Mo Guo
For CS519
Face Recognition with
Deep Learning

Outline1. Introduction
2. Related works
3. DeepFace
4. Alignment
5. Learning
6. Training
7. Results
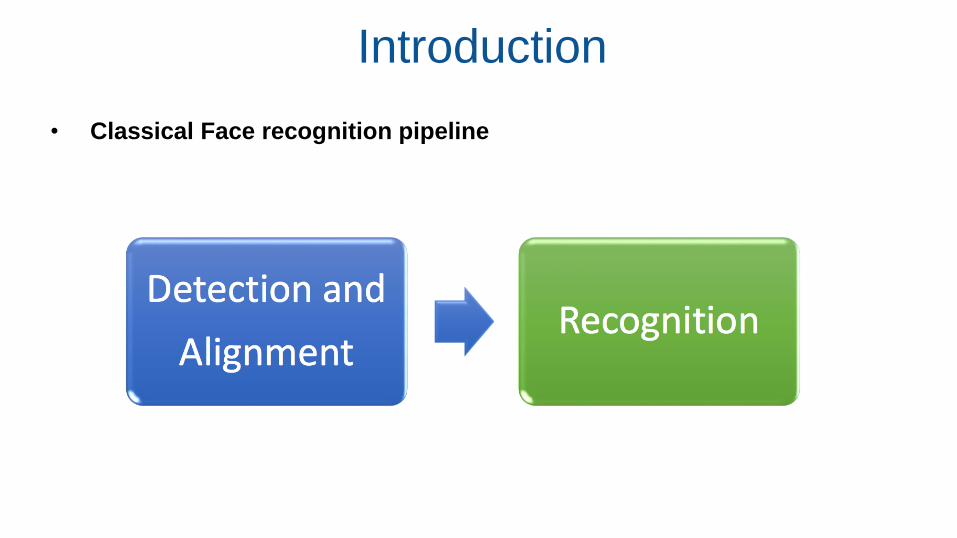
• Classical Face recognition pipeline
Introduction

• Shallow Learning
SIFT, LBP, HOG, etc.Features = handpicked Works well on small datasets but fails on large datasetsAlso ails on illumination variations and facial expressions
Face patterns lie on a complex nonlinear and non‐convex manifold in the high‐dimensional space.
Related Works
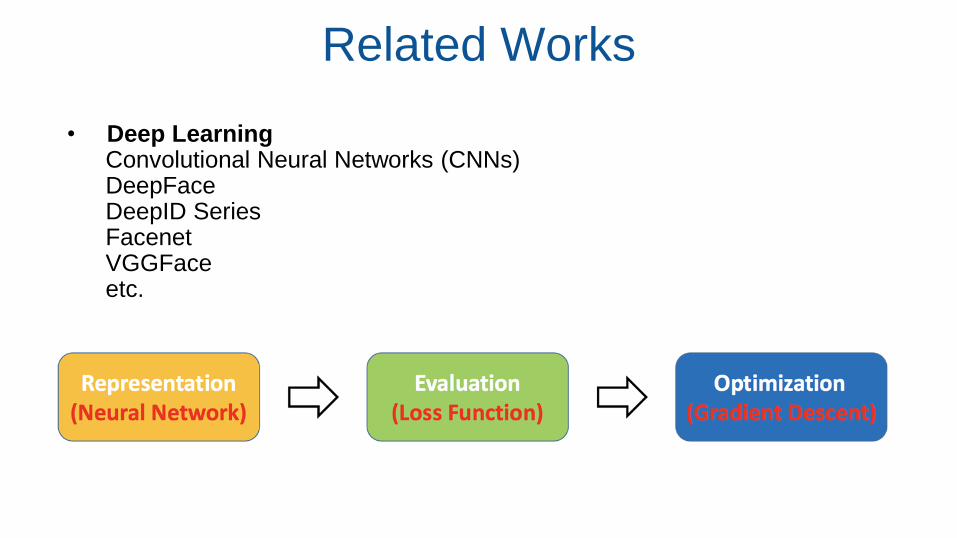
• Deep LearningConvolutional Neural Networks (CNNs)DeepFaceDeepID SeriesFacenetVGGFaceetc.
