
High-Performance MPI and Deep Learning on OpenPOWER Platform
Talk at OpenPOWER SUMMIT (Mar ‘18)
by
Dhabaleswar K. (DK) Panda
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~panda
Hari Subramoni
The Ohio State University
E-mail: [email protected]
http://www.cse.ohio-state.edu/~subramon

OpenPOWER Summit (Mar ’18) 2Network Based Computing Laboratory
Big Data (Hadoop, Spark,
HBase, Memcached,
etc.)
Deep Learning(Caffe, TensorFlow, BigDL,
etc.)
HPC (MPI, RDMA, Lustre, etc.)
Increasing Usage of HPC, Big Data and Deep Learning
Convergence of HPC, Big Data, and Deep Learning!
Increasing Need to Run these applications on the Cloud!!

OpenPOWER Summit (Mar ’18) 3Network Based Computing Laboratory
Parallel Programming Models Overview
P1 P2 P3
Shared Memory
P1 P2 P3
Memory Memory Memory
P1 P2 P3
Memory Memory MemoryLogical shared memory
Shared Memory Model
SHMEM, DSMDistributed Memory Model
MPI (Message Passing Interface)
Partitioned Global Address Space (PGAS)
Global Arrays, UPC, Chapel, X10, CAF, …
• Programming models provide abstract machine models
• Models can be mapped on different types of systems– e.g. Distributed Shared Memory (DSM), MPI within a node, etc.
• PGAS models and Hybrid MPI+PGAS models are gradually receiving importance

OpenPOWER Summit (Mar ’18) 4Network Based Computing Laboratory
Partitioned Global Address Space (PGAS) Models• Key features
- Simple shared memory abstractions
- Light weight one-sided communication
- Easier to express irregular communication
• Different approaches to PGAS- Languages
• Unified Parallel C (UPC)
• Co-Array Fortran (CAF)
• X10
• Chapel
- Libraries• OpenSHMEM
• UPC++
• Global Arrays

OpenPOWER Summit (Mar ’18) 5Network Based Computing Laboratory
Hybrid (MPI+PGAS) Programming
• Application sub-kernels can be re-written in MPI/PGAS based on communication characteristics
• Benefits:– Best of Distributed Computing Model
– Best of Shared Memory Computing Model
Kernel 1MPI
Kernel 2MPI
Kernel 3MPI
Kernel NMPI
HPC Application
Kernel 2PGAS
Kernel NPGAS

OpenPOWER Summit (Mar ’18) 6Network Based Computing Laboratory
Supporting Programming Models for Multi-Petaflop and Exaflop Systems: Challenges
Programming ModelsMPI, PGAS (UPC, Global Arrays, OpenSHMEM), CUDA, OpenMP,
OpenACC, Cilk, Hadoop (MapReduce), Spark (RDD, DAG), etc.
Application Kernels/Applications
Networking Technologies(InfiniBand, 40/100GigE,
Aries, and Omni-Path)
Multi-/Many-coreArchitectures
Accelerators(GPU and FPGA)
MiddlewareCo-Design
Opportunities and
Challenges across Various
Layers
PerformanceScalabilityResilience
Communication Library or Runtime for Programming ModelsPoint-to-point
CommunicationCollective
CommunicationEnergy-
AwarenessSynchronization
and LocksI/O and
File SystemsFault
Tolerance

OpenPOWER Summit (Mar ’18) 7Network Based Computing Laboratory
• Message Passing Interface (MPI) Support
• Support for PGAS and MPI + PGAS (OpenSHMEM, UPC)
• Exploiting Accelerators (NVIDIA GPGPUs)
• Support for Deep Learning
MPI, PGAS and Deep Learning Support for OpenPOWER
Support for Big Data (Hadoop and Spark) on OpenPOWER (Talk at 2:15 pm)

OpenPOWER Summit (Mar ’18) 8Network Based Computing Laboratory
Overview of the MVAPICH2 Project• High Performance open-source MPI Library for InfiniBand, Omni-Path, Ethernet/iWARP, and RDMA over Converged Ethernet (RoCE)
– MVAPICH (MPI-1), MVAPICH2 (MPI-2.2 and MPI-3.1), Started in 2001, First version available in 2002
– MVAPICH2-X (MPI + PGAS), Available since 2011
– Support for GPGPUs (MVAPICH2-GDR) and MIC (MVAPICH2-MIC), Available since 2014
– Support for Virtualization (MVAPICH2-Virt), Available since 2015
– Support for Energy-Awareness (MVAPICH2-EA), Available since 2015
– Support for InfiniBand Network Analysis and Monitoring (OSU INAM) since 2015
– Used by more than 2,875 organizations in 85 countries
– More than 455,000 (> 0.45 million) downloads from the OSU site directly
– Empowering many TOP500 clusters (Nov ‘17 ranking)• 1st, 10,649,600-core (Sunway TaihuLight) at National Supercomputing Center in Wuxi, China
• 9th, 556,104 cores (Oakforest-PACS) in Japan
• 12th, 368,928-core (Stampede2) at TACC
• 17th, 241,108-core (Pleiades) at NASA
• 48th, 76,032-core (Tsubame 2.5) at Tokyo Institute of Technology
– Available with software stacks of many vendors, Linux Distros (RedHat and SuSE), and OpenHPC
– http://mvapich.cse.ohio-state.edu
• Empowering Top500 systems for over a decade

OpenPOWER Summit (Mar ’18) 9Network Based Computing Laboratory
MVAPICH2 Software Family High-Performance Parallel Programming Libraries
MVAPICH2 Support for InfiniBand, Omni-Path, Ethernet/iWARP, and RoCE
MVAPICH2-X Advanced MPI features, OSU INAM, PGAS (OpenSHMEM, UPC, UPC++, and CAF), and MPI+PGAS programming models with unified communication runtime
MVAPICH2-GDR Optimized MPI for clusters with NVIDIA GPUs
MVAPICH2-Virt High-performance and scalable MPI for hypervisor and container based HPC cloud
MVAPICH2-EA Energy aware and High-performance MPI
MVAPICH2-MIC Optimized MPI for clusters with Intel KNC (being updated with KNL-based designs)
Microbenchmarks
OMB Microbenchmarks suite to evaluate MPI and PGAS (OpenSHMEM, UPC, and UPC++) libraries for CPUs and GPUs
Tools
OSU INAM Network monitoring, profiling, and analysis for clusters with MPI and scheduler integration
OEMT Utility to measure the energy consumption of MPI applications

OpenPOWER Summit (Mar ’18) 10Network Based Computing Laboratory
0
50000
100000
150000
200000
250000
300000
350000
400000
450000
500000Se
p-04
Feb-
05
Jul-0
5
Dec-
05
May
-06
Oct
-06
Mar
-07
Aug-
07
Jan-
08
Jun-
08
Nov
-08
Apr-
09
Sep-
09
Feb-
10
Jul-1
0
Dec-
10
May
-11
Oct
-11
Mar
-12
Aug-
12
Jan-
13
Jun-
13
Nov
-13
Apr-
14
Sep-
14
Feb-
15
Jul-1
5
Dec-
15
May
-16
Oct
-16
Mar
-17
Aug-
17
Jan-
18
Num
ber o
f Dow
nloa
ds
Timeline
MV
0.9.
4
MV2
0.9
.0
MV2
0.9
.8
MV2
1.0
MV
1.0
MV2
1.0.
3
MV
1.1
MV2
1.4
MV2
1.5
MV2
1.6
MV2
1.7
MV2
1.8
MV2
1.9
MV2
-GDR
2.0
b
MV2
-MIC
2.0
MV2
-GDR
2.3
aM
V2-X
2.3b
MV2
Virt
2.2
MV2
2.3
rc1
OSU
INAM
0.9
.3
MVAPICH2 Release Timeline and Downloads

OpenPOWER Summit (Mar ’18) 11Network Based Computing Laboratory
Architecture of MVAPICH2 Software Family
High Performance Parallel Programming Models
Message Passing Interface(MPI)
PGAS(UPC, OpenSHMEM, CAF, UPC++)
Hybrid --- MPI + X(MPI + PGAS + OpenMP/Cilk)
High Performance and Scalable Communication RuntimeDiverse APIs and Mechanisms
Point-to-point
Primitives
Collectives Algorithms
Energy-Awareness
Remote Memory Access
I/O andFile Systems
FaultTolerance
Virtualization Active Messages
Job StartupIntrospection
& Analysis
Support for Modern Networking Technology(InfiniBand, iWARP, RoCE, Omni-Path)
Support for Modern Multi-/Many-core Architectures(Intel-Xeon, OpenPOWER, Xeon-Phi, ARM, NVIDIA GPGPU)
Transport Protocols Modern Features
RC XRC UD DC UMR ODPSR-IOV
Multi Rail
Transport MechanismsShared
MemoryCMA IVSHMEM
Modern Features
MCDRAM* NVLink CAPI*
* Upcoming
XPMEM*

