
Social Assistance Pilots Program
SA Pilots Seminar
Hybrid Means Testing (HMT) Model Development
Roman SemkoCASE Ukraine
March, 2010

1.1. Introduction to modelingIntroduction to modeling
2.2. Data analysisData analysis
3.3. Methods for estimationMethods for estimation
4.4. SimulationsSimulations
5.5. Income from assets (agriculture)Income from assets (agriculture)
6.6. Double-blind experiment resultsDouble-blind experiment results
7.7. Model comparisons and conclusionsModel comparisons and conclusions
ContentContent
2

ConceptConcept
3
• The World Bank has developed a methodology for income estimation The World Bank has developed a methodology for income estimation which is based on regression analysis – HYBRID MEANS TESTING which is based on regression analysis – HYBRID MEANS TESTING (HMT)(HMT)
• Under HTM method, eligibility to the SA program is assessed based Under HTM method, eligibility to the SA program is assessed based on the households income modelingon the households income modeling
• Total income is divided into two parts: easy to verify (e.g., pension, Total income is divided into two parts: easy to verify (e.g., pension, stipend) and hardstipend) and hard toto verify (e.g., dividends, shadow wage)verify (e.g., dividends, shadow wage)
• The final goal is to estimate hard to verify share of the income based The final goal is to estimate hard to verify share of the income based on a set of variables, which can be accurately measured and reflect on a set of variables, which can be accurately measured and reflect the hard to verify incomethe hard to verify income
• Hard to verify income is divided into income which is not generated Hard to verify income is divided into income which is not generated by long-term assets (estimated by regression model) and income by long-term assets (estimated by regression model) and income from assets (estimated by formulas)from assets (estimated by formulas)
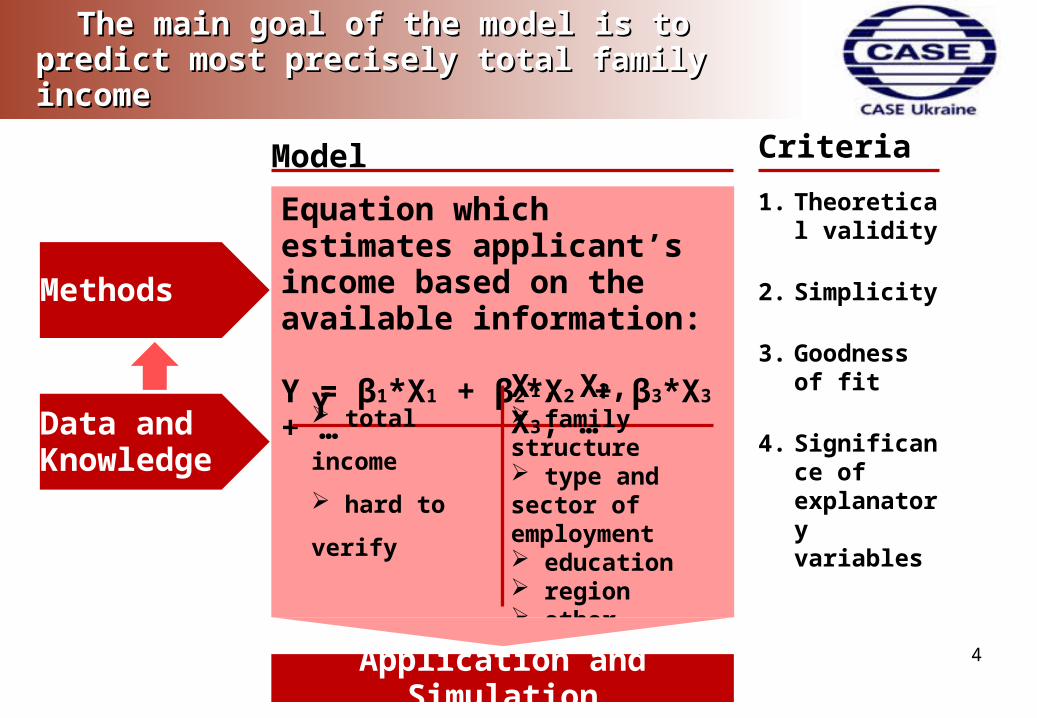
The main goal of the model is to predict most The main goal of the model is to predict most precisely total family incomeprecisely total family income
