Download - RNN Explore

RNN ExploreRNN,LSTM,GRU,Hyperparameters
ByYanKang

1
2
3
4
ThreeRecurrentCells
Hyperparameters
ExperimentsandResults
Conclusion
CONTENT

RNN Cells
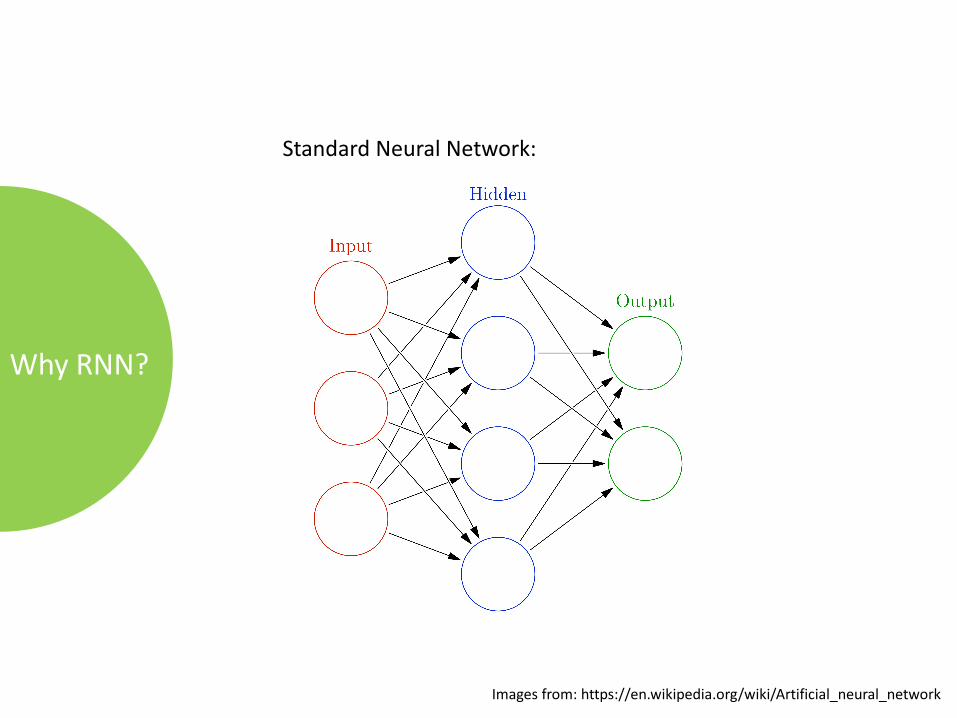
WhyRNN?
StandardNeuralNetwork:
Imagesfrom:https://en.wikipedia.org/wiki/Artificial_neural_network
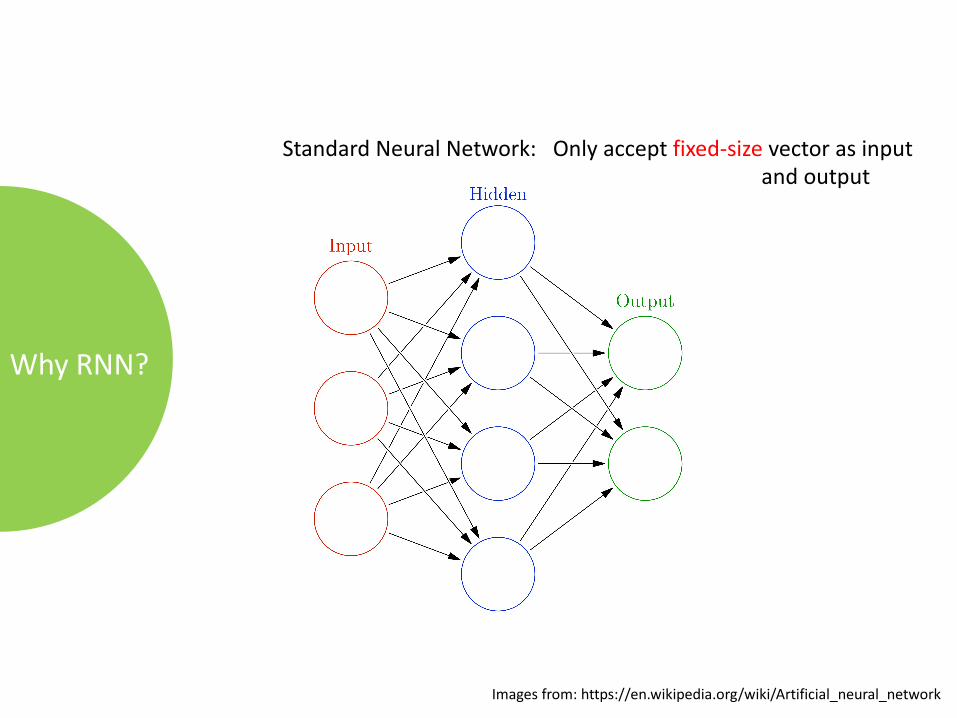
WhyRNN?
StandardNeuralNetwork:Onlyacceptfixed-size vectorasinputandoutput
Imagesfrom:https://en.wikipedia.org/wiki/Artificial_neural_network
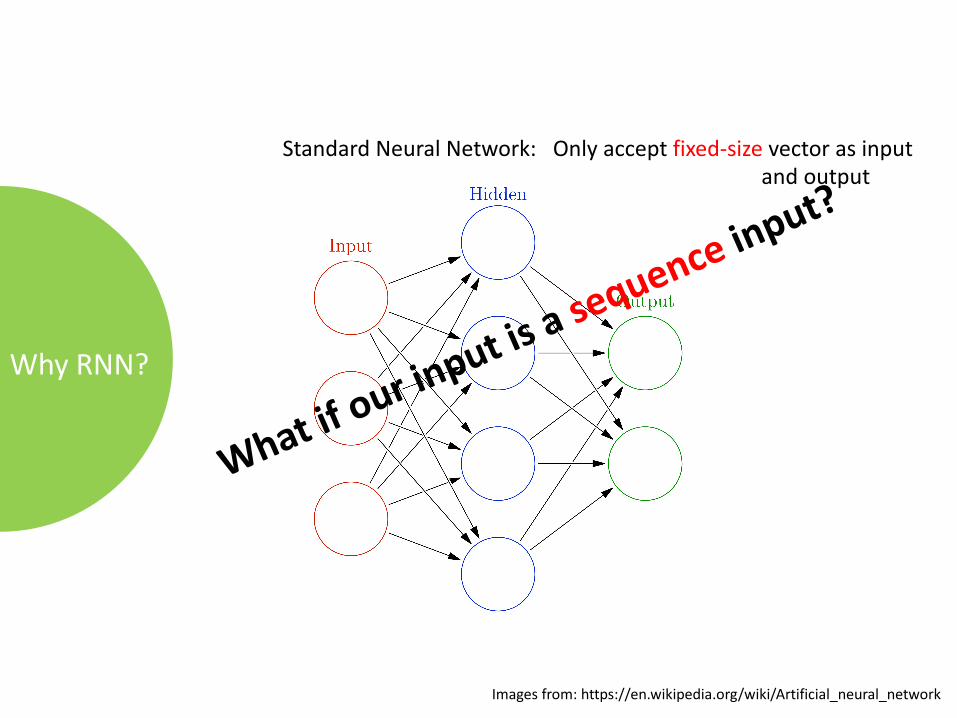
StandardNeuralNetwork:Onlyacceptfixed-size vectorasinputandoutput
WhyRNN?
Imagesfrom:https://en.wikipedia.org/wiki/Artificial_neural_network
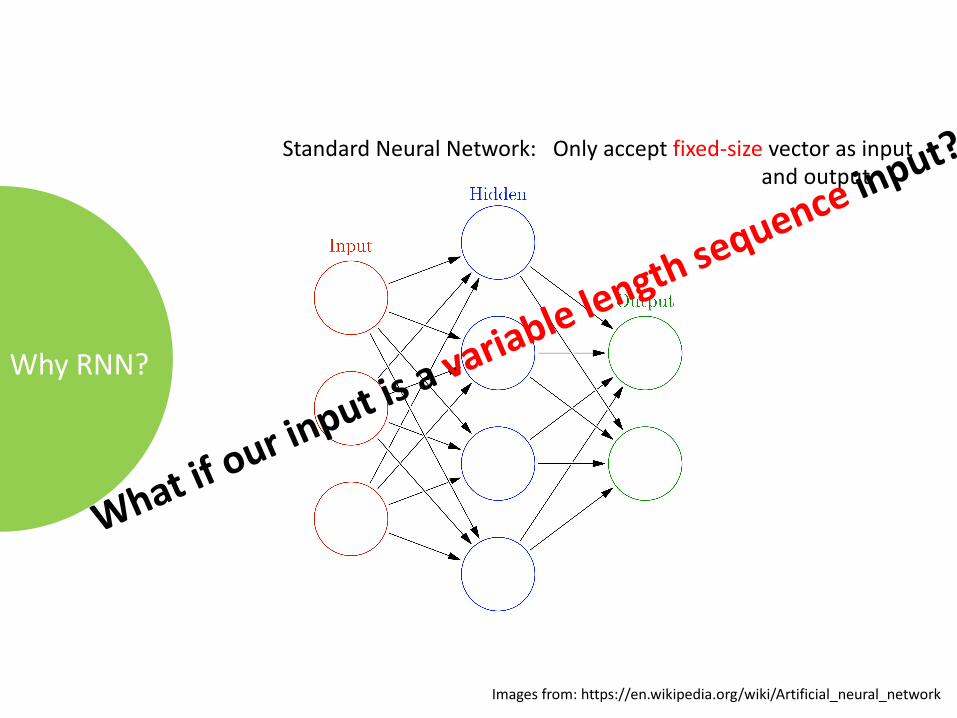
WhyRNN?
StandardNeuralNetwork:Onlyacceptfixed-size vectorasinputandoutput
Imagesfrom:https://en.wikipedia.org/wiki/Artificial_neural_network
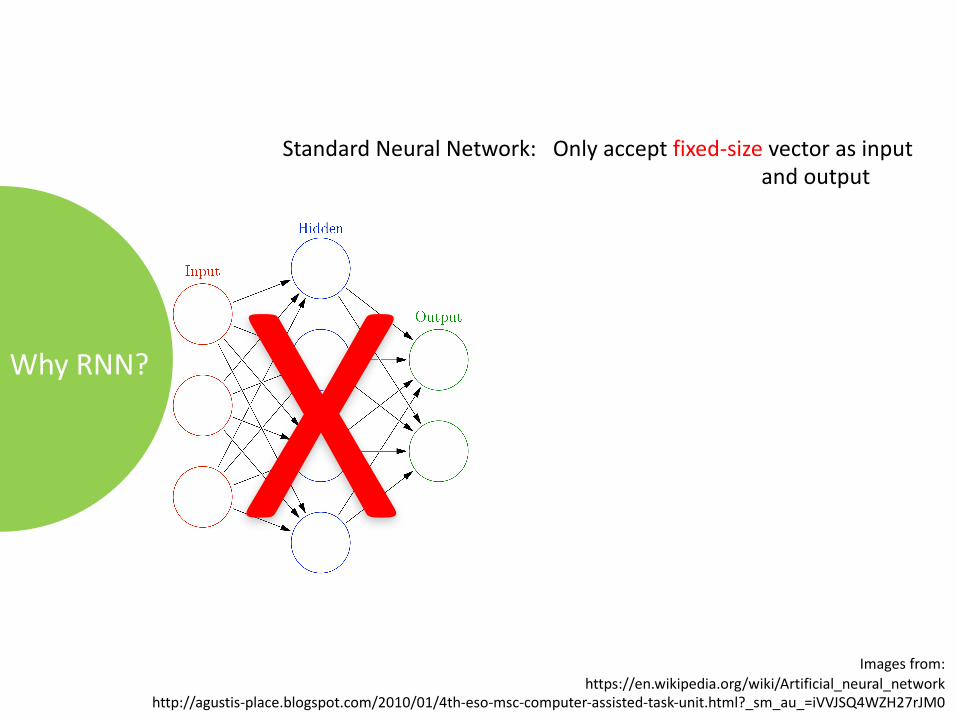
WhyRNN?
StandardNeuralNetwork:Onlyacceptfixed-size vectorasinputandoutput
XImagesfrom:
https://en.wikipedia.org/wiki/Artificial_neural_networkhttp://agustis-place.blogspot.com/2010/01/4th-eso-msc-computer-assisted-task-unit.html?_sm_au_=iVVJSQ4WZH27rJM0
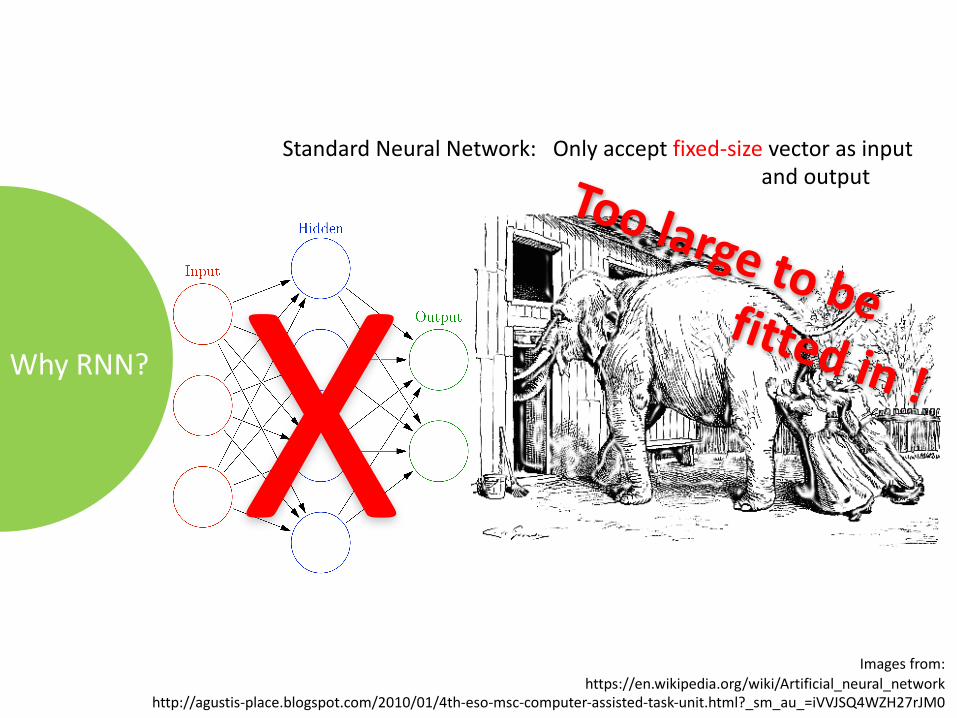
WhyRNN?
StandardNeuralNetwork:Onlyacceptfixed-size vectorasinputandoutput
XImagesfrom:
https://en.wikipedia.org/wiki/Artificial_neural_networkhttp://agustis-place.blogspot.com/2010/01/4th-eso-msc-computer-assisted-task-unit.html?_sm_au_=iVVJSQ4WZH27rJM0
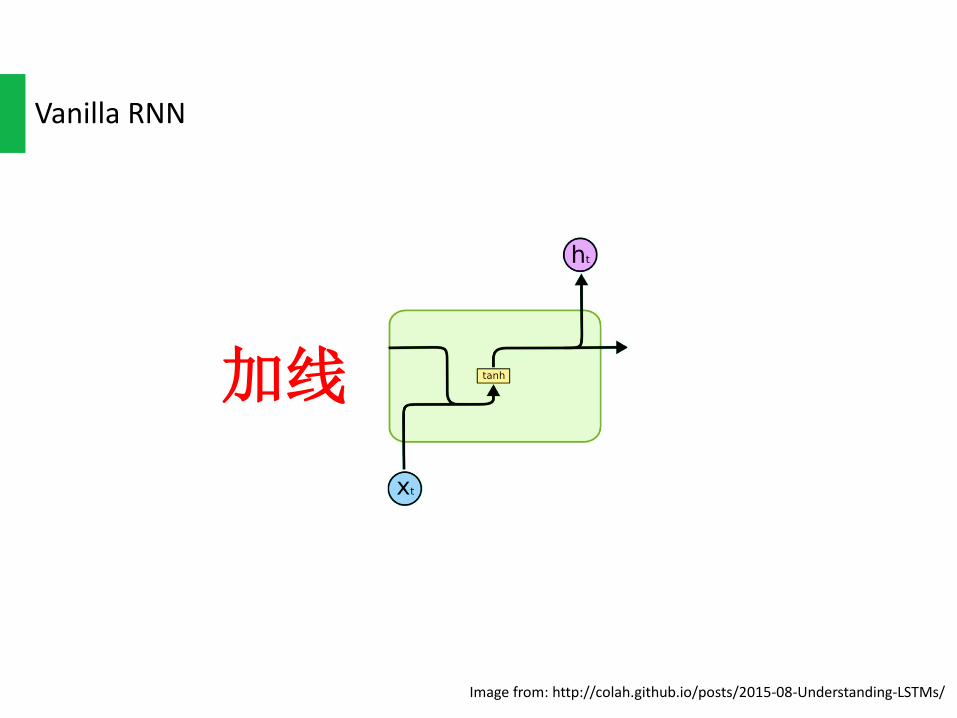
VanillaRNN
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
加线
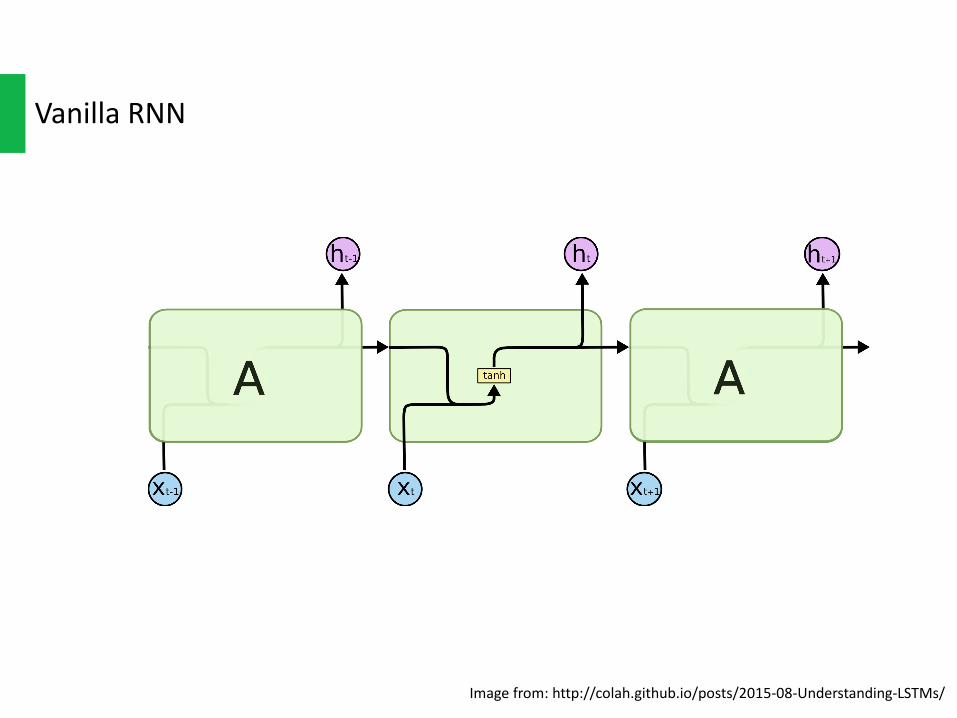
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
VanillaRNN
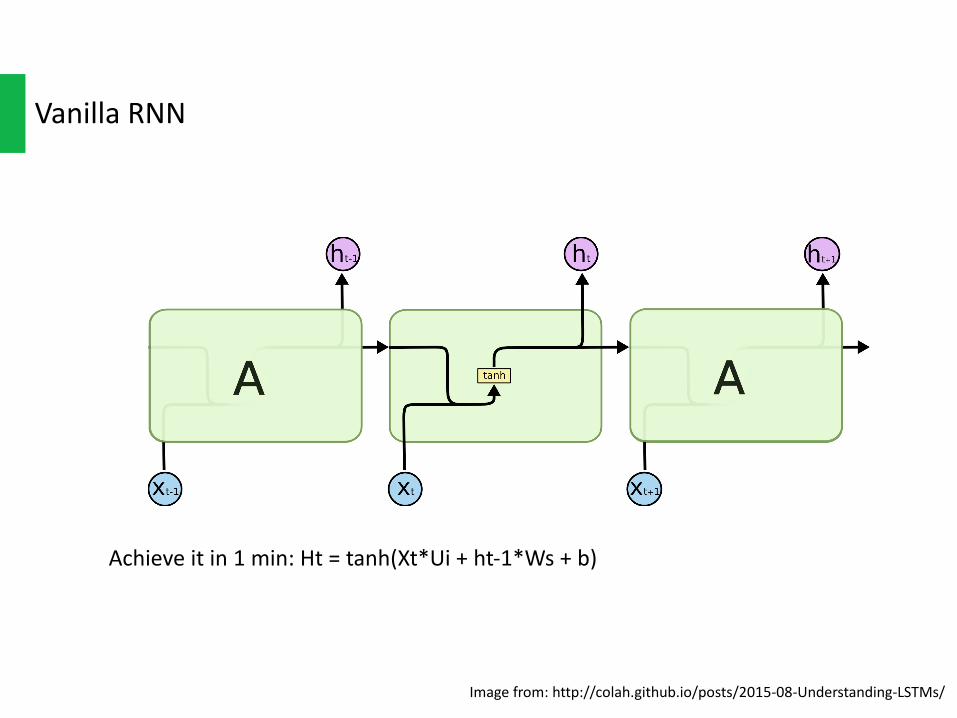
Achieveitin1min:Ht =tanh(Xt*Ui +ht-1*Ws +b)
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
VanillaRNN
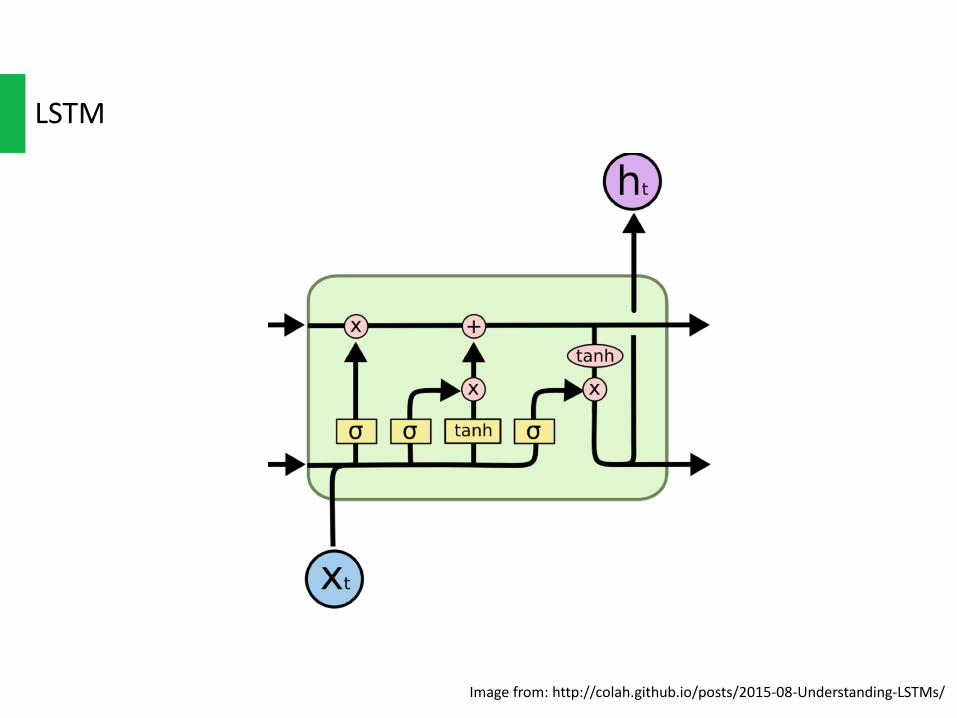
LSTM
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
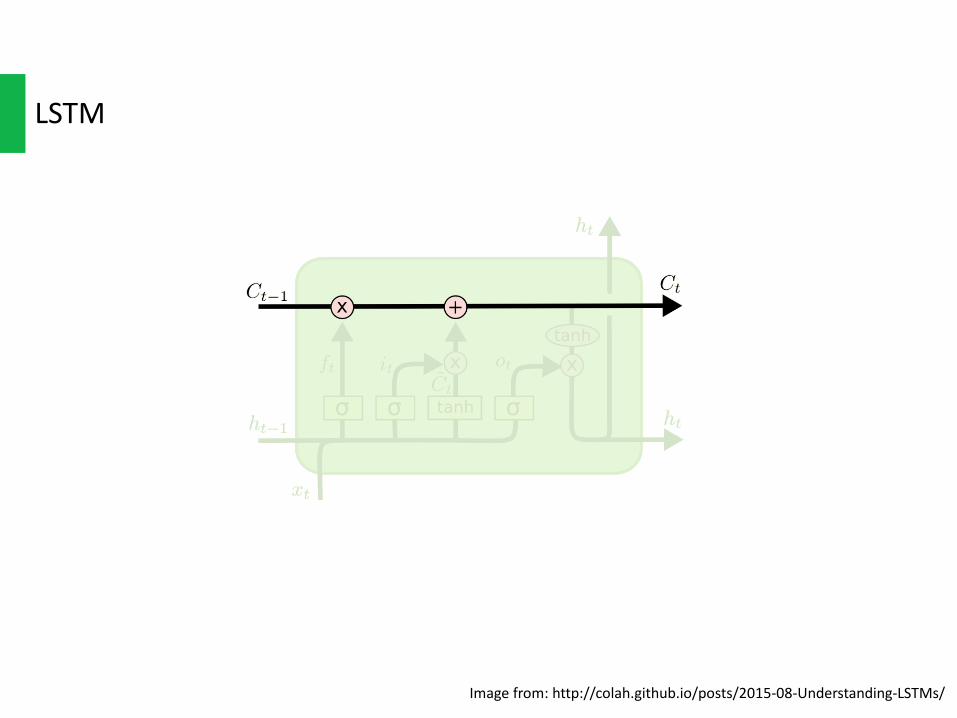
LSTM
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
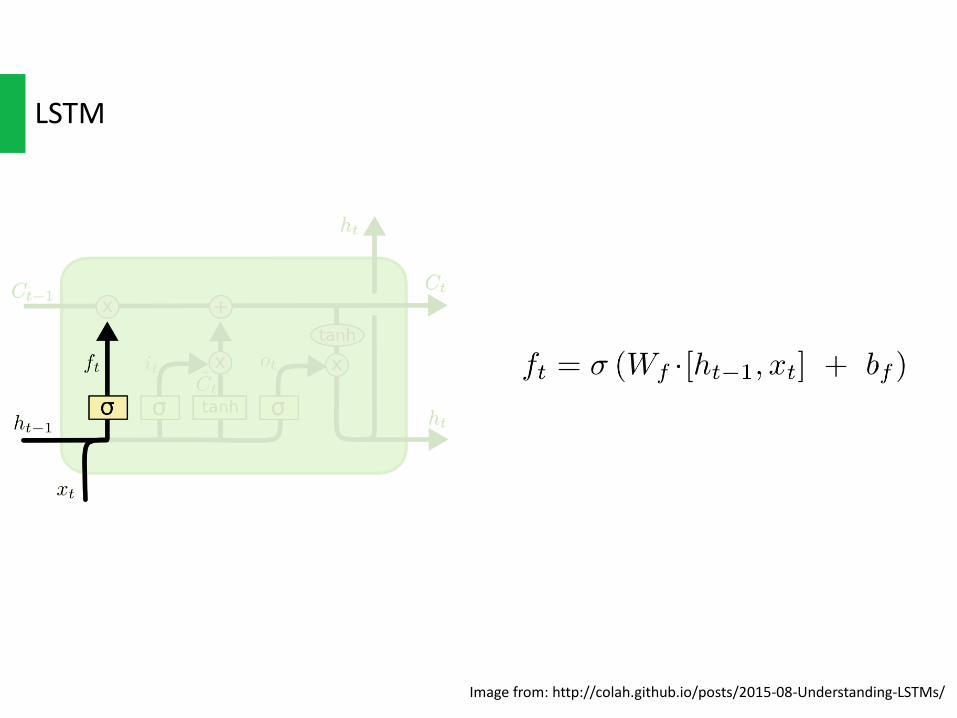
LSTM
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
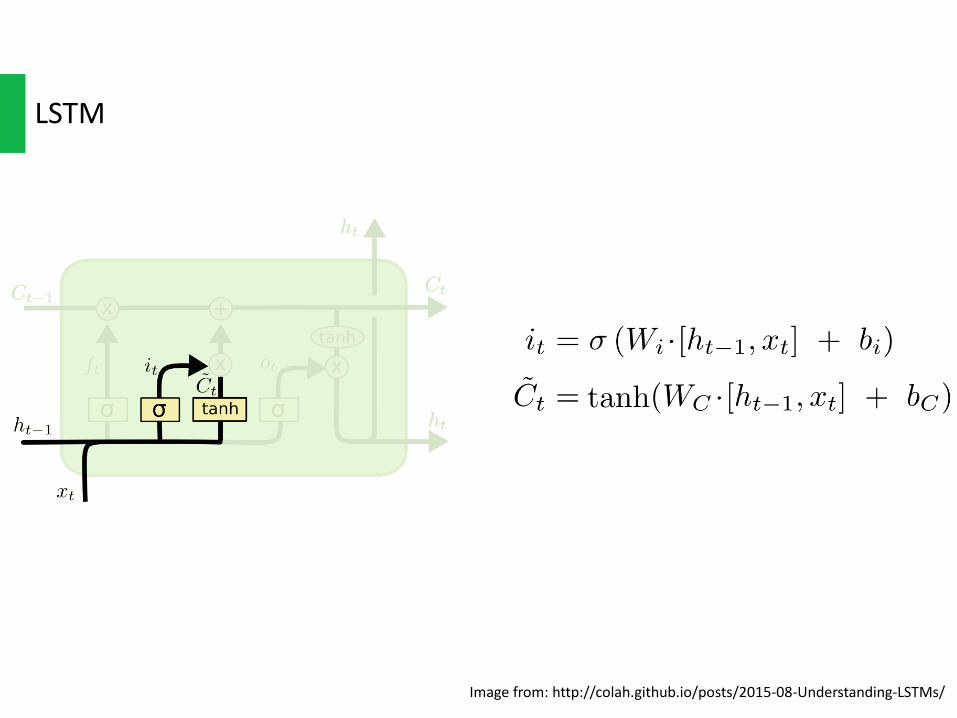
LSTM
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/

