easy transfer learning by exploiting intra-domain …dmqm.korea.ac.kr/uploads/seminar/easy transfer...
TRANSCRIPT

2019. 08. 16
정승섭
Data Mining & Quality Analytics Lab.
EASY TRANSFER LEARNING BY EXPLOITING INTRA-DOMAIN STRUCTURES

- 2 -
Contents
시작하기 앞서
Introduction
Problem Description
EASY TRANSFER LEARNING
CONCLUSIONS

- 3 -
시작하기 앞서 – Transfer Learning 실제 적용 사례
https://youtu.be/DafZSeIGLNE

- 4 -
시작하기 앞서 – Transfer Learning 실제 적용 사례
• 극빈곤 나라에서의 지역의 빈곤 차이 를 알기 위한 빈곤 국가 지도 만들기 (스텐포드 대학)1. 인공위성 데이터를 이용하여 야간에 발생한 조명의 정도로 부의 분포 구분2. 야간 조명 데이터를 활용한 transfer learning 모델과 주간 위성 사진으로 도로, 도시지역, 수로, 농지등 빈곤과 연관
지을 수 있는 지역 구분3. 빈곤지역에서 발생할 야간 조명을 예측하고 낮과 밤 2개의 데이터 세트를 비교하여 빈곤 지역 세부적으로 파악
https://youtu.be/DafZSeIGLNE

- 5 -
시작하기 앞서 – Transfer Learning 실제 적용 사례
https://youtu.be/DafZSeIGLNE

- 6 -https://youtu.be/DafZSeIGLNE
시작하기 앞서 – Transfer Learning 실제 적용 사례

- 7 -
Introduction
• 학습 방법론의 종류 - Single-task learning 일반적인 방법론 하나의 Training set 에서 하나의 model 로 독립적으로 학습
Training Set 1
Model 1
Training Set 2
Model 2
Training Set 3
Model 3
Single Task Learning
https://www.slideshare.net/ssuser62b35f/180808-dynamically-expandable-networkContinual Lifelong Learning and Catastrophic Forgetting 이지윤 연구원 세미나 자료

- 8 -
Introduction
Training Set 1
Model 1
Training Set 2
Model 2
Training Set 3
Model 3
Multi Task Learning
• 학습 방법론의 종류 - Multi-task learning 여러 개의 task 를 동시에 학습 하는 방법론 여러 학습 작업이 동시에 해결되는 동시에 작업 간의 공통점과 차이점을 활용 동시 학습을 통해 지식전이(Knowledge Transfer)가 일어나서 성능이 향상되는 것을 목표
https://www.slideshare.net/ssuser62b35f/180808-dynamically-expandable-networkContinual Lifelong Learning and Catastrophic Forgetting 이지윤 연구원 세미나 자료

- 9 -
Introduction
Training subset
Training subset
Training subset
Training subset
Training subset
Model
Online Learning
• 학습 방법론의 종류 Offline learning : 일반적인 방법론 Online learning : 데이터가 subset 형태로 순차적으로 주어지는 상황에서 학습하되, 학습에 사용된 subset 데이터는저장이 불가하여 더 이상 사용할 수 없음. (subset(mini-batch) 형태 : 일반적인 Training set 이 용량이 너무 커서 조금씩 나누어 주는 방식)
https://www.slideshare.net/ssuser62b35f/180808-dynamically-expandable-networkContinual Lifelong Learning and Catastrophic Forgetting 이지윤 연구원 세미나 자료

- 10 -
Training Set 1
Knowledge
Training Set 2
Model 2Transfer Learned Knowledge
Source task Target task
Source model Target model
Introduction
• 학습 방법론의 종류 - Transfer learning 학습 데이터가 적은 target task 를 잘 수행하기 위해 기존에 잘 훈련된 모델(source model) 활용 일반적으로 target task 를 푸는 single task learning 문제 시나리오 유사 도메인(Source task) 에서 학습된 내용을 이용하여 target 도메인으로 학습
한국어 음성인식 -> 일본어 음성인식 기존 장비 -> 신규 장비 이미지 feature extractor
Continual Lifelong Learning and Catastrophic Forgetting 이지윤 연구원 세미나 자료https://www.slideshare.net/ssuser62b35f/180808-dynamically-expandable-network

