
GC3: Grid Computing Competence Center
Grid ComputingRiccardo Murri, Sergio MaffiolettiGC3: Grid Computing Competence Center,University of Zurich
Oct. 31, 2012

Grid Computing (the vision)
“A computational grid is a hardware andsoftware infrastructure that providesdependable, consistent, pervasive, andinexpensive access to high-end computationalcapabilities.”
Reference: Foster, I., Kesselman, C., “Computational Grids”, in: “The Grid:
a Blueprint for a New Computing Infrastructure”, Morgan-Kauffman,
1999.
LSCI2012 Grid Computing Oct. 31, 2012

Grid Computing (the vision)
“A computational grid is a hardware andsoftware infrastructure that providesdependable, consistent, pervasive, andinexpensive access to high-end computationalcapabilities.”
Predictable and sustained level of performance.
LSCI2012 Grid Computing Oct. 31, 2012

Grid Computing (the vision)
“A computational grid is a hardware andsoftware infrastructure that providesdependable, consistent, pervasive, andinexpensive access to high-end computationalcapabilities.”
Standardized interfaces/APIs
LSCI2012 Grid Computing Oct. 31, 2012

Grid Computing (the vision)
“A computational grid is a hardware andsoftware infrastructure that providesdependable, consistent, pervasive, andinexpensive access to high-end computationalcapabilities.”
Always available in a large variety of environments.
LSCI2012 Grid Computing Oct. 31, 2012

Grid Computing (the vision)
“A computational grid is a hardware andsoftware infrastructure that providesdependable, consistent, pervasive, andinexpensive access to high-end computationalcapabilities.”
Affordable and convenient(relative to the delivered performance).
LSCI2012 Grid Computing Oct. 31, 2012

HPC vs HTC
High-Performance ComputingMinimize turnaround time of computationalapplications.
High-Throughput ComputingMaximize amount of “work” done in a given time.
LSCI2012 Grid Computing Oct. 31, 2012

HPC vs HTC
Given a fixed set of resources, the two objectives areequivalent.
Fast wide-area networking and cheaper computinghardware (and now even cheaper IaaS provisioning)enable aggregation of geographically distributedcompute resources as HTC facilities.
LSCI2012 Grid Computing Oct. 31, 2012

Grid Computing (the reality)
An aggregation of computational clusters for executionof a large number of batch jobs.
LSCI2012 Grid Computing Oct. 31, 2012

HTC system stakeholders
ownersSet the policy for the usage of a resource
sysadminsTake technical and operational decisions
developers (application writers)Interact with HTC system via its APIs and adaptapplications to its conceptual model.
users (customers)Need applications to work; HTC system must beflexible enough to adapt to their requirements.
LSCI2012 Grid Computing Oct. 31, 2012

Example: the UZH “Schrodinger” cluster
Informatik Dienste UZH
{owner
admin
Research groups
{developers
users
LSCI2012 Grid Computing Oct. 31, 2012
Example: SMSCG
Collaborative projectto share HPC clusters
among higher-educationinstitutions.
http://www.smscg.ch/
LSCI2012 Grid Computing Oct. 31, 2012

Example: SMSCG
ownersParticipating institutions
sysadminsPersonnel of the participating institutions
developersSupport groups (e.g., GC3)
usersResearch groups
LSCI2012 Grid Computing Oct. 31, 2012

Resource Management layers
userRun tasks on the distributed infrastructure;application-level scheduling and resource selection.
grid
– Provide uniform/abstract view of computationalresources and authentication/authorizationcredentials.
– Allocate resources to tasks.
fabricActual execution of tasks and storage of data,according to owner policies.
LSCI2012 Grid Computing Oct. 31, 2012
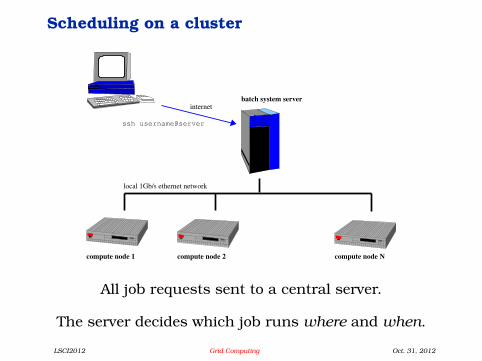
Scheduling on a cluster
compute node N
local 1Gb/s ethernet network
internet
batch system server
compute node 2compute node 1
ssh username@server
����������������
All job requests sent to a central server.
The server decides which job runs where and when.
LSCI2012 Grid Computing Oct. 31, 2012

