
File System Design
CS439: Principles of Computer SystemsOctober 31, 2018

Bringing It Together• One of the most important I/O devices is the disk,
which provides stable storage.• But sending information to and retrieving
information from I/O devices is slow– Spinning disks are particularly slow, so the OS tries to
hide latency• Disk head scheduling algorithm• Partitioning
– SSDs are faster, but still slow• And have durability issues!
• File systems make disks usable– Files are named, persistent data– Files also have metadata, stored in the file header

Today’s AdditionsFile System Design– What is a file?
• How are files represented?• How are files organized?
– What is a directory?• How are directories represented?• How are directories organized?
– Finding a File– FFS locality heuristics– NTFS

File Design

Evaluating File Layouts
• Need strong support for small files–Most files are small
• Large file access should be reasonably efficient–Most disk space is consumed by large files
• Limit fragmentation– Both internal and external!
• Allow files to grow• Allow random and sequential access

Contiguous Allocation
• OS maintains an ordered list of free disk blocks• OS allocates a contiguous chunk of free blocks
when it creates a file• The location information in the file header need
only contain the start location and the size• Advantages: simple, what about access time?• Disadvantages: changing file sizes?
fragmentation?

Contiguous AllocationThis slide is a picture. Text description on next slide.
• File header specifies starting block and length• Placement/Allocation policies– First-fit, best-fit, worst-fit
H

Contiguous Allocation:Text Description
• All file data stored contiguously on disk• File header specifies starting block and length • Placement/allocation policies– First-first, best-fit, worst-fit
• Best performance for the initial write of a file– Once space has been allocated– Later writes may cause the file to grow which would
require it to be copied and moved

Linked Allocation
• File stored as a linked list of blocks• In the file header, keep a pointer to the first
and last sector/block allocated to that file• In each sector, keep a pointer to the next
sector• Advantages: fragmentation? file size changes?
efficiently supports which type of access?• Disadvantages: Does not support which type
of access? Why? Access time? Reliability?

Linked AllocationThis slide is a picture. Text description next slide.
• Files stored as a linked list of blocks• File header contains a pointer to the first and last
file blocks• Two implementations• linked list of disk blocks (seen above) • linked list in a table (FAT)
H

Linked Allocation:Text Description
• File stored as a linked list of blocks• File header contains a pointer to the first and
last file blocks– Pointer to last block makes it easier to grow the
file• 2 implementations– Linked list of disk blocks, data blocks point to
other blocks– Linked list in a table (FAT)

Example: FAT File SystemThis slide is a picture. Text description next slide.
File Allocation Table (FAT)– started with MS-DOS (Microsoft, late 70s)
• in FAT-32, supports 228 blocks and files of 232-1 bytes

Example: FAT File SystemText Description
• File allocation table (FAT)
– Started with MS-DOS (Microsoft, late 70s)
– In FAT-32, supports 2 to the 28th blocks and files of 2 to the 32 - 1 bytes
• Parts:
– Index structures - Master File Table (MFT)
• Array of 32 bit entries
• Each element in the array represents a data block in the system
• File represented as an embedded linked list of the entries in the MFT
– File number = index of first FAT entry, and also indicated first data block of file
– That FAT entry will have number of next FAT entry/data block, which will have the next number, etc.
– Free space map
• If data block i is free, then MFT[i] = 0
• Find free blocks by scanning over MTF
– Locality heuristics
• As simple as next fit
– Scan sequentially from last allocated entry and return next free entry
• Can be improved through defragmentation
– Moving file data around so it is stored more contiguously on disk

FAT File SystemThis is a two-column table. Plain text on next slide.
Advantages• Simple!
Disadvantages• Poor random access
– Requires sequential traversal• Limited access control
– No file owner or group ID metadata– Any user can read/write any file
• No support for hard links– Metadata stored in directory entry
• Volume and file size are limited– FAT-32 entry (for example) is limited to 32 bits
• top 4 are reserved• no more than 2^28 blocks in the file system• If 4KB blocks, at most 2 TB volume• File no bigger than 4 GB
• No support for transactional updates (more later)

