
Smart-Context: A Context Ontology
for Pervasive Mobile Computing
PHILIP MOORE*, BIN HU AND JIZHENG WAN
Department of Computing, Birmingham City University, Birmingham B42 2SU, UK
*Corresponding author: [email protected]
This paper addresses context in intelligent context-aware systems to support personalised service
provision and cooperative computing. Context processing, context modelling, ontology, and
OWL are introduced and a context reasoning ontology presented. Context implementation
reduces to a decision problem which is characterised as one of selecting from a number of potential
options based on the relationship between the values that describe the input and the solution, the
modelling school of decision analysis attempts to construct an explicit model of such relationships,
usually in the form of decision trees. An overview of decision trees with parametric design consider-
ations is presented. Comparisons with related research are drawn and an evaluation and simulation
of Smart-Context is presented. RDF/S with OWL and Jena provide an effective basis for auton-
omous decision making using processing rules, and the issue is one of implementation in adaptable
and tractable solutions. A conclusion with open research questions is presented with consideration
of potential directions for future research.
Keywords: context; context-awareness; pervasive computing
Received 21 February 2007; revised 06 July 2007
1. INTRODUCTION
This paper addresses the issue of personalised service
provision and cooperative computing based on defined need
and situated role, in mobile computing a user’s situated role
describes the current situation users experience during their
interaction with the system. Personalisation requires that an
individual’s profile (termed context) is created. The definition
of context presents many difficulties including identifying
individual users, accommodating users’ evolving preferences,
device and location sensing and managing the heterogeneous
nature of mobile and computational devices with their associ-
ated connectivity constraints and service infrastructure.
Accommodating these diverse demands requires an overall
context definition made up of sub-contextsthat describe and
define entities, an entity being defined in [1] as: a person,
place or physical or computational object.
In posing the question mobile, pervasive, ubiquitous or
wireless? [2], the observation has been made that the term
mobile wireless communication is often used in conjunction
with or interchangeably with pervasive computing; however,
the two are not necessarily synonymous.
Pervasive computing describes a paradigm whose primary
characteristics are (generally) ubiquity and invisibility such
that the opportunity for computation and connectivity are
constantly available while masking the presence of the
system from the user [3]. Pervasive computing is addressed
in [4], the anytime anywhere paradigm being extended to all
the time everywhere.
Currently, pervasive computing fails to realise the objectives
of the pervasive computing paradigm and is limited in its
capacity to implement the systemic requirements of flexibility,
autonomy and adaptability. Developments in hardware and
software have brought pervasive computing close to technical
and economic viability with the basic component technologies
all currently existing [4]. The challenges lie in the development
of intelligent agents implemented in intelligent systems [5] and
the integration of existing component technologies [4].
Pervasive computing must address a number of key issues
including: (1) accommodating a diverse range of applications,
(2) service provision based on relevance, (3) service provision
compliant with device constraints and users’ situated roles,
and (4) meeting users needs, objectives and beliefs, desires
and intentions (BDI). BDI represents mental attitudes repre-
senting, respectively, “information, motivational and delibera-
tive states” [6]. Accommodating these requirements demands
that users are identified based on their context (discussed in
Section 2.1), to enable pervasive computing to effectively
address the issues identified.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
# The Author 2008. Published by Oxford University Press on behalf of The British Computer Society. All rights reserved.For Permissions, please email: [email protected]
Advance Access publication on March 4, 2008 doi:10.1093/comjnl/bxm104
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

This paper introduces Smart-Context, an autonomous intelli-
gent context-aware pervasive system designed to enable
context matching between inputs (information, resources or
queries) and outputs (potential solutions, in this case suitable
users) based on contextual information. Implementation of
context matching essentially reduces to a decision problem,
the modelling school of decision analysis attempts to construct
an explicit model of the relationships between the input and
potential solutions, usually in the form of decision trees.
This paper presents a novel context process model to meet
the context processing needs with a rule-based semantic
context reasoning ontology to provide the basis upon which
effective intelligent context reasoning can be realised. A
brief illustrative location-based on-line cooperative computing
scenario is shown to demonstrate the reasoning process.
Implementation issues are considered with parametric design
considerations and decision trees are proposed as a potential
solution to enable effective intelligent context implemen-
tation. Smart-Context provides the basis upon which effective
implementation of context in intelligent systems can be
realised.
The remainder of the paper is structured as follows: Section
2 considers the background to the study with a discussion on
context, ontologies, the Semantic Web and the Web Ontology
Language (OWL). Section 3 discusses context modelling, the
context process model is presented and the application of
context is addressed with typical examples. Section 4
addresses Smart-Context, which with the context process
model forms the core concept of the paper. The context
factors, their identification and evaluation are discussed with
the RDF properties, the class structure, and the semantic
context reasoning ontology. An example of a reasoned scen-
ario presented. Section 5 considers related research with a
simulation and evaluation of the Smart-Context concept pre-
sented in Section 6. Section 7 looks at implementation
issues and considers decision trees (DT). The paper concludes
with conclusions and a discussion on future work in Section 8
and an appendix.
2. BACKGROUND
This Section introduces context with consideration of the
types of context and the elements that combine to create a
context definition. Ontologies and the issues that impact
their use are discussed with examples. There is a brief intro-
duction to the Semantic Web technologies and consideration
of the Web Ontology Language (OWL) from a context reason-
ing perspective.
2.1. Context
The concept of context is generally agreed, however, a
common definition is not [1], considerable confusion
surrounding the notion of context, its meaning and the role it
plays in interactive systems [7]. Context is purpose and appli-
cation specific requiring the identification of the function(s)
and properties (context factors) specific to each domain [8].
This is exemplified in the application of context-awareness
applied to mobile learning [9] where the starting point in the
definition of context is to identify the purpose of the context
we are interested in.
Contexts are variable, the degree of variability being
reflected in the classification applied to a context. There are
two general classifications [10]:
† A static context (termed customisation) describes a state
in which the ‘look-and-feel’ and content provision is
essentially user-driven, the user having an element of
control.
† A dynamic context (termed personalisation) describes a
state in which the user is passive, or at least somewhat
less in control, system functions monitoring analysing
and reacting to the users situated role [10], actions and
BDI [6].
The two types of context are reflected in the two principal
ways context is used, these are: (1) as a retrieval clue
(a static context) and (2) to tailor system behaviour to match
users’ system usage patterns (a dynamic context).
A context consists of properties (context factors) that
describe and define an entity in computer-readable form [8],
the properties describing any information that can be used to
characterise an entity [5]. A context definition must define
and describe a number of elements that combine to create an
overall context definition, these elements include: (1) spatio-
temporal, (2) personal, (3) device(s), (4) infrastructure and
connectivity constraints, and (5) resource(s). A context is
created by combining property values that describe a diverse
range of elements [4] [10] [11] [12] including: (1) the variable
tasks demanded by users, (2) the mobile and computational
devices, (3) the service infrastructure, (4) the physical situ-
ation including location, and (5) the social setting.
There are three primary types of contextual information
(referred to as context dimensions in [1]): (1) spatio-temporal,
(2) identity, and (3) activity. Primary contextual information is
used to derive secondary contextual information [1]. Second-
ary contextual information relates to property values that
describe context factors such as location, device character-
istics and identity information. Contextual information can
be derived from an array of diverse sources including location,
weather and traffic sensors, sensors monitoring computer net-
works and status sensors for human users or computing
devices in ad hoc networks.
2.2. Ontologies
The use of ontology in computer science can be traced to
Artificial Intelligence (AI) research in the 1960’s [13] [14].
192 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