Related Works

DeepFace (Taigman and Wolf 2014)
2D/3D face modeling and alignment
using affine transformations
9 layer deep neural network
120 million parameters

Alignment(Frontalization)(a) The detected face, with 6 initial fidu- cial points.
(b) The induced 2D-aligned crop.
(c) 67 fiducial points on the 2D-aligned crop with their
corresponding Delaunay triangulation, we added
triangles on the contour to avoid discontinuities.
(d) The reference 3D shape transformed to the 2D-
aligned crop image-plane.
(e) Triangle visibility w.r.t. to the fitted 3D-2D camera;
darker triangles are less visible.
(f) The 67 fiducial points induced by the 3D model that
are used to direct the piece-wise affine warping.
(g) The final frontalized crop.
(h) A new view generated by the 3D model.

Deep Learning
• Input: 3D aligned 3 channel (RGB) face image
152x152 pixels
• 9 layer deep neural network architecture
• Performs softmax for minimizing cross entropy
loss
• Uses SGD(stochastic), Dropout, ReLU
• Outputs k-Class prediction
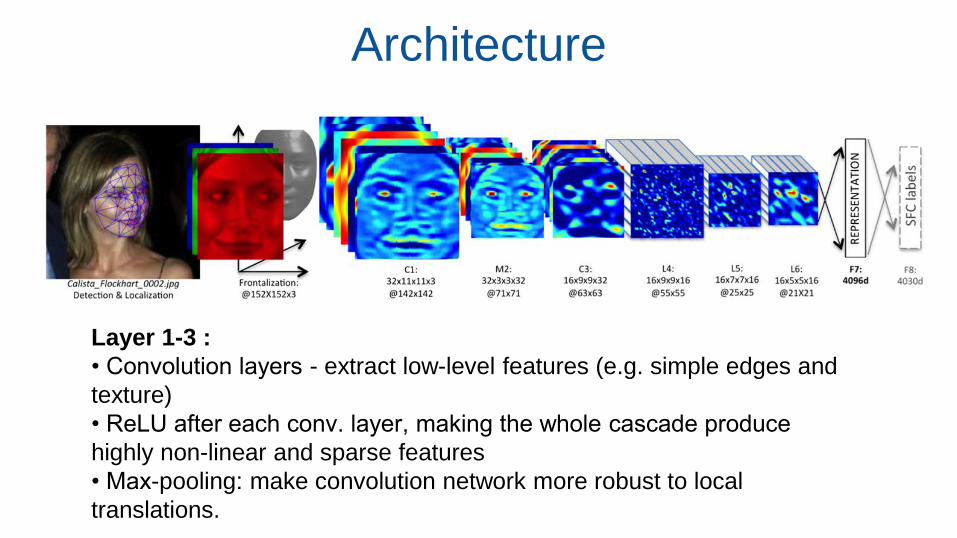
Architecture
Layer 1-3 :
• Convolution layers - extract low-level features (e.g. simple edges and
texture)
• ReLU after each conv. layer, making the whole cascade produce
highly non-linear and sparse features
• Max-pooling: make convolution network more robust to local
translations.
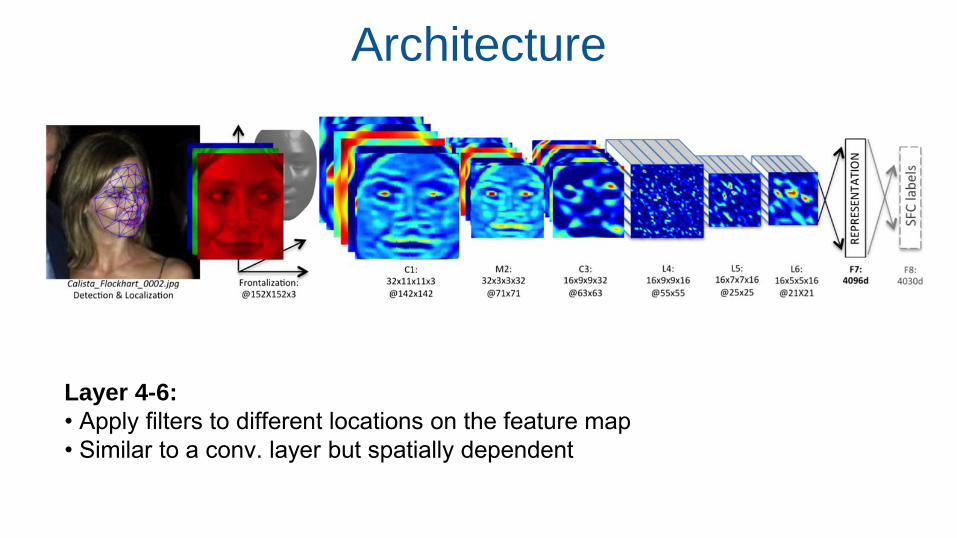
Architecture
Layer 4-6:
• Apply filters to different locations on the feature map
• Similar to a conv. layer but spatially dependent
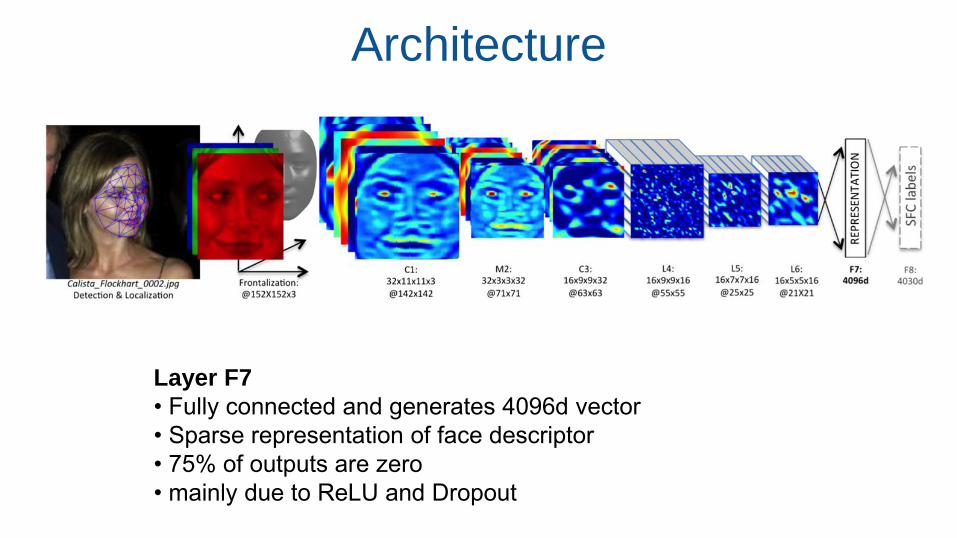
Architecture
Layer F7
• Fully connected and generates 4096d vector
• Sparse representation of face descriptor
• 75% of outputs are zero
• mainly due to ReLU and Dropout
