
PL ISSN 0043-518X e-ISSN 2543-8476
Rok LXII 1 (668) 2017, 62—76
Jadwiga ZARÓD
Zróżnicowanie podregionów Polski ze względu na zagrożenie ubóstwem1
Streszczenie. Celem artykułu jest pokazanie zróżnicowania rozwoju podre-gionów w Polsce ze względu na wybrane cechy oraz charakterystyka obszarów najbardziej zagrożonych ubóstwem. Podregiony Polski opisano przy użyciu danych dotyczących 2013 r., opisują-cych warunki ekonomiczne, społeczne i mieszkaniowe ludności oraz jej aktyw-ność zawodową. Dane te poddano standaryzacji oraz — wykorzystując funkcję dyskryminacyjną — zgrupowano podregiony w 7 obszarach. Obszar I i II, na podstawie wartości funkcji dyskryminacyjnej, zaliczono do zagrożonych ubó-stwem i wykluczeniem społecznym. Następnie dla każdego obszaru oszacowano funkcje klasyfikacyjne. Dany podregion przyporządkowano do obszaru, w przy-padku którego ma on największą wartość klasyfikacyjną. Stwierdzono, że naj-większy wpływ na ostateczny podział podregionów miały następujące wskaźniki: stopa bezrobocia, liczba ludności przypadającej na 1 zatrudnionego oraz prze-ciętna powierzchnia mieszkania.
Słowa kluczowe: analiza dyskryminacyjna, ubóstwo, podregiony. JEL: C12, C15, C38
We wszystkich definicjach występujących w literaturze przedmiotu termin „ubóstwo” określa niezaspokojenie podstawowych potrzeb. Brak wystarczającej ilości pieniędzy i zasobów materialnych to ubóstwo ekonomiczne (Panek, 2014). Według Sena (1992) ubóstwo to nie tylko brak dochodów, ale niezdolność do pełnowartościowego życia spowodowana niedostatkiem środków ekonomicz-nych. Townsend i Gordon (2000) zdefiniowali pojęcie ubóstwa jako niezdolność
1 Artykuł opracowany na podstawie referatu wygłoszonego podczas Ogólnopolskiej Konferencji Pomiar ubóstwa i wykluczenia społecznego w układach regionalnych i lokalnych, Poznań, 11 i 12 czerwca 2015 r.

J. Zaród Zróżnicowanie podregionów Polski... 63
do uczestnictwa w zwykłej aktywności i do życia na poziomie przeciętnym w danej społeczności. Definicja ta oznacza również wykluczenie społeczne. Zgodnie z Narodową Strategią Integracji Społecznej dla Polski wykluczenie społeczne to brak lub ograniczenie możliwości uczestnictwa, wpływania i korzy-stania z podstawowych instytucji publicznych i rynków, które powinny być do-stępne dla wszystkich, a szczególnie dla osób ubogich2, a więc jest to sytuacja uniemożliwiająca lub znacznie utrudniająca jednostce lub grupie zgodne z pra-wem pełnienie ról społecznych, korzystanie z dóbr publicznych i infrastruktury społecznej, gromadzenie zasobów i zdobywanie dochodów w godny sposób3. Na temat ubóstwa i wykluczenia społecznego w Polsce powstało wiele opra-cowań, m.in. Golinowska (2010) badała ten problem w kraju w okresie minio-nych 20 lat. Szukiełojć-Bieńkuńska (2011) analizowała ubóstwo w Polsce na tle krajów Unii Europejskiej. Strategię przeciwdziałania ubóstwu i wykluczeniu społecznemu przedstawił Szarfenberg (2012). Urząd Statystyczny w Poznaniu (2014), za pomocą estymacji pośredniej, przeprowadził analizę terytorialnego zróżnicowania zasięgu ubóstwa podregionów w Polsce. Badaniem poziomu życia ludności poszczególnych podregionów Polski w zakresie wybranych wskaźników zajmowała się również Winiarczyk-Raźniak (2014). Wskazała ona na pogarszanie się poziomu życia w podregionach wokół największych polskich miast. Według Nazarczuka (2013) podregiony położone we wschodniej i połu-dniowo-wschodniej części kraju charakteryzuje niższy poziom życia oraz niższy potencjał rozwojowy i inwestycyjny. Artykuł jest próbą wykorzystania metod taksonomicznych (analizy dyskrymi-nacyjnej) do klasyfikacji podregionów Polski pod względem poziomu rozwoju. Celem opracowania jest identyfikacja zróżnicowania rozwoju podregionów Pol-ski i charakterystyka obszarów ze szczególnym uwzględnieniem problematyki zagrożenia ubóstwem.
METODYKA BADAŃ Analiza dyskryminacyjna wymaga wstępnej klasyfikacji jednostek (obserwa-cji) do grup na podstawie wybranych zmiennych diagnostycznych. Liczbę grup można ustalić na podstawie reguły (Sobczyk, 2015):
l = 1+3,322 log n
gdzie n = 66 — liczba podregionów4.
2 Narodowa Strategia Integracji Społecznej dla Polski z 2003 r., s. 22, www.funduszestruktu- ralne.gov.pl/informator/npr2/dokumenty-strategiczne/Narodowa-Strategia-Integracji-Spolecznej.pdf. Pobrano 5.06.2015 r.
