
Fabi
en H
erm
enier
Resource management in IaaS cloud

where to place the VMs
how much to allocate?

1What can a resource manager do for you
3

2Models of VM scheduler
4

3Implementing VM schedulers
5

1What can a resource manager do for you
6

central piece of code
provide the awaited Quality of Service address the management objectives

?
the RM should solve that
VM1VM2 V
M3
VM4 VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem

the RM should prevent that
VM1
VM
3
VM4VM5
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem VM6
VM2

a contract where a service is formally defined
Service
Agreement
Levelperformance indicator
MTTRMTBF
availability (MTBF/MTTR + MTBF)pricing
penalties…

uptime as the only Key Performance Indicator (KPI)?

Cloud Performance SLAs
What customers wantguaranteed capacities (CPU, memory, bw)
guaranteed latencies/throughput (network, load balancer, disk)
What providers give-


the objectiveprovider side
min(x) or max(x)

min(penalties)min(Total Cost Ownership)
min(unbalance)
atomic objectives
…

min(αx + β y)
composite objectivesusing weights
useful to model sth. you don’t understand ?How to estimate coefficients ?
min(α TCO + β VIOLATIONS)max(REVENUES)
€ as a common quantifier:

?Should a client ask for an objective

?Should a client ask for an objective
no if the provider cannot prove it is achieved
proving a latency is minimal …one can check the latency is below a threshold

VM-host affinity (DRS 4.1)
Dedicated instances (EC2)
MaxVMsPerServer (DRS 5.1)
apr. 2011
mar. 2011
sep. 2012
The constraint needed in 2012
?? 2013
VM-VM affinity (DRS)
2010 ?
Dynamic Power Management (DRS 3.1)
2009 ?
SLOs and objectives are evolving
there is no holy grail

2Models of VM schedulers
20

monitoring data
VM queue
actu
ator
sVM scheduler
cloud model
decisions

sche
dulin
g m
odel
s
static dynamic schedulers
static dynamic resource allocation

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulers
VM7

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulers
VM7

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulers
VM7

Combinatorial problem !
past decisions impact the future ones

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulers
buffering might help

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulers
buffering might help

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulers
VM7
buffering might help

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulersVM7
buffering might help

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
static schedulersVM7
buffering might help
/!\ incoming ratestarvation

static schedulersmanipulate the VM queue only
react on VM arrival

static schedulersproseasy to model simple standard actions manage a few elements

static schedulerscons
hard to perform fine grain optimisation

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
dynamic schedulers
consider every VMs

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
dynamic schedulers
consider every VMs

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
dynamic schedulers
consider every VMs
VM7

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
dynamic schedulers
consider every VMs
VM7

VM1
VM2 VM
3
VM4VM5
VM
6
N1 N2
N4N3
cpu cpu
cpucpu
mem
mem
mem
mem
dynamic schedulers
consider every VMsVM7

