

Two components to basic Bioinformatics
• Storing and retrieving data:
– Biological databases
– Querying these to retrieve data
• Manipulating the data –tools e.g:
– Sequence similarity searches
– Protein families and function prediction
– Comparing sequences –phylogenetics
– Etc.

What is a database
• an organized body of related infomation www.cogsci.princeton.edu/cgi-bin/webwn
• Data collection that is:
– Structured (computer readable)
– Searchable
– Updatable
– Cross-linked
– Publicly available

Biological Databases
• How do you find:– Info on a particular topic -> Wikipedia
– A book -> Amazon
– Accommodation -> AirBnB
– DNA sequence -> EMBL
– Protein sequence -> UniProtKB, RefSeq…
• Biological databases:– Order and make data available to public
– Turn data into computer-readable form
– Provide ability to retrieve data from various sources
• Can have primary (archival) or secondary databases (curated)
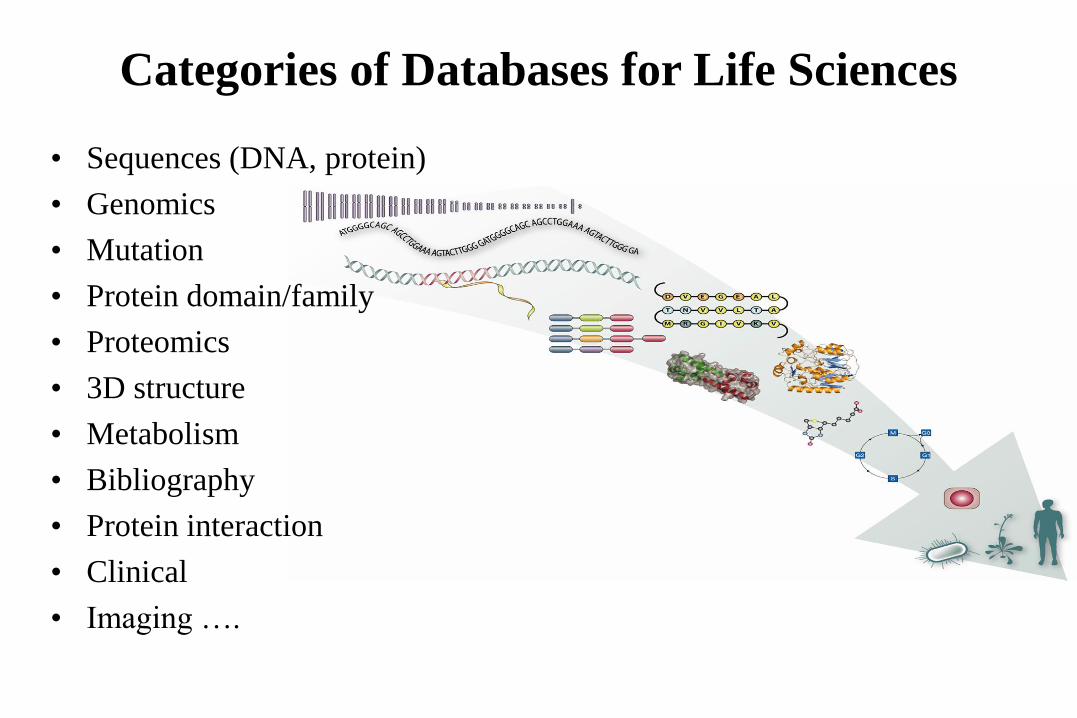
Categories of Databases for Life Sciences
• Sequences (DNA, protein)
• Genomics
• Mutation
• Protein domain/family
• Proteomics
• 3D structure
• Metabolism
• Bibliography
• Protein interaction
• Clinical
• Imaging ….
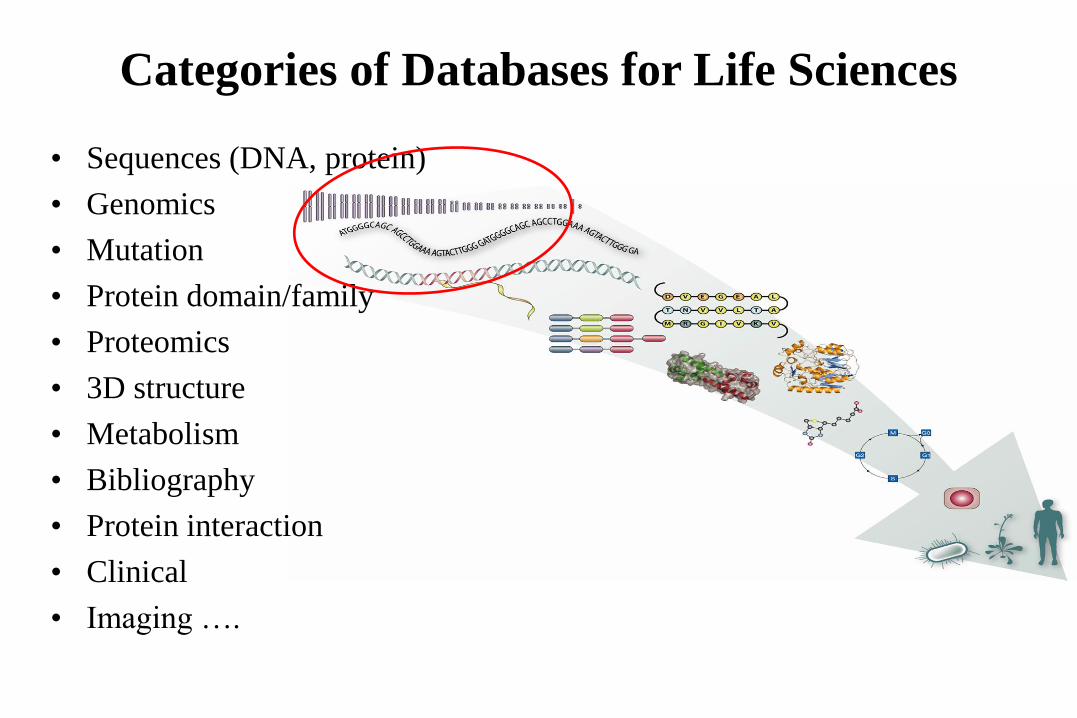
Categories of Databases for Life Sciences
• Sequences (DNA, protein)
• Genomics
• Mutation
• Protein domain/family
• Proteomics
• 3D structure
• Metabolism
• Bibliography
• Protein interaction
• Clinical
• Imaging ….

