
Speech Recognition 2003 LIACS Media Lab Leiden University
Seminar
Speech Recognition
2003
E.M. Bakker
LIACS Media Lab
Leiden University

Speech Recognition 2003 LIACS Media Lab Leiden University
Outline
• Introduction and State of the Art
• A Speech Recognition Architecture– Acoustic modeling – Language modeling – Practical issues
• Applications
NB Some of the slides are adapted from the presentation: “Can Advances in Speech Recognition make Spoken Language as Convenient and as Accessible as Online Text?”, an excellent presentation by: Dr. Patti Price, Speech Technology Consulting Menlo Park, California 94025, and Dr. Joseph Picone Institute for Signal and Information Processing Dept. of Elect. and Comp. Eng. Mississippi State University

Speech Recognition 2003 LIACS Media Lab Leiden University
Research Areas
•Speech Analysis (Production, Perception, Parameter Estimation)
•Speech Coding/Compression
•Speech Synthesis (TTS)
•Speaker Identification/Recognition/Verification (Sprint, TI)
•Language Identification (Transparent Dialogue)
•Speech Recognition (Dragon, IBM, ATT)
Speech recognition sub-categories:
•Discrete/Connected/Continuous Speech/Word Spotting
•Speaker Dependent/Independent
•Small/Medium/Large/Unlimited Vocabulary
•Speaker-Independent Large Vocabulary Continuous Speech Recognition (or LVCSR
for short :)
Speech Recognition 2003 LIACS Media Lab Leiden University
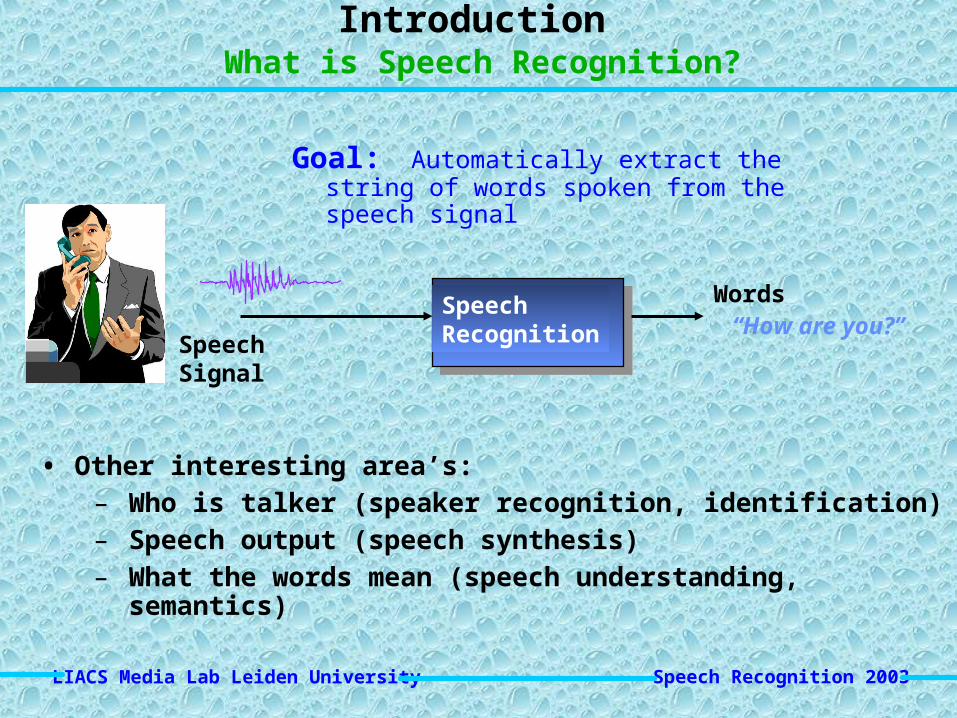
Introduction What is Speech Recognition?
SpeechRecognition
Words“How are you?”
Speech Signal
Goal: Automatically extract the string of words spoken from the speech signal
• Other interesting area’s:– Who is talker (speaker recognition, identification)– Speech output (speech synthesis)– What the words mean (speech understanding, semantics)

Speech Recognition 2003 LIACS Media Lab Leiden University
IntroductionApplications
• Database query – Resource management– Air travel information– Stock quote
•Command and control –Manufacturing–Consumer products
http://www.speech.philips.com
•Dictation
–http://www.lhsl.com/contacts/–http://www-4.ibm.com/software/speech
–http://www.microsoft.com/speech/
Nuance, American Airlines: 1-800-433-7300, touch 1