where: resource allocation model
Computing resources are defined by a structuredset of attributes (key=value pairs).
SGE’s default configuration defines 53 suchattributes: number of available cores/CPUs; total sizeof RAM/swap; current load average; etc.
A node is eligible for running a job iff the nodeattributes are compatible with the job resourcerequirements.
(Other batch systems are similar.)
LSCI2012 Grid Computing Oct. 31, 2012

when: scheduling policy
There are usually more jobs than the system canhandle concurrently. (Even more so, inhigh-throughput computing cases we are interestedin.)
So, job requests must be prioritized.
Prioritization of requests is a matter of the localscheduling policy.
(And this differs greatly among batch systems andamong sites.)
LSCI2012 Grid Computing Oct. 31, 2012

(Hidden) assumptions
1. The scheduling server has complete knowledgeof the nodes
Local networks have low latency (RTT average 0.3 mson a 1GB/s ethernet) and the status information is asmall packet.
2. The server has complete control over the nodes
So a compute node will immediately execute a jobwhen told by the server.
LSCI2012 Grid Computing Oct. 31, 2012

How does this extend to Grid computing?
By definition of a Grid. . .
1. It’s geographically distributed– High-latency links (hence: resource status may be
not up-to-date)
– Network is easily partitioned or nodesdisconnected (hence: resources have a dynamicnature; they may come and go)
2. Resources come from multiple control domains– Prioritization is a matter of local policy!
– AuthZ and other issues may prevent execution atall.
LSCI2012 Grid Computing Oct. 31, 2012
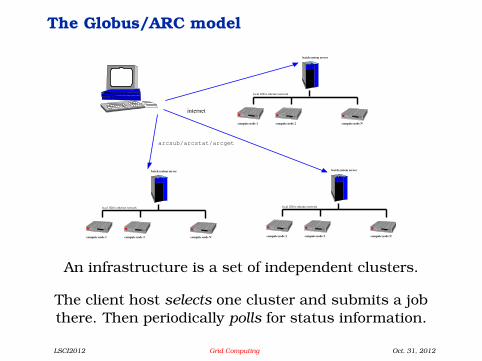
The Globus/ARC model
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1
internet
arcsub/arcstat/arcget
����������������
An infrastructure is a set of independent clusters.
The client host selects one cluster and submits a jobthere. Then periodically polls for status information.
LSCI2012 Grid Computing Oct. 31, 2012

Issues in the Globus/ARC approach?
1. How to select a “good” execution site?
2. How to gather the required information from thesites?
3. Based on the same information, two clients canarrive on the same scheduling information, hencethey can flood a site with jobs.
4. Actual job start times are unpredictable, asscheduling is ultimately a local decision.
5. Client polling increases the load linearly with thenumber of jobs.
LSCI2012 Grid Computing Oct. 31, 2012
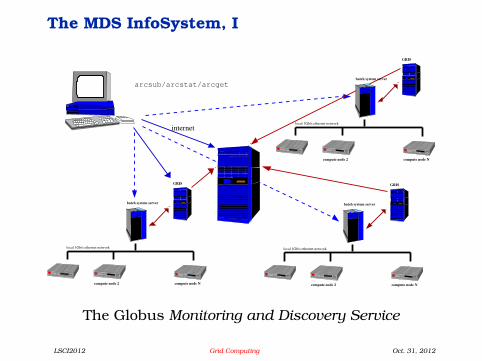
The MDS InfoSystem, I
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2
GRIS
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2
GRIS
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2
GRIS
internet
arcsub/arcstat/arcget
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
����������������������������������������
����������������������������������������
�������������������������
�������������������������
��������������������
����������
����������
���������
���������
���������
���������
����������
����������
����������
����������
��������������������
��������������������
��������������������
��������������������
����������������
The Globus Monitoring and Discovery Service
LSCI2012 Grid Computing Oct. 31, 2012