A formal dictionary definition of the term ontology1 when
used in AI is: An explicit formal specification of how to rep-
resent objects, concepts and other entities that are assumed
to exist in some area of interest and the relationships that
hold among them . . . for AI systems, what exists is that
which can be represented. Ontology is defined in [15] as: A
conceptualisation of a domain into a human-understandable
but machine-readable format consisting of entities, attributes,
relationships and axioms.
The ability of ontologies to represent entities has recognised
benefits; these are the capacity to communicate information
and the ability to name concepts in machine-readable form
[15]. There are however disadvantages [16], and these include:
(i) The potential size and scale of an ontology
(ii) Ontologies are based on well-defined concepts and
logic making concept definition difficult
In considering (i), adding concepts and facts can result in
ontologies growing very large very quickly resulting in pos-
sible tractability issues. In considering (ii), humans (generally)
understand what is meant by different concepts such as
at_home or at_work. Computationally it is necessary to
define such concepts using inference rules on an ontology
which can present difficulties.
Ontology languages allow users to write explicit formal
conceptualisations of domain models. The main requirements
of such models are [17]:
† Well-designed syntax
† Well-designed semantics
† Efficient reasoning support
† Sufficient expressive power
† Convenience of expression
There have been a number of ontology languages devel-
oped, and the most widely known is the Web Ontology
Language OWL2 (a component in the W3c Semantic Web),
which is an extension of RDF/S (this is a generalisation as
there are 3 OWL sub-languages—see Section 2.4). OWL is
(partially) mapped onto a description logic [17] which is a
subset of predicate logic for which efficient reasoning
support is possible [18].
2.3. The Semantic Web
The Semantic Web is a concept predicated on the goal of trans-
forming the world wide web (www) into “. . . a set of con-
nected applications . . . forming a consistent logical web of
data . . .” [19] realised by adding ‘semantic annotations’ to
the XML/RDF tagging schema to impart meaning to web
content [20]. In the Semantic Web information has explicit
meaning enabling easier automated processing (as opposed
to merely presenting content to users).
The Semantic Web functions using Semantic Metadata and
is predicated on the idea that data can be arranged in the form
of an ontology and can be viewed in terms of “a set of logical
assertions about specific things and their relationships” [17,
21]. Ontologies establish a common conceptual description
and a joint terminology between members of communities
of interest (human and autonomous software agents) [22].
An example of a semantic ontology constructed to represent
an animal kingdom built using logical assertions is presented
in [17].
The Semantic Web consists of four W3C recommendations:
† The Extensible Markup Language (XML)
† XML Schema
† The Resource Description Framework (RDF/S)
† The Web Ontology Language (OWL)
XML, XML Schema and RDF/S3 are well-understood con-
cepts. OWL is addressed in the following Section.
2.4. The Web Ontology Language (OWL)
The expessivity of RDF and RDF Schema is (deliberately)
very limited [17]. RDF is (generally) limited to binary
ground predicates, RDF Schema being (again generally)
limited to subclass and property hierarchy with domain and
range definitions of these properties [17]. OWL extends the
expressive power of RDF and RDF Schema, adding additional
vocabulary enabling constraints including: (1) relationships,
(2) equality, (3) richer typing of properties, (4) characteristics
of properties, and (5) enumerated classes. OWL provides three
sub-languages [17]:
† OWL Full: uses all OWL language primitives enabling
their use with RDF and RDF Schema. The disadvantage
is that OWL Full is undecidable, making effective
reasoning support at best impractical and at worst
impossible.
† OWL DL (Description Logic): to enable effective
reasoning OWL DL restricts the use of OWL and RDF
constructors, thus ensuring that the language corresponds
to a description logic. The disadvantage is that full com-
patibility with RDF is lost, RDF documents requiring
extending or restricting before they are legal OWL DL
documents. Conversely, every OWL DL document is a
legal RDF document.
† OWL Lite: represents a further restriction in limiting
OWL to a subset of the language constructors. OWL
Lite exclusions include: (1) enumerated classes, (2) dis-
joint statements, and (3) cardinality. The disadvantage1Dictionary.com: http://dictionary.reference.com/2OWL: http://www.w3.org/TR/owl-features/ 3W3c: http://www.w3.org/TR
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 193
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

of OWL Lite is its restricted expressivity and limited
reasoning capability.
From an ontological perspective there are strict design
notions of upward compatibility between the three sub-
languages [17]:
† Every legal OWL Lite ontology is a legal OWL DL
ontology.
† Every legal OWL DL ontology is a legal OWL Full
ontology.
† Every valid OWL Lite conclusion is a valid OWL DL
conclusion.
† Every valid OWL DL conclusion is a valid OWL Full
conclusion.
Recall that ontological modelling requires sufficient expres-
sive power to enable effective reasoning support, OWL Full and
Lite fail in this regard. OWL DL, being predicated on descrip-
tion logic, does however support effective reasoning.
3. CONTEXT MODELLING
There are many approaches to the modelling of context. A
comprehensive survey of context modelling from a ubiquitous
computing perspective can be found in [23], the context mod-
elling approaches are categorised under 5 headings: (1) Key-
value Models (KVM), (2) Markup Scheme Models (MSM),
(3) Graphical Models (GM), (4) Object-Oriented Models
(OOM), (5) Logic Based Models (LBM), and (6) Ontology
Based Models (OBM). The modelling approaches are classi-
fied based on their data structures, and an analysis in [23]
resulted in the conclusion that Ontology Based Models
represent the optimal approach.
In addition to the categories listed in [23] there are machine
learning (ML) approaches using both supervised and unsuper-
vised learning [16] [24]. There are inherent issues and poten-
tial advantages in using an ML approach, addressing these
forms the basis of future work and are discussed in Sections
5.1, 7 and 8.
The modelling categories are not independent, there being
an element of interdependence. For example, in developing
systems using ontologies OBM may be used to model the
relationships and constraints that exist between entities.
OBM approaches share elements from LBM, OOM, GM and
MSM approaches including the following:
† OBM (using the Semantic Web) uses RDF/S and OWL
(markup-languages)
† The Semantic Web is predicated on OO, OBM therefore
inherits the class-based structure of the OOM approach
† OOM generally employs graphical representations (such
as UML) which exhibit similarities with the GM approach
(using, for example, Entity Relationship diagrams).
† Logic (the basis of LBM) is important in ontologies
therefore aspects of LBM are used in OBM.
In Section 2 ontologies, the Semantic Web, and OWL have
been introduced; the issues and advantages have been dis-
cussed with illustrative examples. There are clearly issues in
the use of ontologies to model context including issues ident-
ified in [16] (discussed in Sections 2.2 and 5.1). Effective
implementation of intelligent context requires sufficient com-
putational intelligence (discussed in Sections 2.2 and 2.4) to
enable inference and reasoning. The ontological modelling
approach using Semantic Web technologies (see Section 2)
provides the optimal modelling approach as shown in [23].
An ontology-based approach to context modelling and reason-
ing in pervasive computing is presented in [25], using a
semantic ontology in a rule-based, event-driven system, the
OBM approach is used to good effect.
The efficacy of ontological context modelling has been
demonstrated, the issues lie in the implementation. The pro-
posed approach to address these issues is addressed in Section 7.
3.1. Context process model
Ontological context modelling represents the optimal solution to
the modelling of context [23]. The modelling function however
fails to address the issue of the processing of contextual infor-
mation (context processing). This Section discusses context pro-
cessing and presents a novel context process model which forms
a pivotal element in the Smart-Context concept.
The domain-specific nature of context [8] extends to the
processing of contextual information. In our research there
are domain-specific system prerequisites, principal amongst
these is the need to access context and update entity context
definitions stored in heterogeneous back-end systems. To
meet the context processing needs a context process model
has been developed, this is presented graphically in Fig. 1.
A context can be viewed as a state with transitional states.
Fig. 1. models this process, commencing with a stored context
(Current Context [A]) and terminating with the replacement of
the initial stored context (Current Context [A]) with the
context (Implemented (updated) Context [D]). The process
is cyclic with a back-up context always retained. Notes 1–6
(see Fig. 1) are expanded below:
† Note 1: The initial stored Current Context [A] is created
(in the first instance default values will be used to create
an initial current context [A]).
† Note 2: Upon an event triggering the system the sensory
input data is processed and the Updated Context [B] is
created to reflect the new situated role.
† Note 3: Based on context processing rules if no further
context processing is required, the Updated Context [B]
will replace the initial stored Current Context [A]. The
new Current Context [A] is also stored in a back-up
system.
194 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

