dusd(labs) breaking down the memory wall for future scalable computing platforms wen-mei hwu...
Post on 21-Dec-2015
213 views
TRANSCRIPT

DUSD(Labs)
Breaking Down the Memory Wall Breaking Down the Memory Wall for Future Scalable Computing Platformsfor Future Scalable Computing Platforms
Wen-mei HwuWen-mei HwuSanders-AMD Endowed Chair ProfessorSanders-AMD Endowed Chair Professor
withwith
John W. Sias, Erik M. Nystrom, Hong-seok Kim, Chien-wei Li,John W. Sias, Erik M. Nystrom, Hong-seok Kim, Chien-wei Li,Hillery C. Hunter, Ronald D. Barnes, Shane Ryoo, Sain-Zee Ueng, Hillery C. Hunter, Ronald D. Barnes, Shane Ryoo, Sain-Zee Ueng,
James W. Player, Ian M. Steiner, Chris I. Rodrigues, Robert E. Kidd,James W. Player, Ian M. Steiner, Chris I. Rodrigues, Robert E. Kidd,Dan R. Burke, Nacho Navarro, Steven S. LumettaDan R. Burke, Nacho Navarro, Steven S. Lumetta
University of Illinois at Urbana-ChampaignUniversity of Illinois at Urbana-Champaign

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 22
Trends in hardwareTrends in hardware High variabilityHigh variability
Increasing speed and power Increasing speed and power variability of transistors variability of transistors
Limited frequency increaseLimited frequency increaseReliability / verification Reliability / verification
challengeschallenges
Large interconnect delayLarge interconnect delay Increasing interconnect delay Increasing interconnect delay
and shrinking clock domains and shrinking clock domains Limited size of individual Limited size of individual
computing enginescomputing engines
Interconnect RC DelayInterconnect RC Delay
1
10
100
1000
10000
350 250 180 130 90 65
Del
ay (
ps)
Clock Period
RC delay of 1mm interconnect
Copper Interconnect
130nm
30%
5X0.90.9
1.01.0
1.11.1
1.21.2
1.31.3
1.41.4
11 22 33 44 55Normalized Leakage (INormalized Leakage (Isbsb))
No
rmal
ized
Fre
qu
ency
No
rmal
ized
Fre
qu
ency
Data: Shekhar Borkar, Intel

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 33
Trends in architectureTrends in architecture
Transistors are free… until connected or usedTransistors are free… until connected or used Continued scaling of traditional processor core no longer Continued scaling of traditional processor core no longer
economically viableeconomically viable2-3X effective area yields ~1.6X performance [PollackMICRO32]2-3X effective area yields ~1.6X performance [PollackMICRO32]Verification, power, transistor variabilityVerification, power, transistor variability
Only obvious scaling route: “Multi-Everything”Only obvious scaling route: “Multi-Everything”Multi-thread, multi-core, multi-memory, multi-?Multi-thread, multi-core, multi-memory, multi-?CW: Distributed parallelism is easy to designCW: Distributed parallelism is easy to design
But what about software?But what about software? If you build a better mousetrap…If you build a better mousetrap…

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 44
A “multi-everything” processor of the futureA “multi-everything” processor of the future
LOCALMEMORY
MA
INM
EMO
RY
GPP
MTM
LOCALMEMORY
ACC ACC
APP
LOCALMEMORY
Distributed, less complex Distributed, less complex componentscomponents
Variability, power density, and Variability, power density, and verification – easier to addressverification – easier to address
Who bears the SW mapping Who bears the SW mapping burden?burden?
General purpose software General purpose software changes prohibitivelychanges prohibitively expensive expensive (cf. SIMD, IA-64)(cf. SIMD, IA-64)
Advanced compiler featuresAdvanced compiler features“Deep Analysis”“Deep Analysis”
New programming models / New programming models / frameworksframeworks
Interactive compilersInteractive compilers
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 55
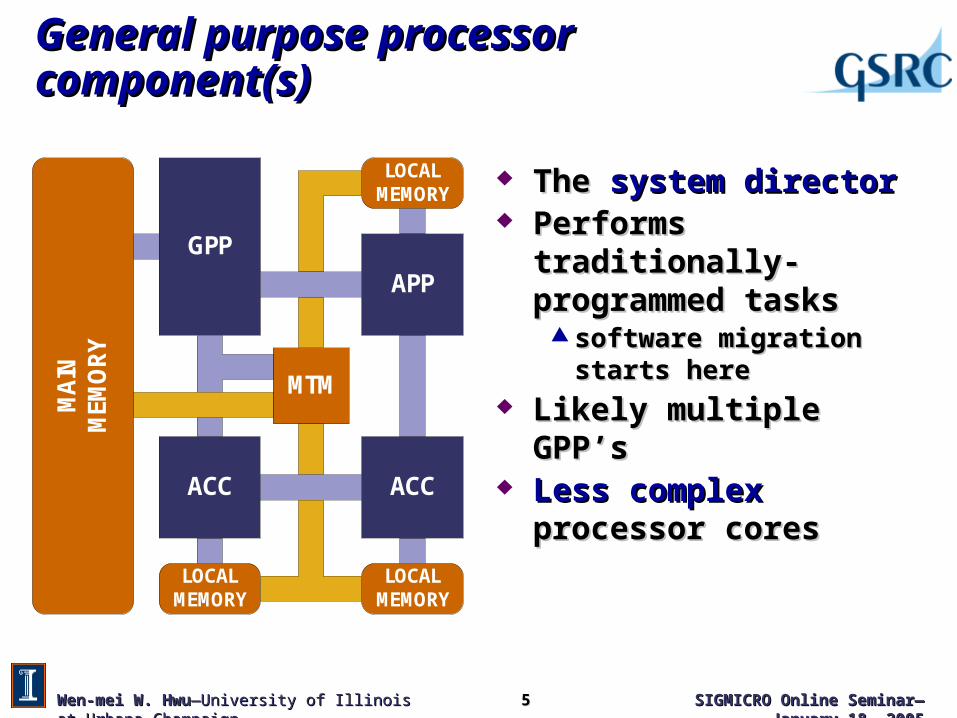
General purpose processor component(s)General purpose processor component(s)
LOCALMEMORY
MA
INM
EMO
RY
GPP
MTM
LOCALMEMORY
ACC ACC
APP
LOCALMEMORY
The The system directorsystem director Performs traditionally-Performs traditionally-
programmed tasksprogrammed tasks software migration starts heresoftware migration starts here
Likely multiple GPP’sLikely multiple GPP’s Less complexLess complex processor cores processor cores

