ecml 2001 a framework for learning rules from multi-instance data yann chevaleyre and jean-daniel...
TRANSCRIPT

ECML 2001
A Framework forA Framework for
Learning Rules fromLearning Rules from
Multi-Instance DataMulti-Instance Data
Yann Chevaleyre and Jean-Daniel Zucker University of Paris VI – LIP6 - CNRS

ECML 2001
atomicdescription
Motivations
Att/Valrepresentation
Relationalrepresentation
global
descriptio
n- Low expressivity+ Tractable
+ high expressivity- Untractability, unless strong biases
MI RepresentationMI Representation
Most available MI learners use numerical data, and generate nonMost available MI learners use numerical data, and generate noneasily interpretable hypotheseseasily interpretable hypotheses
Our goal: design Our goal: design efficient MI learners efficient MI learners handlinghandling numeric and numeric andsymbolic datasymbolic data, and generating interpretable hypotheses, such as , and generating interpretable hypotheses, such as decision treesdecision trees or or rule setsrule sets
The choice of a good representation is a central issue in ML tasks.The choice of a good representation is a central issue in ML tasks.

ECML 2001Outline
• 1) Multiple-Instance Learninig
– Multiple-instance representation, where are the MI-data,
the MI learning problem
• 2) Extending a propositional algorithm to handle MI data
– Method, extending the Ripper rule learner
• 3) Analysis of the multiple-instance extension of Ripper
– Misleading litterals, unrelevant litterals, litteral selection problem
• 4) Experimentations & Applications
• Conclusion et future work

ECML 2001The Multiple Instance Representation: definition
Standard A/V representation:
Multiple Instance representation:
{0,1}-valued label li
is represented byA/V vector xi
is represented by
A/V vector xi,1
A/V vector xi,2
A/V vector xi,r
{0,1}-valued label li+
examplei +
baginstances
example i

ECML 2001
Many complex objects, such as Many complex objects, such as imagesimages or or moleculesmolecules, can, caneasily be represented with bags of instanceseasily be represented with bags of instances
Atom Type Chargec 1 1.18h 3 -1,2h 2 2.78… … …
Relational databases Relational databases may also be represented this waymay also be represented this way
id name age sex year balance
2 Joe 12 m 1999 932… … … … … …
id name age sex year balance1 Laura 43 f 1997 2341 Laura 43 f 1998 8031 Laura 43 f 1999 1200
More complex representations, such as More complex representations, such as datalog factsdatalog facts, may be , may be MI-propositionalized MI-propositionalized [zucker98], [Alphonse and Rouveirol 99][zucker98], [Alphonse and Rouveirol 99]
id name age sex
1 Laura 43 f2 Joe 12 m3 Marry 24 f… … … …
id year balance1 1997 2341 1998 8031 1999 12002 1999 932
… … …
0,n
1
Where can we find MI data?

ECML 2001
t
s(t)
s(tk) s(tk+) s(tk+2.) ... s(tk1+n.)
s(tj) s(tj+) s(tj+2) ... s(tj+n.)
Representing time series as MI data
By encoding each sub-sequence By encoding each sub-sequence ((s(ts(tkk), ... ,s(t), ... ,s(tk+nk+n)))) as an instance, as an instance,
the the representation becomes invariant by translationrepresentation becomes invariant by translation
tk tj
Windows can be chosen of various size to Windows can be chosen of various size to make the representationmake the representation invariant by rescaling invariant by rescaling

ECML 2001The multiple-instance learning problem
From B+,B- sets of positive(resp. negative) bags, find a
consistent hypothesis H
Their exists a function f, such that :lab(b)=1 iff x b, f (x)
unbiasedunbiased multiple-instance multiple-instanceLearning problemLearning problem
single-tuple single-tuple bias bias
multi-instance learningmulti-instance learning[Dietterich 97][Dietterich 97]
Find a function h covering at leastone instance per positive bag and no instancefrom any negative bag
Note: the domain of Note: the domain of hh is the is theinstance space, instead of theinstance space, instead of thebag spacebag space

