
The data deluge driven by Next Generation Sequencing is transforming life sciences and its computational needs
Simon RasmussenAssistant Professor
Center for Biological Sequence AnalysisDepartment of Systems Biology
Technical University of [email protected]
Helicobacter acinonychis str Sheeba
Helicobacter pylori P12
Helicobacter pylori B8
Helicobacter pylori 26695
Helicobacter pylori G
27H
elicobacter pylori B38H
elicobacter pylori HPAG
1H
elicobacter pylori Shi470H
elicobacter pylori J99H
elicobacter cinaedi CC
UG
18818H
elicobacter hepaticus ATCC
51449H
elicobacter mustelae 12198
Helicobacter bilis ATC
C 43879
Helicobacter pullorum
MIT 98−5489
Helicobacter canadensis M
IT 98−5491H
elicobacter wingham
ensis ATCC
BAA−430W
olinella succinogenes DSM
1740
Cam
pylobacter concisus 13826C
ampylobacter curvus 52592
Cam
pylobacter rectus RM
3267C
ampylobacter show
ae RM
3277
Cam
pylobacter fetus subsp fetus 82−40C
ampylobacter hom
inis ATCC
BAA−381C
ampylobacter gracilis R
M3268
Sulfurospirillum deleyianum
DSM
6946N
itratiruptor sp SB155−2
Sulfurimonas denitrificans D
SM 1251
Arcobacter nitrofigilis DSM
7299Arcobacter butzleri R
M4018
Sulfurovum sp N
BC37−1
Nautilia profundicola Am
H
GU
649V1.CD
18.3G
U649V1.C
D35.0
Fusobacterium sp D
11
Fusobacterium sp 3 1 33
Fusobacterium sp 7 1
Fusobacterium nucleatum
subsp nucleatum ATC
C 25586
Fusobacterium nucleatum
subsp nucleatum ATC
C 23726
Fusobacterium sp 3 1 27
Fusobacterium sp 4 1 13
Fusobacterium sp 3 1 36A2
Fusobacterium sp 2 1 31
Fusobacterium sp 1 1 41FAA
Fusobacterium periodonticum
ATCC
33693Fusobacterium
sp D12
Fusobacterium gonidiaform
ans ATCC
25563
Fusobacterium sp 3 1 5R
Fusobacterium varium
ATCC
27725
Fusobacterium ulcerans ATC
C 49185
Fusobacterium m
ortiferum ATC
C 9817
Sebaldella termitidis ATC
C 33386
Leptotrichia goodfellowii F0264
Leptotrichia hofstadii F0254
Leptotrichia buccalis C−1013−b
Streptobacillus moniliform
is DSM
12112
Nostoc punctiform
e PCC
73102
Nostoc sp PC
C 7120
Anabaena variabilis ATCC
29413N
ostoc azollae 0708Trichodesm
ium erythraeum
IMS101
Cyanothece sp PC
C 7425
Thermosynechococcus elongatus BP−1
Acaryochloris marina M
BIC11017
Synechococcus elongatus PCC
7942
Synechococcus elongatus PCC
6301Synechocystis sp PC
C 6803
Cyanothece sp PC
C 8802
Cyanothece sp PC
C 8801
Cyanothece sp ATC
C 51142
Cyanothece sp PC
C 7424
Microcystis aeruginosa N
IES−843
Synechococcus sp PCC
7002
cyanobacterium U
CYN−A
Synechococcus sp WH
8102
Synechococcus sp CC
9605Synechococcus sp C
C9902
Synechococcus sp WH
7803
Synechococcus sp CC
9311Prochlorococcus m
arinus str MIT 9303
Prochlorococcus marinus str M
IT 9313Prochlorococcus m
arinus str MIT 9211
Prochlorococcus marinus subsp m
arinus str CC
MP1375
Prochlorococcus marinus str N
ATL2A
Prochlorococcus marinus str N
ATL1A
Synechococcus sp RC
C307
Prochlorococcus marinus str M
IT 9312
Prochlorococcus marinus str M
IT 9215
Prochlorococcus marinus str AS9601
Prochlorococcus marinus str M
IT 9301Prochlorococcus m
arinus str MIT 9515
Prochlorococcus marinus subsp pastoris str C
CM
P1986
Synechococcus sp JA−3−3Ab
Synechococcus sp JA−2−3Ba(2−13)
Gloeobacter violaceus PC
C 7421
GU
729MH
0021
GU
967MH
0067
GU
768V1.CD
19.0
GU
715MH
0183G
U439M
H0043
GU
484V1.UC
40.0G
U815M
H0137
GU
815O2.U
C44.0
GU
815O2.U
C44.2
GU
196MH
0038G
U306V1.C
D28.0
Rothia mucilaginosa DY−18
Rothia mucilaginosa ATCC 25296
Rothia dentocariosa ATCC 17931
Kocuria rhizophila DC2201Arthrobacter sp FB24
Arthrobacter chlorophenolicus A6
Arthrobacter aurescens TC1
Renibacterium salmoninarum ATCC 33209
Micrococcus luteus NCTC 2665
Micrococcus luteus SK58
Brevibacterium mcbrellneri ATCC 49030
Kytococcus sedentarius DSM 20547
Clavibacter michiganensis subsp sepedonicus
Clavibacter michiganensis subsp michiganensis NCPPB 382
Leifsonia xyli subsp xyli str CTCB07
Kineococcus radiotolerans SRS30216