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 66
Computational efficiency through customizationComputational efficiency through customization
LOCALMEMORY
MA
INM
EMO
RY
GPP
MTM
LOCALMEMORY
ACC ACC
APP
LOCALMEMORY
Goal: Offload most processing Goal: Offload most processing to more specialized, more to more specialized, more efficient unitsefficient units
Application Processors (APP)Application Processors (APP) Specialized instruction sets, Specialized instruction sets,
memory organizations and memory organizations and access facilitiesaccess facilities
Programmable Accelerators Programmable Accelerators (ACC)(ACC)
Think ASIC with knobsThink ASIC with knobs Highly-specialized pipelinesHighly-specialized pipelines Approximate ASIC design pointsApproximate ASIC design points
Higher performance/watt than Higher performance/watt than general purpose for target general purpose for target applicationsapplications

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 77
Memory efficiency through diversityMemory efficiency through diversity
LOCALMEMORY
MA
INM
EMO
RY
GPP
MTM
LOCALMEMORY
ACC ACC
APP
LOCALMEMORY
Traditional monolithic memory Traditional monolithic memory model – major power / model – major power / performance sinkperformance sink
Need partnership of general-Need partnership of general-purpose memory hierarchy and purpose memory hierarchy and software-managed memoriessoftware-managed memories
Local memories will reduce Local memories will reduce unnecessary unnecessary memory trafficmemory traffic and and power consumptionpower consumption
Bulk data transfer scheduled Bulk data transfer scheduled by by Memory Transfer ModuleMemory Transfer Module
Software will gradually adopt Software will gradually adopt decentralized model for decentralized model for powerpower and and bandwidthbandwidth

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 88
Tolerating communication & adding macropipeliningTolerating communication & adding macropipelining
LOCALMEMORY
MA
INM
EMO
RY
GPP
MTM
LOCALMEMORY
ACC ACC
APP
LOCALMEMORY
Bulk communication overhead Bulk communication overhead often substantial for traditional often substantial for traditional acceleratorsaccelerators
Shared memory / snooping Shared memory / snooping communication approach communication approach limits available bandwidthlimits available bandwidth
Compilation tools will have to Compilation tools will have to seamlessly connect seamlessly connect processors and acceleratorsprocessors and accelerators
Accelerators will be able to Accelerators will be able to operate on bulk transferred, operate on bulk transferred, buffered data…buffered data…
… … or on streamed dataor on streamed data
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 99
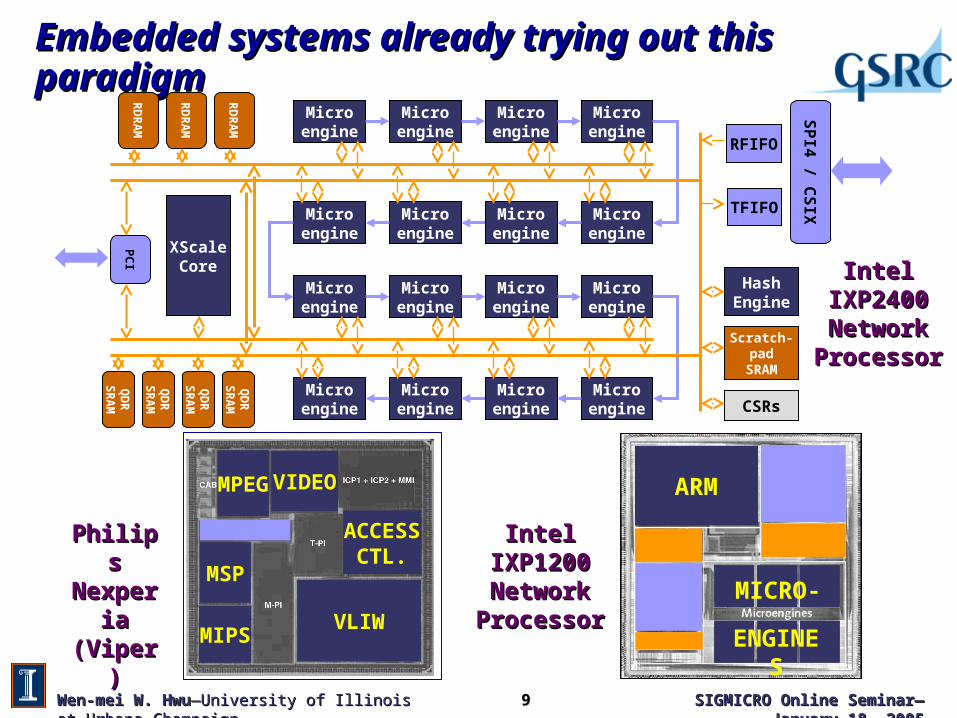
Embedded systems already trying out this paradigmEmbedded systems already trying out this paradigm
XScaleCore
HashEngine
Scratch-pad
SRAM
RFIFO
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
Microengine
QD
RS
RA
M
QD
RS
RA
M
QD
RS
RA
M
QD
RS
RA
M
RD
RA
M
RD
RA
M
RD
RA
M
PC
I
CSRs
TFIFO
SP
I4 / C
SIX
Intel IXP1200 Intel IXP1200 Network Network
ProcessorProcessor
Philips Philips Nexperia Nexperia (Viper)(Viper)
ARM
MICRO-
ENGINES
ACCESSCTL.
MIPS
MPEG
VLIW
VIDEO
MSP
Intel IXP2400 Intel IXP2400 Network Network
ProcessorProcessor