Source: Finance Ministry of Ukraine
Data and Knowledge
Methods
Equation which estimates applicant’s income based on the available information:
Y = β1*X1 + β2*X2 + β3*X3 + …
Y X1, X2, X3, …
total income
hard to verify
family structure type and sector of employment education region other
Model Criteria
1. Theoretical validity
2. Simplicity
3. Goodness of fit
4. Significance of explanatory variables
Application and Simulation4

Pilots datasetHBS 2008
Good model should use all available relevant Good model should use all available relevant information for income predictioninformation for income prediction
5
10,622 observations of households with total income
• > 3,000 observations of families with declared income• Cannot be used separately for model estimation since total income is not available
A lot of information could/should be used to guarantee acceptable level of precision
Declared income (DI) is an important indicator in total income (TI) assessment
MATCHING
CharacteristicsTI
CharacteristicsTI DI
Characteristics DI

Pilots datasetHBS 2008
Observations are matched in a way to guarantee Observations are matched in a way to guarantee the highest similarity between themthe highest similarity between them
6
Procedure1. Form groups based on the follow-ing variables: type of settlement, type of assistance, household’s size, # of children, working persons, pensioners, sex of the single-heads household2. Match each observations from HBS to the observation from pilots dataset from the same groups based on the similar characteristics: age of the head, education of the head, etc. using Euclidean distance function3. Each observation from pilots dataset is used for matching no more than 2 times4. Aggregate the groups if there are no good candidate for HBS observation from corresponding group from pilots dataset and match again
Observation 1Observation …Observation K1
Group 1
Observation 1Observation …Observation K…
Group …
Observation 1Observation …Observation KN
Group N
Observation 1Observation …Observation L1
Group 1
Observation 1Observation …Observation L…
Group …