Direct Allocation
• File header points to each data block• Advantages: Easy to create, grow, and shrink
files, little fragmentation, supports random access
• Disadvantages: File header is big or variably sized
What should we do about large files?
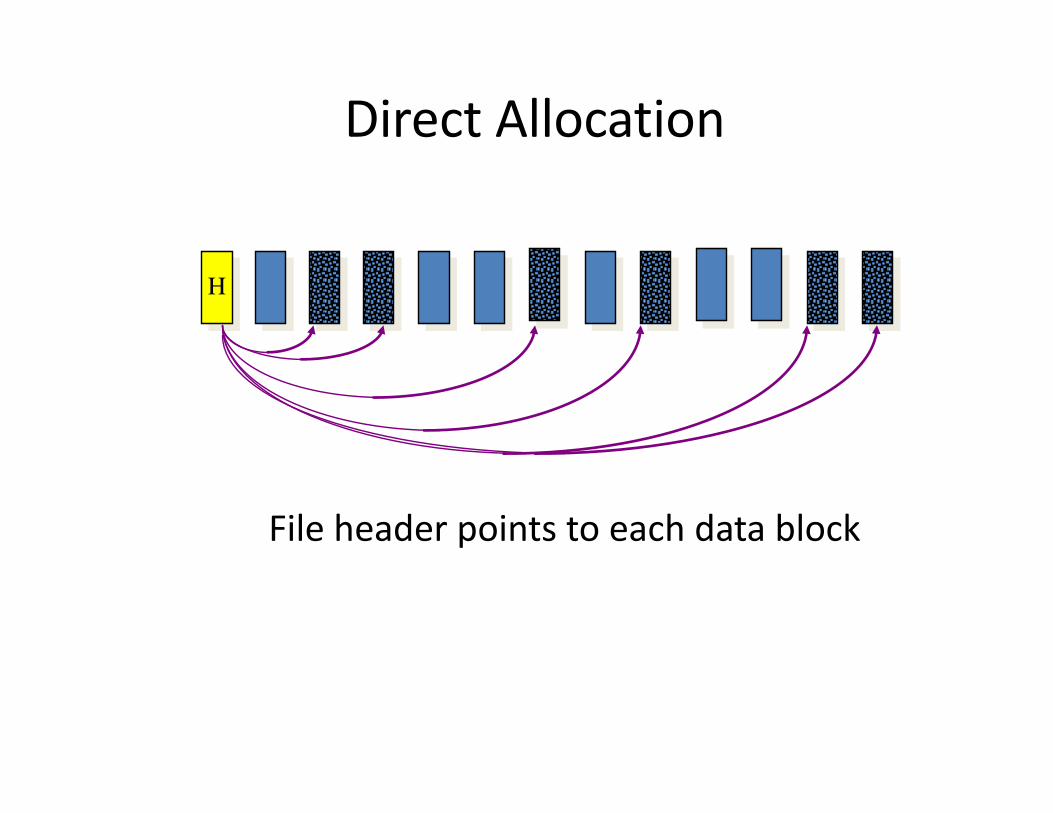
Direct AllocationThis slide is a picture. Text description on next slide.
File header points to each data block
H

Indexed Allocation• OS keeps an array of block pointers for each file in
a non-data block called the index block• OS allocates an array to hold the pointers to all
the blocks when it creates a file, but allocates the blocks only on demand
• OS fills in the pointers as it allocates blocks• Advantages: Supports both types of access, not
much fragmentation• Disadvantages: Maximum file size! Lots of seeks
since data is not contiguous, what about large files?