LSTM
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
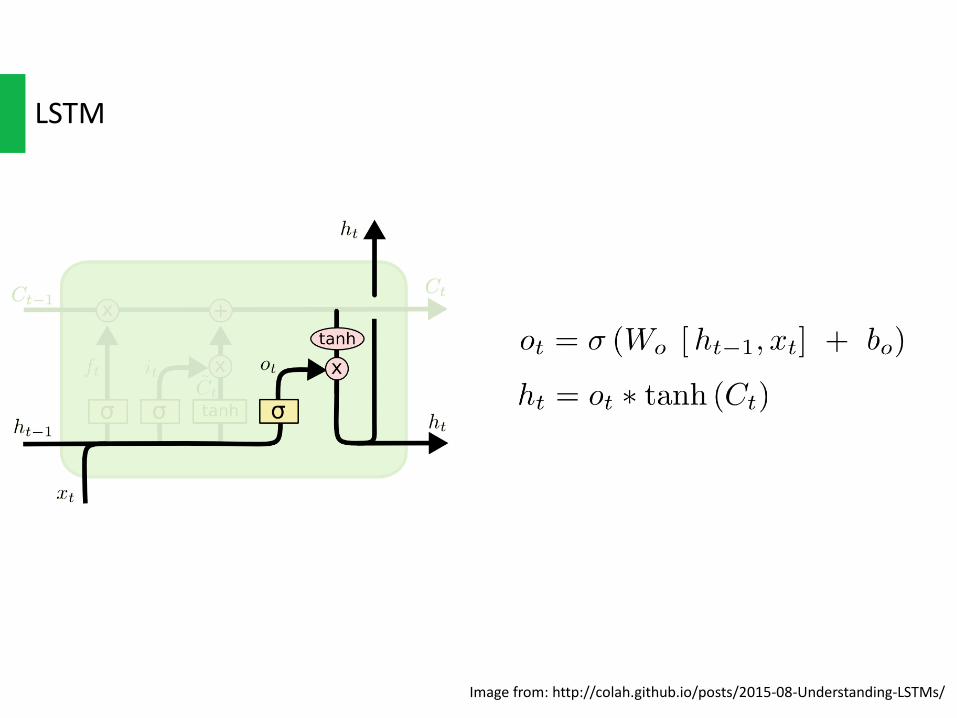
LSTM
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
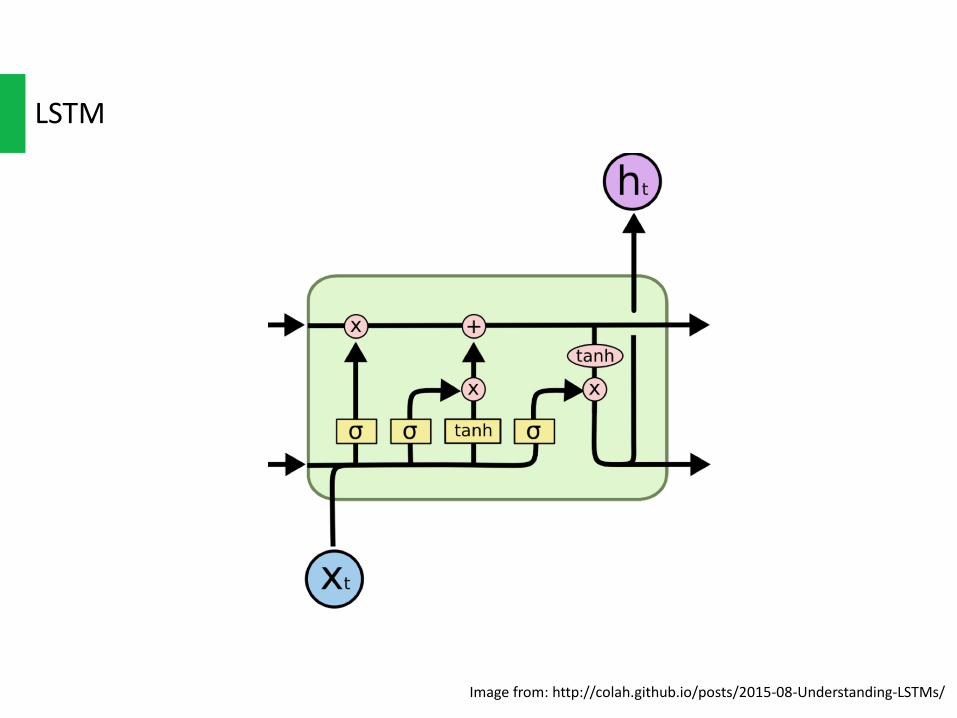
LSTM
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/

