
Kernel Memory Allocation 1
Chapter 12. Kernel Memory Allocation
• Introduction
• Resource Map Allocator
• Simple Power-of-Two Free Lists
• Mckusick-Karels Allocator
• Buddy System
• Mach-OSF/1 Zone Allocator
• Solaris 2.4 Slab Allocator

Kernel Memory Allocation 2
Introduction
• Page-level allocator
– Paging system
• Supports virtual memory system
– Kernel memory allocator
• Provides odd-sized buffers of memory to various
kernel subsystems
• Kernel frequently needs chunks of memory of
various sizes usually for short periods of time

Kernel Memory Allocation 3
Introduction (cont)
• Users of the kernel memory allocator
– pathname translation routine
– allocb( ) allocates STREAMs buffers of
arbitrary size
– In SVR4, the kernel allocates many objects
(proc structures, vnodes, file descriptor
blocks) dynamically when needed

Kernel Memory Allocation 4
Introduction (cont)
Page-levelallocator
Pagingsystem
kernelmemoryallocator
networkbuffers
procstructures
inodes, filedescriptors
userprocesses
block buffercache
physicalmemory

Kernel Memory Allocation 5
Kernel Memory Allocator (KMA)• Functional requirements– Page-level allocator pre-allocates part of main
memory to KMA, which must use this memory pool efficiently
– KMA also have to monitor which part of its pool are allocated and which are free
• Evaluation criteria– Utilization factor
– KMA must be fast• Both average and worst-cast latency are important
– Interaction with the paging system

Kernel Memory Allocation 6
Resource Map Allocator• Resource map– set of <base, size> for free memory
• First fit, Best fit, Worst bit policies
• Advantages– Easy to implement– Not restricted to memory allocation– Allocates the exact numbers of bytes
requested– Client is not constrained to release the exact
region it has allocated– Allocator coalesces adjacent free regions

Kernel Memory Allocation 7
Resource Map Allocator (cont)
• Drawbacks
– Map may become highly fragmented
– As the fragmentation increases, so does the
size of the map
– Sorting for coalescing adjacent regions is
expensive
– Linear search to find a free region
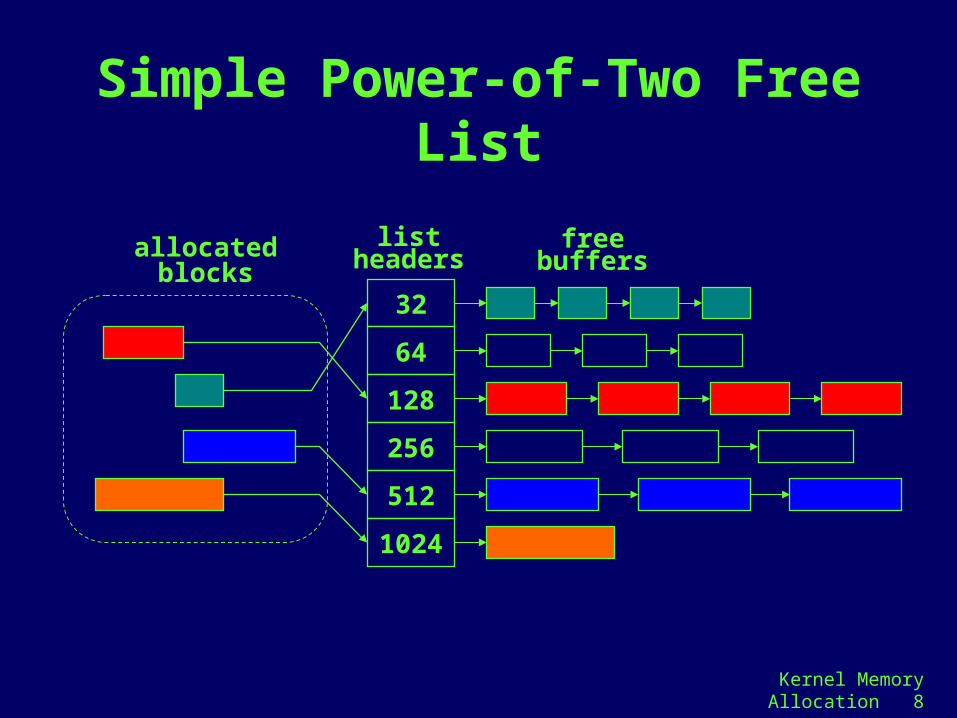
Kernel Memory Allocation 8
Simple Power-of-Two Free List
32
64
128
256
512
1024
listheaders
freebuffersallocated
blocks