† Note 4: In situations where context-processing rules
dictate the Updated Context [B] will be replaced by the
Updated Context [C] (following context processing) to
reflect the changing situated role.
† Note 5: The Updated Context [C] is implemented, the
Updated Context [C] becomes the Implemented
Context [D].
† Note 6: Finally, the Implemented Context [D] replaces
the initial Current Context [A]. The new Current
Context [A] is also stored in a back-up system.
The implementation of the process model requires an intel-
ligent multi-agent context middleware using context reasoning
in a rule-based system (discussed in later Sections), the intel-
ligent agent(s) autonomously applying the context rules to
manage the context processing and implementation thus auto-
mating context updating and implementation.
3.2. The application of context
Context-aware solutions have been applied in many diverse
domains where the provision of personalised services
mapped to an entities context is a system requirement. The fol-
lowing examples whilst not comprehensive, are representative
applications in the field of pervasive context-aware
computing.
† CRUMPET [26]: is a project to create user-
friendly mobile services personalised for tourism.
Context-awareness is used in the integration of four
technology domains: (1) location-aware services, (2)
personalised user interaction, (3) multi-media mobile
communication, and (4) smartware using multi-agent
technology.
† MOBllearn [9]: is an initiative to explore context-
awareness using contextual information in mobile
learning.
† Cooltown4: is a pervasive computing initiative focusing
on extending web technology, wireless networks and
portable devices to create a virtual bridge between
mobile users and physical entities and electronic
services.
† Cyberguid [27]: applies context-awareness to the devel-
opment of a mobile context-aware tour guide.
† Solar [28]: is a middleware platform to assist
context-aware applications aggregate desired context
from heterogeneous sources and to locate environmental
services depending on the current context.
† Group Interaction Support [29]: implements a
context-aware system to support group interaction in
mobile-distributed computing environments.
† Portolano5: A University of Washington project that
emphasises invisible, Internet- based computing. Infer-
ence is drawn from users intentions via their actions in
the environment and their interactions with everyday
objects.
† Oxygen6: is an MIT project to create an infrastructure of
mobile and stationary devices connected to a self-
configuring network.
The projects identified point to location as the predominant
application of context, a survey of context-aware applications
[30] confirms this conclusion. The use of location-based
context as the predominant application arguably stems from
the inherent complexity of context, difficulties in the manage-
ment of context and context matching [10], and issues effect-
ing the processing of contextual information. These are the
issues that intelligent context processing using ontological
context modelling seeks to address.
FIGURE 1. Context process model.
4http://vsbabu.org/mt/archives/2002/06/23/cool_town.html5http://portolano.cs.washington.edu/6http://www.oxygen.lcs.mit.edu/
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 195
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

4. SMART-CONTEXT
The previous sections have introduced the study, addressed the
background, and considered the modelling of context. This
section addresses Smart-Context, which with the context
process model forms the core concept of this paper. The smart-
Context concept builds on work carried out to create an RDF
context framework for personalised mobile learning [8]. This
research focused on the development of a generic context fra-
mework generalisable to similar domains to enable the effec-
tive definition of context for a student in the domain of higher
education (HE).
Smart-Context is an intelligent context-aware system to
enable the mapping of problems (input data) to potential sol-
utions (identified individuals together with their computational
devices/device characteristics). Smart-Context can be viewed
in terms of a decision-making system to implement intelligent
context processing. The context framework and RDF class struc-
ture has been developed with a context reasoning ontology to
provide a basis for effective decision-making to support person-
alised information services and cooperative computing.
Smart-Context is event driven, activated by change. For
example, the movement of an individual (or an individual’s
mobile device) from one location to another prompts an
input into the system notifying the location change, this will
trigger context processing to update and implement an individ-
ual’s context based on context-processing rules (discussed in
Section 3.1).
This section presents the context factors used in the devel-
opment of the context framework with the identification and
evaluation processes. The context properties are reflected in
the RDF/S class structure. A semantic context reasoning ontol-
ogy is presented with consideration of implementation and
evaluation issues.
4.1. Identifying the context factors
The context factors identified are presented in Fig. 2, the list is
non-hierarchical being analogous to a menu from which appli-
cable factors suitable to a domain-specific contextual design
can be selected.
4.2. Context factor identification
The identification of the context factors was achieved using
semi-structured interviews with staff drawn from the Depart-
ment of Computing at Birmingham City University forming
the sample population. Fifteen interviews were conducted, a
breakdown shows that of the fifteen staff interviewed thirteen
were active tutors, one was involved in student support,
and one was employed in technical services. The tutorial
staff interviewed included computing (technical) and
business-oriented (soft systems) staff. A quantitative analysis
shows that 66% were from a computing or technical back-
ground with 33% drawn from soft systems disciplines.
Semi-structured interviews effectively addressed the data
elicitation requirements and the associated issues identified,
the principal issues being:
† Availability and timing constraints.
† Identification and access to the sample population.
† Ethical considerations.
The interviews were conducted by appointment on a
one-to-one basis. Prior to the interview briefing documen-
tation was provided to give the respondents an overview of
the research, its aims, objectives and motivation. The time
envisaged for each interview was 30 minutes, in actuality
the time varied from approximately 30 to 75 minutes.
A potential issue identified at an early stage was the rela-
tively small population size. The research design addressed
this issue using the purposive sampling method [31]. Purpo-
sive sampling calls for the use of populations with recognised
knowledge and experience in the domain the research is
designed to address, thus mitigating the potential for a
biased result. The selected population satisfied the require-
ments of the purposive sampling method.
4.3. Context factor evaluation
The factors were evaluated using a questionnaire, the design
being based on a variation of the Likert scale with four avail-
able options: strongly agree, agree, disagree, and unsure (see
Fig. A1). The questionnaire initially identifies the respondent
as a student or tutor. The questions are set under four sections:
personal, academic, mobile learning system, and device.
FIGURE 2. The context factors.
196 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