LSTMLimitation?
Redundantgates/parameters:
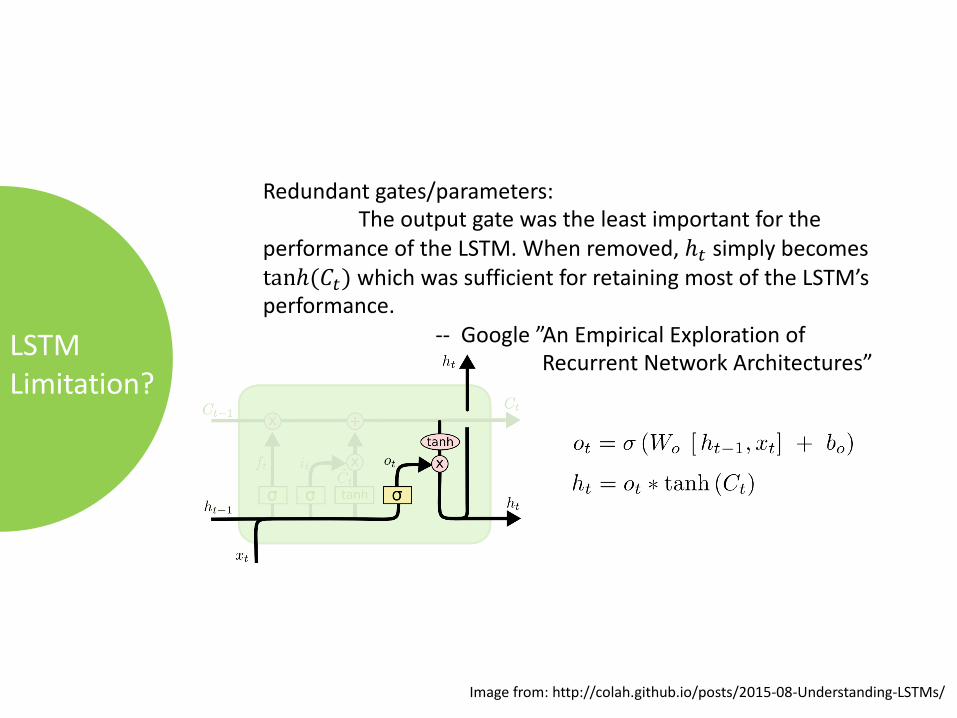
LSTMLimitation?
Redundantgates/parameters:Theoutputgatewastheleastimportantforthe
performanceoftheLSTM.Whenremoved,ℎ" simplybecomestanℎ(𝐶") whichwassufficientforretainingmostoftheLSTM’sperformance.
-- Google”AnEmpiricalExplorationofRecurrentNetworkArchitectures”
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
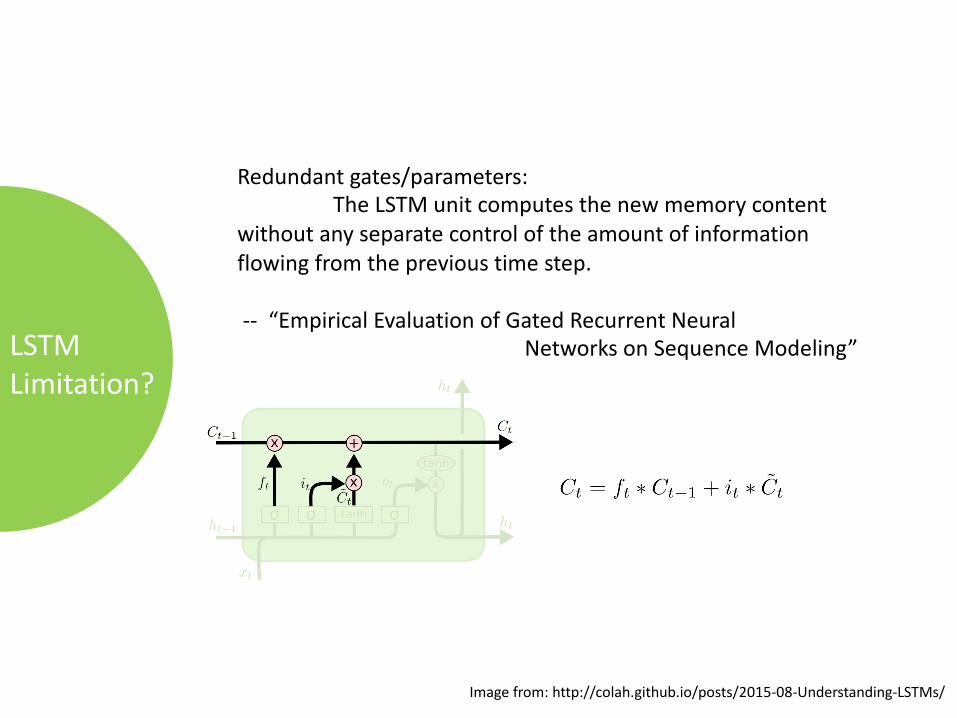
LSTMLimitation?
Redundantgates/parameters:TheLSTMunitcomputesthenewmemorycontent
withoutanyseparatecontroloftheamountofinformationflowingfromtheprevioustimestep.
-- “EmpiricalEvaluationofGatedRecurrentNeuralNetworksonSequenceModeling”
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
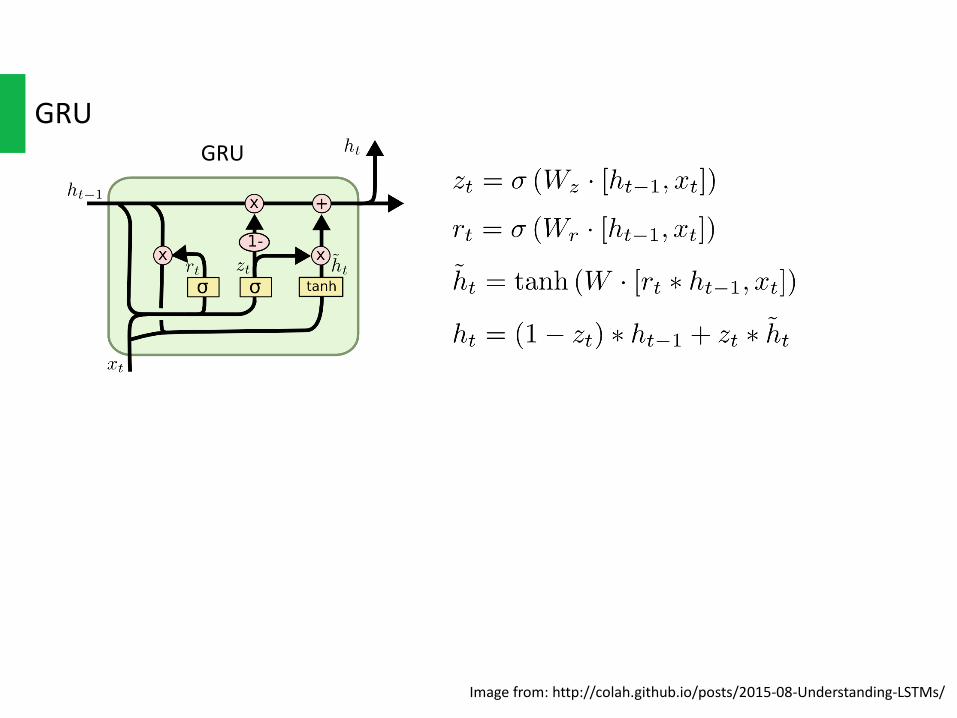
GRU
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
GRU
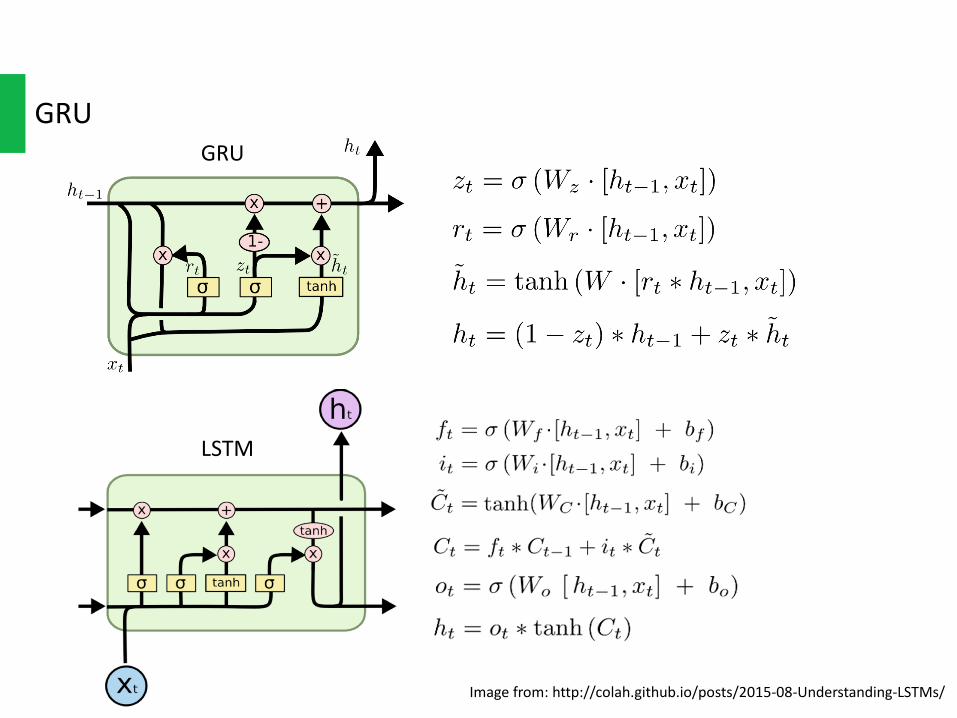
GRU
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
LSTM
GRU