Observation 1Observation …Observation LN
Group N
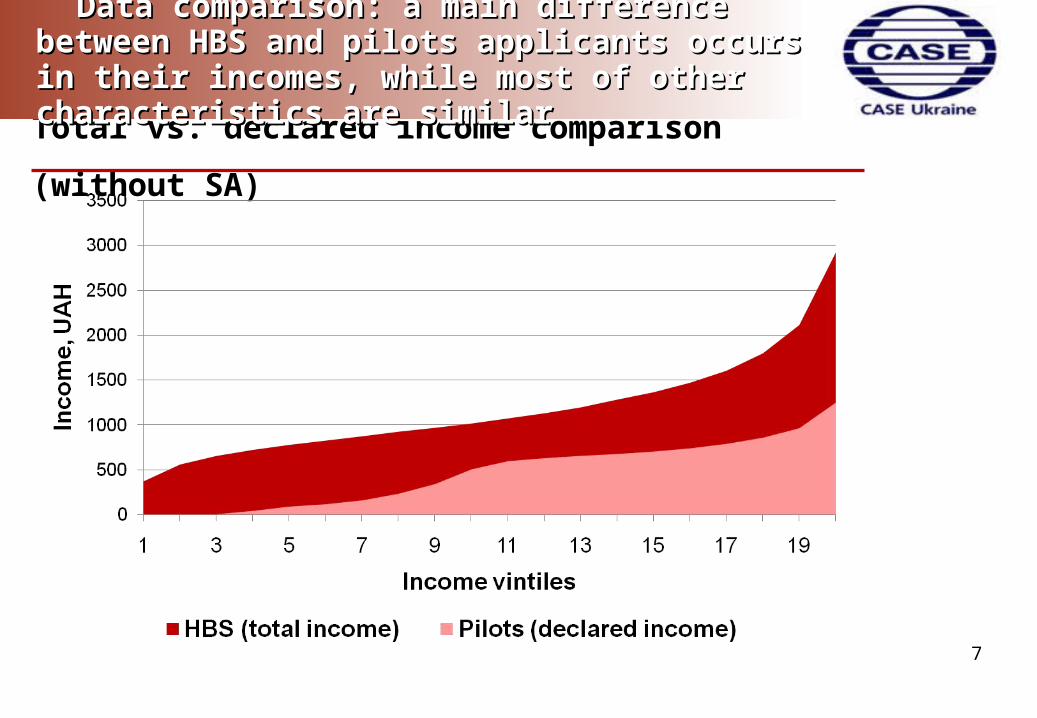
Total vs. declared income comparison (without SA)
Data comparison: a main difference between HBS Data comparison: a main difference between HBS and pilots applicants occurs in their incomes, and pilots applicants occurs in their incomes, while most of other characteristics are similarwhile most of other characteristics are similar
7
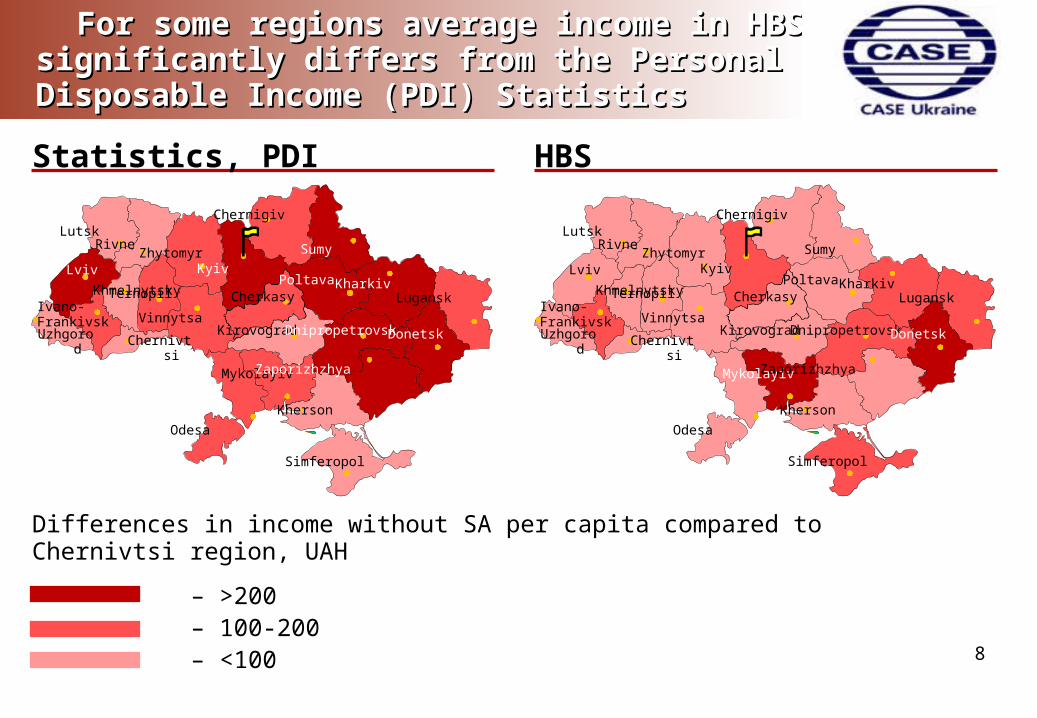
For some regions average income in HBS For some regions average income in HBS significantly differs from the Personal Disposable significantly differs from the Personal Disposable Income (PDI) StatisticsIncome (PDI) Statistics
8
Statistics, PDI HBS
Lviv
LutskRivne
Ternopil Ivano-
Frankivsk Uzhgorod
Chernivtsi
Vinnytsa
Zhytomyr
Chernigiv
Sumy
Kharkiv
PoltavaCherkasy
Kirovograd
Odesa
Kherson
Mykolayiv
Zaporizhzhya
Dnipropetrovsk
Lugansk
Donetsk
Simferopol
Kyiv
Khmelnytsky
Differences in income without SA per capita compared to Chernivtsi region, UAH
– >200 – 100-200 – <100
Lviv
LutskRivne
Ternopil Ivano-
Frankivsk Uzhgorod
Chernivtsi
Vinnytsa
Zhytomyr
Chernigiv
Sumy
Kharkiv
PoltavaCherkasy
Kirovograd
Odesa
Kherson
Mykolayiv
Zaporizhzhya
Dnipropetrovsk
Lugansk
Donetsk
Simferopol
Kyiv
Khmelnytsky

Bayesian econometrics allows combining data Bayesian econometrics allows combining data with aggregated publications of regional PDIwith aggregated publications of regional PDI
9
Standard estimation
Bayesian estimation
Calibration
Researcher artificially determines the model coefficient(s), e.g., if regional macrodata say that income in Kyiv city is 1108 UAH higher than in AR of Crimea, than it is assumed that for Kyiv city applicants income is 1108 UAH higher than for AR of Crimea applicants, other things equal
Coefficients are determined based on the collected observations using standard regression tools (classical econometrics)
Combines both approaches. Estimated coefficient lies between calibrated and estimated in a standard way
Does not lead to significant changes within regions but for regions across Ukraine changes are significant: average predicted income for regions has changes

