Download - HiRDB SQLコーディングガイドラインµ±計レポートの出力情報を指定します出力にはアクセスパス情報 SQL単 位の情報UAP単位の情報 SQL実行時の中間結果情報がありますアクセスパス

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
株式会社 日立製作所 情報・通信システム社 ITプラットフォーム事業本部 DB部
2015/06
HiRDB SQLコーディングガイドライン
第08版

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
1. はじめに
2. インデクスを有効に使う記述
3. 副問合せに関する記述
Contents
1
4. 結合検索に関する記述
5. 表の分割に関する記述
6. DBの件数を考慮した記述
7. 排他に関する記述
8. 更新に関する記述
9. アプリケーション上での記述
10. 保守性を向上させるための記述
11. おわりに

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
1. はじめに
2

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
1-1 本資料について
3
■ 目的
データベース(以下本ドキュメントではDBと略す)へのアクセス性能は、SQL文の
コーディング方法により左右されることがあります。本ガイドラインでは、DBへのアクセ
ス性能を良くするための推奨のSQLコーディング方法を示します。本ガイドラインを
各プロジェクトのSQLコーディング規約を制定する際に活用していただくことで、DBに
アクセスするアプリケーションの性能トラブルを、未然に防ぐことを目的とします。
なお、内容は一般的な推奨であり、必要であれば異なるSQLコーディング方法をとる
ことを妨げるものではありません。
■ 対象バーション
本ドキュメントは、HiRDB Version 8 以降を対象としています。
■ 留意事項
本ドキュメントの例題にて、対比しているSQLは、必ずしも等価なSQLでないため、
SQL文を変形するときは、十分注意してください。
■ コーディング例の凡例
本ドキュメントの例題にて、コーディングの推奨度合を記号表記しています。記号と意
味を以下に示します。
◎:特に推奨 ○:推奨 △:改善の余地あり ×:推奨しない。改善が必要。
以下のURLより、HiRDBの基礎知識を理解しておくと、本資料の理解が深まります。
http://www.hitachi.co.jp/soft/hirdb/info/tech_info.html
HiRDB技術資料のURL

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
1-2 アプリケーション開発の流れ
4
・ ・
1.スキーマ設計
2.プロジェクト内の SQLコーディング規約制定
3.アプリケーション開発
4.単体テスト
5.SI
性能とのトレードオフで正規化のレベルを考える
「ジョインは4表まで」など、プロジェクトで性能も含めた品質を確保するための標準を定める ← 本ガイドラインを活用
コーディング規約に従って、アプリケーションを開発する
SQLのアクセスパスを確認して、アプリケーション開発へフィードバック

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
1-3 SQLのアクセスパスの評価
5
クライアント環境定義に以下を追加し、UAP統計レポートの中で取得します。
アクセスパスの取得
No. クライアント環境定義 統計情報の内容
1 PDCLTPATH 情報出力先。省略時は、カレントディレクトリが仮定されます。
2 PDSQLTRACE トレースのファイルサイズ(byte)を指定。0を指定した場合は、ファイルの最大のサイズとなります。省略をした場合は、情報を出力しない。
3 PDUAPREPLVL
UAP統計レポートの出力情報を指定します。出力には、アクセスパス情報、SQL単位の情報、UAP単位の情報、SQL実行時の中間結果情報があります。アクセスパスの解析時は、aを指定し全ての情報を出力することをお勧めします。
4 PDREPPATH UAP統計レポートファイルをPDCLTPATHで指定したディレクトリとは別の場所に格納したい場合に指定する。指定すると、CONNECT単位にファイルが分かれる。
アクセスパスのチェック
以下のキーワードで示されるアクセスパスは、定性的に負荷の高い処理であるためチェックアウトします。 ' TABLE SCAN ' …(データページ全参照[テーブルスキャン]) ' AND PLURAL INDEXES SCAN ' …(AND複数インデクス利用) ' MERGE JOIN ' …(マージジョイン) ' CROSS JOIN ' …(直積) ' FULL SCAN ' …(インデクスリーフページのフルスキャン) ' WORK TABLE SUBQ ' …(副問合せ結果の作業表への繰り返しスキャン) ' NESTED LOOPS WORK TABLE SUBQ ' …(副問合せの繰り返し実行と作業表へのスキャン)
本ドキュメントを利用しSQLコーディング後、インデクスの使用有無、結合方法などが意図した通りにな っているか、効率の良いアクセスパスになっているかをSQLトレースのUAP統計レポート機能にて確認することを心がけてください。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2. インデクスを有効に使う記述
6
容量の多いDBを高速にアクセスする手段としてインデクスがあります。
しかし、インデクスを定義したにもかかわらず、インデクスが有効に使用されないことがあります。

© Hitachi, Ltd. 2013 , 2015. All rights reserved. 7
コーディング方法を説明する前に、まず、インデクスを どのように使ってアクセスするデータを絞り込んでいるか、 ご説明します。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-1-1 検索方式
8
解説 各検索方式の特徴について解説します。
インデクスを有効に使う記述
キースキャン
インデクスを参照してインデクス中のデータ(インデクス構成列の値または行識別子)にアクセスする方式です。
インデクスであまり絞り込めない場合でも、データページの入出力がなく、インデクスページを参照するだけなので、高速に検索できます。
インデクススキャン
インデクスを参照して条件に該当するデータを絞り込んでから、テーブルのデータをアクセスする方法です。
インデクスであまり絞り込めない場合は、データページに対するランダムな入出力が増え、性能が悪くなります。特にインデクスの全範囲が検索対象になるケースをフルスキャンと呼びます。
テーブルスキャン
検索条件の内容にかかわらず、検索対象表の全行をシーケンシャルにアクセスする方法です。
条件によって検索結果を絞り込める場合でも、すべてのデータページを参照するため、データ量が多いと性能は悪くなります。
インデクス インデクス
表データ 表データ

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
591S 671M
2-1-2 インデクスの基本構造
9
リーフページ
412M 671M
101L ・・・ 202M 302S ・・・ 412M 591L ・・・ 591S 671L ・・・ 671M
202M 412M
論理単位 説明
ルートページ B-tree構造中の最上位のインデクスページ。
下段のページを指しています。
中間ページ B-tree構造中の中間のインデクスページ。
下段のページを指しています。
リーフページ
B-tree構造中の最下位のインデクスページ。
各インデクスページのキー値とそのアドレスを持っています。
中間ページ
ルートページ
解説 インデクスは、キーとキー値から構成されます。列の内容を示した列名のことをキーといいます。また、列の値のことをキー値といいます。表を検索するときの探索条件で使用する列にインデクスを作成しておくと、表の検索性能が向上します。
: インデクスページ
インデクスのB-tree構造
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-1-3 表検索時の条件の分類
10
サーチ条件:インデクスをサーチするための条件で、 インデクスのサーチ範囲が決定
キー条件:インデクス構成列のキー値で評価する条件で、 データページ中のアクセス行を削減
その他の条件:データページ中の 行データを参照して、条件を評価
サーチ条件+キー条件: データページのアクセス行が決定
行の取出し
サーチ条件なしでのインデクス利用: インデクスリーフページのフルスキャン
インデクス
データ
解説 SQLの探索条件は、すべてサーチ条件にて評価できるのが望ましいです。
そして、それは、SQLの記述により変わります。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved. 11
次にインデクスを有効に使用するためのSQLコーディングについて示します。
なお、設計段階ではインデクスを定義しない予定であっても、後のチューニングによりインデクスを定義することが考えられるため、インデクス定義のみでインデクスが有効となるようなSQLにしておく必要があります。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-2 条件指定によるインデクス効果(1)
12
条件指定(WHERE句)の"AND" 、"OR"指定の記述によって、指定項目が同じ場合でも
インデクスの効果が低い場合があります。=条件の項目はインデクスの構成列の先頭から連続している項目をANDで指定すると効率が良いです。例を図 2-2-1、2-2-2に示します。
Point WHERE句のAND条件の指定順は、性能に影響しない
すべてand条件の場合
項目の順番が入れ替わる
~ where C1 = 10 and C2 = 20 and C3 = 30
○ ~ where C1 = 10 and C3 = 30 and C2 = 20
~ where C3 = 30 and C2 = 20 and C1 = 10
C1、C2、C3の順番には 関係なく、すべてのケースでインデクスが有効となる。
図 2-2-1 "AND"、"OR"指定 その1
複数列インデクスAを C1、C2、C3の順で定義。
インデクスを有効に使う記述
インデクスは以下の複数列インデクス A(C1,C2,C3)

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-2-1 条件指定によるインデクス効果(2)
13
すべてand条件の場合
インデクス未定義項目あり
△ ~ where C1 = 10 and C4 = 40 and C3 = 30 インデクスの先頭項目なし
× ~ where C2 = 20 and C4 = 40 and C3 = 30
and条件とor条件の場合
○ ~ where ( C1 = 10 ) or ( C1 = 11 and C2 = 22 )
× ~ where ( C1 = 10 and C2 = 20 ) or ( C3 = 30 )
一致する先頭のC1のみ インデクスのサーチ条件が有効となる。
先頭のC1が一致しないため インデクスが無効となる (リーフページのフルスキャン)。
andが優先されるが、orのそれぞれにC1があるので、インデクスは有効になる(インデクス検索をorの 両辺で2回行う)。
andが優先され、C3がorで独立していると、C3はインデクスの先頭でないのでインデクスが 無効となる (リーフページのフルスキャン)。
図 2-2-2 "AND"、"OR"指定 その2
インデクスを有効に使う記述
インデクスは以下の複数列インデクス A(C1,C2,C3)

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-2-2 条件指定によるインデクス効果(例外的な事例)
14
インデクスを有効に使う記述
SELECT C1 ,・・・・・ FROM TBL1 WHERE C1 = ? AND C3 = ? AND CFLG = ?
インデクスは以下の構成列の主キー(PK)のみ定義されていた。 TBL1(C1,C2,C3)
インデクスの第2構成列C2は、条件で未使用のため、検索範囲の絞り込みは、第1構成列でのみ実施した。
PK
TBL1
図 2-2-3 例外的な事例
主キーによる検索を実施。 しかし、性能が出なかった。原因は?
第1構成列C1は、値がすべて同じだったため、インデクス全範囲を検索となり遅かった。
インデクスを有効に使用するSQLコーディングをしていても性能が出なかった事例を示しま
す。データの値がすべて同じ列は、基本的にインデクスから削除してください。業務等の都合で当該列をインデクスから削除が出来ない場合は、後方の構成列としてください。
解説
値がすべて同じ列(C1)が インデクス構成列の先頭