- 11 -
Introduction
• 학습 방법론의 종류 Transfer learning : 학습 데이터가 적은 target task 를 잘 수행하기 위해 기존에 잘 훈련된 모델(source model) 활용 Pre-train data : 기존에 훈련된 모델의 데이터와 유사점이 좋아야 함 미세조정(fine-tuning) : 기존에 훈련된 모델에 추가 된 데이터로 파라미터 업데이트
Source data set
Source model
Source labels
Training Set 3
Target model
Target labels
Transfer Learned Knowledge
Source task Target task
Large amount of data/labels
small amount of data/labels
<Transfer learning 의 고려점>I. Pre-train data 와의 유사점II. Fine-tuning 할 데이터의 양III. 분석의 할당된 시간IV. 가용한 hardware
Continual Lifelong Learning and Catastrophic Forgetting 이지윤 연구원 세미나 자료

- 12 -
Introduction
• Transfer learning 이 왜 필요한가?• Deep learning – 아주 강력한 model 이지만 진입 장벽이 높다!!
충분한 데이터가 없음 고성능 하드웨어 가 필요 (학습이 너무 오래 걸림(VGGNet 의 경우 2~3주)) 딥러닝으로 구현한 알고리즘 및 튜닝 노하우 가 어렵다
Big Data
https://nittaku.tistory.com/270?category=742607

- 13 -
Introduction
http://cs231n.github.io/transfer-learning/
• Transfer Learning 시나리오 ConvNet as fixed feature extractor : Pretrained CNN 에서 마지막 classification layer( 보통 softmax layer) 만 제거하
면 완전한 feature extractor 다. Feature 을 그대로 사용해서, 우리의 training set 은 linear classifier (e.g. linear SVM or Softmax) 를 학습하기 위해 사용
Fine-tuning the ConvNet : 마지막 classification layer 만을 retrain 하는것이 아니라 pretrain된 전체 네트워크를 재조정 하는것. 상대적으로 사용할 수 있는 데이터가 많을 때 적합
CNN in practice 서덕성 연구원 세미나 자료

- 14 -
Introduction
http://cs231n.github.io/transfer-learning/
• Transfer Learning 시나리오 ConvNet as fixed feature extractor : Pretrained CNN 에서 마지막 classification layer( 보통 softmax layer) 만 제거하
면 완전한 feature extractor 다. Feature 을 그대로 사용해서, 우리의 training set 은 linear classifier (e.g. linear SVM or Softmax) 를 학습하기 위해 사용
Fine-tuning the ConvNet : 마지막 classification layer 만을 retrain 하는것이 아니라 pretrain된 전체 네트워크를 재조정 하는것. 상대적으로 사용할 수 있는 데이터가 많을 때 적합
CNN in practice 서덕성 연구원 세미나 자료

- 15 -
• When and how to fine-tune ?
새 데이터가 작지만 원래 데이터와 비슷한 경우 : 데이터의 양이 적어 fine-tune은 over-fitting 가능하기 때문에 이 경우 최종 linear classifier 레이어만 학습
새 데이터가 매우 많으며 원래 데이터와 유사할 경우 : 전체 레이어에 대해서 fine-tune 학습
새 데이터가 적으며 원래 데이터와 다른 경우 : 데이터 양이 적기 때문에 linear classifier 레이어만 학습 하는것이 좋지만 데이터가 서로 다르기 때문에 결과가 안좋다. 앞쪽 레이어의 activation 값을 사용해서 SVM을 학습
새 데이터가 매우 많으면 원래 데이터와 다른 경우 : 데이터가 많기 때문에 새롭게 ConvNet 을 만들어도 되지만 이러한 경우에도 pretrained model 을 사용하는 것이 더 효율이 좋다. 전체 레이어에 대해서 fine-tune 학습
Introduction
http://cs231n.github.io/transfer-learning/