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1010
Decentralizing parallelism in a JPEG decoderDecentralizing parallelism in a JPEG decoder
Convert a typical media-processing application to the Convert a typical media-processing application to the decentralized modeldecentralized modelArrays used to implement streamsArrays used to implement streamsMultiple loci of computation with various models of parallelismMultiple loci of computation with various models of parallelismMemory access bandwidth a bottleneck w/o private dataMemory access bandwidth a bottleneck w/o private data
BypassedUpsample
Optional
Upsample
ColorConversion
YCCImage
UpsampledImage
RGBImage
texttext
textConversion
Tables
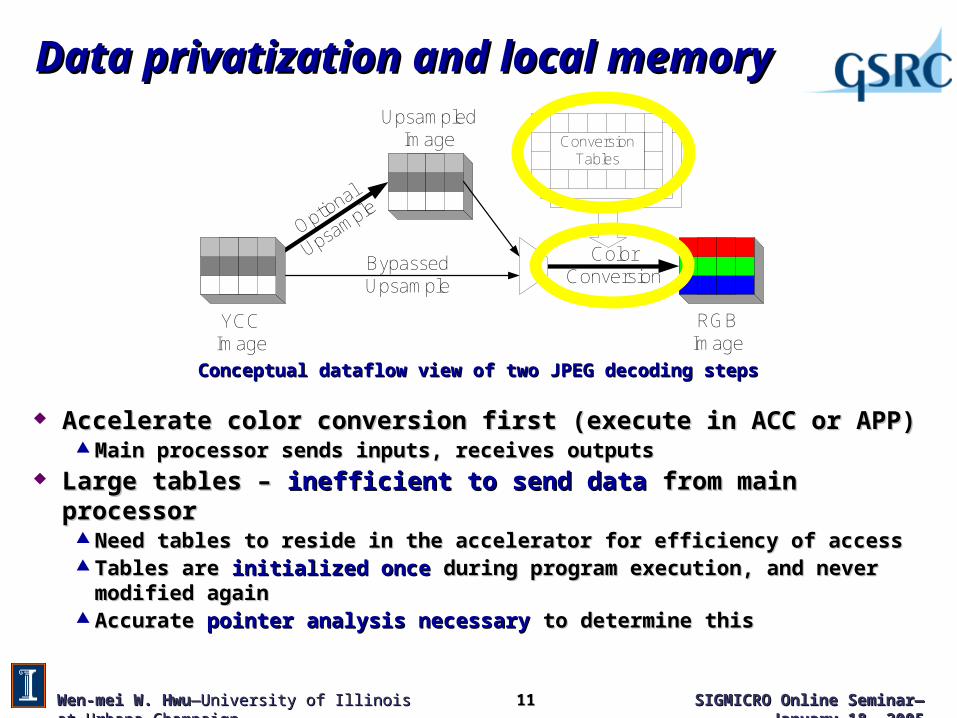
Conceptual dataflow view of two JPEG decoding stepsConceptual dataflow view of two JPEG decoding steps
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1111
Data privatization and local memoryData privatization and local memory
BypassedUpsample
Optional
Upsample
ColorConversion
YCCImage
UpsampledImage
RGBImage
texttext
textConversion
Tables
Conceptual dataflow view of two JPEG decoding stepsConceptual dataflow view of two JPEG decoding steps
Accelerate color conversion first (execute in ACC or APP)Accelerate color conversion first (execute in ACC or APP) Main processor sends inputs, receives outputsMain processor sends inputs, receives outputs
Large tables – Large tables – inefficient to send datainefficient to send data from main processor from main processor Need tables to reside in the accelerator for efficiency of accessNeed tables to reside in the accelerator for efficiency of access Tables are Tables are initialized onceinitialized once during program execution, and never modified during program execution, and never modified
againagain Accurate Accurate pointer analysis necessarypointer analysis necessary to determine this to determine this
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1212
Increasing parallelismIncreasing parallelism
Convert
Stream
ConvertUpsample
Upsample
Time
YCCImage
UpsampledImage
RGBImage
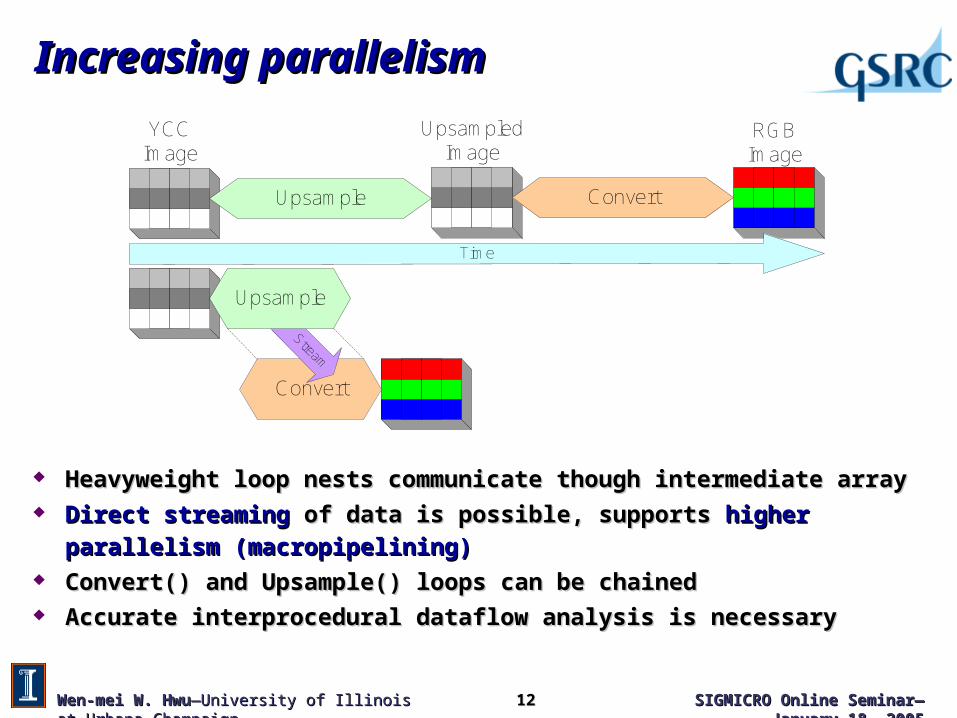
Heavyweight loop nests communicate though intermediate array Heavyweight loop nests communicate though intermediate array Direct streamingDirect streaming of data is possible, supports of data is possible, supports higher parallelism higher parallelism
(macropipelining)(macropipelining) Convert()Convert() and and Upsample()Upsample() loops can be chained loops can be chained Accurate interprocedural dataflow analysis is necessaryAccurate interprocedural dataflow analysis is necessary