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-2-3 探索条件と複数列インデクスのサーチ範囲
15
インデクス
ア ア ア
A
1
A A
2 3
ア ア ア
A
4
B B
1 2
ア ア
B B
3 4
ア ア
C C
1 2
ア ア
C C
3 4
イ イ イ
A
1
A A
2 3
イ イ イ
A
4
B B
1 2
イ イ
B B
3 4
イ イ
C C
1 2
イ イ
C C
3 4
ウ ウ ウ
A
1
A A
2 3
ウ ウ ウ
A
4
B B
1 2
ウ ウ
B B
3 4
ウ ウ
C C
1 2
ウ ウ
C C
3 4
エ エ
A A
1 2
エ エ
A A
3 4
C1= ’イ’ AND C2= ’B’ AND C3= 2
C1= ’イ’ AND C2= ’B’
C1= ’イ’
C1= ’イ’ AND C2= ’B’ AND C3>=2
C1= ’イ’ AND C2>=’B’ AND C3>=2
C1= ’イ’ AND C2>=’B’ AND C3= 2
C1= ’イ’ AND C2>=’B’
C1= ’イ’ AND C2>=’B’ AND C3<=2
C1>= ’イ’ AND C2= ’B’ AND C3= 2
C1>= ’イ’ AND C2= ’B’ AND C3>=2
C1>= ’イ’ AND C2= ’B’
C1>= ’イ’ AND C2= ’B’ AND C3<=2
C1>= ’イ’
C2= ’B’ AND C3= 2
C2= ’B’
C3= 2
C1
(C1, C2, C3) インデクスのサーチ範囲
探索条件を満たす範囲
上段と下段の差が大きい→ 効率悪
(注) 表の下3つは、リーフページのフルスキャンになり、特に効率が悪いです。
上段
下段
C2
C3
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-3 条件式での列演算の使用上の注意(1)
16
スカラ演算した条件はインデクスで評価されません、またはSQL最適化オプションに
「スカラ演算を含むキー条件の適用」を指定した場合は、インデクスのキー条件で評価
しますが効率的に絞り込めません。例を図 2-3-1、2-3-2に示します。
Point FROM句のON、WHERE句の探索条件において、列をスカラ演算しない(列を計算式の中に組み入れない)条件式に変換可能な場合、列をスカラ演算しないこと
例1
○ ~ WHERE TANKA > 950 – 105
× ~ WHERE TANKA + 105 > 950 例2
○ ~ WHERE JDATE1 = '2002' AND JDATE2 = '0301' ○ ~ WHERE (JDATE1, JDATE2) = ('2002','0301') × ~ WHERE JDATE1 || JDATE2 = '20020301'
列を直接演算しない。
図 2-3-1 スカラ演算の例 その1
列を連結して判定しない。
行値構成子で記述 すれば効率よく インデクスを使用 できる。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-3-1 条件式での列演算の使用上の注意(2)
17
例3
○ ~ WHERE SNAME LIKE 'TOKYOU%'
× ~ WHERE SUBSTR(SNAME, 1, 6) = 'TOKYOU' 例4
○ ~ WHERE TANKA = 5
× ~ WHERE TANKA * 12 = 60 例5
○ ~ (SNAME = 'xxx' AND ZSURYO = 1) OR (SNAME = 'yyy' AND ZSURYO <> 1)
× ~ SNAME = CASE WHEN ZSURYO = 1 THEN 'xxx' ELSE 'yyy' END
先頭文字比較はLIKEを使用する。
列を直接演算しない。
CASE式を使用しない。
図 2-3-2 スカラ演算の例 その2
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-4 条件式での変数/定数へのスカラ演算の使用上の注意
18
変数をスカラ演算した条件はインデクスで評価されません、またはSQL最適化オプションに「スカラ演算を含むキー条件の適用」を指定した場合は、インデクスのキー条件で
評価しますが効率的に絞り込めません。
定数をシステム定義スカラ関数、ユーザ定義関数の引数に指定した場合は、一切インデクスが使用されません。
例を図 2-4-1に示します。
Point FROM句のON、WHERE句の探索条件において、
変数をスカラ演算しない(変数を計算式の中に組み入れない)
定数をシステム定義スカラ関数、ユーザ定義関数の引数に指定しない
変数のスカラ演算
○ ~ WHERE SNAME = ?
× ~ WHERE SNAME = CAST(? AS CHAR(5))
定数のシステム定義スカラ関数
○ ~ WHERE SNAME = 'ABC'
× ~ WHERE SNAME = RTRIM('ABC ')
変数をスカラ演算しない。
RTRIMは、システム定義スカラ関数。
あらかじめ必要な演算を実施した
定数を指定する。
?パラメタに値を渡す埋込み変数は、
あらかじめCHAR(5)のデータとしておく。
図 2-4-1 変数/定数へのスカラ演算の例
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-5 中間一致の回避
19
LIKE '%c%' でも、インデクスを使用しますが(場合によっては使用しない)、インデクス
のリーフページをフルスキャンします。LIKEは、LIKE 'c%'やLIKE 'c_'のように前方一致
を指定すればインデクスの参照範囲を絞り込むことができるため、処理性能が向上することが多いです。例を図 2-5-1に示します。
Point LIKE述語は 中間一致('%xx%')、後方一致('%xxx')を避け、極力前方一致
('xxx%')になるように記述すること
○ ~ WHERE SNAME LIKE 'TOKYOU%'
○ ~ WHERE SNAME LIKE 'TOK%OU'
○ ~ WHERE SNAME LIKE 'TOK___'
× ~ WHERE SNAME LIKE '%KYO%'
× ~ WHERE SNAME LIKE '%KYOU'
× ~ WHERE SNAME LIKE '___YOU'
× ~ WHERE SNAME LIKE '_O_Y_U_'
LIKE述語のパターン文字列として?パラメタや埋込み変数を指定した場合も、上記の例のように、設定するパターン文字列を前方一致になるようにすると良いです。
図 2-5-1 LIKEの例
中間一致、後方一致は避ける。
前方一致を用いる。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-6 複数列インデクスでの前方不一致検索の回避
20
複数列インデクスで前方不一致検索(インデクス構成列の前方の列を指定しない)を
行うと、インデクスのリーフページをフルスキャンします。例を図 2-6-1に示します。
Point 複数列インデクスの先頭構成列の条件を指定せず、第2構成列以降の条件を
指定することは避ける
○ ~ WHERE ZSURYO = 20 AND COL = 'blue' ○ ~ WHERE COL = 'blue' AND ZSURYO = 20 ○ ~ WHERE ZSURYO = 20 × ~ WHERE COL = 'blue'
インデクス構成列の順と探索条件指定順は一致しなくて良い。
図 2-6-1 複数列インデクス例
インデクスは以下の複数列インデクス X01(ZSURYO,COL)
インデクスの先頭構成列のみ指定でも良い。
インデクスの後方構成列のみ指定 (リーフページのフルスキャン)。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-7 インデクス列のみ選択の使用
21
問合せ指定でインデクス列のみを選択すると、インデクス列の値は表からではなく、
直接インデクスから読み込まれるため、非常に高速に処理できます。(インデクスページ
のみの読み取りで、データページは読みません。これをキースキャンと呼びます。)
例を図 2-7-1に示します。
Point 選択式に指定する列は、必要最小限にし、さらにインデクス構成列のみ指定する
と高速化できる
○ SELECT ZSURYO, COL FROM ZAIKO WHERE ZSURYO < 100 ;
選択式も、探索条件もインデクス構成列のみ指定すると非常に高速。
図 2-7-1 インデクス列のみ選択の例
インデクスは以下の複数列インデクス X01(ZSURYO,COL)
インデクスを有効に使う記述
このことにより、探索条件に通常は指定しない列であっても、複数列インデクスに追加
することによってパフォーマンスが向上する場合があります。ただし、列サイズが小さく
頻繁に使用される場合のみ使用し、更新性能に十分注意してください。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-8 行値構成子の利用(1)
22
複数列の大小比較をする場合、以下のような指定を行うとインデクスの使用効率が悪くなります。行値構成子を用いれば、インデクスを効率よく利用することができます。
複数列を組み合わせての大小比較は、andとorの条件を組み合わせることにより
記述できますが、インデクスの使用効率が悪くなり性能上不利になります。
例を図 2-8-1に示します。
連結演算を用いた大小比較が可能であった場合でも、インデクスの使用効率が悪く
なり性能上不利になります。例を図 2-8-2に示します。
Point 複数列の組み合わせにて大小比較する場合は行値構成子を用いる
CODE、SUBCODEの組み合わせにて大小比較する場合
○ ~ WHERE (CODE, SUBCODE) > (100, 50)
× ~ WHERE CODE > 100 OR (CODE = 100 AND SUBCODE > 50)
(100, 50)よりも大きいものを検索する。行値構成子を使用すると、複数列インデクスで直接評価ができ効率が良い。
図 2-8-1 行値構成子の使用例 その1
以下の複数列インデクスは定義済み X01(CODE, SUBCODE)
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-8-1 行値構成子の利用(2)
23
XDATE、XTIMEの組み合わせにて大小比較する場合
○ ~ WHERE (XDATE, XTIME) > ('20070301', '223000')
× ~ WHERE XDATE || XTIME > '20070301223000'
連結演算などのスカラ演算を含むとインデクスの使用効率が悪い。
図 2-8-2 行値構成子の使用例 その2
以下の複数列インデクスは定義済み X02(XDATE, XTIME)
('20070301', '223000')よりも大きいものを検索する。 行値構成子を使用すると、複数列インデクスで直接評価 ができ効率が良い。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-9 完全一致にLIKEは用いない
24
LIKE述語にて完全一致の検索を行う場合は固定長文字列でもデータ長が等しいもの
しか一致しない(空白を補完しない)ことも認識してください。例を図 2-9-1に示します。
Point 完全一致の検索の場合は、LIKE述語でなく =述語を用いる
○ ~ WHERE SNAME = 'ABCD' ; × ~ WHERE SNAME LIKE 'ABCD' ;
固定長文字列SNAMEの長さとLIKE述語に指定した文字列の長さが不一致の場合、検索できない。
図 2-9-1 LIKEの完全一致は用いない
=述語の場合、列長に合わせて変数の値に空白を補完するため、長さが異なっても検索できる。
列定義は以下 SNAME CHAR(30)
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-10 任意の複数条件を組み合わせた自由検索の注意
25
LIKEのパターン文字列を変数として、実行時に変数に完全一致の文字列または'%'を与えることにより一つのSQLにて任意の複数条件を組み合わせた自由検索が実現可能
ですが、インデクスの使用効率が悪くなり性能劣化となるので、このような指定は避けてください。このような場合は、条件ごとにそれぞれのSQLを記述したり、動的SQLを組み立てたりして、UAPにて使用するSQLを選択してください。
例を図 2-10-1、 2-10-2に示します。
Point 任意の複数条件を組み合わせた検索で、LIKE述語を使用して検索条件に
汎用性を持たせない
インデクスを有効に使う記述
検索を有効にしたい列を事前に判定し、条件に有効にしたい列だけを指定したSQLで、検索を行う。
SNAMEの条件とSCODEの条件のアドホックな検索において:
SNAMEの条件だけを有効にしたい場合
○ ~ WHERE SNAME = :X1 ;
SCODEの条件だけを有効にしたい場合
○ ~ WHERE SCODE = :X2 ;
=述語として不要な条件(SCODEの条件)を指定しない。 なお、SQLオブジェクトキャッシュのヒット率を上げるために定数でなく変数を用いる。
図 2-10-1 複数のLIKE条件を組み合せて使用しない その1

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-10-1 任意の複数条件を組み合わせた自由検索の注意
26
インデクスを有効に使う記述
検索を有効にしたい列に定数を、有効にしない列に%を設定し、LIKEを使用したSQLを発行している。有効にしない列も検索対象となるため、インデクスの使用効率が悪くなる。
× ~ WHERE SNAME LIKE :X1 AND SCODE LIKE :X2 ;
SNAMEの条件だけを有効にしたい場合 X1 = 'ABCD' X2 = '%'
SCODEの条件だけを有効にしたい場合 X1 = '%' X2 = '1234' 図 2-10-2 複数のLIKE条件を組み合せて使用しない その2

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-11 NOT(!=)のインデクスの使用上の注意
27
インデクスで範囲を絞り込めるように条件の指定ができるならば、NOT(!=)を指定しないでください。NOT(!=)を使用すると、インデクスを使用した検索を行わないことが多いです。
インデクスを使用するためのNOT(!=)に関する例を図 2-11-1に示します。
Point インデクスを使用して範囲が絞り込めるならば、NOT(!=)は使用しない
○ ~ WHERE DNO > 0 × ~ WHERE DNO != 0
DNOに負数がない場合。
図 2-11-1 インデクス定義列でのNOT(!=)の変形例
インデクスを有効に使う記述
インデクスを使用して範囲をあまり絞り込めないなど、インデクスを用いたくない場合に、NOT(!=)を用いてください。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-12 インデクスソートキャンセル(1)
28
ORDER BY句の順序性は、インデクスを使用することでソート処理を行わずに保証できるため、性能向上が期待できます。また、GROUP BY句に対しても、インデクスを使用しソート処理/ハッシュ
処理を行わずにグループ化できるため、性能向上が期待できます。これをインデクスソートキャンセルと呼びます。
インデクスソートキャンセルにするために、以下のすべての条件を満たすようにしてください。
①ORDER BY句/GROUP BY句に指定する列のすべてが、同じ順序で一つのインデクスの第1構
成列から連続しているかまたは連続しない場合には、インデクス構成列の連続しない列に、=述
語(列=値指定)またはIS NULL条件列を探索条件に指定している。
②ORDER BY句のASC/DESC指定と、インデクス定義時の構成列のASC/DESC指定が同じか、
まったく逆。(本項目はGROUP BYには該当しない)
③インデクスが複数のRDエリアに分割されていない(HiRDB/パラレルサーバの場合は、1つのサーバ(BES内)で複数のRDエリアに分割されていない)。
Point ORDER BY句、GROUP BY句は、インデクスを利用できるように工夫する
探索条件中にインデクス構成列に対する絞り込みがあるか、または選択式がインデクス構成列のみで構成されている場合は、よりインデクスソートキャンセルを適用できます。
<補足事項>
インデクスを有効に使う記述 ORDER BY句、GROUP BY句の

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-12-1 インデクスソートキャンセル(2)
29
インデクスが複数のRDエリアに分割されていない場合
○ SELECT ZSURYO, DNO FROM ZAIKO WHERE SNAME = 'A' ORDER BY ZSURYO DESC, DNO ASC;
○ SELECT ZSURYO, DNO FROM ZAIKO ORDER BY SNAME ASC, ZSURYO DESC, DNO ASC;
○ SELECT ZSURYO, DNO FROM ZAIKO ORDER BY SNAME DESC, ZSURYO ASC, DNO DESC;
=述語はインデクスの第1構成列を指定。ORDER BYはインデクスの第2構成列から連続して指定している。
図 2-12-1 インデクスソートキャンセルの例
インデクスは以下の複数列インデクス X01(SNAME ASC, ZSURYO DESC, DNO ASC)
選択式はインデクス構成列のみ。ORDER BY指定列がインデクスの第1構成列から連続して指定する。
ASC/DESCがすべて逆。
インデクスを有効に使う記述
インデクスソートキャンセルとなる例を図 2-12-1に示します。
ORDER BY句、GROUP BY句の

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-12-2 インデクスソートキャンセル(3)
30
インデクスが複数のRDエリアに分割されていない場合
× SELECT ZSURYO, DNO FROM ZAIKO WHERE SNAME = 'A’ ORDER BY ZSURYO ASC, DNO ASC;
× SELECT ZSURYO, DNO FROM ZAIKO WHERE SNAME = 'A’ ORDER BY DNO ASC, ZSURYO ASC;
× SELECT ZSURYO, DNO FROM ZAIKO WHERE SNAME = 'A’ ORDER BY DNO ASC;
× SELECT ZSURYO, DNO FROM ZAIKO ORDER BY SNAME ASC, ZSURYO DESC, DNO ASC, COL ASC ;
ASC/DESCが一致しない。 ②の条件にあてはまらない例
図 2-12-2 インデクスソートキャンセルの不可の例 その1
ORDER BY指定順序とインデクス構成列順が異なる。 ①の条件にあてはまらない例
ORDER BY指定列がインデクスの第1構成列から連続せず、欠落列の=述語指定もない。 ①の条件にあてはまらない例
ORDER BY指定列にインデクスで定義されてない列がある。 ①の条件にあてはまらない例
インデクスを有効に使う記述
インデクスは以下の複数列インデクス X01(SNAME ASC, ZSURYO DESC, DNO ASC)
インデクスソートキャンセル不可となる例を図 2-12-2、2-12-3に示します。
ORDER BY句、GROUP BY句の

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-12-3 インデクスソートキャンセル(4)
31
一つのサーバ内でインデクスが複数のRDエリアに分割されている場合
× SELECT SURYO, DNO FROM ZAIKO ORDER BY SNAME ASC, ZSURYO DESC, DNO ASC;
インデクスが複数のRDエリアに分割されている。 ③の条件にあてはまらない例
図 2-12-3 インデクスソートキャンセルの不可の例 その2
インデクスは、以下 X01(SNAME ASC, ZSURYO DESC, DNO ASC) IN(RDA1, RDA2, RDA3);
インデクスを有効に使う記述
ORDER BY句、GROUP BY句の