The MDS InfoSystem, II
A specialized service provides information about sitestatus.
Each site reports its information to a local database(GRIS).
Each GRIS registers with a global indexing service(GIIS).
The client talks with the GIIS to get the list of sites,and then queries each GRIS for the site-specificinformation.
LSCI2012 Grid Computing Oct. 31, 2012

LDAP
The protocol underlying MDS is called LDAP.
LDAP allows remote read/write accesses to adistributed database (“X.500 directory system”), with aflexible authentication and authorization scheme.
LDAP makes the assumptions that most accesses arereads, so LDAP servers are optimized for infrequentwrites.
Reference: A. S. Tanenbaum, “Computer Networks,”
ISBN 978-0-13-212695-3
LSCI2012 Grid Computing Oct. 31, 2012

LDAP schemas
Entries in an LDAP database are sets of key/valuepairs. (Keys need not be unique; equivalently: a keycan map to multiple values.)
An LDAP schema specifies the names of allowed keys,and the type of corresponding values.
Each entry declares a set of schemas it conforms to;every attribute in an LDAP entry must be defined insome schema.
LSCI2012 Grid Computing Oct. 31, 2012

X.500/LDAP Directories
Entries are organized into a tree structure (DIT). (SoLDAP queries return subtrees, as opposed to flat setsof rows as in a RDBMS query.)
Each entry is uniquely identified by a “DistinguishedName” (DN). The DN of an entry is formed byappending a one or more attribute values to theparent entry’s DN.
LDAP accesses might result in referrals, which redirectthe client to access another entry at a remote server.
LSCI2012 Grid Computing Oct. 31, 2012

Example
Example: this is how the ARC MDS representinformation about a cluster queue in LDAP.# all.q, gordias.unige.ch, Switzerland, griddn: nordugrid-queue-name=all.q,nordugrid-cluster-name=gordias.unige.ch,Mds-Vo-name=Switzerland,o=gridobjectClass: MdsobjectClass: nordugrid-queuenordugrid-queue-name: all.qnordugrid-queue-status: activenordugrid-queue-comment: sge default queuenordugrid-queue-homogeneity: TRUEnordugrid-queue-nodecpu: Xeon 2800 MHznordugrid-queue-nodememory: 2048nordugrid-queue-architecture: x86_64nordugrid-queue-opsys: ScientificLinux-5.5nordugrid-queue-totalcpus: 224nordugrid-queue-gridqueued: 0nordugrid-queue-prelrmsqueued: 4nordugrid-queue-gridrunning: 0nordugrid-queue-running: 0nordugrid-queue-maxrunning: 136nordugrid-queue-localqueued: 4
LSCI2012 Grid Computing Oct. 31, 2012

Based on the information in the previous slide,can you decide whether to send a jobthat requires 200GB of scratch space
to this cluster?
LSCI2012 Grid Computing Oct. 31, 2012

The MDS “cluster” model
Exactly: there’s no way to make that decision.
ARC (and Globus) only provideCPU/RAM/architecture information.
In addition, they assume clusters are organized intohomogeneous queues, which might not be the case.
This is just an example of a more general problem:what information do we need of a remote clusterand how to represent it?
Reference: B. Konya, “The ARC Information System”,
http://www.nordugrid.org/documents/arc infosys.pdf
LSCI2012 Grid Computing Oct. 31, 2012