Hyperparameters
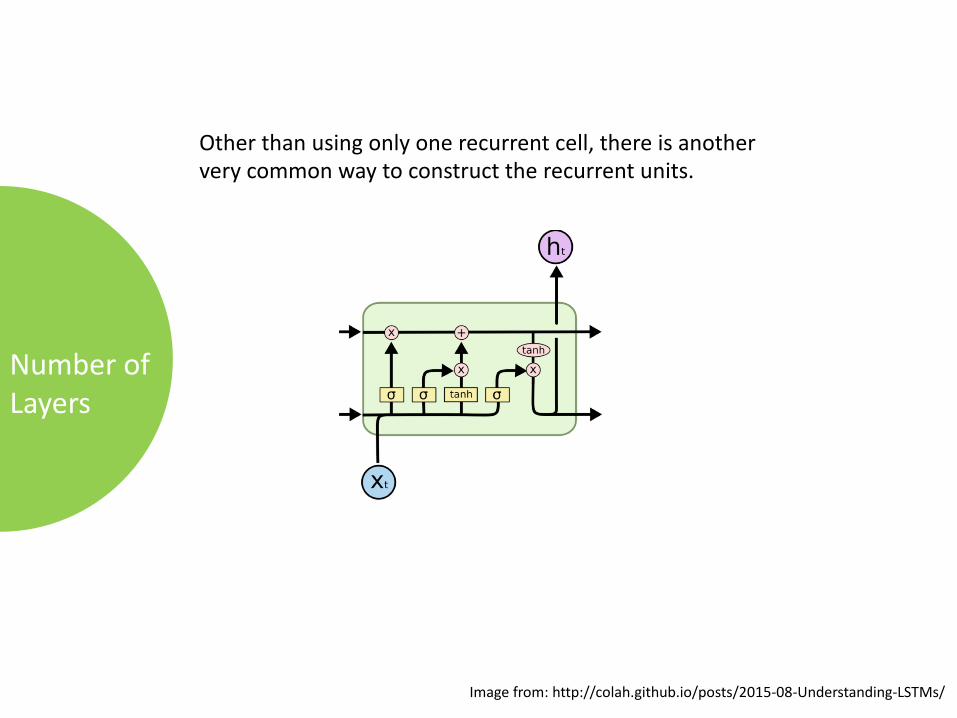
NumberofLayers
Otherthanusingonlyonerecurrentcell,thereisanotherverycommonwaytoconstructtherecurrentunits.
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
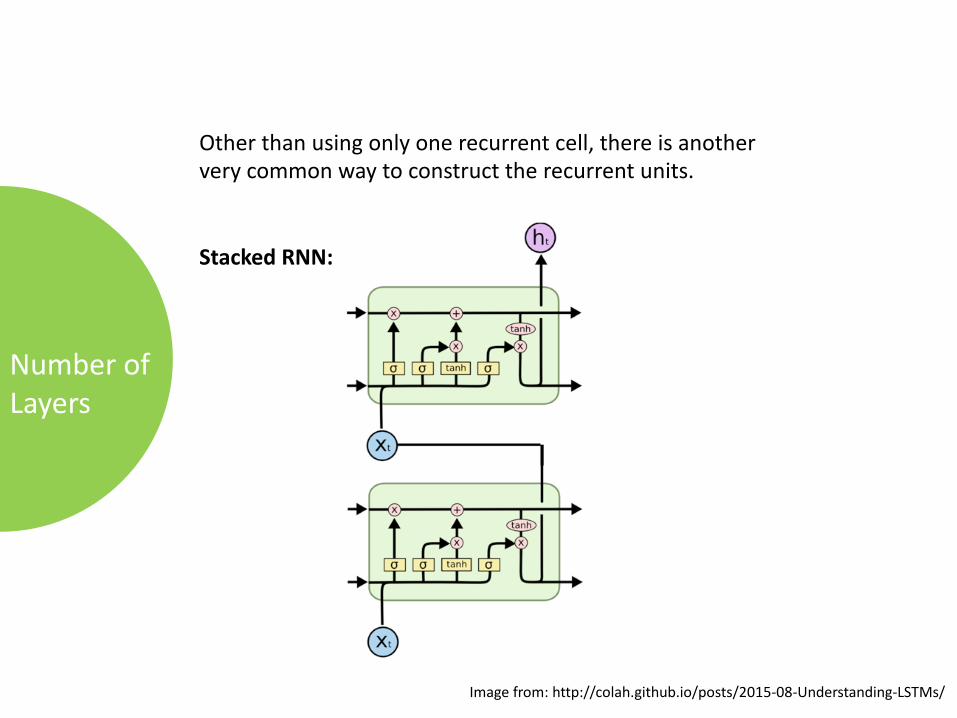
NumberofLayers
Otherthanusingonlyonerecurrentcell,thereisanotherverycommonwaytoconstructtherecurrentunits.
StackedRNN:
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
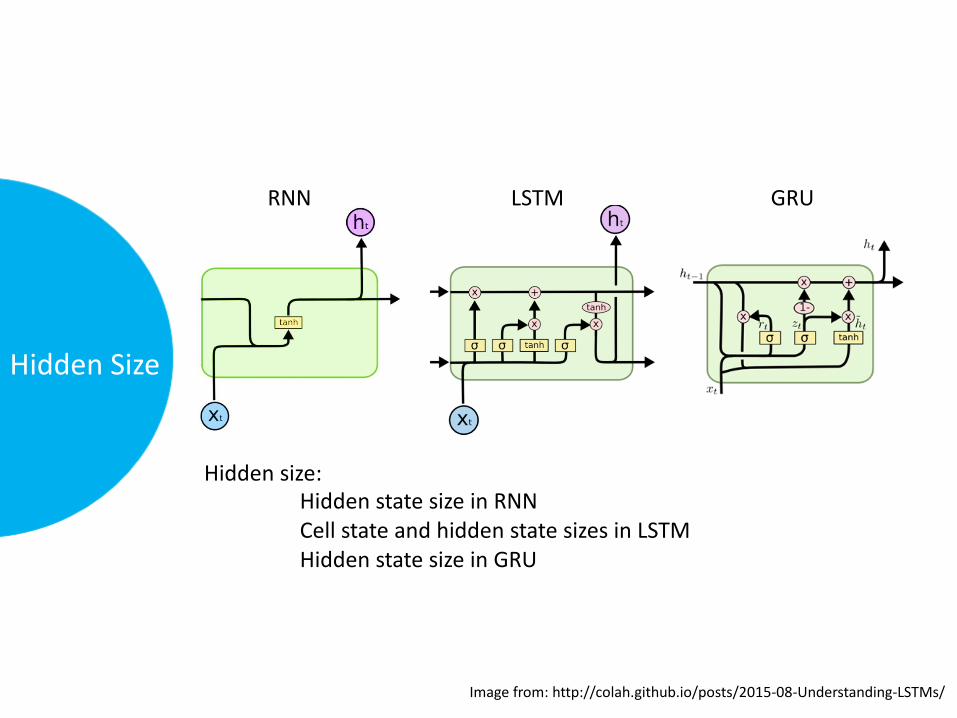
HiddenSize
RNN LSTM GRU
Hiddensize:HiddenstatesizeinRNNCellstateandhiddenstatesizesinLSTMHiddenstatesizeinGRU
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
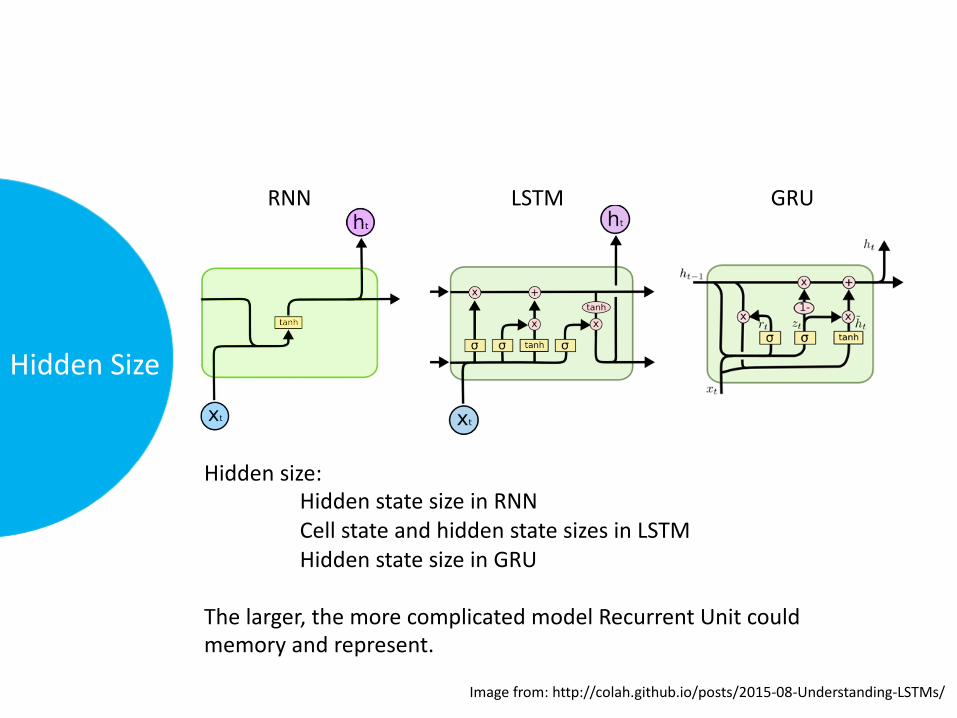
HiddenSize
RNN LSTM GRU
Hiddensize:HiddenstatesizeinRNNCellstateandhiddenstatesizesinLSTMHiddenstatesizeinGRU
Thelarger,themorecomplicatedmodelRecurrentUnitcouldmemoryandrepresent.
Imagefrom:http://colah.github.io/posts/2015-08-Understanding-LSTMs/
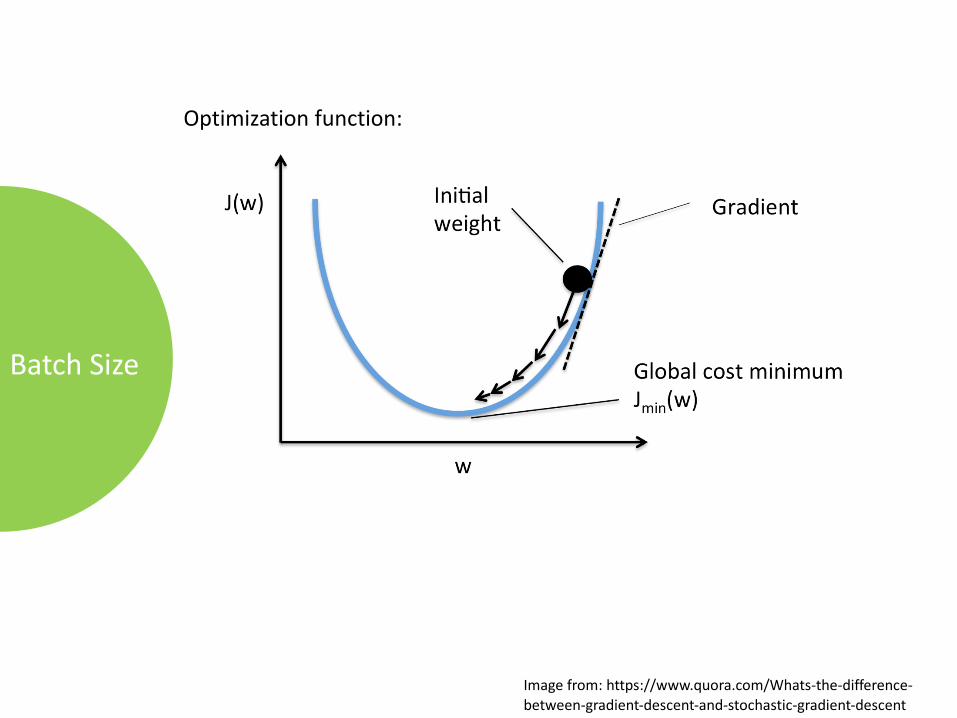
BatchSize
Imagefrom:https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
Optimizationfunction:
BatchSize
Imagefrom:https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
Optimizationfunction:
B=|x| GradientDescentB>1&B<|x| StochasticGradientDescent
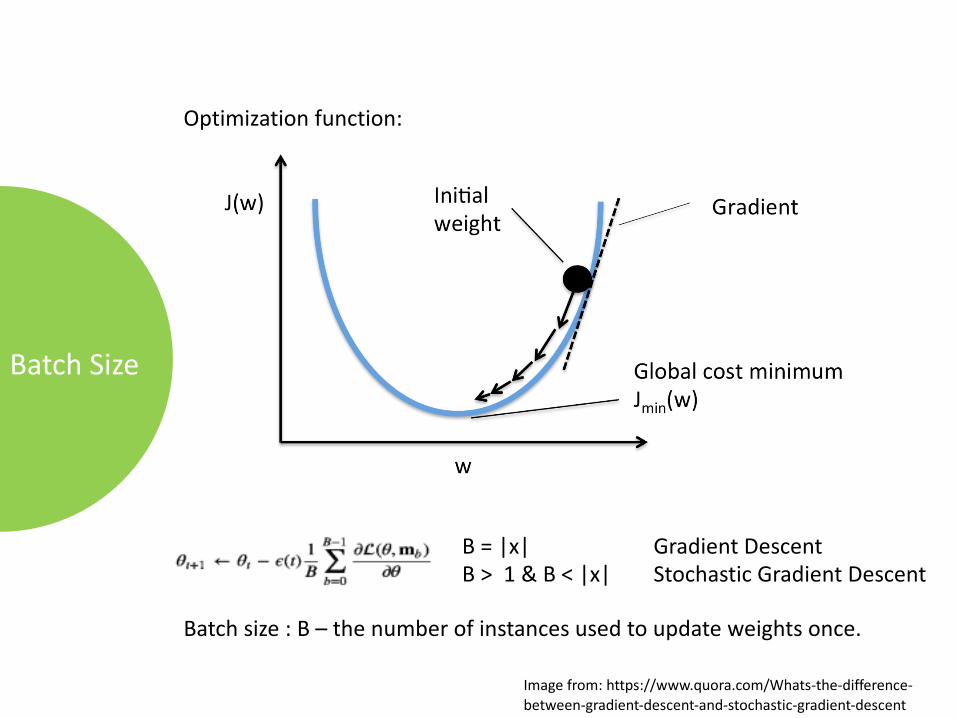
BatchSize
Imagefrom:https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
Optimizationfunction:
B=|x| GradientDescentB>1&B<|x| StochasticGradientDescent
Batchsize:B– thenumberofinstancesusedtoupdateweightsonce.
LearningRate
Imagefrom:https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
Optimizationfunction:
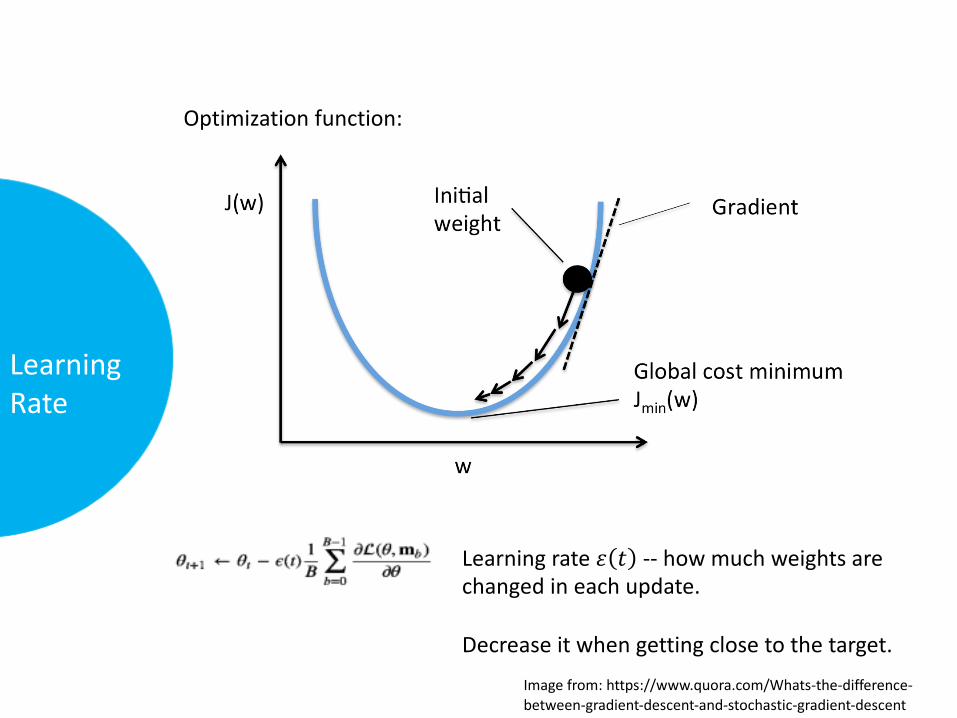
LearningRate
Imagefrom:https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
Optimizationfunction:
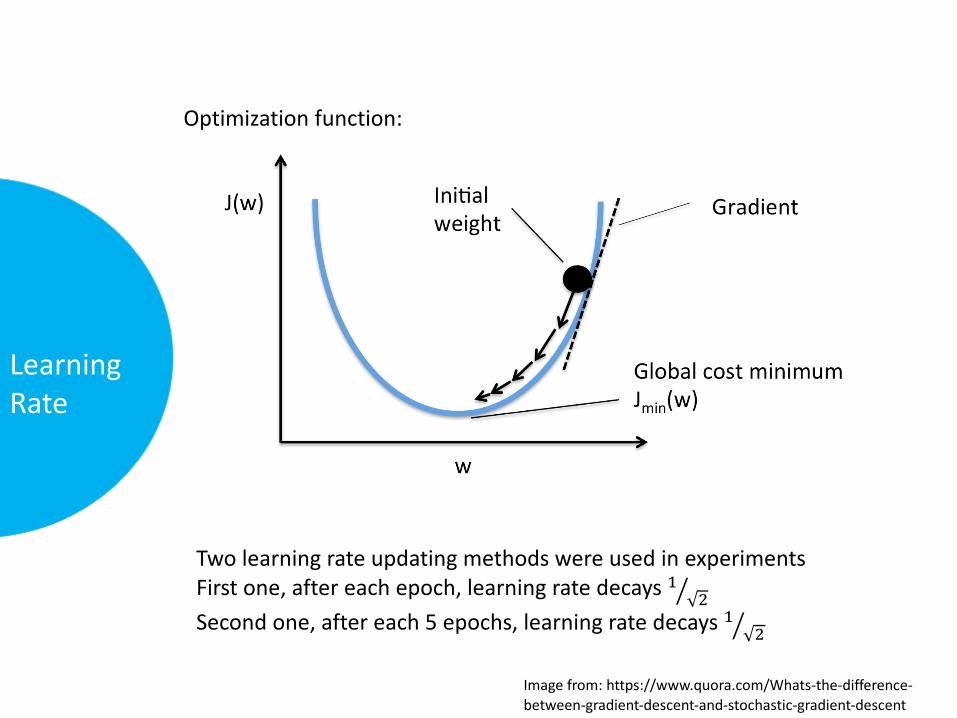
Learningrate𝜀 𝑡 -- howmuchweightsarechangedineachupdate.
Decreaseitwhengettingclosetothetarget.
LearningRate
Imagefrom:https://www.quora.com/Whats-the-difference-between-gradient-descent-and-stochastic-gradient-descent
Optimizationfunction:
TwolearningrateupdatingmethodswereusedinexperimentsFirstone,aftereachepoch,learningratedecays+ ,�.Secondone,aftereach5epochs,learningratedecays+ ,�.