Linear model is the most simpleLinear model is the most simple
Linear
Des
crip
tion
R2
Pre
dict
ions
58 % (large cities – 65%, small cities – 63%, villages – 48%)
• Linear relation between income and family characteristics• Dependent variable is under the logarithm (log-linear)• Independent variables (IVs) include easy to verify income• Other IVs are: number of children, of working persons, of the elderly, type and sector of employments of household heads, education level
– declared income – predicted income
Concept: the more income the applicant declares, the lower the additional predicted income is – a sort of a “zero sum game”
10
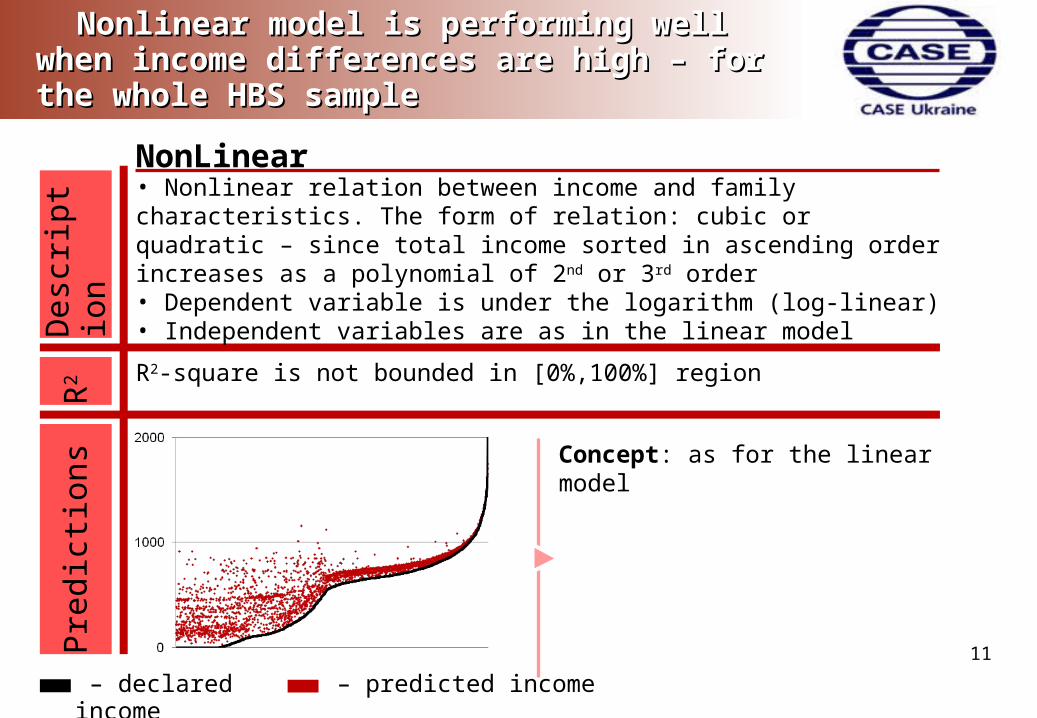
Nonlinear model is performing well when income Nonlinear model is performing well when income differences are high – for the whole HBS sampledifferences are high – for the whole HBS sample
NonLinear
Des
crip
tion
R2
Pre
dict
ions
R2-square is not bounded in [0%,100%] region
• Nonlinear relation between income and family characteristics. The form of relation: cubic or quadratic – since total income sorted in ascending order increases as a polynomial of 2nd or 3rd order• Dependent variable is under the logarithm (log-linear)• Independent variables are as in the linear model
– declared income – predicted income
Concept: as for the linear model
11

Two-step model is effective when there is a large Two-step model is effective when there is a large number of families with zero and nonzero hard to number of families with zero and nonzero hard to verify incomesverify incomes
Two-stage
Des
crip
tion
R2
Pre
dict
ions
47 % (no division by cities)
• At first stage probability that family has shadow income is estimated and then linear relations between income and family characteristics with a hazard of having shadow income is used for estimation • Dependent variable is under the logarithm (log-linear) and does not include salary
– declared income – predicted income
Concept: Stable additional income is added to the declared – “the game with constant markup”.