• Thousands of genomes sequenced
(single organism, varying sizes, including virus)
• Thousands of ongoing genome sequencing projects
• cDNAs sequencing projects (ESTs or cDNAs)
• Metagenome sequencing projects
= environmental samples: multiple ‘unknown’ organisms
=microbiome
• Personal human genomes
• Cost of sequencing is coming down –alternative to other
technologies
Why do we need sequence DBs?
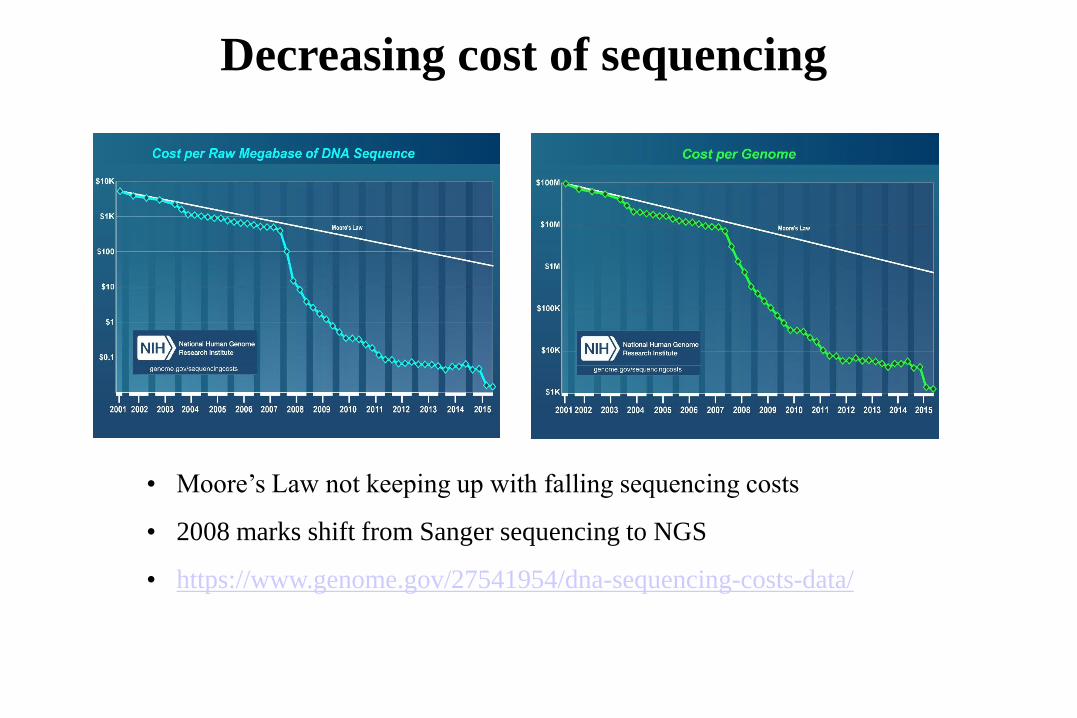
Decreasing cost of sequencing
• Moore’s Law not keeping up with falling sequencing costs
• 2008 marks shift from Sanger sequencing to NGS
• https://www.genome.gov/27541954/dna-sequencing-costs-data/