Mobiluncus mulieris 28−1
Mobiluncus mulieris ATCC 35243
Mobiluncus curtisii ATCC 43063Actinomyces odontolyticus ATCC 17982
Actinomyces odontolyticus F0309
Actinomyces coleocanis DSM 15436
Actinomyces urogenitalis DSM 15434
Actinomyces sp oral taxon 848 str F0332
Arcanobacterium haemolyticum DSM 20595
Cellulomonas flavigena DSM 20109
Sanguibacter keddieii DSM 10542
Xylanimonas cellulosilytica DSM 15894
Jonesia denitrificans DSM 20603
Beutenbergia cavernae DSM 12333
Brachybacterium faecium DSM 4810
Frankia sp EAN1pec
Frankia alni ACN14a
Frankia sp CcI3
Geodermatophilus obscurus DSM 43160
Kribbella flavida DSM 17836
Nocardioides sp JS614
Aeromicrobium marinum DSM 15272
Propionibacterium freudenreichii subsp shermanii CIRM−BIA1
Propionibacterium acnes J139
Propionibacterium acnes J165
Propionibacterium acnes KPA171202
Propionibacterium acnes SK187
Propionibacterium acnes SK137
Bifidobacterium bifidum NCIMB 41171
GU234V1.CD36.0
Bifidobacterium longum subsp infantis ATCC 15697
Bifidobacterium longum subsp longum ATCC 55813
Bifidobacterium longum subsp infantis CCUG 52486
Bifidobacterium longum subsp longum F8
Bifidobacterium longum DJO10A
Bifidobacterium longum NCC2705
Bifidobacterium longum subsp longum JDM301
Bifidobacterium breve DSM 20213
GU69V1.CD36.0
Bifidobacterium adolescentis ATCC 15703
Bifidobacterium adolescentis L2−32
Bifidobacterium pseudocatenulatum DSM 20438
Bifidobacterium catenulatum DSM 16992
Bifidobacterium dentium Bd1
Bifidobacterium dentium ATCC 27678
Bifidobacterium angulatum DSM 20098
Bifidobacterium animalis subsp lactis AD011
Bifidobacterium animalis subsp lactis DSM 10140
Bifidobacterium animalis subsp lactis Bl−04
Bifidobacterium gallicum DSM 20093
Gardnerella vaginalis ATCC 14019
Gardnerella vaginalis 409−05
Parascardovia denticolens F0305
Scardovia inopinata F0304
Tropheryma whipplei str TwistTropheryma whipplei TW0827
Tsukamurella paurometabola DSM 20162Rhodococcus jostii RHA1Rhodococcus opacus B4Rhodococcus erythropolis PR4Rhodococcus erythropolis SK121
Rhodococcus equi ATCC 33707
Nocardia farcinica IFM 10152Gordonia bronchialis DSM 43247
Mycobacterium abscessus ATCC 19977Mycobacterium sp JLSMycobacterium sp KMS
Mycobacterium sp MCSMycobacterium smegmatis str MC2 155
Mycobacterium gilvum PYR−GCKMycobacterium vanbaalenii PYR−1
Mycobacterium tuberculosis F11Mycobacterium tuberculosis KZN 1435
Mycobacterium tuberculosis H37Rv
Mycobacterium tuberculosis CDC1551
Mycobacterium tuberculosis H37Ra
Mycobacterium bovis BCG str Tokyo 172
Mycobacterium bovis BCG str Pasteur 1173P2
Mycobacterium bovis AF212297
Mycobacterium marinum MMycobacterium ulcerans Agy99
Mycobacterium parascrofulaceum ATCC BAA−614
Mycobacterium avium subsp paratuberculosis K−10
Mycobacterium avium 104
Mycobacterium leprae TN
Nakamurella multipartita DSM 44233Actinosynnema mirum DSM 43827Saccharopolyspora erythraea NRRL 2338
Saccharomonospora viridis DSM 43017
Corynebacterium tuberculostearicum SK141Corynebacterium pseudogenitalium ATCC 33035
Corynebacterium accolens ATCC 49725
Bacteroides ovatus SD CC 2a
Bacteroides xylanisolvens SD C
C 1b
Bacteroides sp D1
Bacteroides sp 2 1 22
Bacteroides xylanisolvens XB1A
Bacteroides ovatus SD CMC 3f
Bacteroides ovatus ATCC 8483
Bacteroides sp 2 2 4Bacteroides sp D2
Bacteroides caccae ATCC 43185
Bacteroides finegoldii DSM 17565
Bacteroides thetaiotaomicron VPI−5482
Bacteroides sp 1 1 6Bacteroides fragilis NCTC 9343
Bacteroides fragilis YCH46
Bacteroides sp 2 1 16Bacteroides sp 3 2 5
Bacteroides fragilis 3 1 12
Bacteroides cellulosilyticus DSM 14838
Bacteroides intestinalis DSM 17393
Bacteroides sp D20
Bacteroides uniformis ATCC 8492
Bacteroides eggerthii DSM 20697
Bacteroides stercoris ATCC 43183
GU633M
H0143Bacteroides vulgatus PC510
Bacteroides sp 4 3 47FAA
Bacteroides vulgatus ATCC 8482
Bacteroides dorei DSM 17855
Bacteroides sp 3 1 33FAA