- 16 -
Problem description
• Transfer Learning
학습 데이터(D)가 주어졌을 때 최적의 파라미터(∅)를 구하는 것
https://blog.goodaudience.com/artificial-neural-networks-explained-436fcf36e75
𝑥𝑥1, 𝑦𝑦1 = ( , 고양이)
𝑥𝑥2, 𝑦𝑦2 = ( , 강아지)
𝑤𝑤1𝑤𝑤2𝑤𝑤3𝑤𝑤4
𝑤𝑤𝑖𝑖
𝑤𝑤𝑖𝑖+1𝑤𝑤𝑖𝑖+2
𝑤𝑤𝑗𝑗
𝑤𝑤𝑗𝑗+1
𝑤𝑤𝑗𝑗+2𝑤𝑤𝑗𝑗+3
𝑤𝑤𝑗𝑗+4
𝑤𝑤𝑖𝑖+3
𝑤𝑤𝑖𝑖+4
고양이(1)
강아지(0)
∅ = 𝑤𝑤1, 𝑤𝑤2, 𝑤𝑤3 , …
Model-agnostic meta-learning for fast adaptation of deep networks 목충협연구원세미나자료
Ex. 개와 고양이 사진을 분류하는 인공신경망 모형

- 17 -
학습 데이터(D)가 주어졌을 때 최적의 파라미터(∅)를 구하는 것
Problem description
https://blog.goodaudience.com/artificial-neural-networks-explained-436fcf36e75Model-agnostic meta-learning for fast adaptation of deep networks 목충협연구원세미나자료
𝑥𝑥1, 𝑦𝑦1 = ( , 고양이)
𝑥𝑥2, 𝑦𝑦2 = ( , 강아지)
Train data(Target)Train data가 적다면?
기존에존재하는큰데이터셋에서선학습된모델을 사용하여Transfer-learning을이용하면적은데이터로도충분한학습이가능
• Transfer Learning

- 18 -
Problem description
• 전통 Transfer Learning 의 3가지 어려운 이유
많은 하이퍼 파라미터를 튜닝하기 위해 많은 비용과 시간이 소요되는 과정을 거쳐야 함
모델을 선택하고 하이퍼 파라미터를 튜닝하는 가장 일반적인 전략인 교차 검증은 target 도메인에 레이블이 지정된데이터가 없기 때문에 사용 불가능
최근 AutoML이 tree pruning, boosting, neural architecture search 방식 등으로 하이퍼 파라미터를 자동으로 조정하지만 TL 의 도메인 간 서로 다른 분포를 처리 할 수 없고 이 역시 수렴하는데 시간이 많이 걸림

- 19 -
Easy Transfer Learning

- 20 -
• Easy Transfer Learning setting
Easy Transfer Learning Algorithms
𝐴𝐴 𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙 𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑙𝑙 𝐷𝐷𝑆𝑆𝐷𝐷𝑙𝑙𝐷𝐷𝐷𝐷 Ω𝑠𝑠 = 𝑋𝑋𝑖𝑖𝑠𝑠 , 𝑦𝑦𝑖𝑖
𝑠𝑠𝑖𝑖=1𝑛𝑛𝑠𝑠 , An unlabeled Target Domain Ω𝑡𝑡 = 𝑋𝑋𝑗𝑗
𝑡𝑡𝑗𝑗=1𝑛𝑛𝑡𝑡
Feature space Xs = Xt, label space Ys = Yt but Marginal distribution Ps(xs) ≠ Pt(xt) with conditional distribution Qs(ys|xs) ≠ Qt(yt|xt)The goal is to predict the labels yt ϵYt for the target domain.
Source data set
Source model
Source labels
Training Set 3
Target model
Target labels
Transfer Learned Knowledge
Source task Target task
Large amount of data/labels
small amount of data/labels

- 21 -
Easy Transfer Learning Algorithms
• Intra-domain Alignment
Zr = Xr (cov(Xs + Es) −1
2 (cov Xt + Et)1
2 if r = sXr if r = t
(9)

- 22 -
Easy Transfer Learning Algorithms
• Intra-domain Alignment
http://www.navisphere.net/4119/ufldl-tutorial-17-unsupervised-learning-pca-whitening/
• 16 * 16 크기의 흑백 이미지 패치를 이용하여 PCA 를 진행 한다면, 입력은 256 차원의 벡터가 되고, Xj 는 각 픽셀 값
• 이 데이터는 평균값 0 과 분산 값 을 가지도록 전처리 작업이 되어 있음.

- 23 -
Easy Transfer Learning Algorithms
• Intra-domain Alignment
http://www.navisphere.net/4119/ufldl-tutorial-17-unsupervised-learning-pca-whitening/
• PCA 는 원래보다 적은 차원의 부분공간(subspace)으로데이터를 사영한다.
• 그림을 보면 데이터 분산의 주축을 확인 할 수 있다.