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1313
How the next-generation compiler will do it How the next-generation compiler will do it (1)(1)
To-do list:o Identify acceleration
opportunitieso Localize memoryo Stream data and
overlap computation
Heavyweight loops
Acceleration opportunities:o Heavyweight loops identified for accelerationo However, they are isolated in separate functions called
through pointers
Upsample
ColorConversion
LoadScanline
TableInitialization
MemoryCallgraph
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1414
Accelerator 2
Accelerator 1
Upsample
ColorConversion
LoadScanline
MemoryCallgraph
TableInitialization
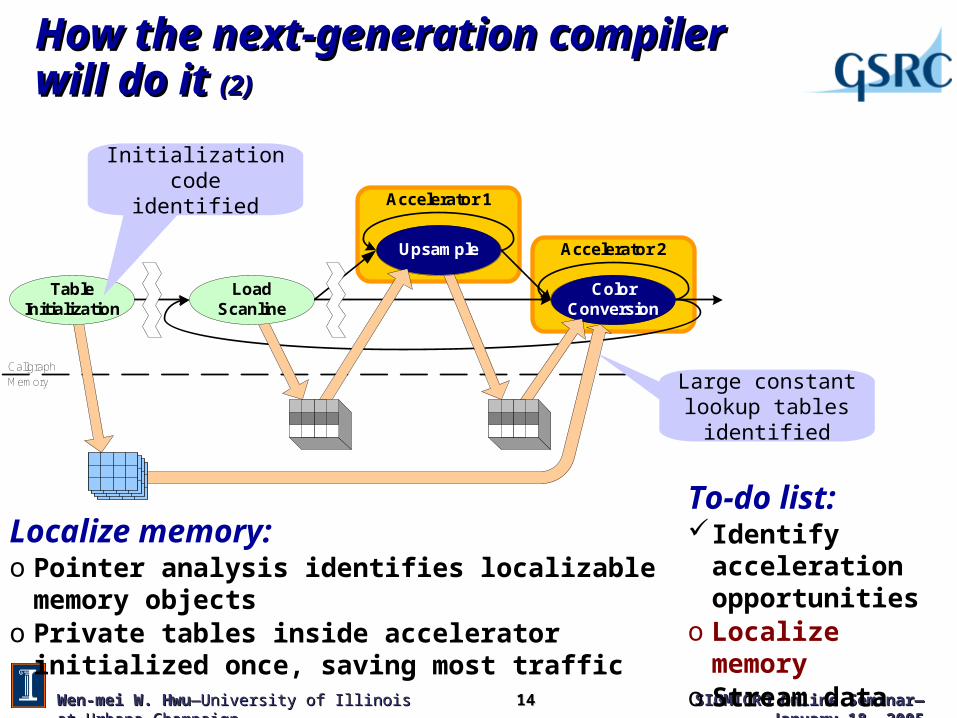
Large constant lookup tables identified
How the next-generation compiler will do it How the next-generation compiler will do it (2)(2)
To-do list: Identify acceleration
opportunitieso Localize memoryo Stream data and
overlap computation
Localize memory:o Pointer analysis identifies localizable memory objectso Private tables inside accelerator initialized once, saving most
traffic
Initialization code identified
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1515
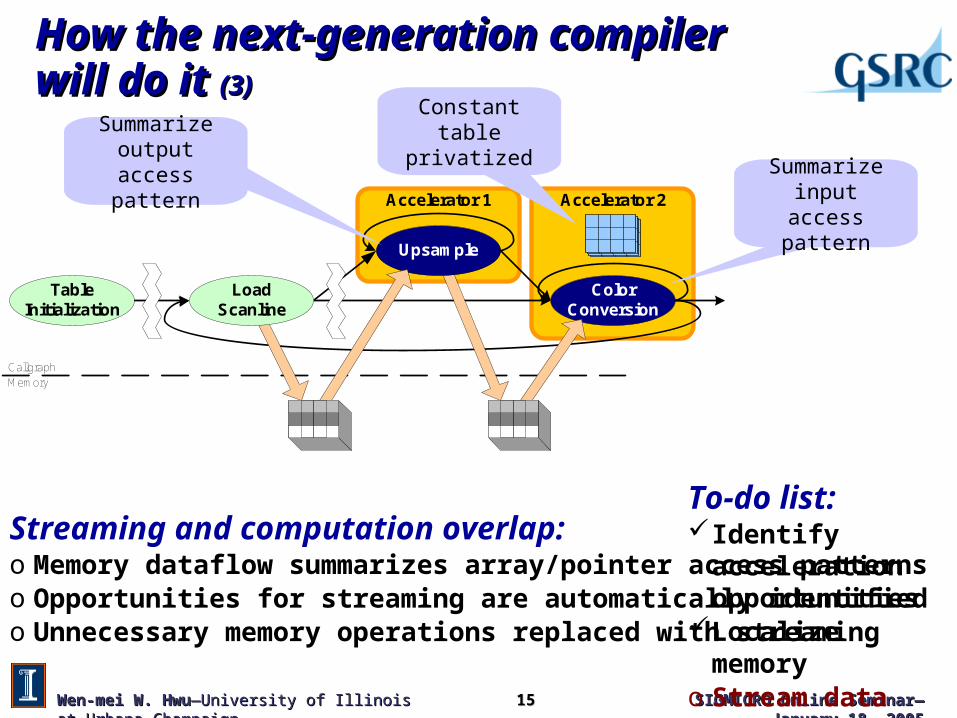
How the next-generation compiler will do it How the next-generation compiler will do it (3)(3)
To-do list: Identify acceleration
opportunitiesLocalize memoryo Stream data and
overlap computation
Streaming and computation overlap:o Memory dataflow summarizes array/pointer access patternso Opportunities for streaming are automatically identifiedo Unnecessary memory operations replaced with streaming
Accelerator 2Accelerator 1
Upsample
ColorConversion
LoadScanline
MemoryCallgraph
TableInitialization
Summarize input access pattern
Summarize output access pattern
Constant tableprivatized
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1616
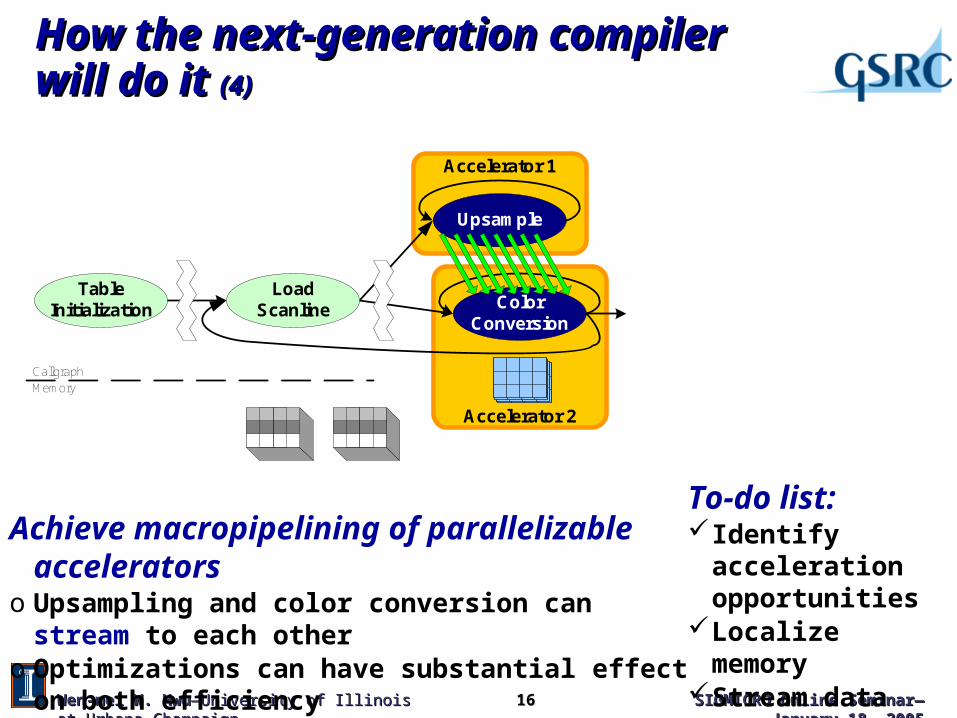
How the next-generation compiler will do it How the next-generation compiler will do it (4)(4)
To-do list: Identify acceleration
opportunitiesLocalize memoryStream data and
overlap computation
Achieve macropipelining of parallelizable acceleratorso Upsampling and color conversion can stream to each othero Optimizations can have substantial effect on both efficiency
and performance
Accelerator 2
Accelerator 1
Upsample
ColorConversion
LoadScanline
MemoryCallgraph
TableInitialization
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1717
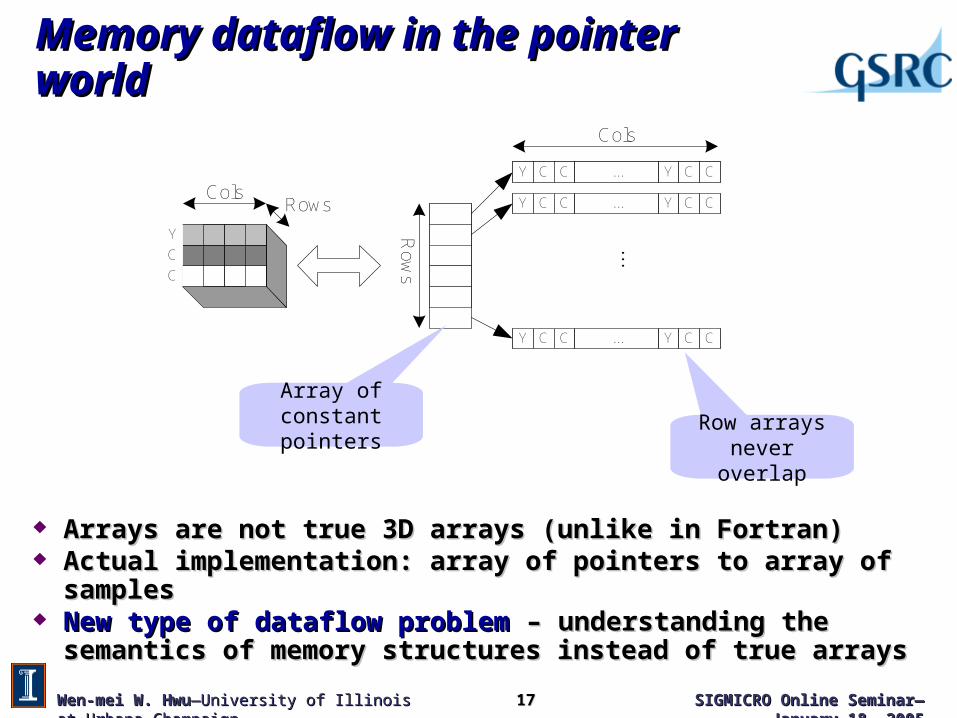
Memory dataflow in the pointer worldMemory dataflow in the pointer world
Y C C Y C C...
Y C C Y C C...
Y C C Y C C...
…Y
C
C
ColsRows
Row
s
Cols
Arrays are not true 3D arrays (unlike in Fortran)Arrays are not true 3D arrays (unlike in Fortran) Actual implementation: array of pointers to array of samplesActual implementation: array of pointers to array of samples New type of dataflow problemNew type of dataflow problem – understanding the semantics of – understanding the semantics of
memory structures instead of true arraysmemory structures instead of true arrays
Array of constantpointers Row arrays never
overlap