Sequence databases
• Used for retrieving a known gene/protein sequence
• Useful for finding information on a gene/protein
• Can find out how many genes are available for a given
organism
• Can comparing your sequence to the others in the database
• Can submit your sequence to store with the rest
• Main databases: nucleotide and protein sequence DBs
• Should be interconnected with other databases
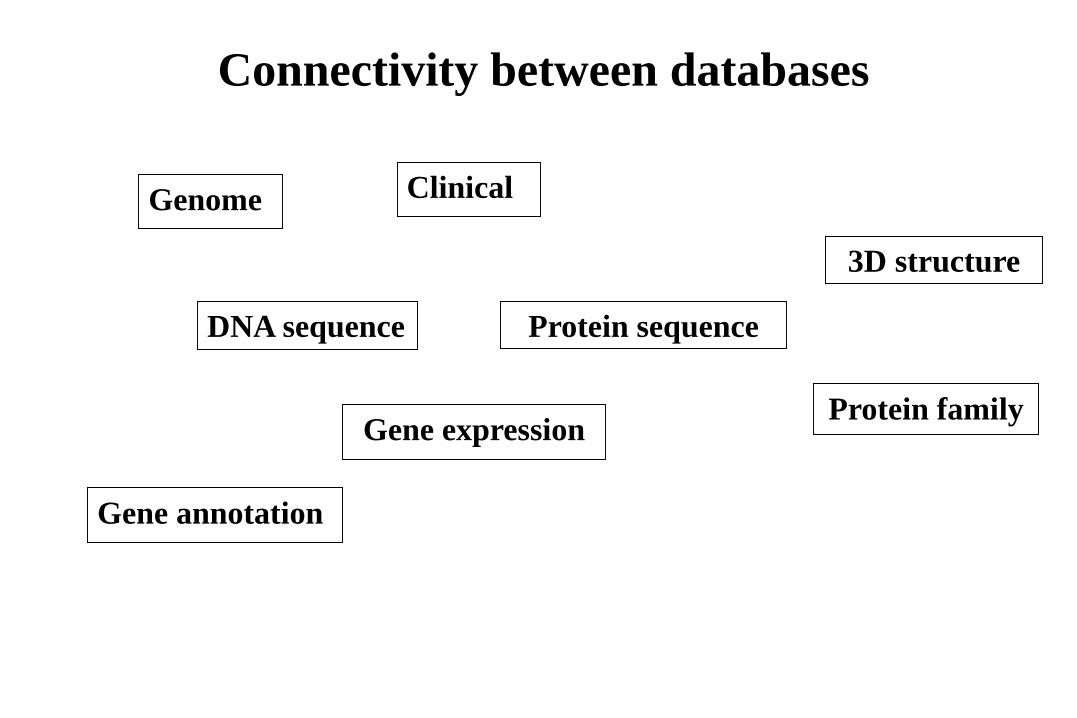
DNA sequence
Gene annotation
Gene expression
Protein sequence
3D structure
Connectivity between databases
Genome
Protein family
Clinical
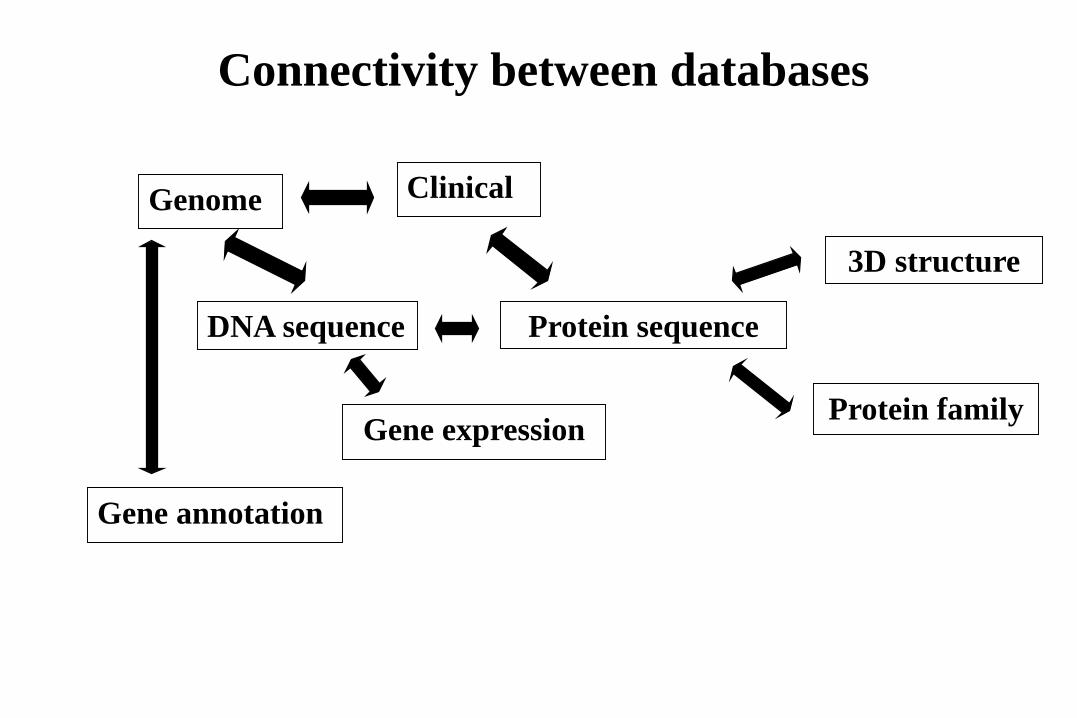
DNA sequence
Gene annotation
Gene expression
Protein sequence
3D structure
Connectivity between databases
Genome
Protein family
Clinical
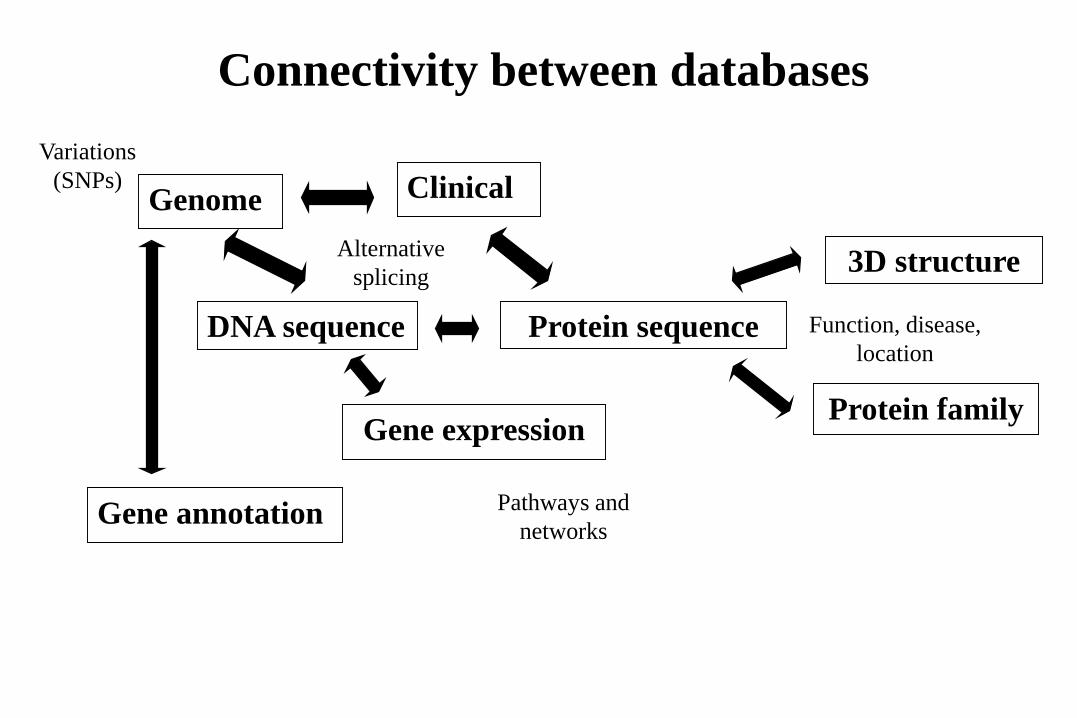
DNA sequence
Gene annotation
Gene expression
Protein sequence
3D structure
Connectivity between databases
Genome
Protein family
Clinical
Variations
(SNPs)
Alternative
splicing
Function, disease,
location
Pathways and
networks

