driving style and behavior analysis based on trip segmentation over gps information. comparison of...
TRANSCRIPT

Driving Style Analysis based on Trip Segmentation.
A Comparative Multi-Technique ApproachMarco Brambilla, Andrea Mauri, Paolo Mascetti
@marcobrambi

Agenda
IntroProblem DefinitionDatasetData Exploration and PreliminariesTrip Segmentation TechniquesValidation Conclusions
Intro: Relevance1.24 million traffic-related fatalities occur annually world wideCurrently the leading cause of death for people aged between 15 and 29 yearsMajority of cases due to improper or risky driving behavior
Source: World Health Organisation (WHO)
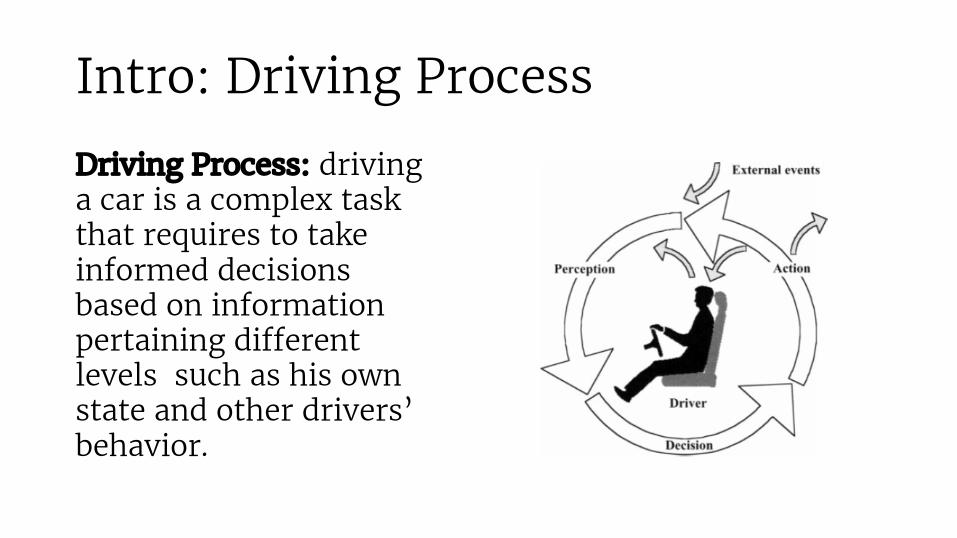
Intro: Driving Process
Driving Process: driving a car is a complex task that requires to take informed decisions based on information pertaining different levels such as his own state and other drivers’ behavior.
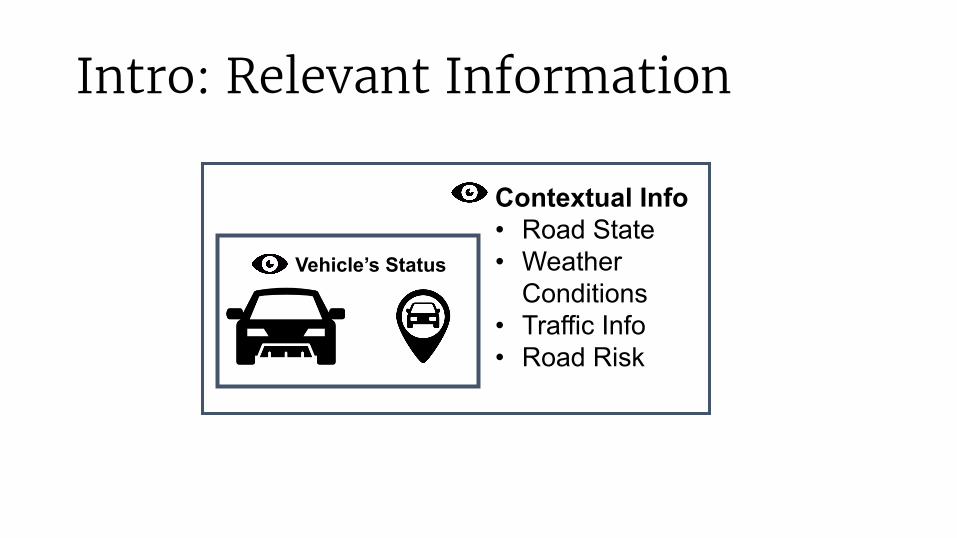
Intro: Relevant Information
Vehicle’s Status
Contextual Info• Road State• Weather
Conditions• Traffic Info• Road Risk• Traffic

Problem Statement
Data-driven driver profilingwith respect to driving risk
Essentially: Multivariate Time Series Segmentation
Application scenarios in insurance, promotingpay-how-you-drive (PHYD) business models

State of the Art and Challenges
State of the art: many works on identification and recognition of behavioural patterns (line following, accelerations, braking etc) and maneuversrecognition, behavioural scoring, prediction of driver intentions.
Supervised Learning techniques require intensive end expensive gathering process.