dynamic schedulersmanipulate the VM queue
reconfigure the schedule with migrations
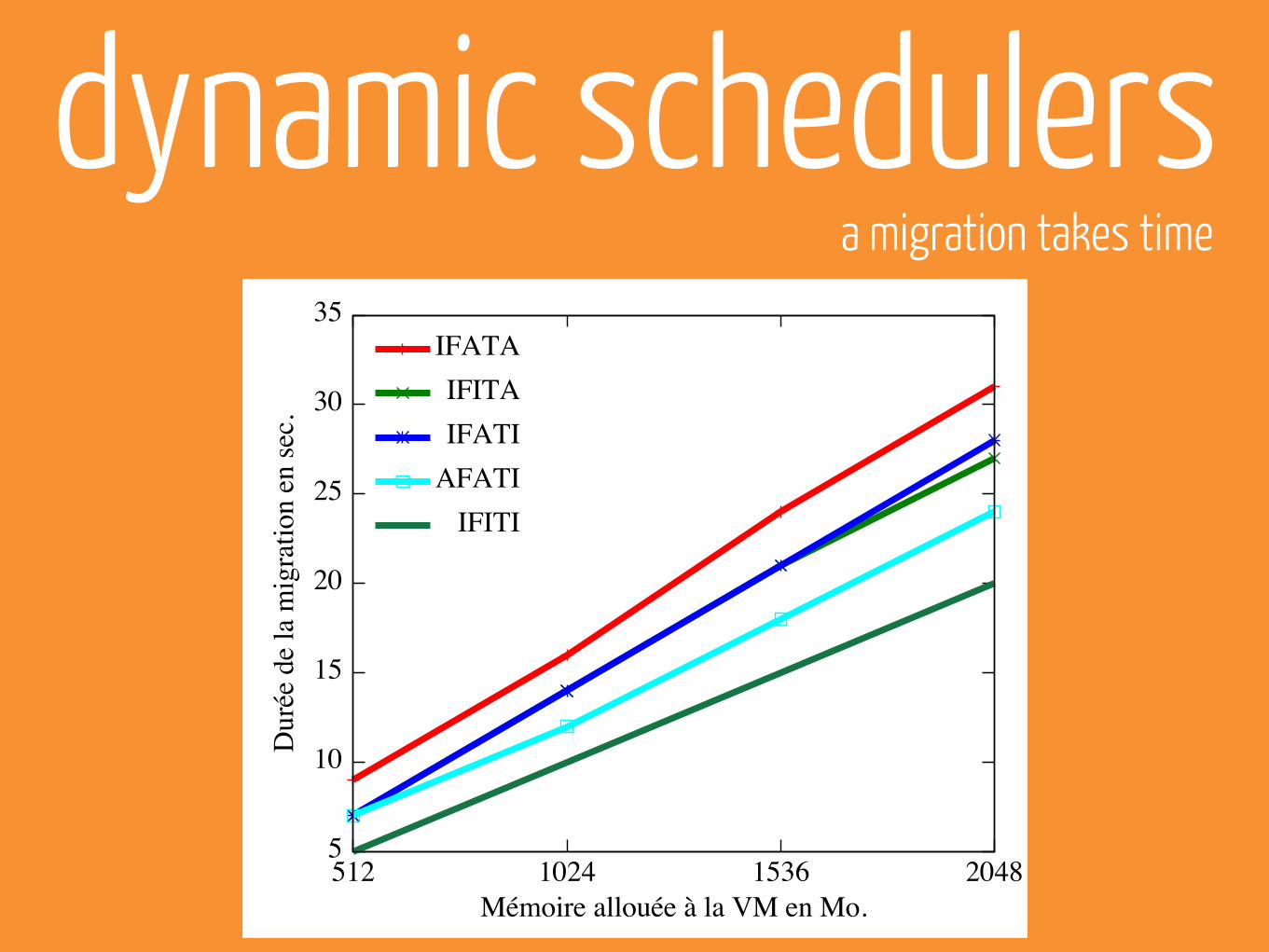
dynamic schedulersa migration takes time
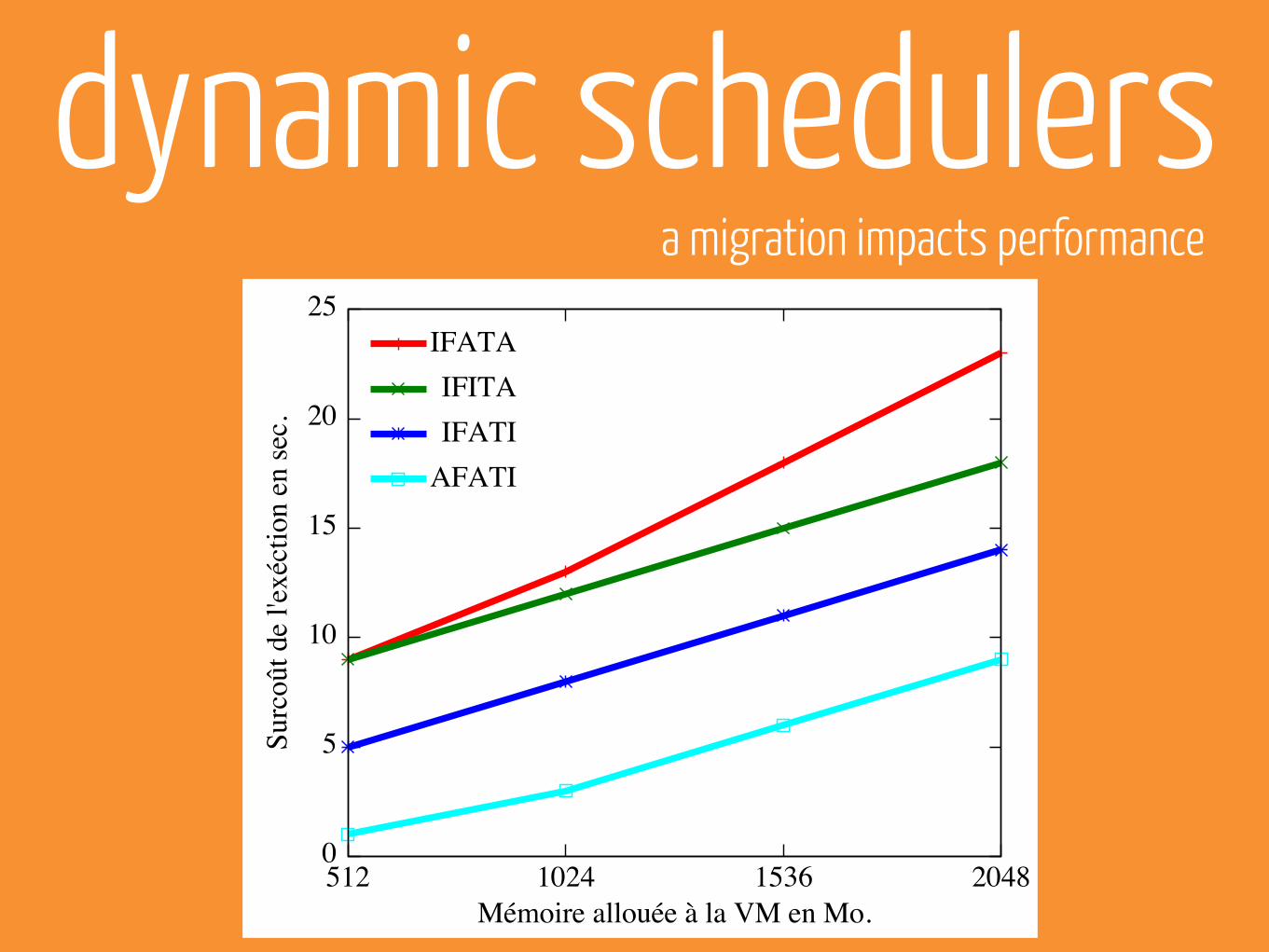