Kernel Memory Allocation 9
Simple Power-of-Two Free List (cont)
• Used frequently to implement malloc( ), and free( ) in the user-level C library
• One-word header for each buffer
• Advantages
– Avoids the lengthy linear search of the resource map method
– Eliminates the fragmentation problem

Kernel Memory Allocation 10
Simple Power-of-Two Free List (cont)
• Drawbacks
– Rounding of requests to the next power of two results in poor memory utilization
– No provision for coalescing adjacent free buffer to satisfy larger requests
– No provision to return surplus free buffers to the page-level allocator
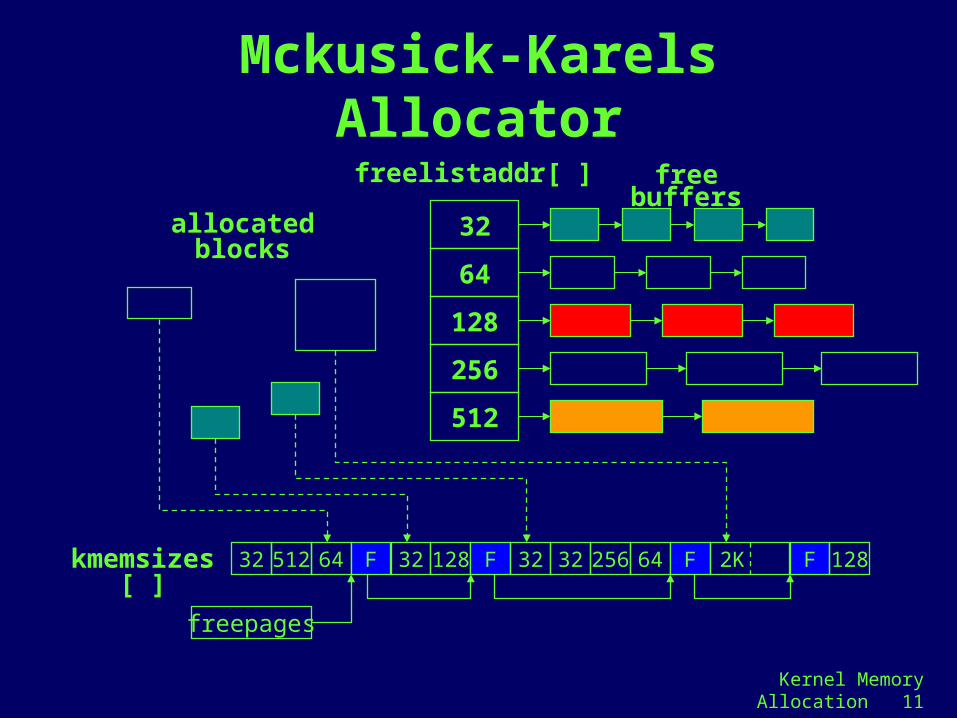
Kernel Memory Allocation 11
Mckusick-Karels Allocator
32
64
128
256
512
freelistaddr[ ] free buffers
allocated blocks
32 512 64 F 32 128 F 32 32 256 64 F 2K F 128
freepages
kmemsizes[ ]

Kernel Memory Allocation 12
Mckusick-Karels Allocator (cont)
• Used in 4.4BSD, Digital UNIX
• Requires that– a set of contiguous pages
– all buffers belonging to the same page to be the same size
• States of each page– Free
• corresponding element of kmemsizes[ ] contains a pointer to the element for the next free page
– Divided into buffers of a particular size• kmemsizes[ ] element contains the size

Kernel Memory Allocation 13
Mckusick-Karels Allocator (cont)
– Part of a buffer that spanned multiple pages• kmemsizes[ ] element corresponding to the first
page of the buffer contains the buffer size
• Improvement over simple power-of-two
– Faster, wastes less memory, can handle large and small request efficiently
• Drawbacks
– No provision for moving memory from one list to another
– No way to return memory to the paging system

Kernel Memory Allocation 14
Buddy System• Basic idea– Combines free buffer coalescing with a power-
of-two allocator– When a buffer is split, each buffer is called the
buddy of the other
• Advantages– Coalescing adjacent free buffers– Easy exchange of memory between the
allocator and the paging system
• Disadvantages– Performance degradation due to coalescing– Program interface needs the size of the buffer