Proposed Solution
Unsupervised techniques to profile drivers behaviour based on identified recurrent patternson driving path segmentationComparison of 3 different approaches and use of all of them for consolidated results
1. Unsupervised Segmentation Based on Clustering2. Unsupervised Segmentation Based on HMM3. Unsupervised Topic Extraction

Contextual Scenes
Observed driving behaviours that are repeated in each driver's behaviour and also across different drivers.A reduced representation of the original Multivariate Time Series conveying a simplified characterizationFurther reasoning is then applied

ETL Process3 Steps:
Extract: read collected files and selection of candidate featuresTransform:
Filter and Grouping Features computation
Load: produce a unique dataset
PreProcessing
Transform
Globaldataset.csv
Load
TripFile.csv
Extract
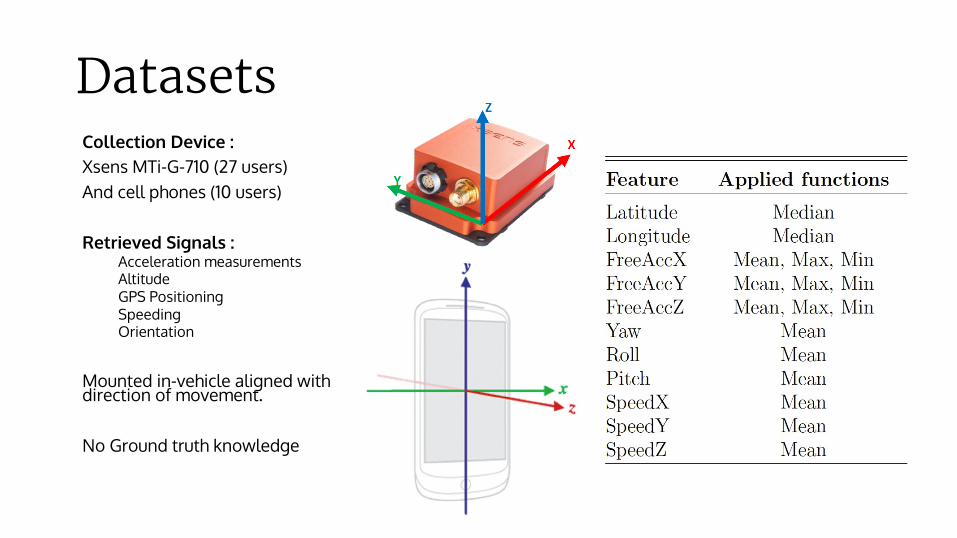
DatasetsCollection Device : Xsens MTi-G-710 (27 users)And cell phones (10 users)
Retrieved Signals : Acceleration measurementsAltitudeGPS PositioningSpeedingOrientation
Mounted in-vehicle aligned with direction of movement.
No Ground truth knowledge