Bacteroides dorei 5 1 36D4
Bacteroides sp 9 1 42FAABacteroides coprocola DSM
17136
Bacteroides coprophilus DSM 18228
Bacteroides plebeius DSM 17135
GU702M
H0047
GU702M
H0135G
U462V1.CD38.0
GU116M
H0047
GU116M
H0006G
U755V1.CD19.0
GU617M
H0046
GU5226O
2.UC43.0
GU891M
H0057Prevotella tannerae ATCC 51259
GU474MH0006
Prevotella bergensis DSM 17361
GU924MH0069
Prevotella bivia JCVIHMP010
Prevotella melaninogenica ATCC 25845
Prevotella melaninogenica D18
Prevotella veroralis F0319
GU164V1.UC56.0
Prevotella copri DSM 18205
Prevotella buccae D17
Prevotella oris F0302
GU1320MH0057
GU1320O2.UC57.0
GU301V1.CD13.0Prevotella buccalis ATCC 35310
Prevotella timonensis CRIS 5C−B1
Prevotella sp oral taxon 472 str F0295
Prevotella sp oral taxon 317 str F0108
Prevotella sp oral taxon 299 str F0039
GU255MH0011
GU255V1.UC55.4
GU1185MH0107
GU1058V1.CD19.0
GU592MH0168
GU520MH0045
GU520MH0012
Prevotella ruminicola 23
GU20MH0012
GU20MH0061
GU51O2.UC37.0
GU118V1.CD15.3
Parabacteroides merdae ATCC 43184
Parabacteroides johnsonii DSM 18315
Bacteroides sp 2 1 7
Bacteroides sp 2 1 33B
Parabacteroides sp D13
Parabacteroides distasonis ATCC 8503
GU2MH0020
GU2MH0074
GU279MH0020
GU279O2.UC18.2
Porphyromonas uenonis 60−3
Porphyromonas endodontalis ATCC 35406
Porphyromonas gingivalis ATCC 33277
Porphyromonas gingivalis W
83
GU1031V1.CD20.4
GU927V1.CD29.0
GU927O2.UC40.2
GU927O2.UC40.0
GU873O2.UC60.0
GU485O2.UC60.0
Candidatus Azobacteroides pseudotrichonymphae genomovar CFP2
GU67O2.UC48.2
GU67MH0012
Alistipes putredinis DSM 17216
GU29MH0002
GU29MH0074
Alistipes shahii WAL 8301
GU268MH0054
GU157V1.UC11.5
GU14MH0012
GU14O2.UC48.2
GU788MH0016
GU788V1.UC49.1
GU561O2.UC51.2
GU561V1.UC49.1GU709MH0158
GU770MH0006
GU770MH0022
GU545MH0009
GU435MH0012
GU514MH0009
GU514MH0031
GU1060MH0044
GU831MH0143
GU831MH0071
Pedobacter heparinus DSM 2366
Sphingobacterium spiritivorum ATCC 33300
Sphingobacterium spiritivorum ATCC 33861
Cytophaga hutchinsonii ATCC 33406
Dyadobacter fermentans DSM 18053
Spirosoma linguale DSM 74
Flavobacterium psychrophilum JIP0286
Flavobacterium johnsoniae UW101
Croceibacter atlanticus HTCC2559
Gramella forsetii KT0803
Zunongwangia profunda SM−A87
Robiginitalea biformata HTCC2501
Capnocytophaga ochracea DSM 7271
Capnocytophaga sputigena ATCC 33612
Capnocytophaga gingivalis ATCC 33624
Flavobacteriaceae bacterium 3519−10
Chryseobacterium gleum ATCC 35910
Chitinophaga pinensis DSM 2588
Candidatus Amoebophilus asiaticus 5a2
Blattabacterium sp (Periplaneta americana) str BPLAN
Blattabacterium sp (Blattella germanica) str Bge
Candidatus Carsonella ruddii PV
Ruminococcus gnavus ATCC 29149
Candidatus Sulcia muelleri GWSS
Candidatus Sulcia muelleri DMIN
Candidatus Sulcia muelleri SMDSEM
Salinibacter ruber
Salinibacter ruber DSM 13855
Rhodothermus marinus DSM 4252
Chlorobium luteolum DSM 273
Chlorobium phaeovibrioides DSM 265
Pelodictyon phaeoclathratiforme BU−1
Chlorobium limicola DSM 245
Chlorobium phaeobacteroides DSM 266
Chlorobium chlorochromatii CaD3
Chlorobaculum parvum NCIB 8327
Chlorobium tepidum TLS
Prosthecochloris aestuarii DSM 271
Chlorobium phaeobacteroides BS1
Chloroherpeton thalassium ATCC 35110
Gemmatimonas aurantiaca T−27
Fibrobacter succinogenes subsp succinogenes S85
Chlamydia trachomatis AHAR−13
Chlamydia trachomatis BTZ1A828OT
Chlamydia trachomatis DUW−3CX
Chlamydia trachomatis BJali20OT
Chlamydia trachomatis L2bUCH−1proctitis
Chlamydia trachomatis 434Bu
Chlamydia muridarum Nigg
Chlamydophila pneumoniae J138
Chlamydophila pneumoniae TW−183
Chlamydophila pneumoniae CWL029
Chlamydophila pneumoniae AR39
Chlamydophila felis FeC−56
Chlamydophila caviae GPIC
Chlamydophila abortus S263
Candidatus Protochlamydia amoebophila UWE25
Waddlia chondrophila WSU 86−1044
GU154MH0012
GU154MH0002
GU154V1.CD31.0
GU344V1.CD7.4
Akkermansia muciniphila ATCC BAA−835
Methylacidiphilum infernorum V4