Speech Recognition 2003 LIACS Media Lab Leiden University
Introduction: State of the Art
Speech-recognition software
• IBM (Via Voice, Voice Server Applications,...)– Speaker independent, continuous command recognition – Large vocabulary recognition – Text-to-speech confirmation – Barge in (The ability to interrupt an audio prompt as it is playing)
• Dragon Systems, Lernout & Hauspie (L&H Voice Xpress™ (:( )
• Philips– Dictation
– Telephone
– Voice Control (SpeechWave, VoCon SDK, chip-sets)
• Microsoft (Whisper, Dr Who)

Speech Recognition 2003 LIACS Media Lab Leiden University
Introduction: State of the Art
Speech over the telephone.:
• AT&T Bell Labs pioneered the use of speech-recognition systems for telephone transactions
• companies such as Nuance, Philips and SpeechWorks are active in this field for some years now.
• IBM Applications over telephone: – request news, internet pages, e-mail
– stock quotes, traveling info
– weather information

Speech Recognition 2003 LIACS Media Lab Leiden University
Introduction: State of the Art
Speech over the telephone (Philips):
• SpeechPearl® large vocabulary natural language recognition (up to 200,000 words)
• SpeechMania® mixed initiative dialog gives the caller the impression of a truly natural dialogue: full replacement of the human operator.
• SpeechWave™ relatively small vocabularies (up to hundreds of words) available in nearly 40 languages
• Voice ReQuest The system recognizes the request and routes the call to the appropriate extension, all without the intervention of an operator.

Speech Recognition 2003 LIACS Media Lab Leiden University
Introduction: State of the Art
Speech over the telephone. :
• Brokerage: E*Trade,...
• Banking
• Travel: United Airlines, Continental Airlines
• BellSouth
• HP
• Federal Express
• Foodline

Speech Recognition 2003 LIACS Media Lab Leiden University
Introduction: State of the Art
Speech over the telephone.

Speech Recognition 2003 LIACS Media Lab Leiden University
Introduction: State of the Art
The following is a transcript of a telephone conversation
between Victor Zue and the Jupiter system for weather
information. Jupiter's toll-free number is 1-888-573-8255:
• [Phone ringing]
• Jupiter: Hi. Welcome to Jupiter, the M.I.T. Lab for Computer Science Weather Information System. This call is being recorded for system development.You may hang up or ask for help at any time. How can I help you?
• V.Z.: What is the forecast for Boston today?
• Jupiter: In Boston this afternoon, partly sunny and windy. High around 50. Tonight, clear, lows around 35. What other information can I give you?
• V.Z.: Will it rain tomorrow? • Jupiter: To my knowledge, the forecast calls for no rain in Boston
tomorrow. Is there anything else?

Speech Recognition 2003 LIACS Media Lab Leiden University
Introduction: State of the Art
• V.Z.: How about Seattle?
• Jupiter: To my knowledge, the forecast calls for no rain in Seattle tomorrow. Is there something else you would like to know?
• V.Z.: Is it sunny anywhere in the Caribbean?
• Jupiter: Sorry, I am not sure what you said.
• V.Z.: Is it sunny anywhere in the Caribbean?
• Jupiter: I am sorry, I may not know the city you are asking about. Try asking for the state or country. For example, what cities do you know about in Massachusetts?
• V.Z.: What is the temperature in Montego Bay?
• Jupiter: In Montego Bay today, high 86 and low 73. Is there something else?
• V.Z.: Good-bye.

Speech Recognition 2003 LIACS Media Lab Leiden University
all speakers of the language
including foreign
application independent or
adaptive
all styles including human-human (unaware)
wherever speech occurs
2005
Factors that Affect Performance of Speech Recognition Systems
vehicle noise radiocell phones
regional accentsnative speakers
competent foreign speakers
some application–
specific data and one engineer
year
natural human-machine dialog (user can adapt)
2000
expert years to create app– specific language model
speaker independent and adaptive
normal officevarious microphonestelephone
planned speech
1995
NOISE ENVIRONMENT
SPEECH STYLE
USER
POPULATION
COMPLEXITY
1985
quiet roomfixed high –quality mic
careful reading
speaker-dep.
application– specific speech and language

Speech Recognition 2003 LIACS Media Lab Leiden University
How Do You Measure the Performance?
USC, October 15, 1999: “the world's first machine system that can recognize spoken words better than humans can.”
“ In benchmark testing using just a few spoken words, USC's Berger-Liaw … System not only bested all existing computer speech recognition systems but outperformed the keenest human ears.”
• What benchmarks?
• What was training?
• What was the test?
• Were they independent?
• How large was the vocabulary and the sample size?
• Did they really test all existing systems?Is that different from chance?
• Was the noise added or coincident with speech?
• What kind of noise? Was it independent of the speech?