An example BRCA1:
Breast cancer gene
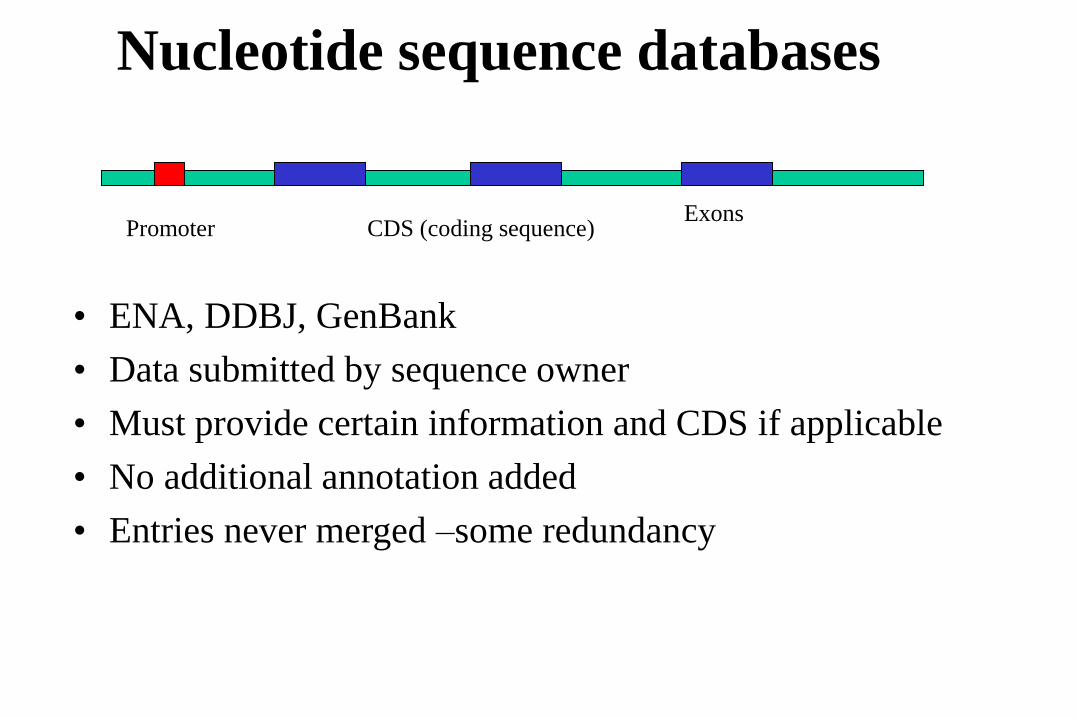
Nucleotide sequence databases
• ENA, DDBJ, GenBank
• Data submitted by sequence owner
• Must provide certain information and CDS if applicable
• No additional annotation added
• Entries never merged –some redundancy
PromoterExons
CDS (coding sequence)
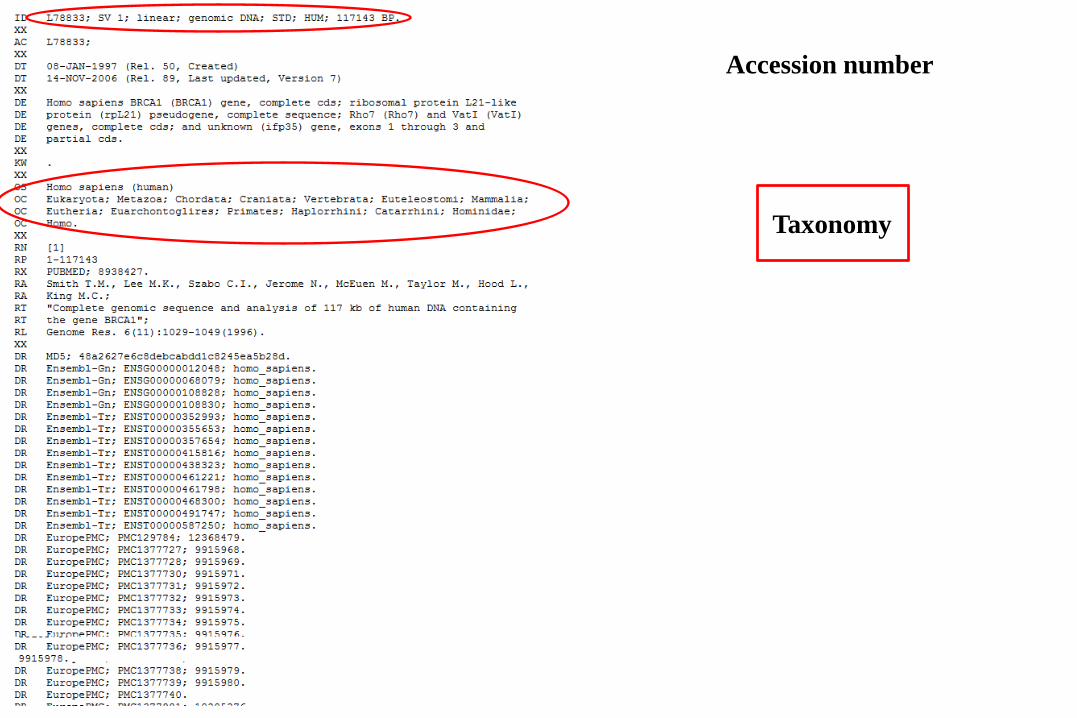
Taxonomy
Accession number

Taxonomy
References
Accession number
Cross-references
Ensembl genome database
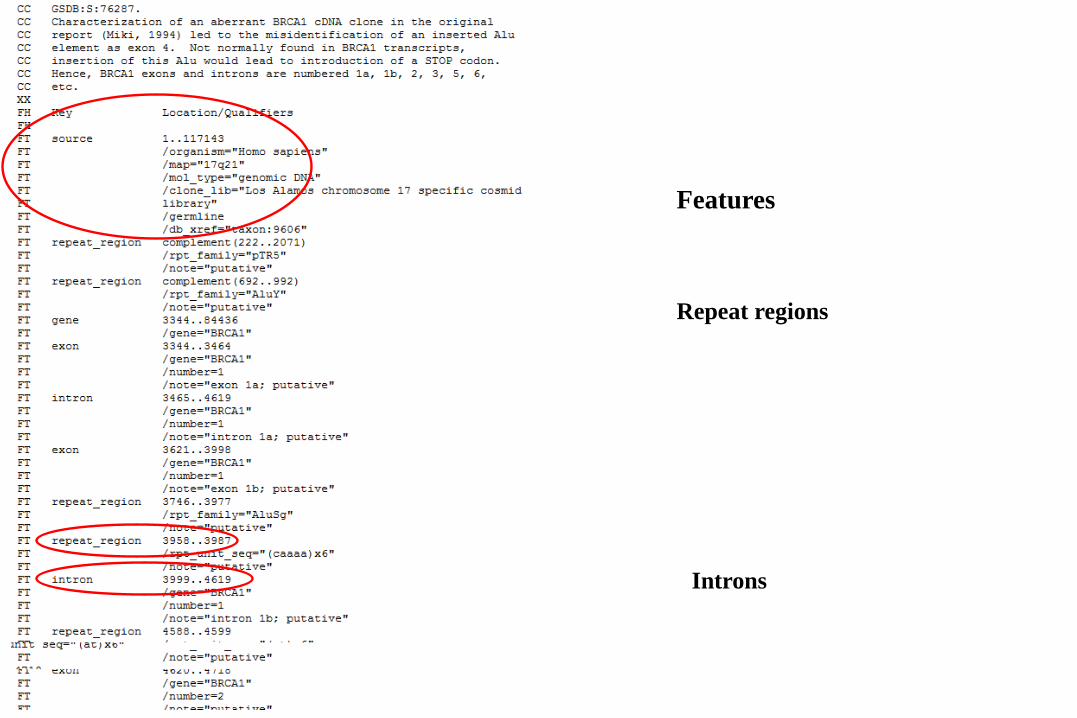
Features
Repeat regions
Introns