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1818
Compiler vs. hardware memory wallsCompiler vs. hardware memory walls
Hardware memory wallHardware memory wallProhibitive implementation cost of memory system while trying Prohibitive implementation cost of memory system while trying
to keep up with the processor speed under power budgetto keep up with the processor speed under power budget Compiler memory wallCompiler memory wall
The use of memory as a generic pool obstructs compiler’s view The use of memory as a generic pool obstructs compiler’s view of true program and data structuresof true program and data structures
The decentralized and diversified memory approach is key The decentralized and diversified memory approach is key to breaking the hardware memory wallto breaking the hardware memory wall
Breaking the compiler memory wall will be increasingly Breaking the compiler memory wall will be increasingly important in breaking the hardware memory wallimportant in breaking the hardware memory wall
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 1919
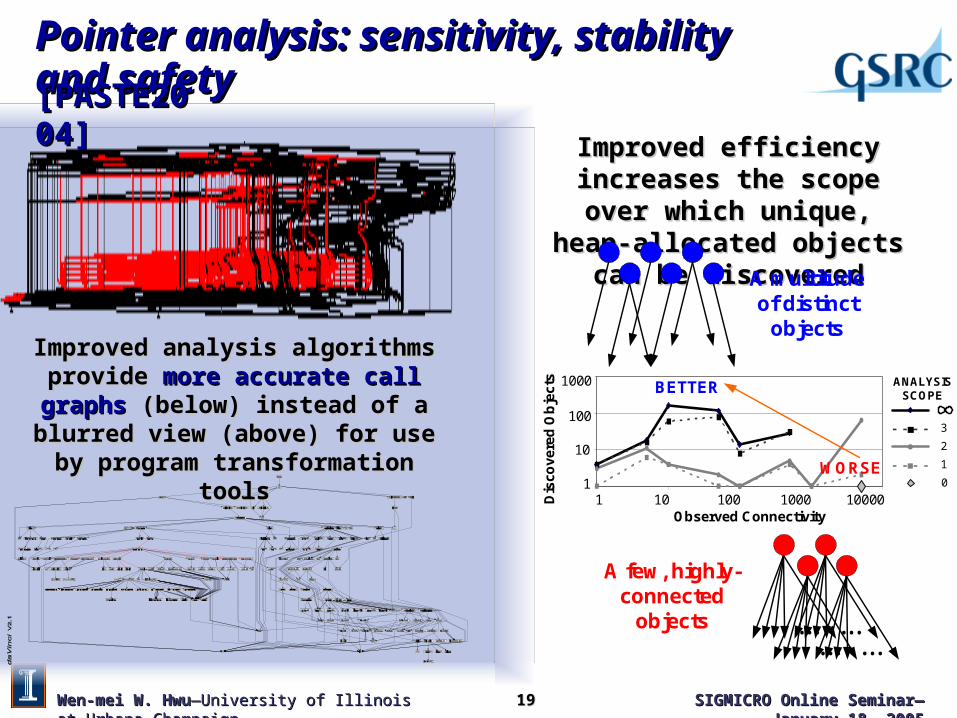
Pointer analysis: sensitivity, stability and safetyPointer analysis: sensitivity, stability and safety
Improved efficiency increases the Improved efficiency increases the scope over which unique, heap-scope over which unique, heap-
allocated objects can be discoveredallocated objects can be discovered
Improved analysis algorithms provide Improved analysis algorithms provide more more accurate call graphsaccurate call graphs (below) instead of a (below) instead of a blurred view (above) for use by program blurred view (above) for use by program
transformation toolstransformation tools
A multitudeof distinct
objects
Observed Connectivity1 10 100 1000 10000
1
10
100
1000
Dis
cove
red
Ob
jec
ts
132.ijpeg
BETTER
WORSE
A few, highly-connected
objects
3
2
1
0
ANALYSISSCOPE
......
......
[PASTE2004][PASTE2004]