Opitutus terrae PB90−1
Coraliomargarita akajimensis DSM 45221
Rhodopirellula baltica SH 1
Pirellula staleyi DSM 6068
Planctomyces limnophilus DSM 3776
Borrelia burgdorferi B31
Borrelia burgdorferi ZS7
Borrelia afzelii PKo
Borrelia garinii PBi
Borrelia turicatae 91E135
Borrelia hermsii DAH
Borrelia recurrentis A1
Borrelia duttonii Ly
Treponema vincentii ATCC 35580
Treponema denticola ATCC 35405
Treponema pallidum subsp pallidum SS14
Treponema pallidum subsp pallidum str Nichols
Leptospira biflexa serovar Patoc strain Patoc 1 (Ames)
Leptospira biflexa serovar Patoc strain Patoc 1 (Paris)
Leptospira borgpetersenii serovar Hardjo−bovis L550
Leptospira borgpetersenii serovar Hardjo−bovis JB197
Leptospira interrogans serovar Copenhageni str Fiocruz L1−130
Leptospira interrogans serovar Lai str 56601
Brachyspira hyodysenteriae WA1
Brachyspira murdochii DSM 12563
Elusimicrobium minutum Pei191
uncultured Termite group 1 bacterium phylotype Rs−D17
Thermosipho melanesiensis BI429
Thermosipho africanus TCF52B
Fervidobacterium nodosum Rt17−B1
Thermotoga petrophila RKU−1
Thermotoga naphthophila RKU−10
Thermotoga sp RQ2
Thermotoga maritima MSB8
Thermotoga neapolitana DSM 4359
Thermotoga lettingae TMO
Kosmotoga olearia TBF 1951
Petrotoga mobilis SJ95
Dictyoglomus turgidum DSM 6724
Dictyoglomus thermophilum H−6−12
Coprothermobacter proteolyticus DSM 5265
Candidatus Cloacamonas acidaminovorans
Dehalococcoides ethenogenes 195
Dehalococcoides sp VS
Dehalococcoides sp GT
Dehalococcoides sp CBDB1
Dehalococcoides sp BAV1
Dehalogenimonas lykanthroporepellens BL−DC−9
Sphaerobacter thermophilus DSM 20745
Thermomicrobium roseum DSM 5159
Thermobaculum terrenum ATCC BAA−798
Chloroflexus sp Y−400−fl
Chloroflexus aurantiacus J−10−fl
Chloroflexus aggregans DSM 9485
Roseiflexus castenholzii DSM 13941
Roseiflexus sp RS−1
Herpetosiphon aurantiacus DSM 785
Synergistetes bacterium SGP1
Aminobacterium colombiense DSM 12261
Anaerobaculum hydrogeniformans ATCC BAA−1850
Thermanaerovibrio acidaminovorans DSM 6589
Pyramidobacter piscolens W5455
Jonquetella anthropi E3 33 E1
Meiothermus ruber DSM 1279
Meiothermus silvanus DSM 9946
Thermus thermophilus HB8
Thermus thermophilus HB27
Deinococcus deserti VCD115
Deinococcus geothermalis DSM 11300
Deinococcus radiodurans R1
Truepera radiovictrix DSM 17093

Life science data deluge• Massive unstructured
data from several areas DNA, patient journals, proteomics, imaging, ...
• Impacts Industry, Environment, Health
• Societal grand challenges
• Cheap sequencing technologies results in explosion of DNA data
What does DNA do?How to make a car? Car blueprint

What does DNA do?How to make a human? DNA
DNA contains the information on how to create an organism!

DNA: strings...GGATCAGCTGACTCGCCTGGCTCTGAGCCCCGCCGCCGCGCTCGGGCTCCGTCAGTTTCCTCGGCAGCGGTAGGCGAGAGCACGCGGAGGAGCGTGCGCGGGGGCCCCGGGAGACGGCGGCGGTGGCGGCGCGGGCAGAGCAAGGACGCGGCGGATCCCACTCGCACAGCAGCGCACTCGGTGCCCCGCGCAGGGTCGCGATGCTGCCCGGTTTGGCACTGCTCCTGCTGGCCGCCTGGACGGCTCGGGCGCTGGAGGTACCCACTGATGGTAATGCTGGCCTGCTGGCTGAACCCCAGATTGCCATGTTCTGTGGCAGACTGAACATGCACATGAATGTCCAGAATGGGAAGTGGGATTCAGATCCATCAGGGACCAAAACCTGCATTGATACCAAGGAAGGCATCCTGCAGTATTGCCAAGAAGTCTACCCTGAACTGCAGATCACCAATGTGGTAGAAGCCAACCAACCAGTGACCATCCAGAACTGGTGCAAGCGGGGCCGCAAGCAGTGCAAGACCCATCCCCACTTTGTGATTCCCTACCGCTGCTTAGTTGGTGAGTTTGTAAGTGATGCCCTTCTCGTTCCTGACAAGTGCAAATTCTTACACCAGGAGAGGATGGATGTTTGCGAAACTCATCTTCACTGGCACACCGTCGCCAAAGAGACATGCAGTGAGAAGAGTACCAACTTGCATGACTACGGCATGTTGCTGCCCTGCGGAATTGACAAGTTCCGAGGGGTAGAGTTTGTGTGTTGCCCACTGGCTGAAGAAAGTGACAATGTGGATTCTGCTGATGCGGAGGAGGATGACTCGGATGTCTGGTGGGGCGGAGCAGACACAGACTATGCAGATGGGAGTGAAGACAAAGTAGTAGAAGTAGCAGAGGAGGAAGAAGTGGCTGAGGTGGAAGAAGAAGAAGCCGATGATGACGAGGACGATGAGGATGGTGATGAGGTAGAGGAAGAGGCTGAGGAACCCTACGAAGAAGCCACAGAGAGAACCACCAGCATTGCCACCACCACCACCACCACCACAGAGTCTGTGGAAGAGGTGGTTCGAGAGGTGTGCTCTGAACAAGCCGAGACGGGGCCGTGCCGAGCAATGATCTCCCGCTG...