Protein sequence
Features
Cross-references for protein
CDS –Coding sequence
InterPro protein families and domains
Protein 3D structure
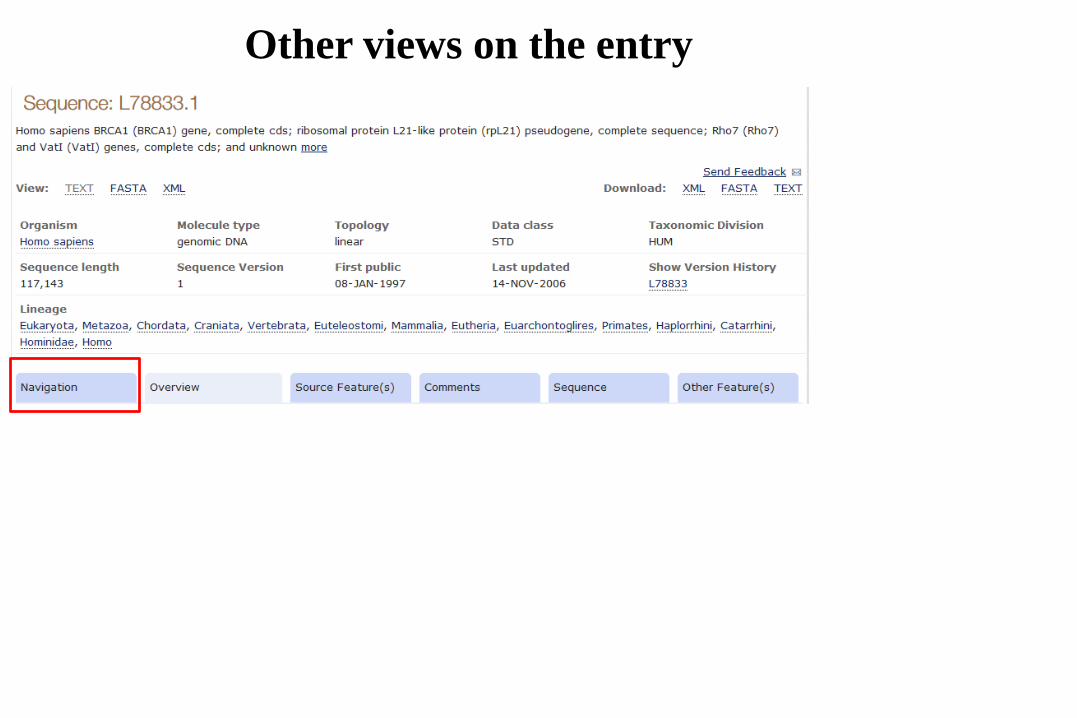
Other views on the entry
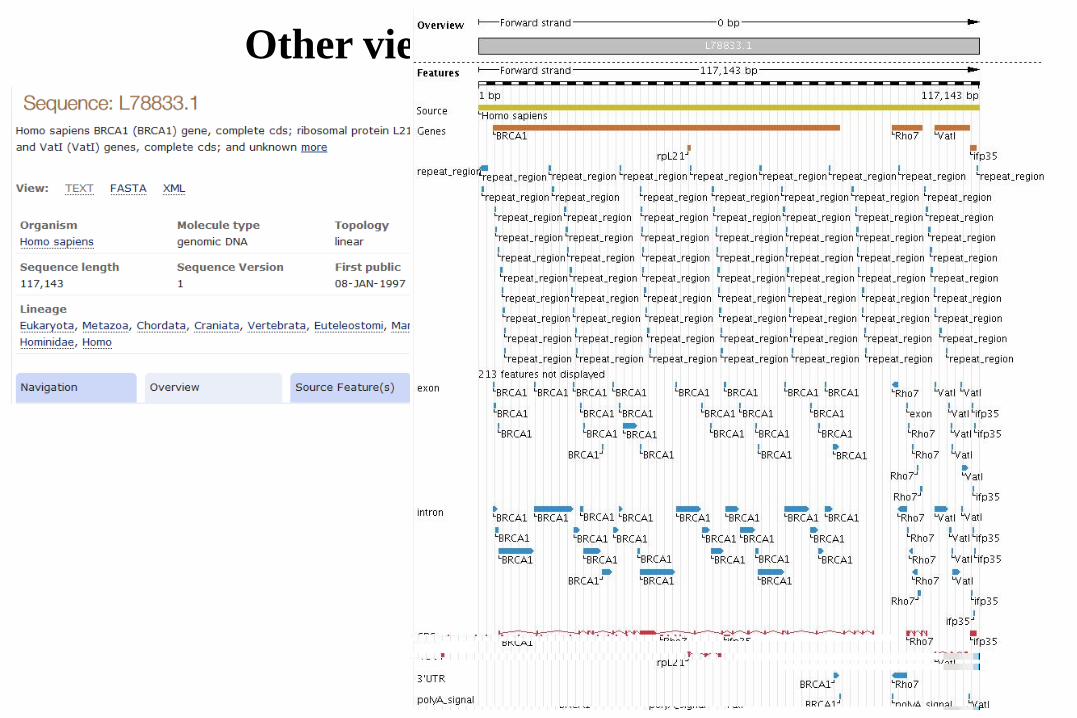
Other views on the entry

Summary of information in ENA entries
• Provides taxonomy from which sequence came
• Provides information on submitters and references
• Describes features on a sequence NB for function, replication, recombination, structure etc.
• Shows if the DNA encodes a protein (CDS) and provides protein sequence
• Provides actual nucleotide sequence
• Describes sequence type, e.g. genomic DNA, RNA, EST