MDS performance
The complete LDAP tree of the SMSCG grid countsover 28000 entries.
A full dump of the SMSCG infosystem tree requiresabout 30 seconds.
So:
1. Information is several seconds old (on average)
2. It does not make sense to refresh informationmore often that this.
By default, ARC refreshes the infosystem every 60seconds.
LSCI2012 Grid Computing Oct. 31, 2012

Supported and unsupported use cases, I
Pre-installed application: OK
The ARC InfoSys has a generic mechanism (“run timeenvironments”) for providing “installed software”information.
So you can select only sites that provide theapplication you want.
(And the information provided in the InfoSys is usuallyenough to make a good guess about the overallperformance.)
LSCI2012 Grid Computing Oct. 31, 2012

Supported and unsupported use cases, II
Java/Python/Ruby/R script
Require brokering based on a large number of supportlibrary/packages: if the dependencies are not there,the program cannot run.
In theory, this solves the issue. In practice: there isalways less information that would be useful, andproviding all the information that would be useful istoo much work.
Ultimately, it relies on convention and “good practice.”
LSCI2012 Grid Computing Oct. 31, 2012

Supported and unsupported use cases, III
Code benchmarking: FAIL
Benchmarking code requires running all cases underthe same conditions.
There is just no way to guarantee that with the“federation of clusters” model: e.g., the site batchscheduler may run two jobs on compute nodes with adifferent CPU.
LSCI2012 Grid Computing Oct. 31, 2012

ARC: Pros and Cons
Pros:
– Very simple to deploy, easy to extend.
– System and code complexity still manageable.
Cons:
– The burden for scaling up is on each site, but notall sites have the required know-how/resources.
– Complexity of managing large collections of jobs ison the client software side.
– Fixed infosystem schema does not accomodatecertain use cases.
LSCI2012 Grid Computing Oct. 31, 2012
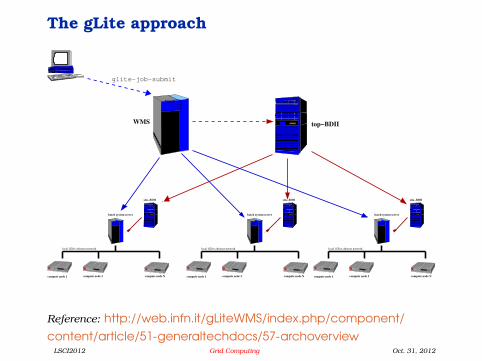
The gLite approach
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1
site−BDII
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1
site−BDII
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1
site−BDII
glite−job−submit
top−BDIIWMS
�����������������������������������
�����������������������������������
����������������
����������������
��������������������
���������
���������
��������
����
���������
���������
��������
����
���������
���������
��������
����
�����������������
�����������������
�����������������
�����������������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
��������
Reference: http://web.infn.it/gLiteWMS/index.php/component/content/article/51-generaltechdocs/57-archoverview
LSCI2012 Grid Computing Oct. 31, 2012

The gLite WMS
Server-centric architecture:
– All jobs are submitted to the WMS server.
– WMS inspects the Grid status, makes thescheduling decision and submits jobs to sites.
– The WMS also monitors jobs as they run, andfetches back the output when a job is done.
– The client polls the WMS, and when a job is donegets the output from the WMS.
LSCI2012 Grid Computing Oct. 31, 2012

The gLite infosystem, I
Hierarchical architecture, based on LDAP:
1. Each “Grid element” runs its own LDAP server(resource BDII) providing information on thesoftware status and capabilities.
2. A site-BDII polls the local element servers, andaggregates information into a site view.
3. A top-BDII polls the site BDIIs and aggregatesinformation into a global view.
Each step requires processing the collected entriesand creating a new LDIF tree based on the newinformation.
LSCI2012 Grid Computing Oct. 31, 2012

The gLite infosystem, II
The CREAM computing element at CSCS has 43entries in its resource BDII. Listing them takes 0.5seconds.
The CSCS site-BDII has 191 entries. Listing themtakes 0.5 seconds.
The CERN top-BDII has > 180 ′000 entries, collectedfrom circa 200 sites. Listing them all takes over 2minutes time.
LSCI2012 Grid Computing Oct. 31, 2012