Indexed AllocationThis slide is a picture. Text description next slide.
• Create a non-data block for each file called the index block– A list of pointers to file blocks– Number based on size of pointer and size of block
• File header contains the index block
IBH

Indexed Allocation:Text Description
• Create a non-data block for each file called the index block (IB)– Contains a list of pointers to file blocks– Number of pointers based on size of pointer and size
of block• File header contains, or has a pointer to, the
index block (but no longer points to data blocks)– So file header has no direct knowledge of where the
file information is on disk

• Linked index blocks (IB+IB+…)
• Multilevel index blocks (IB*IB*…)
Indexed Allocation: Handling Large FilesThis slide is a picture (which I will also draw in class). Text description next slide.
IB IBH IB
IB IBH IBIB

Indexed Allocation: Handling Large FilesText Description
• Linked index blocks (IB + IB + …)– The file header points to an IB, and that IB points
to data blocks and has a pointer to another IB and so on as the file grows
• Multi-level index blocks– Similar in structure to a multi-level page table– The file header points to an IB. This IB only
contains pointers to other IBs, those other IBs are the ones that hold pointers to data blocks
– Can grow in levels to support larger files

iClicker Question
Why would we want to add index blocks to direct allocation?A. Allows greater file sizeB. Faster to create filesC. Simpler to grow filesD. Simpler to prepend and append to files

Multilevel Indexed Files
• Each file is a fixed, asymmetric tree, with fixed size data blocks (e.g. 4KB) as its leaves
• The root of the tree is the file’s inode(UNIX/Linux specific name for file header)– contains file’s metadata– contains a set of pointers• Direct pointers• Indirect pointers of varying levels of indirection

Example: Fast File System
• Implemented by UNIX in the 80s• Each file header contains 13 block pointers.• First 10 pointers point to data blocks• 11th pointer points to a block of 1024 pointers to 1024 more data
blocks (One indirection).• 12th pointer points to a block of pointers to indirect blocks (Two
indirections).• 13th pointer points to a block of pointers to blocks of pointers to
indirect blocks (Three indirections).• Advantages: simple to implement, supports incremental file growth,
small files?• Disadvantages: random access to very large files is inefficient, many
seeks

Fast File System File AllocationMultilevel, indirection, index blocks
This slide is a picture. Text description next slide.
2nd LevelIndirection
Block
nData
Blocks
n3
DataBlocks
3rd LevelIndirection
Block
IB
IB IB
1st LevelIndirection
Block
IB
IB
IB
IB
IB
IB
IB
IB
n2
DataBlocksIB
Inode
10 Data Blocks

Indexed Allocation in UNIX:Text Description
• The inode holds 4 different kinds of pointers in addition to metadata– Direct pointers - point directly to data blocks from inode
• usually the first 10 pointers in the inode– 1st level indirection block
• inode points to 1st IB and it points to data blocks• would hold n data blocks
– 2nd level indirection block• inode points to a block full of pointers to IBs• would hold n^2 data blocks
– 3rd level indirection block• inode points to block full of pointers to 2nd level indirection blocks, and each of
those is full of pointers to IBs• would hold n^3 data blocks
• In total structure holds: 10 + n + n^2 + n^3 blocks

Multilevel Indexed: Key Ideas
• Tree structure– efficient in finding blocks
• Efficient in sequential reads– once an indirect block is read, can read 100s of
data blocks• Fixed structure– simple to implement
• Asymmetric– efficiently supports files big and small

Block vs. Sector
• The OS may choose to use a larger block size than the sector size of the physical disk. (Why?)– Each block consists of consecutive sectors (Why?)– A larger block size increases the transfer efficiency
(Why?)– It may be convenient if the block size matches (a
multiple of) the machine’s page size (Why?)• Most systems allow transferring of many sectors
between interrupts

Example: BigFS• 4KB blocks, 8 byte pointers• An inode stores
• 12 direct pointers• 1 indirect pointer• 1 double indirect pointer• 1 triple indirect pointer• 1 quadruple indirect pointer
Total possible file size = 12*4KB + 512*4KB + 5122*4KB+5123*4KB + 5124*4KB = 256.5 TB

iClicker Question
If my file system only has lots of big video files, what block size do I want?A. LargeB. Small