- 24 -
Easy Transfer Learning Algorithms
• Intra-domain Alignment
http://www.navisphere.net/4119/ufldl-tutorial-17-unsupervised-learning-pca-whitening/
Whitening (화이트닝)
• U1 U2 에 기저에 대해 회전시켜 본 모습.
• 이 데이터의 covariance 행렬은 다음과 같다.
• 분산을 1로 만들어 준다.
U1
U2

- 25 -
Easy Transfer Learning Algorithms
• Intra-domain Alignment
http://www.navisphere.net/4119/ufldl-tutorial-17-unsupervised-learning-pca-whitening/
Whitening (화이트닝)
• 이제 covariance 행렬이 1인 identity matrix 가 되었고이를 whitened 되었다고 함.
• 각 컴포넌트는 서로 상관성이 없고 고정된 분산값 1을갖게 됨

- 26 -
Easy Transfer Learning Algorithms
• Intra-domain Alignment
http://www.navisphere.net/4119/ufldl-tutorial-17-unsupervised-learning-pca-whitening/
Re-coloring (리컬러링)
• 상관성이 없는 whitened 된 컴포넌트에 다시 특정 상관값을 입력함
• 특성을 다시 가지게 됨
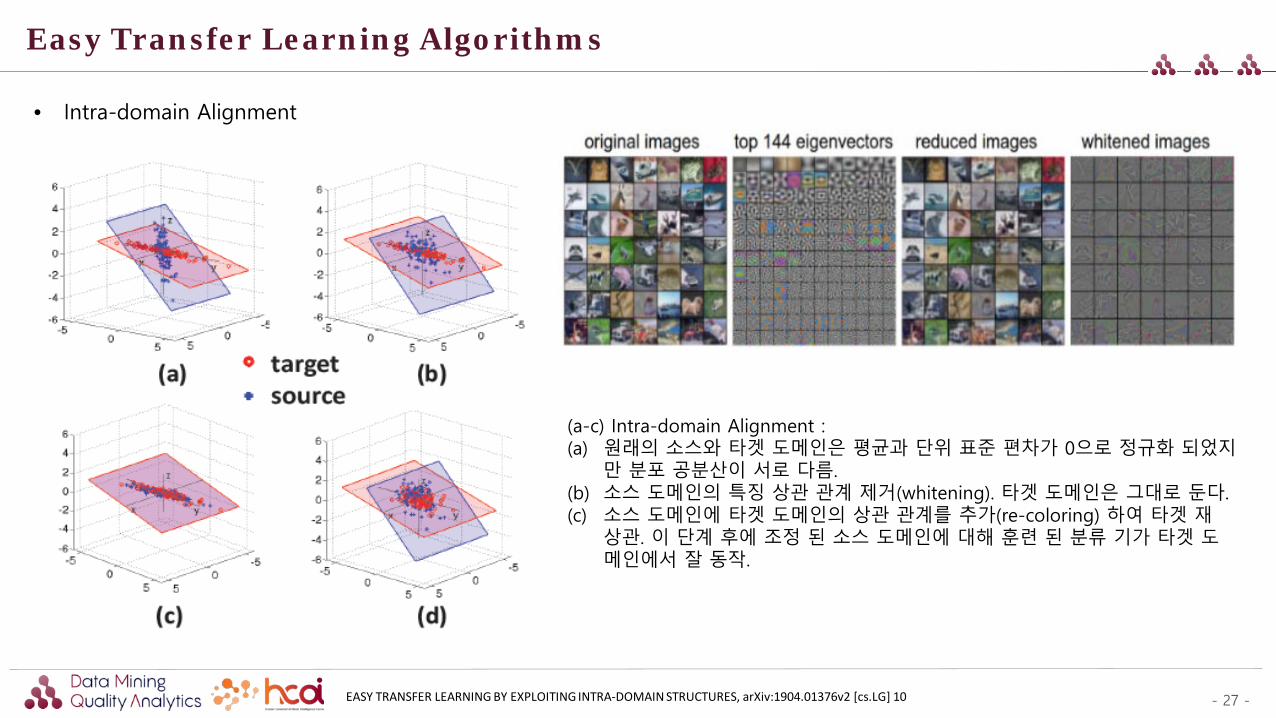
- 27 -
Easy Transfer Learning Algorithms
• Intra-domain Alignment
EASY TRANSFER LEARNING BY EXPLOITING INTRA-DOMAIN STRUCTURES, arXiv:1904.01376v2 [cs.LG] 10
(a-c) Intra-domain Alignment : (a) 원래의 소스와 타겟 도메인은 평균과 단위 표준 편차가 0으로 정규화 되었지
만 분포 공분산이 서로 다름. (b) 소스 도메인의 특징 상관 관계 제거(whitening). 타겟 도메인은 그대로 둔다. (c) 소스 도메인에 타겟 도메인의 상관 관계를 추가(re-coloring) 하여 타겟 재
상관. 이 단계 후에 조정 된 소스 도메인에 대해 훈련 된 분류 기가 타겟 도메인에서 잘 동작.