dynamic schedulersa migration impacts performance
dynamic schedulers
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
?
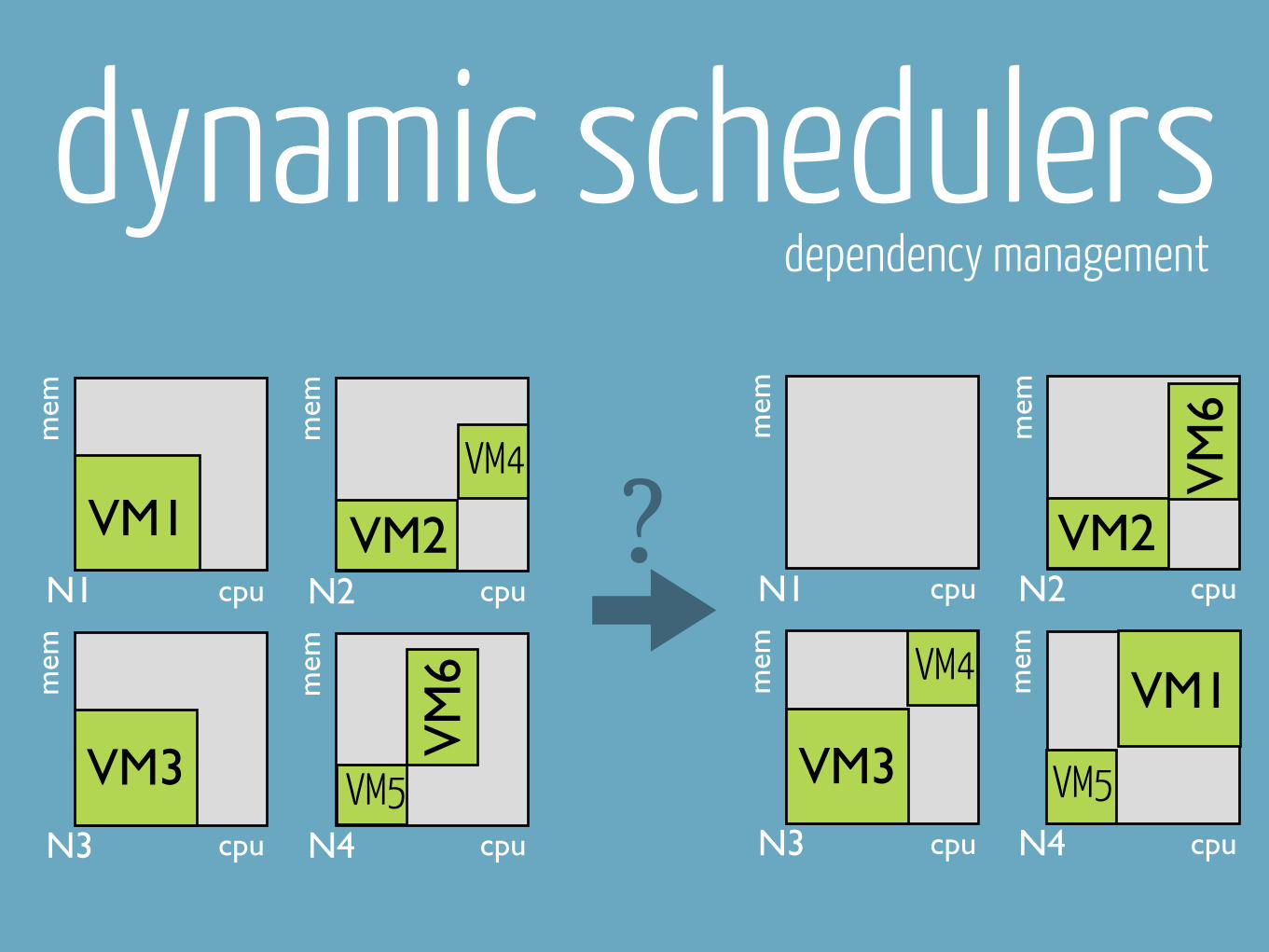
dependency management
VM1
VM1
VM2 VM2
VM3
VM4
VM5VM5
VM
6
VM
6
VM3
VM4

