
PoS Tagging in Greek using Word Embeddings and Deep Neural Networks
Master Thesis Presentation
Thomas Asikis

Introduction • Automatic Part of Speech (PoS) Tagging on a text.
• A word may belong to different PoS, depending on its context, ie: Είδε το πράσινο δέντρο. (το: article)Το είπε στον Γιώργο. (το: pronoun)
Οφείλεις να διατάξεις την επανάληψη του παιχνιδιού! (διατάξεις: verb)Οι νέες διατάξεις προστατεύουν αποτελεσματικά τους πολίτες. (διατάξεις: noun)
• New words appear in a language (e.g. from slang and technical terms)
• We cannot solve the problem by simply using PoS dictionary.
2
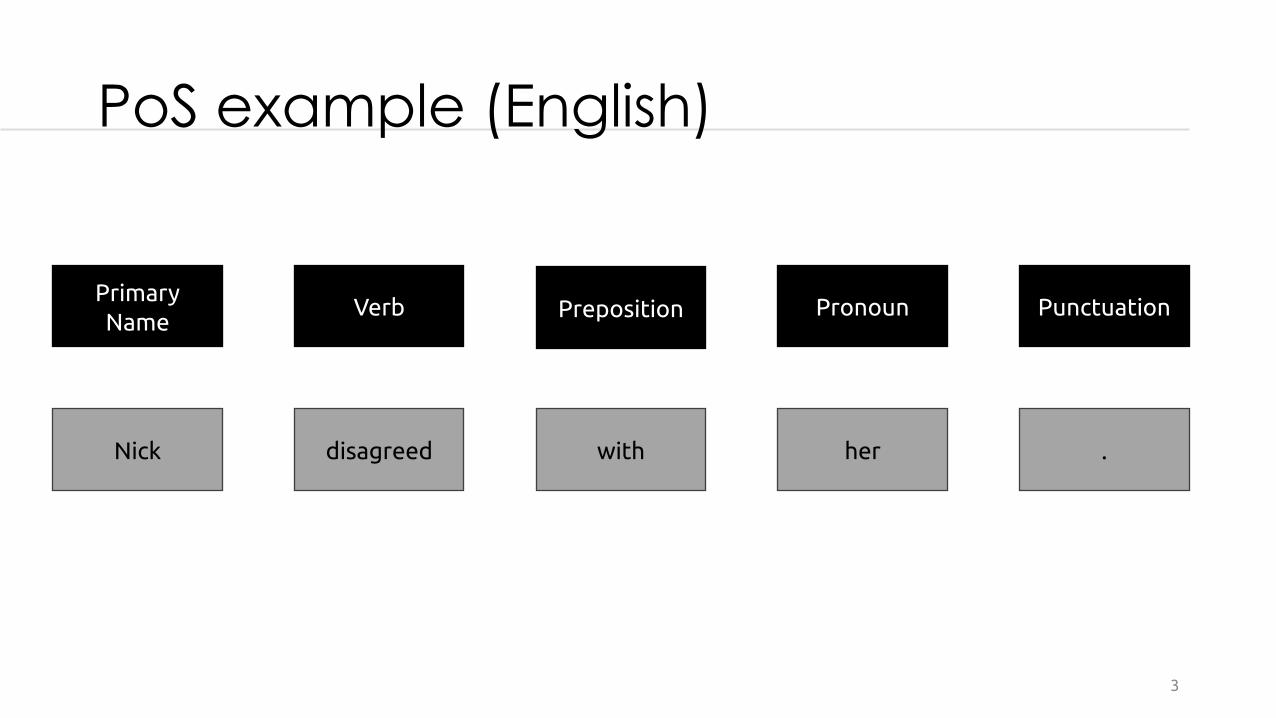
PoS example (English)
Primary Name
Nick disagreed with her .
Verb Preposition Pronoun Punctuation
3

Related Works
• Common Algorithms: Rule based, CRF, HMM, MEMM, ANN, SVM, max Entropy, DNN, rNN.• Accuracy ranges between 95% and 96% in most languages.• There aren’t so many publications in Greek in comparison to
other languages.• There are 4 previous Thesis regarding PoS Tagging in Greek. In
the last one (Koleli, 2012) a PoS Tagging System was developed.
4

Neural Networks
5
Actual Label – Predicted Label = Error
W2-2W2-1
W1-2W1-1
Backpropagation of errors updates thewights.