3 Frąckiewicz (2005), s. 11. 4 Wykorzystano dane dotyczące podregionów obowiązujących w 2013 r. Od 2015 r. rozporzą-
dzeniem Rady Ministrów z 3 XII 2014 r. (Dz. U. z 31 XII 2014 r. poz. 1992) wprowadzono po-dział Polski na 72 podregiony (NTS 3).

64 Wiadomości Statystyczne nr 1 (668), 2017 W analizie dyskryminacyjnej zakłada się, że dane (ujęte w postaci zmien-nych) muszą reprezentować próbę z wielowymiarowego rozkładu normalnego (Krzyśko, 1990). Do oceny normalności rozkładu można wykorzystać metodę graficzną (histogramy rozkładu normalnego) lub testy, np. 2 czy Kołmogorowa- -Smirnowa (Krzyśko, 2004). Przed oszacowaniem funkcji dyskryminacyjnych dane wejściowe należy poddać standaryzacji (Zeliaś, 2000), aby uniezależnić wyniki analiz od jednostek pomiaru poszczególnych zmiennych. Liniowe funkcje dyskryminacyjne mają postać (Krzyśko, 1990):
D=b0+b1 x1+b2 x2+…+bk xk
gdzie: b0 — stała, bk — współczynniki zmiennych dyskryminacyjnych, xk — zmienne dyskryminacyjne. Maksymalna liczba oszacowanych funkcji jest równa liczbie grup minus je-den lub liczbie zmiennych w analizie. Moc dyskryminacyjną modelu określa współczynnik Lambda Wilksa zdefi-niowany jako:
HGG
det
det
gdzie: G — macierz wewnątrzgrupowej wariancji i kowariancji, H — macierz międzygrupowej wariancji i kowariancji. Współczynnik ten przyjmuje wartości z przedziału [0; 1]. Im niższa wartość statystyki , tym wyższa zdolność dyskryminacyjna modelu. Z kolei do oceny zdolności dyskryminacyjnej poszczególnych zmiennych diagnostycznych wyko-rzystuje się cząstkowy współczynnik Lambda Wilksa:
0 cz
j
gdzie: λ — wartość współczynnika Lambda Wilksa dla modelu po wprowadzeniu do
niego j-tej zmiennej, j=1, 2, …, k, 0 — wartość współczynnika Lambda Wilksa dla modelu przed wprowadze-
niem do niego j-tej zmiennej, j=1, 2, …, k.

J. Zaród Zróżnicowanie podregionów Polski... 65
Współczynnik czj zawiera się w granicach [0; 1] i opisuje udział j-tej zmien-
nej w dyskryminacji grupy. Bliska zeru wartość tego współczynnika świadczy o dużym wkładzie zmiennej do dyskryminacji. W celu weryfikacji istotności dyskryminacyjnej j-tej zmiennej wykorzystuje się statystykę testową o postaci (Gatnar, 1998):
czj
czjj lklknF // 11
gdzie: n — łączna liczba obiektów (jednostek, obserwacji) w próbie, k — liczba zmiennych dyskryminacyjnych, l — liczba rozważanych populacji (grup). Hipoteza zerowa testu F zakłada, że dana zmienna wnosi istotny wkład do modelu, natomiast hipoteza alternatywna głosi, że brak jest istotności dyskrymi-nacyjnej tej zmiennej. Statystyka F ma rozkład F-Fishera o liczbach swobody: df1 = k – 1 i df2 = n – k – l +1. Jeżeli wartość statystyki testowej jest mniejsza od wartości krytycznej, przy przyjętym poziomie istotności, to wkład rozważanej zmiennej w dyskryminację grup jest istotny. Najwyższą wartość statystyki F ma zmienna, która weszła do modelu jako pierwsza (o największym wkładzie). Dodatkowo, standardowo obliczany jest współczynnik tolerancji Tj , zdefinio-wany jako:
21 jkj RT dla j=1, ..., k gdzie Rjk — współczynnik korelacji wielorakiej między j-tą zmienną a pozosta-łymi zmiennymi w modelu. Współczynnik ten określa, ile informacji wnoszonych przez tę zmienną nie jest powielanych przez pozostałe zmienne znajdujące się już w modelu. O przynależności jednostki do grupy decydują funkcje klasyfikacyjne o po-staci:
iklkililll xcxcxccS ...2211 gdzie: Sl — wynikowa wartość klasyfikacyjna, l — indeks grupy, k — liczba zmiennych przyjętych do analizy, clj — waga dla j-tej zmiennej przy obliczaniu wartości kwalifikacyjnych dla
l-tej grupy, xik — wartość obserwowana dla danej jednostki (i-tej) i dla j-tej zmiennej.

66 Wiadomości Statystyczne nr 1 (668), 2017 Dla każdej grupy wyznacza się funkcję klasyfikacyjną. Daną jednostkę przy-pisuje się do grupy, dla której ma ona największą wartość klasyfikacyjną.