dynamic schedulersdependency management
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5V
M6

dynamic schedulersdependency management
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5V
M6

dynamic schedulersdependency management
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5V
M6

dynamic schedulersdependency management
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1
VM2
VM3
VM4
VM5V
M6

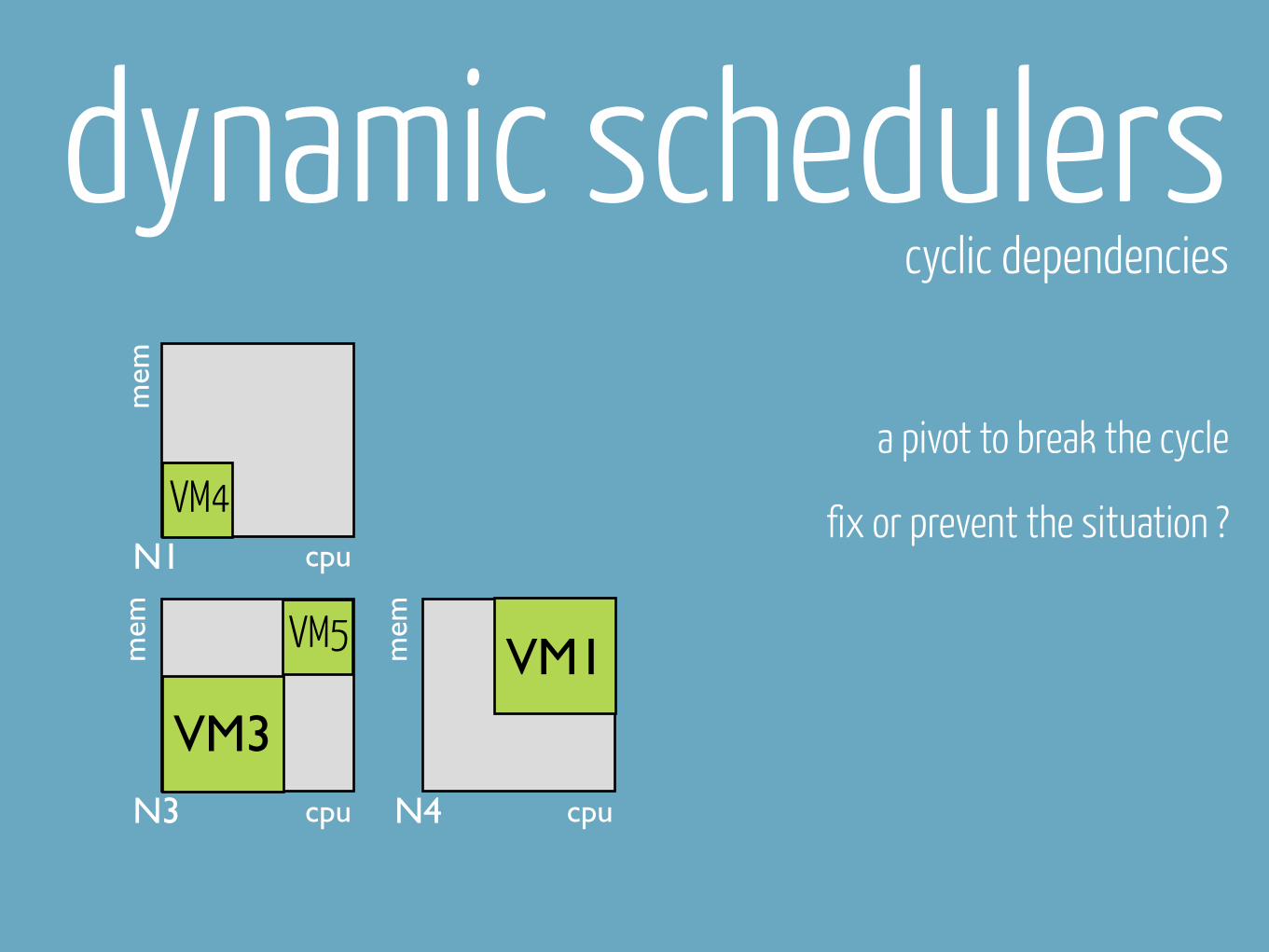
dynamic schedulerscyclic dependencies
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
VM1
VM5VM3
VM4
anti-affinity(VM3,VM4)min(#onlineNodes)
?
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
VM1
VM4VM3
VM5
anti-affinity(VM3,VM4)min(#onlineNodes)

dynamic schedulerscyclic dependencies
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
VM1
VM5VM3
VM4
a pivot to break the cycle
fix or prevent the situation ?

dynamic schedulerscyclic dependencies
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
VM1
VM5VM3
VM4a pivot to break the cycle
fix or prevent the situation ?
dynamic schedulerscyclic dependencies
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
VM1VM5
VM3
VM4a pivot to break the cycle
fix or prevent the situation ?

dynamic schedulerscyclic dependencies
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
VM1VM5
VM3 VM4
a pivot to break the cycle
fix or prevent the situation ?

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1
VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1
VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3
sol #1: 1m,1m,2m

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3
sol #1: 1m,1m,2m

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3
sol #1: 1m,1m,2m

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3
sol #1: 1m,1m,2m

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3
sol #1: 1m,1m,2m
sol #2: 1m,1m1m

dynamic schedulersquality at a price
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
min(#onlineNodes) = 3
sol #1: 1m,1m,2m
sol #2: 1m,1m1m
lower MTTR (faster)

dynamic schedulersquality at a price
the objective should reflect reconfiguration costs
min(MTTR), min(#migrations),…

dynamic schedulersproscontinuous optimisation through reconfiguration

dynamic schedulerscons
harder to model harder to scale
technically expensive costly reconfiguration

benefits depends on
dynamic scheduling is rare in public or large clouds
dynamic scheduling for the win
in theory yes but that’s theory
the workload the objective/ SLAs the infrastructure
?

