
Word EmbeddingUsing natural language for a real
classification challenge
pycon 8, Firenze2017-04-08
[email protected]@eng.it

Big Data competency center
Big Data and analytics competency center
DATA… not only BIG!
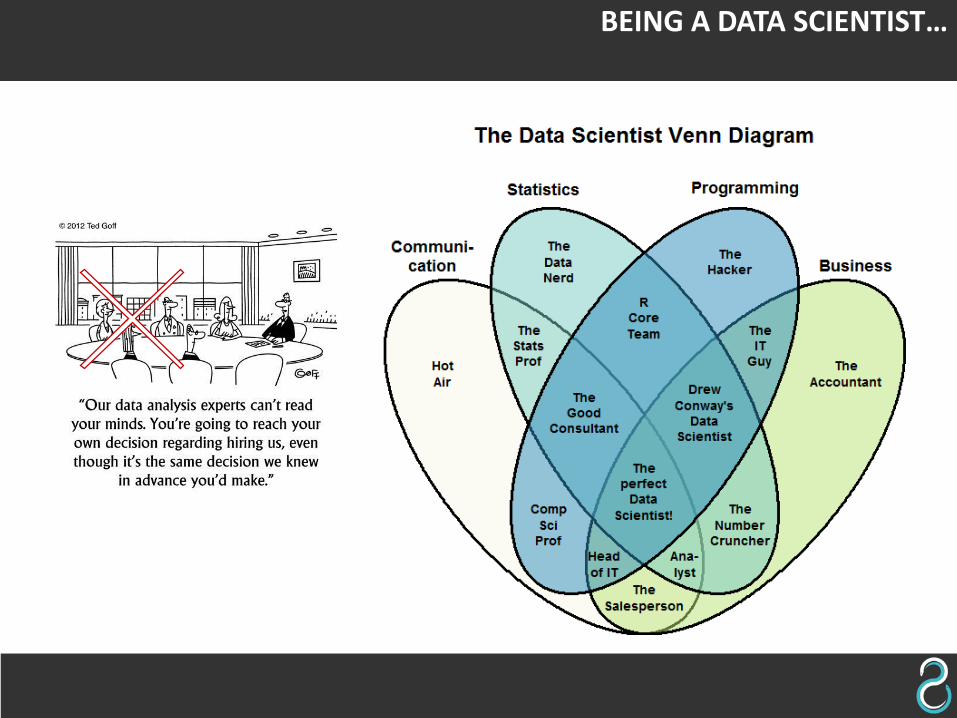
BEING A DATA SCIENTIST…
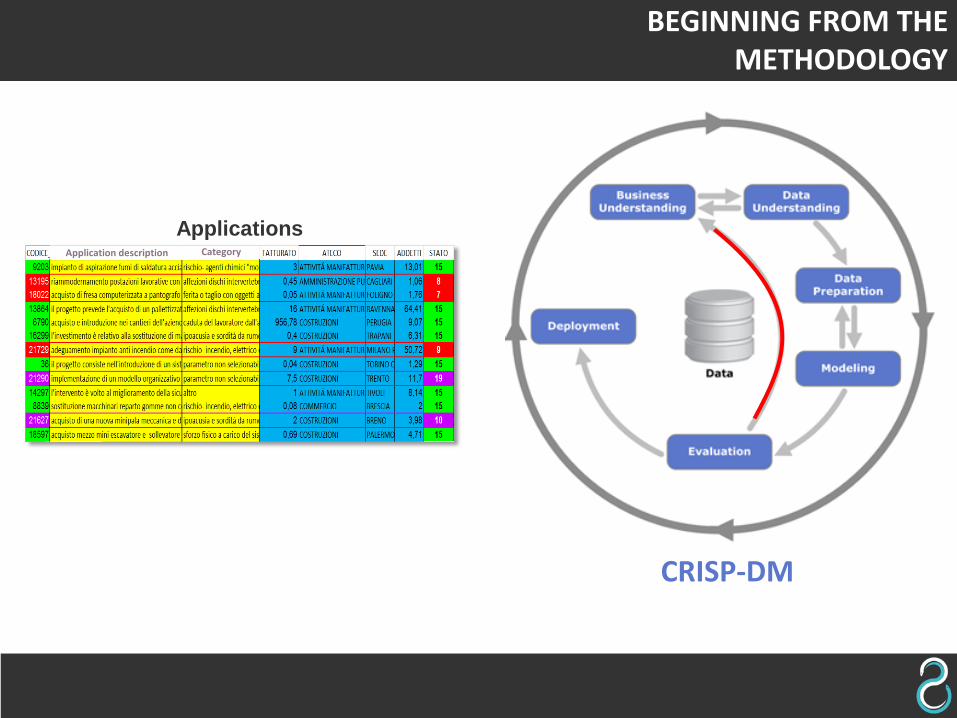
CRISP-DM
BEGINNING FROM THE METHODOLOGY
ApplicationsApplication description Category