ZMIENNE DIAGNOSTYCZNE Na podstawie danych GUS dla 2013 r., dotyczących: ochrony środowiska, ak-tywności zawodowej, dochodów, sytuacji mieszkaniowej, edukacji i warunków socjalnych ludności oraz przedsiębiorczości w podregionach Polski, zapropo-nowano listę zmiennych diagnostycznych. Zmienne te zawiera zestawienie (1).
ZESTAWIENIE (1) ZMIENNYCH DIAGNOSTYCZNYCH
Zmienne Charakterystyka zmiennych
x1 ................. ludność korzystająca z oczyszczalni ścieków w %ludności ogółem
x2 ................. redukcja zanieczyszczeń powietrza w % zanie-czyszczeń wytworzonych
x3 ................. odpady komunalne zebrane na mieszkańca w kg x4 ................. liczba ludności na pracującego x5 ................. bezrobotni zarejestrowani ogółem w tys. osób x6 ................. stopa bezrobocia w % x7 ................. przeciętne miesięczne wynagrodzenie brutto w zł x8 ................. sieć rozdzielcza wodociągowa w km/100 km2 x9 ................. sieć rozdzielcza kanalizacyjna w km/100 km2 x10 ................ sieć rozdzielcza gazowa w km/100 km2 x11 ................ przeciętna powierzchnia użytkowa mieszkania w m2
x12 ................ przeciętna powierzchnia użytkowa na mieszkańcaw m2
x13 ................ liczba ludności na 1 łóżko w szpitalach ogólnych x14 ................ liczba czytelników bibliotek na 1 tys. ludności x15 ................ liczba uczniów liceów/liczba ludności ogółem x16 ................ liczba uczniów techników/liczba ludności ogółem x17 ................ liczba studentów/ liczba ludności ogółem x18 ................ miejsca na widowni w kinach na 1 tys. ludności x19 ................ produkcja sprzedana przemysłu na mieszkańca w złx20 ................ podmioty gospodarki narodowej ogółem wpisane
do rejestru REGON x21 ................ podmioty gospodarki narodowej na 10 tys. ludności
Ź r ó d ł o: opracowanie własne na podstawie danych GUS.
Zmienne x4, x5 i x6 są destymulantami. Poprzez przemnożenie ich wartości przez minus jeden dokonano przekształcenia w stymulanty. Wstępnie przydzielono podregiony do 7 obszarów (grup, l = 1+3,322 log n 7). Skład poszczególnych grup ustalono na podstawie analizy wartości zmiennych diagnostycznych dotyczących bezrobocia i wynagrodzeń. Podregiony o zbliżo-nych wartościach tych zmiennych przypisano do tego samego obszaru. Następnie zgodnie z założeniami analizy dyskryminacyjnej wykonano testy 2 i Kołmogorowa-Smirnowa służące do oceny normalności rozkładu. Zmienne: x1, x3, x4, x5, x6, x7, x11, x12, x13 i x21 reprezentują wielowymiarowy rozkład normalny. Tabl. 1 zawiera wyniki testów dotyczących zmiennych o rozkładzie normalnym.
J. Zaród Zróżnicowanie podregionów Polski... 67
TABL. 1. TESTY ROZKŁADU NORMALNEGO
Zmienne Test 2 Test Kołmogorowa-Smirnowa
H p D p
x1 ............................................................ 2,7121 0,6071 0,0633 0,9391x3 ............................................................ 1,6995 0,8889 0,0777 0,7913x4 ............................................................ 9,0404 0,1075 0,0767 0,8033x5 ............................................................ 4,5682 0,3345 0,0982 0,5162x6 ............................................................ 4,8485 0,3032 0,0881 0,6520x7 ............................................................ 9,3211 0,0963 0,1459 0,0715x11 ........................................................... 1,1624 0,7621 0,1010 0,4804x12 ........................................................... 1,8788 0,7580 0,0897 0,6303x13 ........................................................... 10,6363 0,0907 0,1534 0,0804x21 ........................................................... 1,4419 0,9197 0,0766 0,8054
U w a g a. H, D — wartości testu, p — prawdopodobieństwo testowe o zgodności rozkładu normalnego.
Ź r ó d ł o: obliczenia własne wykonane za pomocą pakietu Statistica.
Prawdopodobieństwo testowe większe od poziomu istotności = 0,05 świad-czy o braku podstaw do odrzucenia hipotezy o zgodności rozkładu z rozkładem normalnym. Dalsze ograniczenie listy zmiennych nastąpiło na podstawie oceny ich mocy dyskryminacyjnej za pomocą testów Lambda Wilksa i F. Wyniki badania przed-stawia tabl. 2.
TABL. 2. ZMIENNE O WYSOKIEJ MOCY DYSKRYMINACYJNEJ
Zmienne Lambda Wilksa
CząstkowyLambda Wilksa
F p Tolerancja 1-Tolerancja (R kwadrat)
x1 .............................................. 0,0095 0,5427 7,4420 0,0000 0,4201 0,5799x4 .............................................. 0,0108 0,4764 9,7070 0,0000 0,3446 0,6554x6 .............................................. 0,0146 0,3526 16,2198 0,0000 0,2937 0,7063x7 .............................................. 0,0065 0,7901 2,3472 0,0439 0,9113 0,0887x11 ............................................. 0,0097 0,5304 7,8214 0,0000 0,3710 0,6290x12 ............................................. 0,0077 0,6649 4,4510 0,0010 0,6003 0,3997x21 ............................................. 0,0075 0,6822 4,1156 0,0018 0,4666 0,5334
Ź r ó d ł o: jak przy tabl. 1.