Features Selected
Acceleration (on Y and X axes),Speed (on Y and X axes) Difference in yaw
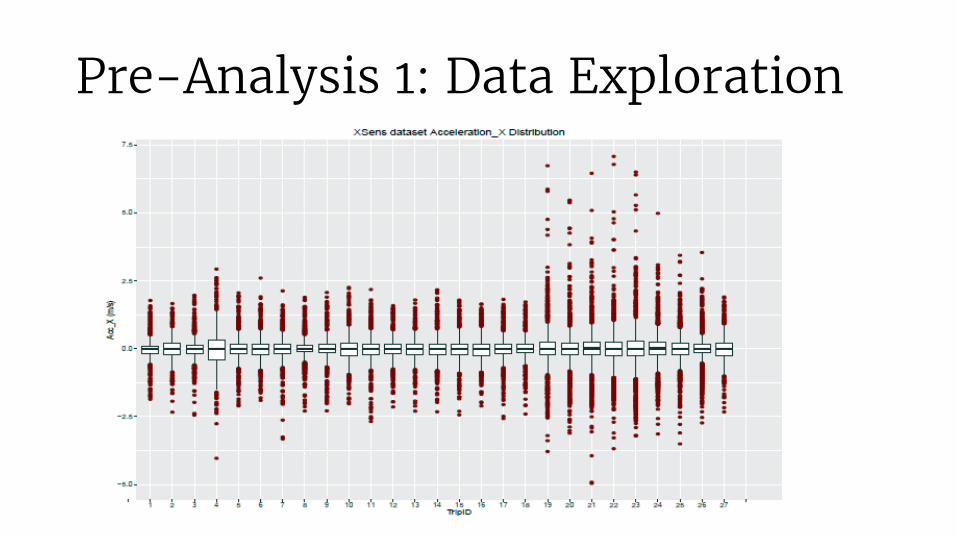
Pre-Analysis 1: Data Exploration
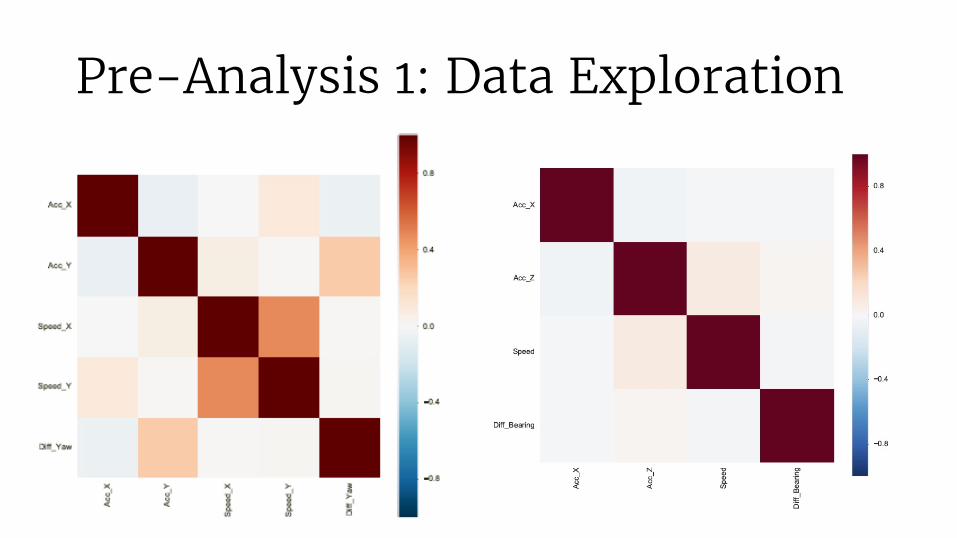
Pre-Analysis 1: Data Exploration

Pre-Analysis 2: Application of Driving Safety Existing AnalysesVaiana et.al. Propose a Driving Safety Diagram based on longitudinal and lateral accelerations analysis.
Aggressiveness Index formulation:(A = Aggressive, S = Safe points)
Graphical representation:

DP-Means

1. Unsupervised Segmentation Based on DP-Means Clustering
Problem: Bayesian nonparametric techniques require expensive sampling methods or variational techniques.
DP-means: proposed by Kulis et. al. revisiting k-means: K-means like objective function + penalty
A new cluster is created whenever a point is farther than λ away from every already existing centroid.
Note:Clustering results depends on data ordering.
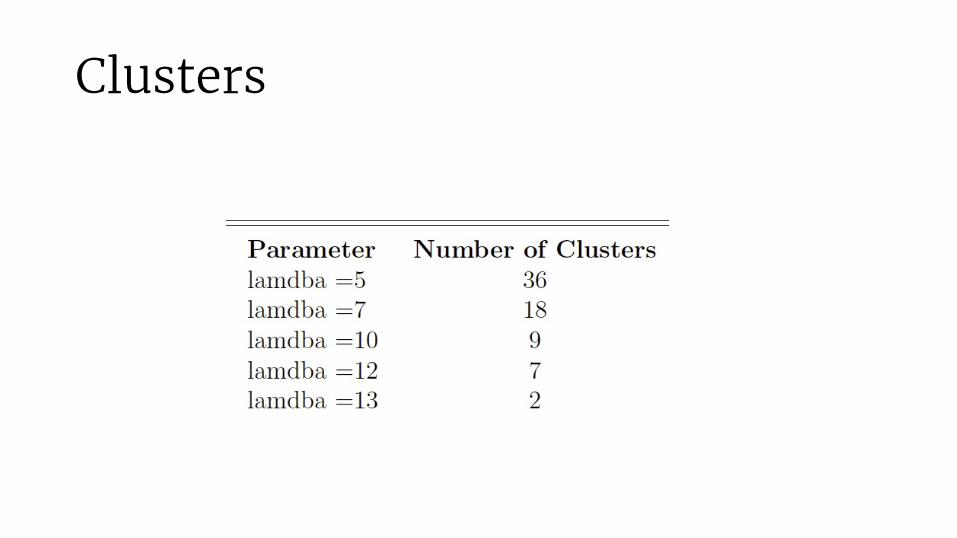
Clusters
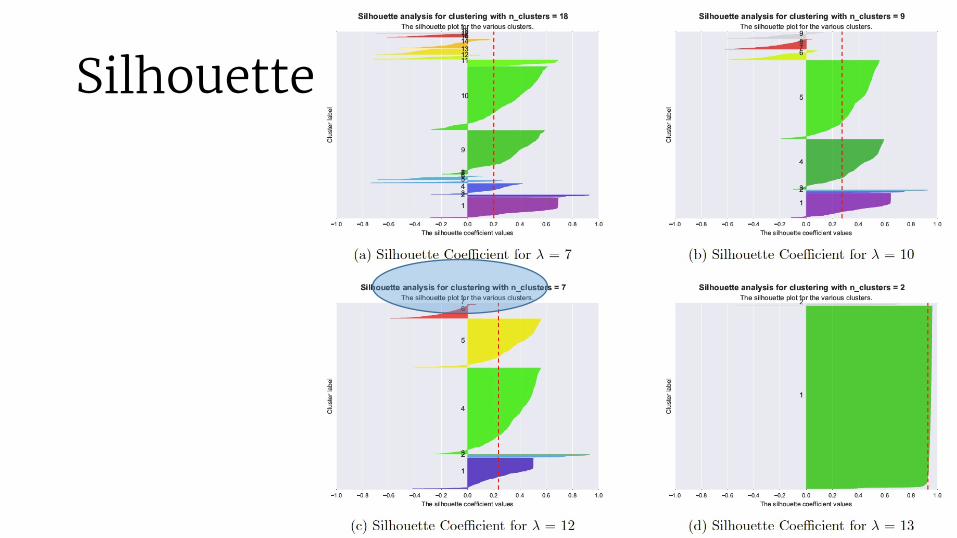
Silhouette

