) 17,24,41,63
Fragment # Site # Transaction # Relation # Generated Record(s)#
F7 S1,S3 (T1∩T3) Patient (1) 41,63
F8 S1 T1 Patient (1) 39
F9 S3 T3 Patient (1) 17,24
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
15
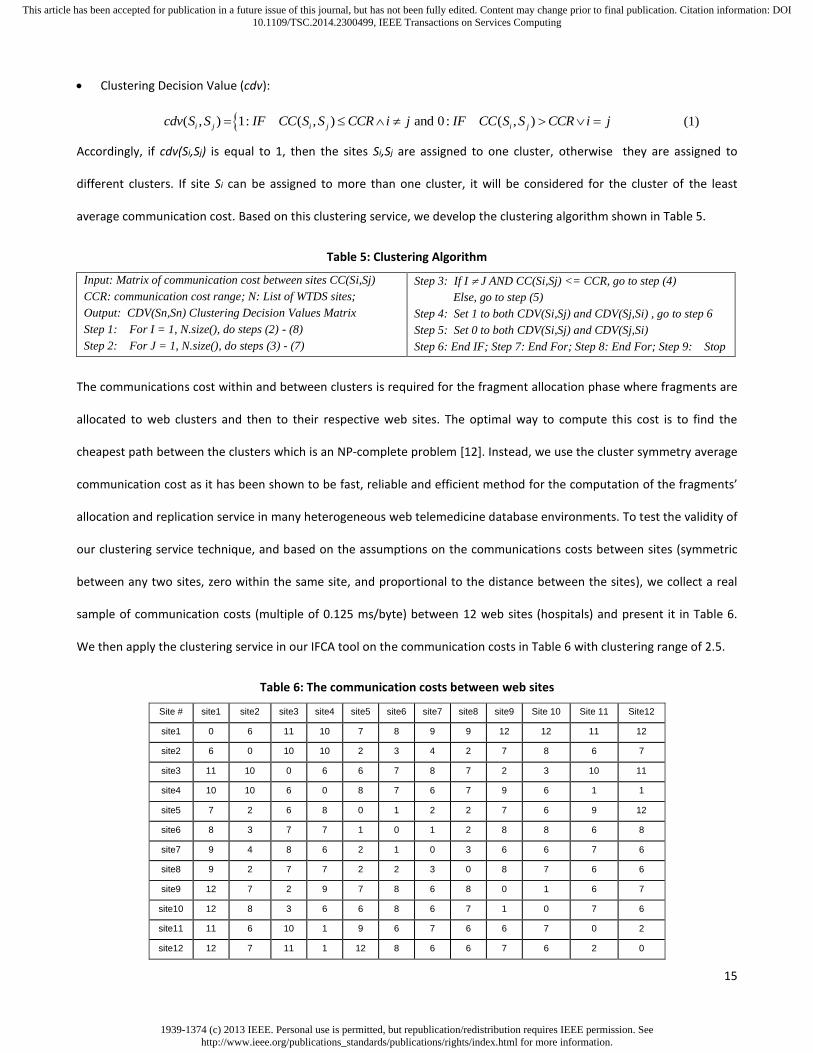
Clustering Decision Value (cdv):
( , ) 1: ( , ) and 0 : ( , )i j i j i jcdv S S IF CC S S CCR i j IF CC S S CCR i j (1)
Accordingly, if cdv(Si,Sj) is equal to 1, then the sites Si,Sj are assigned to one cluster, otherwise they are assigned to
different clusters. If site Si can be assigned to more than one cluster, it will be considered for the cluster of the least
average communication cost. Based on this clustering service, we develop the clustering algorithm shown in Table 5.
Table 5: Clustering Algorithm
Input: Matrix of communication cost between sites CC(Si,Sj)
CCR: communication cost range; N: List of WTDS sites;
Output: CDV(Sn,Sn) Clustering Decision Values Matrix
Step 1: For I = 1, N.size(), do steps (2) - (8)
Step 2: For J = 1, N.size(), do steps (3) - (7)
Step 3: If I J AND CC(Si,Sj) <= CCR, go to step (4)
Else, go to step (5)
Step 4: Set 1 to both CDV(Si,Sj) and CDV(Sj,Si) , go to step 6
Step 5: Set 0 to both CDV(Si,Sj) and CDV(Sj,Si)
Step 6: End IF; Step 7: End For; Step 8: End For; Step 9: Stop
The communications cost within and between clusters is required for the fragment allocation phase where fragments are
allocated to web clusters and then to their respective web sites. The optimal way to compute this cost is to find the
cheapest path between the clusters which is an NP-complete problem [12]. Instead, we use the cluster symmetry average
communication cost as it has been shown to be fast, reliable and efficient method for the computation of the fragments’
allocation and replication service in many heterogeneous web telemedicine database environments. To test the validity of
our clustering service technique, and based on the assumptions on the communications costs between sites (symmetric
between any two sites, zero within the same site, and proportional to the distance between the sites), we collect a real
sample of communication costs (multiple of 0.125 ms/byte) between 12 web sites (hospitals) and present it in Table 6.
We then apply the clustering service in our IFCA tool on the communication costs in Table 6 with clustering range of 2.5.
Table 6: The communication costs between web sites
Site # site1 site2 site3 site4 site5 site6 site7 site8 site9 Site 10 Site 11 Site12
site1 0 6 11 10 7 8 9 9 12 12 11 12
site2 6 0 10 10 2 3 4 2 7 8 6 7
site3 11 10 0 6 6 7 8 7 2 3 10 11
site4 10 10 6 0 8 7 6 7 9 6 1 1
site5 7 2 6 8 0 1 2 2 7 6 9 12
site6 8 3 7 7 1 0 1 2 8 8 6 8
site7 9 4 8 6 2 1 0 3 6 6 7 6
site8 9 2 7 7 2 2 3 0 8 7 6 6
site9 12 7 2 9 7 8 6 8 0 1 6 7
site10 12 8 3 6 6 8 6 7 1 0 7 6
site11 11 6 10 1 9 6 7 6 6 7 0 2
site12 12 7 11 1 12 8 6 6 7 6 2 0

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
16
Figure 4 depicts the experimental results that generate the clusters and their respective sites. It is inferred from the figure
that sites 1 and 3 are located in different clusters because the communication costs of the other sites can't match the
communications cost range with them. Moreover, the number of clusters is increased as the communication cost
between sites increased or the communication cost range becomes small.
Figure 4: Clustering telemedicine web sites
4.3. Data Allocation and Replication
Data allocation techniques aim at distributing the database fragments on the web database clusters and their respective
sites. We introduce a heuristic fragment allocation and replication computing service to perform the processes of
fragments allocation in the WTDS. Initially, all fragments are subject for allocation to all clusters that need these
fragments at their sites. If the fragment shows positive allocation decision value (i.e. allocation benefit greater than zero)
for a specific cluster, then the fragment is allocated to this cluster and tested for allocation at each of its sites, otherwise
the fragment is not allocated to this cluster. This fragment is subsequently tested for replication in each cluster of the
WTDS. Accordingly, the fragment that shows positive allocation decision value for any WTDS cluster will be allocated at
that cluster and then tested for allocation at its sites. Consequently, if the fragment shows positive allocation decision
value at any site of cluster that already shows positive allocation decision value, then the fragment is allocated to that
site, otherwise, the fragment is not allocated. This process is repeated for all sites in each cluster that shows positive
allocation decision value. Figure 5 illustrates the structure of our data allocation and replication technique.