Human: 3 bill
Bacteria: 4 mill
Virus: 10k
A, C, G and T

Some sequencing examples
• Sequence 1000s of human genomes: who are we, who are you, drug effects, diseases, cancers, ...
• Sequence environmental samples, thousands of different bacteria: novel enzymes, the human microbiome, bacteria producing electricity
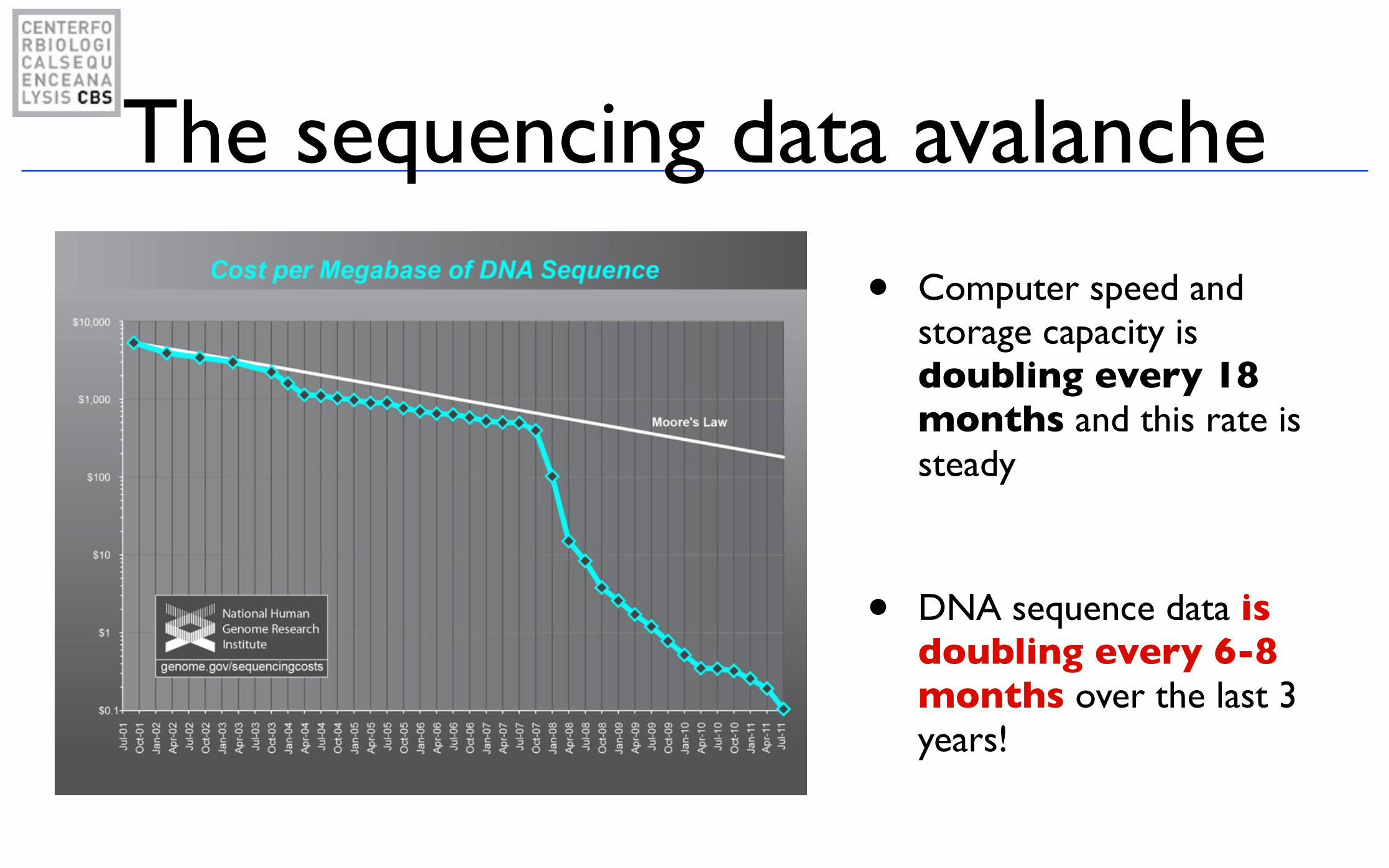
The sequencing data avalanche
• Computer speed and storage capacity is doubling every 18 months and this rate is steady
• DNA sequence data is doubling every 6-8 months over the last 3 years!