- 28 -
Easy Transfer Learning Algorithms
• 질문 1. 소스 도메인과 타겟 도메인 모두 상관값을 제거하면 안될까?
소스 및 타겟 데이터가 도메인 이동으로 인해 서로 다른 하위 공간에 있을 가능성이 있으므로 이는 실패함. (그림 d)
• 질문 2. 타겟 도메인의 상관값을 제거하고 소스 도메인의 상관값을 입력하면 안될까?
실험 결과 소스를 타겟 공간으로 변환 하는것이 성능이 좋게 측정 됨. 소스를 타겟 공간으로 변환함으로써 소스의 레이블정보와 타겟의 레이블이 없는 구조를 모두 사용하여 classifier가 학습 되었기 때문에 잘 동작 하는것으로 예상.
EASY TRANSFER LEARNING BY EXPLOITING INTRA-DOMAIN STRUCTURES, arXiv:1904.01376v2 [cs.LG] 10

- 29 -
Easy Transfer Learning Algorithms
• Intra-domain Programming

- 30 -
Easy Transfer Learning Algorithms
• Intra-domain Programming
-> 제약 1.
-> 제약 2.
-> 제약 3.
Mcj = probability annotation matrix(확률 주석 매트릭스) 의 기본 개념
1. 4 개의 클래스 C(C1,C2,C3,C4) 와 nt개의 target Xnt샘플이 존재함2. softmax 분류기와 유사하게, Xt1의 가장 높은 확률 값은 0.4(M41)이며 이는 C4에 속함을 나타냅니다. -> 제약1.3. Xt1 의 C1~C4에 속할 확률 값은 0.1(M11),0.2(M21),0.3(M31),0.4(M41) 이며 모두 합하면 1 이다. -> 제약 2. 4. Xtnt는 반드시 C 클래스 중 하나에 속해야 하고 Mcj의 이상적인 값은 0또는 1이므로 모든 Mcj 의 합은 1 이상이다. -> 제약 3. 5. Xt2 및 Xt3 등도 마찬가지로 실제 확률 주석 값(Mcj)은 제안 된 방법으로 학습된다. 6. 이 알고리즘은 확률 주석 매트릭스(Mcj)를 학습하는 데 중점을 둡니다.

- 31 -
Easy Transfer Learning Algorithms
• Intra-domain Programming
-> 제약 1.
-> 제약 2.
-> 제약 3.
Dcj = Xtj 와 소스 도메인 Ωs(c) 의 c-th class center 사이의 거리
Dcj = Xtj − hc2
hc = 1Ωs
(c) ∑ins 𝑋𝑋𝑖𝑖
𝑠𝑠 II(𝑦𝑦𝑖𝑖𝑠𝑠 = c)
𝐴𝐴 𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙 𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑙𝑙 𝐷𝐷𝑆𝑆𝐷𝐷𝑙𝑙𝐷𝐷𝐷𝐷 Ω𝑠𝑠 = 𝑋𝑋𝑖𝑖𝑠𝑠 , 𝑦𝑦𝑖𝑖
𝑠𝑠𝑖𝑖=1𝑛𝑛𝑠𝑠 , An unlabeled Target Domain Ω𝑡𝑡
= 𝑋𝑋𝑗𝑗𝑡𝑡
𝑗𝑗=1𝑛𝑛𝑡𝑡
Feature space Xs = Xt, label space Ys = Yt but Marginal distribution Ps(xs) ≠ Pt(xt) with conditional distribution Qs(ys|xs) ≠ Qt(yt|xt).The goal is to predict the labels yt ϵYt for the target domain.