12

1. DEPENDENT VARIABLE
Informal (shadow) salary was incorporated into the dependent variable (hard to verify income) since it is not easy to verify income
Each model needs a set of adjustments in order Each model needs a set of adjustments in order to become fully usefulto become fully useful
13
Adjustments
3. TIME INCONSISTENCIES
In order to compare incomes across different time period, average growth rates of PDI and its elements were used for time adjustment
2. EXPLANATORY VARIABLES (EVs)
Some EVs which can be used for predictions are hard to verify, e.g., number of mobile phones cannot be accurately measured
4. FAMILY HEADS
The definitions of family heads are standar-dized: male co-head and female co-head are used instead of voluntary definitions
Prediction does not change significantly unless dependent variable is redefined. If the dependent variable is redefined, additional predicted income becomes more stable and decreases with the increase of declared income at a lower rate
Description

Average predicted income exceeds declared by Average predicted income exceeds declared by 2626%%
14
Declared vs. Predicted income (by models)

2727% families will be excluded from the SA % families will be excluded from the SA programsprograms
15
Number of beneficiaries (hypothetical scenario)
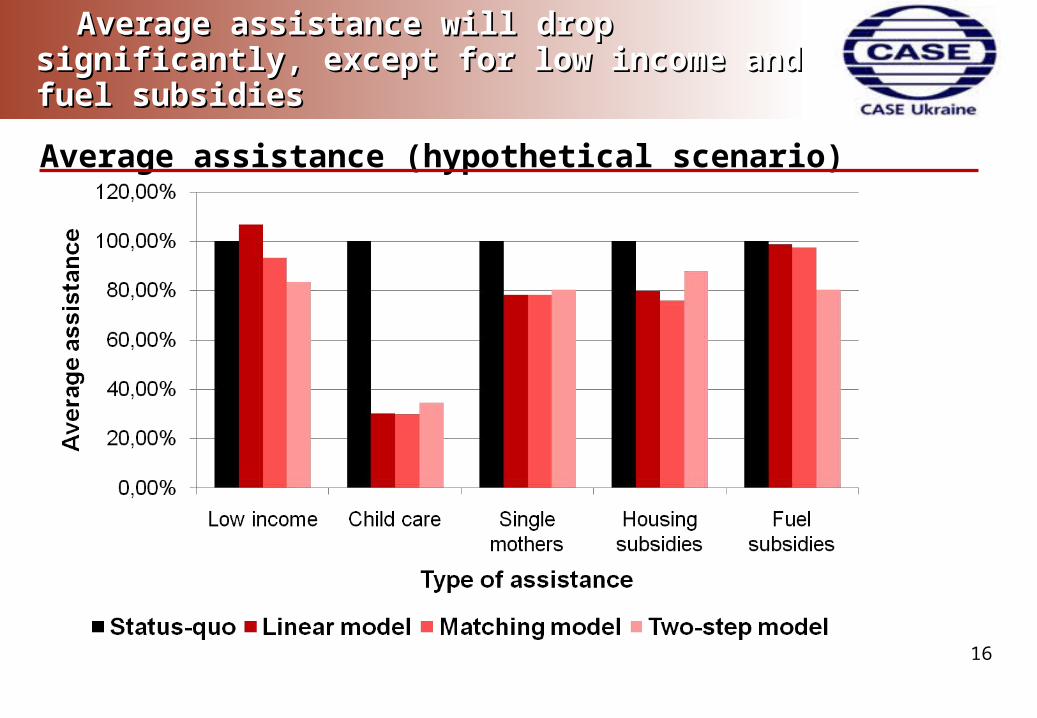
Average assistance will drop significantly, except Average assistance will drop significantly, except for low income and fuel subsidiesfor low income and fuel subsidies