In case a fragment shows negative allocation decision value at all clusters, the fragment is allocated to the cluster that
holds the least average communications cost, and then to the site that achieve the least communications cost with other

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
17
sites in the current cluster. In order to better understand the computation of the queries processing cost functions, a
mathematical model will be used to formulate these cost functions.
Figure 5: Data Allocation and Replication Technique
The allocation decision value ADV is computed as the logical result of the comparison between two compound cost
functions components; the cost of allocating the fragment to the cluster and the cost of not allocating the fragment to the
same cluster. The cost of allocating the fragment Fi issued by the transaction Tk to the cluster Cj, denoted as CA(Tk,Fi,Cj), is
defined as the sum of the following sub-costs: retrievals and updates issued by the transaction Tk to the fragment Fi at
cluster Cj, storage occupied by the fragment Fi in the cluster Cj, and remote updates and remote communications sent
from remote clusters. The mathematical model for each sub-cost function is detailed below.
Cost of local retrievals issued by the transaction Tk to the fragment Fi at cluster Cj. This cost is determined by the
frequency and cost of retrievals. The frequency of retrievals represents the average number (≥0) of retrieval
transactions that occur on each fragment at all sites of a certain cluster. The cost of retrievals is the average cost of
retrieval transactions that occur on each fragment at all sites of a specific cluster, which is set by the telemedicine
database system administrator in time units (millisecond, microsecond,…etc.) / byte. The cost of local retrievals is
computed as the multiplication of the average cost of local retrievals for all sites (m) at cluster Cj and the average
frequency of local retrievals issued by the transaction Tk to the fragment Fi for all sites at cluster Cj.
1 1
( , , , ) ( , , , )( , , )
m mk i j q k i j q
k i j
q q
CLR T F C S FREQLR T F C SCLR T F C
m m
(2)
Cost of local updates issued by the transaction Tk to the fragment Fi at cluster Cj. This cost is determined by the
frequency and cost of updates. The frequency of updates is computed as the average number of update transactions
that occur on each fragment at all sites of a certain cluster. The cost of updates is the average cost of update
transactions that occur on each fragment at all sites of a specific cluster, and is determined by the WTDS
administrator in time units per byte. The cost of local updates is computed as the multiplication of the average cost of
Set of telemedicine
database disjoint
fragments
Execute the allocation
technique for one cluster
Repeat allocation
technique for the other clusters
Input Allocation to clusters Allocation to sites
Execute the allocation
technique for sites of the
clusters allocated by fragments

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
18
local updates for all sites (m) at cluster Cj and the average frequency of local updates issued by the transaction Tk to
the fragment Fi for all sites at cluster Cj.
1 1
( , , , ) ( , , , )( , , )
m mk i j q k i j q
k i j
q q
CLU T F C S FREQLU T F C SCLU T F C
m m
(3)
Cost of storage occupied by the fragment Fi in the cluster Cj. This cost is determined by the storage cost and the
fragment size. The storage cost is the cost of storing a data byte at a certain site in a specific cluster. The fragment
size is the storage occupied by the fragment in bytes. The cost of storage is computed as the result of multiplication
of the average storage cost for all sites (m) at cluster Cj occupied by the fragment Fi and the fragment size.
1
( , , , )( , , ) ( , )
mk i j q
k i j size k i
q
SCP T F C SSCP T F C F T F
m
(4)
Cost of remote updates issued by the transaction Tk to the fragment Fi sent from all clusters (n) in the WTDS except
the current cluster Cj. This cost is determined by the cost of local updates and the frequency of remote updates. The
frequency of remote updates is the number of update transactions that occur on each fragment at remote web
clusters in the WTDS. The cost of remote update is the multiplication of average cost of local updates at cluster Cq
and the average frequency of remote updates issued by the Tk to the fragment Fi at each remote cluster in the WTDS.
1, 1,
( , , , )( , , ) ( , , )
n nk i q
k i j k i q
q q j q q j
FREQRU T F C SCRU T F C CLU T F C
m
(5)
Update ratio is used in the evaluation of cost of remote communications and represents the estimated percentage of
update transactions in the web telemedicine database system. It is computed by dividing the number of local update
frequencies in all WTDS sites by the total number of all local retrievals and update frequencies in all sites.
1 1 1
( , , , ) ( , , , ) ( , , , )m m
k i j q k i j q k i j q
q q
m
q
FREQLU T F CUrati S FREQLR T F C S FREQLU T F C So
(6)
Cost of remote communications issued for the transaction Tk to the fragment Fi sent from remote clusters (n) in the
WTDS. This cost defines the required cost needed for updating the fragment from remote clusters. It is computed as
the product of the average cost of remote communication, the average frequency of local update, and update ratio.
1, 1, 1, 1
( , , , ( , )) ( , , , )( , , )
n m mk i q k i j q
k i j ratio
q q j q
CRC T F C S S FREQLU T F C SCRC T F C U
m m
(7)
According to the definition of the cost of allocating fragments, and based on the previous allocation sub-costs, the
mathematical model that represents the cost of fragment allocation to a certain cluster in the WTDS is computed as :

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
19
( , , ) ( , , ) ( , , ) ( , , ) ( , , ) ( , , )k i j k i j k i j k i j k i j k i jCA T F C CLR T F C CLU T F C SCP T F C CRU T F C CRC T F C (8)
To complete the process of ADV computation, the cost of not allocating fragment to a certain cluster (the fragment
retrieved remotely) should be defined and computed. The cost of not allocating the fragment Fi issued by the transaction
Tk to the cluster Cj, denoted CN(Tk,Fi,Cj), is defined as the sum of the following sub-costs: cost of local retrievals issued by
the transaction Tk to the fragment Fi at cluster Cj (computed in equation 2), and the cost of remote retrievals.
Retrieval ratio is used in the evaluation of the cost of remote retrievals and represents the estimated percentage of
retrieval transactions in the WTDS. The retrieval ratio is computed by dividing the number of local retrieval
frequencies in all WTDS sites by the total number of all local retrievals and update frequencies in all WTDS sites.
1 1 1
( , , , ) ( , , , ) ( , , , )m m m
ratio k i j q k i j q k i j q
q q q
R FREQLR T F C S FREQLR T F C S FREQLU T F C S
(9)
Cost of remote retrievals issued by the transaction Tk to the fragment Fi sent from remote clusters (n) in the WTDS.
The cost of remote retrievals is determined by retrieval ratio, retrieval frequency, and communications cost that
represents the communications between all clusters. This cost is computed as the product of the average cost of
communications between all clusters, the average frequency of remote retrieval, and the retrieval ratio.
1 1, 1, 1, 1
( , , , ( , )) ( , , , ))( , , )
n n mk i q k i q
k i j raio
q q q j
CCC T F C S S FREQRR T F C SCRR T F C R
m m
(10)
Based on the previous not allocation sub-costs, the mathematical model that represents the cost of not allocating
fragment to a certain cluster in the WTDS is computed as:
( , , ) ( , , ) ( , , )k i j k i j k i jCN T F C CLR T F C CRR T F C (11)
Accordingly, the allocation decision value ADV determines the allocation status of the fragment at the cluster and its sites.
ADV is computed as a logical value from the comparison between the cost of allocating the fragment to the cluster
CA(Tk,Fi,Cj ) and the cost of not allocating the fragment to the same cluster CN(Tk,Fi,Cj).