Speech Recognition 2003 LIACS Media Lab Leiden University
• Spontaneous telephone speech is still a “grand challenge”.
• Telephone-quality speech is still central to the problem.
• Broadcast news is a very dynamic domain.
0%
10%
30%
40%
20%
Word Error Rate (WER)
Level Of Difficulty
Digits
ContinuousDigits
Command and Control
Letters and Numbers
BroadcastNews
Read Speech
ConversationalSpeech
Evaluation Metrics
Speech Recognition 2003 LIACS Media Lab Leiden University
0%
5%
15%
20%
10%
10 dB 16 dB 22 dB Quiet
Wall Street Journal (Additive Noise)
Machines
Human Listeners (Committee)
Word Error Rate
Speech-To-Noise Ratio
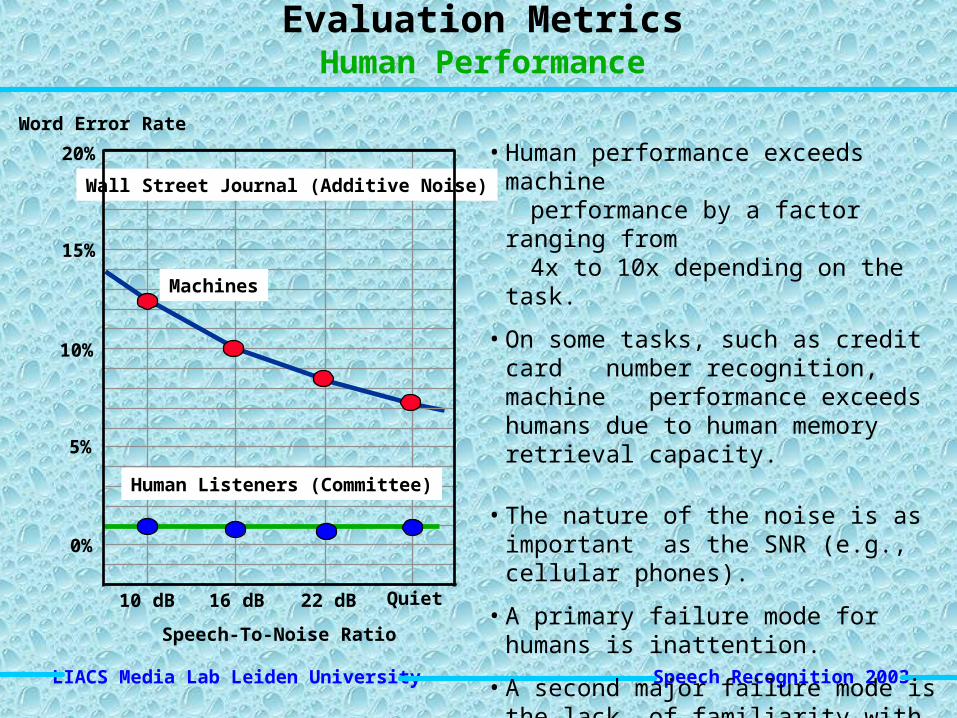
• Human performance exceeds machine performance by a factor ranging from 4x to 10x depending on the task.
• On some tasks, such as credit card number recognition, machine performance exceeds humans due to human memory retrieval capacity.
• The nature of the noise is as important as the SNR (e.g., cellular phones).
• A primary failure mode for humans is inattention.
• A second major failure mode is the lack of familiarity with the domain (i.e., business terms and corporation names).
Evaluation MetricsHuman Performance

Speech Recognition 2003 LIACS Media Lab Leiden University
100%
1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 20031%
10%
ReadSpeech
1k5k
20k vocabularies
Noisy
VariedMicrophones
SpontaneousSpeech
ConversationalSpeech
BroadcastSpeech
(Foreign)
(Foreign)10 X
• A Word Error Rate (WER)below 10% is considered
acceptable. • Performance in the field is typically 2x to 4x worse than performance on an evaluation.
Evaluation MetricsMachine Performance

Speech Recognition 2003 LIACS Media Lab Leiden University
What does a speech signal look like?