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2020
Pointer analysis: sensitivity, stability and safetyPointer analysis: sensitivity, stability and safety
Analysis is abstract executionAnalysis is abstract executionsimplifying abstractions → analysis stabilitysimplifying abstractions → analysis stability““unrealizable dataflow” resultsunrealizable dataflow” results
Many components of accuracyMany components of accuracyTypical to cut some corners to enable “key” Typical to cut some corners to enable “key”
component for particular applicationscomponent for particular applications Making the components usefully Making the components usefully
compatible compatible is a major contributionis a major contributionNo need for No need for a prioria priori corner-cutting → better corner-cutting → better
results across broad code baseresults across broad code base Safety in “unsafe” languagesSafety in “unsafe” languages
C poses major challengesC poses major challengesEfficiency challenge increased in safe algos.Efficiency challenge increased in safe algos.?
Con-text
FieldSub-
typing
Heap
Arith-metic
Flow
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2121
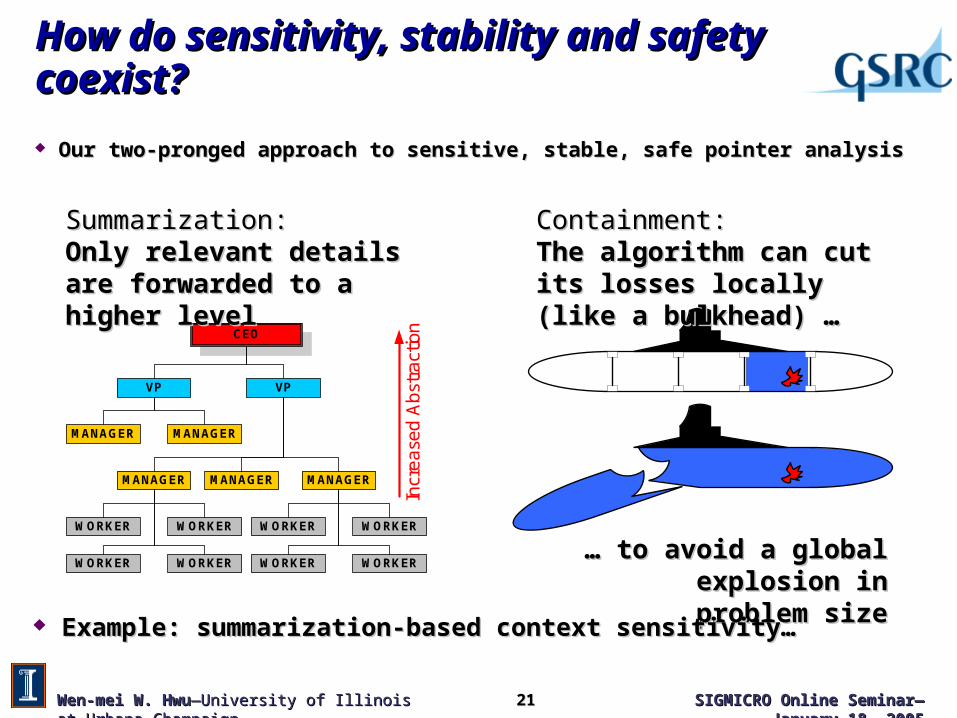
How do sensitivity, stability and safety coexist?How do sensitivity, stability and safety coexist?
Our two-pronged approach to sensitive, stable, safe pointer analysisOur two-pronged approach to sensitive, stable, safe pointer analysis
CEO
VP VP
MANAGERMANAGER
MANAGER MANAGERMANAGER
WORKER WORKER
WORKERWORKER
WORKER WORKER
WORKERWORKER
Incr
ease
d A
bstr
actio
n
Summarization:Summarization:Only relevant details are forwarded Only relevant details are forwarded to a higher levelto a higher level
Containment:Containment:The algorithm can cut its losses The algorithm can cut its losses locally (like a bulkhead) …locally (like a bulkhead) …
… … to avoid a globalto avoid a globalexplosion in problem sizeexplosion in problem size
Example: summarization-based context sensitivity…Example: summarization-based context sensitivity…