( , , ) 1; CN( , , ) ( , , ) and 0; CN( , , ) ( , , )k i j k i j k i j k i j k i jADV T F C T F C CA T F C T F C CA T F C (12)
Therefore, if CN(Tk,Fi,Cj) is greater than or equal to CA(Tk,Fi,Cj), then the allocation status ADV(Tk,Fi,Cj) shows positive
allocation benefit and the fragment is allocated at that cluster, otherwise, CN(Tk,Fi,Cj) is less than CA(Tk,Fi,Cj) where the
allocation status ADV(Tk,Fi,Cj) shows non-positive allocation benefit, so the fragment is not allocated at that cluster. To
formalize the fragment allocation procedures, we developed the allocation and replication algorithm shown in Table 7.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
20
Table 7: Fragments Allocation and Replication Algorithm
Input: T:List of database transactions; F:List of disjoint fragments (section 3.1); C:List of clusters in the WTDS (section 3.2)
Preparation:
Step 1: Set 1 to k
Step 2: Do steps (3-32) until k >T
Step 3: Set 1 to i
Step 4: Do steps (5-30) until i >F
Step 5: Set False to allocation flag
Step 6: Set 1 to j
Step 7: Do steps (8-26) until j >C
Processing:
{Module 1: Computing costs of allocating and costs of not allocating fragment components}
{Module 2: Computing fragment cost of allocation, cost of not allocation, and allocation decision value}
{Module 3: Fragment allocation where negative decision value is achieved}
Output: The List of fragments that are allocated to each web cluster
End.
Module 1: Computing costs of allocating and costs of not allocating fragment components, steps 8-17
{Step 8:initialize Cost of Remote Update to 0; initialize Cost of Remote Communication to 0; initialize Cost of Remote Retrieval to 0
Step 9: Set 1 to y
Step 10: Do steps (11-17) until y >C
Step 11: If y j Then Do steps (12-15); Else Go to step (15)
Step 12: Cost of Remote Update(y) = Cost of Remote Update(y -1) + (Cost of Local Update * Average Frequency of Remote Update)
Step 13: Cost of Remote Communication(y) = Cost of Remote Communication(y -1) +
(Average Cost of Remote Communication * Average Frequency of Local Update * Uratio)
Step 14: Cost of Remote Retrieval(y) = Cost of Remote Retrieval(y -1) +
(Cost of Communication between Clusters * Frequency of Remote Retrieval * Rratio)
Step 15: End If
Step 16: Add 1 to y
Step 17: Loop}
Module 2: Compute fragment cost of allocation, cost of not allocation, and allocation decision value. In this module the total cost of
allocation and total cost of not allocation for each fragment will be computed, as well as the allocation decision value that determine whether the fragment is allocated to or cancelled from the cluster, steps 18-26.
{Step 18: Cost of Allocation = Cost of Local Retrieval + Cost of Local Update + Cost of Storage + Cost of Remote Update + Cost
of Remote Communication
Step 19: Cost of Not allocating = Cost of Local Retrieval + Cost of Remote Retrieval
Step 20: Allocation Decision Value= (Cost of Not allocating >= Cost of Allocation)
Step 21: If Allocation Decision Value = True Then Go to step (22); otherwise; Go to step (23)
Step 22: Allocate the fragment to the current cluster ; Set True to allocation flag; Go to step (24)
Step 23: Cancel the fragment from the current cluster
Step 24: End If
Step 25: Add 1 to j
Step 26: Loop}
Module 3: Fragment allocation where negative decision value is achieved. To maintain data availability, fragments that are not
allocated to any cluster according to their allocation decision value, will be allocated to the cluster with the least communication cost, steps 27-32.
{Step 27: If allocation flag = False Then Allocate the fragment to the cluster who has the least communication cost
Step 28: End If ; Step 29: Add 1 to i
Step 30: Loop
Step 31: Add 1 to k
Step 32: Loop}
Once the fragments are allocated and replicated at the web clusters, then the investigation of the benefit of allocating the
fragments at all sites of each cluster becomes crucial. To get better WTDS performance, fragments should be allocated
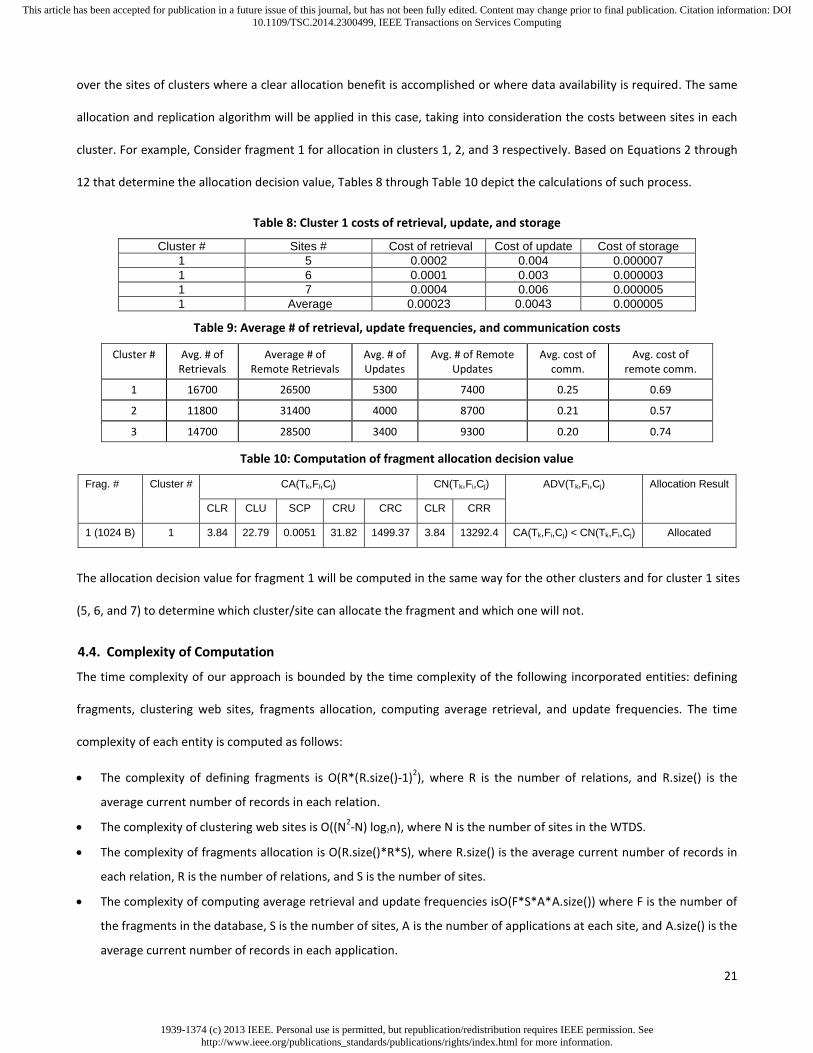
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
21
over the sites of clusters where a clear allocation benefit is accomplished or where data availability is required. The same
allocation and replication algorithm will be applied in this case, taking into consideration the costs between sites in each
cluster. For example, Consider fragment 1 for allocation in clusters 1, 2, and 3 respectively. Based on Equations 2 through
12 that determine the allocation decision value, Tables 8 through Table 10 depict the calculations of such process.