Przedstawione współczynniki Lambda Wilksa oraz współczynniki cząstkowe Lambda Wilksa są wartościami końcowymi, które otrzymano po wprowadzeniu do modelu kolejno wszystkich 7 zmiennych. Wskazują one na wysoką moc dys-kryminacyjną zarówno całego modelu, jak i poszczególnych zmiennych. Naj-większy wkład do dyskryminacji (najwyższe wartości statystyki F) różnych obszarów mają zmienne x6, x4, x11 i x1. Prawdopodobieństwo testowe p0 potwierdza hipotezę, że wszystkie zmienne są istotne w modelu opisującym zróżnicowanie obszarów utworzonych z podre-gionów. Najwyższa wartość tolerancji równa 0,9113 i R kwadrat równy 0,0887 dla zmiennej x7 oznaczają, że 91,13% informacji wnoszonych przez tę zmienną nie jest powielanych przez pozostałe zmienne znajdujące się już w modelu. Naj-mniej dodatkowych informacji dostarcza zmienna x6.

68 Wiadomości Statystyczne nr 1 (668), 2017 Zmienne o wysokiej mocy dyskryminacyjnej dotyczą: zatrudnienia, bezrobo-cia, warunków mieszkaniowych i wynagrodzenia za pracę. Informacje dostar-czane przez te zmienne charakteryzują wyłonione obszary, różnicują je i wska-zują te, które są zagrożone ubóstwem.
WYNIKI ESTYMACJI FUNKCJI DYSKRYMINACYJNEJ Spośród 6 funkcji dyskryminacyjnych oszacowanych na podstawie zmien-nych o wysokiej mocy dyskryminacyjnej wybrano jedną o najwyższej wariancji międzygrupowej. Funkcja ta ma postać: F = 0,4910x1+ 0,0776x4+1,1047x6+0,3394x7 – 0,7740x11+0,0967x12 – 0,2289x21
Wyjaśnia ona 70,2% wariancji międzygrupowej oraz ma najniższą wartość testu Lambda Wilksa (0,0051). Największy wpływ na kształtowanie się wartości tej funkcji mają zmienne x6 oraz x11. Do oceny wpływu poszczególnych zmiennych na tworzenie funkcji dyskryminacyjnych zastosowano współczynniki standaryzowa-ne. Współczynniki te mogą być wykorzystane do obliczenia wartości kanonicznych (wartości funkcji dyskryminacyjnej) dla każdej jednostki i przeciętnych dla każde-go obszaru (tabl. 3) oraz do uszeregowania tych obszarów (Zawadzki, 1999).
TABL. 3. WARTOŚCI ŚREDNIE FUNKCJI DYSKRYMINACYJNEJ WEDŁUG OBSZARÓW
Obszary Średnie wartości
kanoniczne
I ...................................... –3,9058II ..................................... –1,6015III .................................... –1,5640IV .................................... –0,9360V ..................................... 1,5449VI .................................... 4,3921VII .................................. 8,1063
Ź r ó d ł o: jak przy tabl. 1. Najniższa przeciętna wartość funkcji dyskryminacyjnej wskazuje obszar naj-słabiej rozwinięty pod względem badanych cech. Najwięcej osób zamieszkują-cych ten obszar jest zagrożonych ubóstwem i wykluczeniem społecznym. Wraz ze wzrostem przeciętnych wartości kanonicznych obszarów poprawia się sytua-cja finansowa, społeczna i mieszkaniowa osób z tych obszarów. Średnie wartości funkcji dyskryminacyjnej znacznie różnicują wyodrębnio-ne obszary, z wyjątkiem obszarów II i III. Między nimi średnie wartości kano-niczne są zbliżone, co świadczy o dużym podobieństwie podregionów wcho-dzących w ich skład.
KLASYFIKACJA PODREGIONÓW Metody klasyfikacyjne przyporządkowują dany podregion do utworzonych obszarów na podstawie zmiennych, które miały wysoką moc dyskryminacyjną. Duże zróżnicowanie warunków gospodarczych, ekonomicznych i społecz-nych w Polsce wskazuje, że tworzone obszary będą skupiały różną liczbę jedno-

J. Zaród Zróżnicowanie podregionów Polski... 69
stek. W tym celu do klasyfikacji podregionów zastosowano prawdopodobień-stwo a priori, proporcjonalne do wielkości grup. Dla każdego obszaru oszaco-wano funkcje klasyfikacyjne, a poszczególne podregiony przyporządkowano do obszarów, dla których miały one największą wartość klasyfikacyjną. Wstępny podział w 80,3% został potwierdzony przez analizę klasyfikacyjną, co wraz z sugerowanymi zmianami przedstawia tabl. 4.