Movin’ on up… Directories

Directories
• A file that contains a collection of mappings from file name to file number– Those mappings are directory entries<name, file number>
The file number is an inumber (inode number).• Only OS can modify directories– Ensure integrity of mapping– Application programs can read directories
• Directories create a name space for the files

Directory Strategies: Simple and Stupid
One name space for the entire disk.• Use a special area of the disk to hold the
directory• Directory contains <name, index> pairs• If one user uses a name, no one else can

Directory Strategies: Simple User-Based Strategy
• Each user has a separate directory• BUT all of each user’s files must still have
unique names

Directory Strategies:Multi-level Directories
Tree-structured hierarchical name space (all modern OSs)• Store directories on disk, just like files except the file
header for directories has a special flag bit• User programs read directories just like any other file,
but only special system calls can write directories• Each directory contains <name, file number> pairs in
no particular order– The file referred to by <name> may be another directory
• There is one special root directory

A simple UNIX directory entry
This slide is a picture. Text description next slide.

iClicker Question
Every directory has a file header.A. TrueB. False
Given only the inode number (inumber) the OS can find the inode on disk.
A. TrueB. False

How do you find the blocks of a file?
• Find the file header (inode); it contains pointers to file blocks
• To find file header (inode), we need its inumber
• To find inumber, read the directory that contains the file
• To find the directory…• But wait! The directory is a file…

Example: Read file /Users/ans/wisdom.txt
How do we find it?• wisdom.txt is a file• ans/ is a directory that contains the inumber for wisdom.txt– Locate ans/, read directory
• Users/ is a directory that contains the inumber for ans– Locate Users/, read directory
• How do you find the inumber for Users/?– / is a directory that contains the inumber for Users/– In Unix, /’s inumber is 2
• (whew! At least we know how to find that! Or do we? … disk layout up soon!)

How much work was that?How many disk accesses are needed to access file /Users/ans/wisdom.txt?1. Read the inode for / from a fixed location2. Read the first data block for root3. Read the inode for Users/4. Read the first data block for Users/5. Read the inode for ans/6. Read the first data block for ans/7. Read the inode for wisdom.txt8. Read the first data block for wisdom.txt
“You can solve any problem by adding a level of indirection!”

Another Example: Reading a FileThis slide is a picture. Text description next slide.
The steps in looking up /usr/ast/mbox.
Root directory is a file itself and its inode is at a fixed location on disk.

Another Example: Reading a FileText Description
The steps in looking up /usr/ast/mbox on the disk1. Retrieve root directory inode from fixed location on disk2. Retrieve root directory data block from location given in inode.3. Look up usr in root directory data block; its information is in inode 64. Go to inode 6 and determine which block holds the data for /usr
• This is block 1325. Get block 132, the /usr directory data, and lookup ast; its information
is in inode 266. Go to inode 26 and determine which block holds the data for /usr/ast
• This is block 4067. Get block 406, the /usr/ast data, and lookup mbox; its information is in
inode 60• Woot! We have found our email!

Optimize
• Maintain the notion of current working directory (CWD)
• Users can now specify relative file names• OS can cache the data blocks of CWD

File System Layout

File System Metadata and Data
• The superblock has important file system metadata– file system type, number of blocks in the file
system, …• Data: file headers, file data, free space
management, …

File System Layout on DiskThis slide is a picture. Text description on next slide.
Master Boot Record
Contains the addresses of first and last blocks of each partition
Key parameters of the file system: file system type (e.g., FAT), file system size and other administrative info

File System Layout on Disk:Text Description
• Components of the entire disk– MBR - Master Boot Record– Partition table: contains the addresses of first and last blocks of each partition– Disk partitions
• Components of each partition– Boot block– Super block– Free space management– I-nodes– Root directory– Files and directories
• Components of Super Block– File system type (eg FAT)– File system size – Key parameters of system– Other administrative info

Finding Free Space
• Free list!– Linked list of free space (we’ve seen this before!)
• Represent the list of free blocks as a bit vector1111100001111110011101011110011
– one bit for each block on the disk– if bit is 1 then in is allocated, if 0 it is free
• Separate free space data structures for data and metadata– They have special places on the disk