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2222
Context sensitivity: naïve inliningContext sensitivity: naïve inliningint g;
iris()int a;
jade1(&g, 1)
jade2(&a, 3)
g := 1
a := 3
Retention of side effect still leads to spurious results
*p := q;
r := g + 5;
jade(int *p, int q)int r;
x := z
p := &g;
p := &a;
q := 1;
q := 3;
g := 1 a := 3
Excess statements unnecessary and costly
g := 3
a := 1
r := 6
r := 8
jade2*p2 := q2;
p2 := &a; q2 := 3;
r2 := g + 5;
x2 := z2
jade1
x1 := z1
p1 := &g; q1 := 1;*p1 := q1;r1 := g + 5;

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2323
Context sensitivity: summarization-basedContext sensitivity: summarization-basedint g;
iris()int a;
jade1(&g, 1)
jade2(&a, 3)
p := &g;
p := &a;
q := 1;
q := 3;
g := 1 a := 3
g := 1
a := 3
Now, only correct result derived
Compact summary of jade used
int r;
jade(int *p, int q)
*p := q;
r := g + 5;
*p := q; r := 6Summary accounts for all
side-effects. BLOCK assignment to prevent
contaminationx := z
p1 := &g; q1 := 1;
*p1 := q1;jade1
*p2 := q2;
p2 := &a; q2 := 3;jade2

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2424
Analyzing large, complex programsAnalyzing large, complex programs
Bench-Bench-markmark
INACCURATEINACCURATE Context Context
InsensitiveInsensitive (seconds)(seconds)
PREV PREV Context-Context-
Sensitive Sensitive (seconds)(seconds)
NEW NEW Context-Context-SensitiveSensitive
(seconds)(seconds)
espressoespresso 22 99 11
lili 11 13321332 11
ijpegijpeg 22 8585 11
perlperl 44 408408 1111
gccgcc 5252 HOURSHOURS 124124
perlbmkperlbmk 155155 MONTHSMONTHS 198198
gapgap 6262 33503350 117117
vortexvortex 55 136136 33
twolftwolf 11 22 11
This results in an efficient analysis This results in an efficient analysis process without loss of accuracyprocess without loss of accuracy
Originally, problem size exploded as Originally, problem size exploded as more contexts were encounteredmore contexts were encountered
New algorithm contains problem New algorithm contains problem size with each additional contextsize with each additional context
008.espresso099.go 130.li
124.m88ksim 175.vpr134.perl
176.gcc 254.gap 255.vortex
1E+00
1E+02
1E+04
1E+06
1E+08
1E+10
1E+12
1E+14
Naï
ve
Exh
au
sti
ve
In
lin
ing
1 3 5 7 9
11 13 15 17 19 21 23 25 27 29 31 33 35 37 39
1E+00
1E+01
1E+02
1E+03
1E+04
1E+05
Ne
w C
om
pa
cti
on
Alg
ori
thm
Call Graph Depthmain() leaves
1 3 5 7 9
11
13
15
17
19
21
23
25
27
29
31
33
35
37
39
Call Graph Depthmain() leaves
1012
104
[SAS2004][SAS2004]

