eece 571r: data-intensive computing systems
DESCRIPTION
EECE 571R: Data-intensive computing systems. Matei Ripeanu matei at ece.ubc.ca. Contact Info. Email : matei @ ece.ubc.ca Office : KAIS 4033 Office hours : by appointment (email me) Course page : http://www.ece.ubc.ca/~matei/EECE571/. EECE 571R: Course Goals. Primary - PowerPoint PPT PresentationTRANSCRIPT

EECE 571R:Data-intensive computing
systems
Matei Ripeanu
matei at ece.ubc.ca

2Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Contact Info
Email: matei @ ece.ubc.caOffice: KAIS 4033Office hours: by appointment (email me)Course page: http://www.ece.ubc.ca/~matei/EECE571/

3Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
EECE 571R: Course Goals
Primary– Gain deep understanding of fundamental issues that
affect design of:> Data-intensive systems
> (more generally) Large-scale distributed systems
– Survey main current research themes
– Gain experience with distributed systems research> Research on: federated system, networks
Secondary– By studying a set of outstanding papers, build
knowledge of how to do & present research
– Learn how to read papers & evaluate ideas

4Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
What I’ll Assume You Know
Basic Internet architecture– IP, TCP, DNS, HTTP
Basic principles of distributed computing– Asynchrony (cannot distinguish between
communication failures and latency)
– Incomplete & inconsistent global state knowledge (cannot know everything correctly)
– Failures happen (In large systems, even rare failures of individual components, aggregate to high failure rates)
If there are things that don’t make sense, ask!

5Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Outline
Case study (and project ideas):– Volunteer computing: SETI@home /BOINC
– Virtual Data System
– Batch Aware Distributed File System Administrative
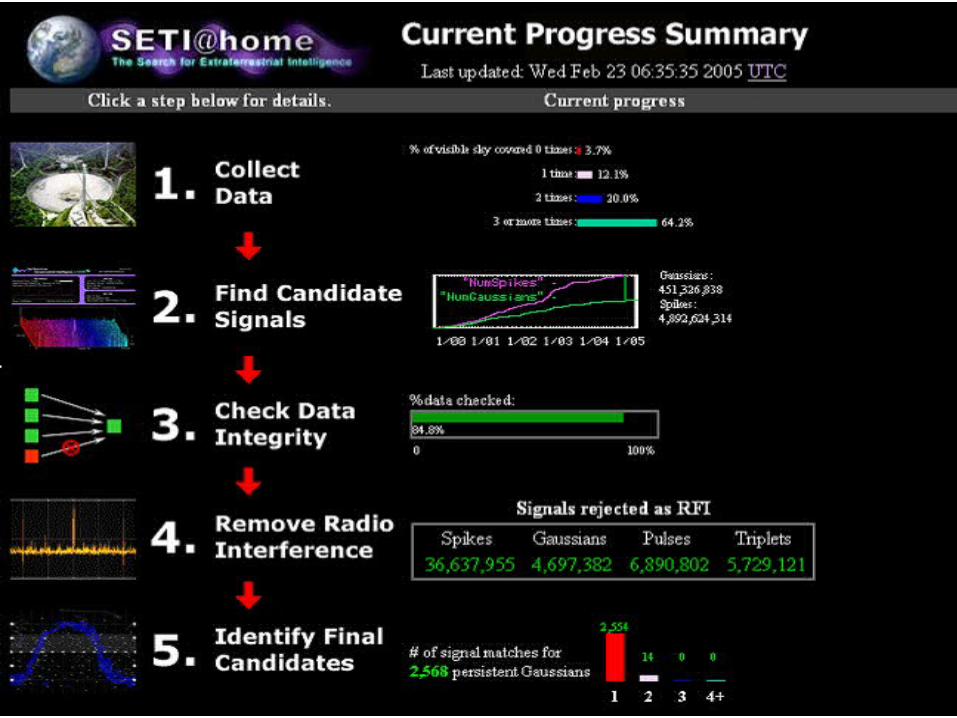
6Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
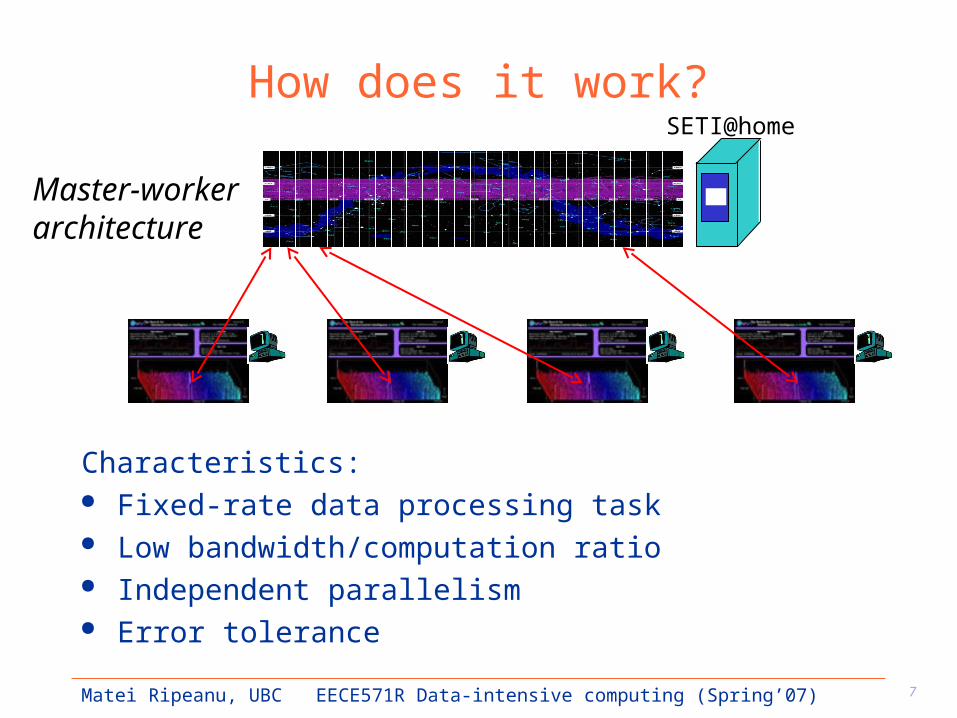
7Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
How does it work?
Characteristics: Fixed-rate data processing task Low bandwidth/computation ratio Independent parallelism Error tolerance
SETI@home
Master-workerarchitecture
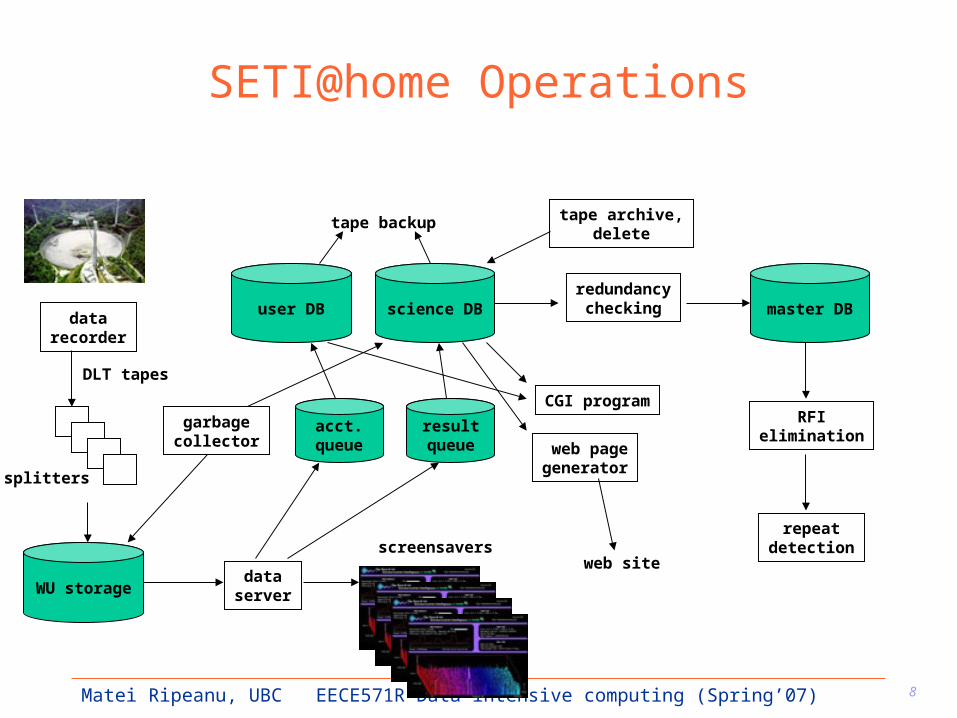
8Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
SETI@home Operations
datarecorder
screensavers
WU storage
splitters
DLT tapes
dataserver
science DBuser DB
resultqueue
acct.queue
garbagecollector
tape archive,delete
tape backup
master DBredundancy
checking
RFIelimination
repeatdetection
web site
CGI program
web pagegenerator

9Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
History and Statistics Conceived 1995, launched April 1999 Millions of users, hosts… No ET signals yet, but other results
Total Last 24 Hours(as of Wed Feb 23 07:04:51)
Users 5,361,313 4,391
Results received 1,779 millions 5 million
Total CPU time 2.2 million years 3610.717 years
Average CPU time/work unit
10 hr 58 min 14.0 sec 6 hr 19 min 30.1 sec

10Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Millions of individual contributors!(Problems)
Server scalability Dealing with excess CPU time Untrusted environment: Bad user behavior
– Cheating
– Team recruitment by spam
– Sale of accounts on eBay Malfunctions of individual components

11Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
SETI@home: Summary The characteristics of the problem …
– Massive (“embarrassing”) parallelism– Low bandwidth/computation ratio– Fixed-rate data processing task
… make possible a solution that operates in an unfriendly environment– Wide area distribution; huge scale – High failure rates– Untrusted/malicious components
Solution: Master-worker design>Master=central point of control>Single point of failure>Performance bottleneck

12Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Outline
Case study (and project ideas):– Volunteer computing: SETI@home /BOINC
– Virtual Data System
– Batch Aware Distributed File System Administrative

13Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Virtual Data System
Context: ’big science’ Motivation/goals: support science process,
– i.e., track all aspects of data capture, production, transformation, and analysis
Requirements: ability to define complex workflows, and to reliably & efficiently execute workflows in heterogeneous, multi-domain environments.
Derived benefits: helps to audit, validate, reproduce, and/or rerun with corrections various data transformations.

14Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
The European Organisation
for Nuclear ResearchCERN builds particle accelerators for particle physics research
BIG Science!
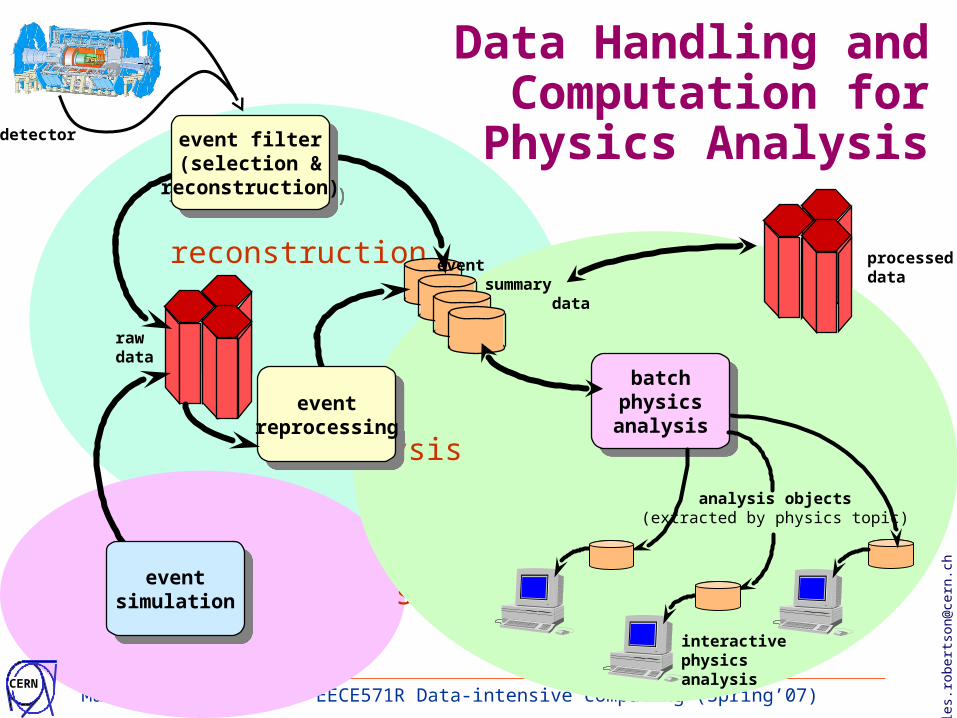
Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
reconstruction
simulation
analysis
interactivephysicsanalysis
batchphysicsanalysis
batchphysicsanalysis
detector
event summary data
rawdata
eventreprocessing
eventreprocessing
eventsimulation
eventsimulation
analysis objects(extracted by physics topic)
Data Handling and Computation for
Physics Analysisevent filter(selection &
reconstruction)
event filter(selection &
reconstruction)
processeddata
les.
rob
ert
son
@ce
rn.c
h
CERN
16Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
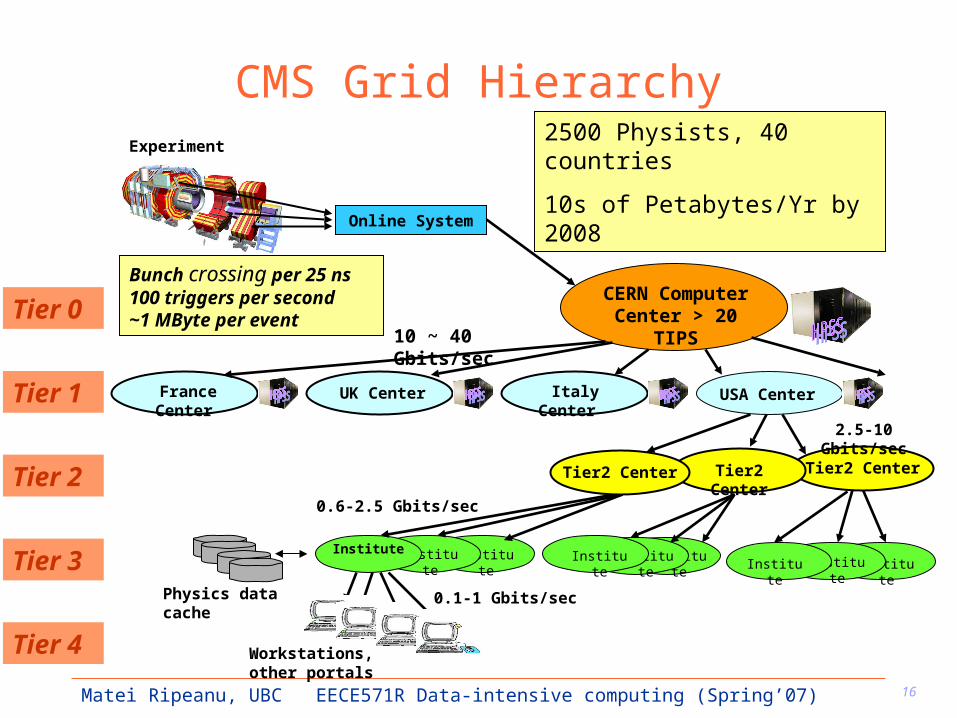
CMS Grid Hierarchy
Tier2 Center
Online System
CERN Computer Center > 20
TIPS
USA CenterFrance Center
Italy Center UK Center
InstituteInstituteInstitute
Workstations,other portals
100MB~1.5GB/sec
2.5-10 Gbits/sec
0.1-1 Gbits/sec