This slide is a picture. Text description next slide

Multilevel Index:Text Description
• Inode array is located at a known location on disk– file number = inode number = index in the array– contains all the inodes in the file system
• Inode contains:– File metadata – A certain number of direct pointers to data blocks
• This example has 12– A pointer to an index block, which contains pointers to data
blocks– A pointer to a double indirect block, which contains pointers to
index blocks– A pointer to a triple indirect block, which contains pointers to
double indirect blocks

FFS Locality Heuristics: Block GroupsThis slide is a picture with text. Plain text version on next slide.
• Divide partition into block groups– Sets of nearby tracks
• Distribute metadata– Old design: free space bitmap and
inode map in a single contiguous region• Lots of seeks when going from reading
metadata to reading data– FFS: distribute free space bitmap and
inode array among block groups• Place file in block group
– When a new file is created, FFS looks for inodes in the same block as the file’s directory
– When a new directory is created, FFS places it in a different block from the parent’s directory
• Place data blocks– First-free heuristics– Trade short-term for long-term locality

FFS Locality Heuristics:File Placement
Slides 29-31 are an animation. Text description found on slide 32.

FFS Locality Heuristics:File Placement
Slides 29-31 are an animation. Text description found on slide 32.

FFS Locality Heuristics:File Placement
Slides 29-31 are an animation. Text description found on slide 32.

FFS Locality Heuristics:Reserved Space
• When a disk is close to full, hard to optimize locality– file may end up scattered through disk
• FFS presents applications with a smaller disk– about 10% smaller– user write that encroaches on reserved space fails

NTFS: Flexible Tree with Extents
Index structure: extents and flexible tree• Extents– Track ranges of contiguous blocks rather than single blocks
• Flexible tree– File represented by variable depth tree
• Large file with few extents can be stored in a shallow tree
– MFT (Master File Table)• Array of 1 KB records holding the trees’ roots• Similar to inode table• Each record stores sequence of variable-sized attribute records
• Microsoft 1993

This slide is a picture. Text description on next slide.

Example of NTFS: Text Description
• Basic file with 2 data extents
• Has a master file table (MFT) that holds all the file headers, which are called MFT records
• MFT record components
– Standard info• File creation time
• Access time
• Owner ID
• Security specifier
• Read-only? Hidden? System?
• File name and number of parent directory
– File name• One file name attribute per hard link
– Information about 2 extents • Start of extent and its length
• Extents contain file data
– May have leftover space

This slide is a picture. Text description on next slide.