Recurrent Neural Networks
6
W2-2W2-1
W1-2W1-1

Recurrent Neural Network, Unfolded
7

Thesis Targets
• Redevelop the older PoS Tagging System, so that it can use more than one classification algorithms, a user defined set of PoS tags, and new features.• Use of new features such as feature embeddings, to
investigate whether they improve the classifier accuracies.• New classifiers (previous works used Maximum Entropy and
KNN), like CRF, SVM and Deep Neural Nets.• Improvement of Meta Tagging Rules.
8
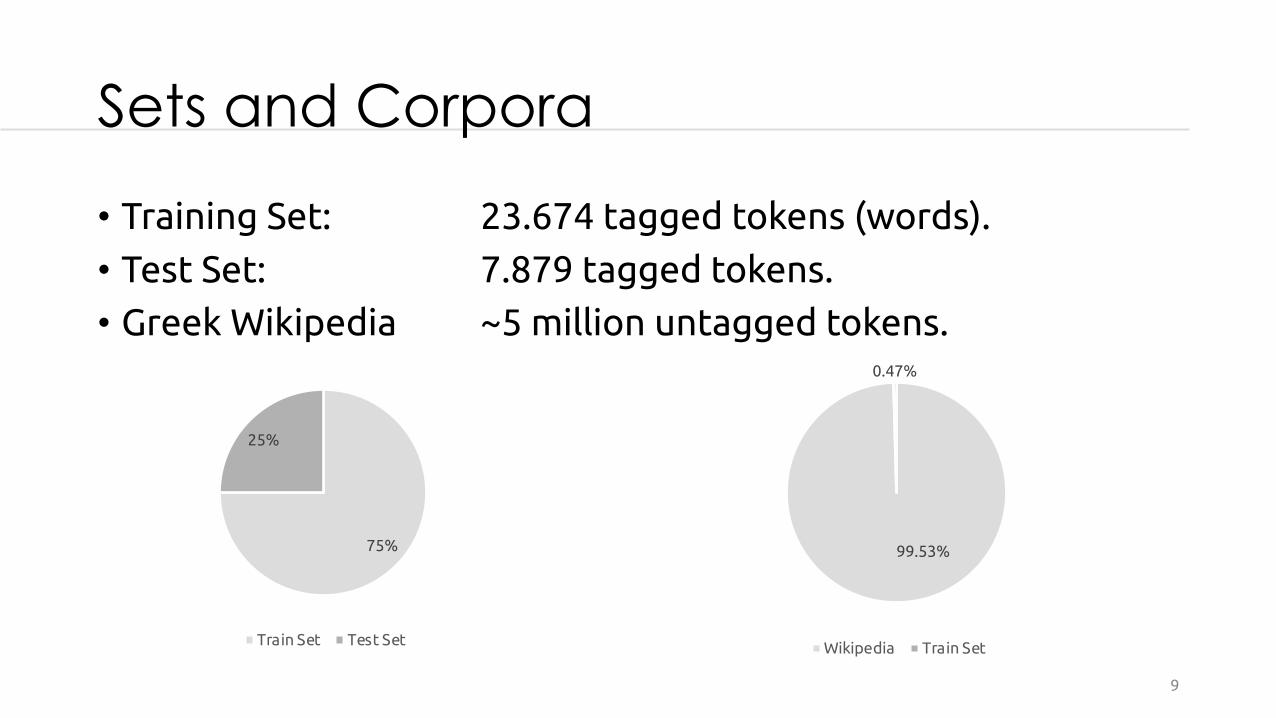
Sets and Corpora
• Training Set: 23.674 tagged tokens (words).• Test Set: 7.879 tagged tokens.• Greek Wikipedia ~5 million untagged tokens.
75%
25%
Train Set Test Set
99.53%
0.47%
Wikipedia Train Set
9

PoS tags – Small Set
Άρθρο - Article Επίρρημα - Adverb Μόριο - Particle
Ρήμα - Verb Σύνδεσμος - Conjunction Πρόθεση - Preposition
Σημείο Στίξης - Punctuation Ουσιαστικό - Noun Αντωνυμία - Pronoun
Επίθετο - Adjective Αριθμητικό - Numeral Άλλο - Other
10

PoS tags – Big Set
170 tags, that are derived by combining the small tag set withPoS specifications:• Plural, Singular.• Active, Passive, Infitive, Participle: Verb.
• Prepositional, Indefinite, Definitive: Article.• Nominative, Genitive, Accusative, Vocative.• Masculine, Feminine, Neuter• Inflectionless Pronouns
11