16
Average assistance (hypothetical scenario)
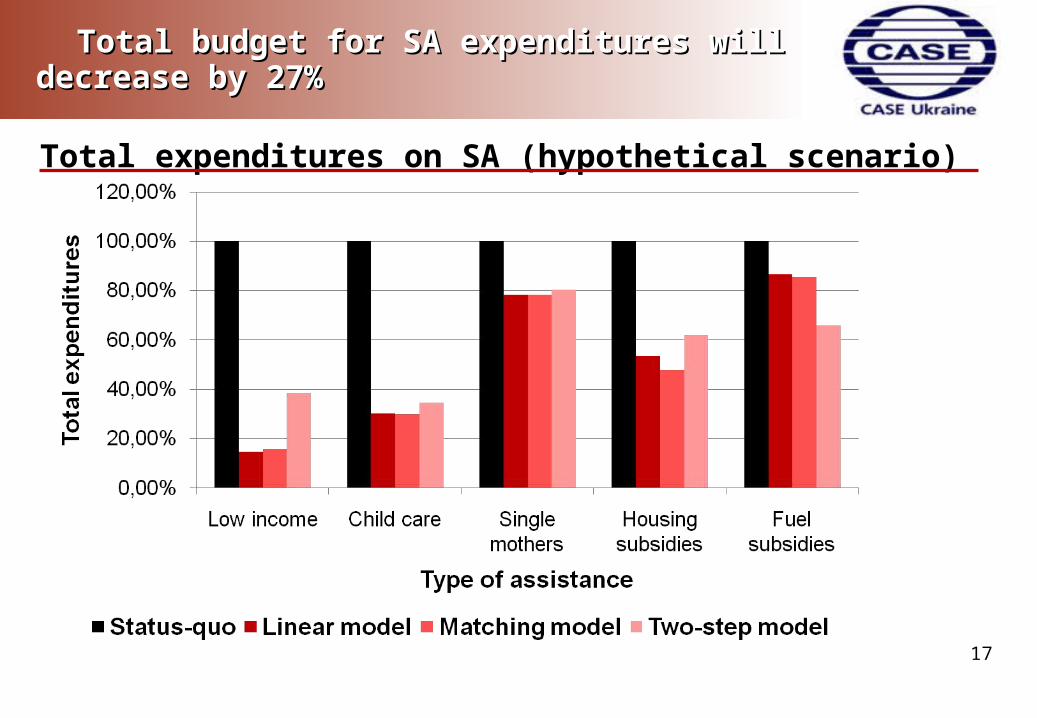
Total budget for SA expenditures will decrease by Total budget for SA expenditures will decrease by 27%27%
17
Total expenditures on SA (hypothetical scenario)

New approachCurrent situation
Income from agriculture assets is calculated Income from agriculture assets is calculated based on the developed normativesbased on the developed normatives
18
• Agriculture income is calculated as income per hectar• Normatives are not unified across regions
• Income calculation per hectar and per each animal• Differentiation between cities and villages• Normatives are unified since they are based on the same methodology and data
Calculation procedureInformation, certified by the village/city council
Is not applied to families with disable persons or elderly (>70)
If applicant lives closer than 10 km to the city – apply city normatives
Income from land is a product of land area and normatives
Income from payi is calculated sepatately
Income from lifestock is the product of number of livestock heads times the normative
Average predicted income exceed declared by 28%

New
ap
pro
ach
Cu
rren
t si
tuat
ion
Example of income calculation from agricultureExample of income calculation from agriculture
19
NORMATIVELAND AREA NORMATIVEANIMALS AGROINCOME
CROPS ANIMALS
Only farm-stead area of 0.56 hectars, located in village (Donetsk region)