Experiments&Results
𝑠0𝑠+𝑠,𝑠1
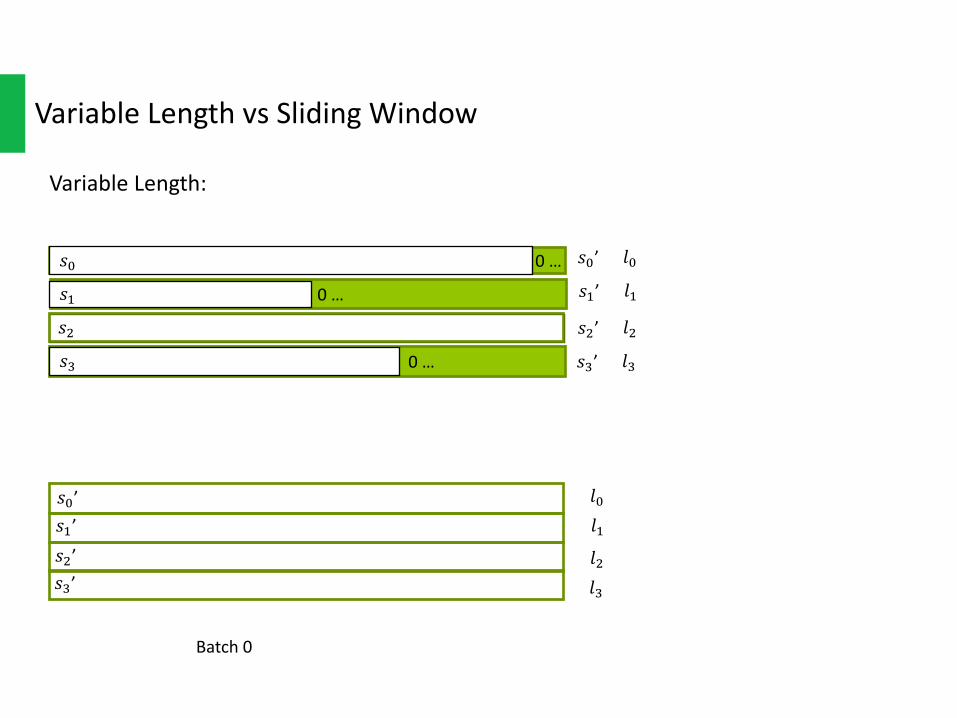
VariableLength:
𝑠0’𝑠+’𝑠,’𝑠1’
0…
0…
0…
Batch0
𝑠0’
𝑠+’
𝑠,’
𝑠1’
VariableLengthvsSlidingWindow
𝑙0𝑙+
𝑙,𝑙1
𝑙0𝑙+𝑙,𝑙1
𝑠0𝑠+𝑠,𝑠1
……𝑤00 𝑤0+ 𝑤04
Batch0 Batch1
𝑤0+
𝑤0,
𝑤01
𝑤05
𝑤00
𝑤0+
𝑤0,
𝑤056+
……
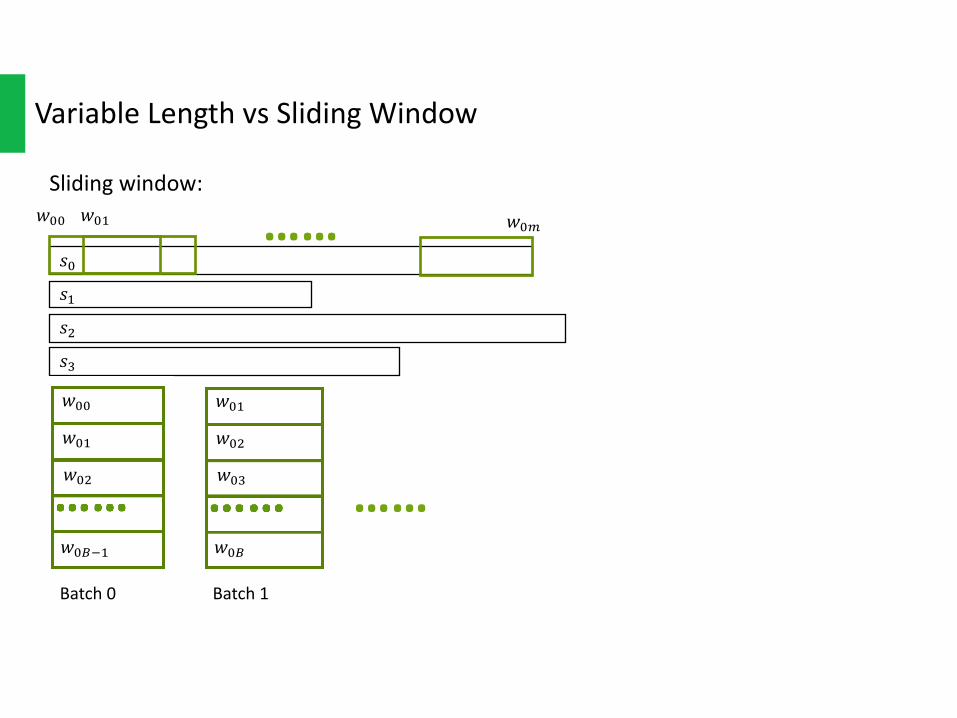
Slidingwindow:
VariableLengthvsSlidingWindow

SlidingWindow:
Advantages:Eachsequencemightgeneratetensoforevenhundredsofsubsequences.Withsamebatchsizetothevariablelengthmethod,itmeansmorebatchesinoneepochandmoreweightsupdatetimesineachepochs– fasterconvergerateperepoch.
Disadvantages:1) Timeconsuming,longertimeforeachepoch;2) Assigningsamelabeltoallsubsequencemightbebiasedandmightcausethe
networknotconverge.
VariableLengthvsSlidingWindow

VariableLengthvsSlidingWindow
VariableLength: AUSLANDataset2565instances
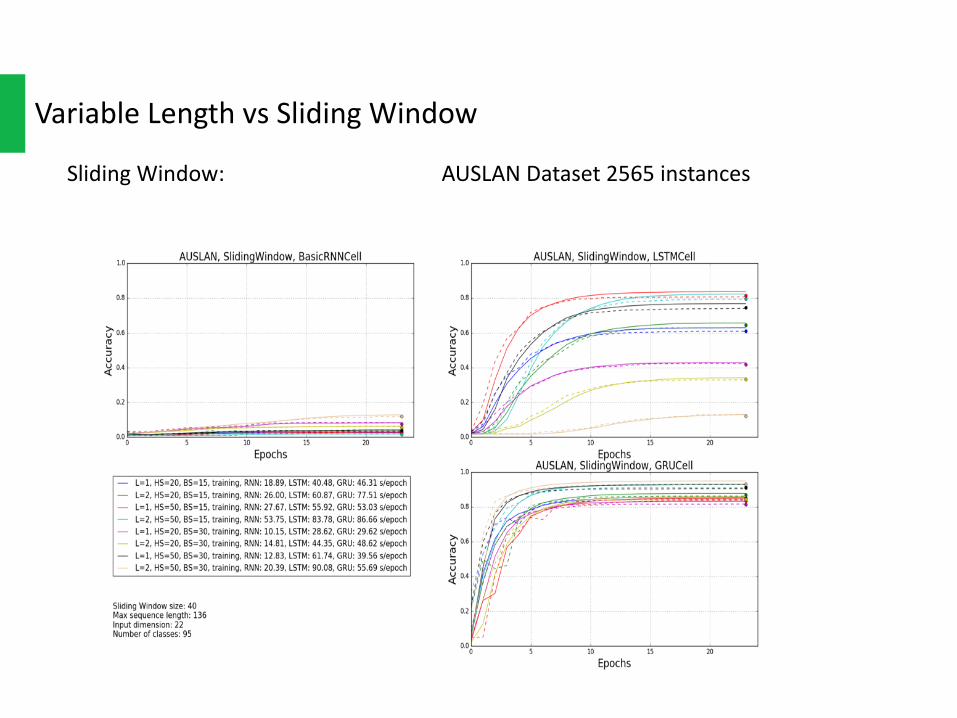
SlidingWindow: AUSLANDataset2565instances
VariableLengthvsSlidingWindow
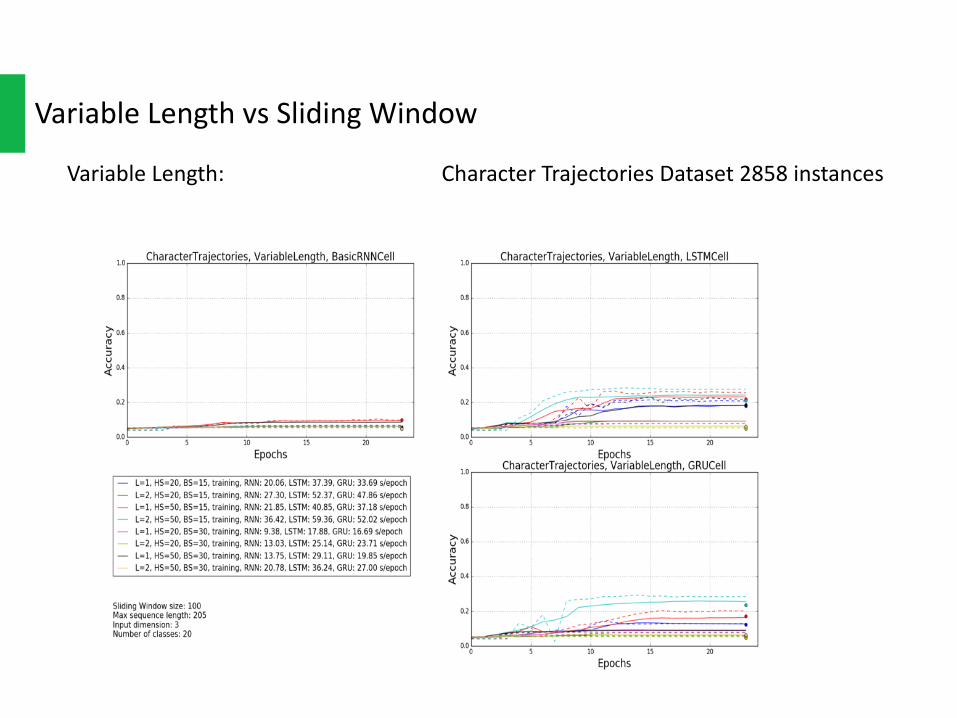
VariableLength: CharacterTrajectoriesDataset2858instances
VariableLengthvsSlidingWindow
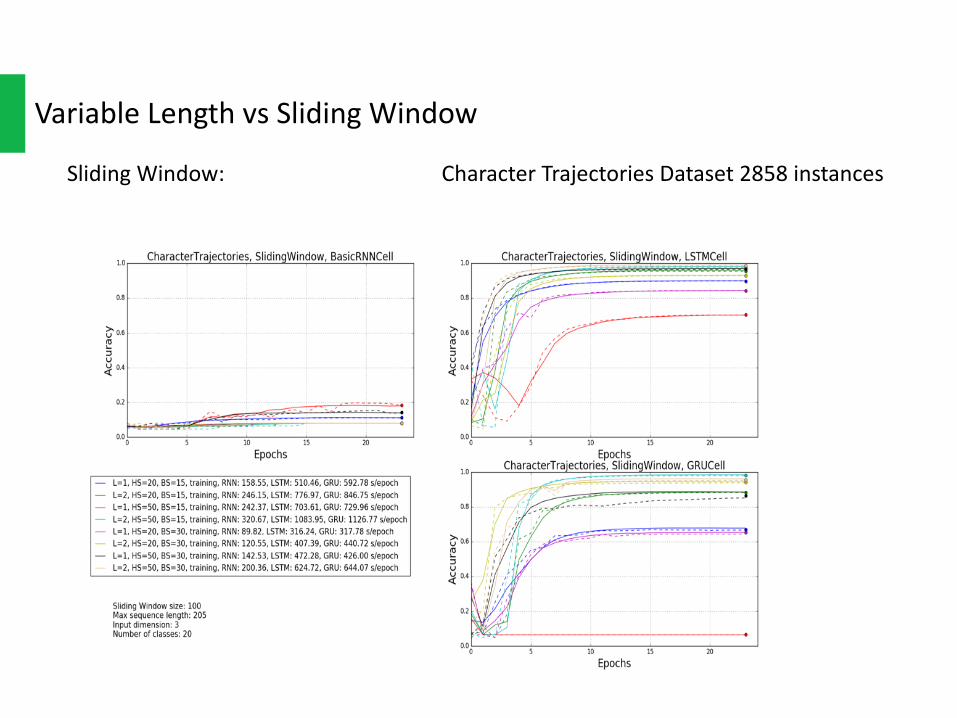
SlidingWindow: CharacterTrajectoriesDataset2858instances
VariableLengthvsSlidingWindow
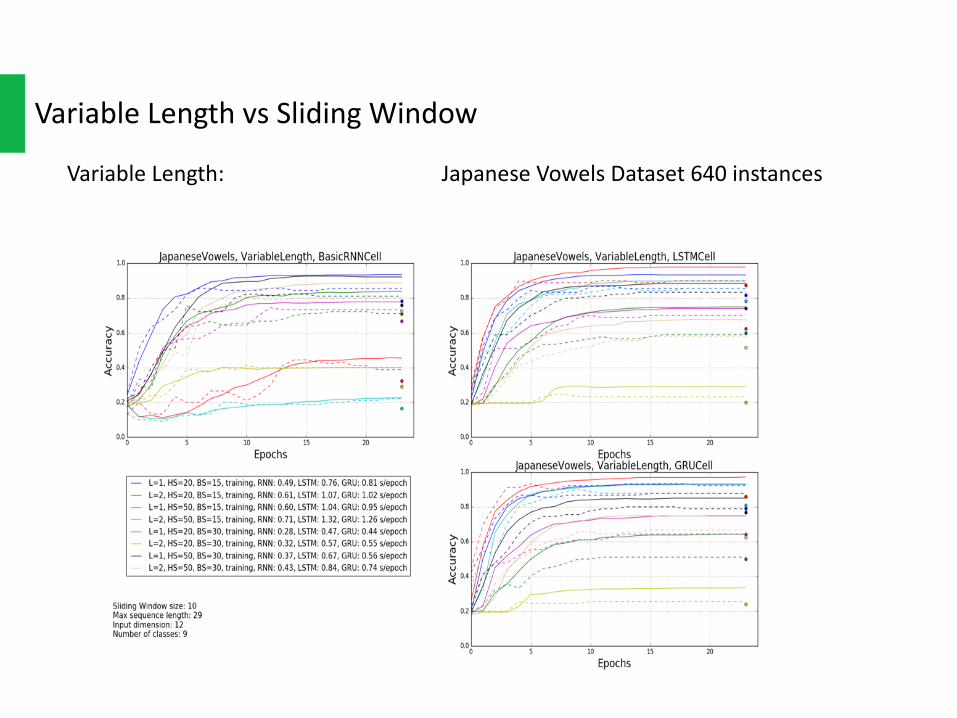
VariableLength: JapaneseVowelsDataset640instances
VariableLengthvsSlidingWindow