Sample Sections of the questionnaire are set out in Fig. A1 in
Section 9 (the appendix).
The questions are framed using the identified context
factors, the final questionnaire being the result of a piloting
process using a different (but similar) population to that
polled in the actual survey. The questionnaire was distributed
to staff and students at Birmingham City University (UK) and
Guilin University of Technology (P.R. China) to determine the
degree to which the factors identified in the interview process
are representative of other HE domains.
4.3.1. The analysis
A statistical analysis used aggregate response (N) values nor-
malised to a maximum value of 1 with standard deviation
(SD), correlation (C) and moving averages (MA). The
results are cross tabulated in Tables 1–3, the results obtained
from the statistical analysis were analysed visually. The
formula for calculating the (N) values is
N ¼X
R� �
=M
where N ¼ the aggregate response value, R ¼ the sum total of
the encoded responses, and M ¼ the notional maximum value
of the encoded responses. For example, given 10 strongly
agree responses to a specific question the value of R is (10 *
4) which equates 40, applying the formula for R ¼ 40:
�N ¼
XR
� �=M
�N ¼ 40=40� ��
N ¼ 1:00�
and applying the formula for R ¼ 30:
�N ¼
XR
� �=M
�N ¼ 30=40� ��
N ¼ 0:75�
It can be seen from the results obtained from applying the
formula that in the first case the result is 1.00 and in the
second case the result is 0.75. This demonstrates the overall
level of agreement with a specific context factor.
The questionnaire returns demonstrated a wide variation in
response to each question, the SD (Table 2) supporting this
observation. The wide range of questionnaire responses were
reflected in the data obtained in the interview process. To
test for relationships between the interview, student, and
tutor data sets and to quantify the strength of any relationship,
correlation coefficients (C) were calculated. The (C) results
were negative ranging from weak (interview/tutor data)
through moderate (interview/student data) to strong (student/
tutor data)(Table 3). These results suggest that statistically sig-
nificant relationships are present in the data.
The (N) values were computed for each question from the
responses returned, a summary of the results is cross tabulated
in Table 1. The (N) values represent a measure of the overall
level of agreement respondents expressed related to the use of
each factor in a student context definition. The results fell into
relatively narrow ranges for tutor and student responses, the
interview results showing a similar maximum but widely dif-
fering minimum and average result. The wide differences
identified are explained by the smaller sample used in the
interviews as compared to the larger survey sample. With
respect to the (MA), notwithstanding the widely differing
(N) values identified, significant patterns and trends in all
three data sets were observed.
The results derived from the statistical and visual analysis
support the observation that there is a level of statistical sig-
nificance in the data. The analysis supports the conclusion
that: (1) the wide variation in the identified factors noted in
the interview process (and used in the development of the fra-
mework) is reflected in the questionnaire responses and (2) the
factors identified in the interviews are representative of other
larger populations.
4.4. RDF Context Properties
Sections 4.2–4.4 have discussed the identification and evalu-
ation of the context factors. The identified factors (Fig. 2) form
the basis for the RDF context properties (Fig. 3) which define
the context framework.
The context framework [8] is defined in RDF schema
document(s) setting out the schema specific vocabularies
that describe entities based on combinations of classes
TABLE 1. Aggregate response values
Max Min Avg
Tutor responses 0.97 0.50 0.74
Student responses 0.90 0.59 0.71
Interview responses 0.93 0.07 0.31
(N) value ranges
TABLE 2. Standard deviation
Max Min Avg
Tutor responses 1.32 0.33 0.81
Student responses 1.01 0.55 0.81
SD value ranges
TABLE 3. Correlation coefficient
Data set comparison Coefficient
Interview data/Q_Tutor data 0.377069672
Student/Q_Tutor data 0.671195618
Interview data/Q_Student data 0.480650532
(C) values
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 197
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

and properties. The RDF schema is non-hierarchical and when
implemented in an application provides the ability to tailor
classes and properties to suit other similar domains. Set out
in Fig. 3 are extracts from the validated RDF member
schema showing the header code with qualified namespaces,
datatypes and example class and property definitions. The
example RDF/S (Fig. 3) illustrates the definitions for the
Class:Profile with its sub-class Class:Person and an individ-
ual’s name property with the associated datatype.
4.5. The Class Structure
The class structure has been developed from the RDF context
framework discussed in [8] and is based on object-orientation
(OO) using classes and sub-classes with associated properties
and sub-properties (based on the identified context factors)
defined in the RDF Schema to represent types and classifi-
cations of entity. The class structure (Fig. 4) provides the cap-
ability to add and remove classes, vocabularies and properties
to tailor and refine context definitions to suit the domain
specific nature of context and contextual design.
The class structure provides a basis upon which context pro-
cessing (discussed in Section 3.1) can be implemented and
process-awareness, arguably the most important element in
Smart-Context, achieved.
Recall that context can be viewed in terms of a series of
states with transitional states. To effectively manage the inter-
actions that take place during context processing the system
must maintain an awareness of all prevailing states and the
context processing process. Class:Process has been incorpor-
ated to fulfil these functions, to receive the input data and
return the resultant output (the matched context(s)). Class:
Process can be viewed in terms of an interface to initiate,
control and manage the context processing process.
The class structure is predicated on the RDF data model and
at its root is the Class:Context, a class designed to hold the
overall context definition built from the entity contexts.
There are four sub-classes of Class:Context, Person, Spatio-
Temporal, Device, and Resource; these classes define the
entity contexts (sub-contexts). Properties that relate to
human users are defined in Class:Person and its sub-classes:
Preference, Schedule, Activity, Task, and Role. Classes
FIGURE 3. RDF/RDFS context properties.
FIGURE 4. The class structure.
198 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

Device Resource and Spatio-Temporal relate to properties
specific to physical objects (Device), computational objects
(Resources) and places including date and time properties
(Spatio-Temporal) respectively.
The class structure is designed to accommodate the
demands imposed by the differing inputs the system must
accept, the inputs fall into three general use-cases:
† A question placed on the system by a questioner with the
objective of identifying a suitably qualified adviser or an
appropriate resource
† A resource entered on the system for distribution to
appropriate individuals
† A resource distributed dynamically based on users con-
texts [5], actions and BDI [6]
In the three use-cases identified the system will be required
to perform context matching in the context space (discussed in
Section 7.2). Context matching involves the mapping of the
problem context to potential solution contexts to identify suit-
able matches. To accommodate this process Class:Process
will enable the use of in-memory data storage to hold the
problem context (while context matching takes place) and
the resultant matched context(s).
The class structure and RDF Schema provide a basis for the
creation of context definitions and context matching. This does
not however address the issue of context reasoning, a context
reasoning ontology has been developed to address this issue.
4.6. Reasoning with Smart-Context ontology
Ontologies are introduced in Section 2.2 with consideration of
semantic issues, inference and reasoning. The Semantic Web,
predicated on the idea that data can be arranged in the form of
ontologies, is discussed in Section 2.3 with an introduction to
OWL presented in Section 2.4. Section 3 reviews and con-
siders the available approaches to context modelling, OBM
representing the optimal approach.
Using OBM a semantic context reasoning ontology based
on the class structure (see Section 4.5 and Fig. 4) has been
developed and is presented graphically in Fig. 5. The follow-
ing brief illustrative location-based on-line cooperative com-
puting scenario demonstrates the context reasoning process.
† A1: Spatio-Temporal (date ¼ “2006:27:11”) [Monday]
† A2: Spatio-Temporal (time ¼ “10:35:48”) [am]
† B1: Person (name ¼ “Tom”) IsAtSpatio-Temporal (location ¼ “library”)
† B2: Person (name ¼ “Tom”) HasAActivity (activity ¼ “on-line”)
† B3: Activity (activity ¼ “on-line”) HasATask (question (subject ¼ “Prolog”))
† B4: “Tom” is on line, is located in the library and has a
role of student
† C1: Person (name ¼ “Sue”) IsAtSpatio-Temporal (location ¼ “on-campus”)
† C2: Person (name ¼ “Sue”) HasAPreference (availability (location ¼ “on campus”))
† C3: Person (name ¼ “Sue”) HasAPreference (day ¼ “Monday - Friday”))
† C4: Person (name ¼ “Sue”) HasAPreference (time ¼ “am”))
† C5: Person (name ¼ “Sue”) HasAStatusPerson (available ¼ “yes”)
† C6: Person (name ¼ “Sue”) HasAModule (module ¼ “Programming Languages”)
† C7: Person (name ¼ “Sue”) HasAQualification (qualification ¼ “Prolog”)
† C8: “Sue” is available, is an appropriate adviser to
“Tom” and has a role of tutor
�ðB1 ^ B2 ^ B3Þ ) B4
��ððA1 ^ A2Þ ^ ðC1 ^ C2 ^ C3 ^ C4ÞÞ ) C5
��ðC5 ^ ðC6 _ C7ÞÞ ) C8
�
FIGURE 5. The semantic reasoning ontology.
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 199
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