Old System Features - Morphological
• Word Length in Characters• Existence of Latin Characters• Existence of Number• Existence of full stop(.).
• Existence of Apostrophe (‘).
12
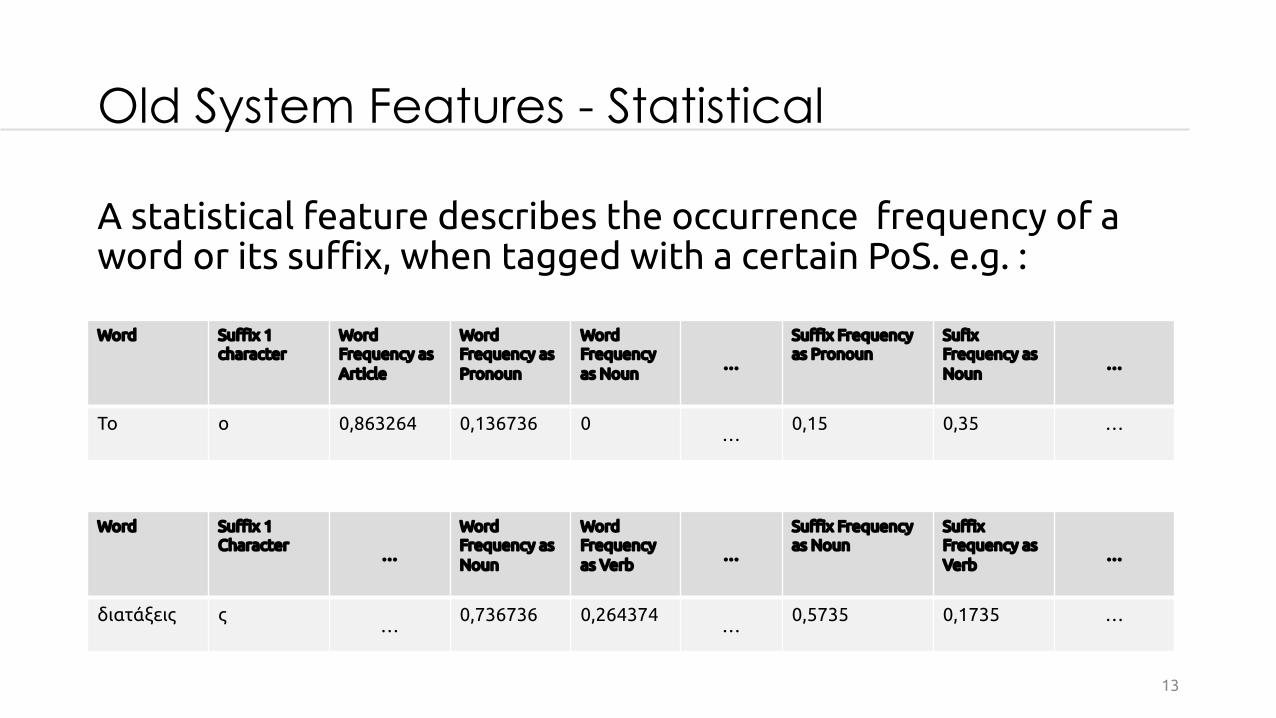
Old System Features - Statistical
A statistical feature describes the occurrence frequency of a word or its suffix, when tagged with a certain PoS. e.g. :
Word Suffix 1 character
Word Frequency as Article
Word Frequency as Pronoun
Word Frequencyas Noun
…
Suffix Frequencyas Pronoun
SufixFrequency as Noun
…
Το ο 0,863264 0,136736 0…
0,15 0,35 …
Word Suffix 1 Character
…
Word Frequency as Noun
Word Frequency as Verb
…
Suffix Frequency as Noun
Suffix Frequency as Verb
…
διατάξεις ς…
0,736736 0,264374…
0,5735 0,1735 …
13

Word Embeddings
• Word Embeddings represent words with similar meanings or syntax in near points of a multidimensional space.• They can be produces via Neural Networks and other ways
(Word2Vec, Glove).
• They can also be produced from Character, prefix, suffix and morphological embeddings (Malinakis, 2016).
14

Meta Tagging
• Preconstructed dictionary with words and the corresponding PoS tags.• If a word contains a number, it is tagged as numeric.• If a word is tagged as an article and the following word is
tagged as verb, then the article tag is replaced with a pronoun tag. Similarly, if a word is tagged as a pronoun before and the following word is tagged as noun, then the pronoun tag is replaced by the article tag.• Automatic creation of a PoS dictionary, from words that occur
only with one tag in the training set.
15