CDS: mRNA versus genomic sequence
CONTIG --------------------------------------------------------------------------------------CGANGGCCTATCAACAATGAAAGGTCGAAACCTG
Genomic AGCTACAAACAGATCCTTGATAATTGTCGTTGATTTTACTTTATCCTAAATTTATCTCAAAAATGTTGAAATTCAGATTCGTCAAGCGAGGGCCTATCAACAATG-AAGGTCGAAACCTG
*** ************ ** * **************
CONTIG CGTTTACTCCGGATACAAGATCCACCCAGGACACGGNAAAGAGACTTGTCCGTACTGACGGAAAG-------------------------------------------------------
Genomic CGTTTACTCCGGATACAAGATCCACCCAGGACACGG-AAAGAGACTTGTCCGTACTGACGGAAAGGTGAGTTCAGTTTCTCTTTGAAAGGCGTTAGCATGCTGTTAGAGCTCGTAAGGTA
************************************ ****************************
CONTIG ------------------------------------------------------------------------------------------------------------------------
Genomic TATTGTAATTTTACGAGTGTTGAAGTATTGCAAAAGTAAAGCATAATCACCTTATGTATGTGTTGGTGCTATATCTTCTAGTTTTTAGAAGTTATACCATCGTTAAGCATGCCACGTGTT
CONTIG ----------------------------------------------GTCCAAATCTTCCTCAGTGGAAAGGCACTCAAGGGAGCCAAGCTTCGCCGTAACCCACGTGACATCAGATGGAC
Genomic GAGTGCGACAAACTACCGTTTCATGATTTATTTATTCAAATTTCAGGTCCAAATCTTCCTCAGTGGAAAGGCACTCAAGGGAGCCAAGCTTCGCCGTAACCCACGTGACATCAGATGGAC
**************************************************************************
CONTIG TGTCCTCTACAGAATCAAGAACAAGAAG---------------------------------------------GGAACCCACGGACAAGAGCAAGTCACCAGAAAGAAGACCAAGAAGTC
Genomic TGTCCTCTACAGAATCAAGAACAAGAAGGTACTTGAGATCCTTAAACGCAGTTGAAAATTGGTAATTTTACAGGGAACCCACGGACAAGAGCAAGTCACCAGAAAGAAGACCAAGAAGTC
**************************** ***********************************************
CONTIG CGTCCAGGTTGTTAACCGCGCCGTCGCTGGACTTTCCCTTGATGCTATCCTTGCCAAGAGAAACCAGACCGAAGACTTCCGTCGCCAACAGCGTGAACAAGCCGCTAAGATCGCCAAGGA
Genomic CGTCCAGGTTGTTAACCGCGCCGTCGCTGGACTTTCCCTTGATGCTATCCTTGCCAAGAGAAACCAGACCGAAGACTTCCGTCGCCAACAGCGTGAACAAGCCGCTAAGATCGCCAAGGA
************************************************************************************************************************
CONTIG TGCCAACAAGGCTGTCCGTGCCGCCAAGGCTGCTNCCAACAAG-----------------------------------------------------------------------------
Genomic TGCCAACAAGGCTGTCCGTGCCGCCAAGGCTGCTGCCAACAAGGTAAACTTTCTACAATATTTATTATAAACTTTAGCATGCTGTTAGAGCTTGTAAGGTATATGTGATTTTACGAGTGT
********************************** ********
CONTIG -------------------------------------------------------------------------------------------------------------------GNAAA
Genomic GTTATTTGAAGCTGTAATATCAATAAGCATGTCTCGTGTGAAGTCCGACAATTTACCATATGCATGAAATTTAAAAACAAGTTAATTTTGTCAATTCTTTATCATTGGTTTTCAGGAAAA
* ***
CONTIG GAAGGCCTCTCAGCCAAAGACCCAGCAAAAGACCGCCAAGAATNTNAAGACTGCTGCTCCNCGTGTCGGNGGAAANCGATAAACGTTCTCGGNCCCGTTATTGTAATAAATTTTGTTGAC
Genomic GAAGGCCTCTCAGCCAAAGACCCAGCAAAAGACCGCCAAGAATGTGAAGACTGCTGCTCCACGTGTCGGAGGAAAGCGATAAACGTTCTCGGTCCCGTTATTGTAATAAATTTTGTTGAC
******************************************* * ************** ******** ***** **** * *********** ***************************
CONTIG C-----------------------------------------------------------------------------------------------------------------------
Genomic CGTTAAAGTTTTAATGCAAGACATCCAACAAGAAAAGTATTCTCAAATTATTATTTTAACAGAACTATCCGAATCTGTTCATTTGAGTTTGTTTAGAATGAGGACTCTTCGAATAGCCCA
*
exon
exon
exon
exon
exon
intron
intron
intron

Other nucleotide databases
• RefSeq
• dbEST
• WGS collections
• NCBI Sequence read archive –reads and alignments
• Depositing large data, e.g. mricobiome, WGS –bulk
upload tools
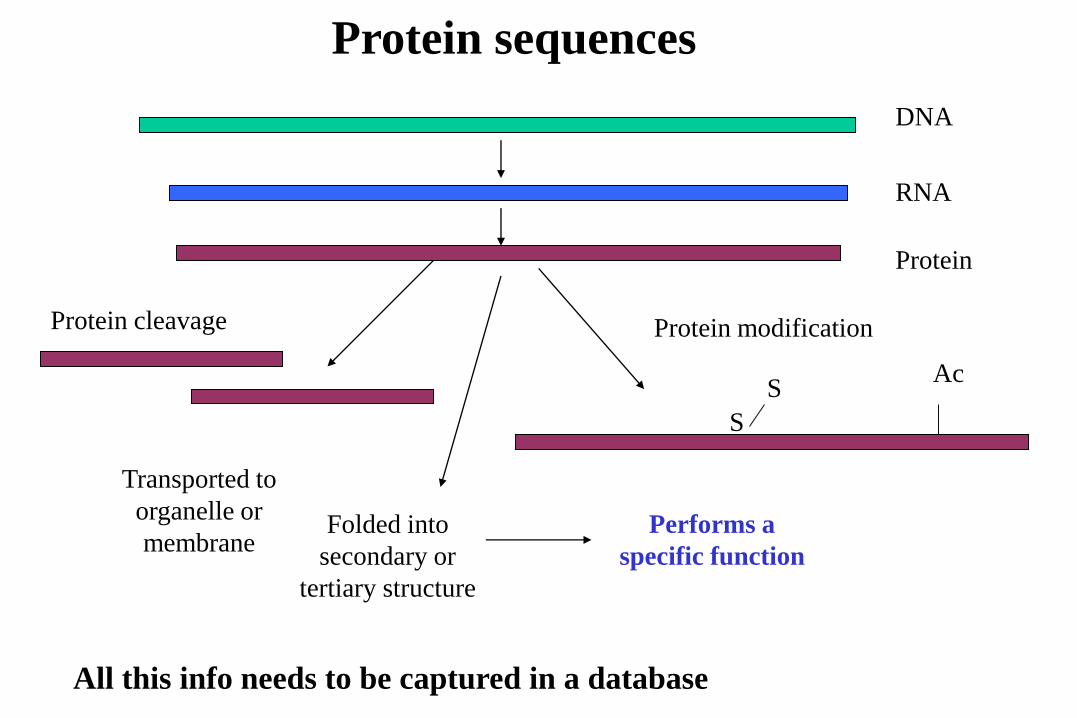
Protein sequences
DNA
RNA
Protein
S
S
Ac
Protein cleavage Protein modification
Transported to
organelle or
membraneFolded into
secondary or
tertiary structure
Performs a
specific function
All this info needs to be captured in a database