SlidingWindow: JapaneseVowelsDataset640instances
VariableLengthvsSlidingWindow

RNNvsLSTMvsGRU
GRUisasimplervariantofLSTMthatsharemanyofthesameproperties,bothofthemcouldpreventgradientvanishingand“remember”longtermdependence.AndbothofthemoutperformvanillaRNNonalmostallthedatasetsand,eitherusingSlidingWindoworVariableLength.
ButGRU hasfewerparametersthanLSTM,andthusmaytrainabitfasterorneedlessiterationstogeneralize.Asshownintheplots,GRUdoesconvergeslightlyfaster.
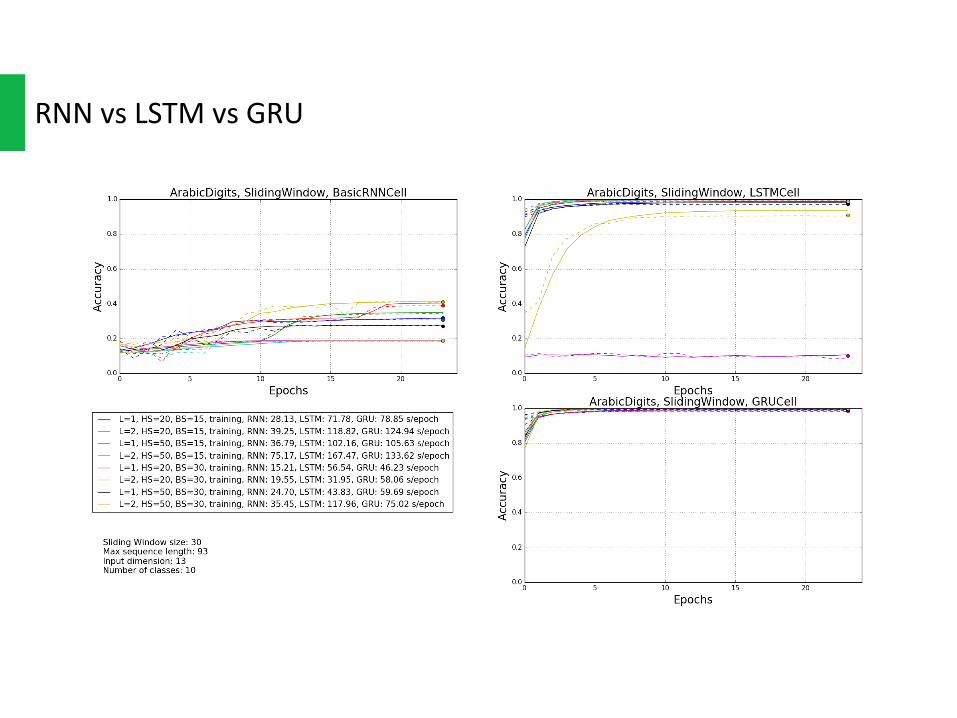
RNNvsLSTMvsGRU
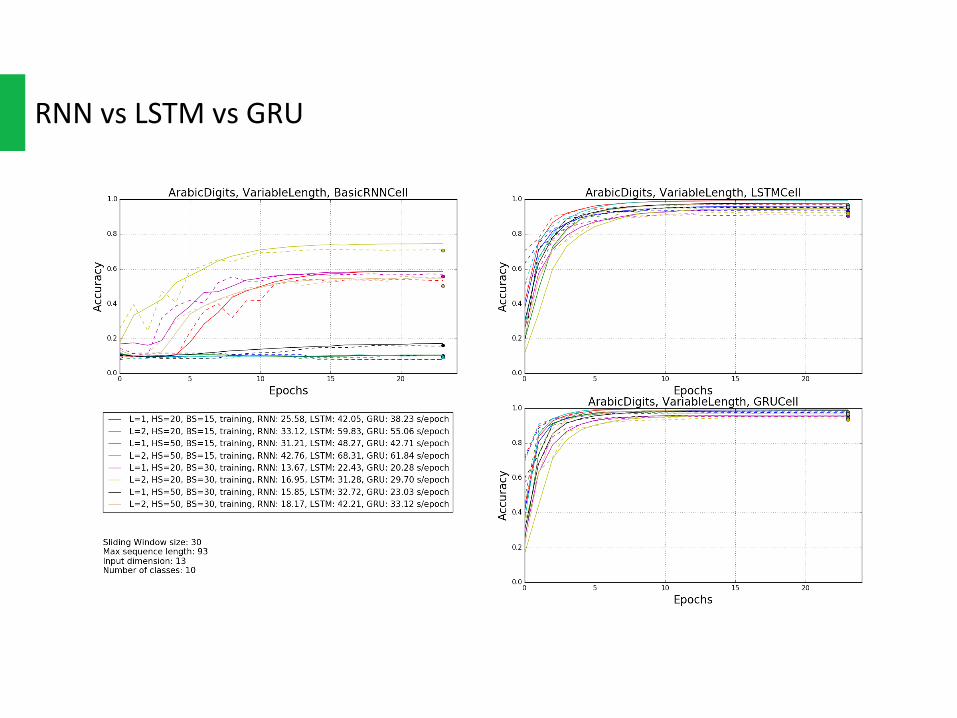
RNNvsLSTMvsGRU
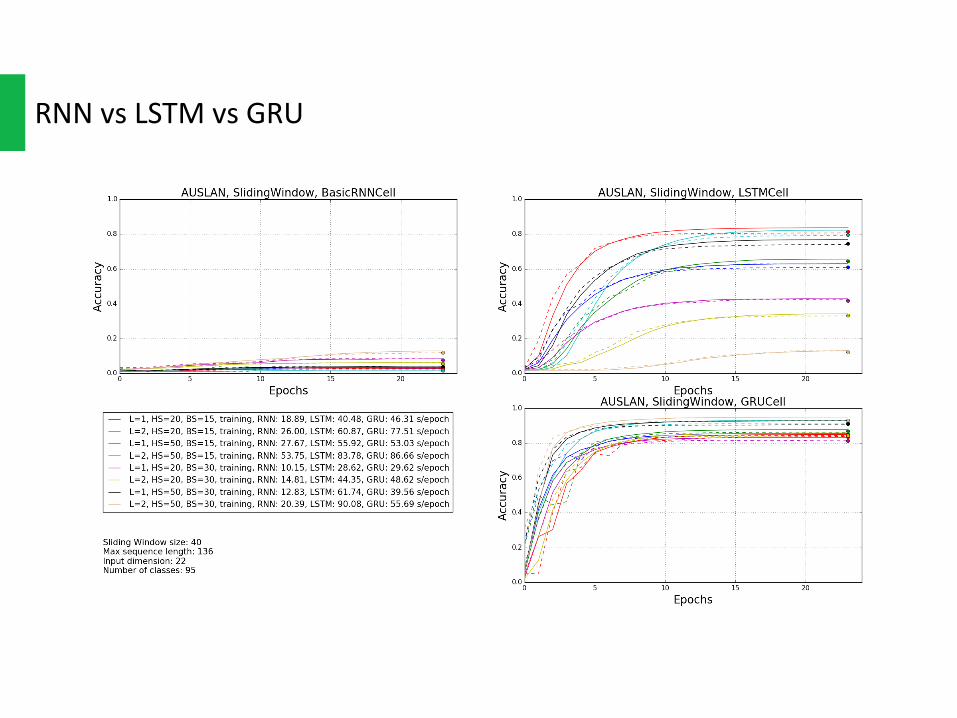
RNNvsLSTMvsGRU
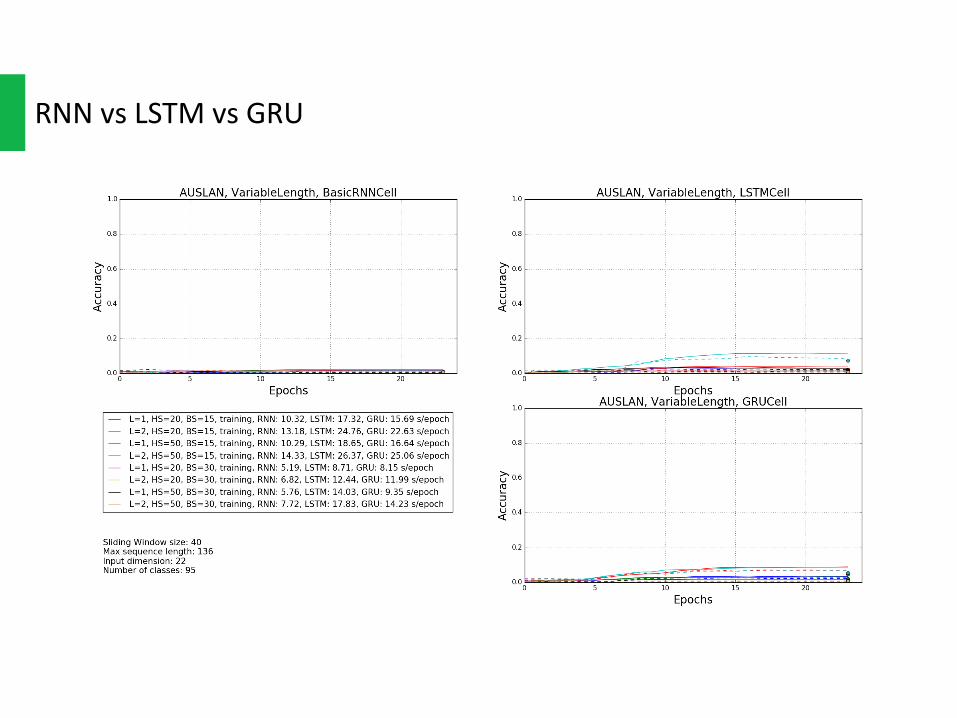
RNNvsLSTMvsGRU

Hyperparameters Comparisons
• LearningRate• BatchSize• NumberofLayers• HiddenSize

LearningRateTwolearningrateupdatingmethodswereusedinexperiments• Firstone,aftereachepoch,learningratedecays+ ,�. ,totally24epochs.• Secondone,aftereach5epochs,learningratedecays+ ,�. ,totally120epochs.
Theleftsideinthefollowingplotsuses24epochs,andtherightsideuses120epochs.
Becauseofthechangeoflearningrateupdatingmechanism,somenotconvergingconfigurations intheleft(24epochs)workprettywellintheright(120epochs).
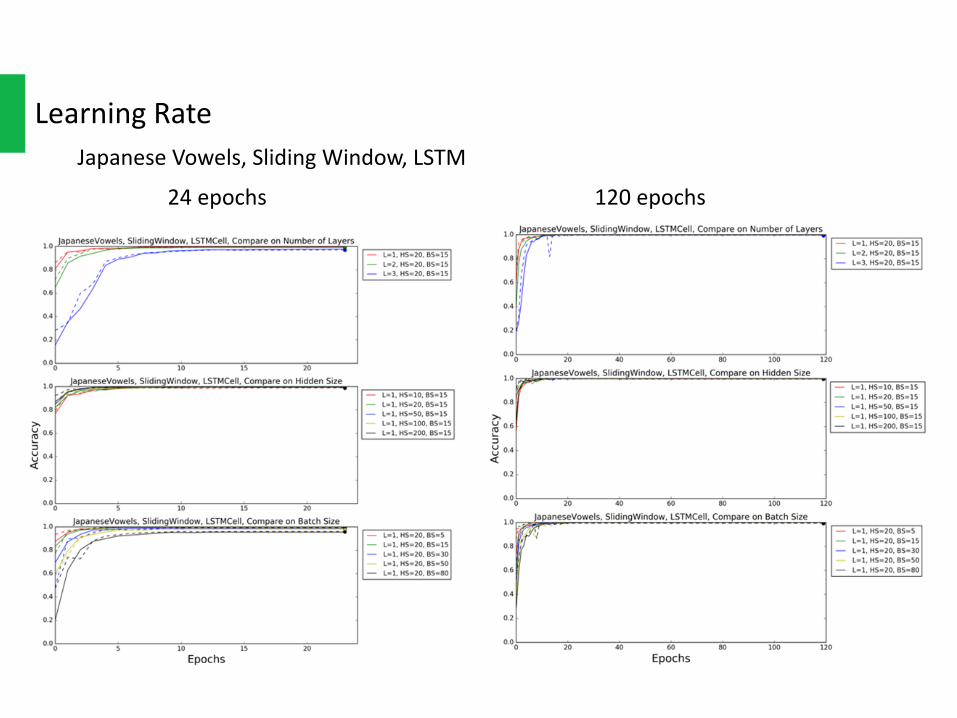
LearningRateJapaneseVowels,SlidingWindow,LSTM
24epochs 120epochs
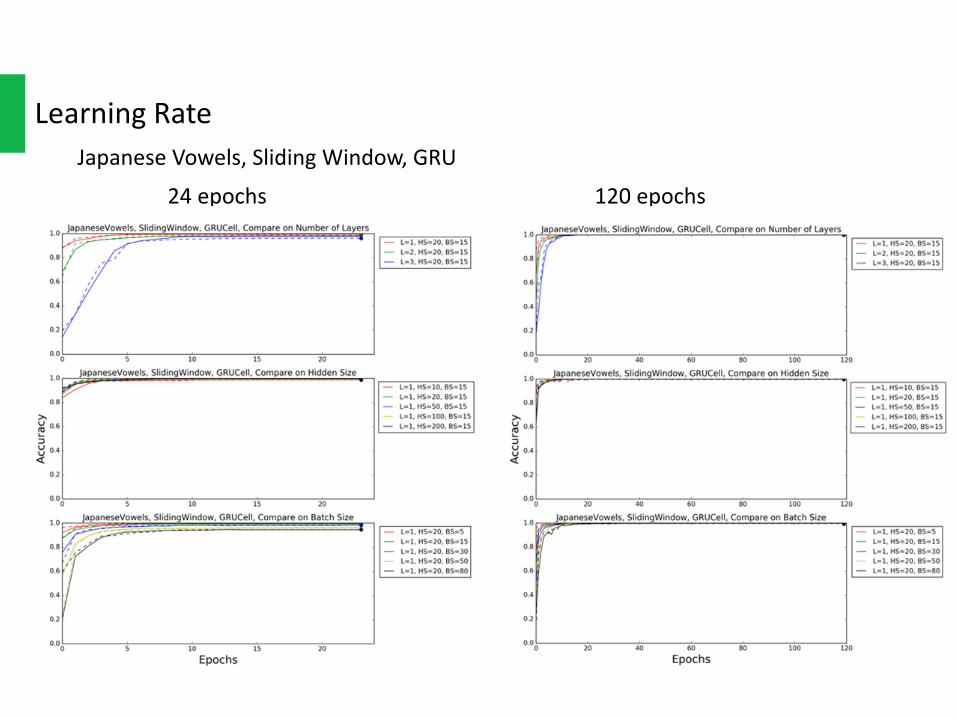
LearningRateJapaneseVowels,SlidingWindow,GRU
24epochs 120epochs
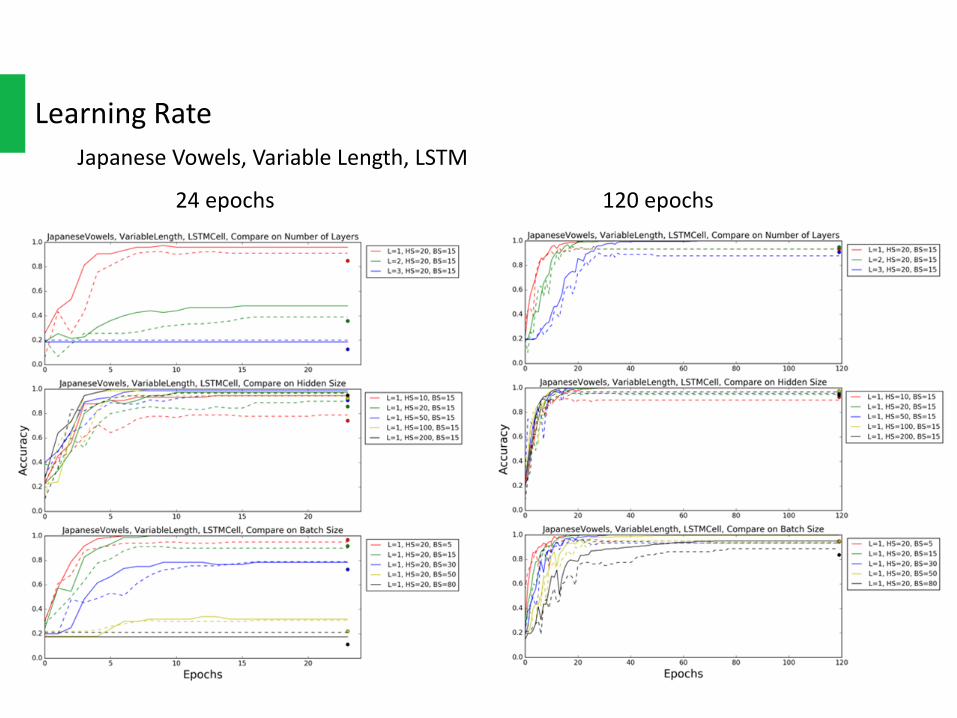
LearningRateJapaneseVowels,VariableLength,LSTM
24epochs 120epochs
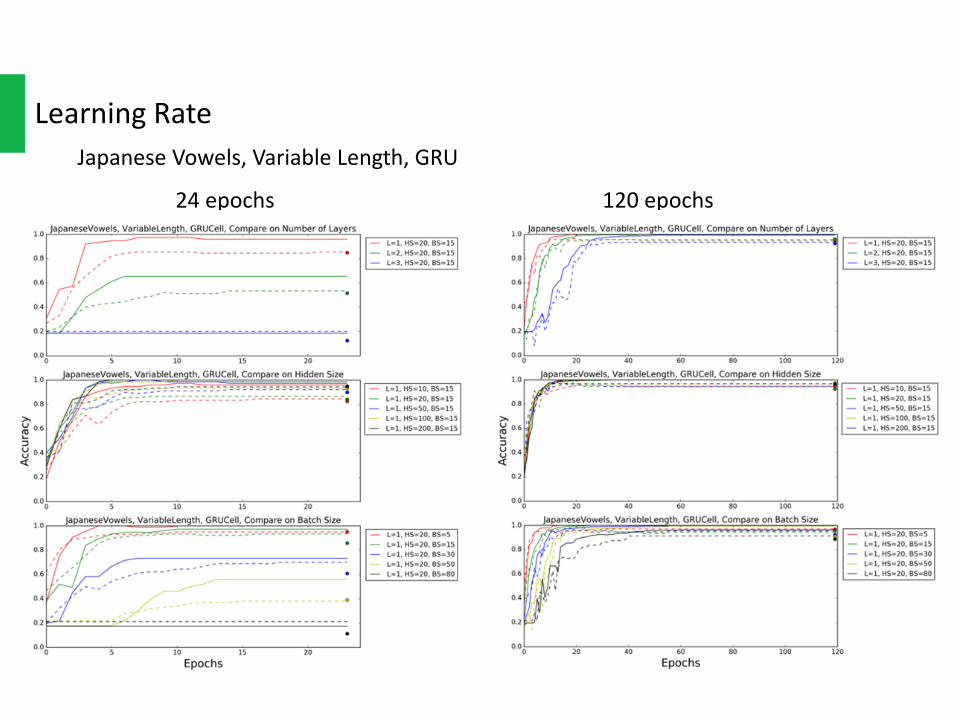
LearningRateJapaneseVowels,VariableLength,GRU
24epochs 120epochs