A wireless device or RFID tag locates and identifies the user
and initiates event-driven (location change) context updating
and input (task/problem) tagging. The scenario sets out a
typical cooperative interaction with an example of context
reasoning. In the scenario spatio-temporal, activity, task, pre-
ference, status, qualification, module, and role context com-
ponents are identified.
Context reasoning with inference using the RDF property
values enables the availability of “Sue” and her suitability as
an adviser to the questioner “Tom” to be inferred based on
their situated roles. The ontology identifies the semantic
relationships based on the semantic links defined by context
properties and their associated values (e.g. location ¼
“library”) enabling reasoned decisions including disambigua-
tion and partial validation to be achieved.
The reasoning process demonstrates conjunctions (AND)
and disjunctions (OR). Implementation of ontologies has
been discussed in Section 7, decision trees (discussed in
Section 7.1) being proposed as a potential solution to enable
effective implementation in decision-centric context-aware
pervasive systems, decision tree induction needing both con-
junction(s) and disjunction(s).
5. RELATED RESEARCH
This paper has introduced Smart-Context and considered con-
textual computing, and context modelling. A goal of Smart-
Context is the ability to generalise to diverse domains,
systems and technologies. Achieving these aims requires an
effective and tractablesolution to
(i) Create and update context definitions
(ii) Enable adaptability
(iii) Enable intelligent context processing
(iv) Implement context in intelligent decision-centric
context-aware systems
To address (i), the class structure is encoded in RDF (dis-
cussed in Sections 4.4 and 4.5). RDF provides an adaptable,
portable and lightweight cross platform solution to context
definition in computer readable form [8] [32] [33] [34]. RDF
has been shown to function effectively in diverse domains,
systems and technologies developed using for example: (1)
Java technologies, (2) ASP, and (3) PHP [32]. This enables
RDF solutions to be used in diverse Internet and distributed
networked applications including [33]:
† Resource Description
† Site Maps
† Collaborative Services
† Content Rating
† Privacy Preferences
In addressing (ii), there exists considerable documented
research in the area of adaptability in context-aware mobile
systems, examples include:
† Mobile Adaptation with Multiple Representation
Approach as Educational Pedagogy [35]: addresses the
issue of web page level content adaptation providing
guidelines for content adaptation in e-learning and
mobile learning environments.
† The Cognitive Trait Model (CTM) for Persistent Student
Modelling [36]: provides a model to supplement
performance-based modelling of students enabling the
transference of relevant information (e.g. cognitive
resources) to similar domains.
† Supporting Learning in Context: Extending Learner-
Centered Design to the Development of Handheld Edu-
cational Software [37]: challenges to the development
of educational software for handheld devices are con-
sidered with the design of Pocket PiCoMap — a learner-
centred tool to support concept mapping activities on
handheld devices.
The research documented in [35] [37] principally targets the
provision of content, the CTM [36] focusing on an adaptable
approach to student modelling; the research considered in
Section 3.2 (generally) focuses on the use of location-based
context. The research identified while addressing contextual
computing issues is limited in scope and fails to address the
requirements of intelligent context and the specific demands
of the Smart-Context concept.
5.1. Intelligent context
To address (iii), RDF in facilitating the description of web
resources in computer readable form has been shown to
enable automated decisions using processing rules [33], a
context definition is an example of a set of processing rules
[5] [8]. Semantic rules form an important element in intelli-
gent systems employing inference and reasoning. The Seman-
tic Web enables the creation of rules with inference and
reasoning, the issue that requires addressing is the implemen-
tation of intelligent context.
In considering (iv) (implementation issues are discussed in
Section 7), research addressing context modelling in intelli-
gent systems generally employs a machine learning approach
using either supervised or unsupervised learning. Flanagan
[16] in addressing personalisation and ontology proposes
unsupervised learning as an alternative to ontologies.
Flanagan [16] recognises the obvious advantages of ontology
however it is argued that ontology is a major barrier to
personalisation. A further potential issue identified is the
provision of a stored context, a system prerequisite for the
Smart-Context system (discussed in Section 3.1).
An abstract context model for an intelligent environment is
proposed in [24], a supervised learning approach using the ID3
200 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

decision tree algorithm being used. The environment, its
occupants and their activities are represented by a model (in
the form of a situation network) consisting of situations and
roles played by entities and their relationships. System ser-
vices (associated to the modelled situations) are adapted to
the changing needs of the user with supervisor feedback cor-
recting inappropriate system services. The proposed approach
is however semi-autonomous being essentially location-based,
issues for Smart-Context; the location-based focus is an issue
shared by other research considered.
5.2. Summary
The accepted advantages of ontology and OBM show that it is
a viable solution to provide an effective basis upon which (i),
(ii), and (iii) can be addressed, the issues relating less to the
concept of ontology than the approach adopted to enable
implementation. Considering (iv), decision trees (discussed
in Section 7.1) in a rule-based system are proposed as a poten-
tial solution to the implementation of context in intelligent
context-aware systems, the reported results achieved using
decision trees to create an abstract context model in an intel-
ligent environment [24] indicates that this approach represents
a potentially viable solution.
6. SIMULATION AND EVALUATION
The twin goals of Smart-Context are (1) to enable personalised
service provision and (2) to support cooperative computing.
To demonstrate these goals a simulation of the proposed
system based on two illustrative scenarios is presented. In
both scenarios location (in this case the library) forms an
important context component.
Section 6.1 presents the simulation, the evaluation process
is discussed in Section 6.2.
6.1. Simulation of Smart-Context
The following scenarios demonstrate the Smart-Context
process, the two scenarios reflecting typical system usage
based on users current context(s). The first scenario (Section
6.1.1) demonstrates automated resource provision. The
second scenario (Section 6.1.2) shows a cooperative inter-
action, the identification of an appropriately qualified individ-
ual user able to assist in the resolution of a problem is shown.
6.1.1. A personalised resource provision scenario
The first scenario describes a situation where the Smart-
Context system allocates a system input (the resource/
problem) to automatonomously identified appropriate recipi-
ents (the solution(s)) based on their context definition. The
identified users are contacted based on their situated role
and related preferences.
† Resources (in this case books on Java Programming) are
entered on the Smart-Context system with tags identify-
ing potential users. [Resource(type ¼ “book”), Module
(module ¼ “Java Programming”)]
† “Bob” is currently enrolled on the Java Programming
Module. [Person(“Bob”) HasA Module(module ¼
“Java Programming”)]
† “Bob” enters the library and a location-change-event is
triggered, the context processing (discussed in Section
3.1) updates the context to reflect the new location and
situated role. [Person(name ¼ “Bob”) IsAt Spatio-
Temporal(location ¼ “library”)] [Person(“Bob”) HasAModule(module ¼ “Java Programming”)]
† The agent in his PDA performs a handshakes with the
agent in context tag at the library. [Device(type ¼
“PDA”) IsAt Spatio-Temporal((location ¼ “library”),
(date ¼ “2006:27:11”), (time ¼ “11:47:39”))]
† After negotiation about trust, the agent in context tag pre-
sents some notices to him based on his registered
modules and sends Bob recommended books on Java
programming. [Resource(type ¼ “book”) IsA Preference
(preference ¼ “textMessage”)]
† “Bob” identifies a book (Java How To Program) and the
agent in the context tag sends the booking message to the
library information system after checking his library ID.
† The context tag receives the book ready message and
transfers to Bob. [Resource(type ¼ “book”) IsAPreference(preference ¼ “textMessage”)].
† “Bob” collects the book at the identified shelfmark.
Fig 6–8 show typical system output(s). Figure 6 shows the
welcome screen setting out the user name and location, the
news field notifies the user that there are messages (book rec-
ommendations). Figure 7 details the book recommendations.
FIGURE 6. Initial screen.
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 201
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