ECML 2001Extending a propositional learner
We need to represent the We need to represent the bags of instancesbags of instances as a as asingle set of vectorssingle set of vectors
att1 att21.2 c-33 a
att1 att27.9 a
b1+b1+
b2-b2-
Adding bag-id and label
to each instance
att1 att2 bag-id lab1.2 c 1 +-33 a 1 +
7.9 a 2 -
Measure the Measure the degree of multiple-instance-consistancydegree of multiple-instance-consistancy of the of the hypothesis being refined.hypothesis being refined.
Instead of measuring p(r), n(r), the number of vectors covered by Instead of measuring p(r), n(r), the number of vectors covered by r, compute r, compute p*(r), n*(r), the number of bags for which r covers at p*(r), n*(r), the number of bags for which r covers at least one instance least one instance Single-tuple coverage measureSingle-tuple coverage measure

ECML 2001Extension de l ’algorithme Ripper (Cohen 95)
Ripper (Cohen 95) is a fast and efficient top-down rule learner,Ripper (Cohen 95) is a fast and efficient top-down rule learner,which compares to C4.5 in terms of accuracy, being much fasterwhich compares to C4.5 in terms of accuracy, being much faster• Naive-RipperMi Naive-RipperMi is the MI-extensions of Ripperis the MI-extensions of Ripper
Naive-Ripper-MINaive-Ripper-MI was tested on the was tested on the musk musk (Dietterich 97) tasks. On (Dietterich 97) tasks. On musk1 musk1 (avg of 5,2 instances per bag), it achieved good accuracy.(avg of 5,2 instances per bag), it achieved good accuracy.On On musk2musk2 (avg 65 instances per bag), only 77% of accuracy. (avg 65 instances per bag), only 77% of accuracy.
Learner Accuracy Induced hypothesisIterated Discrimin 92.4 APRDiverse Density 88.9 point in instance spaceRipper-MI 88 Rule set (avg 7 litterals)Tilde 87 1st order decision treeAll positive APR 80.4 APRMulti-Inst 76.7 APR

ECML 2001Empirical Analysis of Naive-RipperMI
Goal: Analyse pathologies linked to the MI problem and to the Goal: Analyse pathologies linked to the MI problem and to the Naive-Naive-Ripper-MIRipper-MI algorithm. algorithm.
5 positive5 positivebags:bags:
• white triangles bag• white squares bag...
• black triangles bag• black squares bag...
5 negative5 negativebags:bags:
Y
X2 4 6 8 10 12
2
4
6
8
Misleading litteralsMisleading litterals
Unrelevant litteralsUnrelevant litterals
Litteral selection problemLitteral selection problem
Analysing the behaviour of NaiveRipperMi on a simple datasetAnalysing the behaviour of NaiveRipperMi on a simple dataset

ECML 2001
Learning task: induce a rules covering Learning task: induce a rules covering at least one instance of each positive bag.of each positive bag.
Target concept : Target concept :
Y
X2 4 6 8 10 12
2
4
6
X > 5X > 5 & X < 9& X < 9 & Y > 3& Y > 3
Analysing Naive-RipperMI
ECML 2001
Y
X2 4 6 8 10 12
2
4
6
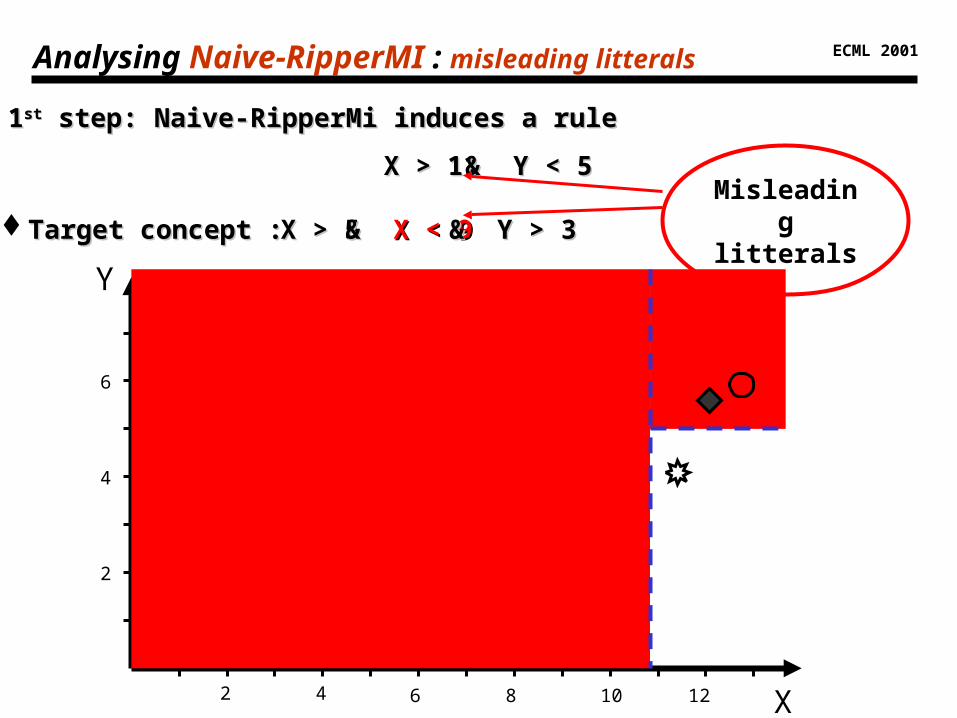
11stst step: Naive-RipperMi induces a rule step: Naive-RipperMi induces a rule
X > 11X > 11 & Y < 5& Y < 5
Analysing Naive-RipperMI : misleading litterals
Target concept : Target concept : X > 5X > 5 & & X < 9X < 9 & Y > 3& Y > 3
Misleadinglitterals