Results
Centroids

Results
Centroids

Distribution of features across clusters
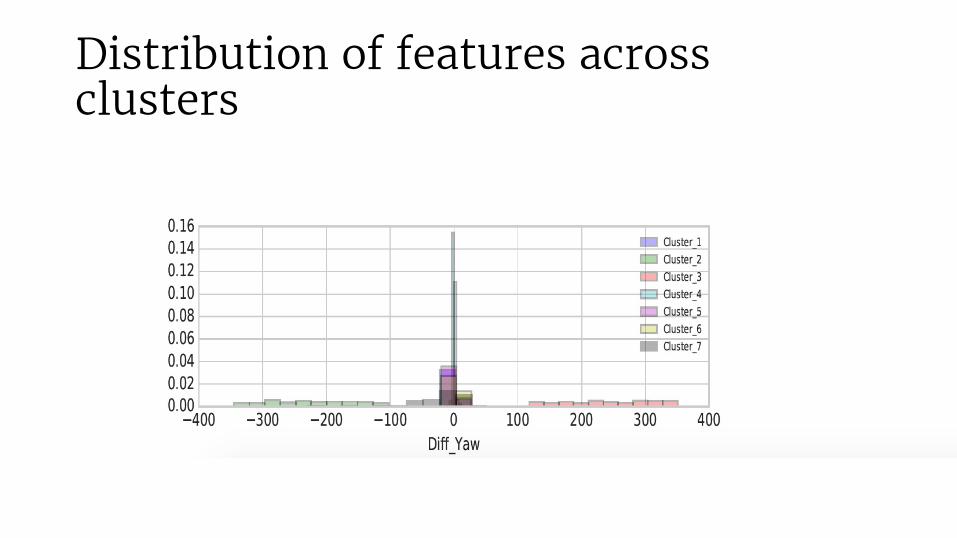
Distribution of features across clusters
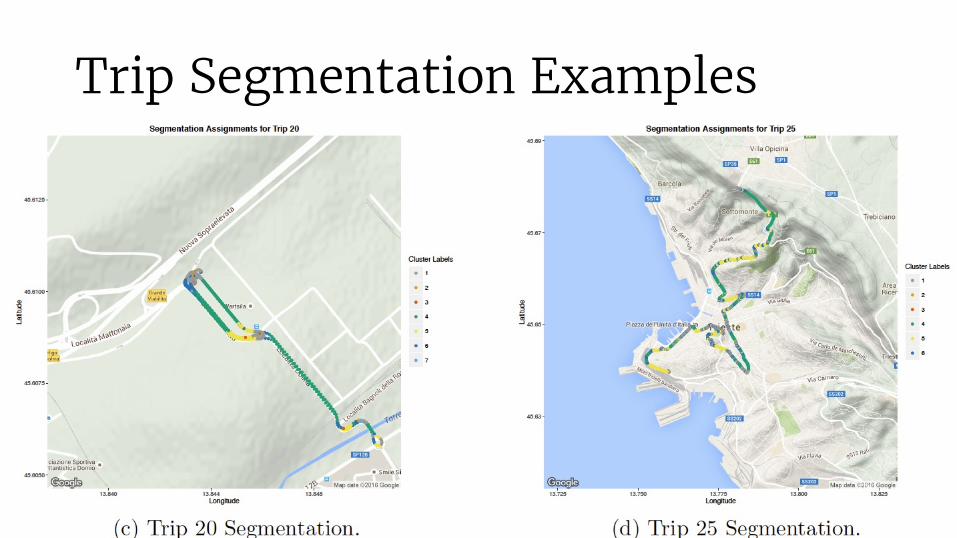
Trip Segmentation Examples