Algorithms
Applications
SOM
Filtered
applications
COMING BACK TO THE BUSINESS UNDERSTANDING
MDS
Network
Analysis
?
Application description Category

CONSIDERING THE UNSTRUCTURED DATA: a first try (vector space model)…
Term 1 Term 2 Term 3 … … Term 𝑛 − 2 Term 𝑛 − 1 Term 𝑛
Project description 1 0.15 0.32 0.00 … … 0.33 0.84 0.01
… … … … … … … … …
Project description 𝑁 0.41 0.54 0.00 … … 0.04 0.00 0.02
Term frequency-inverse document frequency
(tf-idf)Application description Category
𝑤𝑖,𝑗 = 𝑡𝑓𝑖,𝑗 × log𝑁
𝑑𝑓𝑖
“The fact that, for example, not every adjectives occurs with every noun can be used as a measure of meaningdifference… In other words, difference in meaning correlates with difference in distribution.”
Harris (1954)
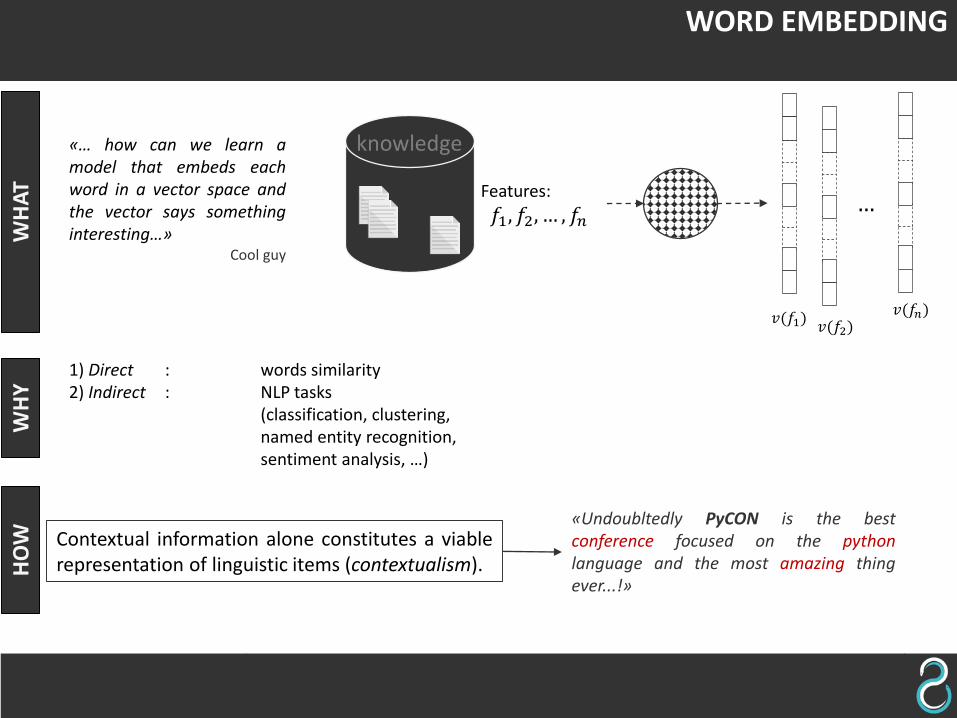
WORD EMBEDDING
«… how can we learn amodel that embeds eachword in a vector space andthe vector says somethinginteresting…»
Cool guy
knowledge
Features:
𝑓1, 𝑓2, … , 𝑓𝑛
𝑣(𝑓𝑛)𝑣(𝑓1)
…
𝑣(𝑓2)
Contextual information alone constitutes a viablerepresentation of linguistic items (contextualism).
1) Direct : words similarity2) Indirect : NLP tasks
(classification, clustering, named entity recognition, sentiment analysis, …)
«Undoubltedly PyCON is the bestconference focused on the pythonlanguage and the most amazing thingever...!»
WH
AT
WH
YH
OW