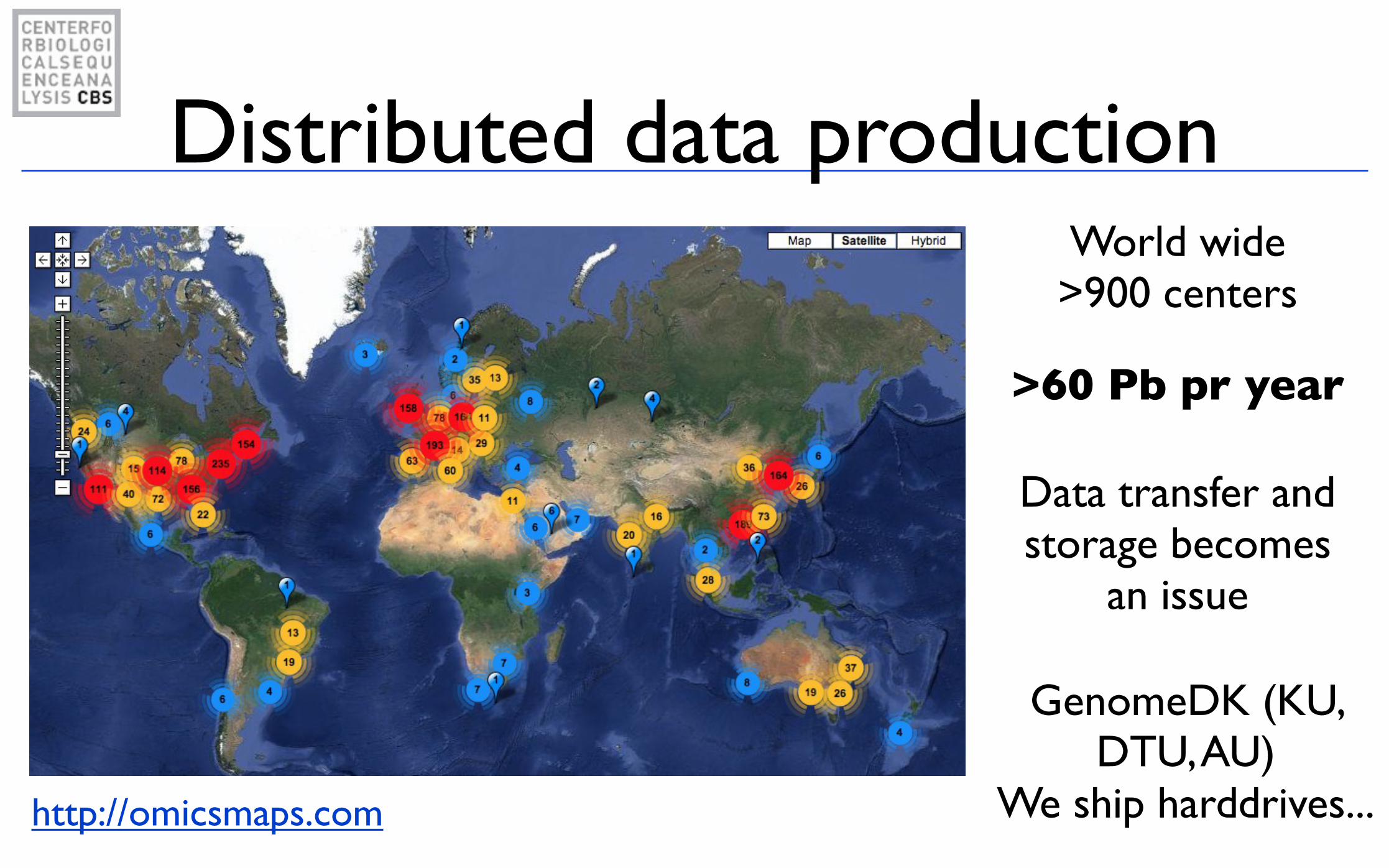
Distributed data productionWorld wide >900 centers
Data transfer and storage becomes
an issue
GenomeDK (KU, DTU, AU)
We ship harddrives...
>60 Pb pr year
http://omicsmaps.com

What does this mean?
• First human genome draft in 2001, final 2004
• Estimated costs $3 billion, time 13 years
• Today: 1 week, $8000
• Towards $1000 genome

Storage and analysis
Highest cost is not the experimentbut storage and analysis
A standard human (30-40x) whole-genome sequencing exp. would create
150 Gb (compressed) data
High strain on IO - read/writing GB->TBs

Analysis: Two basic approaches
• Alignment: We compare to a known genome
• de novo assembly: The genome is unknown we must create it ourselves
• Algorithm development
• is very dynamic - code optimization no longer vital
• What we used 2 years ago we don’t use today!