Trip Segmentation Examples

Hidden Markov Models
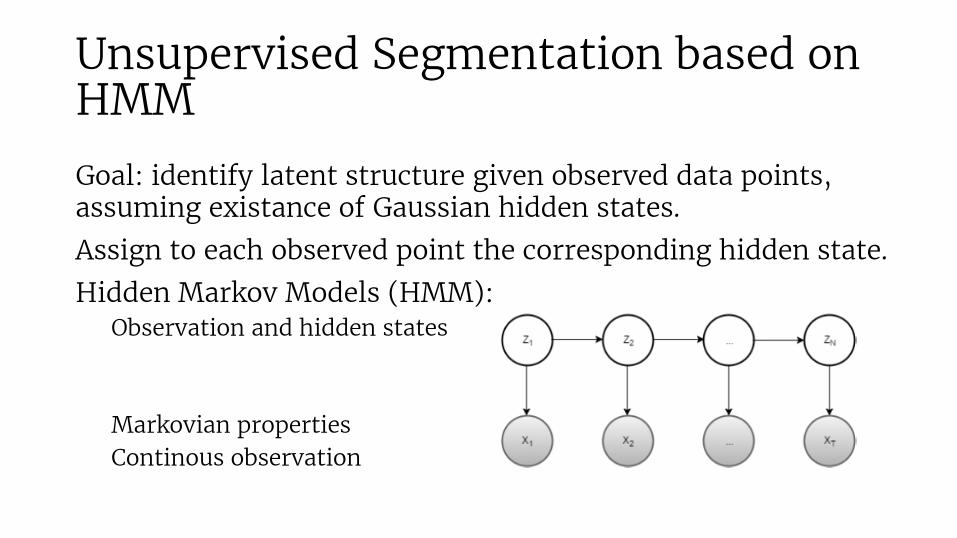
Unsupervised Segmentation based on HMM
Goal: identify latent structure given observed data points, assuming existance of Gaussian hidden states.Assign to each observed point the corresponding hidden state.Hidden Markov Models (HMM):
Observation and hidden states
Markovian propertiesContinous observation