Annual Meetingsof the
Association for Computational
Linguistics(ACL)
Conferences on
EmpiricalMethods in
Natural Language Processing
(EMNLP)
WORD EMBEDDINGa quick market research
Year # ‘word
embedding’
2013 0
2014 4
2015 12
2016 17
Year # ‘embedding’
2013 2
2014 8
2015 25
2016 20

“You shall know a word by the company it
keeps” (Firth, J. R. 1957:11)
“… linguistics was the study of “processes and patterns of life”; “The essential socialbasis for the study of meaning of texts is the context of situation” (1956)
“… language is to be regarded as “embedded in the matrix of living experience…”(1968)
“… meaning “is deeply embedded in the living processes of persons maintainingthemselves in society” (1968)
WORD EMBEDDING:the importance of the context
Distributional hypothesis (Harris, 1954):
“… you can determine the meaning of a word by looking at its company (its context). Iftwo words occur in a same position in two sentences, they are very much related either insemantics or syntactics.”
Zellig Harris
“… the complete meaning of a word is always contextual, and no study of meaningapart from context can be taken seriously” (1935)
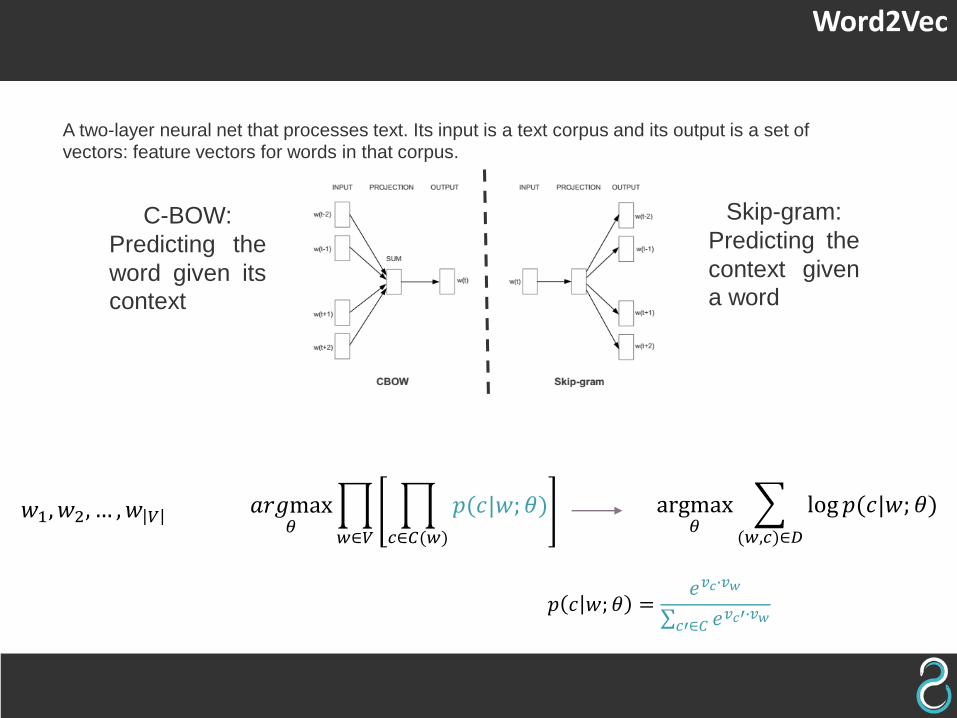
Word2Vec
A two-layer neural net that processes text. Its input is a text corpus and its output is a set of vectors: feature vectors for words in that corpus.
C-BOW:
Predicting the
word given its
context
Skip-gram:
Predicting the
context given
a word
𝑤1, 𝑤2, … , 𝑤 𝑉 𝑎𝑟𝑔max𝜃
𝑤∈𝑉
𝑐∈𝐶(𝑤)
𝑝(𝑐|𝑤; 𝜃) argmax𝜃
(𝑤,𝑐)∈𝐷
log 𝑝(𝑐|𝑤; 𝜃)
𝑝 𝑐 𝑤; 𝜃 =𝑒𝑣𝑐∙𝑣𝑤
𝑐′∈𝐶 𝑒𝑣𝑐′∙𝑣𝑤