Table 8: Cluster 1 costs of retrieval, update, and storage
Cluster # Sites # Cost of retrieval Cost of update Cost of storage
1 5 0.0002 0.004 0.000007
1 6 0.0001 0.003 0.000003
1 7 0.0004 0.006 0.000005
1 Average 0.00023 0.0043 0.000005
Table 9: Average # of retrieval, update frequencies, and communication costs
Cluster # Avg. # of Retrievals
Average # of Remote Retrievals
Avg. # of Updates
Avg. # of Remote Updates
Avg. cost of comm.
Avg. cost of remote comm.
1 16700 26500 5300 7400 0.25 0.69
2 11800 31400 4000 8700 0.21 0.57
3 14700 28500 3400 9300 0.20 0.74
Table 10: Computation of fragment allocation decision value
Frag. # Cluster # CA(Tk,Fi,Cj) CN(Tk,Fi,Cj) ADV(Tk,Fi,Cj) Allocation Result
CLR CLU SCP CRU CRC CLR CRR
1 (1024 B) 1 3.84 22.79 0.0051 31.82 1499.37 3.84 13292.4 CA(Tk,Fi,Cj) < CN(Tk,Fi,Cj) Allocated
The allocation decision value for fragment 1 will be computed in the same way for the other clusters and for cluster 1 sites
(5, 6, and 7) to determine which cluster/site can allocate the fragment and which one will not.
4.4. Complexity of Computation
The time complexity of our approach is bounded by the time complexity of the following incorporated entities: defining
fragments, clustering web sites, fragments allocation, computing average retrieval, and update frequencies. The time
complexity of each entity is computed as follows:
The complexity of defining fragments is O(R*(R.size()-1)2), where R is the number of relations, and R.size() is the
average current number of records in each relation.
The complexity of clustering web sites is O((N2-N) log2n), where N is the number of sites in the WTDS.
The complexity of fragments allocation is O(R.size()*R*S), where R.size() is the average current number of records in
each relation, R is the number of relations, and S is the number of sites.
The complexity of computing average retrieval and update frequencies isO(F*S*A*A.size()) where F is the number of
the fragments in the database, S is the number of sites, A is the number of applications at each site, and A.size() is the
average current number of records in each application.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
22
Based on the complexity computations of the previous incorporated entities, the time complexity of this approach is
bounded by: O(R*(R.size()-1)2+ O((N
2-N) log2n) + R.size()*R*S + F*S*A*A.size()).
5. Experimental Results and Performance Evaluation
To analyze the behavior of its computing service techniques, we develop an IFCA software tool that is used to validate the
telemedicine database system performance. This tool is not only experimental but it also supports the use of knowledge
extraction and decision making. In this tool, we test the feasibility of the three proposed computing services’ techniques.
The experimental results and the performance evaluation of our approach are discussed in the following sections.
5.1. Evaluation of Fragmentation Service
The internal validity of our fragmentation service technique is tested on multiple relations of a WTDS. We apply the
fragmentation computing service in our IFCA tool on a set of data records obtained from eight different transactions as
(Table 11). Figure 6 depicts the experimental results that generate the disjoint fragments and their respective records.
Table 11: Computation of fragment allocation decision value
Transaction #
Record #
Transaction #
Record #
1 1,2,3,7,9 5 18,17
2 11,18,20 6 7,8,9,10,13,14,15,16
3 1 7 13,16
4 1,…,21 8 18,19
Figure 6: Generating Database fragments
Figure 6 shows that our fragmentation computing service satisfies the optimal solution of data fragmentation in WTDS
and generates the minimum number of fragments for each relation. This helps in reducing the communications cost and
the data records storage, hence improving WTDS performance. We now evaluate the fragmentation performance in
terms of fragments storage size reduction. Let Fperr represent the fragmentation performance percentage of the relation
r, Rdrsr represent the relation data records size generated from the database queries, and Rfsr represent the relation final
fragment data records size, then Fperr is computed as: Fperr = (Rdrsr - Rfsr) / Rdrsr (13)
For example, when the fragmentation is performed for relation 1 on data records sets generated from the database
queries of total size 115 kb and a final number of fragments of a total size 33 kb, then the storage size that will be
considered for this relation is reduced from 115 kb to 33 kb with no data redundancy. This action helps in improving the
system performance by reducing the data storage size of about 71%.
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
23
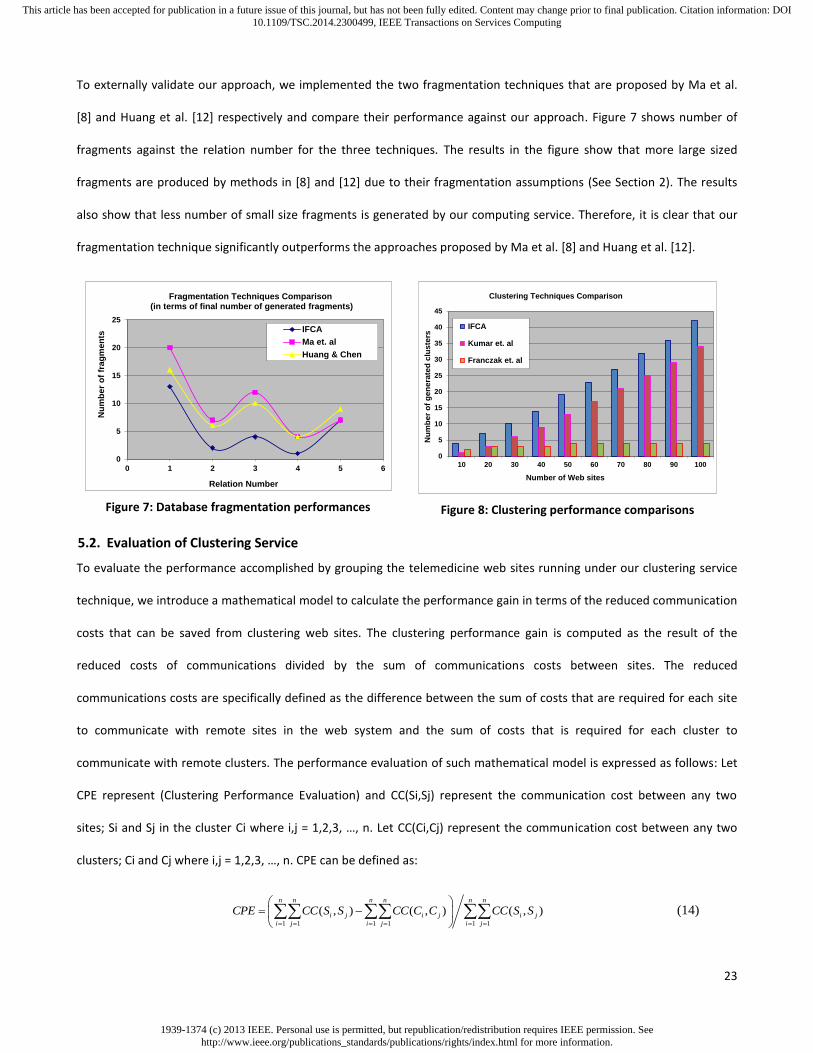
To externally validate our approach, we implemented the two fragmentation techniques that are proposed by Ma et al.
[8] and Huang et al. [12] respectively and compare their performance against our approach. Figure 7 shows number of
fragments against the relation number for the three techniques. The results in the figure show that more large sized
fragments are produced by methods in [8] and [12] due to their fragmentation assumptions (See Section 2). The results
also show that less number of small size fragments is generated by our computing service. Therefore, it is clear that our
fragmentation technique significantly outperforms the approaches proposed by Ma et al. [8] and Huang et al. [12].