Unsupervised Segmentation based on HMM
Training:Baum-Welch EM algorithm to learn model parameters
Decoding:Viterbi decoding to assign to each observed point the most likely hidden state
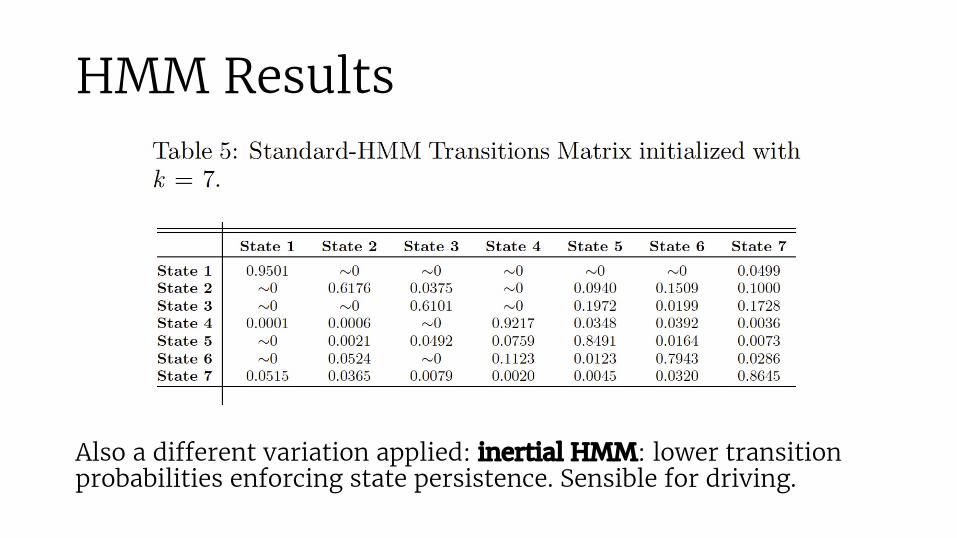
HMM Results
Also a different variation applied: inertial HMM: lower transition probabilities enforcing state persistence. Sensible for driving.
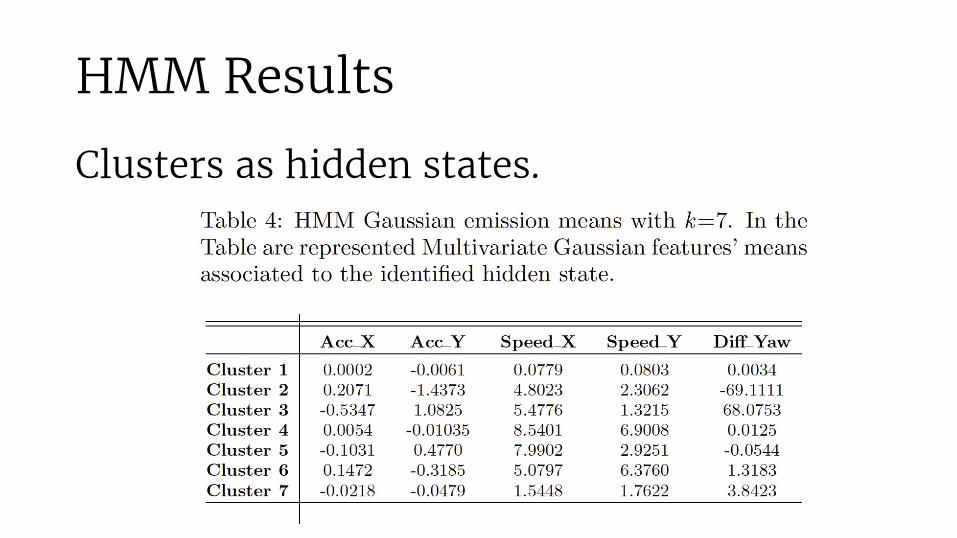
HMM Results
Clusters as hidden states.
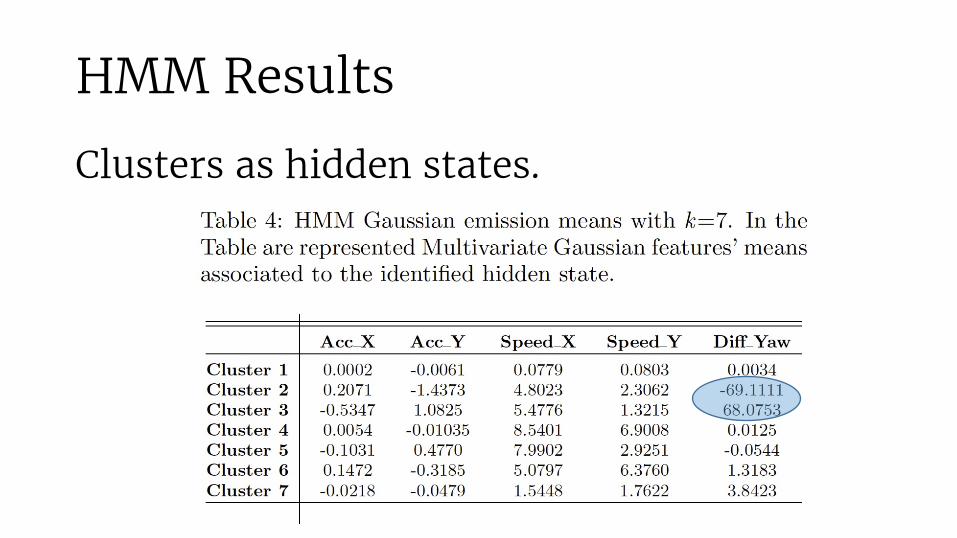
HMM Results
Clusters as hidden states.
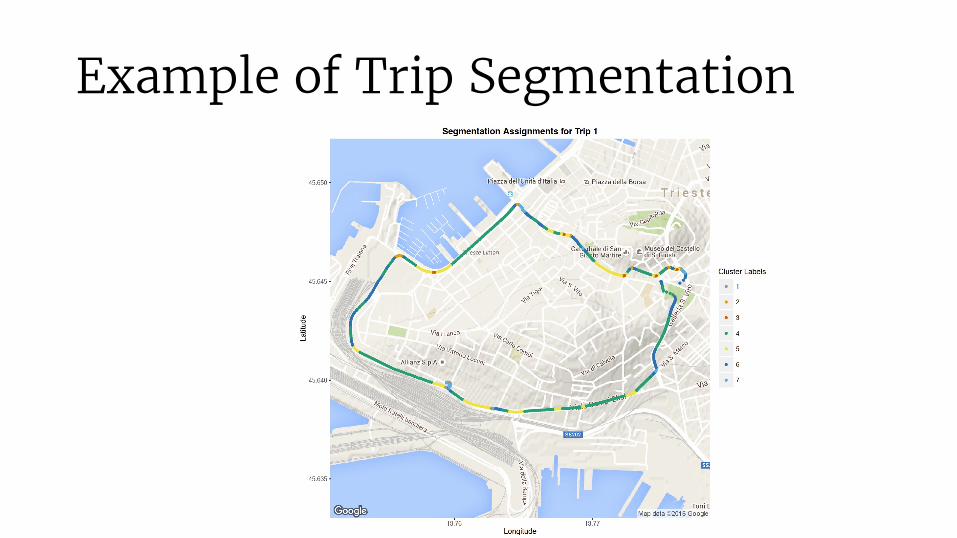
Example of Trip Segmentation