Speech Recognition 2003 LIACS Media Lab Leiden University
Spectrogram

Speech Recognition 2003 LIACS Media Lab Leiden University
Speech Recognition

Speech Recognition 2003 LIACS Media Lab Leiden University
• Measurements of the signal are ambiguous.
• Region of overlap represents classification errors.
• Reduce overlap by introducing acoustic and linguistic context (e.g., context-dependent phones).
Feature No. 1
Feature No. 2
Ph_1
Ph_3Ph_2
• Comparison of “aa” in “IOck” vs. “iy” in bEAt for conversational speech (SWB)
Recognition ArchitecturesWhy Is Speech Recognition So Difficult?

Speech Recognition 2003 LIACS Media Lab Leiden University
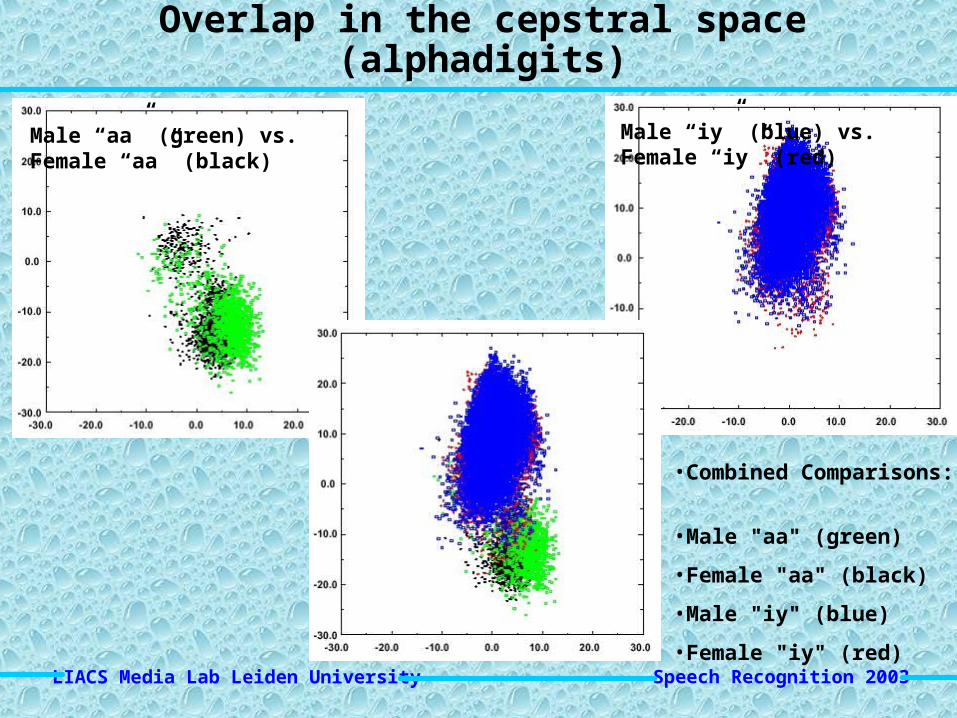
Overlap in the ceptral space (alphadigits)
Male “aa” Male “iy”
Female “aa” Female “iy”
Speech Recognition 2003 LIACS Media Lab Leiden University
Overlap in the cepstral space (alphadigits)
Male “aa” (green) vs. Female “aa” (black)
Male “iy” (blue) vs. Female “iy” (red)
•Combined Comparisons:
•Male "aa" (green)
•Female "aa" (black)
•Male "iy" (blue)
•Female "iy" (red)

Speech Recognition 2003 LIACS Media Lab Leiden University
OVERLAP IN THE CEPSTRAL SPACE (SWB-All)
The following plots demonstrate overlap of recognition features in the cepstral space. These plots consist of all vowels excised from tokens in the
SWITCHBOARD conversational speech corpus.
All Male Vowels All Female Vowels All Vowels