Accuracy Improvement with Meta Tagging
92.20%
92.40%
92.60%
92.80%
93.00%
93.20%
93.40%
93.60%
Ορθότητα
+0,58% Automatic Dictionary
+0,05% Article/Pronoun Rule
+0,09% Numeral Rule
+0% Hand created dictionary
Accuracy16

Machine Learning Algorithms
• Maximum Entropy, Stanford CoreNLP• CRF – Mallet, Stanford NER• Deep Neural Network 4 Layers (Multilayer Perceptron)• LSTM implementation from W.Ling et al. 2015
• SVM
1W. Ling, T. Luis, L. Marujo, R. Astudillo, S. Amir, C. Dyer, A. Black, I. Trancoso, “Finding Function in Form: Compositional Character Models for Open Vocabulary Word Representation”, Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal,pp 1520-1530, 2015a.
17

Deep Neural Network (4 Layers)
• Hidden layers: 4• Neurons per Layer: 90 – 130 – 80 – 60• Epochs: 2• Activation Functions: Rectified Linear Unit (ReLu) – ReLu –
ReLu – ReLu – SoftMax• Weight Learning: Backpropagation with Adam• Cost Function: Categorical Cross Entropy• Validation Set: 5 training set• Results: 90,80% accuracy without meta Tagging