ECML 2001
Y
X2 4 6 8 10 12
2
4
6
2nd step: Naive-RipperMi removes the covered bag(s), and2nd step: Naive-RipperMi removes the covered bag(s), andinduces another rule...induces another rule...
Analysing Naive-RipperMI : misleading litterals

ECML 2001Analysing Naive-RipperMI : misleading litterals
Misleading litterals: litterals bringing information gain but contradicting the target concept
Multiple-instance specific phenomenon.
Dispite other single-instance pathologies, (overfitting,Dispite other single-instance pathologies, (overfitting, attribute selection problem), attribute selection problem), increasing the number of examples won’t help
The « Cover-and-differentiate » algorithm reduced the chance ofThe « Cover-and-differentiate » algorithm reduced the chance of finding the target concept finding the target concept
If If ll is a misleading litteral, then is a misleading litteral, then ll is not. is not.
It is thus sufficient, when the litteral It is thus sufficient, when the litteral l l has been induced, tohas been induced, to
examin examin ll at the same time. at the same time.=> => partitioning the instance space

ECML 2001Analysing Naive-RipperMI : misleading litterals
2 4 12
Y
X6 8 10
2
4
6
Build a Build a partition of the instance spaceof the instance space
Extract the best possible rule : X < 11 & Y < 6 & X > 5 & Y > 3Extract the best possible rule : X < 11 & Y < 6 & X > 5 & Y > 3

ECML 2001Analysing Naive-RipperMI : irrelevant litterals
In multiple-instance learnig, In multiple-instance learnig, irrelevant litteralsirrelevant litterals can occur can occur anywhere in the ruleanywhere in the rule, instead of mainly at the end of a rule in the , instead of mainly at the end of a rule in the single-instance casesingle-instance case
Use Use global pruning
Y
X2 4 6 8 10 12
2
4
6
Y < 6 & Y > 3 & X > 5 & X < 9Y < 6 & Y > 3 & X > 5 & X < 9
ECML 2001
X
Y
2 4 6 8 10 12
2
4
6
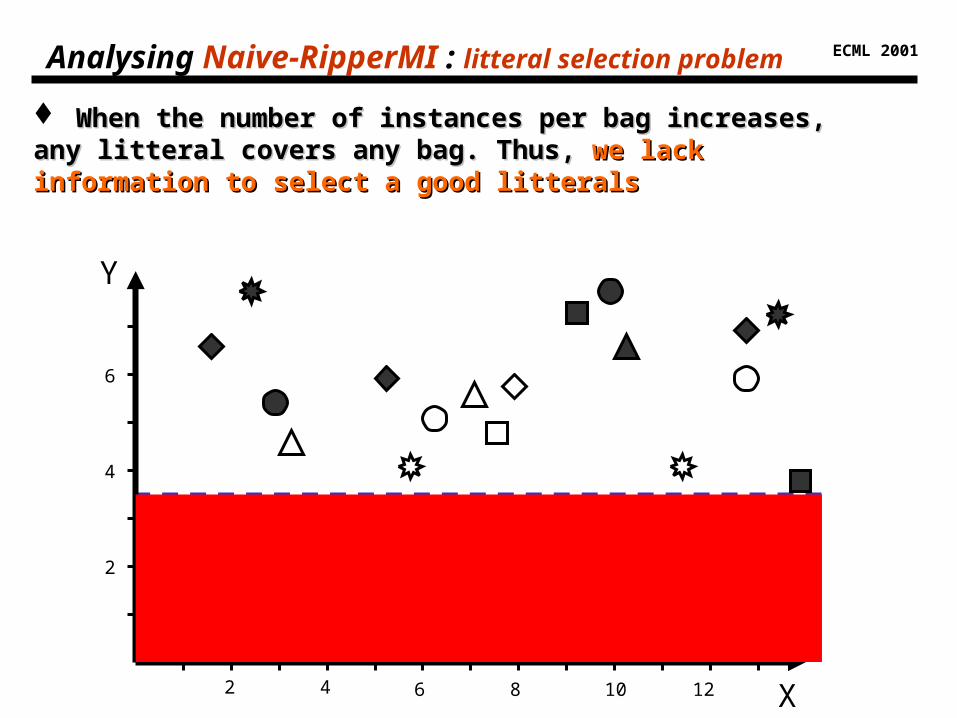
Analysing Naive-RipperMI : litteral selection problem
When the number of instances per bag increases, any litteral When the number of instances per bag increases, any litteral covers any bag. Thus, covers any bag. Thus, we lack information to select a good we lack information to select a good litteralslitterals