Kernel Memory Allocation 15
Buddy System (e.g.)
1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
32 64 128 256 512
bitmap
free list headers
B C D D’ A’
0 256 384 448 512
C’
B’
A
free in use
allocate(256) allocate(128) allocate(64)
1023

Kernel Memory Allocation 16
Buddy System (e.g.)
1 1 1 1 1 1 1 1 0 0 0 0 1 1 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
32 64 128 256 512
bitmap
free list headers
B C D D’ F
0 256 384 448 512
C’
B’
A
allocate(128) release(C, 128)
F’ E’
640 768 1023
E
A’

Kernel Memory Allocation 17
Buddy System (e.g.)
1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
32 64 128 256 512
bitmap
free list headers
B B’ F
0 256 512
C’
A
release(D, 64)
F’ E’
640 768 1023
E

Kernel Memory Allocation 18
SVR4 Lazy Buddy System
• Basic idea
– Defer coalescing until it becomes necessary, and then to coalesce as many buffers as possible
• Lazy coalescing
– N buffers, A buffers are active, L are locally free, G are globally free
– N = A + L + G
– slack = N - 2L - G = A - L

Kernel Memory Allocation 19
SVR4 Lazy Buddy System (cont)
• Lazy state (slack = 0)
– buffer consumption is in a steady state and coalescing is not necessary
• Reclaiming state (slack = 1)
– consumption is borderline, coalescing is needed
• Accelerated state (slack = 2 or more)
– consumption is not in a steady state, and the allocator must coalesce faster

Kernel Memory Allocation 20
Mach-OSF/1 Zone Allocator
zone of zones
zone of zones
zone of zones
...
structzone
structzone
structzone
active zones
free_elements
next_zone
free objects
structobj1
structobj1
structobj1
structobjn
struct objn
struct objn
first_zone
last_zone

Kernel Memory Allocation 21
Mach-OSF/1 Zone Allocator (cont)• Basic idea– Each class of dynamically allocated objects is
assigned to its own size, which is simply a pool of free objects of that class
– Any single page is only used for one zone
– Free objects of each zone are maintained on a linked list, headed by a struct zone
– Allocation and release involve nothing more than removing objects from and returning objects to the free list
– If an allocation request finds the free list empty, it asks the page-level allocator for alloc( ) more bytes

Kernel Memory Allocation 22
Mach-OSF/1 Zone Allocator (cont)
• Garbage collection– Free pages can be returned to the paging
system and later recovered for other zones
• Analysis– Zone allocator is fast and efficient
– No provision for releasing only part of the allocated object
– Zone objects are exactly the required size
– Garbage collector provides a mechanism for memory reuse

Kernel Memory Allocation 23
Hierarchical Allocator for Multiprocessors
main freelist
aux freelist
target = 3
global freelist
bucket list
target = 3
per-pagesfreelistsCoalesce-to-
Page layer
Global layer
Per-CPUcache

Kernel Memory Allocation 24
Solaris 2.4 Slab Allocator
• Better performance and memory utilization than other implementation
• Main issues
– Object reuse• advantage of caching and reusing the same object,
rather than allocating and initializing arbitrary chunks of memory
– Hardware cache utilization • Most kernel objects have their important, frequently
accessed fields at the beginning of the object

Kernel Memory Allocation 25
Solaris 2.4 Slab Allocator– Allocator footprint
• Footprint of a allocator is the portion of the hardware cache and the translation lookaside buffer (TLB) that is overwritten by the allocator itself
• Large footprint causes many cache and TLB misses, reducing the performance of the allocator
• Large footprint: resource maps, buddy systems
• Smaller footprint: Mckusick-Karels, zone
• Design– slab allocator is a variant of the zone method
and is organized as a collection of object caches

Kernel Memory Allocation 26
Solaris 2.4 Slab Allocator (cont)
page-level allocator
vnode cache
proc cache
mbuf cache
msgb cache ...
activevnodes
activeprocs
activembufs
activemsgbs
back end
front end

Kernel Memory Allocation 27
Solaris 2.4 Slab Allocator (cont)• Implementation
free active free active active free active
NULL
coloring area(unused)
slab dataunused space
extra space for linkage
linked listof slabs insame cache
freelist
pointers

Kernel Memory Allocation 28
Solaris 2.4 Slab Allocator (cont)
• Analysis
– Space efficient
– Coalescing scheme results in better hardware cache and memory bus utilization
– Small footprint (only one slab for most requests)