18
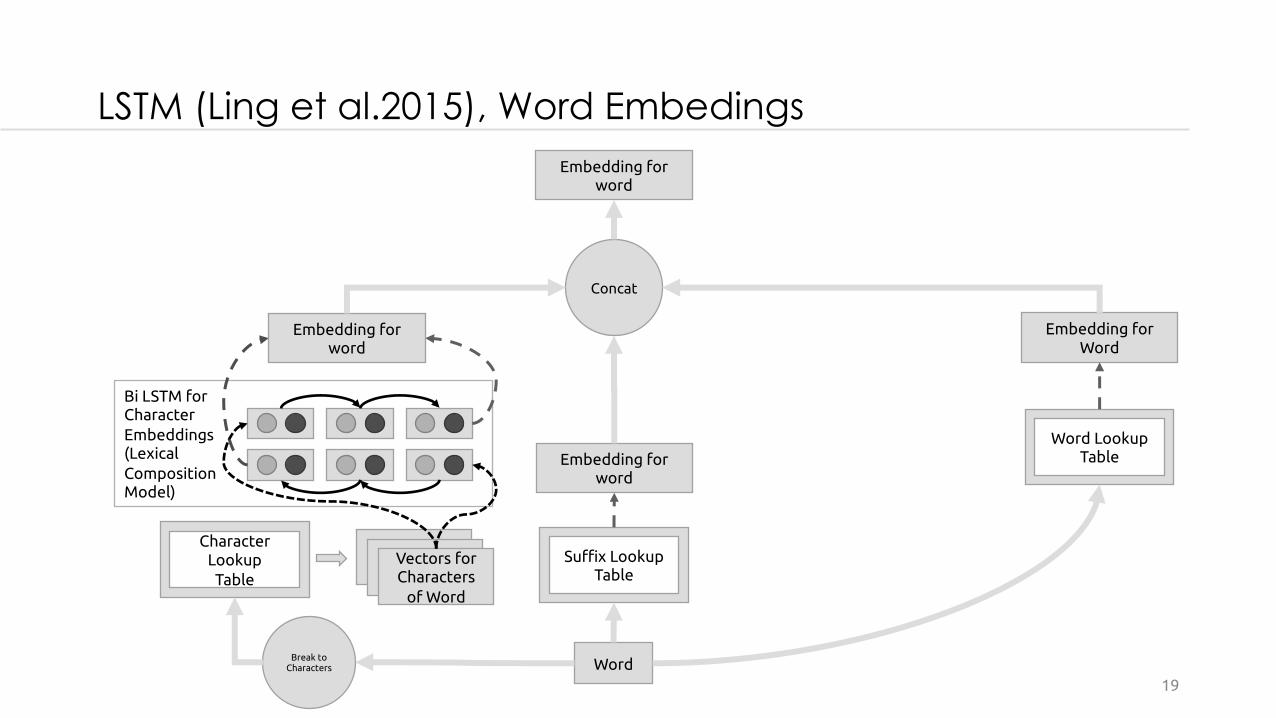
LSTM (Ling et al.2015), Word Embedings
Suffix Lookup Table
Embedding for word
Vectors for Characters
of Word
Bi LSTM for CharacterEmbeddings(Lexical CompositionModel)
Character Lookup Table
Embedding for word
Word Lookup Table
Embedding for Word
Embedding for word
Word
Concat
Break to Characters
19
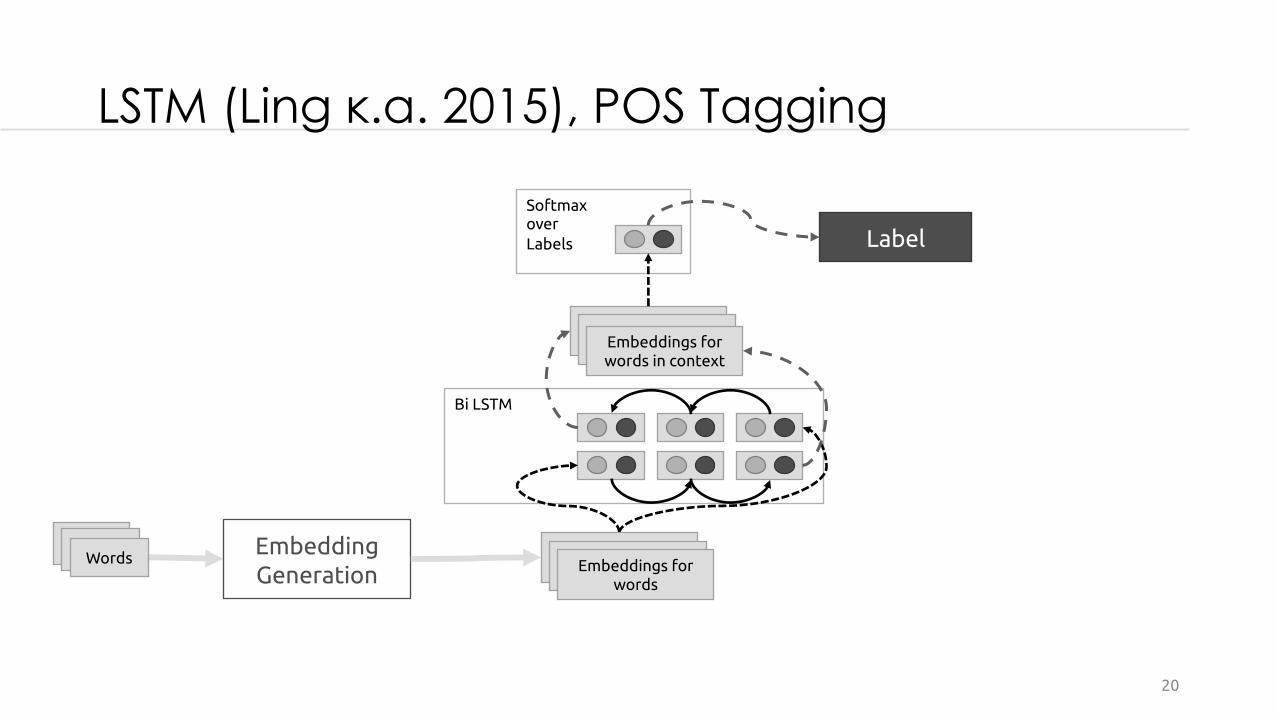
LSTM (Ling κ.α. 2015), POS Tagging
Embedding Generation
Bi LSTM
WordsWordsWords Embeddings for words
Embeddings for words in context
SoftmaxoverLabels Label
20
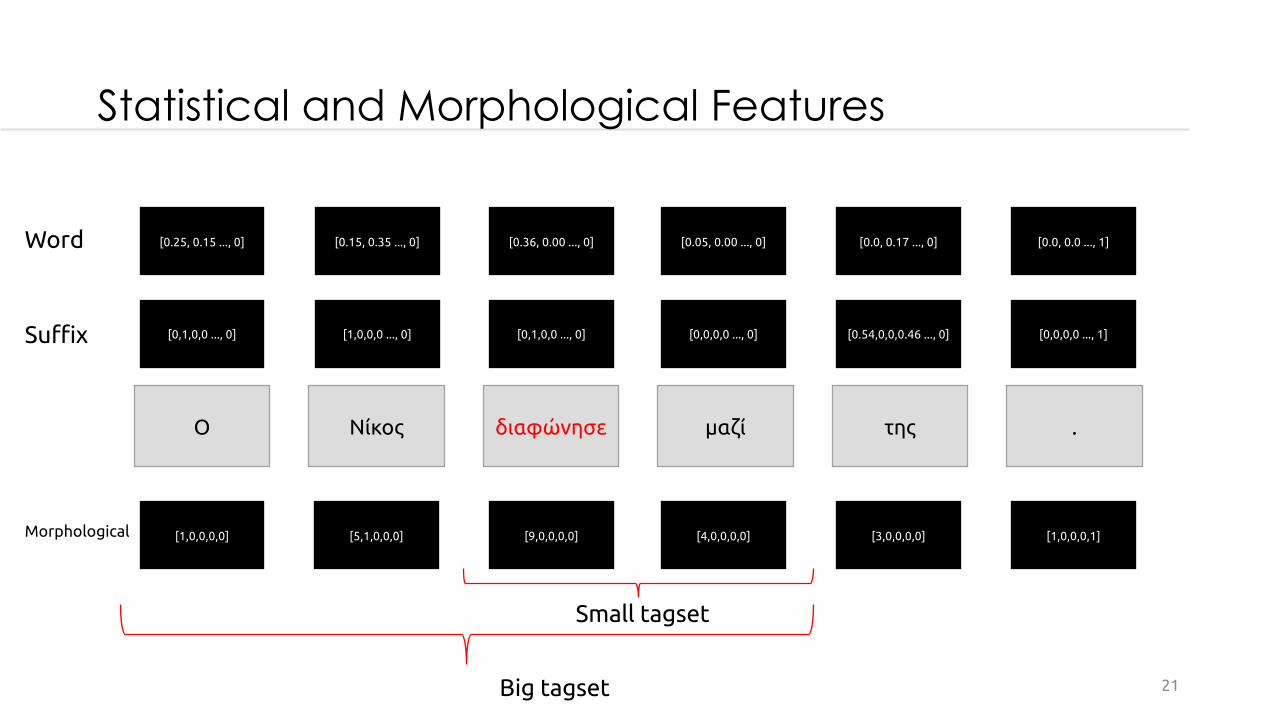
Statistical and Morphological Features
Ο Νίκος διαφώνησε μαζί της .
[0,1,0,0 ..., 0]
[0.25, 0.15 ..., 0]
[1,0,0,0 ..., 0]
[0.15, 0.35 ..., 0]
[0,1,0,0 ..., 0]
[0.36, 0.00 ..., 0]
[0,0,0,0 ..., 0]
[0.05, 0.00 ..., 0]
[0.54,0,0,0.46 ..., 0]
[0.0, 0.17 ..., 0]
[0,0,0,0 ..., 1]
[0.0, 0.0 ..., 1]
[1,0,0,0,0] [5,1,0,0,0] [9,0,0,0,0] [4,0,0,0,0] [3,0,0,0,0] [1,0,0,0,1]
Small tagset
Big tagset
Word
Suffix
Morphological
21