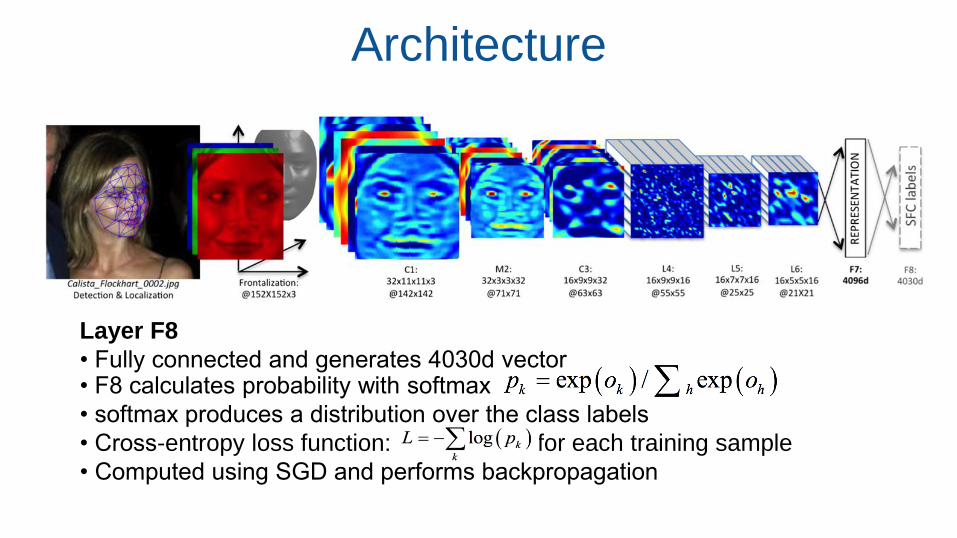
Architecture
• F8 calculates probability with softmax
• softmax produces a distribution over the class labels
• Cross-entropy loss function: for each training sample
• Computed using SGD and performs backpropagation
Layer F8
• Fully connected and generates 4030d vector

Training
• Trained on SFC 4M faces (4030 identities, 800-1200 images per person)
• Focus on Labeled Faces in the Wild (LFW) evaluation
• Used SGD with momentum of 0.9
• Learning rate 0.01 with manual decreasing, final rate was 0.0001
• Random weight initializing
• 15 epochs of training
• 3 days total on a GPU-based engine
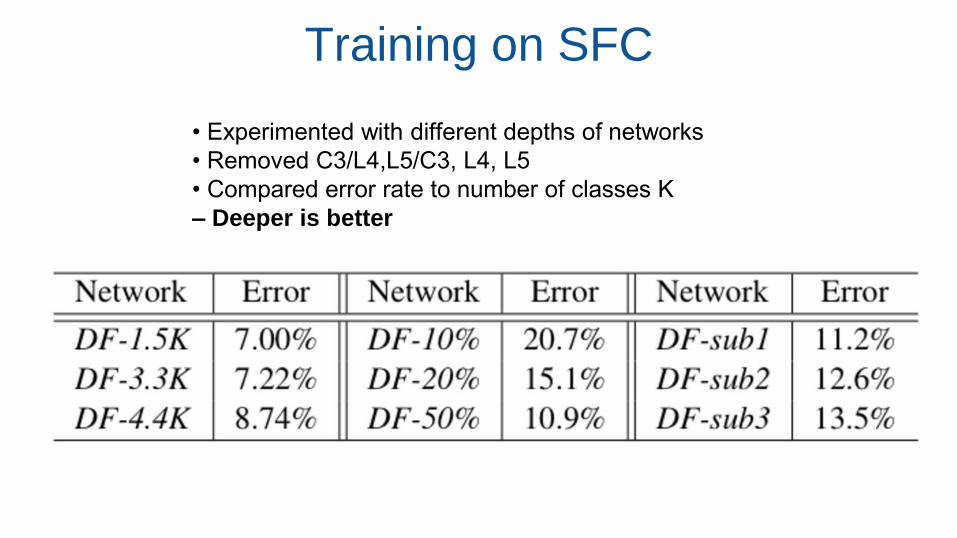
Training on SFC
• Experimented with different depths of networks
• Removed C3/L4,L5/C3, L4, L5
• Compared error rate to number of classes K
– Deeper is better
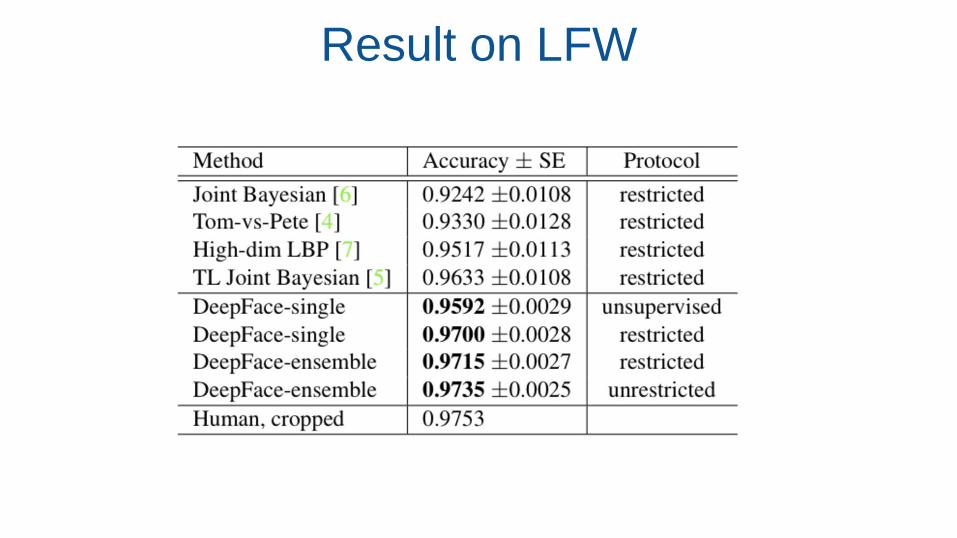
Result on LFW