Figure 8 notifies the user “Bob” of the shelfmark where the
selected book can be found.
6.1.2. A cooperative computing scenario
The second scenario demonstrates a cooperative computing
example in which a question entered by the questioner (the
input) is tagged to enable the Smart-Context system to auton-
omously identify potential qualified adviser(s) (the output)
based on their context and situated role.
† “Bob” is working in the library investigating Java
programming. [Person(name ¼ “Bob”) IsAt Spatio-
Temporal(location ¼ “library”)] [Person(“Bob”) HasAModule(module ¼ “Java Programming”)].
† “Bob” is logged onto the Intranet. [Person(name ¼
“Bob”) HasA Activity(activity ¼ “on-line”)].
† “Bob” places a request on the Smart-Context system
asking for assistance. [Activity(activity ¼ “on-line”)
HasA Task(question(subject ¼ “Java”))].
† The system identifies “Lisa” (amongst other suitable
individuals) as a suitable contact (based on the values
in her context definition including enrolled course,
project, modules, interests and availability for consul-
tation). [Person(name ¼ “Lisa”) HasA Role(function ¼
“adviser”)].
† “Bob” is advised of the potential contacts with their
contact details.
† “Bob” selects Lisa and contacts her using a text message.
[Preference(preference ¼ “textMessage”)].
† “Bob” opens an on-line cooperative interaction with Lisa
to request assistance to resolve his query.
Figures 9 and 10 demonstrate typical system output(s).
Figure 9 shows the status of the user (“on-line”) and the
subject of the question entered onto the Smart-Context
system (the input/problem). Figure 10 shows the opening
contact made by “Bob” to “Lisa”(an output/solution). “Lisa”
is identified as a suitable qualified advisor based on her
context.
6.1.3. Observations
The two scenarios are related to the context reasoning scenario
discussed in Section 4.6. In actuality both scenarios require
that the context matching process in the context space as dis-
cussed in Section 7.2 (matching the resource/problem context
to potential solution context(s)) is implemented. The two scen-
arios demonstrate the use of spatio-temporal, preference and
qualifying (e.g. module) properties to enable context matching
and autonomous decision making in the context matching
process.
FIGURE 8. Selected book details.
FIGURE 7. Book recommendations.
FIGURE 9. User state/question.
202 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

6.2. Evaluation of smart-context
Evaluation of Smart-Context involves the use of a prototype
personalised mobile learning system using scenario-based
metrics based on predefined test data (investigation having
failed to identify a suitable existing corpus). Evaluating the
effectiveness entails comparing the results achieved during
the testing process (using a prototype personalised mobile
learning system) with the predefined test data.
Personalised service provision mapped to user-defined need
introduces the concept of relevance [11]. There is a correlation
between the concept of relevance and issues in search and
information retrieval. The recognised measures of the efficacy
of search and retrieval strategies are precision and recall, a
further measure is fall-out.
† Precision: is a measure of the number of relevant docu-
ments retrieved as measured against the relevant and
retrieved documents received.
† Recall: is a measure of the number of relevant documents
retrieved as measured against the total number of rel-
evant documents available.
† Fall-Out: is a measure of the probability of an irrelevant
document being retrieved as measured against actual
documents retrieved.
The results are expressed as a ratio (normalised to a value
of 1) or a percentage. To effectively evaluate Smart-Context,
evaluation metrics will be developed using the three identified
measures to enable quantitative evaluation upon which the
efficacy of system can be assessed.
Evaluating cooperative computing performance employs a
similar process, predefined test data (matched questioners
and adviser(s) contexts) compared to actual results define
the efficacy of the system.
7. IMPLEMENTATION ISSUES
Ontologies and OBM have been identified as an effective
approach to enable intelligent context. RDF/S with Jena [38]
provide a basis upon which data structures can be created
and updated [5] [32] [34], this however fails to enable
support for ontologies, inference and context reasoning. It
has been shown that the limitations of RDF and RDF
Schema [17] when extended using the OWL vocabulary can
address this issue and provide a basis for intelligent context
implementation. Creating an ontology does not however
address the issue of implementation, this requires the develop-
ment of a strategy which requires autonomous decision
making based on current (updated) context definitions. Ontol-
ogy implementation therefore reduces to a decision problem.
A decision problem is characterised as one of selecting from
a number of potential options based on the relationship
between the values that describe the input (resource or
query) and the solution (identified users). The modelling
school of decision analysis attempts to construct an explicit
model of such relationships, usually in the form of decision
trees [39].
7.1. Decision trees
Decision trees are types of directional graph employing
IF-THEN statements [40]. The inputs to a decision tree are a
set of attribute values (in this research context properties),
the output being Boolean (or multi-valued) decisions. Each
internal node in a decision tree tests the value of one of the
properties, the branches from the node being labelled with
the possible values resulting from the test. Each leaf node in
the tree specifies the value to be returned if the leaf is
reached [39] [40]. The output of the decision tree is derived
by testing attributes sequentially commencing at the root
node and following the branch labelled with the appropriate
value.
It is proposed that the implementation process will involve
the development of an intelligent context middleware to
implement the decision-making process using decision trees
to model the input and potential solution(s) and enable
context matching to arrive at a set of identified solutions
(users).
From a design perspective a potential issue when the use of
decision trees in a rule-based system is considered is the temp-
tation to apply an inappropriate solution to a problem. This
requires that the following question: Is a rule-based solution
implemented using decision trees a suitable option? be
addressed. The following parameters to test the suitability of
decision trees in a KBS as a potential approach have been
identified:
(i) Is human problem-solving knowledge being repli-
cated in the solution?
(ii) Is the problem-solving knowledge heuristic in nature?
FIGURE 10. Contact message.
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 203
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

(iii) Does the knowledge (or expertise) periodically
change?
(iv) If expertise is involved, is the expertise fairly well
understood and accepted?
(v) Is the problem well understood?
(vi) Are the input data always complete and correct?
(vii) Can the problem be (better) solved by conventional
database or programming solutions?
(viii) Does it pass the telephone test? (this test asks whether an
expert, by speaking with someone over the telephone,
can gather sufficient information to solve the problem)
(ix) Is the decision making process merely the matching of
data? (or are rules applied in the decision making
process)
(x) Is speed of operation a prime requisite for the system?
(a rule-based KBS is arguably slower at runtime than
conventional programming solutions)
(xi) Are partial solutions acceptable solutions to the identi-
fication of individuals?
The design parameters i to viii are derived from [40], par-
ameters ix, x and xi represent three further design consider-
ations relevant to the problem under investigation. A
comprehensive discussion on the design and engineering of
knowledge-based systems can be found in [40], however, in
summary a positive response to parameters [i, ii, iii, iv, v,
viii and xi] indicates that a rule-based system does potentially
provide an effective solution. A positive response to par-
ameters [vi, vii, ix and x] however implies that a rule-based
KBS is not potentially a suitable solution.
Applying the design parameters to the problem under inves-
tigation indicates that a rule-based system implemented using
decision trees does potentially provide an effective basis for
constructing a context-aware decision-making system. Such
a system requires sufficient computational intelligence (dis-
cussed in Section 2), to achieve this it is proposed to use a
semantic context ontology (see Sections 2.2 and 4.6)
implemented in an intelligent context-aware system.
Intelligent systems can be viewed as a cooperative of intel-
ligent agents that perceive and act in an environment [41].
Agents can be considered intelligent relative to the degree to
which their actions are successful.
Ontologies are constructed using a number of entity con-
texts (sub-contexts). To effectively process the information
contained in each entity context, it is envisaged that a
number of agents will be employed working in concert in a
context-aware multi-agent system, each agent (sub-system)
being responsible for a specific function such as location
sensing, resource formatting and so on.
7.2. Context middleware
The Context middleware is responsible for the creation,
storage, updating, retrieval and implementation of context(s).
The context middleware must enable a number of key
functions but before we consider the functions the context
middleware is designed to fulfil the notion of context space
[10] must be introduced.
Context space defines the complete set of entity contexts
that make up the overall stored context. The context space
can be viewed in terms of a database made up of past,
current and future contexts (as discussed in Section 3.1) pro-
viding the capability to manage context(s). Based on the
context space, the context middleware must enable the follow-
ing functionalities:
† basic operations (e.g. create, update, delete, search, get
and implement)
† advanced functions (e.g. context matching [10] with
support for context reasoning)
An example of context matching is a typical trouble-
shooting scenario in which a context that defines the ques-
tioner’s situated role (the problem) is matched to that of a
suitably qualified adviser (a solution). In a matching procedure
the questioner and adviser contexts are presented as inputs into
a context space, the context matching agent analysing context
pair(s) based on a set of rules in a rule-based system.
The result will be the production of a signal by the context
matching agent to show the potential suitability of a matched
context pair. This is an example of the decision-making
system in operation. In practice the context middleware is a
Java package based on the Jena RDF API which can be
called by other layers within the application.
8. CONCLUSIONS AND FUTURE WORK
This paper has introduced the Smart-Context concept; context
modelling has been considered with issues related to intelli-
gent context in decision-centric context-aware systems.
Decision trees in rule-based systems have been discussed
with ontologies, the Semantic Web, inference and reasoning.
A semantic context reasoning ontology has been presented
with a simulation and evaluation using personalised service
provision and cooperative computing scenarios.
Context is made up of a number of context types including
personal, task, role, spatio-temporal, and awareness. The
awareness context includes activity, state, social and process
awareness [10]. Process-awareness has been identified as a
pivotal component in intelligent context-aware systems. An
overall context is made up of sub-contexts representing enti-
ties to enable the creation of (static and dynamic) contexts.
It has been shown that context definitions can be effectively
created using the Semantic Web technologies, ontology-based
context modelling (OBM) providing a basis upon which effec-
tive implementation can be realised.
Context modelling (discussed in Section 3) is pivotal to effec-
tive context matching in the context space (discussed in Section
204 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