static dynamic
schedulersstatic dynamic
resource allocation
sche
dulin
g m
odel
s

static resource allocation
cpu, ram, i/o, bandwidth allocated once for all
allocation != utilisation
N1
mem
no sharing conservative allocation
pcpu
VM1
VM2
VM3

N1 pcpu
mem
sharing (overbooking)
performance loss with concurrent accesses
acceptable if stated in the SLA
static resource allocation
VM1
VM2
VM3

dynamic resource allocation
N1 pcpu
mem
cpu, ram, i/o, bandwidth allocated can be revised
N1 pcpu
mem
to fix violations
VM1
VM3
VM2

dynamic resource allocation
N1 pcpu
mem
cpu, ram, i/o, bandwidth allocated can be revised
N1 pcpu
mem
to fix violations
VM1
VM2

dynamic resource allocation
N1 pcpu
mem
cpu, ram, i/o, bandwidth allocated can be revised
N1 pcpu
mem
to fix violations
VM1
VM2

dynamic resource allocation
N1 pcpu
mem
N1 pcpu
mem
to support vertical elasticity
VM1
VM2
VM3

dynamic resource allocation
N1 pcpu
mem
N1 pcpu
mem
VM1
VM2
to support vertical elasticity
VM3

dynamic resource allocation
N1 pcpu
mem
N1 pcpu
mem
VM1
VM2
to support vertical elasticity

dynamic resource allocation
N1 pcpu
mem
N1 pcpu
mem
VM1
VM2
to support vertical elasticity
VM2

benefits depends on
dynamic resource allocation for the win
common on CPU + overbooking (inc. hosting capacity)
the workload the objective/ SLAs the infrastructure
?exceptional for memory
(huge performance loss)

RECAP50

The VM scheduler makes cloud benefits real
51

no holy grail
52

think about what is costly
53

static scheduling for a peaceful life
54

dynamic scheduling to cease the day
55

with great power comes great responsibility
56

Coding a VM scheduler3


static or dynamic scheduler allocation
does the workload/SLA/objective requires migration
VM scheduling is hard
?
?
maximum duration to schedule ?

issues with large infrastructures or hard problems
fast adhoc heuristics despite corner cases
some use biased complete approaches (linear programming, constraint programming)
VM scheduling is NP-Hard
like him

vector packing problemitems with a finite volume to
place inside finite bins
the basic to model the infra. 1 dimension = 1 resource
a generalisation of the bin packing problem
VM1
VM
3
N1 cpu
mem
VM2
VM
4
N2 cpu
mem

?Which resource can be modeled as a
packing dimension

?Which resource can be modeled as a
packing dimension
CPU, memory, disk IO, licences cardinality, network boundaries, …end to end network

how to support migrations
temporary, resources are used on the source and the destination nodes

how to support migrationsa simple way
n-phases vector packing
VM duplication between 2 phases to simulate the migration
hard to manipulate to compute long term previsionsN3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
easy to implement

how to support migrationsa simple way
n-phases vector packing
VM duplication between 2 phases to simulate the migration
hard to manipulate to compute long term previsionsN3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
easy to implementVM4

how to support migrationsa simple way
n-phases vector packing
VM duplication between 2 phases to simulate the migration
hard to manipulate to compute long term previsionsN3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3 VM5
VM
6
easy to implementVM4

how to support migrationsa simple way
n-phases vector packing
VM duplication between 2 phases to simulate the migration
hard to manipulate to compute long term previsionsN3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3 VM5
VM
6
easy to implement
VM
6
VM4

how to support migrationsa simple way
n-phases vector packing
VM duplication between 2 phases to simulate the migration
hard to manipulate to compute long term previsionsN3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3 VM5
easy to implementVM4
VM
6

how to support migrationsa simple way
n-phases vector packing
VM duplication between 2 phases to simulate the migration
hard to manipulate to compute long term previsionsN3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3 VM5
easy to implementVM1VM4
VM
6

how to support migrationsa simple way
n-phases vector packing
VM duplication between 2 phases to simulate the migration
hard to manipulate to compute long term previsionsN3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM2
VM3 VM5
easy to implementVM4
VM
6
VM1

how to support migrationsthe alternative way
1-phase
+ compute dependencies step by steps
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2
VM3
VM4
VM5
VM
6
ok to implement
N5 cpu
memVM7
offline(N2) + no CPU sharing
cycles #migrations/!\

how to support migrationsthe alternative way
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1 VM2VM3VM5V
M6
N5 cpu
mem
VM7 VM4

how to support migrationsthe alternative way
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2 cpu
mem
VM1
VM2
VM3
VM5V
M6
N5 cpu
mem
VM7
1) migrate VM2, migrate VM4, migrate VM5
VM4

how to support migrationsthe alternative way
N3 cpu
mem
N1 cpu
mem
N4 cpu
mem
N2
VM1
VM2
VM3
VM5V
M6
N5 cpu
mem
VM7
1) migrate VM2, migrate VM4, migrate VM52) shutdown(N2), migrate VM7
VM4

coarse grain staging delay actions
mig(VM2)
mig(VM4)
mig(VM5)
off(N2)
mig(VM7)
timestage1 stage2

the clean way to model space and time
Resource-Constrained Project Scheduling Problem
N1
N2
N3
N4
time
VM1
VM5VM6
VM3VM7
VM4VM2 off
0
VM1
VM3
VM7
N5
VM5
VM4VM2
VM6
3 4 8