Speech Recognition 2003 LIACS Media Lab Leiden University
MessageSource
LinguisticChannel
ArticulatoryChannel
AcousticChannel
Observable: Message Words Sounds Features
Bayesian formulation for speech recognition:
• P(W|A) = P(A|W) P(W) / P(A)
Recognition ArchitecturesA Communication Theoretic Approach
Objective: minimize the word error rate
Approach: maximize P(W|A) during training
Components:
• P(A|W) : acoustic model (hidden Markov models, mixtures)
• P(W) : language model (statistical, finite state networks, etc.)
The language model typically predicts a small set of next words based on knowledge of a finite number of previous words (N-grams).
Speech Recognition 2003 LIACS Media Lab Leiden University
Input Speech
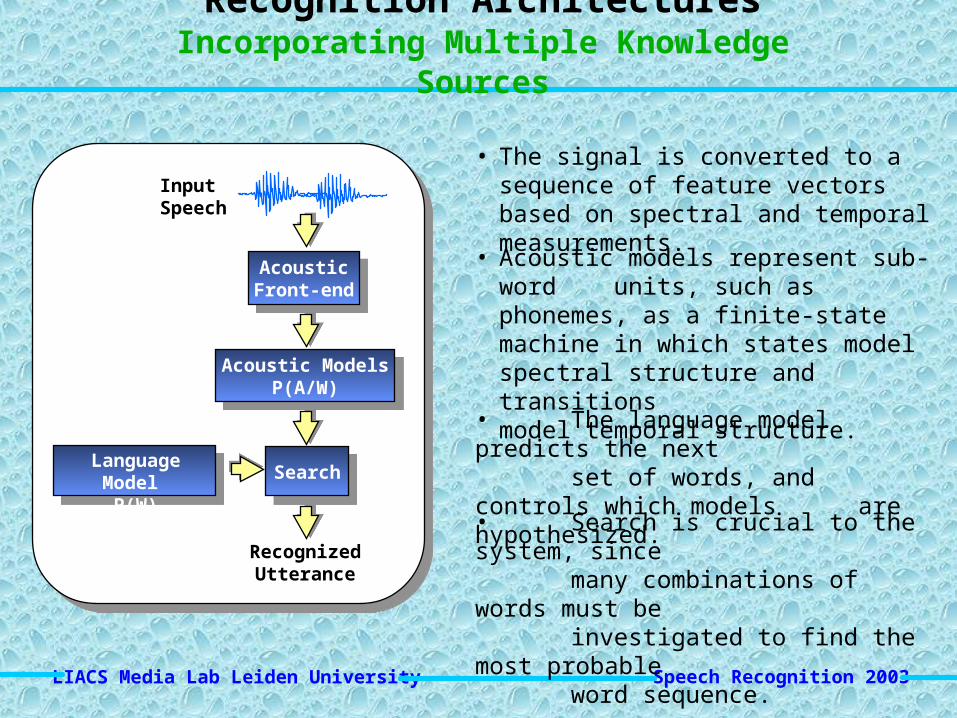
Recognition ArchitecturesIncorporating Multiple Knowledge Sources
AcousticFront-end
AcousticFront-end
• The signal is converted to a sequence of feature vectors based on spectral and temporal measurements.
Acoustic ModelsP(A/W)
Acoustic ModelsP(A/W)
• Acoustic models represent sub-word units, such as phonemes, as a finite-state machine in which states model spectral structure and transitions model temporal structure.
RecognizedUtterance
SearchSearch
• Search is crucial to the system, since many combinations of words must be investigated to find the most probable word sequence.
• The language model predicts the next set of words, and controls which models
are hypothesized.Language Model
P(W)
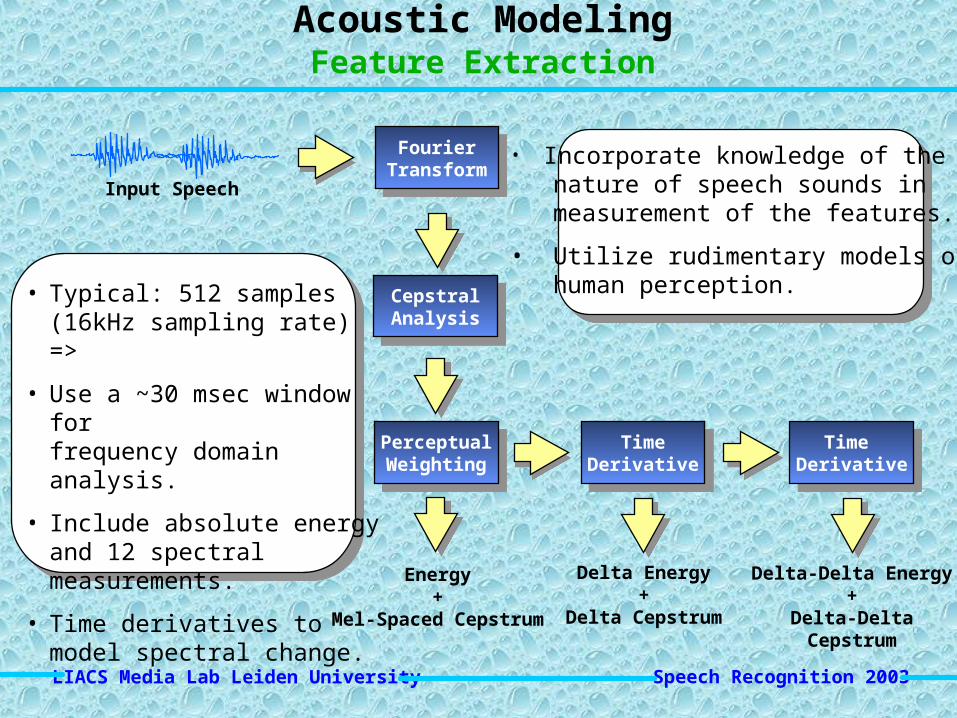
Speech Recognition 2003 LIACS Media Lab Leiden University
FourierTransform
FourierTransform
CepstralAnalysis
CepstralAnalysis
PerceptualWeighting
PerceptualWeighting
TimeDerivative
TimeDerivative
Time Derivative
Time Derivative
Energy+
Mel-Spaced Cepstrum
Delta Energy+
Delta Cepstrum
Delta-Delta Energy+
Delta-Delta Cepstrum
Input Speech
• Incorporate knowledge of the nature of speech sounds in measurement of the features.
• Utilize rudimentary models of human perception.
Acoustic ModelingFeature Extraction
• Typical: 512 samples (16kHz sampling rate) =>
• Use a ~30 msec window forfrequency domain analysis.
• Include absolute energy and 12 spectral measurements.
• Time derivatives to model spectral change.