ECML 2001
X
Y
2 4 6 8 10 12
2
4
6
When the number of instances per bag increases, any litteral When the number of instances per bag increases, any litteral covers any bag. Thus, covers any bag. Thus, we lack information to select a good we lack information to select a good litteralslitterals
Analysing Naive-RipperMI : litteral selection problem

ECML 2001Analysing Naive-RipperMI : litteral selection problem
We must We must take into account the number of covered instances
Making an assumption on the distribution of instances canMaking an assumption on the distribution of instances can lead to a lead to a formal coverage measureformal coverage measure
+ widely studied in MI learning [Blum98,Auer97,...]+ simple coverage measure, and good learnability properties- very unrealistic
The single distribution model: The single distribution model: A bag is made of A bag is made of rr instances instances
drawn i.i.d. from a unique distributiondrawn i.i.d. from a unique distribution D
The two distribution model: The two distribution model: A positive (resp. negative) bag A positive (resp. negative) bag
is made of is made of rr instances drawn i.i.d. from instances drawn i.i.d. from D+ (resp.(resp.D- ) with at ) with at least one (resp. none) covered by least one (resp. none) covered by f.f.
+more realistic- complex formal measure useful for small number of instances (log # bags)
Design algorithms or measures which « work well » with these Design algorithms or measures which « work well » with these modelsmodels

ECML 2001Analysing Naive-RipperMI : litteral selection problem
Compute for each positif bag Pr(at least one of the k covered Compute for each positif bag Pr(at least one of the k covered instance instance target concept) target concept)
X
Y
2 4 6 8 10 12
2
4
6
Target concept
Y > 5
1 1k
r
PD f k

ECML 2001
# instances per bag
Err
or r
ate
(%)
Analysis of RipperMi: experiments
Artificial datasets of 100 bags with a variable number of instances per bag.Artificial datasets of 100 bags with a variable number of instances per bag.
Target concept: monomials (hard to learn with 2 instances per bag [Haussler89])Target concept: monomials (hard to learn with 2 instances per bag [Haussler89])
On the mutagenesis problem : On the mutagenesis problem : NaiveRipperMi: 78% NaiveRipperMi: 78% RipperMi-refined-cov: 82%RipperMi-refined-cov: 82%

ECML 2001
Perception
W
IF Color = blue AND size > 53 THEN DOOR
segmentation
Main color Size X/Y ratio YposRed 12 1,5 152Green 56 0,34 11Blue 176 0,2 11
What isall this ?
I seea door
lab = door
Application : Anchoring symbols
[with Bredeche]
Early experiments with NaiveRipperMi reached Early experiments with NaiveRipperMi reached 80% accuracy80% accuracy

ECML 2001Conclusion & Future work
Many problems which existed in relational learning appear Many problems which existed in relational learning appear clearly within the multiple-instance framework.clearly within the multiple-instance framework.
Algorithms presented here are aimed at solving these problems Algorithms presented here are aimed at solving these problems They were tested on artificial datasets.They were tested on artificial datasets.
Other realistic models, leading to better heuristicsOther realistic models, leading to better heuristics
Instance selection and attribute selectionInstance selection and attribute selection
Future work: MI-propositionalization, applying multiple-instance Future work: MI-propositionalization, applying multiple-instance learning to data-mining taskslearning to data-mining tasks
Many ongoing applications ...Many ongoing applications ...