TABL. 4. WYNIKI KLASYFIKACJI WSTĘPNEJ
Obszary Poprawność
klasyfikacji w %
Liczba podregionów w poszczególnych obszarach
I II III IV V VI VII
I ................................................ 87,50 7 1 x x x x xII .............................................. 83,33 x 10 2 x x x xIII ............................................. 86,67 x 2 13 x x x xIV ............................................. 63,64 x x 2 7 2 x xV .............................................. 62,50 x x x 3 5 x xVI ............................................. 83,33 x x x x 1 5 xVII ........................................... 100,00 x x x x x x 6Średnia ..................................... 80,30 7 13 17 10 8 5 6
U w a g a. Wiersze — klasyfikacja wstępna, kolumny — podział na podstawie funkcji klasyfikacyjnych.
Ź r ó d ł o: jak przy tabl. 1.
Wstępnie, bezbłędnie przypisano podregiony do obszaru VII (100%), najmniej-szy odsetek trafnych klasyfikacji wystąpił natomiast w obszarach V (62,5%) i IV (63,64%). Po dokonaniu zmian, zgodnie z sugerowaną klasyfikacją, ponownie oszacowa-no funkcje klasyfikacyjne i obliczono wartości tych funkcji dla każdego podregio-nu. Procedurę tę powtarzano aż do uzyskania 100% poprawności klasyfikacji. Tabl. 5 przedstawia współczynniki funkcji klasyfikacyjnych, na podstawie których dokonano ostatecznego podziału podregionów na obszary.
TABL. 5. WSPÓŁCZYNNIKI ZMIENNYCH FUNKCJI KLASYFIKACYJNYCH WEDŁUG OBSZARÓW
Zmienne I II III IV V VI VII
x1 ........................ –0,5673 4,0386 –3,3322 –4,2701 1,5410 6,1751 6,1698x4 ........................ 3,5741 6,1451 –1,4459 –6,4698 –3,2295 2,0526 2,9246x6 ........................ –15,1079 –10,2765 –1,1845 2,8683 7,1011 9,1054 15,5272x7 ........................ 5,5132 5,1421 0,2519 2,5813 –2,7208 –5,2179 –8,9572x11 ....................... –3,2786 –3,9356 0,7139 3,3536 2,4103 –0,8036 0,1772x12 ....................... 2,9953 0,2264 0,3409 2,3751 –3,4598 –3,3156 –0,6356x21 ........................ –1,5134 –0,3857 –1,6596 0,6934 1,1499 2,0437 5,0008Stała ................... –13,5819 –8,1303 –2,8016 –9,7944 –5,0367 –13,3517 –36,1211
Ź r ó d ł o: jak przy tabl. 1.
Im wyższa wartość bezwzględna współczynników stojących przy zmiennych, tym wyższy wpływ tych zmiennych na tworzenie funkcji klasyfikacyjnych, jak również na klasyfikację danego podregionu do odpowiedniego obszaru. W obszarach: I, II, V, VI i VII duży wpływ na ostateczny podział podregio-nów miała stopa bezrobocia. Od liczby ludności przypadającej na pracującego

70 Wiadomości Statystyczne nr 1 (668), 2017 klasyfikacja zależała w obszarach od I do V. Przeciętne miesięczne wynagro-dzenie brutto odegrało dużą rolę w kategoryzacji obszarów: I, II, VI i VII, nato-miast przeciętna powierzchnia mieszkania w znacznej mierze decydowała o podziale niemal we wszystkich obszarach, tj. z wyjątkiem obszarów III i V. W obszarach: III, IV, VI i VII na klasyfikację wpłynęła również liczba ludności korzystającej z oczyszczalni ścieków. Wyniki ostatecznej kwalifikacji zawiera tabl. 6.
TABL. 6. WYNIKI KLASYFIKACJI KOŃCOWEJ
Obszary Poprawność
klasyfikacji w %
Liczba podregionów według obszarów
I II III IV V VI VII
I ................................................ 100 7 x x x x x xII .............................................. 100 x 8 x x x x xIII ............................................. 100 x x 25 x x x xIV ............................................. 100 x x x 7 x x xV .............................................. 100 x x x x 7 x xVI ............................................. 100 x x x x x 6 xVII ........................................... 100 x x x x x x 6
Ź r ó d ł o: jak przy tabl. 1.
Klasyfikację podregionów do odpowiednich obszarów przedstawia zestawie-nie (2).
ZESTAWIENIE (2) PRZYPORZĄDKOWANIA PODREGIONÓW
DO POSZCZEGÓLNYCH OBSZARÓW
Obszary Podregiony
I ................... grudziądzki, włocławski, radomski, elbląski, ełcki,koszaliński, stargardzki
II ................. krośnieński, przemyski, rzeszowski, tarnobrzeski,słupski, starogardzki, kielecki, olsztyński
III ................ jeleniogórski, wałbrzyski, bielski, chełmsko-zamoj-ski, puławski, gorzowski, zielonogórski, łódzki,piotrkowski, sieradzki, skierniewicki, nowosą-decki, oświęcimski, tarnowski, ciechanowsko--płocki, ostrołęcko-siedlecki, nyski, łomżyński, suwalski, częstochowski, sandomiersko-jędrze-jowski, kaliski, koniński, leszczyński, pilski
IV ................ wrocławski, krakowski, warszawski wschodni, war-szawski zachodni, gdański, poznański, szczeciński
V ................. lubelski, opolski, białostocki, bielski, bytomski, rybnicki, sosnowiecki
VI ................ legnicko-głogowski, bydgosko-toruński, miasto Łódź, gliwicki, tyski, miasto Szczecin
VII .............. miasto Wrocław, miasto Kraków, miasto Warsza-wa, trójmiejski, katowicki, miasto Poznań
Ź r ó d ł o: opracowanie własne przy zastosowaniu pakietu Statistica.