OpenPOWER Summit (Mar ’18) 12Network Based Computing Laboratory
• MVAPICH2 – Basic MPI support
• since MVAPICH2 2.2rc1 (March 2016)
• MVAPICH2-X– PGAS (OpenSHMEM and UPC) and Hybrid MPI+PGAS support
• since MVAPICH2-X 2.2b (March 2016)
– Advanced Collective Support with CMA• Since MVAPICH2-X 2.3b (Oct 2017)
• MVAPICH2-GDR – NVIDIA GPGPU support with NVLink (CORAL like systems)
• Since MVAPICH2-GDR 2.3a (Nov 2017)
OpenPOWER Platform Support in MVAPICH2 Libraries

OpenPOWER Summit (Mar ’18) 13Network Based Computing Laboratory
• Message Passing Interface (MPI) Support– Point-to-point Inter-node and Intra-node
– CMA-based Collectives
– Upcoming XPMEM Support
• Support for PGAS and MPI + PGAS (OpenSHMEM, UPC)
• Exploiting Accelerators (NVIDIA GPGPUs)
• Support for Deep Learning
MPI, PGAS and Deep Learning Support for OpenPOWER

OpenPOWER Summit (Mar ’18) 14Network Based Computing Laboratory
0
0.5
1
1.5
0 1 2 4 8 16 32 64 128 256 512 1K 2K
Late
ncy
(us)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0
Intra-node Point-to-Point Performance on OpenPower
Platform: Two nodes of OpenPOWER (Power8-ppc64le) CPU using Mellanox EDR (MT4115) HCA
Intra-Socket Small Message Latency Intra-Socket Large Message Latency
Intra-Socket Bi-directional BandwidthIntra-Socket Bandwidth
0.30us0
20
40
60
80
4K 8K 16K 32K 64K 128K 256K 512K 1M 2M
Late
ncy
(us)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0
0
10000
20000
30000
40000
1 8 64 512 4K 32K 256K 2M
Band
wid
th (M
B/s)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0
0
20000
40000
60000
80000
1 8 64 512 4K 32K 256K 2M
Band
wid
th (M
B/s)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0

OpenPOWER Summit (Mar ’18) 15Network Based Computing Laboratory
0
1
2
3
4
0 1 2 4 8 16 32 64 128 256 512 1K 2K
Late
ncy
(us)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0
Inter-node Point-to-Point Performance on OpenPower
Platform: Two nodes of OpenPOWER (Power8-ppc64le) CPU using Mellanox EDR (MT4115) HCA
Small Message Latency Large Message Latency
Bi-directional BandwidthBandwidth
0
50
100
150
200
4K 8K 16K 32K 64K 128K 256K 512K 1M 2M
Late
ncy
(us)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0
0
5000
10000
15000
1 8 64 512 4K 32K 256K 2M
Band
wid
th (M
B/s)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0
0
10000
20000
30000
1 8 64 512 4K 32K 256K 2M
Band
wid
th (M
B/s)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0.2OpenMPI-3.0.0

OpenPOWER Summit (Mar ’18) 16Network Based Computing Laboratory
0
1
2
0 1 2 4 8 16 32 64 128 256 512
Mul
ti-pa
ir La
tenc
y (u
s)MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
Multi-Pair Latency ComparisonIn
tra-
node
(PPN
=20)
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=bunch
• Basic point-to-point multi-pair latency comparison– Up to 48% and 45% performance improvement over Spectrum MPI and OpenMPI for intra-/inter-node
0
2
4
6
0 1 2 4 8 16 32 64 128 256 512
Mul
ti-pa
ir La
tenc
y (u
s)
Message Size
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
Inte
r-no
de
(Nod
es=2
, PPN
=20)
0
100
200
300
400
500
0 2 8 32 128
512 2K 8K 32K
128K
512K 2M
Mul
ti-pa
ir La
tenc
y (u
s)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
0
1000
2000
3000
4000
1K 2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M
Mul
ti-pa
ir La
tenc
y (u
s)
Message Size
MV2-2.3rc1
SpectrumMPI-10.1.0
OpenMPI-3.0.0
MV2-XPMEM
48%
45%
40%
32%
45%
OpenPOWER Summit (Mar ’18) 17Network Based Computing Laboratory
0
5000
10000
15000
Band
wid
th (M
B/s)
Message Size
MV2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MV2-XPMEM
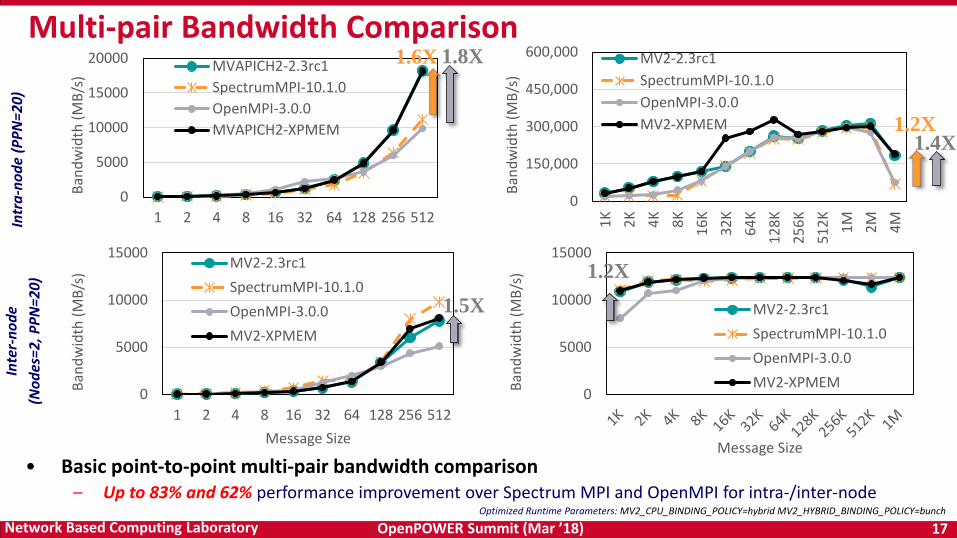
Multi-pair Bandwidth Comparison
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=bunch
• Basic point-to-point multi-pair bandwidth comparison– Up to 83% and 62% performance improvement over Spectrum MPI and OpenMPI for intra-/inter-node
0
5000
10000
15000
1 2 4 8 16 32 64 128 256 512
Band
wid
th (M
B/s)
Message Size
MV2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MV2-XPMEM
Inte
r-no
de
(Nod
es=2
, PPN
=20)
0
5000
10000
15000
20000
1 2 4 8 16 32 64 128 256 512
Band
wid
th (M
B/s)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
Intr
a-no
de (P
PN=2
0)
0
150,000
300,000
450,000
600,000
1K 2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M
Band
wid
th (M
B/s)
MV2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MV2-XPMEM
1.8X1.6X
1.4X1.2X
1.5X1.2X
OpenPOWER Summit (Mar ’18) 18Network Based Computing Laboratory
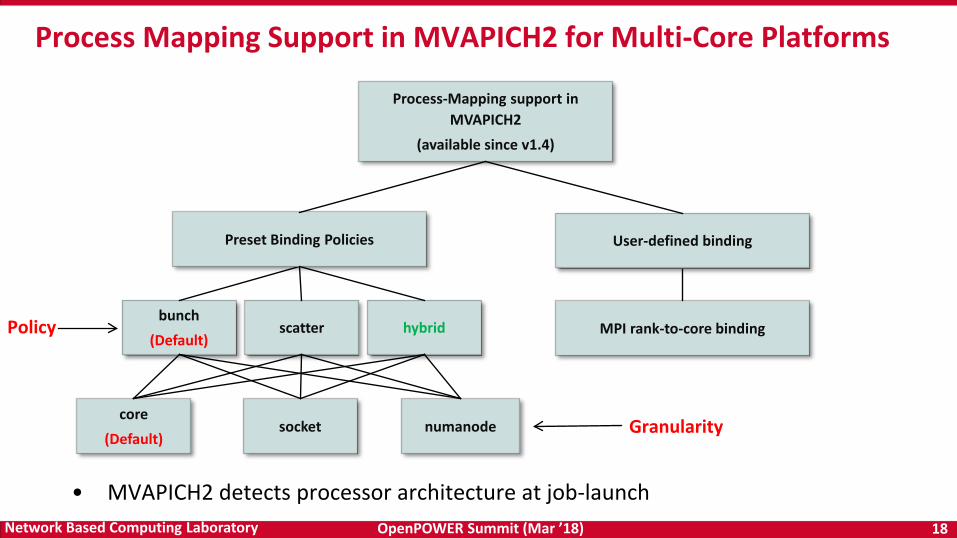
Process Mapping Support in MVAPICH2 for Multi-Core Platforms
Process-Mapping support in MVAPICH2
(available since v1.4)
bunch(Default)
scatter
core(Default)
socket numanode
Preset Binding Policies User-defined binding
MPI rank-to-core binding
• MVAPICH2 detects processor architecture at job-launch
Policy
Granularity
hybrid