Word EmbeddignsΕτικέτα σε Διάγραμμα Περιγραφή
Morph1 50 Concatenation of peudo-prefix and pseudo-suffix embeddings, 25 + 25 dimensions.
Morph 150 Concatenation of peudo-prefix and pseudo-suffix embeddings, 75 + 75 dimensions.
Morph 300 Concatenation of peudo-prefix and pseudo-suffix embeddings, 150 + 150 dimensions.
Morph-P 25 Pseudo-prefix Word Embeddings, 25 dimensions.
Morph-P 75 Pseudo-prefix Word Embeddings, 75 dimensions.
Morph-P 150 Pseudo-prefix Word Embeddings,150 dimensions.
Morph-S 25 Pseudo-suffix Word Embeddings, 25 dimensions.
Morph-S 75 Pseudo-suffix Word, 75 dimensions.
Morph-S 150 Pseudo-suffix Word, 150 dimensions.
w2v 50 Word Embeddings from Word2Vec, 50 dimensions.
w2v 150 Word Embeddings from Word2Vec, 150 dimensions.
w2v 300 Word Embeddings from Word2Vec, 300 dimensions.
Word2Vec: Negative Sampling, Skip-gram, Default Settings1All of the embeddings starting with Morph- are produced in the Thesis of Malinakis (2016)
22