Protein Sequence Databases
• UniProt:– Swiss-Prot –manually curated, distinguishes between
experimental and computationally derived annotation
– TrEMBL - Automatic translation of EMBL, no manual curation, some automatic annotation
• GenPept -GenBank translations
• RefSeq - Non-redundant sequences for certain organisms
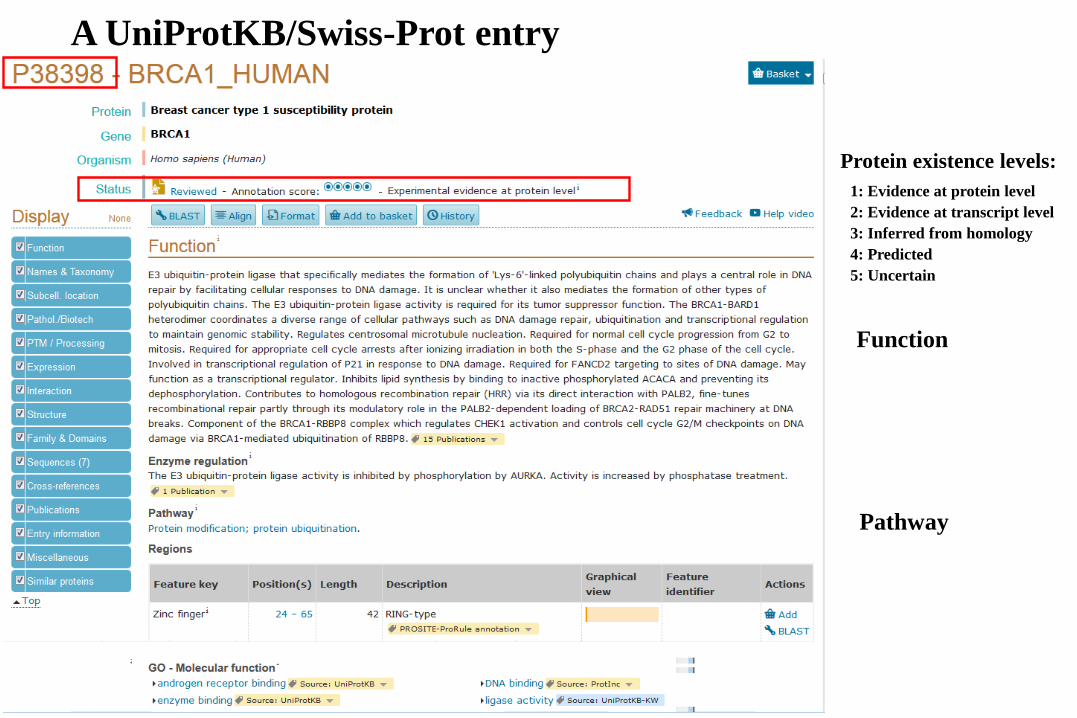
A UniProtKB/Swiss-Prot entry
Protein existence levels:
1: Evidence at protein level
2: Evidence at transcript level
3: Inferred from homology
4: Predicted
5: Uncertain
Function
Pathway

Keywords
Taxonomy
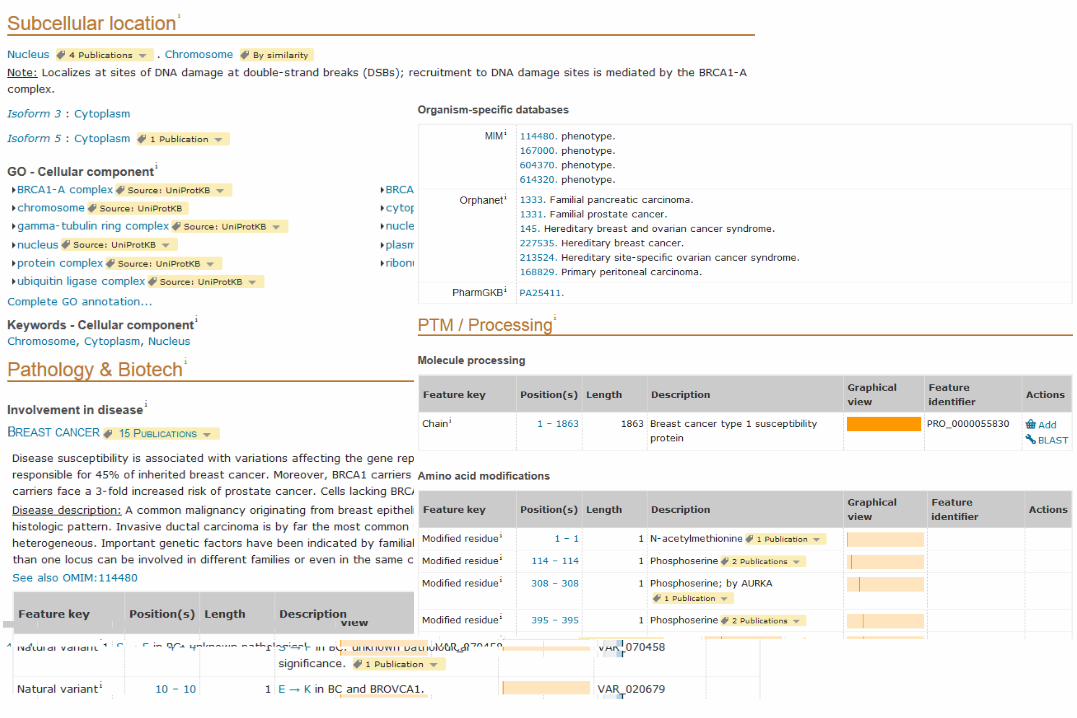
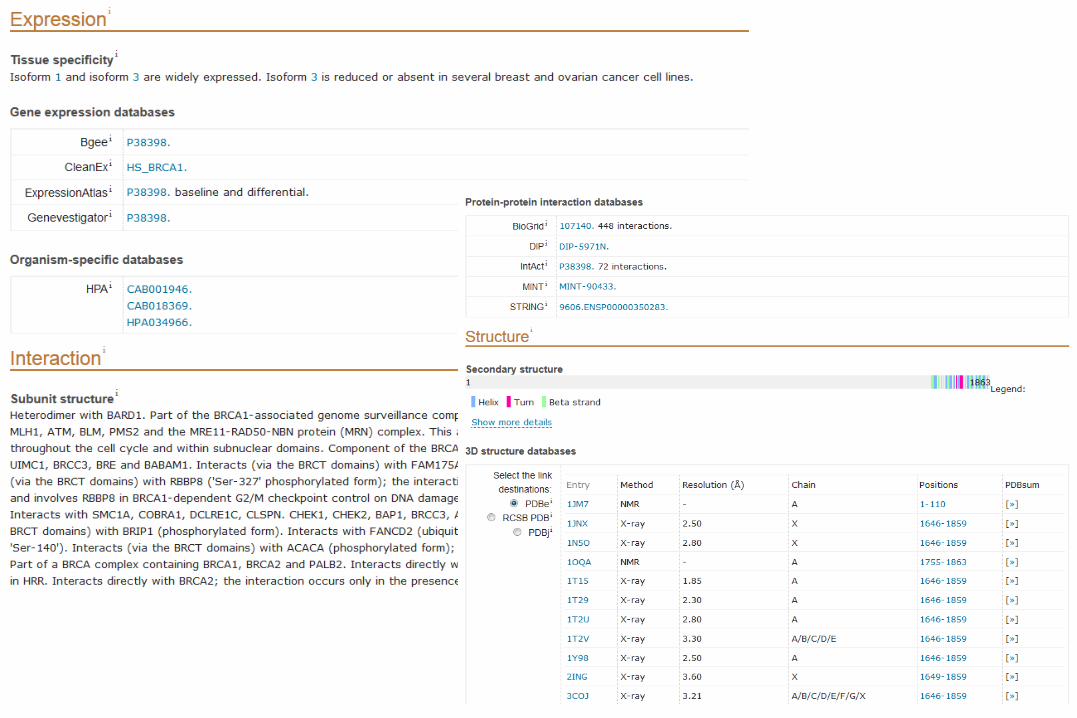
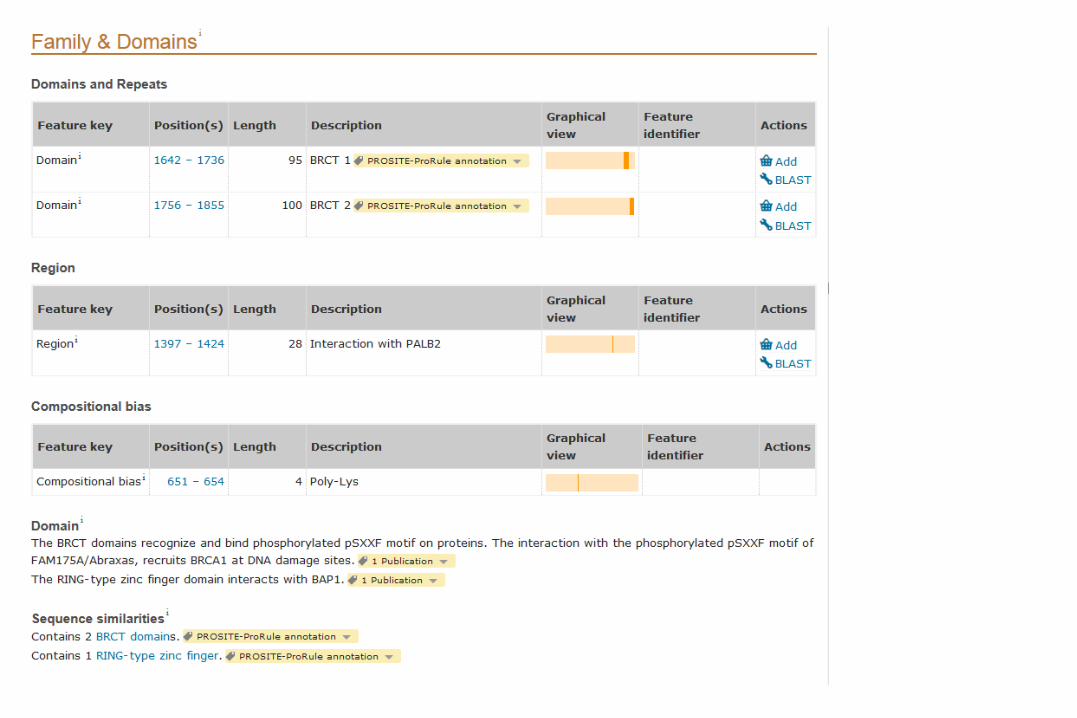