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
2-13 集合関数MAX/MINの引数の注意
32
ひとつのSQLに異なる列を引数とする集合関数MAX、 MINを同時に指定すると、
インデクスを使用せずMAX、 MINの値を求めるため性能が悪くなります。違う引数の
MAX、 MINはSQLを分け、引数にインデクスの第1構成列を指定してください。
例を図 2-13-1に示します。
Point 一つのSQLに、異なる列を引数とするMAX、 MINを同時に指定しない
SELECT MAX(ZA.ZSURYO) FROM ZAIKO ZA; ○ SELECT MIN(ZA.DNO) FROM ZAIKO ZA;
× SELECT MAX(ZA.ZSURYO), MIN(ZA.DNO) FROM ZAIKO ZA;
一つのSQLにて、MAXとMINの引数に異なる列を指定している。
図 2-13-1 インデクスの構成列をMAX,MINの引数に指定した例
インデクスは、 X01(ZSURYO, DNO) X02(DNO)
異なる列のMAXとMINのSQL文を分けて指定する。 なお、各列は第1構成列となるようにインデクスを定義する。
インデクスを有効に使う記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3. 副問合せに関する記述
33
副問合せは、SQLの構文ベースでアクセスパス(処理手順)がほぼ決まる
ため、副問合せを使用する場合は書き方によって大きく性能が異なります。
よって、適切に使用するように心掛けてください。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-1 副問合せの使用方針
34
# 方針 メリット
1
ジョインで記述可能なSQLは副問合せを使用せず、ジョインで
記述する。
検索順序、データの突合せ方法をHiRDB
が最適化できるので、SQL構文をあまり考えなくて良い。
2 FROM句の副問合せは使用しない。
検索順序、データの突合せ方法、絞り込みのインデクスをHiRDBが最適化できるので、SQL構文をあまり考えなくて良い。
3
IN副問合せ(=ANY副問合せ)とEXISTS副問合せは、絞り込みによって使い分ける。
絞り込みを伝播できるようになりデータの処理量が削減できる。
4
IN副問合せ(=ANY副問合せ)
と=副問合せは、副問合せのヒット件数が1件かどうかで使い分ける。
インデクスを効率よく使用できるようになり、データの処理量が削減できる。
5 NOT IN副問合せ(<>ALL副問合せ)はなるべく使用しない。
NOTを含むとデータ処理量が多くなるが、NOT INは特に重いので避ける。
副問合せを使用する場合は、以下の順に考慮して使用すると良いです。
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-2 副問合せよりもジョインを使用する(1)
35
IN副問合せ、ANY副問合せ、ALL副問合せでは作業表を作成します。また、副問合せ
だと表の検索順序が限られるため、最も効率の良い順序で表を検索することができず、
表の結合で記述したほうが処理の性能が向上することが多いです。IN副問合せ、=ANY
副問合せは、結合で記述できます。図 3-2-1、図 3-2-2に、副問合せを解消できる例を示します。
Point 副問合せを用いないSQL文に変更可能な場合、なるべく副問合せを使用しない
○ SELECT ZA.SNAME FROM JUTYU DE, ZAIKO ZA WHERE DE.DNO = ZA.DNO AND ZA.ZSURYO = 20 ;
× SELECT ZA.SNAME FROM ZAIKO ZA WHERE DNO IN ( SELECT DE.DNO FROM JUTYU DE) AND ZA.ZSURYO = 20 ;
副問合せを使用すると、作業表
オーバヘッド、さらにインデクスが
使えなければ直積相当の負荷が
かかる。
ZAIKO表を先に検索して絞り込みを伝播させた方が良いが、JUTYU表を絞り込まずに先に検索してしまう。
図 3-2-1 副問合せを使用しないSQL例 その1
副問合せを使用しないで、表結合で実現。
(DE.DNOの値に重複がある場合は注意が必要)
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-2-1 副問合せよりもジョインを使用する(2)
36
○ SELECT ZA.SNAME FROM JUTYU DE, ZAIKO ZA WHERE DE.DNO = ZA.DNO AND DE.TCODE = 'A' ;
× SELECT ZA.SNAME FROM ZAIKO ZA WHERE EXISTS ( SELECT * FROM JUTYU DE WHERE DE.DNO = ZA.DNO AND DE.TCODE = 'A') ;
外への参照あり副問合せでは、 外側問合せを先に検索する。 ゆえに、外側問合せにデータの 絞り込みが無ければ、表の全件の突合せが実施され負荷が高い。
図 3-2-2 副問合せを使用しないSQL例 その2
副問合せを使用しないで、表結合で実現。
(DE.DNOの値に重複がある場合は注意が必要)
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-3 FROM句の副問合せの使用上の注意(1)
37
FROM句の副問合せを指定すると、内部導出表を作成することが多くなります。内部導出表を作成した場合、以下のような点で性能が悪くなるため、FROM句の副問合せはなるべく用いないでください。例を図 3-3-1に示します。
内部導出表は、FROM句の副問合せ結果で作成する作業表であるため、作業表へのI/Oが発生する。
内部導出表を作成すると、外側問合せに指定した探索条件は、FROM句の副問合せ結果で作成する作業表の作成後に評価するため、インデクスが用いられない。
Point FROM句の副問合せはなるべく用いない
○ SELECT B.SNAME FROM JUTYU A, ZAIKO B WHERE A.DNO = B.DNO AND A.TCODE = 'A' ;
× SELECT B.SNAME FROM (SELECT DNO, TCODE FROM JUTYU WHERE TCODE='A') A, (SELECT DNO, SNAME FROM ZAIKO) B WHERE A.DNO = B.DNO ;
内部導出表を作成する。
図 3-3-1 FROM句に副問合せを使用しないSQL例
DNOにインデクスを定義していても使用しない。
DNOのインデクスを用いたネストループジョインとなる。
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-3-1 FROM句の副問合せの使用上の注意(2)
38
× SELECT P.* FROM TBL2 T2, (SELECT T1.* , VALUE(T1.C1S, T1.C1L, 0) C1 FROM TBL1 T1 ) P WHERE T2.TBL1ID = P.ID AND P.C1 BETWEEN T2.C2 AND T2.C3 AND T2.TBL2ID = ?
図 3-3-2 FROM句の副問合せの書き換えでの性能向上例
FROM句の 副問合せ。
○ SELECT T1.* , VALUE(T1.C1S, T1.C1L, 0) C1 FROM TBL2 T2, TBL1 T1 WHERE T2.TBL1ID = T1.ID AND VALUE(T1.C1S, T1.C1L, 0) BETWEEN T2.C2 AND T2.C3 AND T2.TBL2ID = ?
マージジョイン
作業表相手だとマージジョインのみ。
TBL2ID = ?で絞り込んだが絞り込みを伝播できず性能劣化。
絞り込まれず全件検索
ネストループジョイン
TBL2ID = ?で絞り込んだ絞り込みを伝播。
実表の検索であれば、結合条件のインデクスで絞り込んで検索。
TBL2
TBL1
TBL2 作業表 P TBL1
内部導出表
FROM句の副問合せの書き換えで性能向上した例を図 3-3-2に示します。
副問合せに関する記述
演算は展開する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-4 IN副問合せとEXISTSの使い分け
39
副問合せで記述する場合には、外への参照あり/なしによって、外側問合せと副問合せのどちらを
先に検索するかが変わります。外への参照ありは外側問合せを先に、外への参照なしは副問合せを
先に検索します。そのため、絞り込める問合せを先に検索するように、外への参照あり/なしを考え
る必要があります。外への参照ありで記述する場合は、EXISTS述語の副問合せを使用してください。外への参照なしで記述する場合は、IN述語の副問合せを使用してください。
例を図 3-4-1に示します。
Point 副問合せ内を絞り込める場合は、外への参照なしIN 副問合せを使用する
副問合せより外側問合せが絞り込める場合は、外への参照ありEXISTSを使用する
○ SELECT ZA.SNAME FROM ZAIKO ZA WHERE ZA.DNO IN ( SELECT DE.DNO FROM JUTYU DE WHERE DE.TCODE = 'A') ; ○ SELECT ZA.SNAME FROM ZAIKO ZA WHERE EXISTS ( SELECT * FROM JUTYU DE WHERE DE.DNO = ZA.DNO) AND ZA.SNAME = 'A' ;
外への参照無しINの場合は、ZA.DNOに インデクスを定義して、副問合せから外側問合せへ突き合わせる。
図 3-4-1 外への参照なしIN と、外への参照ありEXISTSの使い分け
副問合せ内が絞り込める場合は、 外への参照なしINにて、副問合せを先に検索したほうが良い。
外側問合せが絞り込める場合は、 外への参照ありEXISTSにて、外側問合せを先に検索したほうが良い。
DE.DNOにインデクスを定義して、外側問合せから副問合せへ突き合わせる。
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-4-1 IN副問合せとEXISTSの使い分け(解説)
40
外への参照無し IN副問合せ
解説 外への参照有無により、先に検索する表が変わります。絞り込める表から検索できるように、外への参照有無を使い分けます。
SELECT ZA.SNAME FROM ZAIKO ZA WHERE ZA.DNO IN ( SELECT DE.DNO FROM JUTYU DE WHERE DE.TCODE = 'A' ) ;
SELECT ZA.SNAME FROM ZAIKO ZA WHERE EXISTS ( SELECT * FROM JUTYU DE WHERE DE.DNO = ZA.DNO) AND ZA.SNAME = 'A' ;
ZAIKO JUTYU
TCODE DNO
作業表
TCODE='A'
①副問合せ検索 ②外側問合せ検索
ZAIKO JUTYU
DNO SNAME
SNAME='A'
②副問合せ検索 ①外側問合せ検索
外への参照あり EXISTS副問合せ
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-5 IN副問合せと=副問合せの使い分け
41
Point 副問合せ内で1件しかヒットしない場合は、=副問合せを使用する
○ SELECT ZA.SNAME FROM ZAIKO ZA WHERE ZA.DNO = ( SELECT DE.DNO FROM JUTYU DE WHERE DE.TCODE = 'A' ) ; × SELECT ZA.SNAME FROM ZAIKO ZA WHERE ZA.DNO IN ( SELECT DE.DNO FROM JUTYU DE WHERE DE.TCODE = 'A' ) ;
副問合せが1件しかヒットしないときは、INを使用せず=を使用する。
図 3-5-1 IN副問合せと=副問合せの使い分け
主キーであるので、1件しかヒットしない。
ZA.DNOにインデクスを定義して、副問合せから外側問合せへ突き合わせる。
JUTYU表の主キー:JUTYU(TCODE)
主キーを探索条件の=条件で指定する場合など、副問合せ結果が1件であることが自明な場合は、IN副問合せ(=ANY副問合せも同様)を使用せず=副問合せを使用してくだ
さい。=副問合せであれば、作業表の作成が不要なこととインデクスが自由に使用できることから、高速化できます。例を図 3-5-1に示します。
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-5-1 IN副問合せと=副問合せの使い分け(例)
42
図 3-5-2 IN副問合せと=副問合せの使い分け例
○ CREATE VIEW VIEW1 AS SELECT * FROM TBL1 WHERE CCODE2 = (SELECT CCODE2 FROM TBL2 WHERE CNAME = 'NAME1') ;
× CREATE VIEW VIEW1 AS SELECT * FROM TBL1 WHERE CCODE2 IN (SELECT CCODE2 FROM TBL2 WHERE CNAME = 'NAME1') ; SELECT T3.CID AS C1_ ・・・・・・ FROM TBL3 T3 INNER JOIN VIEW1 T1 ON T3.CCODE1 = T1.CCODE1 WHERE ( T3.CID = 'A01' ・・・・・ ) ;
主キー
TBL3 TBL1
ネストループジョイン
TBL1(CCODE1, CCODE2) のインデクス
IN副問合せではネストループジョインと同時に評価できず、探索範囲が 広がる。
インデクスで大量データがヒットし性能劣化
ビュー表定義を=副問合せに変更して、 インデクスでの絞り込みができるようにした。
副問合せに関する記述
1件しかヒットしないので=でよい
主キー

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
3-6 NOT INの代用としてのNOT EXISTSの使用
43
表の結合では表現できないものは、副問合せで記述します。副問合せを使用するときは、なるべく外への参照を行わないようにするのが望ましいですが、外への参照を行わなくてもNOT INの場合は内部的な直積が発生するため注意が必要です。処理性能の向上のためには、NOT INを用いるよりも、外への参照をしてでもNOT EXISTSで置き換えた方が良いことが多いです。
基本的にはNOT INを使用しないようにしますが、下記例でSNAME='A'が絞り込めず、かつ副問合せの検索行数が極端に少ない場合は、NOT INを用います。絞り込める場合はNOT EXISTSを使用します。ただし、このような検索は一般的に処理負荷が高いのでなるべく避けるのが望ましいです。
Point なるべくNOT IN副問合せよりもNOT EXISTS副問合せを用いる
△ SELECT ZA.SNAME FROM ZAIKO ZA WHERE NOT EXISTS ( SELECT * FROM JUTYU DE WHERE DE.DNO = ZA.DNO) AND ZA.SNAME = 'A' ;
× SELECT ZA.SNAME FROM ZAIKO ZA WHERE ZA.DNO NOT IN ( SELECT DE.DNO FROM JUTYU DE) AND ZA.SNAME = 'A' ;
副問合せ検索行数が少ない。
図 3-6-1 外への参照なしNOT INと、外への参照ありNOT EXISTSの使い分け
あまり絞り込めない場合。
小さく絞り込める場合。
副問合せに関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
4. 結合検索に関する記述
44
結合検索を使用する場合、書き方によっては処理負荷が高くなります。
処理負荷が高くならないようにするSQLコーディングについて示します。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
4-1 表の結合(1)
45
表の結合で、処理負荷がかからないように、以下に示すように指定してください。
①結合処理は、一般的に結合表数が増えるほど処理負荷が高くなるので、結合する表数は少なくなるように工夫する。
②表の結合は、ネストループジョインになるように設計する。あまり絞り込まないで結合を行うことが必要な場合は、ハッシュジョインになるよう設計する。極力直積、マージジョインにならないようにする。これらは、外結合(LEFT OUTER JOIN)にも該当する。
③結合条件にはデータを絞り込めるように、=(等号)条件を指定する。
④結合条件にスカラ演算等の演算を使用しないようにする。スカラ演算等は直積で処理するため処理負荷が高くなる。
⑤結合条件をOR論理演算しないようにする。OR論理演算すると直積で処理するため、処理負荷が高くなる。
⑥絞り込める条件の列と、対する表の結合条件の列にインデクスを定義する。 ⑦HiRDB/パラレルサーバで外結合を行う場合は、表の分割列を結合条件に指定するよ
うにする。分割列を結合条件に指定しないと、ネストループジョインにならなくなる(HiRDB/シングルサーバ、およびHiRDB/パラレルサーバでも非分割表の場合は問題ない)。
Point
表の結合は、次の点に注意してください。
・ 不必要な表を結合しない
・ 結合条件は=(等号)条件を指定する
・ 結合条件にスカラ演算等の演算を使用しない
・ 結合条件をOR論理演算しない
・ HiRDB/パラレルサーバの外結合は、表の分割列を結合条件に指定するようにする
結合検索に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
4-1-1 表の結合(2)
46
結合条件をOR論理演算しないようにする例を図 4-1-1に示します。図 4-1-1に示す
方法が適用できない場合は、集合演算(UNION ALL)を用いる方法も検討する。
○ SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.DNO = ZA.DNO AND (ZA.ZSURYO = 0 OR ZA.SNAME = 'A') ;
× SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE (JU.DNO = ZA.DNO AND ZA.ZSURYO = 0) OR (JU.DNO = ZA.DNO AND ZA.SNAME = 'A') ;
結合条件をOR論理演算している。
図 4-1-1 直積を回避するために結合条件をORの外へ括り出す例
結合条件をOR論理演算の外へ括り出す。
結合検索に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
4-2 外結合と内結合の混在SQLでの注意(1)
47
Point 外結合と内結合を混在する場合には内結合はINNER JOIN構文で記述する
かつ
探索条件にて最も絞り込める表をFROM句の最初に指定する
外結合と内結合の混在SQLで以下を指定した場合、データが効率的に絞り込めません。
FROMにカンマで区切り表を書き並べて結合するものと、LEFT OUTER JOINを混在
して指定した場合、LEFT OUTER JOINが先に処理される。
探索条件にて絞り込む表がLEFT OUTER JOINの外表以外であった場合、LEFT
OUTER JOINの外表を最初に検索するため、表のデータが絞り込めない状態でLEFT
OUTER JOIN処理を行うので遅くなる。
上記の場合、内結合をINNER JOIN構文で記述し、探索条件にて絞り込む表をFROM句
の最初に指定します。絞り込んだ表を最初に検索し、少ない行数で結合処理を行うため高速に処理できます。なお、INNER JOIN構文、LEFT OUTER JOIN構文では、FROM句の指定順に結合します。
結合検索に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
4-2-1 外結合と内結合の混在SQLでの注意(2)
48
○ SELECT A.SURYO, B.SNAME, C.ZSURYO FROM JUTYU A INNER JOIN SYOHIN B ON A.DNO = B.DNO LEFT OUTER JOIN ZAIKO C ON B.DNO = C.DNO WHERE A.TCODE = 'A' ;
× SELECT A.SURYO, B.SNAME, C.ZSURYO FROM JUTYU A , SYOHIN B LEFT OUTER JOIN ZAIKO C ON B.DNO = C.DNO WHERE A.DNO = B.DNO AND A.TCODE= 'A' ;
カンマで書き並べたJUTYU表はLEFT OUTER JOINの後に結合する。
図 4-2-1 外結合と内結合の混在SQL例
LEFT OUTER JOINを先に処理するためSYOHIN表を絞り込まないで最初に検索する。
INNER JOINにすることでFROM句の記述順に結合する。よって、最初にJUTYU表をTCODE='A'にて絞り込んで検索する。
外結合と内結合の混在SQLでデータを効率的に絞り込める例を図 4-2-1に示します。
結合検索に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
4-3 外結合の使用上の注意
49
LEFT OUTER JOINの内表をWHERE句で絞り込むと(NULL述語は除く)、INNER JOINと同じ結果になります。また、内表の条件をWHERE句に指定するとインデクスを使用出来ず、性能が悪くなります。ゆえに、LEFT OUTER JOINの内表はON条件中で絞り込む必要があります。
例を図 4-3-1に示します。
Point LEFT OUTER JOINの内表はON条件中にて絞り込む
○ SELECT A.SNAME, B.SURYO FROM SYOHIN A LEFT OUTER JOIN JUTYU B ON A.DNO = B.DNO AND B.SURYO > 0 WHERE A.SNAME = 'A' ;
× SELECT A.SNAME, B.SURYO FROM SYOHIN A LEFT OUTER JOIN JUTYU B ON A.DNO = B.DNO WHERE A.SNAME = 'A' AND B.SURYO > 0 ;
SELECT A.SNAME, B.SURYO FROM SYOHIN A INNER JOIN JUTYU B ON A.DNO = B.DNO WHERE A.SNAME = 'A' AND B.SURYO > 0 ;
内表をWHERE句で絞り込んでいるインデクスが使用されない。
図 4-3-1 LEFT OUTER JOIN 内表の絞り込み
INNER JOINと同じ結果になる。
等価なSQL
内表はON条件中にて絞り込む インデクスを使用する。
結合検索に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
5. 表の分割に関する記述
50
分割表を使用することで性能向上が図れます。
この利点を活かすSQLコーディングについて示します。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
注文日 注文コード 商品コード 数量 ・・・
2009-01-15 10111011 13425 100
・・
2010-03-28 12104567 92473 10
・・
2011-05-30 15012890 51247 50
・・
2012-07-06 17309684 10496 30
・・
2013-11-09 19109953 30929 150
・・
表の分割とは、一つの表を特定の列の値を基に複数の領域へ分割して格納し、管理する方法です。分割した表を分割表といい、表を分割するときに指定した特定の列を分割キーといいます。SQL実行時は、探索条件に分割キーを指定すると対象となるデータが格納されている領域を判定し、必要な領域にのみアクセスします。
解説
アプリケーション側では、表の分割/非分割を
意識しなくてもアクセス可能ですが、分割キーに
よるアクセス範囲と(パラレルサーバの)BES間
データ転送方法(5-1-1参照)を意識することで性能を向上できます。
例) SELECT 商品コード, 数量 FROM 注文履歴表
WHERE 注文日 = '2011-04-01'
⇒ 検索対象のRDエリアはRDAREA3のみとなる。
表の分割の詳細につきましては、マニュアル 「システム導入・設計ガイド」ー「表の設計」を 参照してください。
表の分割に関する記述
5-1 表の分割とは
51
◆注文日による表の分割の例
注文履歴表
'2010-01-01' ~'2010-12-31'
RDAREA2
'2011-01-01' ~'2011-12-31'
RDAREA3
'2012-01-01' ~'2012-12-31'
RDAREA4
'2013-01-01'~
RDAREA5
~'2009-12-31'
RDAREA1
分割キー