Evaluation, Small Tagset
93.41%
90.61%
91.67%
90.80%
94.56%
95.39%
92.72%
88.00%
89.00%
90.00%
91.00%
92.00%
93.00%
94.00%
95.00%
96.00%
MaxEnt, Old System Features SVM CRF DNN LSTM Ling et al. MaxEnt with Word Emveddings (w2v 300)
Algorithm Evaluation - Small Tagset
23
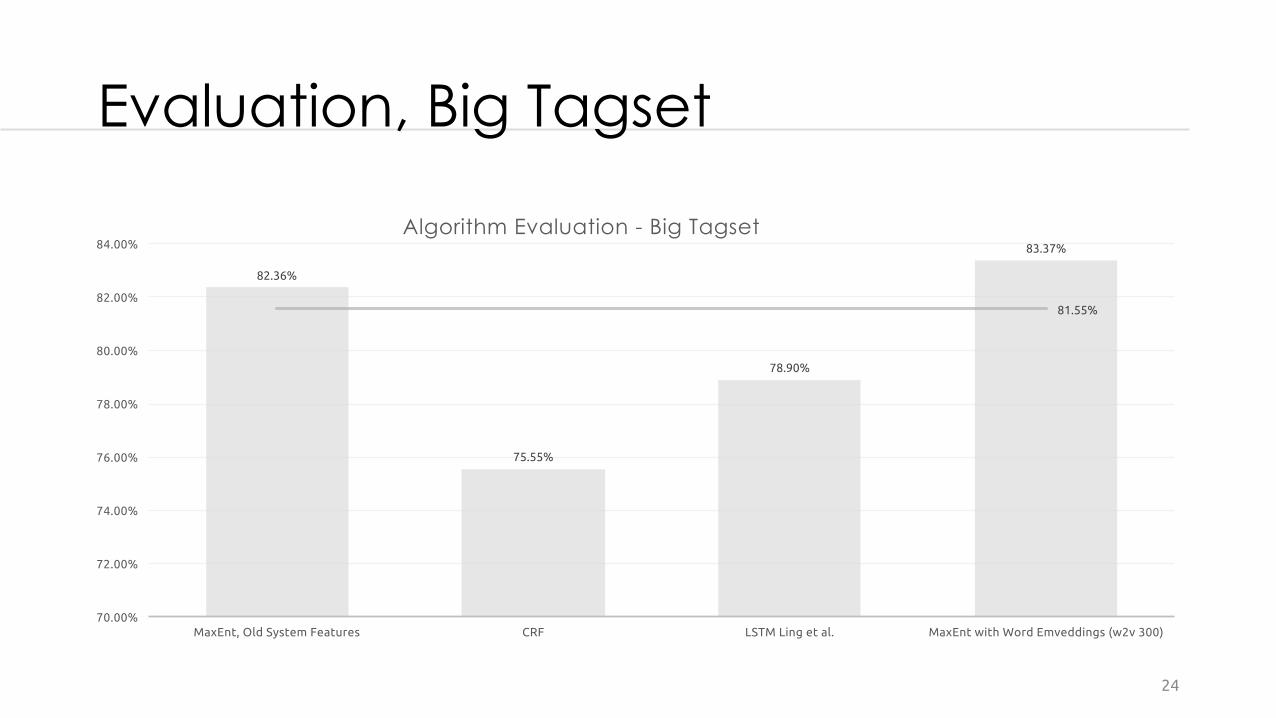
Evaluation, Big Tagset
82.36%
75.55%
78.90%
83.37%
81.55%
70.00%
72.00%
74.00%
76.00%
78.00%
80.00%
82.00%
84.00%
MaxEnt, Old System Features CRF LSTM Ling et al. MaxEnt with Word Emveddings (w2v 300)
Algorithm Evaluation - Big Tagset
24