Figure 7: Database fragmentation performances
Figure 8: Clustering performance comparisons
5.2. Evaluation of Clustering Service
To evaluate the performance accomplished by grouping the telemedicine web sites running under our clustering service
technique, we introduce a mathematical model to calculate the performance gain in terms of the reduced communication
costs that can be saved from clustering web sites. The clustering performance gain is computed as the result of the
reduced costs of communications divided by the sum of communications costs between sites. The reduced
communications costs are specifically defined as the difference between the sum of costs that are required for each site
to communicate with remote sites in the web system and the sum of costs that is required for each cluster to
communicate with remote clusters. The performance evaluation of such mathematical model is expressed as follows: Let
CPE represent (Clustering Performance Evaluation) and CC(Si,Sj) represent the communication cost between any two
sites; Si and Sj in the cluster Ci where i,j = 1,2,3, …, n. Let CC(Ci,Cj) represent the communication cost between any two
clusters; Ci and Cj where i,j = 1,2,3, …, n. CPE can be defined as:
1 1 1 1 1 1
( , ) ( , ) ( , )n n n n n n
i j i j i j
i j i j i j
CPE CC S S CC C C CC S S
(14)
0
5
10
15
20
25
0 1 2 3 4 5 6
Nu
mb
er
of
fra
gm
en
ts
Relation Number
Fragmentation Techniques Comparison(in terms of final number of generated fragments)
IFCA
Ma et. al
Huang & Chen
0
5
10
15
20
25
30
35
40
45
10 20 30 40 50 60 70 80 90 100
Nu
mb
er
of
gen
era
ted
clu
ste
rs
Number of Web sites
Clustering Techniques Comparison
IFCA
Kumar et. al
Franczak et. al

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
24
For example, consider a telemedicine database system simulated on 10 web sites grouped in 4 clusters, each site
communicates with the other 9 sites, and each cluster communicate with the other 3 clusters taking into consideration
the communications within the cluster itself. For simplicity, we assume the sum of communications costs between sites is
697.5 ms/byte and between clusters is 181.42 ms/byte. By applying CPE (Equation 14), the communications cost is
decreased to 74% of the original communications cost.
To externally validate our clustering service, we implement the clustering techniques by Kumar et al. [13] and Franczak et
al. [15] and compare them with our clustering service in terms of the number of generated clusters against the number of
websites (Figure 8). The results in Figure 8 show that our clustering service generates more clusters for smaller number of
sites; hence it induces less communication costs within the clusters. On the other hand, the other techniques generate
less clusters for large number of sites, thus, they induce more communication costs within the clusters. Figure 8 shows
that the clustering trend increases with the increase in the number of network sites in [13] and ours. In contrast, the
number of clusters generated by the clustering approach in [15] is less due to their clustering approximation function that
uses natural logarithmic function. This in turn results in maximizing the number of sites in each cluster which increases
the communications cost.
5.3. Evaluation of Fragment Allocation Service
To evaluate our fragment allocation computing, we use a set of disjoint fragments obtained from our fragmentation
service, a set of the clusters and their sites generated from our clustering service, and a set of average number of
retrievals and updates at each site (Table 12-a). We apply the fragmentation service in our IFCA software too using the
site costs of storage, retrieval, and update depicted in Table 12-b. the results are shown in Figure 9.
Table 12-a: Fragments retrieval and update frequencies Table 12-b: Costs of storage, retrieval, and update

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
25
We propose the following mathematical model to evaluate the performance of fragment allocation and replication
service. Let IAFS represent the initial size of allocated fragments at site S, n represent the maximum number of sites in the
current cluster, FAFS represent the final size of allocated fragments at site S, and APEC represents the fragment allocation
and replication performance evaluation at cluster C, then APEC is computed as:
n
s
s
n
s
s
n
s
sc IAFSFAFSIAFSAPEC
111
(15)
Figure 9: Fragments allocation at clusters
For example, assume that 35 fragment allocations with a total size of 91 kb are initially allocated to the WTDS clusters.
The final fragment allocation using our approach is 14 with a total size of 27 kb. Therefore, the storage gain of our
allocation technique is about 70% which in turn reduces fragments allocation average computation time. Our proposed
allocation technique is compared with the allocation methods by Ma et al. [8] and Menon et al. [20]. These two
approaches allocate large numbers of fragments to each site and hence consume more storage which in turn increase the
fragments allocation average computation time in each cluster. Figure 10 illustrates the effectiveness of our fragment
allocation and replication technique in terms of average computation time compared to the fragment allocation methods
in [8] and [20]. The figure shows that our fragment allocation and replication technique incurs the least average
computation time required for fragment allocation. This is because our clustering technique produces more clusters of
small number of web sites which reduces the fragment allocation average computation time in each cluster. We Infer
from Figure 8 that the average computation time of fragment allocation increases as the number of web sites in the
cluster increases. Most importantly, the figure shows that that our technique outperforms the ones in [8] and [20].
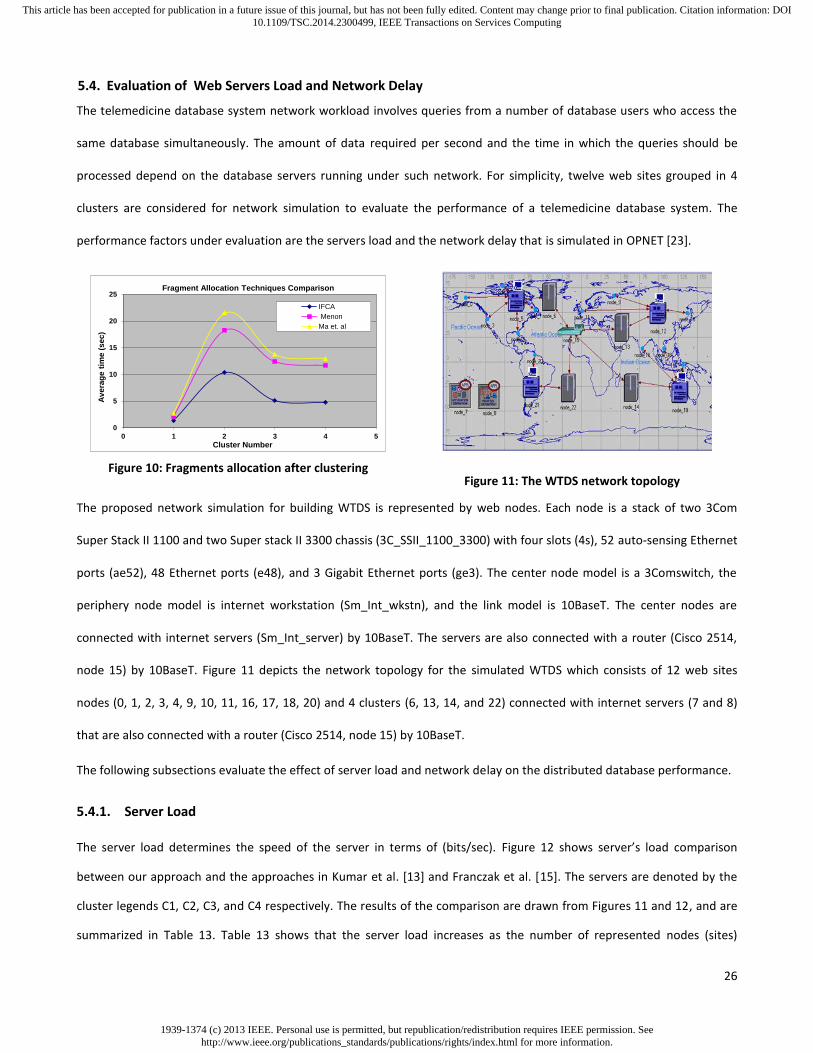
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
26
5.4. Evaluation of Web Servers Load and Network Delay
The telemedicine database system network workload involves queries from a number of database users who access the
same database simultaneously. The amount of data required per second and the time in which the queries should be
processed depend on the database servers running under such network. For simplicity, twelve web sites grouped in 4
clusters are considered for network simulation to evaluate the performance of a telemedicine database system. The
performance factors under evaluation are the servers load and the network delay that is simulated in OPNET [23].