OpenPOWER Summit (Mar ’18) 19Network Based Computing Laboratory
• A new process binding policy – “hybrid”– MV2_CPU_BINDING_POLICY = hybrid
• A new environment variable for co-locating Threads with MPI Processes– MV2_THREADS_PER_PROCESS = k
– Automatically set to OMP_NUM_THREADS if OpenMP is being used
– Provides a hint to the MPI runtime to spare resources for application threads.
• New variable for threads bindings with respect to parent process and architecture– MV2_THREADS_BINDING_POLICY = {linear | compact | spread}
• Linear – binds MPI ranks and OpenMP threads sequentially (one after the other)
– Recommended to be used on non-hyperthreaded systems with MPI+OpenMP
• Compact – binds MPI rank to physical-core and locates respective OpenMP threads on hardware threads
– Recommended to be used on multi-/many-cores e.g., KNL, POWER8, and hyper-threaded Xeon
Process and Thread binding policies in Hybrid MPI+Threads

OpenPOWER Summit (Mar ’18) 20Network Based Computing Laboratory
User-Defined Process Mapping• User has complete-control over process-mapping
• To run 4 processes on cores 0, 1, 4, 5:– $ mpirun_rsh -np 4 -hostfile hosts MV2_CPU_MAPPING=0:1:4:5 ./a.out
• Use ‘,’ or ‘-’ to bind to a set of cores:– $mpirun_rsh -np 64 -hostfile hosts MV2_CPU_MAPPING=0,2-4:1:5:6 ./a.out
• Is process binding working as expected?– MV2_SHOW_CPU_BINDING=1
• Display CPU binding information
• Launcher independent
• Example
– MV2_SHOW_CPU_BINDING=1 MV2_CPU_BINDING_POLICY=scatter
-------------CPU AFFINITY-------------
RANK:0 CPU_SET: 0
RANK:1 CPU_SET: 8
• Refer to Running with Efficient CPU (Core) Mapping section of MVAPICH2 user guide for more information
• http://mvapich.cse.ohio-state.edu/static/media/mvapich/mvapich2-2.3rc1-userguide.html#x1-600006.5

OpenPOWER Summit (Mar ’18) 21Network Based Computing Laboratory
• Message Passing Interface (MPI) Support– Point-to-point Inter-node and Intra-node
– CMA-based Collectives
– Upcoming XPMEM Support
• Support for PGAS and MPI + PGAS (OpenSHMEM, UPC)
• Exploiting Accelerators (NVIDIA GPGPUs)
• Support for Deep Learning
MPI, PGAS and Deep Learning Support for OpenPOWER

OpenPOWER Summit (Mar ’18) 22Network Based Computing Laboratory
0
10
20
30
40
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
MVAPICH2-X-2.3bSpectrumMPI-10.1.0.2OpenMPI-3.0.0
Scalable Collectives with CMA (Intra-node Reduce & AlltoAll)(N
odes
=1, P
PN=2
0)
0
50
100
150
200
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
MVAPICH2-X-2.3bSpectrumMPI-10.1.0.2OpenMPI-3.0.0
(Nod
es=1
, PPN
=20)
Up to 5X and 3x performance improvement by MVAPICH2-X-2.3b for small and large messages respectively
3.6X
Alltoall
Reduce
5.2X
3.2X3.3X
0
400
800
1200
1600
2000
8K 16K 32K 64K 128K 256K 512K 1M
Late
ncy
(us)
MVAPICH2-X-2.3bSpectrumMPI-10.1.0.2OpenMPI-3.0.0
(Nod
es=1
, PPN
=20)
0
2500
5000
7500
10000
8K 16K 32K 64K 128K 256K 512K 1M
Late
ncy
(us)
MVAPICH2-X-2.3bSpectrumMPI-10.1.0.2OpenMPI-3.0.0
(Nod
es=1
, PPN
=20)
3.2X
1.4X
1.3X1.2X

OpenPOWER Summit (Mar ’18) 23Network Based Computing Laboratory
0
1000
2000
8K 16K 32K 64K 128K 256K 512K 1M
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3bSpectrumMPI-10.1.0.2OpenMPI-3.0.0
0
25
50
75
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3b
SpectrumMPI-10.1.0.2
OpenMPI-3.0.0
0
15
30
45
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3bSpectrumMPI-10.1.0.2OpenMPI-3.0.0
Scalable Collectives with CMA (Intra-node, Gather & Scatter)(N
odes
=1, P
PN=2
0)
0
250
500
750
8K 16K 32K 64K 128K 256K 512K 1M
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3bSpectrumMPI-10.1.0.2OpenMPI-3.0.0
(Nod
es=1
, PPN
=20)
(Nod
es=1
, PPN
=20)
(Nod
es=1
, PPN
=20)
Up to 24X and 15x performance improvement by MVAPICH2-X-2.3b for medium to large messages respectively
Scatter
Gather24.5X
5.6X
8.3X
15.6X
4.9X
1.5X
6.4X 6.7X

OpenPOWER Summit (Mar ’18) 24Network Based Computing Laboratory
0
10
20
30
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
MVAPICH2-X-2.3b
OpenMPI-3.0.0
Scalable Collectives with CMA (Multi-node, Reduce & Alltoall)(N
odes
=4, P
PN=2
0)
0
500
1000
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
MVAPICH2-X-2.3bOpenMPI-3.0.0
(Nod
es=4
, PPN
=20)
Up to 12.4X and 8.5X performance improvement by MVAPICH2-X-2.3b for small and large messages respectively
12.4X
Alltoall
Reduce
1.9X
0
2000
4000
6000
8K 16K 32K 64K 128K 256K 512K 1M
Late
ncy
(us)
MVAPICH2-X-2.3b
OpenMPI-3.0.0
(Nod
es=4
, PPN
=20)
0
50000
100000
150000
8K 16K 32K 64K 128K 256K 512K 1MLa
tenc
y (u
s)
MVAPICH2-X-2.3bOpenMPI-3.0.0
(Nod
es=4
, PPN
=20)
8.5X
1.0X

OpenPOWER Summit (Mar ’18) 25Network Based Computing Laboratory
0
1000
2000
3000
4000
8K 16K 32K 64K 128K 256K 512K 1M
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3b
OpenMPI-3.0.0
0
20
40
60
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3b
OpenMPI-3.0.0
0
20
40
60
80
100
4 8 16 32 64 128 256 512 1K 2K 4K
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3b
OpenMPI-3.0.0
Scalable Collectives with CMA (Multi-node, Gather & Scatter)(N
odes
=4, P
PN=2
0)
0
1000
2000
3000
4000
5000
8K 16K 32K 64K 128K 256K 512K 1M
Late
ncy
(us)
Message Size (bytes)
MVAPICH2-X-2.3b
OpenMPI-3.0.0
(Nod
es=4
, PPN
=20)
(Nod
es=4
, PPN
=20)
(Nod
es=4
, PPN
=20)
Up to 17.8X and 3.9X performance improvement by MVAPICH2-X-2.3b for medium to large messages respectively
Scatter
Gather17.8X 3.9X
1.6X 0.8X

OpenPOWER Summit (Mar ’18) 26Network Based Computing Laboratory
• Message Passing Interface (MPI) Support– Point-to-point Inter-node and Intra-node
– CMA-based Collectives
– Upcoming XPMEM Support
• Support for PGAS and MPI + PGAS (OpenSHMEM, UPC)
• Exploiting Accelerators (NVIDIA GPGPUs)
• Support for Deep Learning
MPI, PGAS and Deep Learning Support for OpenPOWER

OpenPOWER Summit (Mar ’18) 27Network Based Computing Laboratory
0
1000
2000
3000
256K 512K 1M 2M
Late
ncy
(us)
MVAPICH2-2.3rc1
SpectrumMPI-10.1.0
OpenMPI-3.0.0
MVAPICH2-XPMEM
3X0
100
200
300
16K 32K 64K 128K
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
34%
0
1000
2000
3000
4000
256K 512K 1M 2M
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
0
100
200
300
16K 32K 64K 128K
Late
ncy
(us)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
Optimized MVAPICH2 All-Reduce with XPMEM(N
odes
=1, P
PN=2
0)
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=bunch
• Optimized MPI All-Reduce Design in MVAPICH2– Up to 2X performance improvement over Spectrum MPI and 4X over OpenMPI for intra-node
2X
(Nod
es=2
, PPN
=20)
4X
48%
3.3X
2X
2X