WORD EMBEDDINGmeaningful vectors but… watch the biases
R
King Woman
0.99
0.99
0.05
0.7
0.02
0.01
0.999
0.5
royality
masculinity
femminility
age
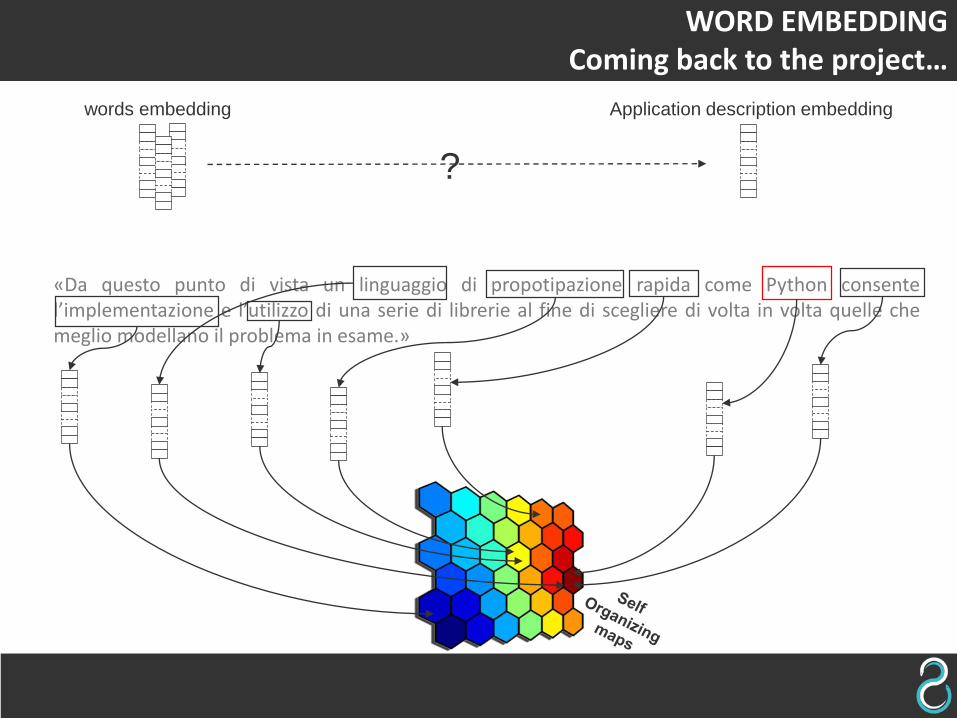
WORD EMBEDDINGComing back to the project…
words embedding
«Da questo punto di vista un linguaggio di propotipazione rapida come Python consentel’implementazione e l’utilizzo di una serie di librerie al fine di scegliere di volta in volta quelle chemeglio modellano il problema in esame.»
Application description embedding
?

WORD EMBEDDINGDoes it really work…?
Word Embedding for Natural Language Processing in Python: Wordembeddings are a family of Natural Language Processing (NLP) algorithmswhere words are mapped to vectors in low-dimensional space. The interestaround word embeddings has been on the rise in the past few years becausethese techniques have been driving important improvements in many NLPapplications like text classification sentiment analysis or machine translation.M.Bonzanini
Word Embedding: come codificare il linguaggio naturale per algoritmi diprevisione e classificazione Da qualche anno si parla sempre piùinsistentemente di Word Embedding identificando così quell insieme ditecniche che tentano di modellare il linguaggio umano creando unamappatura delle parole nel campo vettoriale. Come spesso accade perambiti in rapido sviluppo si è assistito alla nascita di diversi approccialgoritmici tra i quali a volte è difficile districarsi. Da questo punto di vistaun linguaggio di propotipazione rapida come Python consente limplementazione e l utilizzo di una serie di librerie al fine di scegliere divolta in volta quelle che meglio modellano il problema in esame. Il talkmostra la potenzialità del word embedding entrando nel merito di dueapplicazioni reali relative a due contesti lontani fra loro quali quelli dellapubblica amministrazione e del privato. In ambito PA viene mostrato comeanalizzando le descrizioni progettuali presentate da un insieme di aziendead un importante istituto italiano è possibile prevedere l esito dellerispettive richieste di finanziamento consentendo di aumentare in modosostanziale il numero degli investimenti. Nella seconda parte ci spostiamoinvece nel privato e mostriamo come codificare un informazionenaturalmente non strutturata come la descrizione di un intervento in unaofficina meccanica rendendola così gestibile al pari di quella strutturata.A.Ianni, F.Tuosto