the clean way to model space and time
Resource-Constrained Project Scheduling Problem
N1
N2
N3
N4
time
VM1
VM5VM6
VM3VM7
VM4VM2 off
0
VM1
VM3
VM7
N5
VM5
VM4VM2
VM6
3 4 8

the clean way to model space and time
Resource-Constrained Project Scheduling Problem
N1
N2
N3
N4
time
VM1
VM5VM6
VM3VM7
VM4VM2 off
0
VM1
VM3
VM7
N5
VM5
VM4VM2
VM6
3 4 8

the clean way to model space and time
Resource-Constrained Project Scheduling Problem
N1
N2
N3
N4
time
VM1
VM5VM6
VM3VM7
VM4VM2 off
0
VM1
VM3
VM7
N5
VM5
VM4VM2
VM6
3 4 8

the clean way to model space and time
Resource-Constrained Project Scheduling Problem
N1
N2
N3
N4
time
VM1
VM5VM6
VM3VM7
VM4VM2 off
0
VM1
VM3
VM7
N5
VM5
VM4VM2
VM6
3 4 8

the clean way to model space and time
Resource-Constrained Project Scheduling Problem
N1
N2
N3
N4
time
VM1
VM5VM6
VM3VM7
VM4VM2 off
0
VM1
VM3
VM7
N5
VM5
VM4VM2
VM6
3 4 8

the pure way to support migrations
Resource-Constrained Project Scheduling Problem
1 resource per (node x dimension), bounded capacity
tasks to model the VM lifecycle. height to model a consumption width to model a duration
at any moment, the cumulative task consumption on a resource cannot exceed its capacity
comfortable to express continuous optimisation
very hard to implement (properly)

From a theoretical schedule to a practical one
duration may be longer
0:3 - migrate VM4 0:3 - migrate VM5 0:4 - migrate VM2 3:8 - migrate VM7 4:8 - shutdown(N2)
convert to an event based schedule
- : migrate VM4 - : migrate VM5 - : migrate VM2 !migrate(VM2) & !migrate(VM4): shutdown(N2) !migrate(VM5): migrate VM7

Back to vector packing
based approaches

Fit Fit Decrease (FFD)basic VM scheduling
sort VMs in desc order for each VM pick the first suitable node

Fit Fit Decrease (FFD)basic VM scheduling
sort VMs in desc order for each VM pick the first suitable node
difficult VMs first !

Fit Fit Decrease (FFD)basic VM scheduling
sort VMs in desc order for each VM pick the first suitable node
difficult VMs first !enough free resources

N1 N2 N3 N4
V1
V2
V3
V4
Fit Fit Decrease (FFD)example

N1 N2 N3 N4
V1
V2
V3
V4
Fit Fit Decrease (FFD)example

N1 N2 N3 N4
V1
V2
V3
V4
Fit Fit Decrease (FFD)example

N1 N2 N3 N4
V1
V2
V3
V4
Fit Fit Decrease (FFD)example

N1 N2 N3 N4
V1
V2
V3
V4
Fit Fit Decrease (FFD)example

multi-dimension sorting ?
V1
V2
V3
V4 easy, 1 dimension is varying
V1
V3
V4 easy, uniform variation
?V1
V3
V4

multi-dimension sorting ?
V1
V2
V3
V4 easy, 1 dimension is varying
V1
V3
V4 easy, uniform variation
V1
V3
V4 sort by dimension
aggregate dimensions find the most critical one …

Balancing VMs

Why?

Why?to reduce loss in terms of failures to reduce hotspots to absorb load spikes

balancingmin(stddev([load(n ), … , load(n )]))
in theory
1 i
min(max([load(n ), … , load(n )]),min([load(n ), … , load(n )]),)
1 i
1 i
OR

Worst Fit Decrease (WFD)balancing, a practice
sort VMs in desc order for each VM pick the suitable node with the highest remaining space

balancing over multiple dimensions
?

dimension normalisation worst dimension dimension aggregation current state vs. next state
balancing over multiple dimensions
?

VM-host affinity (DRS 4.1)
Dedicated instances (EC2)
MaxVMsPerServer (DRS 5.1)
apr. 2011
mar. 2011
sep. 2012
The constraint needed in 2012
?? 2013
VM-VM affinity (DRS)
2010 ?
Dynamic Power Management (DRS 3.1)
2009 ?
What about the SLOs ?

SLOs inject additional rules
placement constraint (anti)affinity rules
VM-VM, VM-PM, relative, absolute
temporal constraint precedences, parralelism, sequence
fault tolerance, hw. compatibility, security
control between actionscontrol, performance
counting constraint
per node, group of nodes, resourceperformance, licensing restriction
… …

discrete constraints
spread(VM[1,2]) ban(VM1, N1) ban(VM2, N2)
N1
N2
N3
VM1
VM2
N1
N2
N3
VM1
VM2
continuous constraints
>>spread(VM[1,2]) ban(VM1, N1) ban(VM2, N2)
harder scheduling problem (think about actions interleaving)
“simple” spatial problem

soft constraints
hard constraints
must be satisfied all or nothing approach not always meaningful
satisfiable or not internal or external penalty model
harder to implement/scale hard to standardise ?
spread(VM[1..50])
mostlySpread(VM[1..50], 4, 6)