Figure 10: Fragments allocation after clustering
Figure 11: The WTDS network topology
The proposed network simulation for building WTDS is represented by web nodes. Each node is a stack of two 3Com
Super Stack II 1100 and two Super stack II 3300 chassis (3C_SSII_1100_3300) with four slots (4s), 52 auto-sensing Ethernet
ports (ae52), 48 Ethernet ports (e48), and 3 Gigabit Ethernet ports (ge3). The center node model is a 3Comswitch, the
periphery node model is internet workstation (Sm_Int_wkstn), and the link model is 10BaseT. The center nodes are
connected with internet servers (Sm_Int_server) by 10BaseT. The servers are also connected with a router (Cisco 2514,
node 15) by 10BaseT. Figure 11 depicts the network topology for the simulated WTDS which consists of 12 web sites
nodes (0, 1, 2, 3, 4, 9, 10, 11, 16, 17, 18, 20) and 4 clusters (6, 13, 14, and 22) connected with internet servers (7 and 8)
that are also connected with a router (Cisco 2514, node 15) by 10BaseT.
The following subsections evaluate the effect of server load and network delay on the distributed database performance.
5.4.1. Server Load
The server load determines the speed of the server in terms of (bits/sec). Figure 12 shows server’s load comparison
between our approach and the approaches in Kumar et al. [13] and Franczak et al. [15]. The servers are denoted by the
cluster legends C1, C2, C3, and C4 respectively. The results of the comparison are drawn from Figures 11 and 12, and are
summarized in Table 13. Table 13 shows that the server load increases as the number of represented nodes (sites)
0
5
10
15
20
25
0 1 2 3 4 5
Av
era
ge
tim
e (
sec
)
Cluster Number
Fragment Allocation Techniques Comparison
IFCA
Menon
Ma et. al
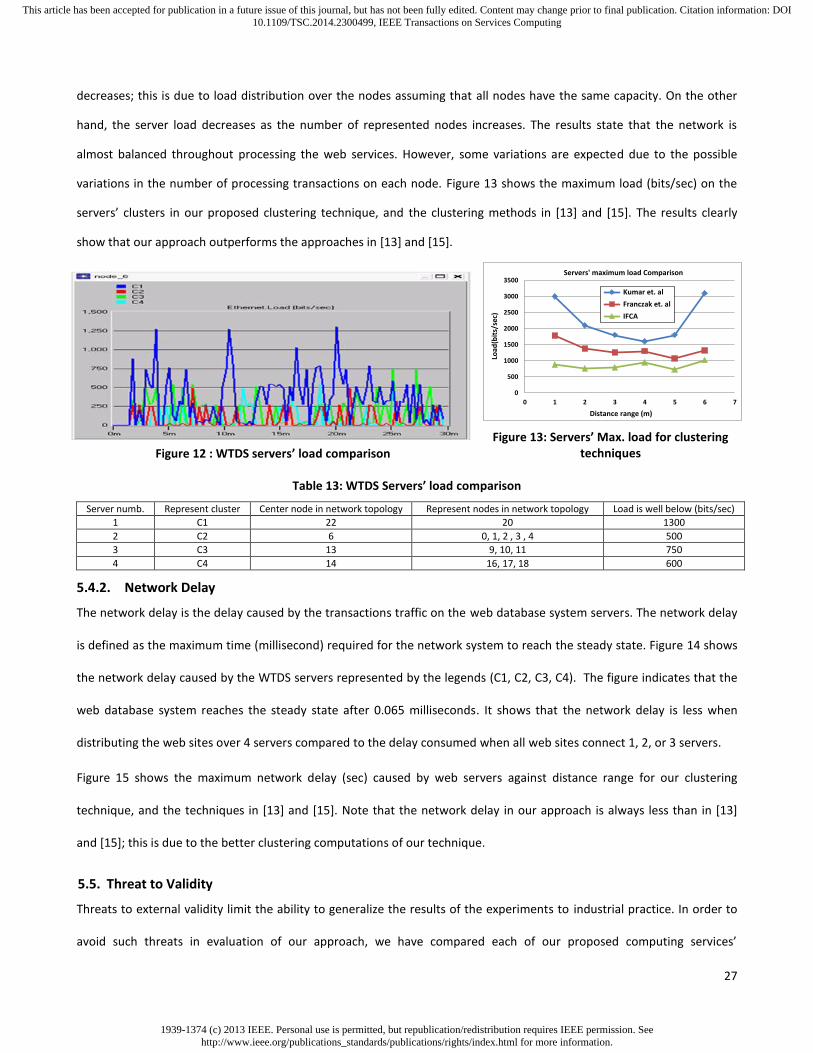
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
27
decreases; this is due to load distribution over the nodes assuming that all nodes have the same capacity. On the other
hand, the server load decreases as the number of represented nodes increases. The results state that the network is
almost balanced throughout processing the web services. However, some variations are expected due to the possible
variations in the number of processing transactions on each node. Figure 13 shows the maximum load (bits/sec) on the
servers’ clusters in our proposed clustering technique, and the clustering methods in [13] and [15]. The results clearly
show that our approach outperforms the approaches in [13] and [15].
Figure 12 : WTDS servers’ load comparison
Figure 13: Servers’ Max. load for clustering techniques
Table 13: WTDS Servers’ load comparison
Server numb. Represent cluster Center node in network topology Represent nodes in network topology Load is well below (bits/sec)
1 C1 22 20 1300
2 C2 6 0, 1, 2 , 3 , 4 500
3 C3 13 9, 10, 11 750
4 C4 14 16, 17, 18 600
5.4.2. Network Delay
The network delay is the delay caused by the transactions traffic on the web database system servers. The network delay
is defined as the maximum time (millisecond) required for the network system to reach the steady state. Figure 14 shows
the network delay caused by the WTDS servers represented by the legends (C1, C2, C3, C4). The figure indicates that the
web database system reaches the steady state after 0.065 milliseconds. It shows that the network delay is less when
distributing the web sites over 4 servers compared to the delay consumed when all web sites connect 1, 2, or 3 servers.
Figure 15 shows the maximum network delay (sec) caused by web servers against distance range for our clustering
technique, and the techniques in [13] and [15]. Note that the network delay in our approach is always less than in [13]
and [15]; this is due to the better clustering computations of our technique.