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
5-1-1 BES間データ転送方法(パラレルサーバ)
52
転送方法の条件 方式 転送元 転送先
パラレルサーバで表の結合する際、BES間のデータの転送をともないます。分割表の結合では、表の分割キーを結合キーに含むことで、効率よく処理できます。
解説
表の分割に関する記述
サーバ サーバ
サーバ サーバ
分割キーによって転送先サーバを決定
サーバ サーバ
サーバ サーバ
常に同じ転送先のサーバにデータを転送
サーバ サーバ
サーバ サーバ
すべての転送先サーバにデータをコピーして転送
1対1転送
( 1 TO 1 )
下記の条件をすべて満たす場合。
・データ転送先の表がキーレンジ分割表またはハッシュ 分割表。
・転送先の表の分割キーが結合キーに含まれている。
下記の条件をすべて満たす場合。
・両方の表の分割キー、分割の種類、分割条件、格納先BESが完全に一致している。
・両方の表の分割キーが結合キーに含まれている。
分割キーが、結合キーに含まれていない。
注:分割数が多く、転送元のヒット件数が多いほど、通信および結合オーバヘッドが大きくなり、性能が悪くなる。
BES間データ
転送方法の種類
キーレンジ転送
(KEY RANGE)
ハッシュ転送
(HASH)
ブロードキャスト転送
(BROADCAST)
© Hitachi, Ltd. 2013 , 2015. All rights reserved.
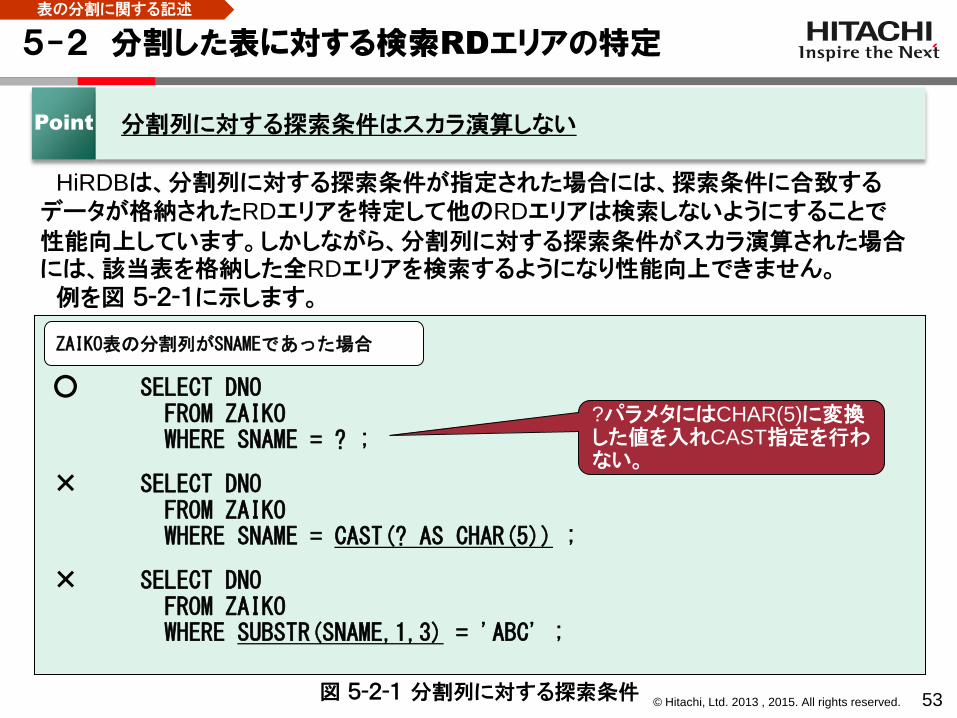
5-2 分割した表に対する検索RDエリアの特定
53
HiRDBは、分割列に対する探索条件が指定された場合には、探索条件に合致するデータが格納されたRDエリアを特定して他のRDエリアは検索しないようにすることで
性能向上しています。しかしながら、分割列に対する探索条件がスカラ演算された場合には、該当表を格納した全RDエリアを検索するようになり性能向上できません。
例を図 5-2-1に示します。
Point 分割列に対する探索条件はスカラ演算しない
○ SELECT DNO FROM ZAIKO WHERE SNAME = ? ;
× SELECT DNO FROM ZAIKO WHERE SNAME = CAST(? AS CHAR(5)) ;
× SELECT DNO FROM ZAIKO WHERE SUBSTR(SNAME,1,3) = 'ABC' ;
図 5-2-1 分割列に対する探索条件
?パラメタにはCHAR(5)に変換した値を入れCAST指定を行わない。
ZAIKO表の分割列がSNAMEであった場合
表の分割に関する記述
© Hitachi, Ltd. 2013 , 2015. All rights reserved.
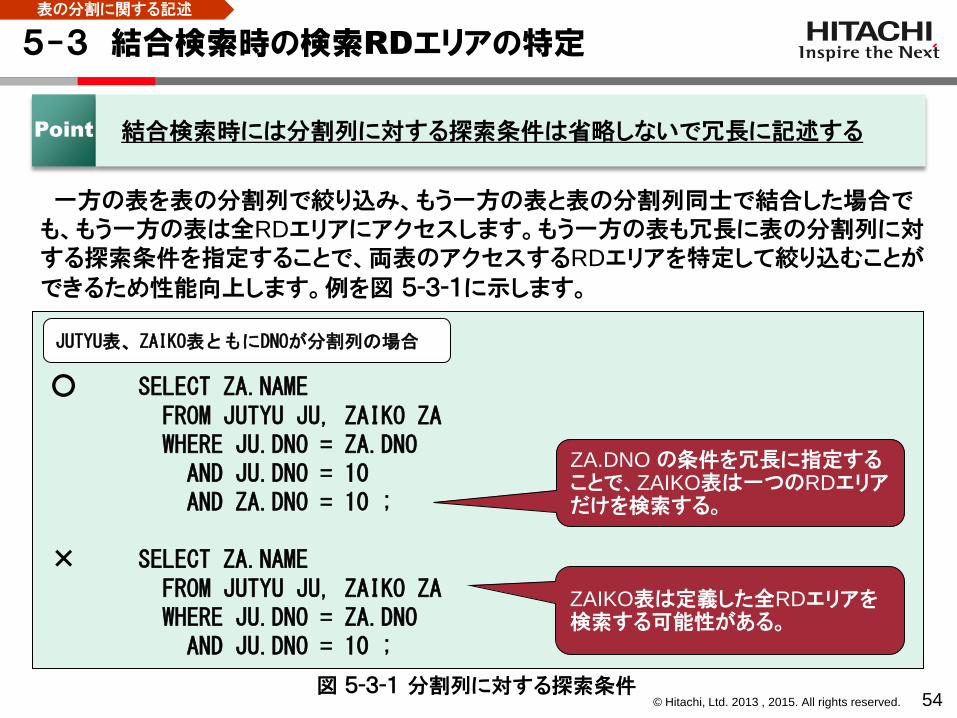
5-3 結合検索時の検索RDエリアの特定
54
一方の表を表の分割列で絞り込み、もう一方の表と表の分割列同士で結合した場合でも、もう一方の表は全RDエリアにアクセスします。もう一方の表も冗長に表の分割列に対する探索条件を指定することで、両表のアクセスするRDエリアを特定して絞り込むことが
できるため性能向上します。例を図 5-3-1に示します。
Point 結合検索時には分割列に対する探索条件は省略しないで冗長に記述する
○ SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.DNO = ZA.DNO AND JU.DNO = 10 AND ZA.DNO = 10 ;
× SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.DNO = ZA.DNO AND JU.DNO = 10 ;
ZAIKO表は定義した全RDエリアを検索する可能性がある。
図 5-3-1 分割列に対する探索条件
ZA.DNO の条件を冗長に指定することで、ZAIKO表は一つのRDエリアだけを検索する。
JUTYU表、ZAIKO表ともにDNOが分割列の場合
表の分割に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
5-4 結合検索での表の分割列と結合条件列の関係
55
HiRDB/パラレルサーバにおいて表の結合検索を行う場合、以下に示すように指定してく ださい。
=述語の結合条件に表の分割列を含むようにする。 各行の結合相手のデータがどのBES*に格納されているか特定できるため高速に 処理できる。
大量データを保持する表は、分割列を揃えるだけでなく、表の分割数と格納BESを 揃える。
結合条件に表の分割列を含まない場合は、以下のような性能低下を招きます。
各行の結合相手のデータがどのBESに格納されているかを特定できないため一つ の行に対する結合処理を結合相手の表を格納した全BESコピー転送(BROAD CASTと呼ぶ)して実行するようになるので、パラレルの効果が得られず分割損が起 きる。
LEFT OUTER JOINの場合は、外表を全行返すというSQLの仕様上、BROAD CASTが行えなくなり、両方の表の結合列での再配置を行うのでBES間のデータ 転送量が増える。さらに両方の表の再配置を行うと結合列でのインデクス検索が行 えないのでネストループジョイン以外の結合方式となり性能低下を招く。
例を図 5-4-1に示します。
Point 結合検索時に表の分割列で結合できるように表を設計する
特に、LEFT OUTER JOINの場合は内表の分割列で結合できるように表を設計する
表の分割に関する記述
* DBアクセスサーバ(Back End Server)。HiRDB/パラレルサーバの構成要素の一つです。 DBへのアクセスや排他制御を実行します。
<パラレル限定>

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
5-4-1 結合検索での表の分割列と結合条件列の関係
56
◎ SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.DNO = ZA.DNO AND JU.CNO = 10 ;
○ SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.CNO = ZA.DNO AND JU.CNO = 10 ;
× SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.DNO = ZA.CNO AND JU.CNO = 10 ;
× SELECT ZA.NAME FROM JUTYU JU LEFT OUTER JOIN ZAIKO ZA ON JU.DNO = ZA.CNO WHERE JU.CNO = 10 ;
転送先の表の結合列に分割列を含まない。 ⇒JUTYU表データのBROAD CAST 転送が発生し、負荷が高くなる。
図 5-4-1 分割列に対する探索条件
外結合の転送先の表の結合列に分割列を含まない。 ⇒マージジョインとなり、両表のデータ 転送、ZAIKO表の全件検索、作業表 作成、ソート処理が発生し、負荷が 高くなる。
転送先の表の結合列に分割列を含む。 ⇒JUTYU表のデータをZAIKO表の分割 に合わせてキーレンジ転送、または ハッシュ転送し効率が良い。
分割列同士で結合する。(さらに表の分割方法が同じなら) ⇒1TO1転送となり最も処理効率が良い
表の分割に関する記述
JUTYU表、ZAIKO表ともにDNOが分割列で、 ZAIKO表のDNOとCNOにインデクスが定義されている場合
<パラレル限定>