energy efficient VM scheduler

(Environmental Protection Agency, 2007)
of the 2005 budget
1.5%
in 2010 ?3 %USA


1Consume less2003

●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●●● ●●●●●
●
●●●
●
●●●●●●
●
●●●●●●●●●●●●●●●●
●●●
●●●●●●●●●●●●●●●●●●●●●●●●●
●●●●
●
●●●●●●●●●●●●●●●●●●●●●●●●
●
●●●
●●●●●●●●●●●●
●
●●●●●●●●●●●●●
●●
●●●●●●●●
●●●
●
●●●●●●●●●●●●
●●●
●●●●●●●●●●
●●●
●●●●●●●
●●●
●
●●
●
●●●●●●●●
●
●
●●●●●●●●●
●
●
●●●●●●●●●●●●
●
●
●●●●●
●
●
●●●●●●●●●●●●●●
●
●
●
●●
●●●●●●●●●●●●●●●●●
●●
●●
●●●●●
●
●●●●●●●
●●
●●
●
●
●
●
●
●
●●
●
●●●●
●●●
●●●●●
●●
●●●
●
●
●●●●●●●●●●●●●●
●
●●
●
●●●●●●●●
●
●●●●●●●●●●●●
●
●
●●
●
●
●●●●●●●●●●
●
●
●●●●
●
●
●
●●●●●●●●●●●●●●●●
●
●
●
●
●●●
●●●●
●●
●●●●●●●●●●●●●
●●
●●●●●●
●●●●
●
●
●●
●●●●●●
●●
●●●●●●●●●
●●
●●
●
●
●●●
●
●
●
●●●
●
●●
●
●●
●
●●●●●●●●
●
●
●
●●
●
●●●●●●●●
●●
●●●●●●●●●
●
●●●
●
●
●
●
●
●●
●●●●●
●
●●●
●
110
120
130
140
150
160
170
180
0 1 2 3 4VM #
Con
sum
ptio
n (W
att)
Node consumption statistics (Cluster edel, 128GB HDD)
110 W
175 W
servers are not energy efficient

how to reduce consumption with identical nodes
?

The principles
place VMs on the minimum number of nodes
turn off idle nodes
rince/repeat for the dynamic version

Best Fit Decrease (BFD)a simple heuristic to pack VMs
sort VMs in desc order for each VM pick the suitable node with the least remaining space
efficiency decreases when nb. of dimensions increase

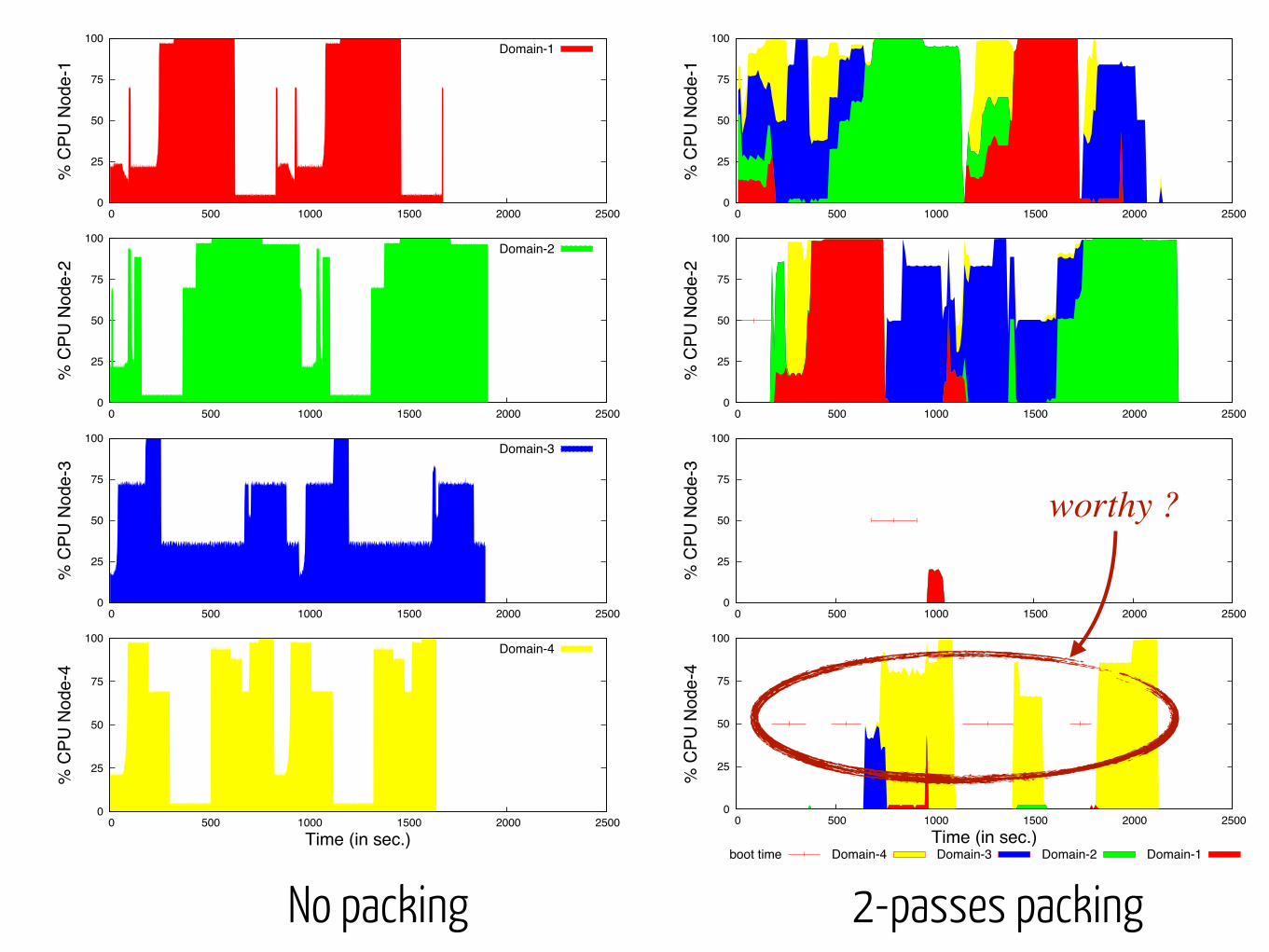
2-pass dynamic VM packingto manage the running VMs
on saturated nodes, BFD to move away VMs on non-saturated nodes
on low-loaded nodes, BFD to move away VMs on heavily loaded nodes
1) address performance issues
2) address energy efficiency issues
many variations using threshold based systems, load predictions …