5.5. Threat to Validity
Threats to external validity limit the ability to generalize the results of the experiments to industrial practice. In order to
avoid such threats in evaluation of our approach, we have compared each of our proposed computing services’
0
500
1000
1500
2000
2500
3000
3500
0 1 2 3 4 5 6 7
Load
(bit
s/se
c)
Distance range (m)
Servers' maximum load Comparison
Kumar et. al
Franczak et. al
IFCA
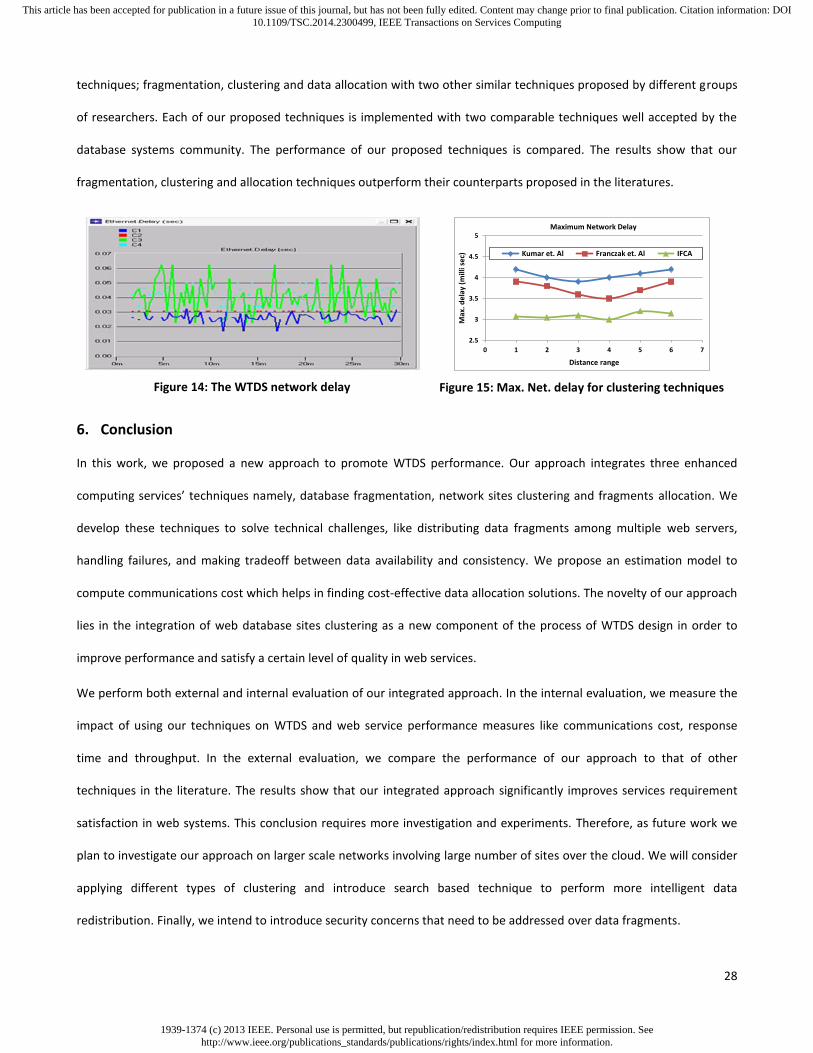
1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
28
techniques; fragmentation, clustering and data allocation with two other similar techniques proposed by different groups
of researchers. Each of our proposed techniques is implemented with two comparable techniques well accepted by the
database systems community. The performance of our proposed techniques is compared. The results show that our
fragmentation, clustering and allocation techniques outperform their counterparts proposed in the literatures.
Figure 14: The WTDS network delay
Figure 15: Max. Net. delay for clustering techniques
6. Conclusion
In this work, we proposed a new approach to promote WTDS performance. Our approach integrates three enhanced
computing services’ techniques namely, database fragmentation, network sites clustering and fragments allocation. We
develop these techniques to solve technical challenges, like distributing data fragments among multiple web servers,
handling failures, and making tradeoff between data availability and consistency. We propose an estimation model to
compute communications cost which helps in finding cost-effective data allocation solutions. The novelty of our approach
lies in the integration of web database sites clustering as a new component of the process of WTDS design in order to
improve performance and satisfy a certain level of quality in web services.
We perform both external and internal evaluation of our integrated approach. In the internal evaluation, we measure the
impact of using our techniques on WTDS and web service performance measures like communications cost, response
time and throughput. In the external evaluation, we compare the performance of our approach to that of other
techniques in the literature. The results show that our integrated approach significantly improves services requirement
satisfaction in web systems. This conclusion requires more investigation and experiments. Therefore, as future work we
plan to investigate our approach on larger scale networks involving large number of sites over the cloud. We will consider
applying different types of clustering and introduce search based technique to perform more intelligent data
redistribution. Finally, we intend to introduce security concerns that need to be addressed over data fragments.
2.5
3
3.5
4
4.5
5
0 1 2 3 4 5 6 7
Max
. de
lay
(mill
i se
c)
Distance range
Maximum Network Delay
Kumar et. Al Franczak et. Al IFCA

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
29
References
[1] Jui-chien Hsieh and Meng-Wei Hsu. “A cloud computing based 12-lead ECG telemedicine service,” BMC Medical Informatics and
Decision Making, 2012. pp 12- 77.
[2] Tamhanka, A. and Ram, S. “Database Fragmentation and Allocation: An Integrated Methodology and Case Study,” IEEE
Transactions on Systems, Man. and Cybernetics-Part A. Systems and Humans. 1998, V. 28(3), pp. 288 – 305.
[3] Borzemski, L. “Optimal Partitioning of a Distributed Relational Database for Multistage Decision-Making Support systems,”
Cybernetics and Systems Research. 1996, V. 2(13), pp. 809-814.
[4] Son, J. and Kim, M. “An Adaptable Vertical Partitioning Method in Distributed Systems,” The Journal of Systems and Software,
2004 V. 73(3), pp. 551 – 561.
[5] Lim, S. and Ng, Y. “Vertical Fragmentation and Allocation in Distributed Deductive Database Systems,” The Journal of Information
Systems, 1997, V. 22(1), pp. 1-24.
[6] Agrawal, S.; Narasayya, V. and Yang, B. “Integrating Vertical and Horizontal Partitioning into Automated Physical Database Design,”
ACM SIGMOD 2004, Paris, France, pp. 359-370.
[7] Navathe, S.; Karlapalem, K. and Minyoung, R. “A mixed fragmentation methodology for initial distributed database design,”
Journal of Computer and Software Engineering. 1995, V. 3(4), pp.395-425.
[8] Ma, H.; Scchewe, K. and Wang, Q. “Distribution design for higher-order data models,” Data and Knowledge Engineering, 2007, V.
60, pp. 400-434.
[9] Yee, W.; Donahoo, M. and Navathe, S. “A Framework for Server Data Fragment Grouping to Improve Server Scalability,”
Intermittently Synchronized Databases – CIKM 2000.
[10] Jain, A.; Murty, M. and Flynn, P. “Data Clustering: A Review,” ACM Computing Surveys. 1999, V. 31(3),pp. 264-323.
[11] Lepakshi Goud. “Achieving Availability, Elasticity and Reliability of the Data Access in Cloud Computing,” International Journal of
Advanced Engineering Sciences and Technologies, Vol. 5(2), 150 -155.
[12] Huang, Y. and Chen, J. “Fragment Allocation in Distributed Database Design,” Journal of Information Science and Engineering,
2001 V. 17, pp. 491-506.
[13] Kumar, P.; Krishna, P.; Bapi, R. and Kumar, S. “Rough Clustering of Sequential Data,” Data and Knowledge Engineering, 2007, V.63,
pp. 183-199.