OpenPOWER Summit (Mar ’18) 28Network Based Computing Laboratory
0
100
200
300
400
16K 32K 64K 128K
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1OpenMPI-3.0.0MVAPICH2-XPMEM
0
1000
2000
3000
4000
256K 512K 1M 2M
Late
ncy
(us)
MVAPICH2-2.3rc1OpenMPI-3.0.0MVAPICH2-XPMEM
0
100
200
300
400
16K 32K 64K 128K
Late
ncy
(us)
MVAPICH2-2.3rc1OpenMPI-3.0.0MVAPICH2-XPMEM
Optimized MVAPICH2 All-Reduce with XPMEM (N
odes
=3, P
PN=2
0)
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=bunch
• Optimized MPI All-Reduce Design in MVAPICH2– Up to 2X performance improvement over OpenMPI for inter-node. (Spectrum MPI didn’t run for >2 processes)
22%
0
1000
2000
3000
4000
256K 512K 1M 2M
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1OpenMPI-3.0.0MVAPICH2-XPMEM
(Nod
es=4
, PPN
=20)
42% 27%
2X 35%
11%20%
18.8%
OpenPOWER Summit (Mar ’18) 29Network Based Computing Laboratory
0
200
400
16K 32K 64K 128K 256K
Late
ncy
(us)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
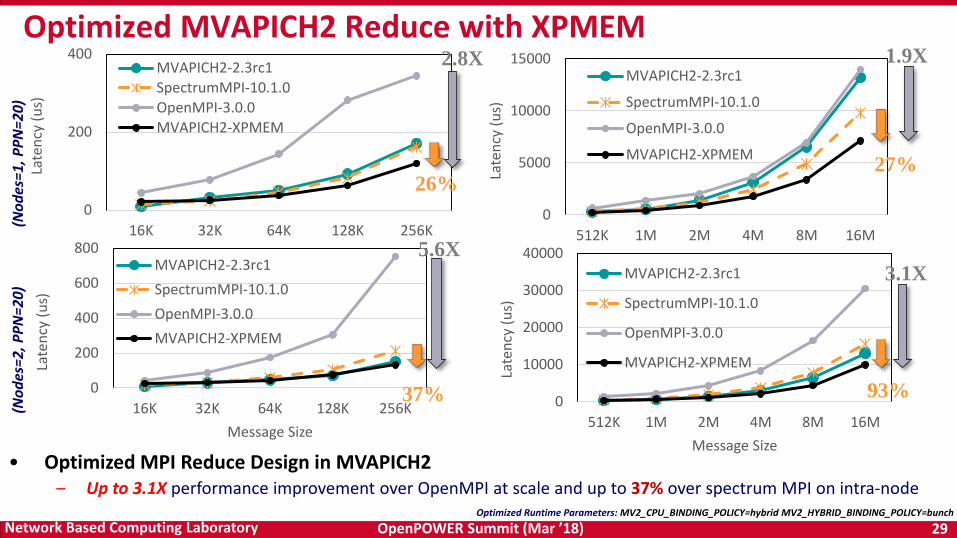
Optimized MVAPICH2 Reduce with XPMEM(N
odes
=1, P
PN=2
0)
0
200
400
600
800
16K 32K 64K 128K 256K
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=bunch
(Nod
es=2
, PPN
=20)
• Optimized MPI Reduce Design in MVAPICH2– Up to 3.1X performance improvement over OpenMPI at scale and up to 37% over spectrum MPI on intra-node
0
5000
10000
15000
512K 1M 2M 4M 8M 16M
Late
ncy
(us)
MVAPICH2-2.3rc1
SpectrumMPI-10.1.0
OpenMPI-3.0.0
MVAPICH2-XPMEM
0
10000
20000
30000
40000
512K 1M 2M 4M 8M 16M
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1
SpectrumMPI-10.1.0
OpenMPI-3.0.0
MVAPICH2-XPMEM
26%
2.8X
27%
1.9X
37%
5.6X
93%
3.1X

OpenPOWER Summit (Mar ’18) 30Network Based Computing Laboratory
0
200
400
600
800
1000
16K 32K 64K 128K 256K
Late
ncy
(us)
MVAPICH2-2.3rc1SpectrumMPI-10.1.0OpenMPI-3.0.0MVAPICH2-XPMEM
Optimized MVAPICH2 Reduce with XPMEM(N
odes
=3, P
PN=2
0)
0
200
400
600
800
1000
1200
16K 32K 64K 128K 256K
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1
SpectrumMPI-10.1.0
OpenMPI-3.0.0
MVAPICH2-XPMEM
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=bunch
(Nod
es=4
, PPN
=20)
• Optimized MPI Reduce Design in MVAPICH2– Up to 7X performance improvement over OpenMPI at scale and up to 25% over MVAPICH2-2.3rc1
0
10000
20000
30000
40000
50000
512K 1M 2M 4M 8M 16M
Late
ncy
(us)
MVAPICH2-2.3rc1
SpectrumMPI-10.1.0
OpenMPI-3.0.0
MVAPICH2-XPMEM
0
10000
20000
30000
40000
50000
512K 1M 2M 4M 8M 16M
Late
ncy
(us)
Message Size
MVAPICH2-2.3rc1
SpectrumMPI-10.1.0
OpenMPI-3.0.0
MVAPICH2-XPMEM
16%
4X6X
25%
7X
8%
14%
4X

OpenPOWER Summit (Mar ’18) 31Network Based Computing Laboratory
0
20
40
60
10 20 40 60
Exec
utio
n Ti
me
(s)
MPI Processes (proc-per-sock=10, proc-per-node=20)
MVAPICH-2.3rc1MVAPICH2-XPMEM
MiniAMR Performance using Optimized XPMEM-based Collectives
• MiniAMR application execution time comparing MVAPICH2-2.3rc1 and optimized All-Reduce design– Up to 45% improvement over MVAPICH2-2.3rc1 in mesh-refinement time of MiniAMR application for weak-
scaling workload on up to four POWER8 nodes.
45%41%
36%42%
Optimized Runtime Parameters: MV2_CPU_BINDING_POLICY=hybrid MV2_HYBRID_BINDING_POLICY=scatter

OpenPOWER Summit (Mar ’18) 32Network Based Computing Laboratory
• Message Passing Interface (MPI) Support
• Support for PGAS and MPI + PGAS (OpenSHMEM, UPC)
• Exploiting Accelerators (NVIDIA GPGPUs)
• Support for Deep Learning
MPI, PGAS and Deep Learning Support for OpenPOWER

OpenPOWER Summit (Mar ’18) 33Network Based Computing Laboratory
MVAPICH2-X for Hybrid MPI + PGAS Applications
• Current Model – Separate Runtimes for OpenSHMEM/UPC/UPC++/CAF and MPI– Possible deadlock if both runtimes are not progressed
– Consumes more network resource
• Unified communication runtime for MPI, UPC, UPC++, OpenSHMEM, CAF– Available with since 2012 (starting with MVAPICH2-X 1.9) – http://mvapich.cse.ohio-state.edu
OpenPOWER Summit (Mar ’18) 34Network Based Computing Laboratory
0
0.2
0.4
1 2 4 8 16 32 64 128 256 512
Late
ncy
(us)
Message Size
shmem_get (intra)shmem_put (intra)
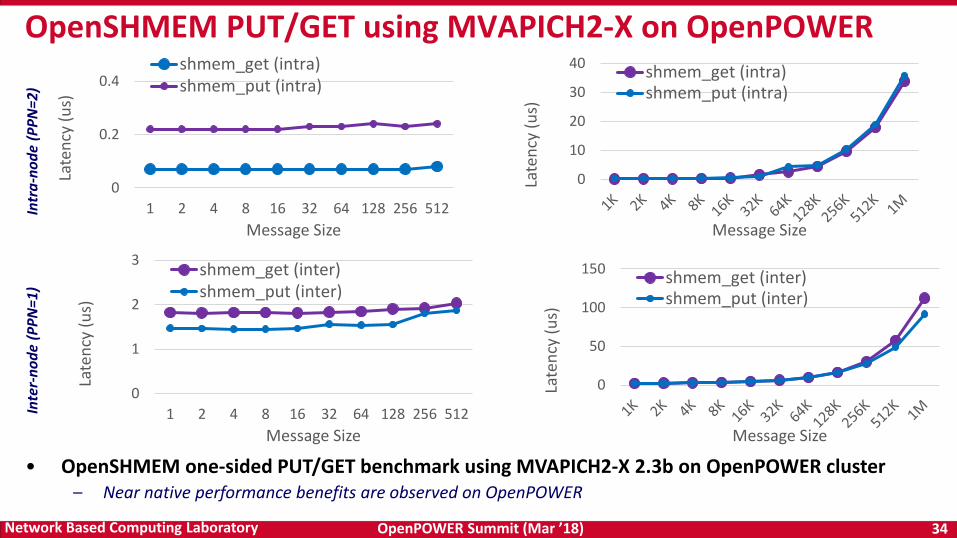
OpenSHMEM PUT/GET using MVAPICH2-X on OpenPOWERIn
tra-
node
(PPN
=2)
• OpenSHMEM one-sided PUT/GET benchmark using MVAPICH2-X 2.3b on OpenPOWER cluster– Near native performance benefits are observed on OpenPOWER
Inte
r-no
de (P
PN=1
)
0
10
20
30
40
Late
ncy
(us)
Message Size
shmem_get (intra)shmem_put (intra)
0
1
2
3
1 2 4 8 16 32 64 128 256 512
Late
ncy
(us)
Message Size
shmem_get (inter)shmem_put (inter)
0
50
100
150
Late
ncy
(us)
Message Size
shmem_get (inter)shmem_put (inter)