7.2), demanding the modelling of both the solution and problem
spaces within the overall context space. Given that perfect
matches are highly unlikely, an approach enabling partial vali-
dation is important. Context modelling, whilst providing a
basis upon which intelligent context can be realised fails to
address the issue of implementation in intelligent systems.
A review of current contextual computing research identi-
fied has concluded that the demands of intelligent context
implementation are not addressed. To address this issue
decision trees in a rule-based approach are proposed in this
paper, the parametric analysis set out in Section 7.1 showing
that decision trees do represent a good potential solution in a
decision-centric context-aware systems. The work of Brdiczka
et al. [24] has demonstrated that decision tree induction using
the ID3 algorithm is an effective potential solution however
the limited scope of their system does not fully address the
needs of intelligent context implementation as envisaged for
the Smart-Context concept.
There are a number of approaches in the literature that
address the issue of decision tree induction including purely
statistical approaches and evolutionary systems. These
approaches also fail to meet the demands of the Smart-Context
concept. These observations raise a number of significant
research questions:
† There is an apparent synergy between the tree structure
that is a feature of both the Semantic Web technologies
and decision trees. Can this apparent synergy be har-
nessed to enable effective implementation?
† What contribution can decision tree induction using
machine learning (supervised and unsupervised) make
to realising intelligent context implementation?
† Do decision trees in rule-based systems (implemented in
intelligent multi-agent context middleware) represent an
effective approach?
† What contribution can logic-based context modelling
make to the implementation of intelligent context?
† Context is complex and often ambiguous, can fuzzy
logic, fuzzy sets, or rough sets contribute to resolution
of such issues in intelligent context-aware systems?
† “Neural network [learning] methods provide a robust
approach to approximating real-valued, discrete-valued,
and vector-valued target functions . . . it [ANN learning]
is also applicable to problems for which more symbolic
representations are often used, such as decision tree
learning” [42]. Given the observations of Mitchell
[42], do artificial neural networks provide an effective
basis upon which implementation of intelligent context
can be achieved?
† Given that IF-THEN statements exist in all high-level
programming languages, can the use of such approaches
including database solutions using relational database
systems (a capability enabled in Jena) provide an effec-
tive solution?
† Will evolutionary systems (ES) provide a better approach
than rule-based systems or traditional high-level pro-
gramming approaches?
† Will the optimum solution be a hybrid approach [43] that
exploits the global perspective of ES with the conver-
gence of traditional problem-specific search techniques?
A principal aim of the research is the development of a
generic system incorporating interoperability, the system
being capable of implementing intelligent context in diverse
domains, systems and technologies. Addressing the research
questions and resolving the issues identified with the develop-
ment of an implementation strategy to implement the Smart-
Context concept discussed in this paper to realise the design
goals forms the basis of future work.
REFERENCES
[1] GIT-GVU-99-22 (1999) Towards a Better Understanding of
Context and Context Awareness. Georgia Institute of
Technology, USA.
[2] Gorlenko, L. and Merrick, R. (2003) No wires attached:
usability challenges in the connected mobile world. IBM Syst.
J., 42, 639–651.
[3] Ray, K. and Kurkovsky, S. (2003) A Survey of Intelligent
Pervasive Computing. Proc. ICAI’03, Las Vegas, NV, June
23–26, pp. 30–35. CSREA Press, USA.
[4] Saha, D. and Mukherjee, A. (2003) Pervasive computing: a
paradigm for the 21st century. Perspectives, March, 25–31.
[5] Moore, P. and Hu, B. (2006) Entity Profiling: Context with
Ontology. Proc. SPCA 2006, Urumqi, Xinjiang, P.R. China,
August 3–5, pp. 172–177. IEEE Press, USA.
[6] Rao, A.S. and Georgeff, M.P. (1995) BDI Agents: From Theory
to Practice. Proc. First Int. Conf. Multi-Agent Systems
IMCAS-95, San Francisco, USA, June, pp. 312–319. The MIT
Press, USA.
[7] Dourish, P. (2004) What we talk about when we talk about
context. Pers. Ubiquitous Comput., 8, 19–30.
[8] Moore, P. and Hu, B. (2006) A Context Framework for Entity
Identification for the Personalisation of Learning in Pedagogic
Systems. Proc. CSCWD 2006, Nanjing P.R. China, May 3–5,
pp. 1381–1386. IEEE Press, USA.
[9] Lonsdale, P., Barber, C., Sharples, M. and Arvanitis, T.N. (2003)
A Context Awareness Architecture for Facilitating Mobile
Learning. Proc. MLEARN 2003, London, UK, May 19–20,
pp. 79–85. Learning and Skills Development Agency, London.
[10] Hu, B. and Moore, P. (2005) A Context Framework Supporting
Contextual and Cooperative Learning. Proc. IADIS Int. Conf.
Mobile Learning 2005, Quara, Malta, June, pp. 236–240.
IADIS, Portugal.
[11] Coppola, P. and Della, M.A. (2004) The concept of relevance in
mobile and ubiquitous access. Mobile and Ubiquitous Info.,
LNCS 2954, pp. 1–10.
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 205
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from