Topic Extraction

Topic Extraction ApproachWhat is topic extraction ?
Model topical concepts belonging to a set of textual documents.Data are described as documents and the components are distributions of terms that reflect recurring patterns, name Topics.
Hierarchical Dirichlet Processes (HDPs)soft-clustering technique based on non-parametric Bayesian theory.number of topics is not set a priori, but learned from data.Posteriori probability approximated by Variational Inference algorithm by Wang et.al.
Results:Most relevant topics for each document and terms distribution in each topic.
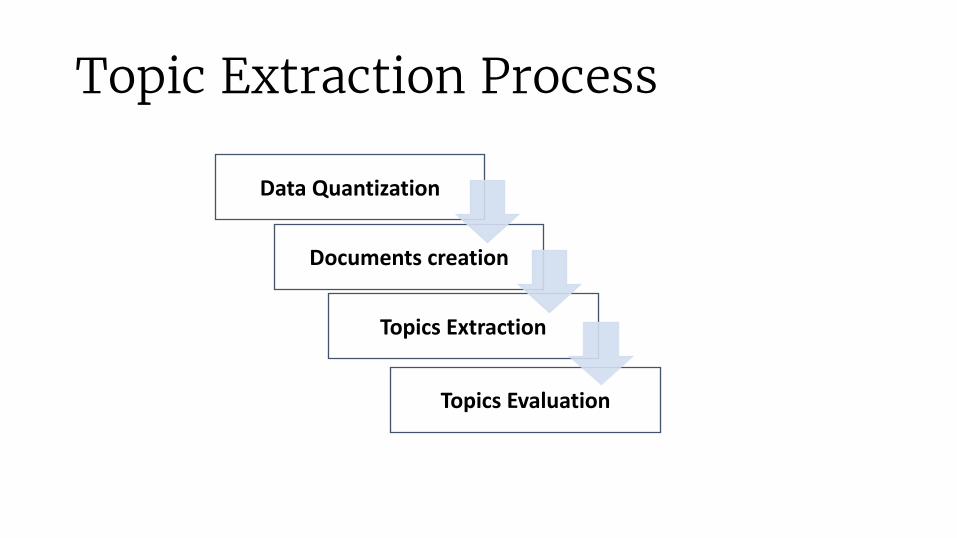
Topic Extraction Process
DataQuantization
Documents creation
TopicsExtraction
TopicsEvaluation