- 32 -
Easy Transfer Learning Algorithms
• Intra-domain Programming
-> 제약 1.
-> 제약 2.
-> 제약 3.
𝐴𝐴 𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙𝑙 𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑆𝑙𝑙 𝐷𝐷𝑆𝑆𝐷𝐷𝑙𝑙𝐷𝐷𝐷𝐷 Ω𝑠𝑠 = 𝑋𝑋𝑖𝑖𝑠𝑠 , 𝑦𝑦𝑖𝑖
𝑠𝑠𝑖𝑖=1𝑛𝑛𝑠𝑠 , An unlabeled Target Domain Ω𝑡𝑡
= 𝑋𝑋𝑗𝑗𝑡𝑡
𝑗𝑗=1𝑛𝑛𝑡𝑡
Feature space Xs = Xt, label space Ys = Yt but Marginal distribution Ps(xs) ≠ Pt(xt) with conditional distribution Qs(ys|xs) ≠ Qt(yt|xt).The goal is to predict the labels yt ϵYt for the target domain.

- 33 -
Easy Transfer Learning Algorithms
• Computational Complexity
big-O notation : 알고리즘의 효율성을 나타내는 지표 시간에 대한 개념인 시간 복잡도 : 알고리즘의 수행 시간이 얼마인지를 나타냄
1. 반복문 을 기준으로 입력 값(n) 에 영향을 받는 핵심적인 코드가 어느 부분인지 파악하고 n 과 어떤 관계가있는지 파악하는 관점
2. 특정 입력 값 O(n) 이 O(1) 보다 빠를 수도 있음3. 상수항 무시(O(2n)->O(n)), 영향력 없는 항 무시 가능 (O(n²+n)->O(n²))4. O(1) < O(log n) < O(n) < O(n log n) < O(n²) < O(2ⁿ) < O(n!) < O(nⁿ)
https://cjh5414.github.io/big-o-notation/

- 34 -
Easy Transfer Learning Algorithms
• Computational Complexity
예시 : 입력값 N 에 대해 N2 을 구하는 프로그램을 작성 한다고 한다면..
https://cjh5414.github.io/big-o-notation/
곱셈 연산 1개로 big-O 표기법으로 O(1)
덧셈 연산 1개와 대입 연산 1개가 n만큼 실행되므로 2n의 시간이 걸리지만big-O 표기법으로는 상수항을 무시하여 O(n)
덧셈 연산, 대입 연산 이 각각 nxn번 실행되므로 총 2n²의 시간이 걸리지만마찬가지로 상수항을 무시하여 big-O 표기법으로 O(n²)

- 35 -
Easy Transfer Learning Algorithms
• Computational Complexity
계산 복잡성에서도 다른 모델에 비해 경쟁력이 있다. Intra-domain alignment : Eq.(9) O(Cns
3) Intra-domain programming : Eq.(7) O(nt
3C3)
A single round of SVM : O((ns + nt)3)
https://cjh5414.github.io/big-o-notation/

- 36 -
• Experimental Setup
Image 및 sentiment 에서 여러 비교군들과 테스트를 하였을때 Accuracy 가 상당히 높게 측정됨. 특히 Amazon Review 의 경우 모든 경우에서 제일 좋은 결과가 측정 됨.
Easy Transfer Learning

- 37 -
Easy Transfer Learning
• Accuracy and Efficiency
The results demonstrate that EasyTL outperforms all comparison methods in both sentiment and image data.

- 38 -
• 장점 쉬움 : 모델 선택 또는 하이퍼 파라미터 튜닝이 필요하지 않고 다루기 쉽다.
정확성 : EasyTL은 최첨단 전통적 방법과 심층 방법에 비해 인기있는 여러 TL 작업에서 경쟁력 있는 결과를 제공한다.
효율성 : EasyTL은 다른 방법보다 훨씬 효율적이고 웨어러블과 같은 리소스 제한 장치에 더 적합하다.
확장성 : EasyTL은 분류기를 도메인 내 프로그래밍으로 대체하여 기존 TL 메소드의 성능을 향상시킬 수 있다.
Conclusion
• 아쉬운점 너무 간단히 쓰여 있어서 다른 자료를 찾는데 시간이 많이 소요 되었다.
다 좋다고 쓰여 있는데 정말로 그런지 잘 모르겠다.

감사합니다.