Other parts to UniProt
• UniParc –archive of all sequences
• UniProt –Swiss-Prot + TrEMBL
• UniProt NREF100 (100% seqs merged)
• UniProt NREF90 (90% seqs merged)
• UniProt NREF50 (50% seqs merged)
• UniMES –metagenomic sequences

Sequence formats
• Not MSWord, but text!
• Most include an ID/name/annotation of some sort
• FASTA, E.g.
>xyz some other comment
ttcctctttctcgactccatcttcgcggtagctgggaccgccgttcagtcgc
caatatgcgctctttgtccgcgcccaggagctacacaccttcgaggtga
ccggccaggaaacggtcgccagatcaaggctcatgtagcctcactgg
Others specific to programs, e.g. GCG, abi, clustal, etc.

Accession numbers
• GenBank/EMBL/DDBJ: 1 letter & digits, e.g.:
U12345 or 2 letters & 6 digits, e.g.: AY123456
• GenPept Sequence Records -3 letters & 5 digits,
e.g.: AAA12345
• UniProt -All 6 characters: [A,B,O,P,Q] [0-9] [A-
Z,0-9] [A-Z,0-9] [A-Z,0-9] [0-9], e.g.:
P12345 and Q9JJS7

Cross-referencing identifiers
• So many different IDs for same thing, e.g. Ensembl, EMBL, HGNC, UniGene, UniProt, Affy ID, etc.
• Need mapping files to move between them to avoid having to parse every entry
• PICR (http://www.ebi.ac.uk/Tools/picr/) enables mapping between IDs
• UniProt website mapper (www.uniprot.org)

Literature database: PubMed/Medline
• Source of Medical-related & scientific literature
• PubMed has articles published after 1965
• Can search by many different means, e.g. author, title, date, journal etc., or keywords for each
• PubMed has list of tags to search specific fields, e.g. [AU], [TI], [DP] etc.
• Can save queries and results
• Can usually retrieve abstracts and full papers

Types of search fields
• Title Words [TI] MeSH Terms [MH]
• Title/Abstract Words [TIAB] Language [LA]
• Text Words [TW] Journal Title [TA]
• Substance Name [NM] Issue [IP]
• Subset [SB] Filter [FILTER]
• Secondary Source ID [SI] Entrez Date [EDAT]
• Subheadings [SH] EC/RN Number [RN]
• Publication Type [PT] Author Name [AU]
• Publication Date [DP] All Fields [ALL]
• Personal Name as Subject [PS] Affiliation [AD]
• Page Number [PG] Unique Identifiers [UID]
• Title Words [TI] MeSH Major Topic [MAJR]
• MeSH Date [MHDA]

How to query databases
• Query languages e.g. SQL
• Can query with single word or phrase
• Boolean queries
• Regular expressions
• Basic database querying is usually done through web interface
– Text or sequence-based searches
– Can use Boolean queries and regular expressions

Words and phrases
• Most searches are case insensitive
• Keywords are single words searched
• Phrases –groups of words
• E.g. tyrosine protein kinase –returns anything with either of the words “tyrosine ”, “protein ” or “kinase” (keywords)
• “tyrosine protein kinase” –returns anything with the complete phrase only

Boolean operators (George Boole)
• Operators e.g. & (AND), | (OR), ! (NOT), e.g.:
– protein & kinase ! tyrosine
– tyrosine & protein & kinase
• More complex: (tyrosine OR kinase) AND (NOT serine)
• Operators don’t work in “”, e.g. “tyrosine and kinase”
• Wildcards * and ? E.g. cell*ase finds all words starting
with “cell” and ending in “ase”
• Attributes are used to be more specific about where to
find the keyword

Resources for searching databases
• EBI –all EBI databases search
• NCBI –Entrez
• Each database usually has own web interface
allowing simple queries