127.62 per hectar per month
Possess one cow and 10 chickens
Only related through the hayfields and pasturage
Only farm-stead area of 0.56 hectars, located in village (Donetsk region)
412.44 per hectar per month
Possess one cow and 10 chickens (the same)
270.83 for cow, and 4.48 for one chicken
+ 63.81 UAH per month
+ 521.85 UAH per month
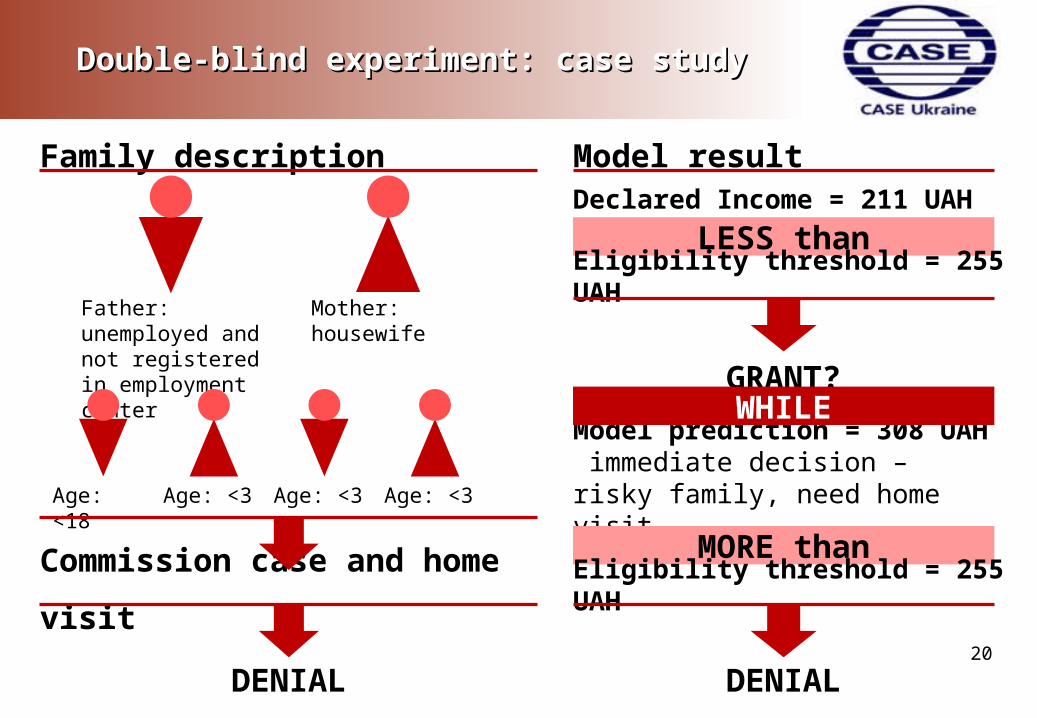
Declared Income = 211 UAH
Double-blind experiment: case studyDouble-blind experiment: case study
20
Family description
Father: unemployed and not registered in employment center
Mother: housewife
Age: <18 Age: <3 Age: <3 Age: <3
Commission case and home visit
DENIAL
Model result
LESS thanEligibility threshold = 255 UAH
Model prediction = 308 UAH immediate decision – risky family, need home visit
GRANT?WHILE
MORE thanEligibility threshold = 255 UAH
DENIAL

Cases of SA denials through commission, based Cases of SA denials through commission, based on home inspectionson home inspections
21
Type of assistanceDeclared income
Predicted income
Absolute difference
Relative difference
UAH UAH UAH %Low income 9 133 124 1320Low income 211 308 97 46Low income 264 344 80 30Child care 10 133 123 1238Child care 12 127 114 931Child care 209 286 77 37Child care 250 327 77 31Child care 260 365 105 40Child care 273 330 56 21Single mothers 0 68 68 -Single mothers 222 291 69 31
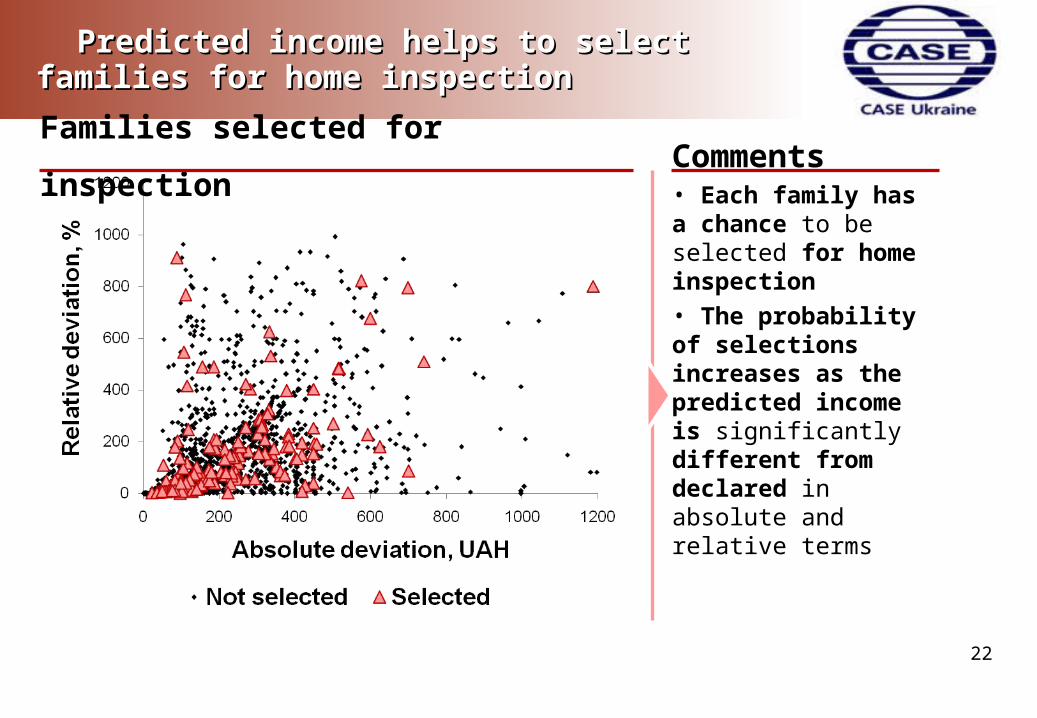