The GLUE schema
The gLite information system represents systemsstatus based on the GLUE schema. (Version 1.3currently being phased out in favor of v. 2.0)
Comprehensive and complex schema:
1. aimed at interoperability among Grid providers;
2. attempt to cover every feature supported by themajor middlewares and productioninfrastructures (esp. HEP);
3. heavy use of cross-entry references.
Can accomodate the “scratch space” example, butthere’s still no way of figuring out whether (and how) ajob can request 16 cores on the same physical node.
LSCI2012 Grid Computing Oct. 31, 2012

Comparison with ARC’s InfoSystem
ARC stores information about jobs and users in theinfosystem:
– relatively large number of entries in the ARCinfosys
– cannot scale to a large high-throughputinfrastructure
However, gLite’s BDII puts a large load on the top BDII:
– must handle load from all clients
– must be able to poll all site-BDIIs in a fixed time
– so it must cope with network timeouts, slow sites,etc.
LSCI2012 Grid Computing Oct. 31, 2012

gLite WMS: Pros and Cons
Pros:
– Global view of the Grid, could take bettermeta-scheduling decisions.
– Can support aggregate job types (e.g., workflows)
– Aggregates the monitoring operations, so reducesthe load on site.
Cons:
– The WMS is a single point of failure.
– Clients still use a polling mechanism, so the WMSmust sustain the load.
– Extremely complex piece of software, running on asingle machine: very hard to scale up!
– Relies on a infosystem to take sensible decisions(fixed schema/representation problem).
LSCI2012 Grid Computing Oct. 31, 2012
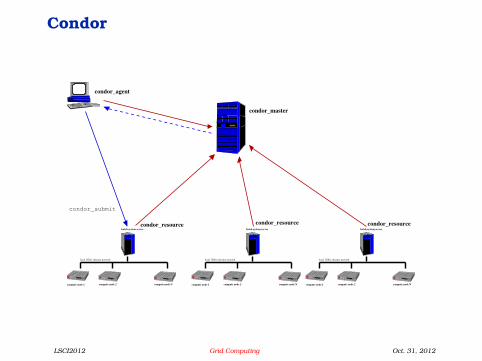
Condor
compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1 compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1 compute node N
local 1Gb/s ethernet network
batch system server
compute node 2compute node 1
condor_master
condor_submit
condor_resourcecondor_resource condor_resource
condor_agent
�����������������������������������
�����������������������������������
����������������
����������������
���������������
���������������
�����������������
�����������������
�����������������
�����������������
��������
LSCI2012 Grid Computing Oct. 31, 2012

Condor overview
Agents (client-side software) and Resources(cluster-side software) advertise their requests andcapabilities to the Condor Master.
The Master performs match-making betweenAgents’ requests and Resources’ offerings.
An Agent sends its computational job directly to thematching Resource (claiming).
Reference: Thain, D., Tannenbaum, T. and Livny, M. (2005):
“Distributed computing in practice: the Condor experience.”
Concurrency and Computation: Practice and Experience,
17:323–356.
LSCI2012 Grid Computing Oct. 31, 2012

Matchmaking
Agents and resources publish “advertisements”:requests and offers using the “ClassAd” format (anenriched key=value format).
No prescribed schema, hence a Resource is free toadvertise any “interesting feature” it has, and torepresent it in any way that fits the key=value model.Similarly, a client may require arbitrary constraints.
LSCI2012 Grid Computing Oct. 31, 2012

Condor: Pros and Cons
Pros:
– Fully-distributed job submission and monitoringsystem.
– Flexible mechanism (schemaless) for specifying jobrequirements and enforcing resource usagepolicies.
– Modular architecture and separate claimingprotocol allow for running many types of“workloads” (e.g., computational jobs, VMs, . . . )
Cons:
– Schemalessness moves correct specification ofrequirements and policies up into theorganizational layer.
LSCI2012 Grid Computing Oct. 31, 2012