Learning Curves, Small Tagset, MaxEnt, Word Embeddings
100.00% 99.21% 99.26% 99.15% 99.13% 99.14% 99.07% 99.05% 99.05% 99.04% 99.04%
40.02%
93.88%93.96% 94.61% 94.30% 94.34% 94.56% 94.59% 95.06% 95.10% 95.39%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Accuracy - Training Set Accuracy - Test Set
25
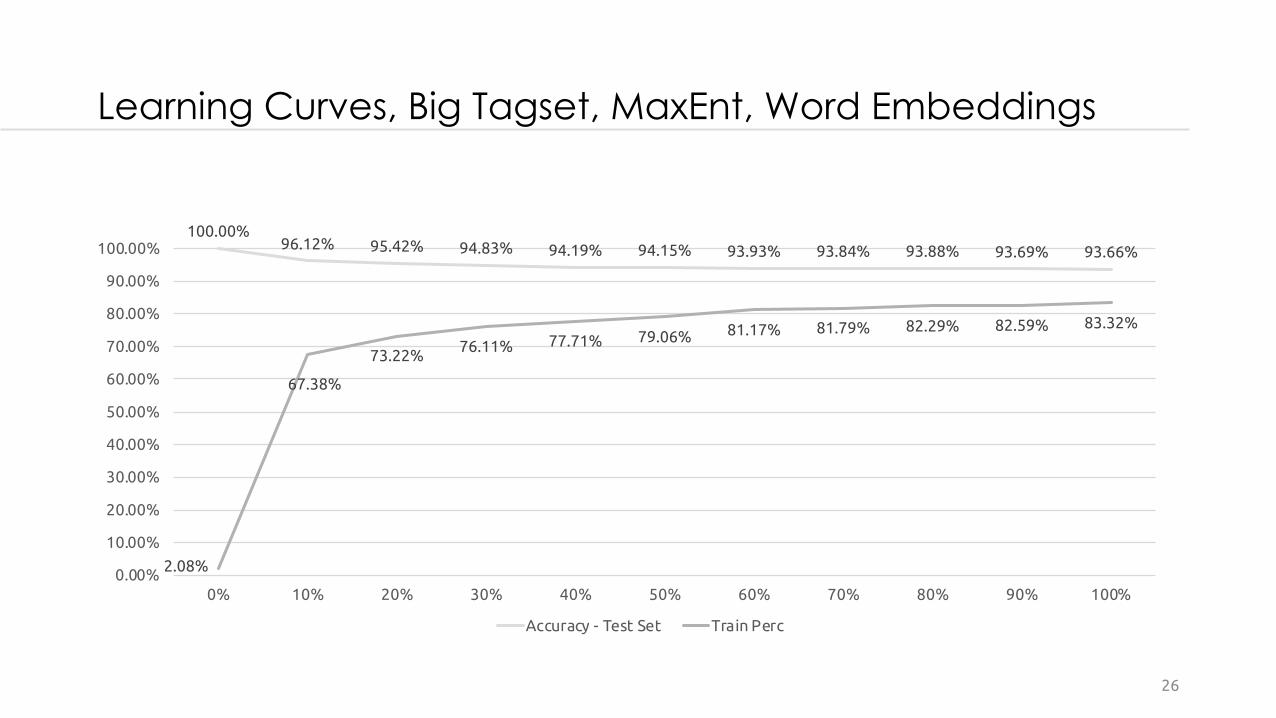
Learning Curves, Big Tagset, MaxEnt, Word Embeddings
100.00%96.12% 95.42% 94.83% 94.19% 94.15% 93.93% 93.84% 93.88% 93.69% 93.66%
2.08%
67.38%
73.22%76.11% 77.71% 79.06% 81.17% 81.79% 82.29% 82.59% 83.32%
0.00%
10.00%
20.00%
30.00%
40.00%
50.00%
60.00%
70.00%
80.00%
90.00%
100.00%
0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Accuracy - Test Set Train Perc
26

Conclusions
• We tested and compared several machine learning algorithms (MaxEnt, CRF, SVM, deep Neural nets).• The best results were achieved by using word embeddings
with MaxEnt classifier.
• LSTMs and DNNs were competitive especially in the small category, but they need more resources (time and hardware) to train.• CRFs did not perform as expected
27

Future Works
• Most of the Learning Curves, a bigger train set could lead in better results.• Most of the algorithms, and especially Neural Networks could
be parametrized more in order to produce even better results, especially via techniques like Bayesian optimization.• Meta Tagging can be improved by adding more rules.• Ensemble of Machine Learning with Meta Classifiers or Voting
cold further improve the system.• Dimensionality Reduction Techniques could help in faster
trainingand better results, especially in the big tagset.
28

QuestionsWhat was the last picture you took with your phone?
Do you know any big gossips?
Have you been pulled over by a cop?
What have you always wanted? Did you ever get it?
What kind of sickness have you lied about
so you wouldn’t go to work?
Have you ever danced in the
rain?
What was the weirdest prank call that you have made?
What is your perfect pizza?
What question do you hate to answer?
What is the last digit of Pi?
How do you start a conversation?
What keys on a keyboard do
you not use?
What is the longest you have gone without sleep?
29