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6. DBの件数を考慮した記述
57
DBアクセス性能は、検索結果件数および検索中(SQL実行中)にアクセスするデータ件数に大きく依存します。この場合のSQLコーディングについて示します。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-1 表の件数の取得
58
表の件数を求めるときは、以下を指定してください。
COUNT(*)を使う。このとき可能な限りWITHOUT LOCK NOWAITを指定する。
条件式にはインデクスの定義された列を指定する。
例を図 6-1-1に示します。
条件式に指定した列がインデクスの第一構成列でない場合、性能が悪くなることがあります。
Point 表の件数を求めるとき、COUNT(*)を使用すること
○ SELECT COUNT(*) FROM ZAIKO WHERE ZSURYO > 10 WITHOUT LOCK NOWAIT ;
件数の取得には COUNT(*)を使用する。
ZSURYO にインデクスを定義する。
図 6-1-1 件数の取得のSQL例
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-2 データの存在有無の取得
59
データの存在チェックを行うときの留意事項を以下に記載します。
LIMIT 1を指定して、1件見つけたら処理を打ち切るようにする。
可能な限りWITHOUT LOCK NOWAITを指定する。
条件式と選択式にはインデクスの定義された列を指定する。
ORDER BY は作業表を作成することがあるため、指定しない。
例を図 6-2-1に示します。
Point データの存在チェックにはLIMITを使用すること
○ SELECT ZA.ZSURYO FROM ZAIKO ZA WHERE ZA.ZSURYO = 0 LIMIT 1 WITHOUT LOCK NOWAIT ;
ZSURYO にインデクスを定義する。
図 6-2-1 存在チェックのSQL例
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-3 NOT(!=)の使用上の注意
60
NOT(!=)を使用した条件に対して、HiRDBは、あまり絞り込めないと判断し結合方法、結合順序を決定します。取り得る値が1か0だけのフラグなど2値しか持たない列は、
条件に指定してもあまり絞り込めないので、NOT(!=)を使用して条件を指定することで、HiRDBは、絞り込めないことを認識できます。3値以上持つがあまり絞り込めない場合は、NOT INを用いても良いです。例を図 6-3-1に示します。
Point 絞り込めないとわかっている条件はNOT(!=)を指定する
○ ~ FROM JUTYU JU,ZAIKO ZA WHERE JU.DNO = ZA.DNO AND JU.FLAG != 1 AND ZA.ZSURYO = 20
× ~ FROM JUTYU JU,ZAIKO ZA WHERE JU.DNO = ZA.DNO AND JU.FLAG = 0 AND ZA.ZSURYO = 20
JU.FLAGは、1か0であり、かつZA.ZSURYO=20が絞り込める場合
図 6-3-1 結合を伴うSQLでのNOT使用例
JU.FLAG != 1とすることで、ZA.ZSURYO = 20のインデクスを確実に使用し、ZAからJUへのネストループジョインにて高速に処理する。
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-4 集合演算の使用上の注意(1)
61
UNION/UNION ALLなどの集合演算を使用したとき、集合演算で区切られた問合せ指定(SELECT文)は、別々に表アクセスします。また、集合演算を使用すると、作業表を作成することが多いです(UNION ALLのみの集合演算であれば集合演算のための作業表は作成しない)。そのため、集合演算を用いないSQL文にすると処理性能が向上することが多いです。
図 6-4-1に、単純な場合の例を示します。
Point 各問合せ指定の述語に指定する値だけが異なるような場合は、集合演算を 使用しないようにする
○ SELECT SNAME FROM ZAIKO WHERE ZSURYO IN (10, 20) ; × SELECT SNAME FROM ZAIKO WHERE ZSURYO = 10 UNION SELECT SNAME FROM ZAIKO WHERE ZSURYO = 20 ;
=条件の値だけが異なる場合は、UNION等の集合演算を使用しない。
図 6-4-1 集合演算を使用しないSQL文の例
IN述語を使用することにより集合演算を使用しない。
DBの件数を考慮した記述
© Hitachi, Ltd. 2013 , 2015. All rights reserved.
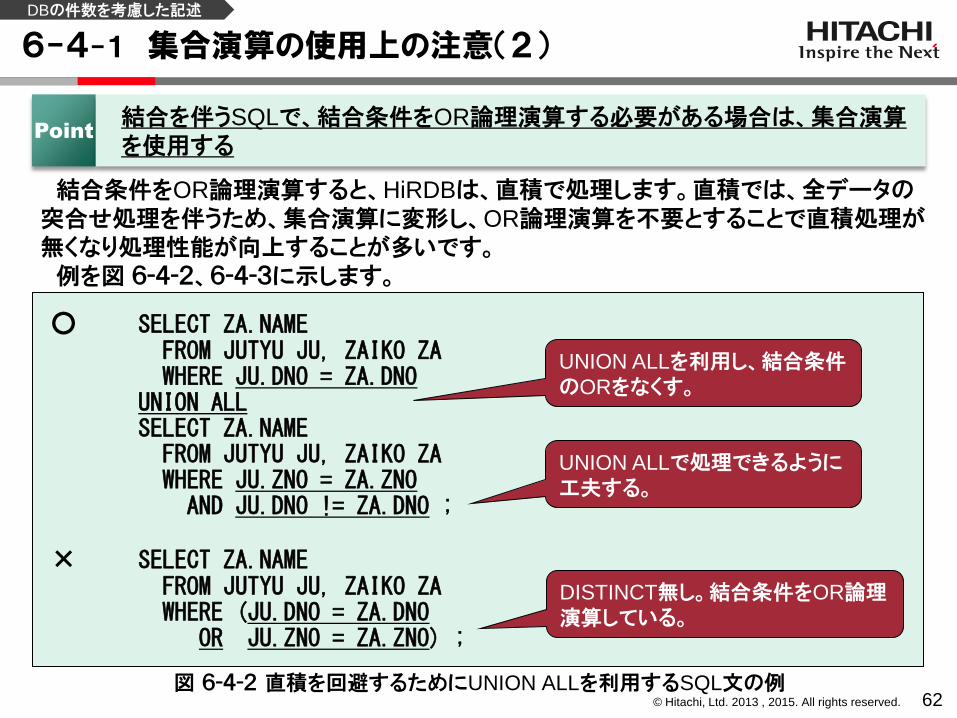
6-4-1 集合演算の使用上の注意(2)
62
結合条件をOR論理演算すると、HiRDBは、直積で処理します。直積では、全データの突合せ処理を伴うため、集合演算に変形し、OR論理演算を不要とすることで直積処理が無くなり処理性能が向上することが多いです。
例を図 6-4-2、6-4-3に示します。
Point 結合を伴うSQLで、結合条件をOR論理演算する必要がある場合は、集合演算
を使用する
○ SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.DNO = ZA.DNO UNION ALL SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.ZNO = ZA.ZNO AND JU.DNO != ZA.DNO ; × SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE (JU.DNO = ZA.DNO OR JU.ZNO = ZA.ZNO) ;
DISTINCT無し。結合条件をOR論理演算している。
図 6-4-2 直積を回避するためにUNION ALLを利用するSQL文の例
UNION ALLを利用し、結合条件のORをなくす。
UNION ALLで処理できるように工夫する。
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-4-2 集合演算の使用上の注意(3)
63
○ SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.TCODE = 'A01' AND JU.DNO = ZA.DNO UNION SELECT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.TCODE = 'A01' AND JU.SURYO = ZA.ZSURYO ; × SELECT DISTINCT ZA.NAME FROM JUTYU JU, ZAIKO ZA WHERE JU.TCODE = 'A01' AND (JU.DNO = ZA.DNO OR JU.SURYO = ZA.ZSURYO) ;
DISTINCT指定有り。
結合条件をOR論理演算している。
図 6-4-3 直積を回避するためにUNIONを利用するSQL文の例
UNIONを利用し、結合条件のOR
をなくす。
UNIONでは重複を排除するため、DISTINCTの指定が不要。
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-5 DISTINCTの使用上の注意
64
DISTINCTは重複排除のために作業表作成とソートを行います。そのオーバヘッドが
あるので、必要のないDISTINCTは使用しないでください。重複排除が必要な場合でも、選択式が列指定のみで、かつ値の重複が多い場合は、GROUP BYを用いてください。例を図 6-5-1に示します。
GROUP BYを用いた場合、以下の向上が図れます。
インデクスが定義されていれば、インデクスを利用して、重複排除を効率よく行える。
インデクスを利用できなくても、グループ分け高速化機能*(SQL最適化オプション)
が適用できれば、処理性能が向上することが多い。
Point DISTINCTは、確実に重複があり、重複を排除する必要がある場合以外 使用しない
○ SELECT SNAME FROM ZAIKO GROUP BY SNAME ;
△ SELECT DISTINCT SNAME FROM ZAIKO ;
不要なDISTINCTは使用しない。
図 6-5-1 重複排除を効率よく行うSQL文の例
選択式が列のみで、重複が多い場合の重複排除は、GROUP BYを用いる。
<補足事項> GROUP BYを使用する場合、重複排除した結果の行数が1024(クライアント環境定義のPDAGGRデフォルト値)を超えるならば、PDAGGRに1024より大きい値を指定すると処理性能が向上する場合があります。
* SQLのGROUP BY句を指定してグループ分け処理をする場合、ソートしてからグループ分けをしています。これにハッシングを組み合わせて グループ分けすることで高速なグループ分け処理が実現できます。
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-6 ビュー表の使用上の注意(1)
65
ビュー表定義に、DISTINCT、GROUP BY、結合表を指定すると、内部導出表を作成す
ることが多くなります(内部導出表の作成条件は、マニュアル「SQLリファレンス」を参照)。
ビュー表定義で内部導出表を作成した場合、以下のような点で性能が悪くなります。
内部導出表は、ビュー定義時の導出問合せ式の結果で作成する作業表であるため、
作業表へのI/Oが発生する。
内部導出表を作成すると、ビュー表検索時に指定した探索条件は、内部導出表の作
成後に評価するため、内部導出表作成時の処理件数が多くなり性能が悪くなる。
これらは、ビュー表だけでなく、WITH句を含めた名前つき導出表すべてに該当します。
例を図 6-6-1、6-6-2に示します。
Point ビュー表定義でDISTINCT指定、GROUP BY指定は注意が必要
ビュー表定義で結合表(LEFT OUTER JOIN/INNER JOIN)指定は注意が必要
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
6-6-1 ビュー表の使用上の注意(2)
66
○ CREATE VIEW V1(DNO, TCODE) AS SELECT DNO, TCODE FROM JUTYU ;
SELECT DISTINCT ZA.SNAME FROM V1 V, ZAIKO ZA WHERE V.DNO = ZA.DNO AND V.TCODE = 'A' ;
× CREATE VIEW V1(DNO,TCODE) AS SELECT DISTINCT DNO,TCODE FROM JUTYU ;
SELECT ZA.SNAME FROM V1 V, ZAIKO ZA WHERE V.DNO = ZA.DNO AND V.TCODE = 'A' ;
DISTINCTを指定すると内部導出表となる。
図 6-6-1 内部導出表とならないビュー表の例 その1
この条件はDISTINCT処理後に評価する。
重複排除が必要な場合はVIEWの外に記述する。
内部導出表とならないため、この条件はDISTINCT処理前に評価できる。
DBの件数を考慮した記述
© Hitachi, Ltd. 2013 , 2015. All rights reserved.
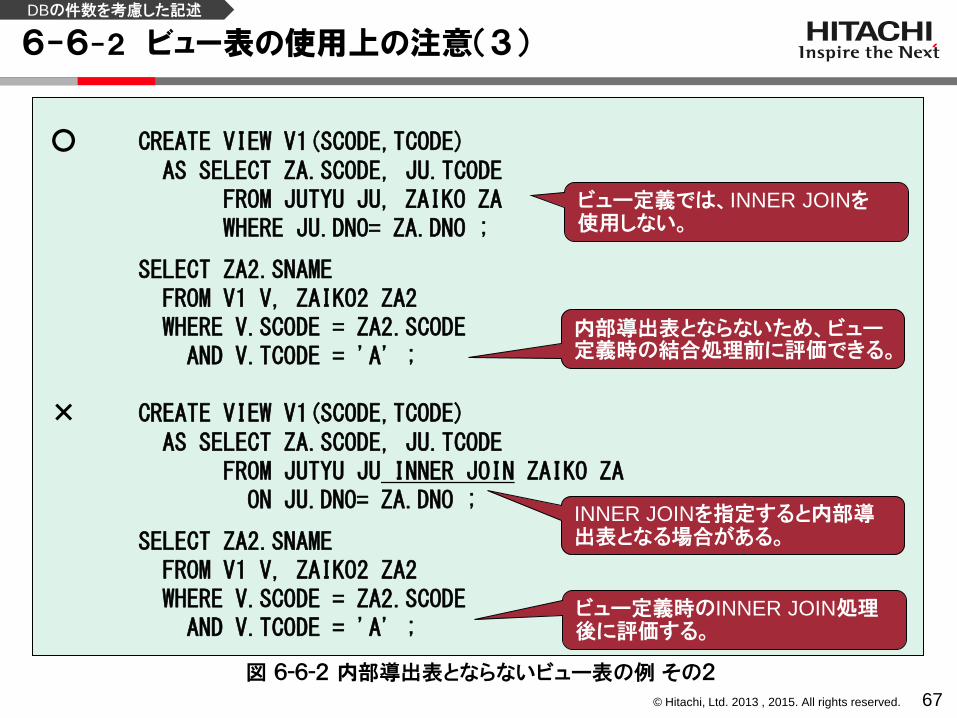
6-6-2 ビュー表の使用上の注意(3)
67
○ CREATE VIEW V1(SCODE,TCODE) AS SELECT ZA.SCODE, JU.TCODE FROM JUTYU JU, ZAIKO ZA WHERE JU.DNO= ZA.DNO ;
SELECT ZA2.SNAME FROM V1 V, ZAIKO2 ZA2 WHERE V.SCODE = ZA2.SCODE AND V.TCODE = 'A' ;
× CREATE VIEW V1(SCODE,TCODE) AS SELECT ZA.SCODE, JU.TCODE FROM JUTYU JU INNER JOIN ZAIKO ZA ON JU.DNO= ZA.DNO ;
SELECT ZA2.SNAME FROM V1 V, ZAIKO2 ZA2 WHERE V.SCODE = ZA2.SCODE AND V.TCODE = 'A' ;
INNER JOINを指定すると内部導出表となる場合がある。
ビュー定義時のINNER JOIN処理後に評価する。
ビュー定義では、INNER JOINを 使用しない。
内部導出表とならないため、ビュー定義時の結合処理前に評価できる。
図 6-6-2 内部導出表とならないビュー表の例 その2
DBの件数を考慮した記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
7. 排他に関する記述
68
HiRDBでは検索に対しても共用モードの排他を取得します。不要な排他は取得しないように排他オプションを指定すると性能向上に結びつきます。
本章では、排他オプションの適切な指定について記述します。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
7-1 排他制御(1)
69
各表の利用方法を考慮し、SQL文ごとに排他制御の記述を行ってください。
検索式ごとに排他方法は必ず検討してください。
排他オプションの指定がない場合、PDISLLVLに指定されているデータ保証レベルに
従います。PDISLLVLが省略されていた場合、WITH SHARE LOCKが仮定されるため、他のユーザが更新するとき更新待ち状態になることがあります。
排他オプションは、可能な限り WITHOUT LOCK NOWAIT(排他無し) を使用し、排他
は極力行わないでください。排他オーバーヘッドの削減(HiRDB内処理量および排他待
ちの軽減)となります。ただし、一般に検索した行を必ず更新する場合には、検索時に排
他を掛けます。
例を図 7-1-1に示します。
Point 排他オプションはなるべく記述すること
排他に関する記述
© Hitachi, Ltd. 2013 , 2015. All rights reserved.
7-1-1 排他制御(2)
70
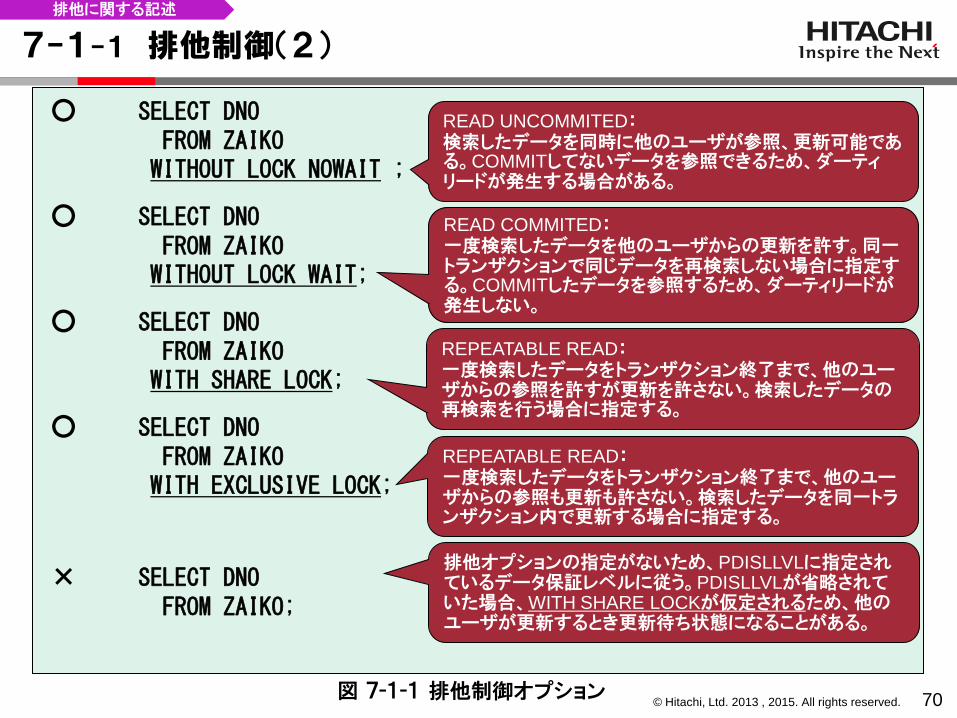
○ SELECT DNO FROM ZAIKO WITHOUT LOCK NOWAIT ;
○ SELECT DNO FROM ZAIKO WITHOUT LOCK WAIT;
○ SELECT DNO FROM ZAIKO WITH SHARE LOCK;
○ SELECT DNO FROM ZAIKO WITH EXCLUSIVE LOCK;
× SELECT DNO FROM ZAIKO;
REPEATABLE READ: 一度検索したデータをトランザクション終了まで、他のユーザからの参照も更新も許さない。検索したデータを同一トランザクション内で更新する場合に指定する。
REPEATABLE READ: 一度検索したデータをトランザクション終了まで、他のユーザからの参照を許すが更新を許さない。検索したデータの再検索を行う場合に指定する。
READ COMMITED: 一度検索したデータを他のユーザからの更新を許す。同一トランザクションで同じデータを再検索しない場合に指定する。COMMITしたデータを参照するため、ダーティリードが発生しない。
排他に関する記述
READ UNCOMMITED: 検索したデータを同時に他のユーザが参照、更新可能である。COMMITしてないデータを参照できるため、ダーティリードが発生する場合がある。
図 7-1-1 排他制御オプション
排他オプションの指定がないため、PDISLLVLに指定されているデータ保証レベルに従う。PDISLLVLが省略されていた場合、WITH SHARE LOCKが仮定されるため、他のユーザが更新するとき更新待ち状態になることがある。
© Hitachi, Ltd. 2013 , 2015. All rights reserved.
7-2 更新順序の統一
71
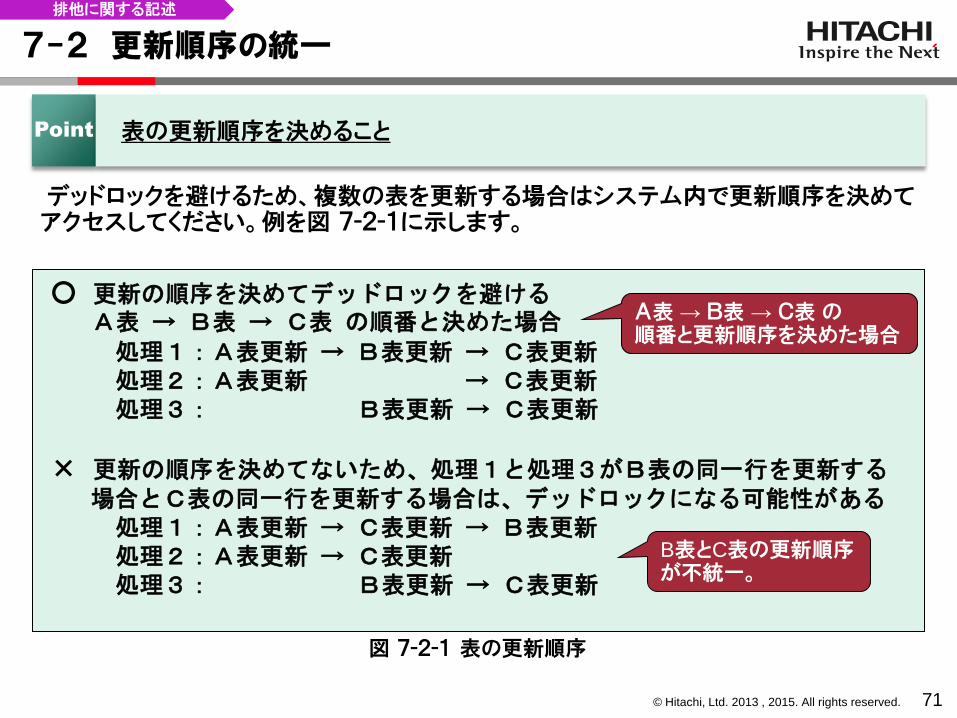
デッドロックを避けるため、複数の表を更新する場合はシステム内で更新順序を決めてアクセスしてください。例を図 7-2-1に示します。
Point 表の更新順序を決めること
○ 更新の順序を決めてデッドロックを避ける A表 → B表 → C表 の順番と決めた場合
処理1:A表更新 → B表更新 → C表更新 処理2:A表更新 → C表更新 処理3: B表更新 → C表更新
× 更新の順序を決めてないため、処理1と処理3がB表の同一行を更新する 場合とC表の同一行を更新する場合は、デッドロックになる可能性がある 処理1:A表更新 → C表更新 → B表更新 処理2:A表更新 → C表更新 処理3: B表更新 → C表更新
B表とC表の更新順序 が不統一。
図 7-2-1 表の更新順序
A表 → B表 → C表 の 順番と更新順序を決めた場合
排他に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
7-3 表単位の排他
72
LOCK文は、表単位で他のトランザクションからの検索や更新を抑止できます。このた
め、他のトランザクションからの操作を防ぎたい場合に指定を検討します。同時実行性は
失われますが、デッドロックの発生を防ぐことができます。
大量更新する場合、LOCK文は行単位の排他より、排他オーバーヘッドや排他資源の
節約ができます。このため、他のトランザクションが同じ表を操作しないときでも、LOCK
文を指定することを検討してください。
検索時は、SHAREモードで、更新時は、EXCLUSIVEモードで表にロックを掛けます。
例を図 7-3-1に示します。
Point LOCK文は、他のトランザクションからの操作を防ぎたい場合に指定を検討する
大量更新する場合は、表の操作が単独の実行であっても、LOCK文の指定を検討する
○ トランザクション開始 ↓ LOCK TABLE JUTYU IN EXCLUSIVE MODE ; ↓ DELETE FROM JUTYU WHERE JDATE < '20131001' ; × トランザクション開始 ↓ DELETE FROM JUTYU WHERE JDATE < '20131001' ;
大量削除などの大量更新 により、排他資源が枯渇し エラーとなる。
図 7-3-1 LOCK TABLE文の使用
LOCK文を発行する。 更新時は、「IN EXCLUSIVE MODE」 参照時は、「IN SHARE MODE 」 (注)SQL Executerなどの自動コミットは解除しておく必要がある。
排他に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
7-4 FOR UPDATEの使用上の注意
73
FOR UPDATEは、カーソルを使って更新するための検索、または更新中の表を検索するために指定するオプションです。通常は、暗黙的にEXCLUSIVEの排他が掛かりますが、クライアント環境変数PDISLLVLの指定によってはEXCLUSIVEの排他がかからない場合があるので、FOR UPDATEを排他オプションの代用にはしないでください。
例を図 7-4-1に示します。
Point 排他取得する目的では、FOR UPDATEでなく、WITH EXCLUSIVE LOCKを指定する
○ SELECT C2 FROM T1 WHERE C1 > 0 WITH EXCLUSIVE LOCK ; ○ SELECT C2 FROM T1 WHERE C1 > 0 WITH EXCLUSIVE LOCK FOR UPDATE ; × SELECT C1 FROM T1 WHERE C1 > 0 FOR UPDATE ;
更新前提で排他取得する場合は、排他オプションとFOR UPDATEの両方を指定する。
図 7-4-1 検索でEXCUSIVEの排他を取得する場合
排他取得だけが目的の場合は、 排他オプションのみを指定する。
クライアント環境定義にPDFORUPDATEEXLOCK=YESを指定すると、FOR UPDATE指定によって、必ず
EXCLUSIVEの排他を取得するようになります。他DBMSからのUAPの移行などで、FOR UPDATE指定時にEXCLUSIVEの排他を適用したい場合は、本指定の検討をしてください。バージョン09-50以降では、オペランド省略時動作が推奨モードの時、PDFORUPDATEEXLOCKを省略するとYESが仮定されます。
<補足事項>
排他に関する記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
8. 更新に関する記述
74
更新処理では二重更新、排他待ちやデッドロックになる場合があります。
これらを起こさないためのSQLコーディングについて示します。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
8-1 更新SQLでの二重更新に対する注意(1)
75
UPDATEにて更新後の値が、インデクスで絞り込んだ範囲に含まれる場合、同一行を
二重更新(二回更新)することがあります。DBの整合性は保たれますが、SQL連絡領域
の更新行数には述べ更新行数が通知されます。更新行数を意識するアプリケーションで
は、注意してください。例を図 8-1-1に示します。
Point インデクスを使用して絞り込んだデータに対し、そのインデクス構成列の更新を する場合は、更新後の値が探索条件にヒットしないように記載する
○ UPDATE T1 SET C1 = 10 WHERE C1 > 0 AND C1 <> 10 ;
△ UPDATE T1 SET C1 = C1 + 10 WHERE C1 > 0 ;
× UPDATE T1 SET C1 = 10 WHERE C1 > 0 ;
C1の更新後の値がヒットしないような探索条件を指定する。
図 8-1-1 UPDATEで探索条件に使用するインデクスを更新する場合
更新値の指定にスカラ演算を含む場合は、作業表にデータを一旦退避するので二重更新することはない。
探索条件で使用するインデクスの構成列を更新する場合は、更新行数が二重にカウントされるので注意が必要。
更新に関する記述
インデクス定義 T1(C1)