Speech Recognition 2003 LIACS Media Lab Leiden University
• Acoustic models encode the temporal evolution of the features (spectrum).
• Gaussian mixture distributions are used to account for variations in speaker, accent, and pronunciation.
• Phonetic model topologies are simple left-to-right structures.
• Skip states (time-warping) and multiple paths (alternate pronunciations) are also common features of models.
• Sharing model parameters is a common strategy to reduce complexity.
Acoustic ModelingHidden Markov Models

Speech Recognition 2003 LIACS Media Lab Leiden University
• Word level transcription• Supervises a closed-loop data-driven
modeling• Initial parameter estimation
• The expectation/maximization (EM) algorithm is used to improve our parameter estimates.
• Computationally efficient training algorithms (Forward-Backward) are crucial.
• Batch mode parameter updates are typically preferred.
• Decision trees and the use of additional linguistic knowledge are used to optimize parameter-sharing, and system complexity,.
Acoustic ModelingParameter Estimation
• Initialization
• Single Gaussian Estimation
• 2-Way Split
• Mixture Distribution Reestimation
• 4-Way Split
• Reestimation
•••

Speech Recognition 2003 LIACS Media Lab Leiden University
Language ModelingIs A Lot Like Wheel of Fortune

Speech Recognition 2003 LIACS Media Lab Leiden University
Language ModelingN-Grams: The Good, The Bad, and The Ugly
Bigrams (SWB):
• Most Common: “you know”, “yeah SENT!”, “!SENT um-hum”, “I think”• Rank-100: “do it”, “that we”, “don’t think”• Least Common: “raw fish”, “moisture content”,
“Reagan Bush”
Trigrams (SWB):
• Most Common: “!SENT um-hum SENT!”, “a lot of”, “I don’t know”
• Rank-100: “it was a”, “you know that”• Least Common: “you have parents”,
“you seen Brooklyn”
Unigrams (SWB):
• Most Common: “I”, “and”, “the”, “you”, “a”• Rank-100: “she”, “an”, “going”• Least Common: “Abraham”, “Alastair”, “Acura”

Speech Recognition 2003 LIACS Media Lab Leiden University
Language ModelingIntegration of Natural Language
• Natural language constraints can be easily incorporated.
• Lack of punctuation and search space size pose problems.
• Speech recognition typically produces a word-level
time-aligned annotation.
• Time alignments for other levels of information also available.