All these job management systems are based on apush model (you send the job to an execution cluster).
Is there conversely a pull model?
LSCI2012 Grid Computing Oct. 31, 2012

Scaling issues in the “push” model
– Scheduling entities need to have a comprehensiveview of the system.
– Information needs frequent updates.
– No complete information on local schedulingpolicies.
– The meta-scheduler is another scheduling layer ontop of local cluster scheduling.
LSCI2012 Grid Computing Oct. 31, 2012

Condor glide-ins
Idea: run Condor daemons as regular grid/batch jobsand build a “personal resource pool”
out of allocated job slots.
LSCI2012 Grid Computing Oct. 31, 2012

Condor glide-ins
Idea: run Condor daemons as regular grid/batch jobsand build a “personal resource pool”
out of allocated job slots.
1. User starts a “personal” Condor match-makingdaemon
2. User submits Condor condor resource servers asbatch job to foreign systems.
3. As submitted resource daemons are started, theycontact back the “personal” Condor master andform a resource pool.
4. User can now run jobs through the “personal”Condor pool.
LSCI2012 Grid Computing Oct. 31, 2012
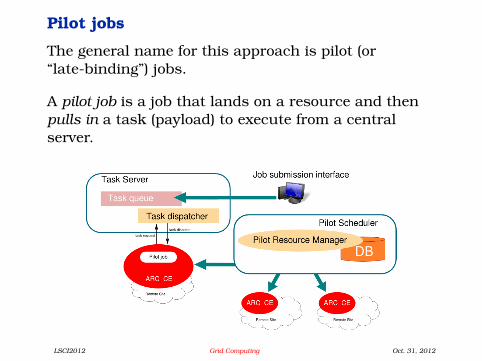
Pilot jobs
The general name for this approach is pilot (or“late-binding”) jobs.
A pilot job is a job that lands on a resource and thenpulls in a task (payload) to execute from a centralserver.
LSCI2012 Grid Computing Oct. 31, 2012

Advantages of late binding
Information about the execution node can be gatheredat the moment the pilot job starts execution.
– More accurate description: can look for neededfeatures (e.g., installed software/libraries)
– Hence, no need for an information system.
– Load balancing done according to local systemresponsiveness.
Easier failure handling: if a pilot job fails, assign sametask to another pilot.
– Users only need to monitor the task success ratio!
LSCI2012 Grid Computing Oct. 31, 2012

Disadvantages
Outbound network connectivity required.
Heterogeneous workload (e.g., mixture of parallel andsequential tasks) leads to combinatorial explosion ofthe number of submitted jobs.
Multi-user pilot job frameworks introduce another(possibly opaque) step in the traceability chain.
LSCI2012 Grid Computing Oct. 31, 2012

References, I
– Foster, I. (2002): “What is the Grid? A Three PointChecklist.”, Grid Today, July 20, 2002http://dlib.cs.odu.edu/WhatIsTheGrid.pdf
– Thain, D., Tannenbaum, T. and Livny, M. (2005):“Distributed computing in practice: the Condorexperience.” Concurrency and Computation:Practice and Experience, 17: 323–356.DOI: 10.1002/cpe.938
– Livny, M., Raman, R., “High-Throughput ResourceManagement”, in: Foster, I. and Kesselman, C.(eds.) “The Grid: Blueprint for a New ComputingInfrastructure”, Morgan-Kauffman, 1999.
LSCI2012 Grid Computing Oct. 31, 2012

References, II
– Konya, B. (2010): “The ARC Information System”,http://www.nordugrid.org/documents/arc infosys.pdf
– Cecchi, M. et al. (2009): “The gLite WorkloadManagement System”, Lecture Notes in ComputerScience, 5529/2009, pp. 256–268.
– Andreozzi, S. et al. (2009): “GLUE Specificationv. 2.0”, http://www.ogf.org/documents/GFD.147.pdf
LSCI2012 Grid Computing Oct. 31, 2012