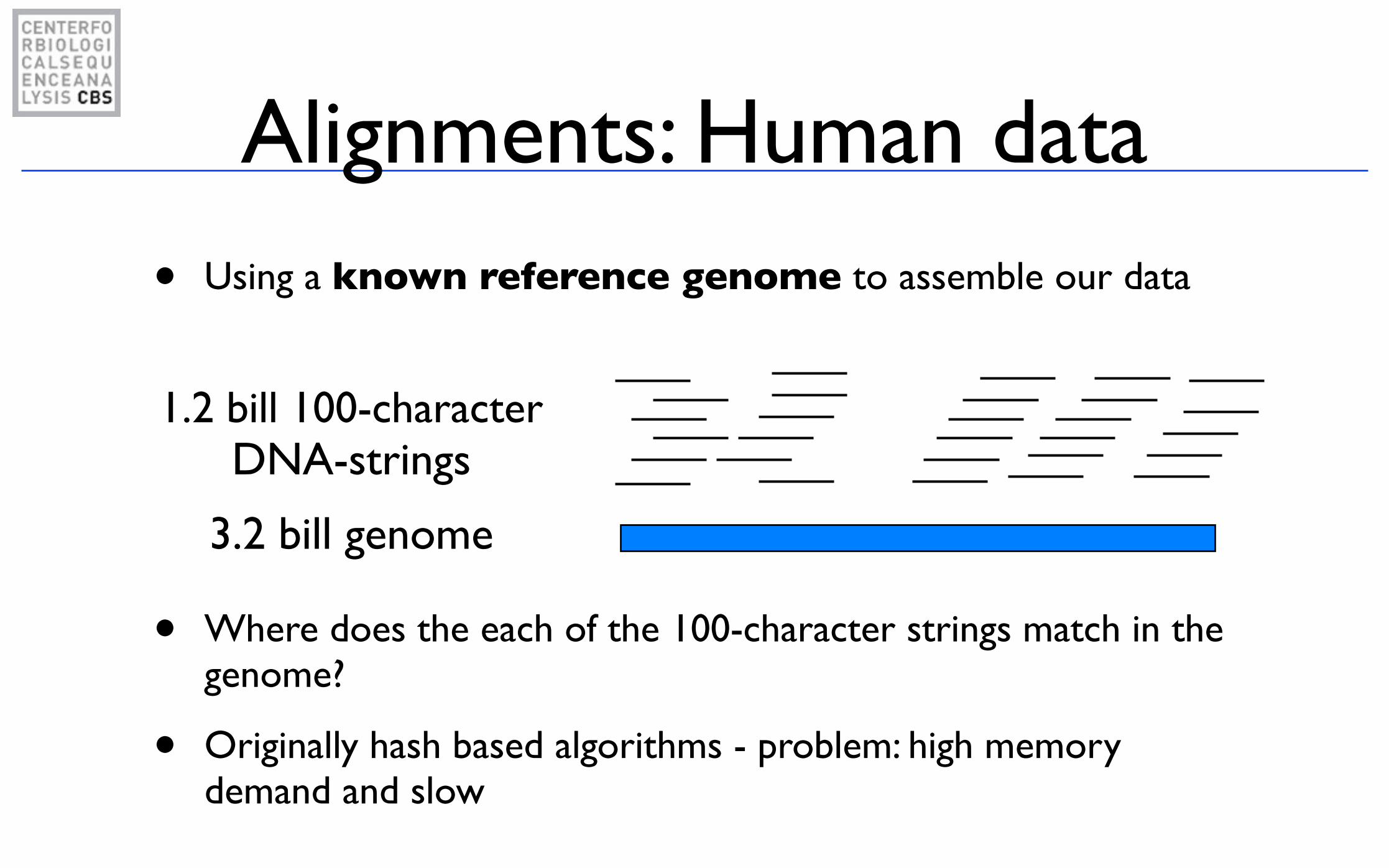
Alignments: Human data
• Using a known reference genome to assemble our data
• Where does the each of the 100-character strings match in the genome?
• Originally hash based algorithms - problem: high memory demand and slow
1.2 bill 100-character DNA-strings
3.2 bill genome

BWT alignment
• Burrows Wheelers Transformation (known from bzip2)
• Reversible transformation rearranging a character string into runs of similar characters
• Important because genomes tend to have many similar strings!
• Combine with suffix arrays to quickly find all possible matches
• High speed, high precision, low memory usage

Human project example• 51 human genomes from around the world
• Compute cluster resources used >20 CPU-years, 43 Tb storage
• >30 of algorithms/software used for only this project
• Application pipelines (sequential code and data flow) - need versatile compute facilities!
• Time to solution is key
• Competing with Stanford University, we could outperform them on compute time - we publish
• Time matters! - Accessibility matters!

de novo assembly algorithms• If no genome is known for a species we need
to make it
• Graph theory - de bruijn graphs
• Example: Polarbear
• Raw data: ~4 bill 100-character DNA strings
• Eg. total 400 bill characters!
• Originally: All vs. all comparisons - no chance

De Bruijn graph assemblers
• Directed graph of overlapping items (here DNA sequences)
• Graph is created by 1 pass of the data and assembly by walking Eulerian path
• Lots of RAM required (up to 2Tb or more)
• Data is unstructured - placement of each data string can be anywhere in the graph!
• High strain on communication between nodes in SMP systems!

Example genome de Bruijn graphs
only a handful of near-identical repeats longer than 200 bp (Fig. 3), whereas complex genomes, such as the human, usually have their repeat length determined by whether there has been an active LINE or SINE transposable element (usually around 4 kb in length for the former and between 500 bp and 1 kb for the lat-ter). As the ability to produce longer read pairs (also referred to as ‘mate pairs’ to distinguish them from the shorter read pairs) has only recently been optimized for next-generation technologies, assemblies of complex genomes have been rare.