OpenPOWER Summit (Mar ’18) 35Network Based Computing Laboratory
0
1
2
3
1 2 4 8 16 32 64 128 256 512 1K
Late
ncy
(us)
Message Size
upc_getmem (intra)upc_putmem (intra)
UPC PUT/GET benchmarks using MVAPICH2-X on OpenPOWERIn
tra-
node
(PPN
=2)
• UPC one-sided memput/memget benchmarks using MVAPICH2-X 2.3b on OpenPOWER cluster– Near native performance benefits are observed on OpenPOWER
Inte
r-no
de (P
PN=1
)
0
200
400
600
2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M
Late
ncy
(us)
Message Size
upc_getmem (intra)upc_putmem (intra)
0
1
2
3
1 2 4 8 16 32 64 128 256 512 1K
Late
ncy
(us)
Message Size
upc_getmem (inter)upc_putmem (inter)
0
100
200
300
400
2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M
Late
ncy
(us)
Message Size
upc_getmem (inter)upc_putmem (inter)

OpenPOWER Summit (Mar ’18) 36Network Based Computing Laboratory
0
0.02
0.04
0.06
1 2 4 8 16 32 64 128 256 512 1K
Late
ncy
(us)
Message Size
upcxx_async_get (intra)upcxx_async_put (intra)
UPC++ PUT/GET benchmarks using MVAPICH2-X on OpenPOWERIn
tra-
node
(PPN
=2)
• UPC++ one-sided async_copy_put/get benchmarks using MVAPICH2-X 2.3b on OpenPOWER cluster– Near native performance benefits are observed on OpenPOWER
Inte
r-no
de (P
PN=1
)
0
100
200
2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M
Late
ncy
(us)
Message Size
upcxx_async_get (intra)upcxx_async_put (intra)
0
1
2
1 2 4 8 16 32 64 128 256 512 1K
Late
ncy
(us)
Message Size
upcxx_async_get (inter)upcxx_async_put (inter)
0
500
2K 4K 8K 16K
32K
64K
128K
256K
512K 1M 2M 4M
Late
ncy
(us)
Message Size
upcxx_async_get (inter)upcxx_async_put (inter)

OpenPOWER Summit (Mar ’18) 37Network Based Computing Laboratory
• Message Passing Interface (MPI) Support
• Support for PGAS and MPI + PGAS (OpenSHMEM, UPC)
• Exploiting Accelerators (NVIDIA GPGPUs)– CUDA-aware MPI– Optimized GPUDirect RDMA (GDR) Support– Optimized MVAPICH2 for OpenPower
• Support for Deep Learning
MPI, PGAS and Deep Learning Support for OpenPOWER
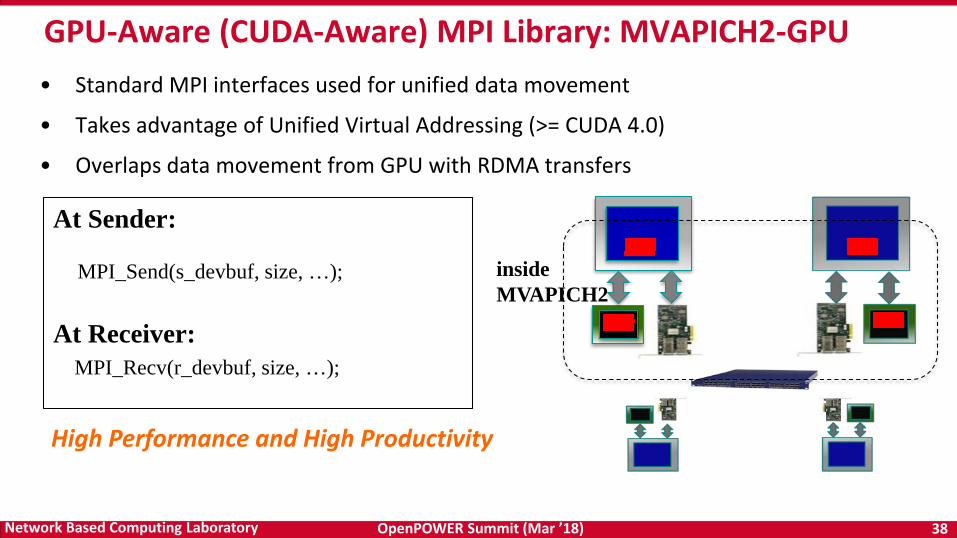
OpenPOWER Summit (Mar ’18) 38Network Based Computing Laboratory
At Sender:
At Receiver:MPI_Recv(r_devbuf, size, …);
insideMVAPICH2
• Standard MPI interfaces used for unified data movement
• Takes advantage of Unified Virtual Addressing (>= CUDA 4.0)
• Overlaps data movement from GPU with RDMA transfers
High Performance and High Productivity
MPI_Send(s_devbuf, size, …);
GPU-Aware (CUDA-Aware) MPI Library: MVAPICH2-GPU

OpenPOWER Summit (Mar ’18) 39Network Based Computing Laboratory
CUDA-Aware MPI: MVAPICH2-GDR 1.8-2.3 Releases• Support for MPI communication from NVIDIA GPU device memory• High performance RDMA-based inter-node point-to-point communication
(GPU-GPU, GPU-Host and Host-GPU)• High performance intra-node point-to-point communication for multi-GPU
adapters/node (GPU-GPU, GPU-Host and Host-GPU)• Taking advantage of CUDA IPC (available since CUDA 4.1) in intra-node
communication for multiple GPU adapters/node• Optimized and tuned collectives for GPU device buffers• MPI datatype support for point-to-point and collective communication from
GPU device buffers• Unified memory

OpenPOWER Summit (Mar ’18) 40Network Based Computing Laboratory
0
2000
4000
6000
1 2 4 8 16 32 64 128
256
512 1K 2K 4K
Band
wid
th (M
B/s)
Message Size (Bytes)
GPU-GPU Inter-node Bi-Bandwidth
MV2-(NO-GDR) MV2-GDR-2.3a
01000200030004000
1 2 4 8 16 32 64 128
256
512 1K 2K 4K
Band
wid
th (M
B/s)
Message Size (Bytes)
GPU-GPU Inter-node Bandwidth
MV2-(NO-GDR) MV2-GDR-2.3a
0
10
20
300 1 2 4 8 16 32 64 128
256
512 1K 2K 4K 8K
Late
ncy
(us)
Message Size (Bytes)
GPU-GPU Inter-node Latency
MV2-(NO-GDR) MV2-GDR-2.3a
MVAPICH2-GDR-2.3aIntel Haswell (E5-2687W @ 3.10 GHz) node - 20 cores
NVIDIA Volta V100 GPUMellanox Connect-X4 EDR HCA
CUDA 9.0Mellanox OFED 4.0 with GPU-Direct-RDMA
10x
9x
Optimized MVAPICH2-GDR Design
1.88us11X