Predicted income helps to select families for Predicted income helps to select families for home inspectionhome inspection
22
Families selected for inspection Comments• Each family has a chance to be selected for home inspection
• The probability of selections increases as the predicted income is significantly different from declared in absolute and relative terms
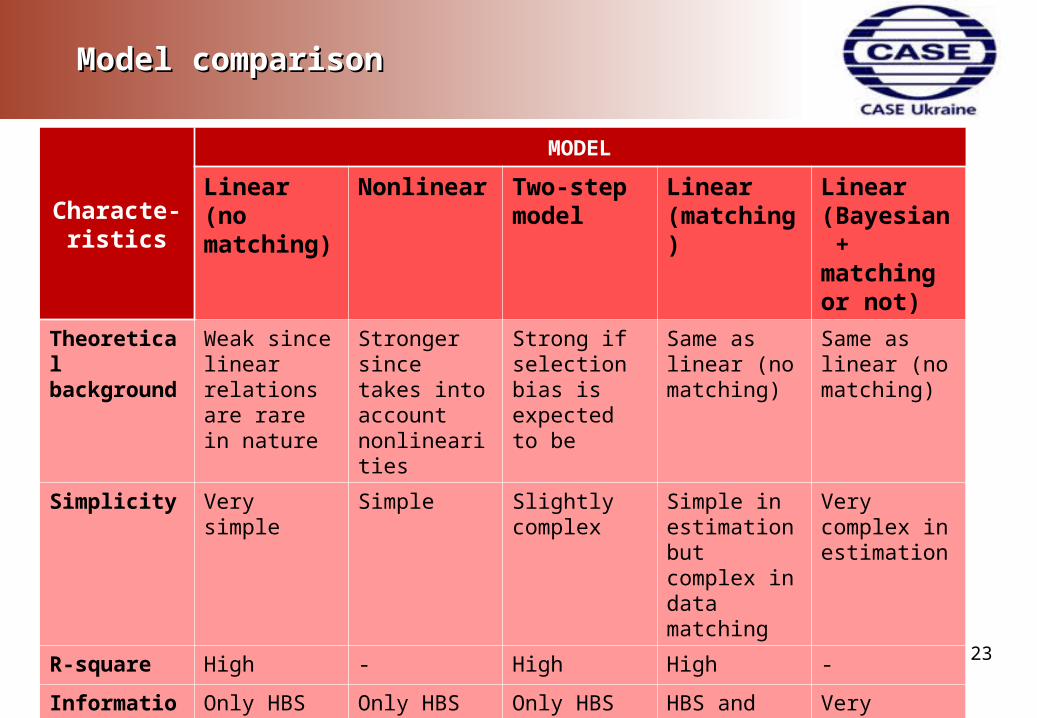
Model comparisonModel comparison
23
Characte-ristics
MODEL
Linear (no matching)
Nonlinear Two-step model
Linear (matching)
Linear (Bayesian + matching or not)
Theoretical background
Weak since linear relations are rare in nature
Stronger since takes into account nonlinearities
Strong if selection bias is expected to be
Same as linear (no matching)
Same as linear (no matching)
Simplicity Very simple Simple Slightly complex
Simple in estimation but complex in data matching
Very complex in estimation
R-square High - High High -
Information as an input
Only HBS Only HBS Only HBS HBS and pilots dataset
Very effective use of information
Influence on applicant
High High Medium High High

ConclusionsConclusions
24
Income estimates generated by the models significantly differ from the incomes declared by the SA applicants
Further empirical tests with the models are needed
Initially model results should be used only as an advice rather than a criterion for granting SA benefits
The models may be used as an instrument for selecting families for home inspections4
3
2
1