The other main barrier for large, complex genome assem-blies is the memory overhead for these methods. Although the de Bruijn data structure is compressed, all the methods use some sort of adjunct data structures in addition to the core de Bruijn graph to map the reads to the graph. These adjunct structures are critical for leveraging additional information required for accurate assemblies, such as read pair information.
sequence length from a reference assembly. The read lengths need only be over the k-mer length to generate a reasonable assembly (in theory, k must be over 15 bp, though in practice 19 is the lowest sensible k-mer, and larger k-mers are always better, although at the expense of having to generate more coverage to support these large k-mer sizes).
The first assembler to exploit this technology was Roche’s 454 assembler, Newbler, which adapted the scheme specifically to handle the main source of error in 454 sequencing—namely, ambiguity in the length of homopolymer runs. In late 2007 and early 2008, sev-eral second-generation de Bruijn graph assemblers were released for very short reads, compatible with the Solexa technology, includ-ing SHARCGS27, VCAKE28, VELVET29, EULER-SR30, EDENA31, ABySS32 and ALLPATHS33. Some of these methods, such as VELVET, EULER-SR and ABySS, explicitly use de Bruijn graphs, whereas other methods implicitly explore a de Bruijn graph—for example, constrained by read-pair behavior, as in ALLPATHS. The methods differ in how they treat errors and to what extent they use read-pair information. Read pairs are defined as two short DNA sequence reads generated from different ends of a longer DNA molecule—for example, 35-bp reads generated from both ends of a 500 bp frag-ment. One does not know the identity of the sequence between the read pairs, but one usually has an estimate of the length of the inter-vening sequence. As it is only marginally more expensive to generate short reads in read-pair format than as single reads, extremely high coverage of read pairs is routinely available. The more advanced de Bruijn graph assemblers29,30,32,33 can use read pairs to provide long assemblies. A particular challenge has been the two-base-encoding ‘color space’ of ABI SOLiD technology. In this two-base encoding, a single error produces a systematic translation error on all subse-quent decoding of the bases for the rest of the read. In the context of an alignment, such an encoding scheme can be integrated into the alignment routine, and there is an argument that the double base encoding provides better discrimination between errors and observed differences. In de novo assembly, however, there is no ref-erence. The solution has been to perform the assembly directly in color space and then ‘key’ the resulting color space assembly to one of the four feasible base-pair assemblies using either a small amount of traditional sequence or the presence of a known base at the start of each SOLiD read.
Whichever sequencing technology and assembly method are used, the ability to provide long assemblies critically requires that at least a proportion of the read pairs are longer than the longest common near-identical repeat in the genome. This var-ies considerably between genomes. Bacterial genomes often have
Linear stretches
Tips
! ! ! ! ! ! ! !
! ! !
! ! ! !
! ! ! ! ! !
!
! ! ! !
!
!!!!!!!!!
a
b
1. Sequencing (for example, Solexa or 454)
2. Hashing
3. Simplification of linear stretches
4. Error (tip and bubble) removal Bubble
!
Figure 3 | Constructing and visualizing a de Bruijn graph of a DNA sequence. (a) An example de Bruijn graph assembly for a short genomic sequence without polymorphism. Sequence at top represents the genome, which is then sampled using shotgun sequencing in base space with 7-bp reads (step 1). Some of the reads have errors (red). In step 2, the k-mers in the reads (4-mers in this example) are collected into nodes and the coverage at each node is recorded. There are continuous linear stretches within the graph, and the sequencing errors create distinctive, low-coverage features through out the graph. In step 3, the graph is simplified to combine nodes that are associated with the continuous linear stretches into single, larger nodes of various k-mer sizes. In step 4, error correction removes the tips and bubbles that result from sequencing errors and creates a final graph structure that accurately and completely describes in the original genome sequence. (b) A full de Bruijn graph from a bacterial genome that shows the general lack of repetitive structure within the entire genome.
S10 | VOL.6 NO.11s | NOVEMBER 2009 | NATURE METHODS SUPPLEMENT
REVIEW
Figure 2.9: Graphical representation of the de Bruijn of the Streptococcussuis genome
In this representation, node sequences are represented as curves, whichconnect at their tips.
2.7.2 Local reference based visualisation
It quickly became clear that troubleshooting some of the algorithms de-scribed in the following chapters would require some adequate visualisa-tion techniques. Given that most tests were done on species with a knownreference, it was possible to use this sequence as a guide to the graph’scomplexity.
The first solution consisted in following the path of the referencesequence through the graph, recording the properties of the nodes beingtraversed. Figure 2.10 represents the length and multiplicity of successivenodes on the reference path.
In this diagram, long contigs are interrupted by two types of breaks.Sometimes, two long contigs are separated by a very short, isolated fea-
39
Simple genome
A bit more complex genome
>1Tb RAM580 days of compute
>5 Tb storage

Conclusions• The data deluge is fundamentally changing life science and the
required computational resources
• Analysis requires High Performance Computing facilities, CPU, Memory, Storage, IO and fast data links
• Time to solution - need accessible compute resource
• Dynamic algorithm development - very fast algorithm turnaround
• A need for shared compute (cloud) and storage facilities - computable storage

Acknowledgements
• Center for Biological Sequence analysis (DTU)
• Søren Brunak
• John Damm Sørensen
• Bent Petersen
Preprocessing and SNP calling Natasja S. Ehlers, PhD student Center for Biological Sequence Analysis Functional Human Variation Group