Dokładne rozmieszczenie obszarów na terenie Polski przedstawia wykr. 1.

J. Zaród Zróżnicowanie podregionów Polski... 71
CHARAKTERYSTYKA PODREGIONÓW O NAJWIĘKSZEJ LICZBIE LUDNOŚCI ZAGROŻONEJ UBÓSTWEM
O zakwalifikowaniu podregionów do obszaru I, którego mieszkańcy są zagro-żeni ubóstwem i wykluczeniem społecznym, zadecydowały: stopa bezrobocia, przeciętne miesięczne wynagrodzenie brutto, liczba ludności przypadającej na jednego pracującego oraz przeciętna powierzchnia użytkowa mieszkania w 2013 r. Wysokość stopy bezrobocia w poszczególnych podregionach obszaru I przed-stawia wykr. 2.
Wykr. 1. PODZIAŁ POLSKI NA OBSZARY
Ź r ó d ł o: opracowanie własne.
Kategorie obszarów:
I
II
III
IV
V
VIVII

72 Wiadomości Statystyczne nr 1 (668), 2017
grudziądzki włocławski radomski elbląski ełcki koszaliński stargardzki
30%
25
20
15
10
5
0
Wykr. 2. STOPA BEZROBOCIA PODREGIONÓW I OBSZARU
Ź r ó d ł o: opracowanie własne na podstawie danych GUS.
21,10
23,8024,60
21,90
26,00
21,30
23,70
Ź r ó d ł o: jak przy wykr. 2.
grudziądzki włocławski radomski elbląski ełcki koszaliński stargardzki
3500zł
3400
3300
3200
3100
3000
100
0
Wykr. 3. PRZECIĘTNE MIESIĘCZNE WYNAGRODZENIE
3466,95
3109,813092,24
3111,75
3050,59
3242,92
3175,88
J. Zaród Zróżnicowanie podregionów Polski... 73
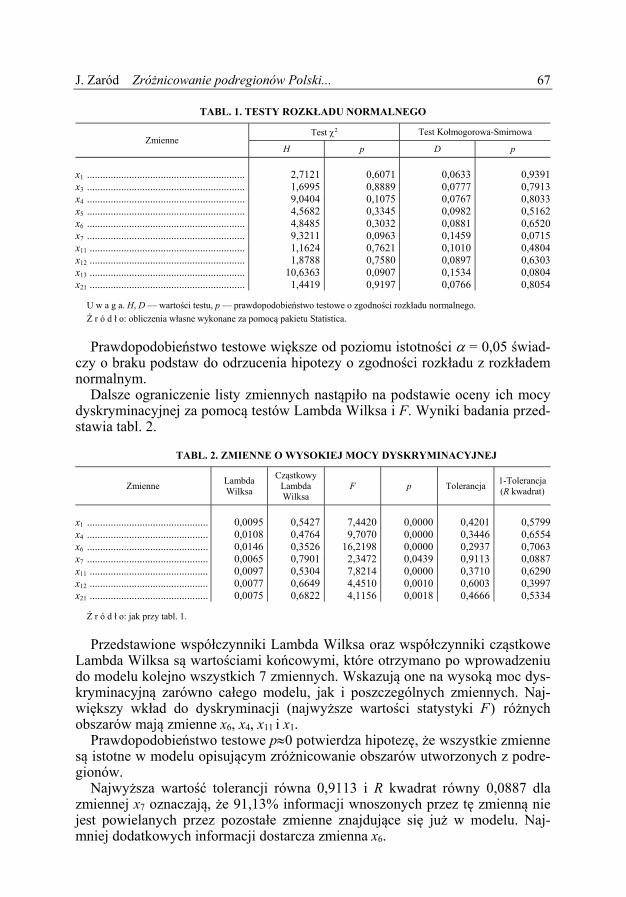
Wykr. 4. LICZBA LUDNOŚCI PRZYPADAJĄCA NA JEDNEGO ZATRUDNIONEGO
Ź r ó d ł o: jak przy wykr. 2.