Example of NTFS: Text Description
• Small file where data is resident– Resident means the data is stored directly in the
file record• MFT record still has the other information
components– standard info, file name, data and free space
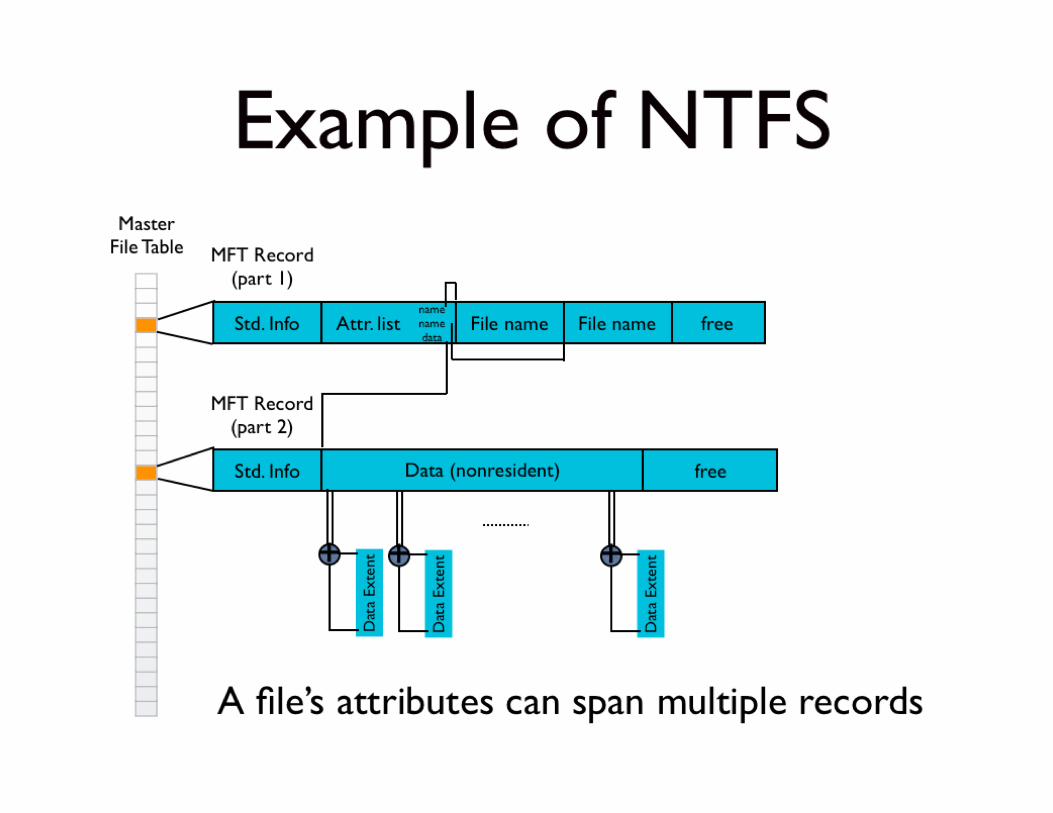
This slide is a picture. Text description next slide.

Example of NTFS: Text Description
• A file’s attributes can span multiple records, if necessary– For this example:• The first record holds an attribute list that points to the
second record• Second record holds the pointers to extents

This slide is a picture. Text description on next slide.

Small, Normal, and Big File NTFS Examples: Text Description
• Small file has data resident in MFT record• Medium (or non-fragmented) file has a single
MFT record with pointers to extents• Large (or badly fragmented) files can span many
MFT records– Each record has a pointers to extents until it is full– Also includes pointer to next record
• And for really huge (or badly fragmented) files, even the attribute list can become nonresident– File can span many many MFT records

NTFS: Metadata Files
• NTFS stores most metadata in ordinary files with well-known numbers– 5 (root directory); 6 (free space bitmap); 8 (list of bad blocks)
• $Secure (file no. 9) – Stores access control list for every file– Indexed by fixed-length key– Files store appropriate key in their MFT record
• $MFT (file no. 0) – Stores Master File Table– To read MFT, need to know first entry of MFT
• a pointer to it stored in first sector of NTFS– MFT can start small and grow dynamically– To avoid fragmentation, NTFS reserves part of start of volume for MFT
expansion

NTFS: Locality Heuristics
Best fit– Finds smallest region large enough to fit file– NTFS caches allocation status for a small area of
disk• Writes that occur together in time get clustered
together– SetEndOfFile() lets users specify expected length
of file at creation

The File System Abstraction (One More Thing)
path: string that identifies a file or directory– absolute (if it starts with “/”, the root directory)– relative (with respect to the current working
directory)

Summary• Directories provide a way to locate each of the files and
map the file number to the human-friendly name• Finding a file from the root node can be expensive, so
the current working directory is cached• On disks, the inode structures and free map are kept in
specific places– But where varies
• Locality heuristics group data to maximize access performance
• NTFS is a different sort of file system, using a flexible tree with extents

Announcements• Project 3 is posted due Friday, 11/16
– Group registration due TODAY!– Design Milestone due Friday– Project 2 must be working
• Except multi-oom• Class performance formula posted to Piazza• Discussion Sections this week! Problem Set 8 is posted.• Exam next week (Wednesday 11/7)
– JGB 2.324 7p-9p– Exam review information will be posted on Thursday
• Instructions for how to get help with any remaining Project 2 tests are posted to Piazza– You must show us your working Project 2 in order to complete the
class