[14] Voges, K.; Pope, N. and Brown, M. “Cluster Analysis of Marketing Data Examining Online Shopping Orientation: A comparison of
K-means and Rough Clustering Approaches,” H.A. Abbass, R.A. Sarker, C.S. Newton (Eds.), Heuristics and Optimization for
Knowledge Discovery, Idea Group Publishing, Hershey. 2002, pp. 207 – 224.
[15] Fronczak, A.; Holyst, J.; Jedyank, M. and Sienkiewicz, J. “Higher Order Clustering Coefficients,” Barabasi-Albert Networks, Physica
A: Statistical Mechanics and its Applications. 2002, V. 316(1-4), pp. 688-694.
[16] Halkidi, M.; Batistakis, Y. and Vazirgiannis, M. “Clustering algorithms and Validity Measures,” Proceedings of the SSDBM
Conference 2001.
[17] Ishfaq A.; Karlapalem, K. and Kaiso, Y. “Evolutionary Algorithms for Allocating Data in Distributed Database Systems,” Distributed
and Parallel Databases, Kluwer Academic Publishers. 2002, v.11, pp.5-32.
[18] Danilowicz, C. and Nguyen, N. “Consensus Methods for Solving Inconsistency of Replicated Data in Distributed Systems,”
Distributed and Parallel Databases. 2003, V.14, pp. 53-69.
[19] Costa, R. and Lifschitz, S. “Database Allocation Strategies for Parallel BLAST Evaluation on Clusters,” Distributed and Parallel
Databases, 2003, V.13, pp. 99-127.
[20] Menon, S. “Allocating Fragments in Distributed Databases,” IEEE Transactions on Parallel and Distributed Systems, 2005, Vol. 16-7,
pp. 577-585.
[21] Daudpota, N. “Five Steps to Construct a Model of Data Allocation for Distributed Database Systems,” Journal of Intelligent
Information Systems: Integrating Artificial Intelligence and Database Technologies. 1998, V. 11(2), pp.153-68.
[22] Microsoft SQL Server 2012. Available from: <http://www.microsoft.com/sql/editions/express/default.mspx> [Accessed 20th
October, 2012].
[23] MySQL 5.6 available from: <http://www.mysql.com/> [Accessed 21th October, 2013].
[24] OPNET IT Guru Academic, OPNET Technologies, Inc. 2003. Available
from:<http://www.opnet.com/university_program/itguru_academic_edition/> [Accessed 27th August,, 2013]
[25] Hauglid, J.; Ryeng, N. and Norvag, K. “DYFRAM: Dynamic Fragmentation and Replica Management in Distributed Database
Systems,” Distributed and Parallel Databases, 2010, V. 28, pp. 157–185.
[26] Wang, Z.; Li, T.; Xiong, N. and Pan, Y. “A Novel Dynamic Network Data Replication Scheme Based on Historical Access Record and
Proactive Deletion,” Journal of Supercomputing – Springer DOI: 10.1007/s11227-011-0708-z. Published online 19 October 2011.

1939-1374 (c) 2013 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission. Seehttp://www.ieee.org/publications_standards/publications/rights/index.html for more information.
This article has been accepted for publication in a future issue of this journal, but has not been fully edited. Content may change prior to final publication. Citation information: DOI10.1109/TSC.2014.2300499, IEEE Transactions on Services Computing
30
[27] Khan, S. and Ahmad, I. “Replicating Data Objects in Large Distributed Database Systems: An Axiomatic Game Theoretic
Mechanism Design Approach,” Distributed and Parallel Databases, 2010, V. 28(2-3), pp. 187-218.
[28] KhanS, h. and Hoque, L. “A New Technique for Database Fragmentation in Distributed Systems,” International Journal of
Computer Applications V. 5(9), 2010, pp. 20-24.
[29] Jagannatha, S.; Mrunalini, M.; Kumar, T. and Kanth, K. “Modeling of Mixed Fragmentation in Distributed Database Using UML 2.0,”
IPCSIT, V. 2 , 2011, pp. 190 – 194.
[30] Morffi, A.; Gonzalez, C.; Lemahieu, W. and Gonzalez, L. “SIADBDD: An Integrated Tool to Design Distributed Databases,” Revista
Facultad de Ingenieria Universidad de Antioquia ISSN (Version impresa): 0120-6230, No. 47 March, 2009, pp. 155-163.
[31] Özsu, M. T. and Valduriez, P. “Principles of Distributed Databases,” 3rd edition, 2011, Springer, ISBN 978-1-4419-8833-1
[32] Mao, G.; Gao, M. and Yao, W. “An Algorithm for Clustering XML Data Stream Using Sliding Window,” The Third International
Conference on Advances in Databases, Knowledge, and Data Applications, 2011, pp. 96-101.
[33] Paixão, M. P.; Silva, L. and Elias G. “Clustering Large-Scale, Distributed Software Component Repositories,” The Fourth
International Conference on Advances in Databases, Knowledge, and Data Applications, 2012, pp. 124-129.
[34] Decandia, G.; Hastorun, D.; Jampani, M.; Kakulapati, G., Lakshman, A.; Pilchin, A.; Sivasubramanian, S.; Vosshall, P. and Vogels, W.
“Dynamo: Amazon’s Highly Available Key-Value Store,” ACM Symposium on Operating Systems Principles, 2007, pp. 205–220.
[35] http://en.wikipedia.org/wiki/MongoDB. Accessed on 12th November, 2013.
[36] Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W. C.; Wallach, D. A.; Burrows, M.; Chandra, T.; Fikes, A. and Gruber, R. E. “Big
Table: a Distributed Storage System for Structured Data,” Operating Systems Design and Implementation, 2006, pp. 205–218.
Ismail Hababeh holds a PhD degree in Computer Science from Leeds Metropolitan University - U.K.
He also holds a Master degree in Computer Science from Western Michigan University – USA, and a
Bachelor Degree in Computer Science from University of Jordan. Dr. Hababeh research areas of
particular interest include, but are not limited to the following: Distributed Databases, Cloud
Computing, Network Security, and Systems Performance.
Issa Khalil received his B.Sc. and M.S. degrees from Jordan University of Science and Technology in
1994 and 1996, and the PhD degree from Purdue University, USA, in 2007, all in Computer Engineering.
Immediately thereafter, he joined the College of Information Technology (CIT) of the United Arab
Emirates University (UAEU) where he was promoted to associate professor in September 2011. In June
2013 Khalil joined Qatar Computing Research Institute (QCRI) as a senior scientist with the cyber
security group. Khalil's research interests span the areas of wireless and wire-line communication
networks. He is especially interested in security, routing, and performance of wireless Sensor, Ad Hoc
and Mesh networks. Khalil’s recent research interests include malware analysis, advanced persistent
threats, and ICS/SCADA security. Dr. Khalil served as the technical program co-chair of the 6th International Conference
on Innovations in Information Technology, and was appointed as a Technical Program Committee member and reviewer
for many international conferences and journals. In June 2011, Khalil was granted the CIT outstanding professor award for
outstanding performance in research, teaching, and service.
Abdallah Khreishah received his Ph.D. and M.S. degrees in Electrical and Computer Engineering from
Purdue University in 2010 and 2006, respectively. Prior to that, he received his B.S. degree with honors
from Jordan University of Science & Technology in 2004. In Fall 2012, he joined the ECE department of
New Jersey Institute of Technology as an Assistant Professor. His research spans the areas of network
coding, wireless networks, cloud computing, and network security.