3,42 3,413,20
3,52
3,90
3,57
4,17
0,0
1,0
2,0
3,0
4,0
0,5
1,5
2,5
3,5
4,5
grudziądzki włocławski radomski elbląski ełcki koszaliński stargardzki
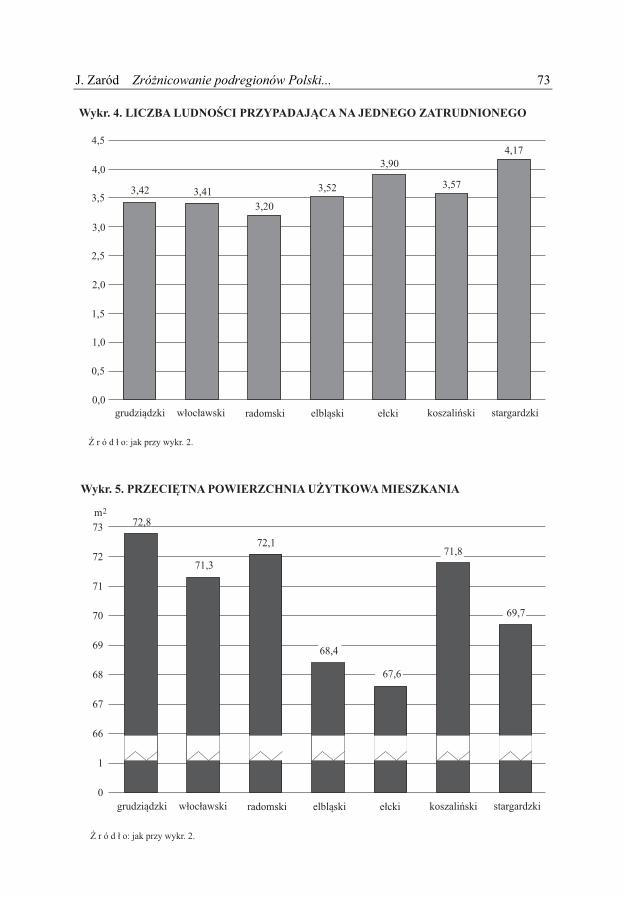
Wykr. 5. PRZECIĘTNA POWIERZCHNIA UŻYTKOWA MIESZKANIA
Ź r ó d ł o: jak przy wykr. 2.
0
1
66
67
68
69
70
71
72
73m2
72,8
71,3
72,1
68,4
71,8
69,7
67,6
grudziądzki włocławski radomski elbląski ełcki koszaliński stargardzki

74 Wiadomości Statystyczne nr 1 (668), 2017 W każdym podregionie należącym do obszaru I stopa bezrobocia przekraczała 20%, natomiast w obszarze VII mieściła się w granicach 4,2% (miasto Poznań)— —8,0% (podregion katowicki). Stopa bezrobocia w Polsce w 2013 r. wynosiła 13,4%. W podregionie ełckim, o najwyższej stopie bezrobocia, uzyskano najniższe przeciętne miesięczne wynagrodzenie brutto. Średnie miesięczne wynagrodzenie brutto w Polsce w 2013 r. wynosiło 3877,43 zł. W 2013 r. w Polsce średnio na jednego zatrudnionego przypadało 2,74 osoby. Najwyższa liczba ludności przypadającej na jednego zatrudnionego była w pod-regionie stargardzkim, a najniższa w Warszawie (1,6 osoby). Przeciętna powierzchnia użytkowa mieszkania w obszarze I wahała się od 67,6 do 72,8 m2. Najniższą w Polsce notowano w podregionie katowickim (51,7 m2), a najwyższą w podregionie krakowskim (93,8 m2). W Polsce przeciętna po-wierzchnia użytkowa mieszkania w 2013 r. wynosiła 73,1 m2.
Podsumowanie
W 2013 r. na podstawie zmiennych diagnostycznych dotyczących: ochrony środowiska, aktywności zawodowej, dochodów, sytuacji mieszkaniowej, eduka-cji, warunków socjalnych ludności oraz przedsiębiorczości w podregionach do-konano wstępnego podziału Polski na siedem obszarów. Do oszacowania funkcji dyskryminacyjnej wykorzystano tylko zmienne o rozkładzie normalnym i o wy-sokiej mocy dyskryminacyjnej. Duży wpływ na kształtowanie się wartości wybranej funkcji dyskryminacyj-nej miała stopa bezrobocia i przeciętna powierzchnia użytkowa mieszkania. Obliczone przeciętne wartości kanoniczne dla każdego obszaru pozwoliły usze-regować powstałe kompleksy od najsłabiej do najlepiej rozwiniętych pod wzglę-dem badanych cech. Trafność podziału potwierdził niski współczynnik testu Lambda Wilksa (0,0051). Następnie dla każdego obszaru oszacowano funkcje klasyfikacyjne, a podregiony przyporządkowano do obszarów, dla których miały największą wartość klasyfikacyjną. O przyporządkowaniu podregionów do obszaru I, w którym największa liczba mieszkańców była zagrożona ubóstwem i wykluczeniem społecznym, zadecy-dowały zmienne: stopa bezrobocia, przeciętne miesięczne wynagrodzenie brutto, liczba ludności przypadającej na jednego zatrudnionego oraz przeciętna po-wierzchnia użytkowa mieszkania. Stopa bezrobocia w każdym podregionie nale-żącym do obszaru I przekraczała 20%, natomiast w podregionie ełckim wynosiła nawet 26%, przy czym dla Polski stopa bezrobocia rejestrowanego w grudniu 2013 r. wynosiła 13,4%. Przeciętne miesięczne wynagrodzenie brutto w Polsce w analizowanym roku wynosiło 3877,43 zł, a w obszarze I wahało się od 3050,59 do 3466,95 zł. W obszarze VII było znacznie wyższe i sięgało 5226,05 zł w Warszawie. Najwyższa liczba ludności przypadającej na jednego zatrudnione-

J. Zaród Zróżnicowanie podregionów Polski... 75
go (4,17 osoby) była w podregionie stargardzkim (obszar I). Średnio w Polsce na jednego zatrudnionego w 2013 r. przypadało 2,76 osoby. Przeciętna po-wierzchnia użytkowa mieszkania w obszarze I mieściła się w granicach 67,6— —72,8 m2 i była tylko nieznacznie niższa niż w Polsce (73,1 m2). Analiza dyskryminacyjna pozwoliła podzielić Polskę na obszary różniące się od siebie pod względem wybranych zmiennych. Wskazała na podregiony, w których największa liczba ludności była zagrożona ubóstwem w 2013 r. Me-toda ta może więc być wykorzystywana jako narzędzie wspomagające badanie zróżnicowania poziomu życia społeczeństwa, a także może przyczynić się do kreowania polityki społecznej i gospodarczej w analizowanych podregionach. dr Jadwiga Zaród — Zachodniopomorski Uniwersytet Technologiczny w Szczecinie
LITERATURA
Frąckiewicz, L. (2005). Wykluczenie społeczne w skali makro- i mikroregionalnej. W: L. Frąc-kiewicz (red.), Wykluczenie społeczne, s. 11—26, Katowice: Wydawnictwo Akademii Ekono-micznej im. Karola Adamieckiego w Katowicach.