Textual content
Distribuzione dei topics
TF-IDFmatrix
word2vecmatrix
Cleaning & Transformation
Vocabulary codification
Wikipedia
REJECTEDClassification
doc2vecmatrix
SUCCESSFUL
RETREATED
FORECASTING
Structured content
company data
application data
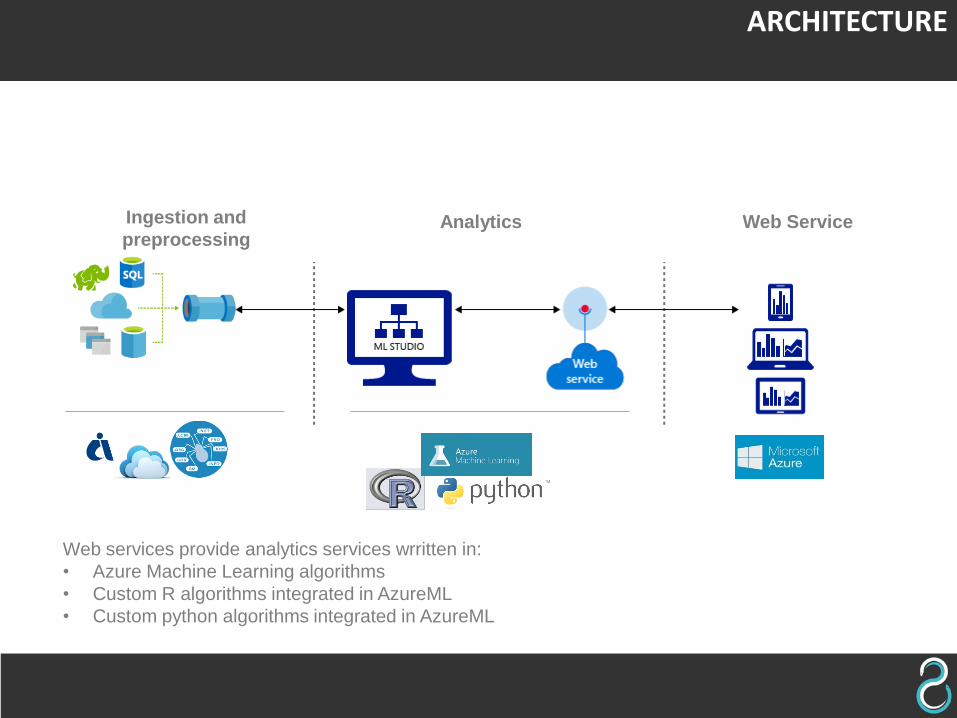
Ingestion and
preprocessingAnalytics Web Service
Web services provide analytics services wrritten in:
• Azure Machine Learning algorithms
• Custom R algorithms integrated in AzureML
• Custom python algorithms integrated in AzureML
ARCHITECTURE

HANDS ON CODEstealing from pycon..
from bs4 import BeautifulSoupimport requestsimport reimport csvUSE_PROXY = TrueYEAR = 2017MinNumberOfWords = 20
html_file = 'pyconSchedule_'+str(YEAR)+'.html'speech_file = 'speechText_'+str(YEAR)+'.csv'
with open(html_file, 'r') as htmlFile, open('proxy_credentials.txt', 'r') ascredentials, open(speech_file, 'w') as outputFile:
lines = credentials.readlines()user = lines[0].split(":")[1]password = lines[1].split(":")[1]outputWriter = csv.writer(outputFile, delimiter=";",
quoting=csv.QUOTE_NONE, quotechar='$', lineterminator='\n')if USE_PROXY:
proxies={'http' : lines[0],'https': lines[1]
}else:
proxies = {'http' : None,'https': None
}
html_doc= htmlFile.read()soup = BeautifulSoup(html_doc, 'html.parser')evts=soup.select('div.track > div')for evt in evts:
# find the titletitle_html= evt.select('h3 > a')link=''if title_html:
link=title_html[0].attrs['href']if 'talks' in link:
title_text=title_html[0].get_text()response=requests.get(link, proxies=proxies)description_content=response.content
description_as_tag=BeautifulSoup(description_content,'html.parser')select = description_as_tag.select('div.cms')if select:
tags=description_as_tag.select('span.tag')tags_list=[]if tags:
for tag in tags:tags_list.append(tag.get_text().encode('utf8'))
description_text= select[0].get_text()description_text=re.sub('[,:;\n\r()\!\?"]',' ',description_text)myLine =
['"'+title_text.encode('utf8')+'"','"'+description_text.encode('utf8')+'"',','.join(tags_list)]
if len(myLine[0]) > MinNumberOfWords:outputWriter.writerow(myLine)

HANDS ON CODEmining pycon..