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
8-1-1 更新SQLでの二重更新に対する注意(2)
76
カーソルを使った更新でも、同様に二重更新されることがあるので、更新後の値が探索条件にヒットしないようにしてください。例を図 8-1-2に示します。
○ SELECT C2 FROM T1 WHERE C1 > 0 AND C1 <> 10 WITH EXCLUSIVE LOCK FOR UPDATE ; UPDATE T1 SET C1 = 10 WHERE CURRENT OF カーソル名 ;
× SELECT C2 FROM T1 WHERE C1 > 0 WITH EXCLUSIVE LOCK FOR UPDATE ; UPDATE T1 SET C1 = 10 WHERE CURRENT OF カーソル名 ;
C1の更新後の値がヒットしないような探索条件を指定する
図 8-1-2 カーソルを用いた更新で探索条件に使用するインデクスを更新する場合
検索で使用するインデクスの構成列を更新する場合は注意が必要。
以下のいずれかの指定の場合、UPDATEで探索条件に使用するインデクス構成列を更新すると、
必ず作業表にデータを一旦退避するので、二重更新されることはありません。しかし作業表作成のオーバヘッドかかるため、性能が劣化します。
システム定義に、pd_indexlock_mode =KEY (デフォルトはNONE:「インデクスキー値無排
他」)を指定
SQL最適化オプションから"DETER_WORK_TABLE_FOR_UPDATE"(デフォルトで仮定さ
れる:「更新SQLの作業表作成抑止」)を外す
<補足事項>
更新に関する記述
インデクス定義 T1(C1)

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
9. アプリケーション上での記述
77
HiRDBにおける性能向上、保守性向上のためのアプリケーション記述の
ガイドラインを示します。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
9-1 埋込み変数の使用
78
DBMSはSQL文の解析(SQLオブジェクト作成)→実処理の2ステップでSQL文を実行します。SQL文の解析処理を高速化するため、SQL文とその解析結果はSQLオブジェクト用バッファにキャッシュされます。探索条件の値だけが異なるSQLを複数回発行する場合は、埋込み変数を利用し、同一のSQL文を使いまわすようにします。すると、HiRDBはキャッシュを使用し、SQLの解析処理を省略するため、性能が向上します。また、埋込み変数を用いると値が変化する箇所が明確になり、可読性・保守性が向上します。
例を図 9-1-1に示します。動的SQLの場合は、?パラメタを利用してください。
Point 探索条件の値だけが異なるSQL文が2つ以上ある場合は埋込み変数を利用する
○ SELECT SNAME FROM ZAIKO WHERE ZSURYO = :XSURYO ;
× SELECT SNAME FROM ZAIKO WHERE ZSURYO = 123 ;
× SELECT SNAME FROM ZAIKO WHERE ZSURYO = 987 ;
別々のSQL文として発行しない
図 9-1-1 埋込み変数の例
埋込み変数にそれぞれ123、987を代入して発行
アプリケーション上での記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
9-2 比較時の型一致
79
INT型とDECIMAL型など、異なる型の列を比較する場合、内部で型の変換処理が発生し、オーバヘッドがかかります。無駄な処理を省き、型変換を明示するために予め比較対
象の型を合わせておきます。定数指定の場合は、HiRDBがSQL解析時に型変換を行う
場合もありますが、埋込み変数などの変数指定時は、各行を評価するごとに型変換処
理を行うため、特に注意が必要です。
列比較時における型の例を図 9-2-1に示します。
Point 探索条件では、予め比較の型を合わせておく
○ ~ WHERE ZSURYO = :XX × ~ WHERE ZSURYO = :YY
YYはINT型
図 9-2-1 列比較時における型の例
XXはDEC(3)型
ZSURYOはDEC(3)型
アプリケーション上での記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
9-3 配列FETCHの使用
80
ヒット件数が多い場合には、配列FETCHを使用します。配列FETCHは、FETCH文でINTO句に配列型の埋込み変数を指定することで複数行取得できます。複数の検索結果の転送をまとめることで、通信量削減による性能向上が期待できます。
配列FETCHを適用できない場合は、ブロック転送機能を使用してください。
例を図 9-3-1に示します。
Point ヒット件数が多い場合には、配列FETCHを使用する
◎ FETCH カーソル名 INTO :埋込み変数配列:標識変数配列
○ クライアント環境定義 PDBLKF=50
配列変数にて複数行を一括してFETCHする。
図 9-3-1 配列FETCH、ブロック転送の指定例
複数行の検索結果を一括して転送する。転送行数50は適切にチューニングする。
アプリケーション上での記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
9-4 表中の全行の削除はPURGE TABLE文を使用
81
表のすべての行を削除する場合、PURGE TABLE文を使用してください。PURGE
TABLE文の場合は、表データの管理情報をクリアします。このため、DELETE文を実行し
て一つ一つの行を削除するより、高速に表を空にします。また、管理情報をクリアするた
め、削除した領域は再利用可能となり、使用中空きページが発生しません。
なお、PURGE TABLE文が成功すると自動的にCOMMITされ、ROLLBACKできないこ
とに留意してください。例を図 9-4-1に示します。
Point 表中の全行を削除する場合は、PURGE TABLE文を使用する
○ PURGE TABLE ZAIKO ; × DELETE FROM ZAIKO ;
WHERE句指定なしのDELETE文を使用して表中のデータをすべて削除
図 9-4-1 PURGE TABLE文で表中の全データ削除例
アプリケーション上での記述
© Hitachi, Ltd. 2013 , 2015. All rights reserved.
9-5 検索のみのトランザクション処理時の注意
82
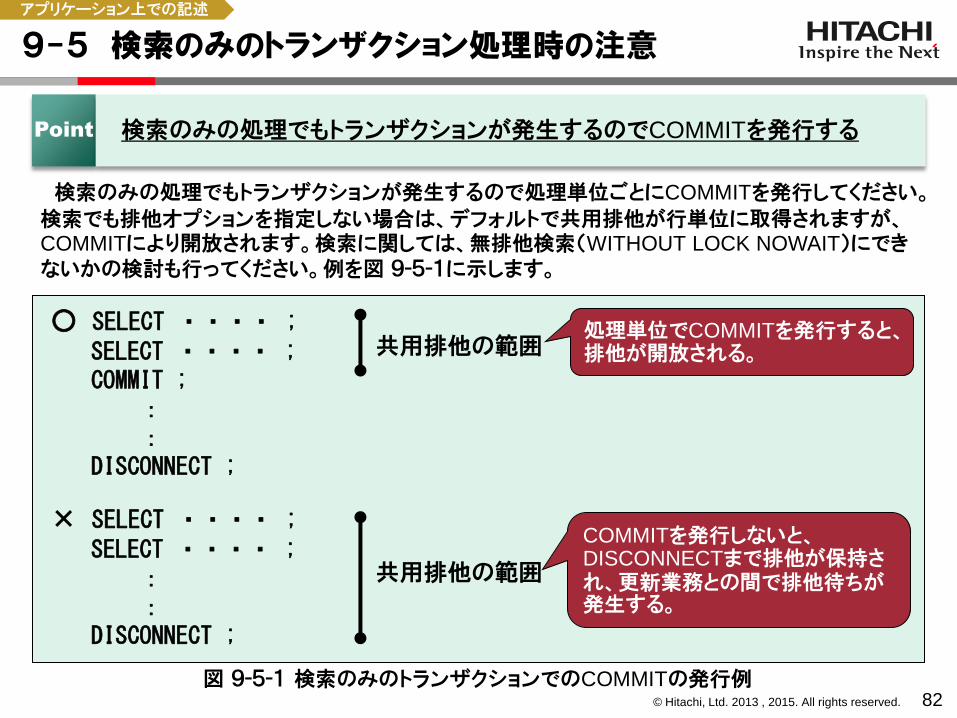
検索のみの処理でもトランザクションが発生するので処理単位ごとにCOMMITを発行してください。
検索でも排他オプションを指定しない場合は、デフォルトで共用排他が行単位に取得されますが、COMMITにより開放されます。検索に関しては、無排他検索(WITHOUT LOCK NOWAIT)にできないかの検討も行ってください。例を図 9-5-1に示します。
Point 検索のみの処理でもトランザクションが発生するのでCOMMITを発行する
○ SELECT ・・・・ ; SELECT ・・・・ ; COMMIT ; : : DISCONNECT ;
× SELECT ・・・・ ; SELECT ・・・・ ; : : DISCONNECT ;
COMMITを発行しないと、DISCONNECTまで排他が保持され、更新業務との間で排他待ちが発生する。
図 9-5-1 検索のみのトランザクションでのCOMMITの発行例
共用排他の範囲
共用排他の範囲
処理単位でCOMMITを発行すると、 排他が開放される。
アプリケーション上での記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10. 保守性を向上させるための記述
83
SQL文のリーダビリティを向上させるために、SQL文のコーディング規約を設けます。本章ではSQL文の標準スタイルについて規定します。
本章のSQL例で使用するEMP表の定義構造を以下に示します。
列名 EMP_NO ENAME SAL DEPT_NO データ型 INT NVARCHAR(50) INT INT
EMP表の定義構造