Gatnar, E. (1998). Symboliczne metody klasyfikacji danych. Warszawa: PWN.
Golinowska, S. (2010). Polityka wobec ubóstwa i wykluczenia społecznego w Polsce w minionym dwudziestoleciu. Polityka Społeczna, nr 9, s. 7—13.
GUS (2015). Rocznik Statystyczny Województw 2014. Warszawa: GUS.
Krzyśko, M. (1990). Analiza dyskryminacyjna. Warszawa: WNT.
Krzyśko, M. (2004). Statystyka matematyczna. Poznań: Wydawnictwo Naukowe UAM.
Nazarczuk, J. (2013). Potencjał rozwojowy a aktywność inwestycyjna województw i podregionów Polski. Olsztyn: Wydawnictwo Uniwersytetu Warmińsko-Mazurskiego.
Panek, T. (2014). Statystyka społeczna. Warszawa: PWE.
Sen, A. (1992). Inequality Reexamined. Oxford: Publisher Oxford University Press.
Sobczyk, M. (2015). Statystyka. Warszawa: PWN.
Szarfenberg, R. (2012). Ubóstwo i wykluczenie społeczne w Polsce: pomiar, wyjaśnienie, strategie przeciwdziałania. Pobrano z: http://rszarf.ips.uw.edu.pl/pdf/uiws2012a.pdf (dostęp 15.05.2015 r.).
Szukiełojć-Bieńkuńska, A. (2011). Ubóstwo w Polsce na tle krajów UE — podstawowe fakty i dane. Pobrano z: http://www.eapn.org.pl/expert/files/Ubostwo_w_Polsce_na_tle_krajow_UE- -A.Sz-B.pdf (pobrano 15.05.2015 r.).
Townsend, P., Gordon, D. (2000). Breadline Europe: the measurement of poverty. Bristol: Policy Press.
US Poznań (2014), Mapa ubóstwa na poziomie podregionów w Polsce z wykorzystaniem estymacji pośredniej. Pobrano z: http://stat.gov.pl/z-prac-studialnych/mapy-ubostwa-na-poziomie-podre-gionow-w-polsce-z-wykorzystaniem-estymacji-posredniej,4,1.html (pobrano 5.06.2015 r.).
Winiarczyk-Raźniak, A. (2014). Wymiary poziomu życia w Polsce w świetle wybranych wskaźni-ków. W: E. Kaczmarska, P. Raźniak (red.), Społeczno-ekonomiczne i przestrzenne przemiany struktur regionalnych, s. 116—129, Kraków: Oficyna Wydawnicza AFM.
Zawadzki, J. (1999). Zastosowanie analizy dyskryminacyjnej dla wielu populacji do badania kondycji finansowej firm. Szczecin: Wydawnictwo Zapol.
Zeliaś, A. (2000). Metody statystyczne. Warszawa: PWE.

76 Wiadomości Statystyczne nr 1 (668), 2017 Summary. This article aims to show the diversity of the development of sub- -regions in Poland in view of the selected features and to characterize the areas with the highest risk of poverty. The Polish sub-regions were described using data for 2013, depicting economic, social and housing conditions of the Polish population as well as its economic activity. These data were standardized and — using discriminant function — sub-regions were grouped in 7 areas. The areas I and II, based on the value of the discriminant function, were classified as areas of the risk of poverty and social exclusion. Then, for each area classification functions were estimated. Each sub-region was assigned to the area for which it has the greatest classification value. It was found that the greatest impact on the final classification of sub-regions have following indicators: the unemployment rate, population per 1 employee and the average size of the apartment. Keywords: discriminant analysis, poverty, sub-regions.