OpenPOWER Summit (Mar ’18) 41Network Based Computing Laboratory
• Platform: Wilkes (Intel Ivy Bridge + NVIDIA Tesla K20c + Mellanox Connect-IB)• HoomDBlue Version 1.0.5
• GDRCOPY enabled: MV2_USE_CUDA=1 MV2_IBA_HCA=mlx5_0 MV2_IBA_EAGER_THRESHOLD=32768 MV2_VBUF_TOTAL_SIZE=32768 MV2_USE_GPUDIRECT_LOOPBACK_LIMIT=32768 MV2_USE_GPUDIRECT_GDRCOPY=1 MV2_USE_GPUDIRECT_GDRCOPY_LIMIT=16384
Application-Level Evaluation (HOOMD-blue)
0
500
1000
1500
2000
2500
4 8 16 32
Aver
age
Tim
e St
eps p
er
seco
nd (T
PS)
Number of Processes
MV2 MV2+GDR
0500
100015002000250030003500
4 8 16 32Aver
age
Tim
e St
eps p
er
seco
nd (T
PS)
Number of Processes
64K Particles 256K Particles
2X2X
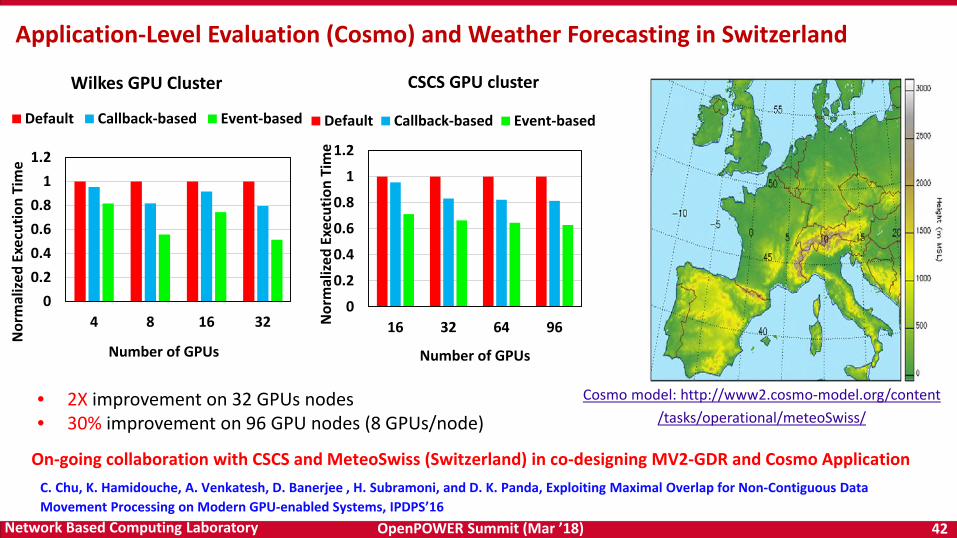
OpenPOWER Summit (Mar ’18) 42Network Based Computing Laboratory
Application-Level Evaluation (Cosmo) and Weather Forecasting in Switzerland
0
0.2
0.4
0.6
0.8
1
1.2
16 32 64 96Nor
mal
ized
Exec
utio
n Ti
me
Number of GPUs
CSCS GPU cluster
Default Callback-based Event-based
00.20.40.60.8
11.2
4 8 16 32
Nor
mal
ized
Exec
utio
n Ti
me
Number of GPUs
Wilkes GPU Cluster
Default Callback-based Event-based
• 2X improvement on 32 GPUs nodes• 30% improvement on 96 GPU nodes (8 GPUs/node)
C. Chu, K. Hamidouche, A. Venkatesh, D. Banerjee , H. Subramoni, and D. K. Panda, Exploiting Maximal Overlap for Non-Contiguous Data Movement Processing on Modern GPU-enabled Systems, IPDPS’16
On-going collaboration with CSCS and MeteoSwiss (Switzerland) in co-designing MV2-GDR and Cosmo Application
Cosmo model: http://www2.cosmo-model.org/content/tasks/operational/meteoSwiss/
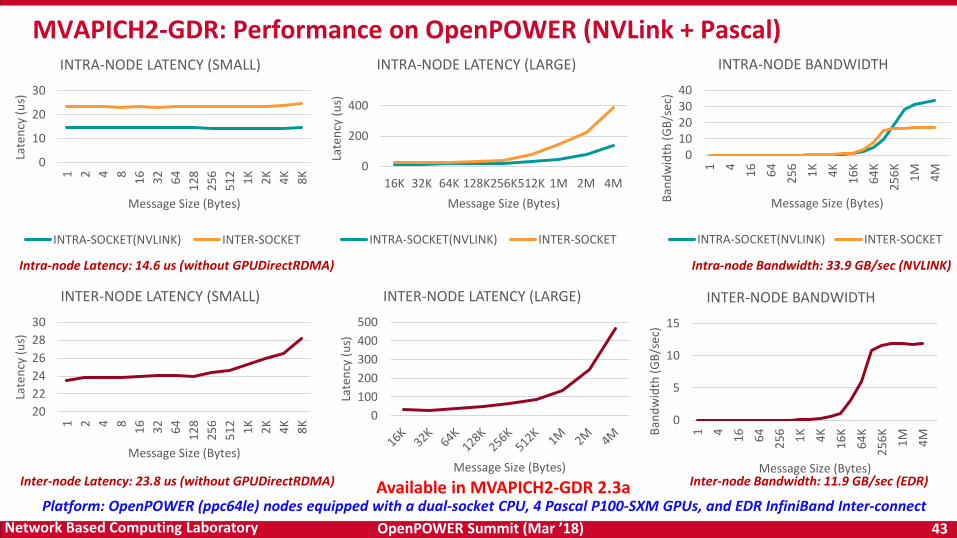
OpenPOWER Summit (Mar ’18) 43Network Based Computing Laboratory
0
10
20
30
1 2 4 8 16 32 64 128
256
512 1K 2K 4K 8K
Late
ncy
(us)
Message Size (Bytes)
INTRA-NODE LATENCY (SMALL)
INTRA-SOCKET(NVLINK) INTER-SOCKET
MVAPICH2-GDR: Performance on OpenPOWER (NVLink + Pascal)
010203040
1 4 16 64 256 1K 4K 16K
64K
256K 1M 4M
Band
wid
th (G
B/se
c)
Message Size (Bytes)
INTRA-NODE BANDWIDTH
INTRA-SOCKET(NVLINK) INTER-SOCKET
0
5
10
15
1 4 16 64 256 1K 4K 16K
64K
256K 1M 4M
Band
wid
th (G
B/se
c)
Message Size (Bytes)
INTER-NODE BANDWIDTH
Platform: OpenPOWER (ppc64le) nodes equipped with a dual-socket CPU, 4 Pascal P100-SXM GPUs, and EDR InfiniBand Inter-connect
0
200
400
16K 32K 64K 128K256K512K 1M 2M 4M
Late
ncy
(us)
Message Size (Bytes)
INTRA-NODE LATENCY (LARGE)
INTRA-SOCKET(NVLINK) INTER-SOCKET
202224262830
1 2 4 8 16 32 64 128
256
512 1K 2K 4K 8K
Late
ncy
(us)
Message Size (Bytes)
INTER-NODE LATENCY (SMALL)
0100200300400500
Late
ncy
(us)
Message Size (Bytes)
INTER-NODE LATENCY (LARGE)
Intra-node Bandwidth: 33.9 GB/sec (NVLINK)Intra-node Latency: 14.6 us (without GPUDirectRDMA)
Inter-node Latency: 23.8 us (without GPUDirectRDMA) Inter-node Bandwidth: 11.9 GB/sec (EDR)Available in MVAPICH2-GDR 2.3a

OpenPOWER Summit (Mar ’18) 44Network Based Computing Laboratory
• MPI runtime has many parameters• Tuning a set of parameters can help you to extract higher performance• Compiled a list of such contributions through the MVAPICH Website
– http://mvapich.cse.ohio-state.edu/best_practices/
• List of applications (16 contributions so far)– Amber, Cloverleaf, GAPgeofem, HoomDBlue, HPCG, LAMPS, LU, Lulesh, MILC,
Neuro, POP2, SMG2000, SPEC MPI, TERA_TF, UMR, and WRF2• Soliciting additional contributions, send your results to mvapich-help at
cse.ohio-state.edu• We will link these results with credits to you
Compilation of Best Practices

OpenPOWER Summit (Mar ’18) 45Network Based Computing Laboratory
• Message Passing Interface (MPI) Support
• Support for PGAS and MPI + PGAS (OpenSHMEM, UPC)
• Exploiting Accelerators (NVIDIA GPGPUs)
• Support for Deep Learning– New challenges for MPI Run-time
– Optimizing Large-message Collectives
– Co-designing DL Frameworks
MPI, PGAS and Deep Learning Support for OpenPOWER