No packing 2-passes packing
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
1Domain-1
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
2
Domain-2
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
3
Domain-3
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
4
Time (in sec.)
Domain-4
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
1
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
2
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
3
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
4
Time (in sec.)boot time Domain-4 Domain-3 Domain-2 Domain-1
No packing 2-passes packing
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
1Domain-1
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
2
Domain-2
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
3
Domain-3
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
4
Time (in sec.)
Domain-4
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
1
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
2
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
3
0
25
50
75
100
0 500 1000 1500 2000 2500
% C
PU N
ode-
4
Time (in sec.)boot time Domain-4 Domain-3 Domain-2 Domain-1
worthy ?

300
400
500
600
700
800
0 5 10 15 20 25 30 35 40
Ener
gy (W
atts
)
Time (min)Native execution IVS execution prototype
baseline IVS 2-pass VM packing
interesting gains, the node boot time was the bottleneck
simplistic model (identical nodes)

Consequences of having heterogeneous nodes ?

Consequences of having heterogeneous nodes ?
different performance different Power Usage Effectiveness
…
how to estimate the benefits of a migration ?

a specialised model
vector packing problem +performance model +power model +cost model +…

power modelsestimate the energy consumption
usually linear equations
model the static and the dynamic energy profile of the components
Wh(node) = α Hw +β

VM performance models
a model to map VM performance with their host
a neutral performance unit mips, ECU, GCU, …
perf(VM, N) = α %cpu +βn

multi-core CPUs, DDR3 memory, spinning HD, PUE / CUE, boot/shutdown time
VM template migration duration
migration payback time
hw. particularities
a fine-grain power model
workload particularities

coarse to fine grain optimisation
-16%
-47%
- 27%-7%

2Consume better2012 from a spatial to a temporal point of view

2013 2016
let existing and new data centres become energy adaptive
DC4Cities

0
25
50
75
100
16/01 17/01 18/01 19/01 20/01Date
rene
wabl
e po
wer (
%)
0
200
400
600
16/01 17/01 18/01 19/01 20/01Date
Powe
r (W
)
grid renewable part
sunroof PV production
renewable energies are intermittent

1000
1500
2000
2500
3000
23:00 05:00 11:00 17:00 23:00Time
Request/s
0.0
0.5
1.0
1.5
2.0
0 200 400 600 800Performance degradation (Req/s)
Pena
lty (e
uros
)
6 to 20 moonshot cartridges
penalty modelSLO
so are elastic and batch-oriented applications

align workload to renewable energies availability
DC4Cities

shape EASCs for sustainable profitability
forecasts
energyproviders
sustainable objectiveEasc
application descriptor
elected working modes
smart cityauthority
Easc...Carverweb service
videotranscoder
energy adaptiveapplications
min(penalty(SLO) + penalty(SMA) + price(E))pick WMs such as

Energy Adaptive Software Components
attached to an application
exhibit - working modes - SLO (cumulative or instant) - actuators
(see UCC’15 paper)

An automaton for each EASC model the behavior,
+ penalty functions for the SMA, the SLA

0
100
200
300
400
500
16/01 17/01 18/01 19/01 20/01Date
Watts
applicationE−learningG−indexingWebsite
0
200
400
16/01 17/01 18/01 19/01 20/01Date
Watts
applicationE−learningG−indexingWebsite
0
200
400
16/01 17/01 18/01 19/01 20/01Date
Watts
applicationE−learningG−indexingWebsite
baseline (satisfy perf )
“green” (max renewable)
carver

17/01/15 18/01/15 19/01/15 20/01/15
0
1000
2000
perf
green
Carver pe
rfgre
enCarv
er perf
green
Carver pe
rfgre
enCarv
er
Run
ning
cos
t (eu
ros)
expenseenergySLOSMA
Resulting running costs

RECAP114

no holy grail
115

master the problem
116