[12] Kaasinen, E. (2003) User needs for location-aware mobile
services. Pers. Ubiquitous Comput., 7, 70–79.
[13] Gruber, T.R. (1995) Toward principles for the design of
ontologies used for knowledge sharing. Int. J. Human–
Comput. Stud., 43, 907–928.
[14] Russel, S. and Norvig, P. (1995) Artificial Intelligence, a
Modern Approach. Prentice-Hall, NJ, USA.
[15] Middleton, S.E., Shadbolt, N.R. and Roure, D.C. (2004).
Ontological user profiling in recommender systems. ACM
Trans. Inf. Syst., 22, 54–88.
[16] Flanagan, J.A. (2005) Context awareness in a mobile device:
ontologies versus unsuper-vised/supervised learning. http://
www.cis.hut.fi/AKRR05/papers/.
[17] Antoniou, G. and Van Harmelen, F. (2003). Web Ontology
Language: OWL. In Staab, S. and Struder, R. (eds),
Handbook on Ontologies, Springer, Germany.
[18] Baader, F., Calvanese, T.D., McGuinness, D.L., Nardi, D.
and Patel-Schneider, P.F. (eds) (2003) The Description Logic
Handbook: Theory, Implementation, Applications. Cambridge
University Press, Cambridge, UK.
[19] Berners-Lee, T. (1998). Semantic web roadmap. http://www.w3.
org/DesignIssues/Semantic.html.
[20] Horrocks, I. (2007). Semantic Web: The Story So Far. Proc.
2007 Int. Cross-Disciplinary Conf. Web Accessibility
(W4A2007), Banff, Canada, May 7–8, pp. 225. 120–125.
ACM Press, NY, USA.
[21] Marsh, P. (2004) A Web of meaning. IEE Comput. Control
Eng., April/May 10–15.
[22] Geroimenko, V. and Chen, C. (2002) Visualising the Semantic
Web. Springer, Berlin, Germany.
[23] Strang, T. and Linnhoff–-Popien, C. (2003) A Context
Modeling Survey. Proc. UbiComp 2004, Nottingham, UK,
September 7–10, pp. 34–41. ACM Press, USA.
[24] Brdiczka, O., Reignier, P. and Crowley, J.L. (2005). Supervised
Learning of an Abstract Context Model for an
Intelligent Environment. Proc. Joint sOc-EUSAI conf. 2005,
Grenoble, France, October 12–14, pp. 259–264. ACM Press,
NY, USA.
[25] Ejigu, D., Scuturici, M. and Brunie, L. (2007) An
Ontology-based Approach to Context Modelling
and Reasoning in Pervasive Computing. Proc.
PerComW’07, White Plains, NY, USA, March 19–23,
pp. 14–19. IEEE, USA.
[26] Poslad, S., Laamanen, H., Malaka, R., Nick, A., Buckle, P.
and Zipf, A. (2001) CRUMPET: Creation of User-friendly
Mobile Services Personalised for Tourism. Proc. 3G 2001,
London, UK, March 26–28. IEE, UK.
[27] Abowd, G.D., Atkeson, C.G., Hong, J., Long, S., Kooper, R.
and Pinkerton, M. (1997) Cyberguide: a mobile context-aware
tour guide. Wirel. Netw., 3, 421–433.
[28] Chen, G. and Kotz, D. (2002) Solar: An Open Platform for
Contextaware Mobile Applications. Proc. First Int. Conf.
Pervasive Computing (Short paper), Zurich, Switzerland,
August 26–28, pp. 41–47. Springer, Berlin, Germany.
[29] Ferscia, A. et al. (2004) Context Awareness for Group
Interaction Support. Proc. MobiWac’04, Philadelphia, PA,
USA, October 1, pp. 88–97. ACM Press, USA.
[30] Korkea-aho, M. (2000). Context-aware applications survey.
http://users.tkk.fi/mkoreaa/context-aware.html#
[31] Robson, C. (2002) Real World Research (2nd edn). Blackwell,
Mass, USA.
[32] W3c. (2006). Resource Description Framework (RDF).
Available: http://www.w3.org/RDF/
[33] Ianella, R. (1999) An idiot’s guide to the resource description
framework. The New Rev. Inf. Netw., 4. Available: http://
archive.dstc.edu.au/RDU/reports/RDF-Idiot/
[34] McBride, B. (2006) An introduction to RDF and the Jena RDF
API. Available: http://jena.sourceforge.net/RDF_API/
[35] Kinshuk and Goh, T.T. (2003) Mobile Adaptation with Multiple
Representation as Educational Pedagogy. Wirtschaftsinformatik
2003, Dresden, Germany, September 17–19, pp. 747–763.
Physica, Heidelberg, Germany.
[36] Lin, T. Kinshuk. and Patel, A. (2003) Cognitive Trait Model for
Persistent Student Modelling. Proc. EdMedia 2003,
Honolulu, Hawai, USA, June 23–24, pp. 2114–2147. AACE,
Norfolk, VA, USA.
[37] Luchini, K., Curtis, M., Quintana, C. and Soloway, E. (2002)
Supporting Learning in Context: Extending Learner-Centered
Design to the Development of Handheld Educational
Software. Proc. WMTE 2002, Vaxjo, Sweden, August 29–39,
pp. 107–111. IEEE, USA.
[38] Jena. Jena-A semantic web framework for java. Available:
http://jena.sourceforge.net/index.html
[39] Graham, I. and Jones, P.L. (1998) Expert Systems
Knowledge, Uncertainty and Decision. Chapman and hall,
New York, USA.
[40] Gonzales, A.J. and Dankel, D.D. Dankel. (1993) The
Engineering of Knowledge-Based Systems Theory and
Practice. Prentice-Hall, New Jersey, USA.
[41] Boden, M.A. (1996) Artificial Intelligence. Academic Press,
London.
[42] Mitchell, T.M. (1997) Machine Learning. McGraw-Hill,
London, UK.
[43] Goldberg, D.E. (1989) Genetic Algorithms in Search, Optimisation
and Machine Learning. Addison Wesley Longman, Canada.
9. APPENDIX
Figure A1 presents a screen shot showing sample sections of
the (4 page) questionnaire used in the evaluation process.
The Questionnaire initially identified the respondent as
either a student or tutor, the data being analysed using the
data derived from the questionnaire for the overall sample
with comparisons drawn for student and tutor groups of
respondents.
The evaluation compared the results obtained from the
questionnaire data with the data obtained from the semi-
structured interviews. The context factor identification
206 P. MOORE et al.
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from
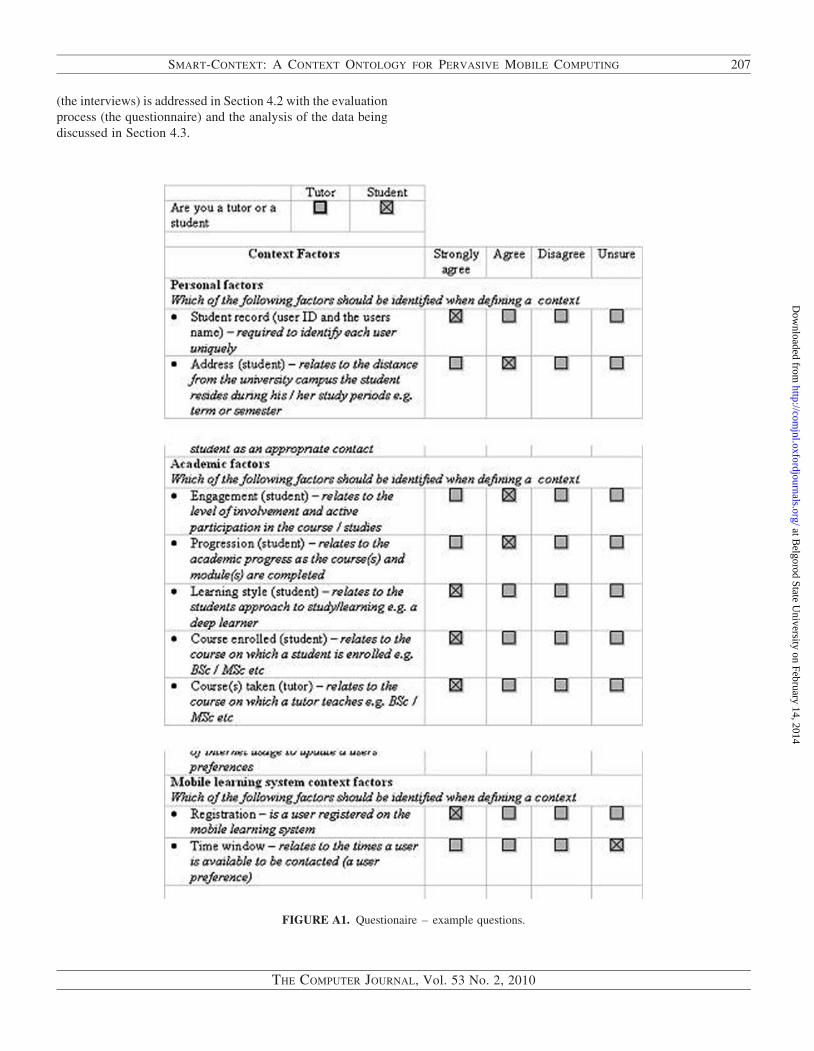
(the interviews) is addressed in Section 4.2 with the evaluation
process (the questionnaire) and the analysis of the data being
discussed in Section 4.3.
FIGURE A1. Questionaire – example questions.
SMART-CONTEXT: A CONTEXT ONTOLOGY FOR PERVASIVE MOBILE COMPUTING 207
THE COMPUTER JOURNAL, Vol. 53 No. 2, 2010
at Belgorod State U
niversity on February 14, 2014http://com
jnl.oxfordjournals.org/D
ownloaded from