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2525
The outlook in softwareThe outlook in software
Software is changing too, more graduallySoftware is changing too, more gradually Applications driving development – rich in parallelismApplications driving development – rich in parallelism
Physical world – medicine, weatherPhysical world – medicine, weatherVideo, games – signal & media processingVideo, games – signal & media processing
Source code availabilitySource code availabilityOpen Source continues to growOpen Source continues to growMicrosoft’s Phoenix Compiler ProjectMicrosoft’s Phoenix Compiler Project
New programming modelsNew programming modelsEnhanced developer productivity & enhanced parallelismEnhanced developer productivity & enhanced parallelism

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2626
Beyond the traditional language environmentBeyond the traditional language environment
Domain-specific, higher-level modeling languagesDomain-specific, higher-level modeling languagesMore intuitive than C for inherently parallel problemsMore intuitive than C for inherently parallel problems Implementation details abstracted away from developersImplementation details abstracted away from developers
increased productivity, increased portabilityincreased productivity, increased portability Still an important role for the compiler in this domainStill an important role for the compiler in this domain
Little visibility “through” the model for low-level optimization by Little visibility “through” the model for low-level optimization by developersdevelopers communication, memory optimization will be communication, memory optimization will be critical critical in next-gen systemsin next-gen systems
Model can provide structured semantics for the compiler, beyond Model can provide structured semantics for the compiler, beyond what can be derived from analysis of low-level codewhat can be derived from analysis of low-level code
As new system models are developed, compilers, As new system models are developed, compilers, modeling languages, and developers will take on new, modeling languages, and developers will take on new, interactive rolesinteractive roles
SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2727
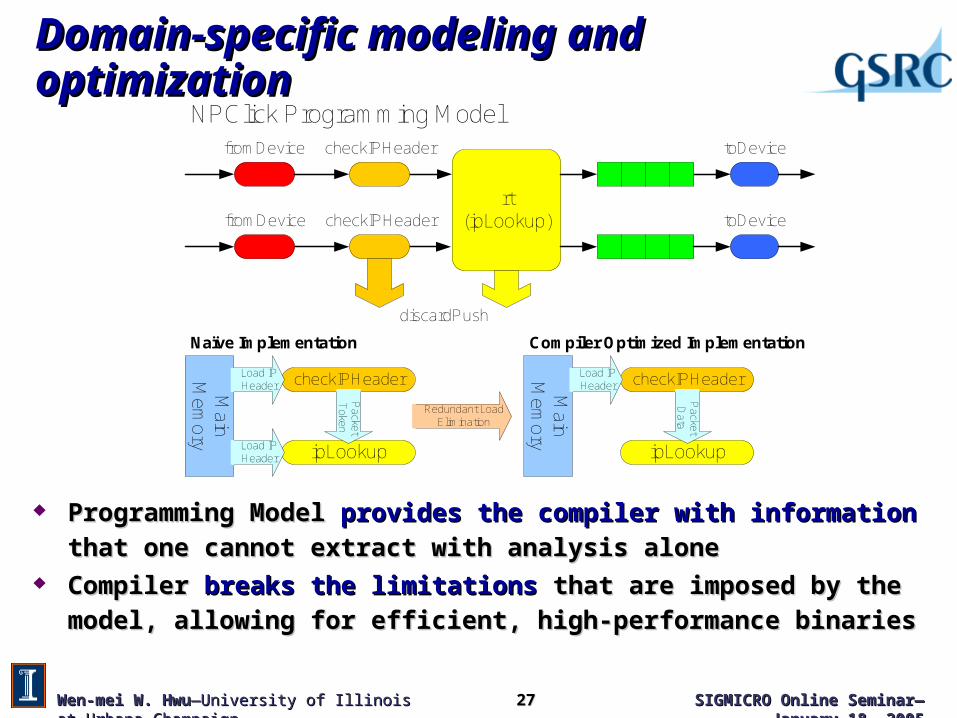
Domain-specific modeling and optimizationDomain-specific modeling and optimization
rt(ipLookup)
fromDevice
fromDevice checkIPHeader
checkIPHeader toDevice
toDevice
discardPush
Main
Mem
ory
checkIPHeaderLoad IPHeader
ipLookup
Packet
Token
Load IPHeader
Main
Mem
ory
checkIPHeaderLoad IPHeader
ipLookup
PacketD
ata
NPClick Programming Model
Naïve Implementation Compiler Optimized Implementation
Redundant LoadElimination
Programming Model Programming Model provides the compiler with informationprovides the compiler with information that one cannot that one cannot
extract with analysis aloneextract with analysis alone Compiler Compiler breaks the limitationsbreaks the limitations that are imposed by the model, allowing for that are imposed by the model, allowing for
efficient, high-performance binariesefficient, high-performance binaries

SIGMICRO Online Seminar—January 18, 2005SIGMICRO Online Seminar—January 18, 2005Wen-mei W. HwuWen-mei W. Hwu—University of Illinois at Urbana-Champaign—University of Illinois at Urbana-Champaign 2828
Concluding thoughtsConcluding thoughts
Reaching the true potential of multi-everything hardware Reaching the true potential of multi-everything hardware Scalability requires distributed parallelism and memory modelsScalability requires distributed parallelism and memory modelsRequires new compilation tools to break compiler memory wallRequires new compilation tools to break compiler memory wall
Broad suite of analyses necessaryBroad suite of analyses necessaryAdvanced pointer analysisAdvanced pointer analysisMemory dataflow analysisMemory dataflow analysisNew interactions of classical analysesNew interactions of classical analyses
This is not just reinventing HPFThis is not just reinventing HPFNew distributed parallelism paradigmsNew distributed parallelism paradigmsNew applications New applications new challenges! new challenges!
As the field develops, new domain-specific programming As the field develops, new domain-specific programming models will also benefit from advanced compilation models will also benefit from advanced compilation technologytechnology