BatchSizeThelargerbatchsizemeansthateachtimeweupdateweightswithmoreinstance.Soithaslowerbiasbutalsoslowerconvergerate.
Onthecontrary,smallbatchsizeupdatestheweightsmorefrequently.Sosmallbatchsizeconvergesfasterbuthashigherbias.
Whatweoughttodomightbefindingthebalancebetweentheconvergerateandtherisk.
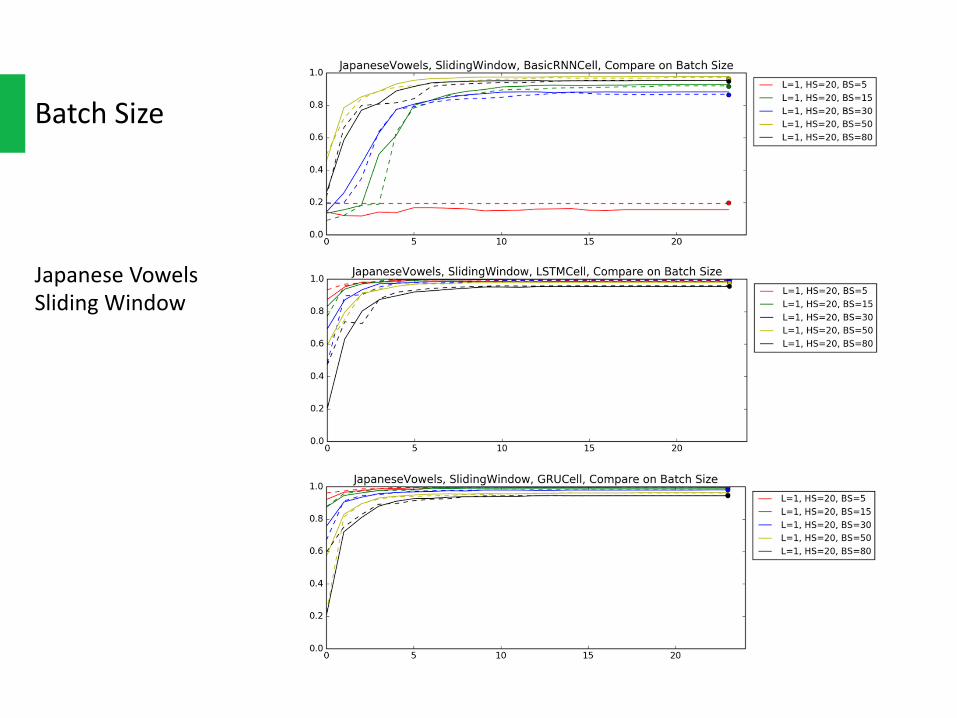
BatchSize
JapaneseVowelsSlidingWindow
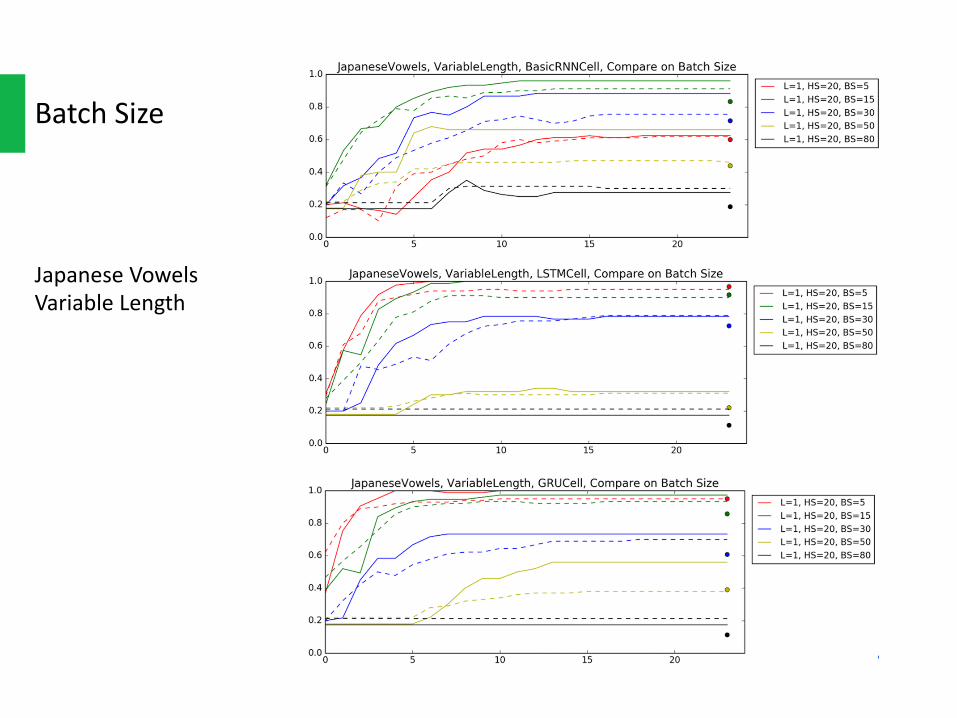
BatchSize
JapaneseVowelsVariableLength
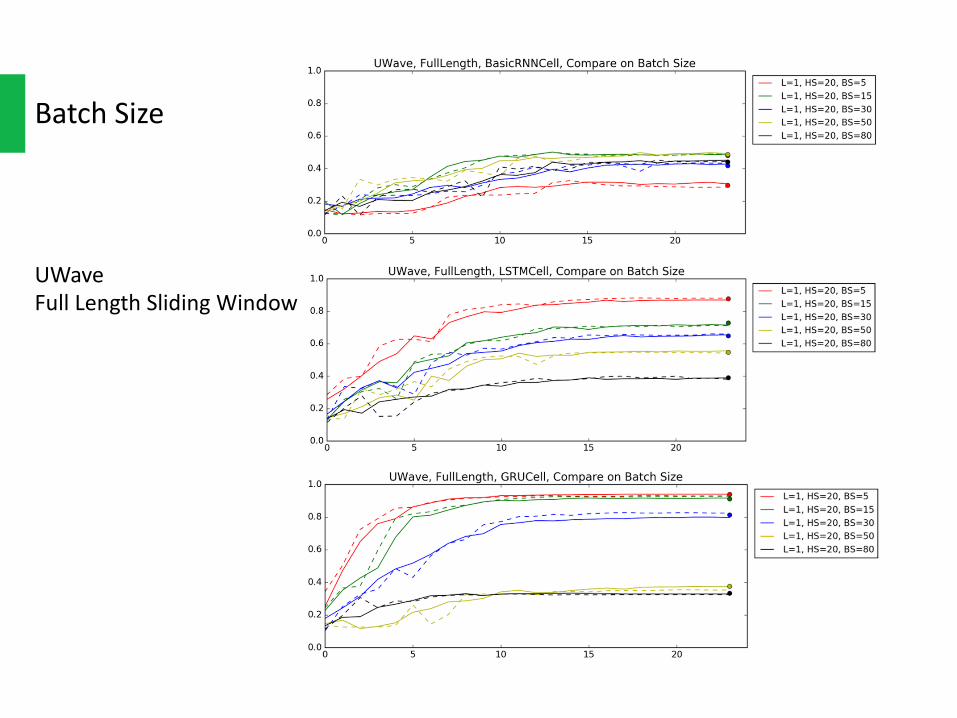
BatchSize
UWaveFullLengthSlidingWindow

Numberoflayers
Multi-layerRNNismoredifficulttoconverge.Withthenumberoflayersincreasing,it’sslowertoconverge.
Andeventheydo,wedon’tgaintoomuchfromthelargerhiddenunitsinsideit,atleastonJapaneseVoweldataset.Thefinalaccuracydoesn’tseembetterthantheonelayerrecurrentnetworks.Thismatchessomepaper’sresultsthatstackedRNNscouldbetakenplacebyonelayerwithlargerhiddensize.
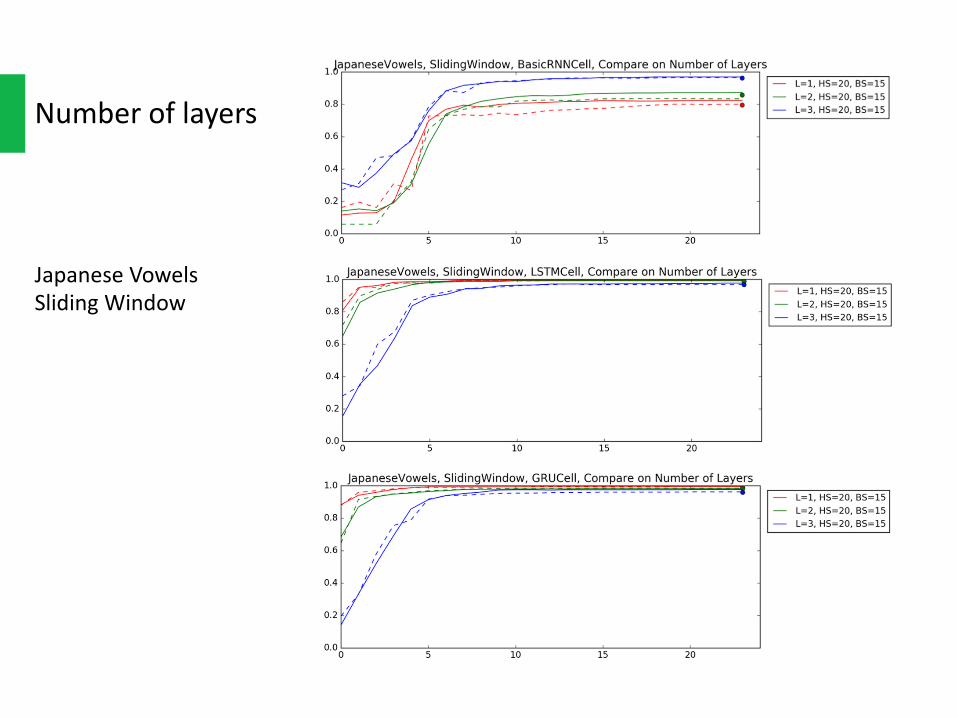
Numberoflayers
JapaneseVowelsSlidingWindow
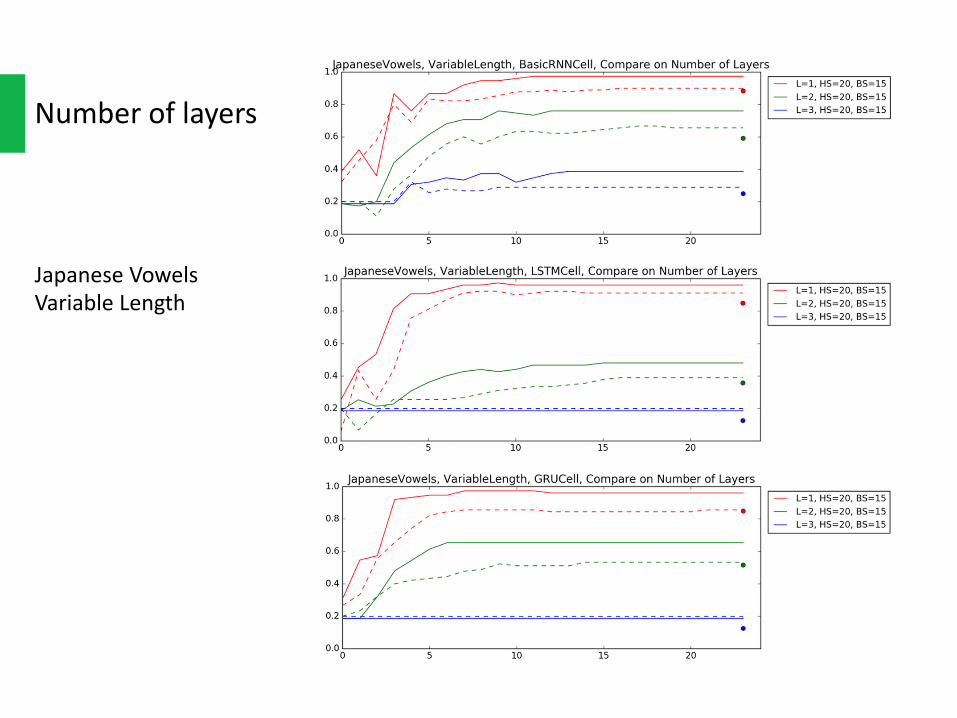
Numberoflayers
JapaneseVowelsVariableLength
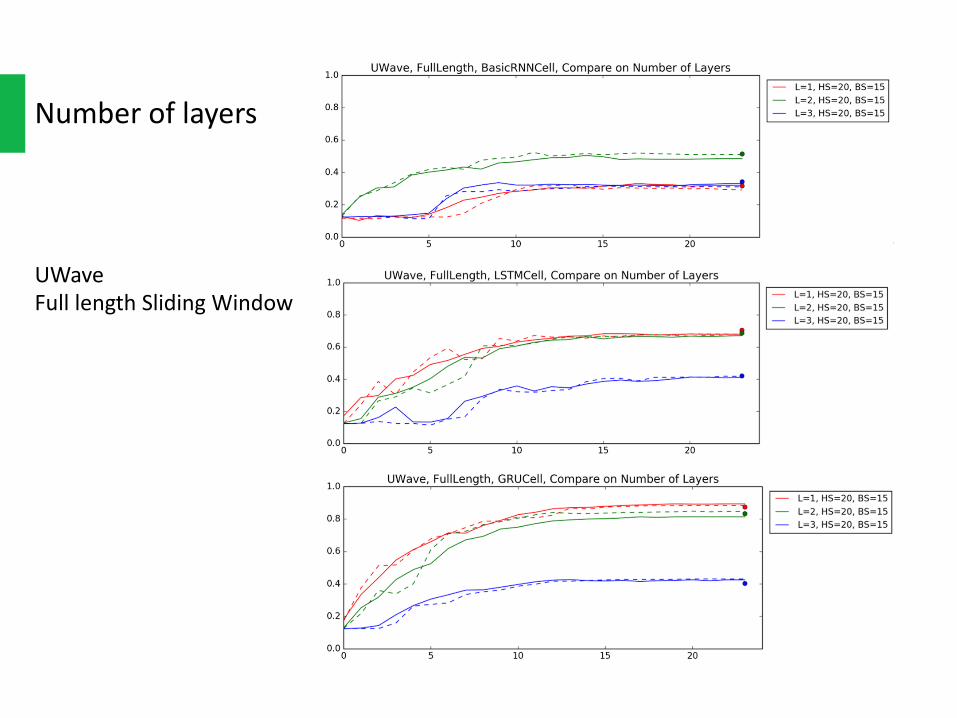
Numberoflayers
UWaveFulllengthSlidingWindow