Speech Recognition 2003 LIACS Media Lab Leiden University
• Dynamic programming is used to find the most probable path through the network.
• Beam search is used to control resources.
Implementation IssuesDynamic Programming-Based Search
• Search is time synchronous and left-to-right.
• Arbitrary amounts of silence must be permitted between each word.
• Words are hypothesized many times with different start/stop times, which significantly increases search complexity.

Speech Recognition 2003 LIACS Media Lab Leiden University
• Cross-word Decoding: since word boundaries don’t occur in spontaneous speech, we must allow for sequences of sounds that span word boundaries.
• Cross-word decoding significantly increases memory requirements.
Implementation IssuesCross-Word Decoding Is Expensive

Speech Recognition 2003 LIACS Media Lab Leiden University
• Typical LVCSR systems have about 10M free parameters, which makes training a challenge.
• Large speech databases are required (several hundred hours of speech).
• Tying, smoothing, and interpolation are required.
Implementation Issues Search Is Resource Intensive
Megabytes of Memory
FeatureExtraction
(1M)
Acoustic Modeling
(10M)
LanguageModeling (30M)
Search(150M)
Percentage of CPUFeature
Extraction1%
LanguageModeling
15%
Search 25% Acoustic
Modeling 59%

Speech Recognition 2003 LIACS Media Lab Leiden University
Applications Conversational Speech
• Conversational speech collected over the telephone contains background noise, music, fluctuations in the speech rate, laughter, partial words, hesitations, mouth noises, etc.
• WER (Word Error Rate) has decreased from 100% to 30% in six years.
• Laughter
• Singing
• Unintelligible
• Spoonerism
• Background Speech
• No pauses
• Restarts
• Vocalized Noise
• Coinage

Speech Recognition 2003 LIACS Media Lab Leiden University
ApplicationsAudio Indexing of Broadcast News
Broadcast news offers some uniquechallenges:• Lexicon: important information in infrequently occurring words
• Acoustic Modeling: variations in channel, particularly within the same segment (“ in the studio” vs. “on location”)
• Language Model: must adapt (“ Bush,” “Clinton,” “Bush,” “McCain,” “???”)
• Language: multilingual systems? language-independent acoustic modeling?

Speech Recognition 2003 LIACS Media Lab Leiden University
ApplicationsAutomatic Phone Centers
• Portals: Bevocal, TellMe, HeyAniat
• VoiceXML 2.0
• Automatic Information Desk
• Reservation Desk
• Automatic Help-Desk
• With Speaker identification
• bank account services• e-mail services• corporate services

Speech Recognition 2003 LIACS Media Lab Leiden University
• From President Clinton’s State of the Union address (January 27, 2000):
“These kinds of innovations are also propelling our remarkable prosperity...Soon researchers will bring us devices that can translate foreign languagesas fast as you can talk... molecular computers the size of a tear drop with thepower of today’s fastest supercomputers.”
Applications Real-Time Translation
• Imagine a world where:
• You book a travel reservation from your cellular phone while driving in your car without ever talking to a human (database query)
• You converse with someone in a foreign country and neither speakerspeaks a common language (universal translator)
• You place a call to your bank to inquire about your bank account and never have to remember a password (transparent telephony)
• You can ask questions by voice and your Internet browser returns answers to your questions (intelligent query)
• Human Language Engineering: a sophisticated integration of many speech and language related technologies... a science for the next millennium.

Speech Recognition 2003 LIACS Media Lab Leiden University
Conclusions:
• supervised training is a good machine learning technique
• large databases are essential for the development of robust statistics
Challenges:
• discrimination vs. representation
• generalization vs. memorization
• pronunciation modeling
• human-centered language modelingThe algorithmic issues for the next decade:• Better features by extracting articulatory information?
• Bayesian statistics? Bayesian networks?
• Decision Trees? Information-theoretic measures?
• Nonlinear dynamics? Chaos?
Technology Future Directions
1970
Hidden Markov ModelsAnalog Filter Banks Dynamic Time-Warping
1980 19902000
1960