OpenPOWER Summit (Mar ’18) 46Network Based Computing Laboratory
• Deep Learning frameworks are a different game altogether
– Unusually large message sizes (order of megabytes)
– Most communication based on GPU buffers
• Existing State-of-the-art– cuDNN, cuBLAS, NCCL --> scale-up performance
– CUDA-Aware MPI --> scale-out performance• For small and medium message sizes only!
• Proposed: Can we co-design the MPI runtime (MVAPICH2-GDR) and the DL framework (Caffe) to achieve both?
– Efficient Overlap of Computation and Communication
– Efficient Large-Message Communication (Reductions)
– What application co-designs are needed to exploit communication-runtime co-designs?
Deep Learning: New Challenges for MPI Runtimes
Scal
e-up
Per
form
ance
Scale-out Performance
cuDNN
NCCL
gRPC
Hadoop
ProposedCo-Designs
MPIcuBLAS
A. A. Awan, K. Hamidouche, J. M. Hashmi, and D. K. Panda, S-Caffe: Co-designing MPI Runtimes and Caffe for Scalable Deep Learning on Modern GPU Clusters. In Proceedings of the 22nd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP '17)
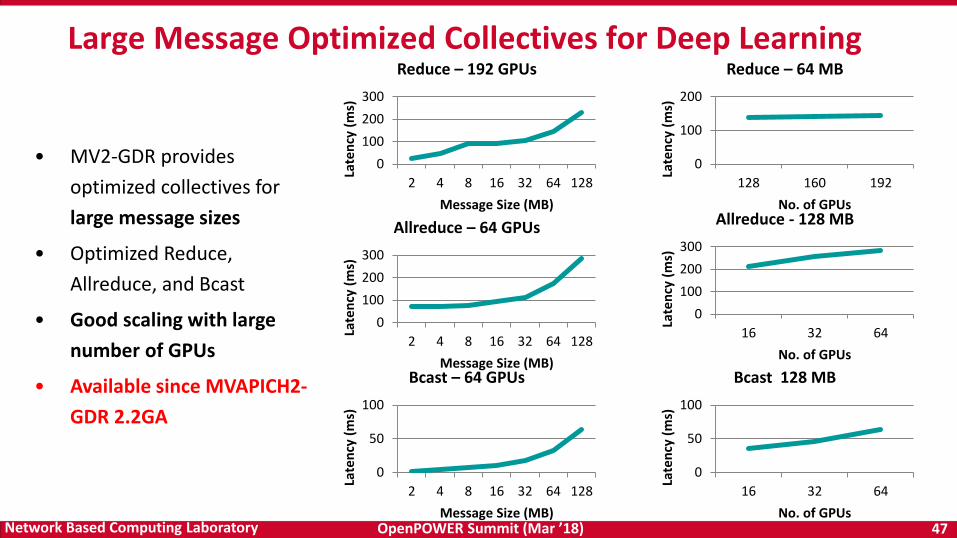
OpenPOWER Summit (Mar ’18) 47Network Based Computing Laboratory
0100200300
2 4 8 16 32 64 128
Late
ncy
(ms)
Message Size (MB)
Reduce – 192 GPUsLarge Message Optimized Collectives for Deep Learning
0
100
200
128 160 192
Late
ncy
(ms)
No. of GPUs
Reduce – 64 MB
0100200300
16 32 64
Late
ncy
(ms)
No. of GPUs
Allreduce - 128 MB
0
50
100
2 4 8 16 32 64 128
Late
ncy
(ms)
Message Size (MB)
Bcast – 64 GPUs
0
50
100
16 32 64
Late
ncy
(ms)
No. of GPUs
Bcast 128 MB
• MV2-GDR provides optimized collectives for large message sizes
• Optimized Reduce, Allreduce, and Bcast
• Good scaling with large number of GPUs
• Available since MVAPICH2-GDR 2.2GA
0100200300
2 4 8 16 32 64 128La
tenc
y (m
s)Message Size (MB)
Allreduce – 64 GPUs
OpenPOWER Summit (Mar ’18) 48Network Based Computing Laboratory
0
1000
2000
3000
4000
5000
6000
512K 1M 2M 4M
Late
ncy
(us)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
0100000200000300000400000500000600000700000800000
8M 16M
32M
64M
128M
256M
512M
Late
ncy
(us)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
1
10
100
1000
10000
100000
4 16 64 256 1K 4K 16K
64K
256K
Late
ncy
(us)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
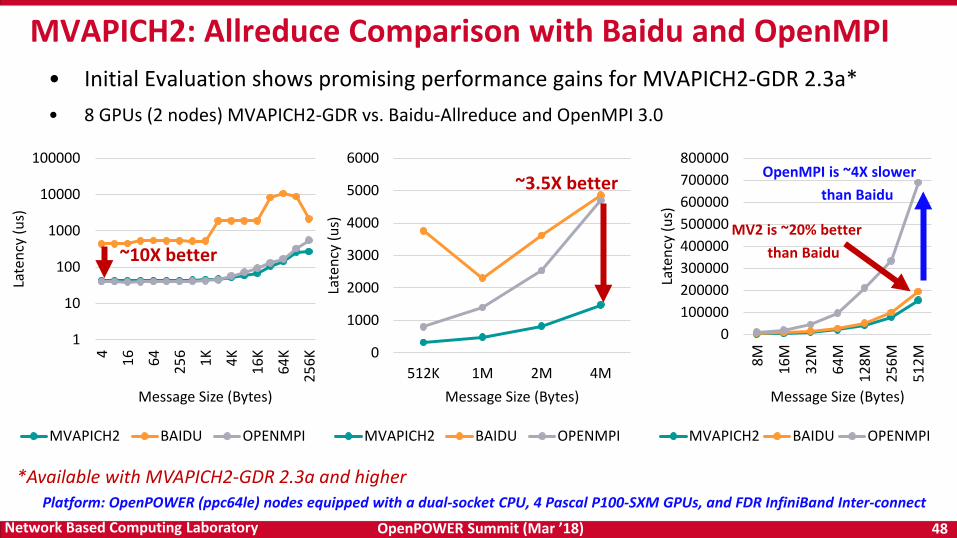
• Initial Evaluation shows promising performance gains for MVAPICH2-GDR 2.3a*• 8 GPUs (2 nodes) MVAPICH2-GDR vs. Baidu-Allreduce and OpenMPI 3.0
MVAPICH2: Allreduce Comparison with Baidu and OpenMPI
*Available with MVAPICH2-GDR 2.3a and higher
~10X betterMV2 is ~20% better
than Baidu
~3.5X better OpenMPI is ~4X slower than Baidu
Platform: OpenPOWER (ppc64le) nodes equipped with a dual-socket CPU, 4 Pascal P100-SXM GPUs, and FDR InfiniBand Inter-connect

