Download - INTEL CONFIDENTIAL Reducing Parallel Overhead Introduction to Parallel Programming – Part 12

INTEL CONFIDENTIAL
Reducing Parallel OverheadIntroduction to Parallel Programming – Part 12

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
2
Review & Objectives
Previously:Use loop fusion, loop fission, and loop inversion to create or
improve opportunities for parallel executionExplain why it can be difficult both to optimize load balancing
and maximize locality
At the end of this part you should be able to:Explain the pros and cons of static versus
dynamic loop schedulingExplain the different OpenMP schedule clauses and
the situations each one is best suited for

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
3
Reducing Parallel Overhead
Loop schedulingReplicating work

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
4
Loop Scheduling Example
for (i = 0; i < 12; i++) for (j = 0; j <= i; j++) a[i][j] = ...;
Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
5
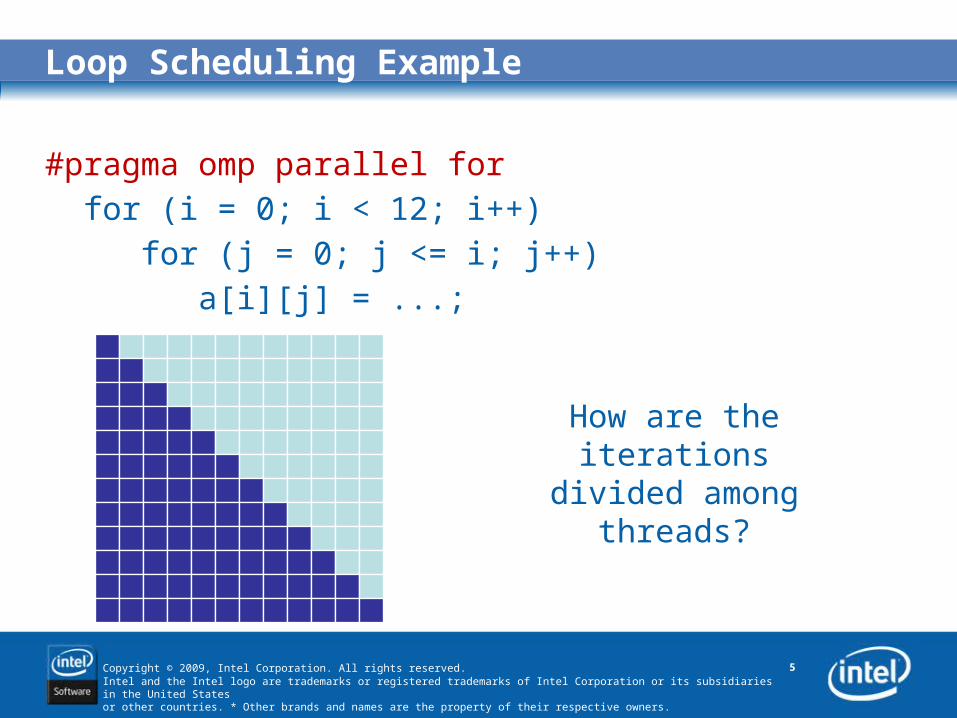
Loop Scheduling Example
#pragma omp parallel for for (i = 0; i < 12; i++) for (j = 0; j <= i; j++) a[i][j] = ...;
How are the iterations divided among threads?

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
6
Loop Scheduling Example
#pragma omp parallel for for (i = 0; i < 12; i++) for (j = 0; j <= i; j++) a[i][j] = ...;
Typically, the iterations are divided by the
number of threads and assigned as
chunks to a thread

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
7
Loop Scheduling
Loop schedule: how loop iterations are assigned to threads
Static schedule: iterations assigned to threads before execution of loop
Dynamic schedule: iterations assigned to threads during execution of loop
The OpenMP schedule clause affects how loop iterations are mapped onto threads

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
The schedule clause
schedule(static [,chunk])• Blocks of iterations of size “chunk” to threads• Round robin distribution• Low overhead, may cause load imbalance
Best used for predictable and similar work per iteration
8

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
9
Loop Scheduling Example
#pragma omp parallel for schedule(static, 2) for (i = 0; i < 12; i++) for (j = 0; j <= i; j++) a[i][j] = ...;

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
The schedule clause
schedule(dynamic[,chunk])• Threads grab “chunk” iterations • When done with iterations, thread requests next set• Higher threading overhead, can reduce load imbalance
Best used for unpredictable or highly variable work per iteration
10

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
11
Loop Scheduling Example
#pragma omp parallel for schedule(dynamic, 2) for (i = 0; i < 12; i++) for (j = 0; j <= i; j++) a[i][j] = ...;

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
The schedule clause
schedule(guided[,chunk])• Dynamic schedule starting with large block • Size of the blocks shrink; no smaller than “chunk”
Best used as a special case of dynamic to reduce scheduling overhead when the computation gets progressively more time consuming
12

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
13
Loop Scheduling Example
#pragma omp parallel for schedule(guided) for (i = 0; i < 12; i++) for (j = 0; j <= i; j++) a[i][j] = ...;

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
14
Replicate Work
Every thread interaction has a costExample: Barrier synchronizationSometimes it’s faster for threads to replicate work
than to go through a barrier synchronization

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
15
Before Work Replication
for (i = 0; i < N; i++) a[i] = foo(i);x = a[0] / a[N-1];for (i = 0; i < N; i++) b[i] = x * a[i];
Both for loops are amenable to parallelization

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
16
First OpenMP Attempt
#pragma omp parallel{ #pragma omp for for (i = 0; i < N; i++) a[i] = foo(i); #pragma omp single x = a[0] / a[N-1]; #pragma omp for for (i = 0; i < N; i++) b[i] = x * a[i];}
Synchronization among threads required if x is shared and one thread performs assignment
Implicit Barrier

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
17
After Work Replication
#pragma omp parallel private (x){ x = foo(0) / foo(N-1);#pragma omp for for (i = 0; i < N; i++) { a[i] = foo(i); b[i] = x * a[i]; }}

Copyright © 2009, Intel Corporation. All rights reserved. Intel and the Intel logo are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States or other countries. * Other brands and names are the property of their respective owners.
18
References
Rohit Chandra, Leonardo Dagum, Dave Kohr, Dror Maydan, Jeff McDonald, and Ramesh Menon, Parallel Programming in OpenMP, Morgan Kaufmann (2001).
Peter Denning, “The Locality Principle,” Naval Postgraduate School (2005).
Michael J. Quinn, Parallel Programming in C with MPI and OpenMP, McGraw-Hill (2004).