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10-1 キーワード
84
名前を指定する場合、引用符(")で囲んで指定することを推奨します。なお、名前を引用符(")で囲んだ場合、半角英小文字、及び半角英大文字は区別して扱います。
名前には、予約語と同じ名前を指定できませんが、引用符(")で囲んだ場合は、予約語と同じ名前を指定できます。SQLの拡張に伴って、システムに登録する予約語を追加する場合があるので、名前はあらかじめ引用符(")で囲んで指定しておくと、追加した予約語と重複する問題が発生しません。
ただし、次に示す名前をUAPで使用する場合は、SQLの予約語と同じでも引用符(")で囲まないで指定してください。
・ カーソル名
・ SQL文識別子
・ 埋込み変数名、標識変数名、ホスト識別子
※本ガイドラインの他の例では、スペースの都合で引用符(")を省略しています。
Point 識識別子等の名前は、引用符(")で囲む
保守性を向上させるための記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10-2 表名の付与
85
表名を付与することにより列が属している表を明確化することができ、可読性・保守性が高まります。 また同じ表を結合する場合、または副問合せで同じ表の列を参照する場合に備えて、表名として相関名を使用すると良いです。
表名付与の例を図 10-2-1に示します。
Point SELECT文においては、(単一の表に対する処理でも)すべての列名を表名(
または相関名。名称が短くできるため相関名の方が良い)で修飾すること
○ SELECT EM.ENAME, DE.DNAME FROM EMP EM, DEPT DE WHERE EM.DEPT_NO = DE.DEPT_NO AND EM.SAL > 1000 ;
× SELECT ENAME, DNAME FROM EMP, DEPT WHERE EMP.DEPT_NO = DEPT.DEPT_NO AND SAL > 1000 ;
図 10-2-1 列名の接頭辞使用の例
※本ガイドラインの他の例では、スペースの都合で表名を省略している場合があります。
列名に表名が無い
列名に表名が無い
相関名を付与
相関名を付与
保守性を向上させるための記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10-3 列の明示的指定(1)
86
列の指定時にすべての列を取り出す「*」を指定すると、解析の処理時間が増大します。
それだけでなく、列の順番は物理設計(性能・格納効率を考慮し、可変長の列を最後尾に入れ替える)・列の追加などによって変更される可能性が高く、列の順番に依存したSQL
文はバグの原因となります。また無駄な列を指定していれば、その分処理・転送時間が増加します。
検索時の指定の例を図 10-3-1に、挿入時の例を図 10-3-2に示します。
Point
列の指定を「*」で省略しないこと
不要な列の情報を取得しないこと
INSERT時の列指定を省略しないこと
保守性を向上させるための記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10-3-1 列の明示的指定(2)
87
○ SELECT EM.EMP_NO, EM.ENAME FROM EMP EM ; ○ SELECT EM.EMP_NO, EM.ENAME, EM.SAL, EM.DEPT_NO FROM EMP EM ; × SELECT EM.* FROM EMP EM ;
業務に必要な列のみ参照する
全列が必要な場合も*を使用せず、明示的に指定
*を使用しない
図 10-3-1 SELECT文における列指定の例
保守性を向上させるための記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10-3-2 列の明示的指定(3)
88
○ INSERT INTO EMP(EMP_NO, ENAME) VALUES (200007, N'スカート') ; ○ INSERT INTO EMP(EMP_NO, ENAME, SAL, DEPT_NO) VALUES (200008, N'ブラウス', 1000000, 1080) ; × INSERT INTO EMP VALUES (200008, N'ブラウス', 1000000, 1080) ;
図 10-3-2 INSERT文における列指定の例
全列に挿入しない場合、 列指定の省略は不可
全列に挿入する場合でも、 列を明示的に指定する
全列に挿入する場合、列指定を省略した悪例
保守性を向上させるための記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10-4 ORDER BY句における明示的列指定
89
ORDER BY句では何列目でソートするかを数字で指定することも可能ですが、列順に依存するため保守性に劣ります。よってORDER BY句では列名を使用します。
また、ASC(昇順)、DESC(降順)の指定を明記してください。例を図 10-4-1に示します。
Point ORDER BY句では列名を使用すること
ASC(昇順),DESC(降順)の指定を省略せず明記すること
○ SELECT EM.EMP_NO, EM.ENAME, EM.SAL FROM EMP EM; ORDER BY EM.EMP_NO ASC, EM.SAL ASC ;
× SELECT EM.EMP_NO, EM.ENAME, EM.SAL FROM EMP EM ORDER BY 1 ASC, 3 ASC ;
図 10-4-1 ORDER BY句の使用例
ソート順をソート項目指定番号で
指定しないこと
ORDER BY句では、列名で指定
保守性を向上させるための記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
10-5 SQL文の記述
90
動的SQLを繰り返し用いる場合、SQLオブジェクトにヒットしSQLの前処理を省略するためには、SQL文の一字一句が大文字小文字も含めてまったく同じである必要があります。
条件の値が異なれば、SQLオブジェクトがヒットしなくなります。よって、?パラメタ、埋込み変数を用いることにより、SQLオブジェクトにヒットするようにできます。
?パラメタを用いる例を図 10-5-1に示します。埋込み変数を用いる例については、
「9-1 埋込み変数の使用」を参照してください。
Point SQL文の記述は、大文字または小文字のいずれかに統一することが望ましい
条件の値が異なるだけのSQL文は、?パラメタ、埋込み変数を用いる
○ SELECT ZA.ZSURYO FROM ZAIKO ZA WHERE ZA.TANKA > ? ; × SELECT ZA.ZSURYO FROM ZAIKO ZA WHERE ZA.TANKA > 100 ;
図 10-5-1 ?パラメタの使用例
条件の値100を200、300…など
値を変更して繰り返し検索する
場合、?パラメタを用いる。
保守性を向上させるための記述

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
11. おわりに
91

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
11-1 おわりに
92
これからもHiRDBに ご期待ください!

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録A. SQLの最適化指定
93

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録A-1 使用インデクスのSQL最適化指定の適用検討
94
アプリケーション内でDBをアクセスする場合、SQL文が使用するインデクスを確認します。通常HiRDBのオプティマイザが自動的に最適なインデクスを選択しますが、場合によっては、効率の悪いインデクスを選択する場合があります。
今後、アプリケーションを変更(新規を含む)する場合、DBアクセス時に使用するインデクスをSQL
トレースで確認し、最適なインデクスが選択されていない場合には、使用するインデクスを明示的に指定するWITH INDEX句を記述し、使用するインデクスを固定することを推奨します。
(オプティマイザとWITH INDEX句の指定が異なる場合は、できるだけ性能測定を行います。)
解説 使用インデクスを指示したい場合のSQL最適化指定の使い方について解説します。
HiRDBが、ヒット件数が多くてアクセス効率の悪い場合、 SQL最適化指定の適用を検討する SELECT SNAME FROM ZAIKO WHERE TANKA <= 500 AND ZSURO = 100; TANKAで効率よく絞り込める場合 SELECT SNAME FROM ZAIKO WITH INDEX (IDX1) WHERE TANKA <= 500 AND ZSURO = 100; TANKAとAND条件のZSURYOでさらに絞り込める場合 SELECT SNAME FROM ZAIKO WITH INDEX (IDX1,IDX2) WHERE TANKA <= 500 AND ZSURYO = 100;
図 A.1-1 WITH INDEX句を指定した指定例
インデクス定義 IDX1(TANKA) IDX2(ZSURYO)

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録A-2 結合方式のSQL最適化指定の適用検討
95
HiRDBのオプティマイザが自動的に効率の良い結合方法を選択しますが、稀に悪い結合方法を選択する場合があります。その場合、個別のSQLに効率の良い結合方法をチューニングするためにSQL最適化指定を指定します。ただし、指定できるのは、INNER
JOINまたはLEFT OUTERの構文のみです。
解説 結合方式を指示したい場合のSQL最適化指定の使い方について解説します。
HiRDBのオプティマイザが効率の悪い結合方法を選択した場合のSQL SELECT ZA.ZSURYO, ZA.DNO FROM ZAIKO ZA, JUTYU JU WHERE ZA.ZSURYO = JU.SURYO ; 個別のSQLで効率の良い結合方式のSQL最適化指定した場合 SELECT ZA.ZSURYO, ZA.DNO FROM ZAIKO ZA INNER JOIN BY NEST JUTYU JU ON ZA.ZSURYO = JU.SURYO ; SELECT ZA.ZSURYO, ZA.DNO FROM ZAIKO ZA INNER JOIN BY HASH JUTYU JU ON ZA.ZSURYO = JU.SURYO ; SELECT ZA.ZSURYO, ZA.DNO FROM ZAIKO ZA INNER JOIN BY MERGE JUTYU JU ON ZA.ZSURYO = JU.SURYO ;
個別のSQLで結合方式のSQL最適化指定すると、効率が改善される。
図 A.2-1 SQL最適化指定を指定した例
BY NEST を指定してネストループジョインで結合する。 絞り込める表を外表に指定する。
BY HASH を指定してハッシュジョインで結合する。 ハッシュ表のサイズが小さくなる表を内表に指定する。
BY MERGEを指定してマージジョインで 結合する。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録B. 定義に関する記述
96

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録B-1 表の属性
97
NULL値の利用が不要であり、かつ可変長列の使用の必要がない場合は、極力FIX表を使用します。ただし、FIX表にするために、可変長文字列を固定長文字列に変換する場合は、DB容量が増加しないように注意する必要があります。
FIX表の場合、以下について向上が図れます。
FIX属性を指定していない表と比べて、物理的な行長が1列で2バイト短くなるので、
列数の多い表の場合はディスク所要量を削減できる。
UAPで行単位インタフェースが使用できるため、列数が多くてもアクセス性能を向上
できる。
Point NULL値の利用が不要であり、かつ可変長列の使用の必要がない場合は、 極力FIX表を 使用する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録B-2 列の属性
98
A) 十数バイト以下の列または格納されるデータが全行ほぼ同じ長さの場合、CHAR属性を使用する。VARCHARにはしない。
B) 小数点以下を使用しない場合はINTEGERを使用する。演算負荷が高いので、DECIMAL
は使用しない。
C) 金額のデータにはFLOATを使用しない。誤差が出る。
D) 半角文字と全角文字が混在して格納される値がある場合に限り混在文字データ型(MCHAR)を指定する。
E) 混在文字データ型(MCHAR)では半角文字、全角文字を意識するオーバヘッドが発生し性能劣化を引き起こすため格納文字種別が半角/全角に特定できる場合は文字データ型(CHAR)、各国文字データ型(NCHAR)を指定する。
F) VARCHAR/CHAR型に全角文字を格納すると、LIKE述語で正しく判定されないので全角文字を格納する場合は、NVARCHAR/NCHAR型またはMVARCHAR/MCHAR型を指定すること。
G) 実長256バイト以上となることが多い文字列データ型の列の定義時には、NO SPLITを指定すると格納効率が向上する。バージョン09-50以降、NO SPLITを常に適用する。
H) データ長が長くて非FIX表のCHAR、MCHAR、NCHARの後方に空白が多い場合に、SUPPRESSを指定する。スペースを抑止してDBに格納することにより、ディスク容量を削減する。
Point 列属性は、適切なものを指定する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録B-3 インデクス定義
99
A) PRIMARY KEYは主キーを明確にするために有効である。しかしPRIMARY KEYの
インデクスは、インデクス名が自動的に決定されるため、インデクス専用グローバルバッファを定義するときは保守性が悪くなる。そのため、PRIMARY KEYには、専用のインデクス格納用RDエリアを定義し、そのRDエリアにグローバルバッファを定義したほうが良い。また、PRIMARY KEYのインデクス構成列を変更するためには、表の再定義が必要になるので注意が必要である。
B) インデクス定義は、アクセスするデータを絞り込める条件の列に定義する。データページのI/O回数を大きく削減する。
C) 各探索条件のパターン、各探索条件によるヒット件数、ソートの有無、更新列、および実行頻度等に基づき、インデクスのサーチ範囲、データのアクセス回数を考慮し、インデクスの構成列、構成順序、インデクス数を決定する。
D) インデクスの未使用領域比率の比率指定は、データロード後に更新がない場合や、キー値が昇順にしか追加されない場合に、0を指定する。ディスク容量を節約やバッファの利用効率が良くなる。均等に更新される場合は、更新頻度に応じて未使用領域作成しておくことによって、インデクススプリットの発生を抑えることができる。
E) UNBALANCED SPLITは、連続した中間キー値の追加が頻繁に発生する場合に指
定する。最終ページ以外のリーフページの追加位置によって分割位置を変えることで、スプリットの発生頻度を削減する。
Point インデクス設計時には、各種オプションにも留意する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録B-4 表オプション
100
A) 表の未使用領域の比率の指定(PCTFREE)
データロード後にデータの参照、データ入力のみの場合は0を指定することで、
ディスク容量を削減できる。
NULLの列にデータを入れるとき、更新してデータが長くなる(更新前のデータが
NULLまたは更新後より短い)場合0以外を指定することで、データの格納に乱れが
ないので性能の劣化を防ぐ。
B) 表中のDECIMALデータの前0サプレス指定(SUPPRESS)
非FIX表で、DECIMALデータの定義精度に対してデータ中の前0が多い場合に、
前0を除いてDB中に格納することによって、ディスク容量を削減する。
C) WITHOUT ROLLBACK
採番のために使用する表(採番管理表)では、排他が集中して、同じ実行性が悪くな
らないように、表定義時にWITHOUT ROLLBACKオプションを指定する。更新完了
後は、ロールバックされないので、番号が跳ぶ可能性があるので注意する。
Point 表設計時には、各種オプションにも留意する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録B-5 順序数生成子の使用上の注意
101
A) 採番には、採番管理表を用いて採番する方法と、自動採番機能(順序生成子を使用する)を使用する方法がある。自動採番機能は、INSERTやUPDATEを実行する場合、採番した値が確認できないので、採番処理中でも採番した値が確認しやすい採番管理表を用いて採番する方法を主に用いる。
B) 自動採番機能を使用する場合に、採番した値の確認は採番処理が終了した後に検索処理を行なう。また、主キーは採番して入力する列とは別の列に定義する。
C) 順序数生成子の出力間隔は、大きく指定することでログ出力回数が削減されるため、処理性能が向上する。
Point 採番の方式には複数あり、用途に合ったものを使用する
採番管理表を用いて採番を管理する 順序数生成子を用いて採番を管理する
図 B-5-1 採番の例
INSERT INTO SEQUENCE_TBL VALUES('T1',1); : DECLARE CUR1 CURSOR FOR SELECT SEQ_NO FROM SEQUENCE_TBL WHERE TABLE_NAME='T1' FOR UPDATE OF SEQ_NO WITH EXCLUSIVE LOCK; : OPEN CUR1 ; FETCH CUR1 INTO :X_SEQ_NO ; UPDATE SEQUENCE_TBL SET SEQ_NO=:X_SEQ_NO +1 WHERE CURRENT OF CUR1 ; CLOSE CUR1 ; : INSERT INTO T1 (DNO,ZNO,SNAME_ID) VALUES(:X_SEQ_NO,104,204);
INSERT INTO T2(DNO,ZNO,SNAME_ID) VALUES(NEXT VALUE FOR SEQ1,104,204) ;
採番した値を確認できる。
採番管理表の定義 CREATE FIX TABLE SEQUENCE_TBL (TABLE_NAME CHAR(30), SEQ_NO INTEGER )WITHOUT ROLLBACK;
順序数生成子の定義 CREATE SEQUENCE SEQ1 AS INTEGER START WITH 10 INCREMENT BY 10 MAXVALUE 999 MINVALUE 10 CYCLE LOG INTERVAL 10 IN RDDATA10;
採番した値を確認できない。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録C. SQLをチューニングするパラメタの定義
102