HiddenSize
EitherfromJapaneseVowelsorUWave,thelargerthehiddensizeonLSTMandGRU,thebetterthefinalaccuracywouldbe.AnddifferenthiddensizesharesimilarconvergerateonLSTMandGRU.Butthetrade-offoflargerhiddensizeisthatittakeslongertime/epochtotrainthenetwork.
There’resomeabnormalbehavioronvanillaRNN,whichmightbecausedbythegradientvanishing.
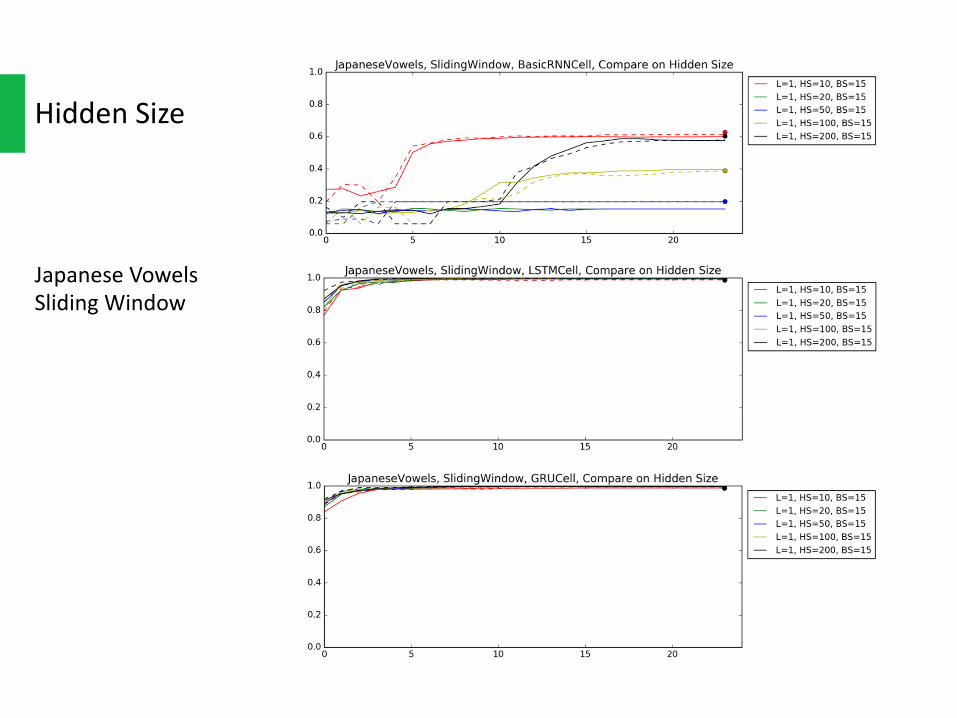
HiddenSize
JapaneseVowelsSlidingWindow
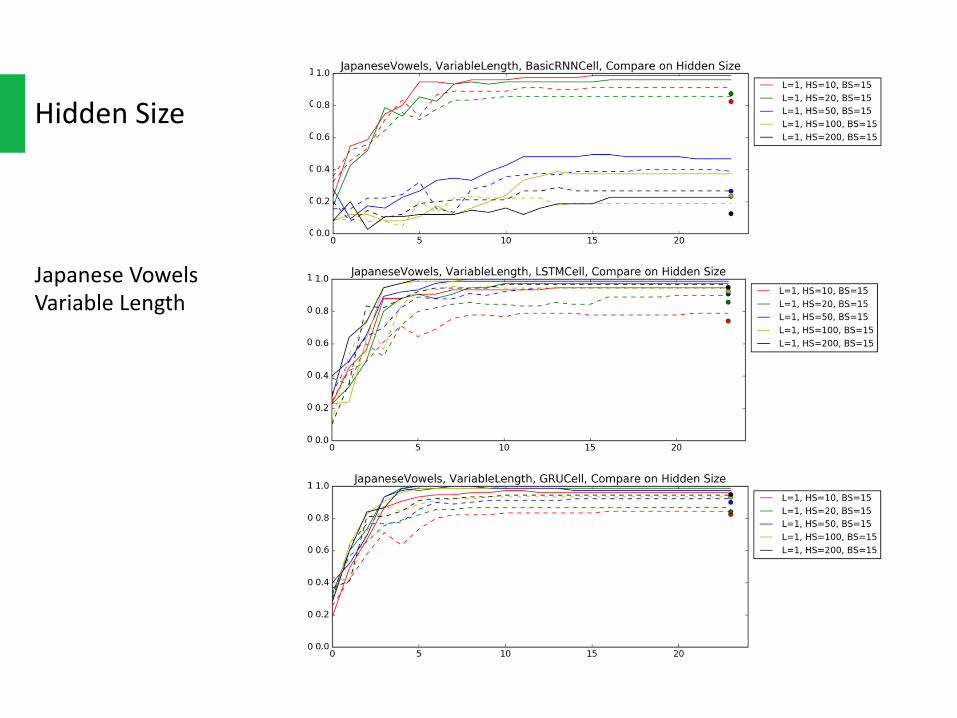
HiddenSize
JapaneseVowelsVariableLength
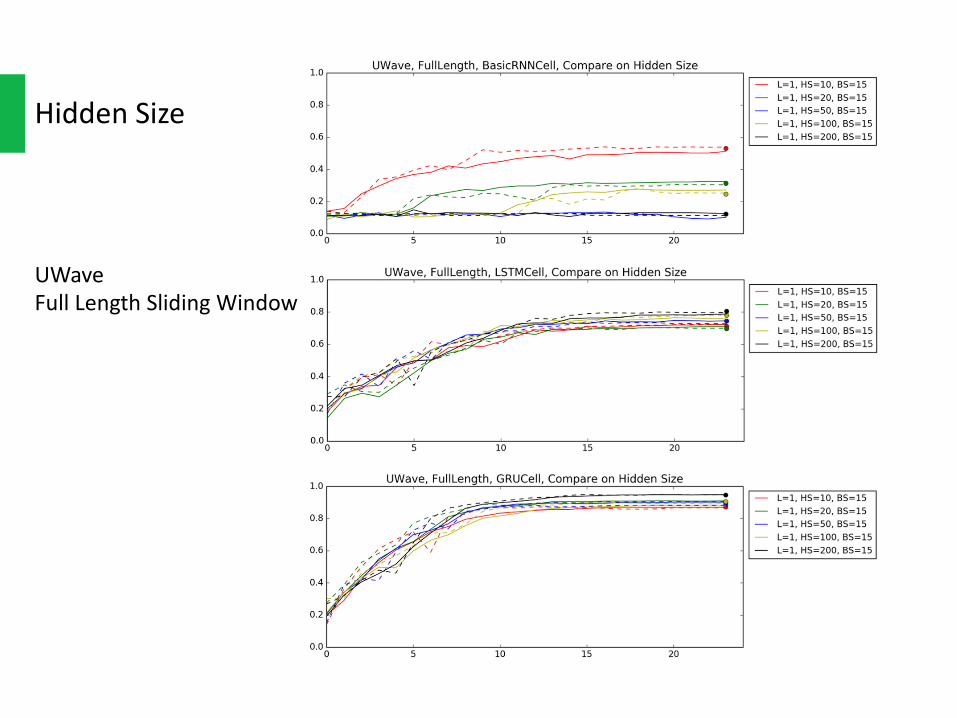
HiddenSize
UWaveFullLengthSlidingWindow

Conclusion

Conclusion
Inthispresentation,wefirstdiscussed:• WhatareRNN,LSTMandGRU,andwhyusingthem.• Whatarethedefinitionsofthefourhyperparameters.
Andthroughroughly800experiments,weanalyzed:• DifferencebetweenSlidingWindowandVariableLength.• DifferenceamongRNN,LSTMandGRU.• What’stheinfluenceofnumberoflayers.• What’stheinfluenceofhiddensize.• What’stheinfluenceofbatchsize• What’stheinfluenceoflearningrate

Conclusion
Inthispresentation,wefirstdiscussed:• WhatareRNN,LSTMandGRU,andwhyusingthem..• Whatarethedefinitionsofthefourhyperparameters.
Andthroughroughly800experiments,weanalyzed:• DifferencebetweenSlidingWindowandVariableLength.• DifferenceamongRNN,LSTMandGRU.• What’stheinfluenceofnumberoflayers.• What’stheinfluenceofhiddensize.• What’stheinfluenceofbatchsize• What’stheinfluenceoflearningrate
Generallyspeaking,GRUworksbetterthanLSTM,and,becauseofsufferinggradientvanishing,vanillaRNNworksworst.
Slidingwindowisgoodtosolvelimitedinstancedatasets,which1)mayhaverepetitivefeatureor2)sub-sequencecouldcapturekeyfeatureofthefullsequence.
Allthesefourhyperparameters playimportantroleintuningthenetwork.

Limitations
Howevertherearestillsomelimitations:
1. Variablelength:• Thesequencelengthistoolong(~100-300formostdatasets,someeven
largerthan1000)

Limitations
Howevertherearestillsomelimitations:
1. Variablelength:• Thesequencelengthistoolong(~100-300formostdatasets,someeven
largerthan1000)2. Slidingwindow:
• Ignoresthecontinualitybetweentheslicedsubsequences.• Biasedlabelingmaycausessimilarsubsequencesbeinglabeleddifferently.

Limitations
Howevertherearestillsomelimitations:
1. Variablelength:• Thesequencelengthistoolong(~100-300formostdatasets,someeven
largerthan1000)2. Slidingwindow:
• Ignoresthecontinualitybetweentheslicedsubsequences.• Biasedlabelingmaycausessimilarsubsequencesbeinglabeleddifferently.
Luckily,thesetwolimitationscouldbesolvedsimultaneously.

Limitations
Howevertherearestillsomelimitations:
1. Variablelength:• Thesequencelengthistoolong(~100-300formostdatasets,someeven
largerthan1000)2. Slidingwindow:
• Ignoresthecontinualitybetweentheslicedsubsequences.• Biasedlabelingmaycausessimilarsubsequencesbeinglabeleddifferently.
Luckily,thesetwolimitationscouldbesolvedsimultaneously.-- ByTruncatedGradient
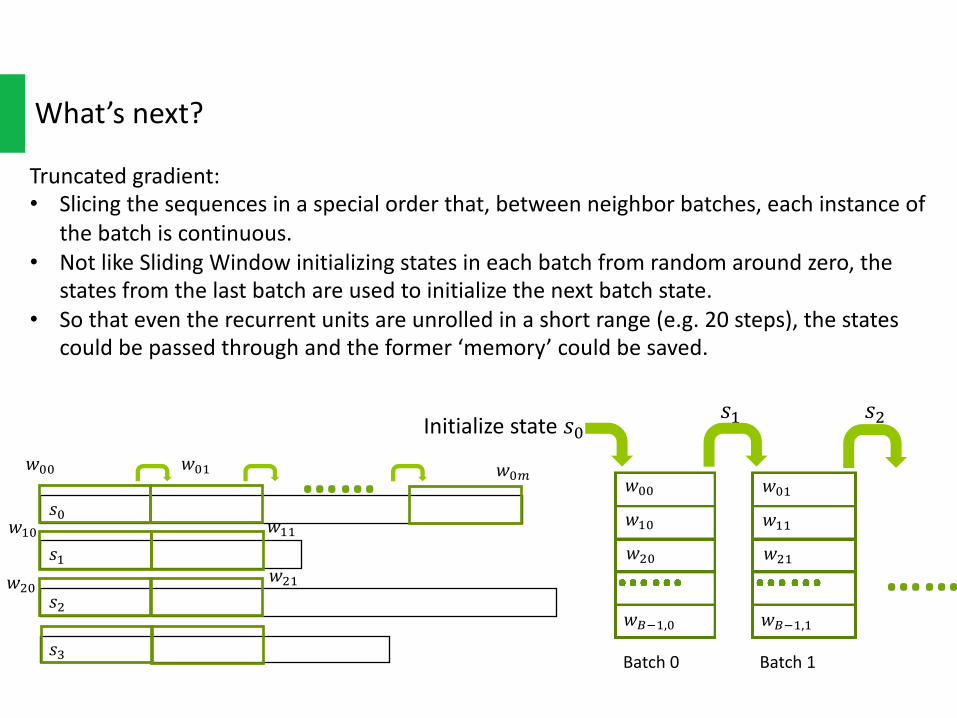
What’snext?
Truncatedgradient:• Slicingthesequencesinaspecialorderthat,betweenneighborbatches,eachinstanceof
thebatchiscontinuous.• NotlikeSlidingWindowinitializingstatesineachbatchfromrandomaroundzero,the
statesfromthelastbatchareusedtoinitializethenextbatchstate.• Sothateventherecurrentunitsareunrolledinashortrange(e.g.20steps),thestates
couldbepassedthroughandtheformer‘memory’couldbesaved.
𝑠0
𝑠+
𝑠,
𝑠1
……𝑤00 𝑤0+ 𝑤04
𝑤+0 𝑤++
𝑠+
……Batch0 Batch1
𝑤0+𝑤++𝑤,+
𝑤56+,+
𝑤00𝑤+0𝑤,0
𝑤56+,0
Initializestate𝑠0𝑠,
𝑤,0 𝑤,+

What’snext?
Averagedoutputstodoclassification:• Rightnow,weareusinglasttimestep’soutputtodosoftmax andthenusingCross
Entropytoestimateeachclass’sprobability.• Usingtheaveragedoutputsofalltimestepsorweightedaveragedoutputsmightbea
goodchoicetotry.

What’snext?
Averagedoutputstodoclassification:• Rightnow,weareusinglasttimestep’soutputtodosoftmax andthenusingCross
Entropytoestimateeachclass’sprobability.• Usingtheaveragedoutputsofalltimestepsorweightedaveragedoutputsmightbea
goodchoicetotry.
Prediction(sequencemodeling):• Alreadydidthesequencetosequencemodelwithl2-normlossfunction.• Whatneedstobedoneisfindingaproperwaytoanalyzethepredictedsequence.

THANK YOUThanks for Dmitriy’s instructions
And discussions with Feipeng and Xi

Questions?