OpenPOWER Summit (Mar ’18) 49Network Based Computing Laboratory
0
10000
20000
30000
40000
50000
512K 1M 2M 4M
Late
ncy
(us)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
0
1000000
2000000
3000000
4000000
5000000
6000000
8M 16M
32M
64M
128M
256M
512M
Late
ncy
(us)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
1
10
100
1000
10000
100000
4 16 64 256 1K 4K 16K
64K
256K
Late
ncy
(us)
Message Size (Bytes)
MVAPICH2 BAIDU OPENMPI
• 16 GPUs (4 nodes) MVAPICH2-GDR vs. Baidu-Allreduce and OpenMPI 3.0
MVAPICH2: Allreduce Comparison with Baidu and OpenMPI
*Available with MVAPICH2-GDR 2.3a and higher
~30X betterMV2 is ~2X better
than Baidu
~10X better OpenMPI is ~5X slower than Baidu
~4X better
Platform: OpenPOWER (ppc64le) nodes equipped with a dual-socket CPU, 4 Pascal P100-SXM GPUs, and FDR InfiniBand Inter-connect
OpenPOWER Summit (Mar ’18) 50Network Based Computing Laboratory
1
10
100
1000
10000
1000004 16 64 256 1K 4K 16K
64K
256K 1M 4M 16M
64M
Late
ncy
(us)
Message Size (Bytes)
NCCL2 MVAPICH2-GDR
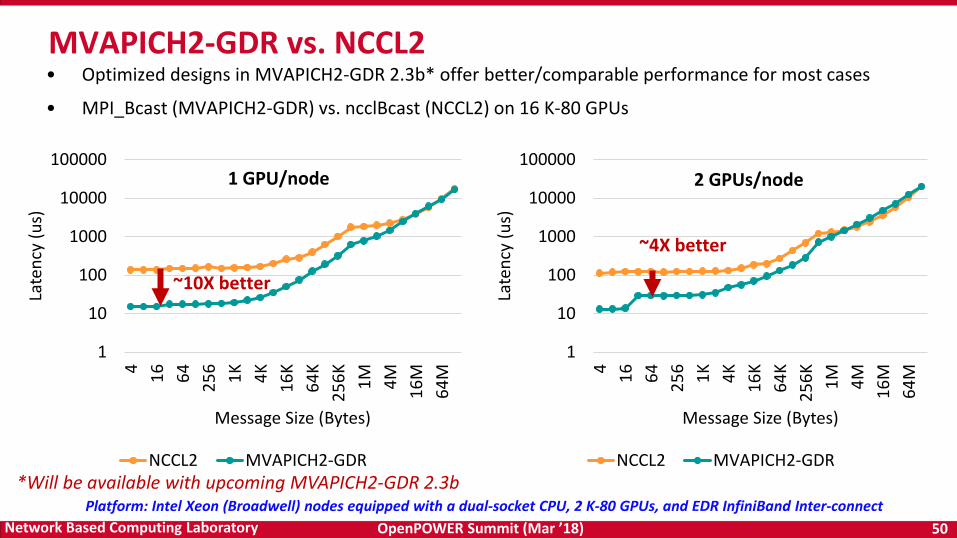
MVAPICH2-GDR vs. NCCL2• Optimized designs in MVAPICH2-GDR 2.3b* offer better/comparable performance for most cases
• MPI_Bcast (MVAPICH2-GDR) vs. ncclBcast (NCCL2) on 16 K-80 GPUs
*Will be available with upcoming MVAPICH2-GDR 2.3b
1
10
100
1000
10000
100000
4 16 64 256 1K 4K 16K
64K
256K 1M 4M 16M
64M
Late
ncy
(us)
Message Size (Bytes)
NCCL2 MVAPICH2-GDR
~10X better
~4X better
1 GPU/node 2 GPUs/node
Platform: Intel Xeon (Broadwell) nodes equipped with a dual-socket CPU, 2 K-80 GPUs, and EDR InfiniBand Inter-connect
OpenPOWER Summit (Mar ’18) 51Network Based Computing Laboratory
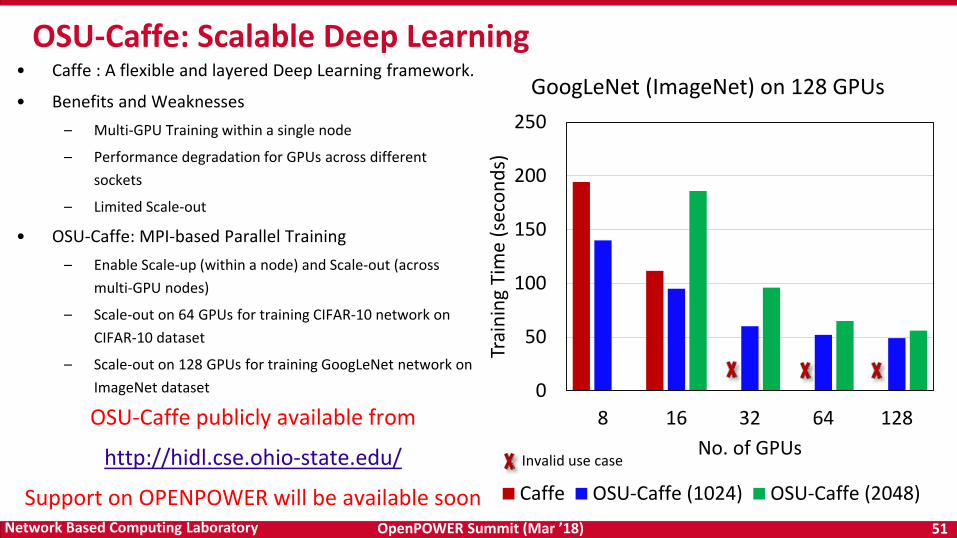
• Caffe : A flexible and layered Deep Learning framework.
• Benefits and Weaknesses– Multi-GPU Training within a single node
– Performance degradation for GPUs across different sockets
– Limited Scale-out
• OSU-Caffe: MPI-based Parallel Training – Enable Scale-up (within a node) and Scale-out (across
multi-GPU nodes)
– Scale-out on 64 GPUs for training CIFAR-10 network on CIFAR-10 dataset
– Scale-out on 128 GPUs for training GoogLeNet network on ImageNet dataset
OSU-Caffe: Scalable Deep Learning
0
50
100
150
200
250
8 16 32 64 128
Trai
ning
Tim
e (s
econ
ds)
No. of GPUs
GoogLeNet (ImageNet) on 128 GPUs
Caffe OSU-Caffe (1024) OSU-Caffe (2048)
Invalid use case
OSU-Caffe publicly available from
http://hidl.cse.ohio-state.edu/
Support on OPENPOWER will be available soon

OpenPOWER Summit (Mar ’18) 52Network Based Computing Laboratory
• Next generation HPC systems need to be designed with a holistic view of Big Data and Deep Learning
• OpenPOWER platform is emerging with many novel features
• Presented some of the approaches and results along these directions from the MVAPICH2 and HiDL Projects
• Solutions Enable High-Performance and Scalable HPC and Deep Learning on OpenPOWER Platforms
Concluding Remarks

OpenPOWER Summit (Mar ’18) 53Network Based Computing Laboratory
High-Performance Hadoop and Spark on OpenPOWER Platform
Talk at 2:15 pm

OpenPOWER Summit (Mar ’18) 54Network Based Computing Laboratory
Funding AcknowledgmentsFunding Support by
Equipment Support by

OpenPOWER Summit (Mar ’18) 55Network Based Computing Laboratory
Personnel AcknowledgmentsCurrent Students (Graduate)
– A. Awan (Ph.D.)
– R. Biswas (M.S.)
– M. Bayatpour (Ph.D.)
– S. Chakraborthy (Ph.D.)
– C.-H. Chu (Ph.D.)
– S. Guganani (Ph.D.)
Past Students – A. Augustine (M.S.)
– P. Balaji (Ph.D.)
– S. Bhagvat (M.S.)
– A. Bhat (M.S.)
– D. Buntinas (Ph.D.)
– L. Chai (Ph.D.)
– B. Chandrasekharan (M.S.)
– N. Dandapanthula (M.S.)
– V. Dhanraj (M.S.)
– T. Gangadharappa (M.S.)
– K. Gopalakrishnan (M.S.)
– R. Rajachandrasekar (Ph.D.)
– G. Santhanaraman (Ph.D.)
– A. Singh (Ph.D.)
– J. Sridhar (M.S.)
– S. Sur (Ph.D.)
– H. Subramoni (Ph.D.)
– K. Vaidyanathan (Ph.D.)
– A. Vishnu (Ph.D.)
– J. Wu (Ph.D.)
– W. Yu (Ph.D.)
Past Research Scientist– K. Hamidouche
– S. Sur
Past Post-Docs– D. Banerjee
– X. Besseron
– H.-W. Jin
– W. Huang (Ph.D.)
– W. Jiang (M.S.)
– J. Jose (Ph.D.)
– S. Kini (M.S.)
– M. Koop (Ph.D.)
– K. Kulkarni (M.S.)
– R. Kumar (M.S.)
– S. Krishnamoorthy (M.S.)
– K. Kandalla (Ph.D.)
– M. Li (Ph.D.)
– P. Lai (M.S.)
– J. Liu (Ph.D.)
– M. Luo (Ph.D.)
– A. Mamidala (Ph.D.)
– G. Marsh (M.S.)
– V. Meshram (M.S.)
– A. Moody (M.S.)
– S. Naravula (Ph.D.)
– R. Noronha (Ph.D.)
– X. Ouyang (Ph.D.)
– S. Pai (M.S.)
– S. Potluri (Ph.D.)
– J. Hashmi (Ph.D.)
– H. Javed (Ph.D.)
– P. Kousha (Ph.D.)
– D. Shankar (Ph.D.)
– H. Shi (Ph.D.)
– J. Zhang (Ph.D.)
– J. Lin
– M. Luo
– E. Mancini
Current Research Scientists– X. Lu
– H. Subramoni
Past Programmers– D. Bureddy
– J. Perkins
Current Research Specialist– J. Smith
– M. Arnold
– S. Marcarelli
– J. Vienne
– H. Wang
Current Post-doc– A. Ruhela
Current Students (Undergraduate)– N. Sarkauskas (B.S.)

OpenPOWER Summit (Mar ’18) 56Network Based Computing Laboratory
Thank You!
Network-Based Computing Laboratoryhttp://nowlab.cse.ohio-state.edu/
The High-Performance MPI/PGAS Projecthttp://mvapich.cse.ohio-state.edu/
The High-Performance Deep Learning Projecthttp://hidl.cse.ohio-state.edu/
The High-Performance Big Data Projecthttp://hibd.cse.ohio-state.edu/





![Performance Evaluation of MPI Libraries on GPU-enabled ...nowlab.cse.ohio-state.edu/.../abstract/IWOPH_19_MPI_on_POWER.pdf · nodes, the concept of CUDA-aware MPI [28] has been introduced](https://cdn.vdocuments.net/doc/165x107/5ec5b93d26ea6d3c9424f66c/performance-evaluation-of-mpi-libraries-on-gpu-enabled-nodes-the-concept-of.jpg)