Quantization – Binning Processwith static binning strategy
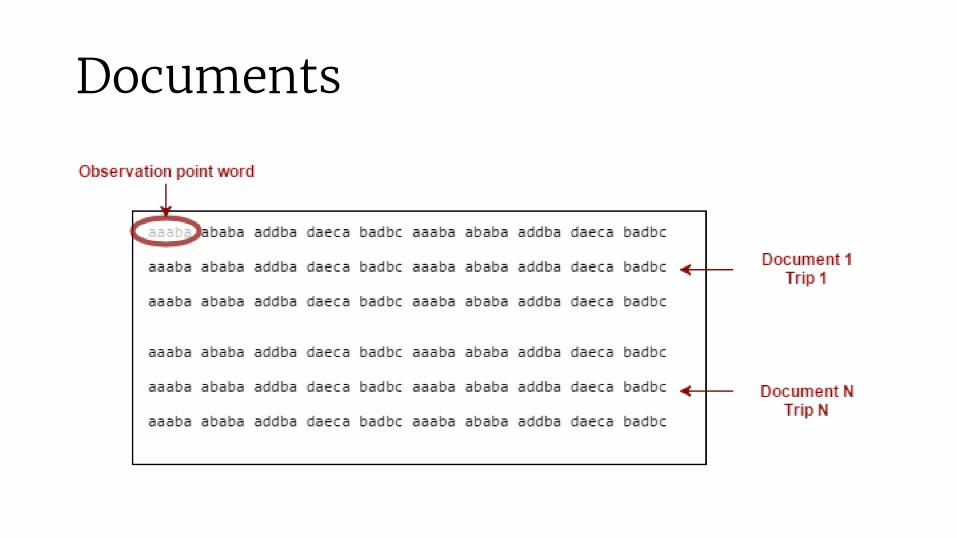
Documents

Terms Relevance on Top 7 Topics
Linguist…

Terms Relevance on Top 7 Topics
… and data analyst perspectives
…

Comparison and Validation

Big Issue: How to Compare?
1) Point-to-point or point distribution2) Resulting grouping of trips3) Perceived user similarity of trips

Solution 1: Point-to-Point
Overlap of clusters? Per trip? Overall?

Solution 1: Point-to-Point
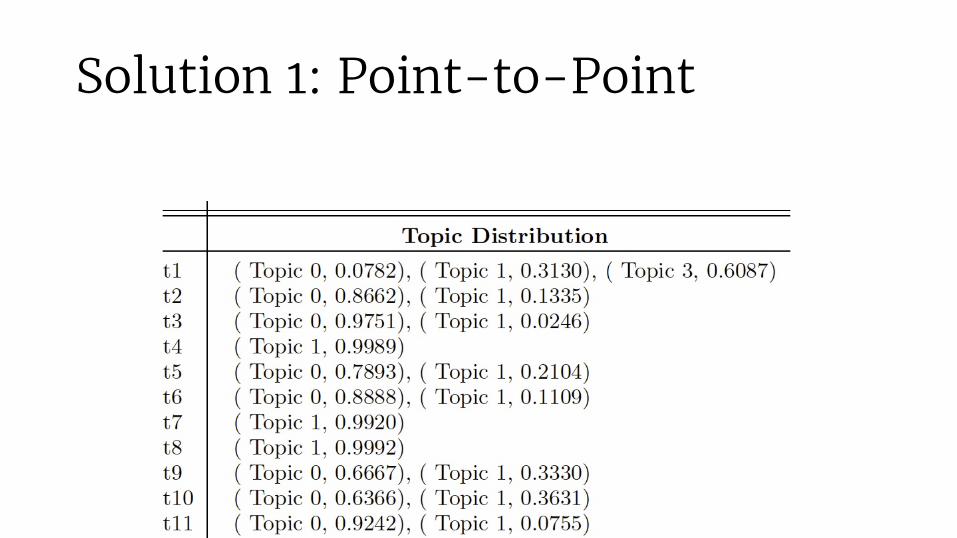
Solution 1: Point-to-Point

Solution 2: Moving from Points to TripsCan we cluster trips based on how observation points have been clustered?
à Simple K-means clustering of trips for each approach. à Comparison of overlap of the different clusters
Coherent with original question: grouping of trips (and thus drivers) by driving behavior

Result of overlap analysis
K-means with K=6 clusters.
DP-means vs. HMM: 74% overlapDP-means vs. Topic: 44% HMM vs. Topic: 48%

Human Validation of Trip Groups
Experts (knowledgeable about driving styles and driving paths recorded) identify possible groups of trips in the dataset
Problem: - Unable to distinguish 6 categories of groups- Only 3 categories are feasible- Best matching 6à3 categories for each method

Results

Conclusions
Three different clustering techniques of driving behavior over trips
-> segmentationClustering of trips based on behavior
-> up to 74% overlap over 6 clusters-> 100% overlap over 3 clusters
User Validation-> 96% precision over 3 clusters

Future Work
About collection process:Gathering process including contextual information (road risk, traffic status, weather conditions)Larger dataset to improve inference performance
About implemented methods:Smarter data ordering for DP-meansRelax independency assumption in HMMImprovements in data discretization process for HDP

Marco Brambilla, @marcobrambi, [email protected]
http://datascience.deib.polimi.it
Thanks! Questions?