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録C-1 結合検索に関する記述(1)
103
表を数%以下に絞り込んでジョインする場合は、ネストループジョインが一番高速です。HiRDBはSQL最適化オプションのデフォルト値にネストループジョイン優先("PRIOR_NEST_JOIN")を含んでおり、=述語で絞り込まれたジョインであればネストループジョインするようになっています。
何も絞り込まずにジョインする場合などでもネストループジョインを必要とする場合は、ネストループジョイン強制("FORCE_NEST_JOIN")をSQL最適化オプションに指定します。なお、デフォルトで指定される他のオプションを否定しないよう明示指定することに留意してください。
なお、上記オプションを指定しても以下のいずれかの場合にはネストループジョインとはなりません。
結合条件の内表の列にインデクスが定義されない。
結合列がインデクスの先頭構成列であるか、先頭構成列から結合列まで連続して=条件が指定されている必要がある。
結合条件には「列=列」の条件がない、または、OR条件下に指定されている。
ただし、結合条件の外表がスカラ演算されている場合は、SQL拡張最適化オプションに値式に対する結合条件適用機能("APPLY_JOIN_COND_FOR_VALUE_EXP")を指定すればネストループジョインとなる。
結合の内表が内部導出表(詳細は、HiRDB SQLリファレンス 2章)とならない。
パラレルサーバに限るが、分割表に対するLEFT OUTER JOINにて、内表の分割キーの内 結合
条件に含まれない列がある。
ネストループジョインを強制する場合

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録C-1-1 結合検索に関する記述(2)
104
結合結果の件数が多い場合、ハッシュジョインが効率よく結合処理を行なう場合があります。ネストループジョインをハッシュジョインに変更する指定を以下に示します。
① SQL拡張最適化オプションに、コストベース最適化モード2の適用(“COST_BASE_2”)かつハッシュジョイン、副問合せのハッシュ実行(“APPLY_HASH_JOIN”)を指定する。
② ハッシュ表サイズの指定を行う。
システム定義のpd_hash_table_sizeまたはクライアント環境変数のPDHASHTBLSIZE
③ 作業表用バッファの確保方式の指定を行う(デフォルトはpoolのため、省略可能)。
システム定義のpd_work_buff_mode = pool
④ 作業表用バッファのサイズの指定を行う。
システム定義のpd_work_buff_sizeまたはシステム定義のpd_work_buff_expand_limit
⑤ SQL最適化オプションにて、ネストループジョイン優先("PRIOR_NEST_JOIN")、またはネストループジョイン強制("FORCE_NEST_JOIN")を指定していれば外す。
上記で、まだネストループジョインを行う場合は、
⑥ 結合列のインデクスを削除する。
(注)ハッシュジョインを行うためには、データ型・データ長が同じ列同士の列=列の結合条件(OR演
算した条件は不可)が指定されている必要があります。
ネストループジョインをハッシュジョインに変更する場合

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録C-1-2 結合検索に関する記述(3)
105
ハッシュ表サイズの指定で一括ハッシュジョイン処理(内表から作成したハッシュ表を、すべて作業表バッファ領域に展開しハッシュジョインする)か、バケット分割ハッシュジョイン処理(内表、外表をバケットに分割し、内表の一部を作業表用バッファ領域に展開し、残りを作業表用ファイルに退避する)かが決まり、性能も大きく異なります。
一括ハッシュジョインにするためには、ハッシュ表サイズを、内表の条件評価後のヒットデータをすべて載せるために十分な大きさにします。
ハッシュ表に内表データをすべて載せるには、以下のシステム定義、クライアント環境変数のオペランドを変更します。
① システム定義のpd_hash_table_sizeまたはクライアント環境変数のPDHASHTBLSIZEを大き
くする。
② システム定義のpd_work_buff_sizeまたはpd_work_buff_expand_limitを大きくする。
(注)一括ハッシュジョインかバケット分割ハッシュジョインかどうか、および一括ハッシュジョインする
ために必要なハッシュ表サイズは、UAPに関する統計情報またはUAP統計レポート機能で確
認できます。
内表の条件評価後のヒットデータが、ハッシュ表に載りやすくするために、条件評価後のヒットデータの少ない表を内表とします。
外表と内表を入れ替えは、結合表構文(INNER JOIN)を指定することにより行います。
ハッシュジョインを一括ハッシュジョインにする場合

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録C-2 グループ分け高速化処理
106
SQL最適化オプションの指定を省略した場合、 "RAPID_GROUPING"(グループ分け高速化処理)は省略値であるため、GROUP BYを指定したSQLに対して、ハッシュ表を使用したグループ分け高速化処理が適用されます。
ハッシュ表のサイズは、クライアント環境定義PDAGGR(省略値は1024)に基づいて決
定されます。ハッシュ表の領域不足を起こさないためには、クライアント環境定義PDAGGRにグループ化での最大グループ数を指定します。ただし、メモリの使用量との
トレードオフであるため、実メモリの空きサイズより適切な値を検討してください。
グループ分け高速化処理は、グループ化前の行数に対して、グループ数が十分小さい場合に大きな効果を発揮します。
Point グループ分け高速化処理に対しては、PDAGGRをチューニングする

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録C-3 無排他条件判定の指定(1)
107
インデクスが適切に定義されていないため、効率よくインデクスを利用した検索できない場合や、テーブルスキャンになる場合、検索する行に排他が一時的にかかるため、条件に該当しないものにも排他がかかってしまいます。このようなとき、無排他条件判定で探索条件を判定して満たした行にだけ排他を掛けます。 無排他条件判定は、検索処理時には排他を掛けないで、探索条件を判定して満たした行にだけ排他を掛けます。探索条件を満たさない行、またはキー値に対して排他を掛けないため、通常の検索と比べて、検索時間が短縮でき、同時実行性を向上させます。
Point 厳密な条件判定が要求されない場合は、無排他条件判定の適用を検討する
図 C.3-1 通常の検索処理と排他の例
次に検索する行の有無の判定
検索する行に排他を掛ける
探索条件の判定
条件に該当しない
条件に該当する
そのままの状態
排他を解除する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録C-3-1 無排他条件判定の指定(2)
108
無排他条件判定を指定する場合は、余分な範囲を検索しないように、検索するキーは探索範囲絞り込めるようにインデクスのチューニングを行っておきます。 インデクスのキーによって、探索範囲をある程度絞り込んだ状態から、条件を切り出して検索した場合、条件を満たすものだけに排他を掛けます。このため、探索範囲の件数に比べて、条件を満たす件数が少ないと、通常の検索処理に比べて(条件を満たす件数/探索範囲の件数)の割合で排他処理を削減できます。 無排他条件判定は、クライアント環境定義のPDLOCKSKIPでYESを指定します。 排他を掛けないで条件判定をするため、COMMITしていないデータを検索して条件判定するおそれがあります。例えば、更新トランザクションと同時に条件判定するとき、条件判定での検索結果と、更新トランザクションの処理結果との間に差異(ROLLBACKによる読み飛ばし)が発生することがあるので注意が必要です。
図 C.3-2 無排他条件判定を使用した検索処理の排他の例
次に検索する行の有無の判定
探索条件の判定
条件に該当しない
条件に該当する
検索する行に排他を掛ける
そのままの状態
そのままの状態

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D. チューニングに関する記述
109

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D-1 インデクスを有効に使用するための考慮
110
以下にインデクスを有効に使用するために考慮する点について示します。
A) 大量データのランダム参照とI/Oの増加
大量データをアクセスすると、ランダムにデータを参照したり、アクセスする表の全データページ数を大きく超えるI/Oが発生したりする場合がある。I/Oを削減するため
に、絞り込める列にインデクスを定義する。またインデクスを定義した列に絞り込みできるようにすること。
B) 更新列のインデクスメンテナンスによる更新オーバヘッドの増加
インデクス定義時、更新の多い列に対する考慮すること。
C) 重複の多いキー値は、インデクスメンテナンスオーバヘッド大
ナル値の重複が多い場合は、インデクス定義でナル値の除外を指定すること。
D) 絞り込める条件を指定している検索においてテーブルスキャン
絞り込める条件の列にインデクスを定義することによって、表のデータのアクセス量
を削減し、検索性能を改善できる。(表の行数が少なく、現時点で性能が悪くなくても、将来、行数が増加する場合や、本番環境で行数が多いという場合に、インデクスを利用すると性能が安定する。)
Point インデクス定義時は、メリット/デメリットを考慮する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D-2 集合関数MAX/MINでのインデクス利用(1)
111
集合関数MAX、 MINは、引数の列にインデクスの構成列を指定します。探索条件がな
い場合は、MAX、 MINの引数に、第1構成列を指定します。また、探索条件がある場合
は、条件を満たすインデクス構成列を指定することで、インデクスを利用して最小値・最
大値を求める性能が向上します。
Point 集合関数MAX、 MINの引数にする列は、インデクスを定義する
探索条件がある場合、次の条件を満たすインデクスが利用される。 =条件列(またはIS NULL条件列)を、第1~第n構成列として連続して含む
n≧1 MAX、 MINの引数の列に、第n+1構成列に含む その他の条件列を第n+2構成列以降に含む
SQL文中にC1~Cmまで使用する。 m:定義したインデクスの最大構成列数 SELECT MAX(Cn+1 ), MIN(Cn+1 ) FROM T1 WHERE C1=10 AND …AND Cn=20 AND Cn+2 <30 AND Cm >40 INDEX ON T1(C1, ・・・ , Cn, Cn+1, Cn+2, ・・・, Cm)
図 D.2-1 集合関数MIN/MAXでのインデクスの利用

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D-2-1 集合関数MAX/MINでのインデクス利用(2)
112
○ SELECT MAX(ZA.ZSURYO) FROM ZAIKO ZA WHERE ZA.DNO=10 AND ZA.ZNO=20 ;
○ SELECT MAX(ZA.ZSURYO) FROM ZAIKO ZA WHERE ZA.DNO=10 AND ZA.ZNO=20 AND ZA.ZSURYO<30 ;
○ SELECT MAX(ZA.ZSURYO) FROM ZAIKO ZA WHERE ZA.DNO=10 AND ZA.ZNO=20 AND ZA.TANKA<40 ;
× SELECT MAX(ZA.ZSURYO) FROM ZAIKO ZA WHERE ZA.DNO=10 AND ZA.ZNO<20 ;
× SELECT MAX(ZA.ZSURYO) FROM ZAIKO ZA WHERE ZA.DNO=10 AND ZA.ZNO=20 AND ZA.SNAME_ID<50 ;
図 D.2-2 最小値・最大値を取得の例
インデクス X01( DNO, ZNO, ZSURYO, TANKA )
条件にインデクスの第1構成列から連続して=指定。MAXの引数にインデクスの第3構成列を指定。
条件にインデクスの第1構成列に=指定、第2構成列は<指定。MAXの引数にインデクスの第3構成列を指定。第2構成列の条件指定は=条件を指定する。
条件にインデクス以外の列を指定。条件にはインデクスの構成列を指定して、ソート処理を削減する。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D-2-2 集合関数MAX/MINでのインデクス利用(3)
113
次の場合は、MAX、MIN利用時、効率的に最小値・最大値を取得できないので注意して
ください。
結合検索を指定
GROUP BY句を指定
引数の異なるMAX、 MINを指定
探索条件に値式または256バイト以上の値
表がサーバ内で複数RDエリアに分割格納され、インデクスも分割インデクス(分割キー
のすべての構成列に=条件がある場合を除く)
以降は、HiRDB/パラレルサーバのみ
INSERT~SELECT文中
集合演算を指定
HAVING句を指定
FOR READ ONLYを指定

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D-3 DISTINCT集合関数のインデクス利用
114
DISTINCT集合関数の引数にインデクスの第1構成列を指定すると、作業表の作成が回避されます。
Point DISTINCT集合関数の引数にする列はインデクスの第1構成列に定義する
○ CREATE INDEX XO1 ON ZAIKO (SNAME, COL); ○ CREATE INDEX XO1 ON ZAIKO (SNAME); × CREATE INDEX XO1 ON ZAIKO (COL, SNAME);
図 D.3-1 インデクス列のみ選択の例
引数が第1構成列にならない
SELECT COUNT(DISTINCT ZA.SNAME) FROM ZAIKO ZA;

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D-4 ネストループジョイン(1)
115
内表検索時に行データを参照して結合条件を評価する指定は、検索の性能を著しく悪く
させます。検索の性能向上を図るために、以下に示す結合キーをインデクスに定義して、
インデクス利用効率を向上させます。
結合キーと一致するインデクスである
結合キーのすべての列が第1~第n構成列に連続して含まれるインデクスである
不連続な場合、第1~第n構成列は、結合列か=条件列かIS NULL条件列である
Point インデクスは内表の結合キーを第1構成列から連続して構成列に指定して 定義する

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録D-4-1 ネストループジョイン(2)
116
SELECT JU.ZNO FROM ZAIKO ZA, JUTYU JU WHERE ZA.DNO = 10 AND JU.ZNO = ZA.ZNO AND JU.SURYO = ZA.ZSURYO AND JU.TCODE = ZA.TCODE ;
○ CREATE INDEX XO1 ON JUTYU(ZNO, SURYO, TCODE);
○ CREATE INDEX XO1 ON JUTYU(TCODE, SURYO, ZNO);
○ CREATE INDEX XO1 ON JUTYU(ZNO, TCODE, SURYO);
○ CREATE INDEX XO1 ON JUTYU(ZNO, SURYO, TCODE, JDATE1);
△ CREATE INDEX XO1 ON JUTYU(ZNO, SURYO, JDATE1, TCODE);
× CREATE INDEX XO1 ON JUTYU(ZNO);
× CREATE INDEX XO1 ON JUTYU(SURYO);
× CREATE INDEX XO1 ON JUTYU(ZNO, SURYO);
図 D.4-1 結合キーとインデクスの定義例
ZAIKO → JUTYUのネストループジョインとする 内表JUTYUの結合キーは以下 ZNO, SURYO, TCODE
結合キーがすべて含まれる。
探索条件の指定順序と構成列順が異なっても良い。
結合キーのいくつかが インデクス構成列に 含まれない。
結合キーは先頭の構成列から連続していれば良い。
JDATE1により結合キーは先頭の構成列から連続しないとサーチ範囲が広く 性能劣化。

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録E. SQL最適化オプション
117

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
付録E-1 SQL最適化オプション、SQL拡張最適化オプション
118
SQL最適化オプション、SQL拡張最適化オプションとは、データベースの状態を考慮して、最も効率的なアクセスパスを決定するためのSQL実行時の最適化方法を指定するオプションのことです。
SQL最適化オプションとSQL拡張最適化オプションの指定方法を示します。
詳細は、マニュアル「システム定義」、「UAP開発ガイド」または「SQLリファレンス」を参照してください。
解説
指定の種類 指定場所 パラメタ
SQL最適化
オプションの指定
システム定義 pd_optimize_level
クライアント環境定義 PDSQLOPTLVL
ストアドルーチン中およびトリガ中のSQL文 OPTIMIZE LEVEL
SQL拡張最適化
オプションの指定
システム定義 pd_additional_optimize_level
クライアント環境定義 PDADDITIONALOPTLVL
ストアドルーチン中およびトリガ中のSQL文 ADD OPTIMIZE LEVEL

© Hitachi, Ltd. 2013 , 2015. All rights reserved.
株式会社 日立製作所 情報・通信システム社
ITプラットフォーム事業本部 DB部
HiRDB SQLコーディングガイドライン
第08版
2015/06
END
119