Bunch crossing per 25 ns100 triggers per second~1 MByte per event
Physics data cache
10 ~ 40 Gbits/sec
Tier2 CenterTier2 Center
0.6-2.5 Gbits/sec
Tier 0
Tier 1
Tier 3
Tier 4
Experiment2500 Physists, 40 countries
10s of Petabytes/Yr by 2008
InstituteInstituteInstituteInstituteInstituteInstitute
Tier 2
17Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
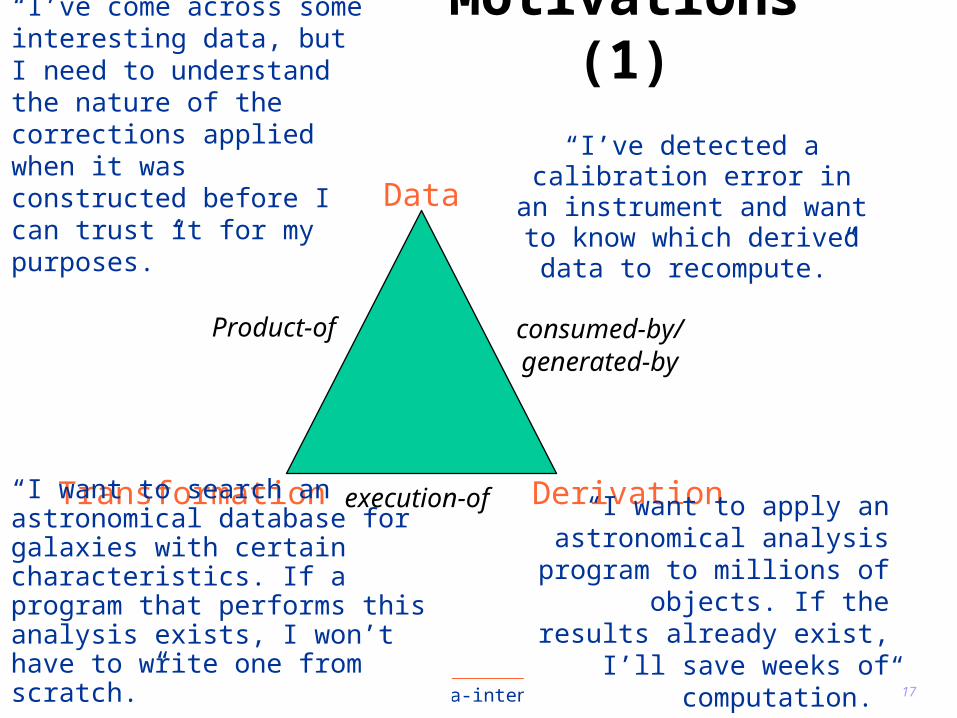
Transformation Derivation
Data
Product-of
execution-of
consumed-by/generated-by
“I’ve detected a calibration error in an
instrument and want to know which derived data
to recompute.”
“I’ve come across some interesting data, but I need to understand the nature of the corrections applied when it was constructed before I can trust it for my purposes.”
“I want to search an astronomical database for galaxies with certain characteristics. If a program that performs this analysis exists, I won’t have to write one from scratch.”
“I want to apply an astronomical analysis
program to millions of objects. If the results already exist, I’ll save weeks of computation.”
Motivations (1)

18Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Motivations (2)
Data track-ability and result audit-ability Repair and correction of data
– Rebuild data products—c.f., “make” Workflow management
– A new, structured paradigm for organizing, locating, specifying, and requesting data products
Performance optimizations– Ability to re-create data rather than move it

19Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Requirements Express complex multi-step “workflows”
– Perhaps 100,000s of individual tasks Operate on heterogeneous distributed data
– Different formats & access protocols Harness many computing resources
– Parallel computers &/or distributed Grids Execute workflows reliably
– Despite diverse failure conditions Enable reuse of data & workflows
– Discovery & composition Support many users, workflows, resources
– Policy specification & enforcement
20Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
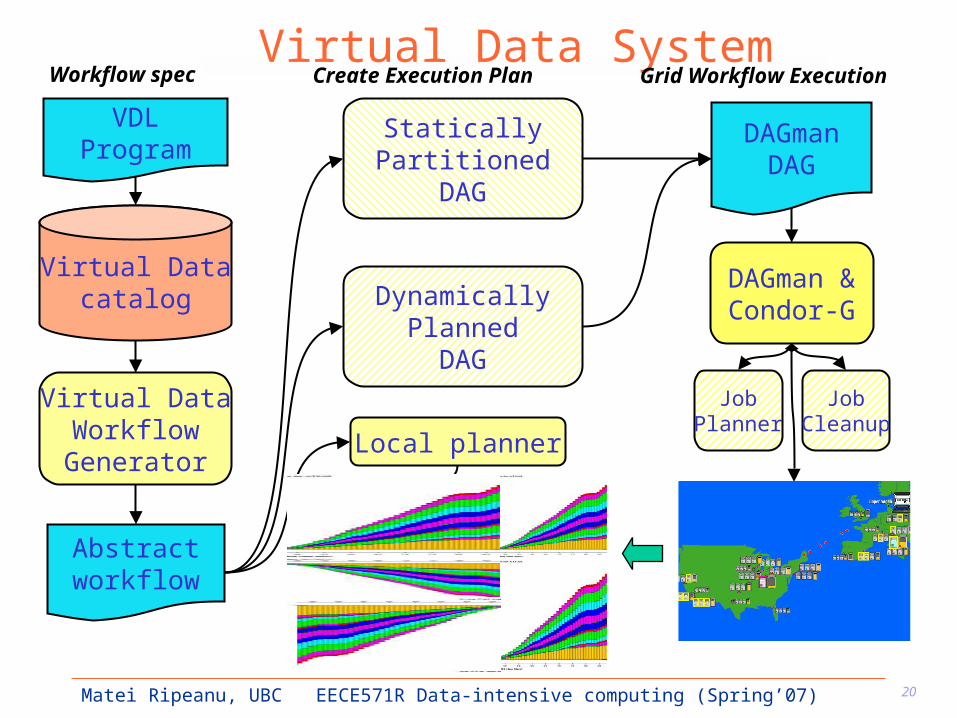
Virtual Data System
Local planner
DAGmanDAG
StaticallyPartitioned
DAG
DAGman &Condor-GDynamically
PlannedDAG
JobPlanner
JobCleanup
Abstractworkflow
VDLProgram
Virtual Datacatalog
Virtual DataWorkflowGenerator
Workflow spec Create Execution Plan Grid Workflow Execution
21Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
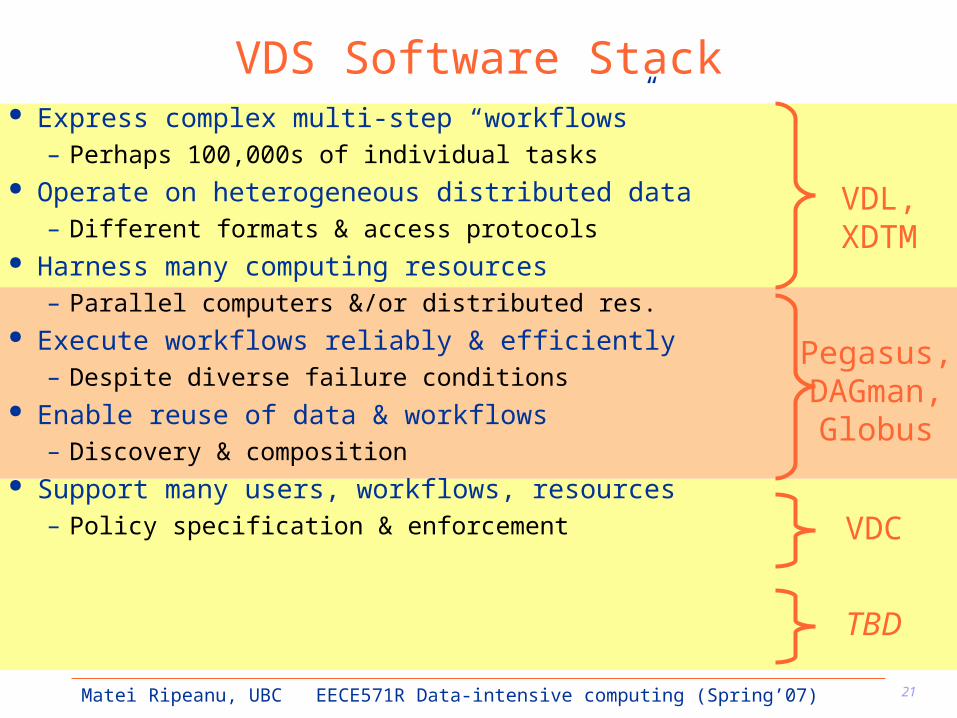
VDS Software Stack Express complex multi-step “workflows”
– Perhaps 100,000s of individual tasks Operate on heterogeneous distributed data
– Different formats & access protocols Harness many computing resources
– Parallel computers &/or distributed res. Execute workflows reliably & efficiently
– Despite diverse failure conditions Enable reuse of data & workflows
– Discovery & composition Support many users, workflows, resources
– Policy specification & enforcement
VDL,XDTM
Pegasus,DAGman,
Globus
VDC
TBD

22Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Outline
Case study (and project ideas):– Volunteer computing: SETI@home /BOINC
– Virtual Data System
– Batch Aware Distributed File System Administrative

Batch-aware Distributed File System

24Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Motivating question: Are existing distributed file systems adequate for batch computing workloads?
NO. Internal decisions inappropriate– Caching, consistency, replication
A solution: Combine scheduling knowledge with external storage control– Detail information about workload is known
– Storage layer allows external control
– External scheduler makes informed storage decisions Combining information and control results in
– Improved performance
– More robust failure handling
– Simplified implementation
Explicit Control in a Batch-Aware Distributed File System, John Bent, Douglas Thain, Andrea C.Arpaci-Dusseau, Remzi H. Arpaci-Dusseau, Miron Livny, (NSDI '04)

25Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Outline
Batch computing– Systems– Workloads– Environment– Why not DFS?
Solution: BAD-FS– Design– Experimental evaluation

26Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Batch computing
Home storage
Internet

27Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
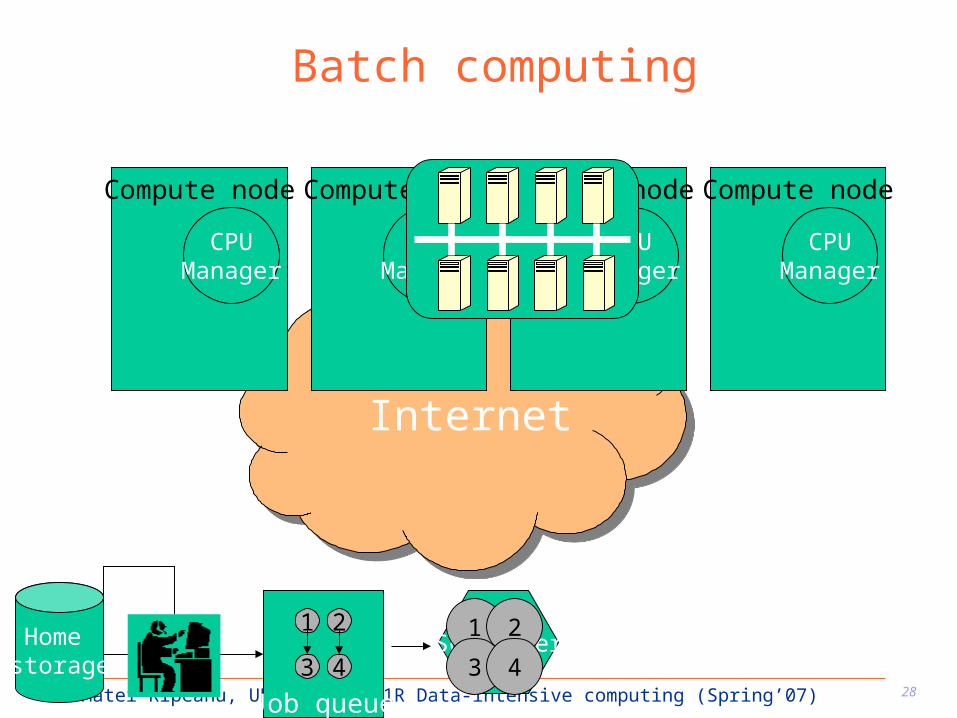
Batch computing
Not interactive Compute Loop
– Users submit jobs> Job description languages
– System itself executes
– Results are copied back to user system Many exiting batch systems
– Condor, LSF, PBS, Sun Grid Engine
28Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Internet
Batch computing
Scheduler
Compute node
CPUManager
Compute node
CPUManager
Compute node
CPUManager
Compute node
CPUManager
Job queue
1 2
3 4Home storage
1 2
3 4

29Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
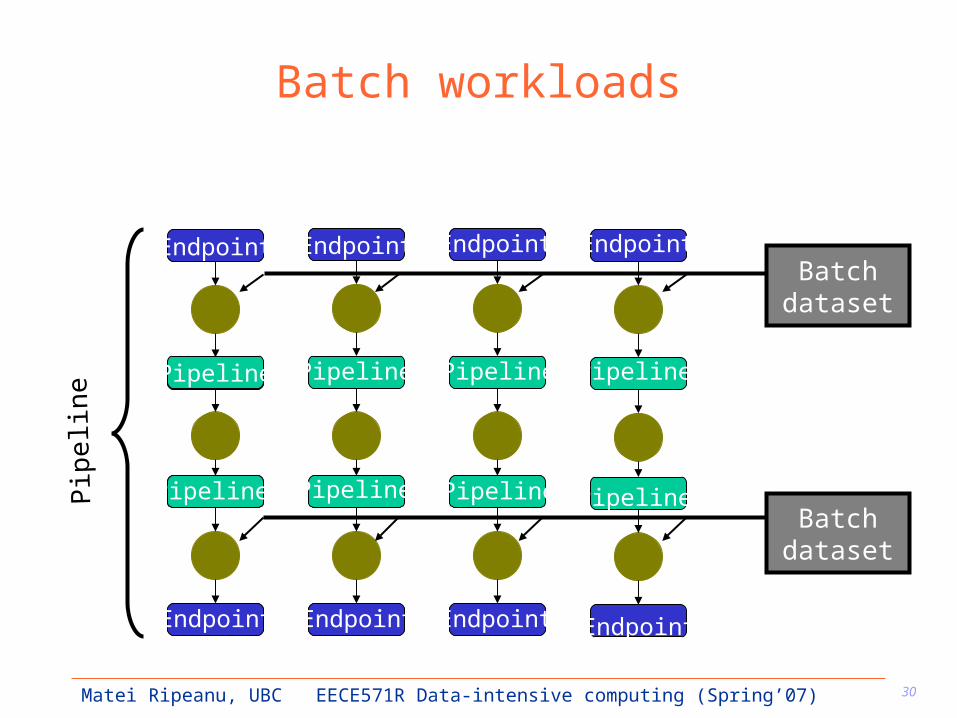
Batch workloads General properties
– Large number of processes– Process and data dependencies– I/O intensive
Different types of I/O– Endpoint– Batch– Pipeline
Usage: mainly scientific workloads, but also video production, data mining, electronic design, financial services, graphic rendering
Pipeline and Batch Sharing in Grid Workloads, Douglas Thain, John Bent, Andrea Arpaci-Dusseau, Remzi Arpaci-Dussea, Miron Livny. HPDC 12, 2003.
30Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Batch workloads
Endpoint
Endpoint
EndpointBatch
dataset
Batch dataset
Pipeline
Pip
elin
e
Endpoint Endpoint
EndpointEndpointEndpointEndpoint
Pipeline Pipeline
Pipeline Pipeline Pipeline
PipelinePipeline
31Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
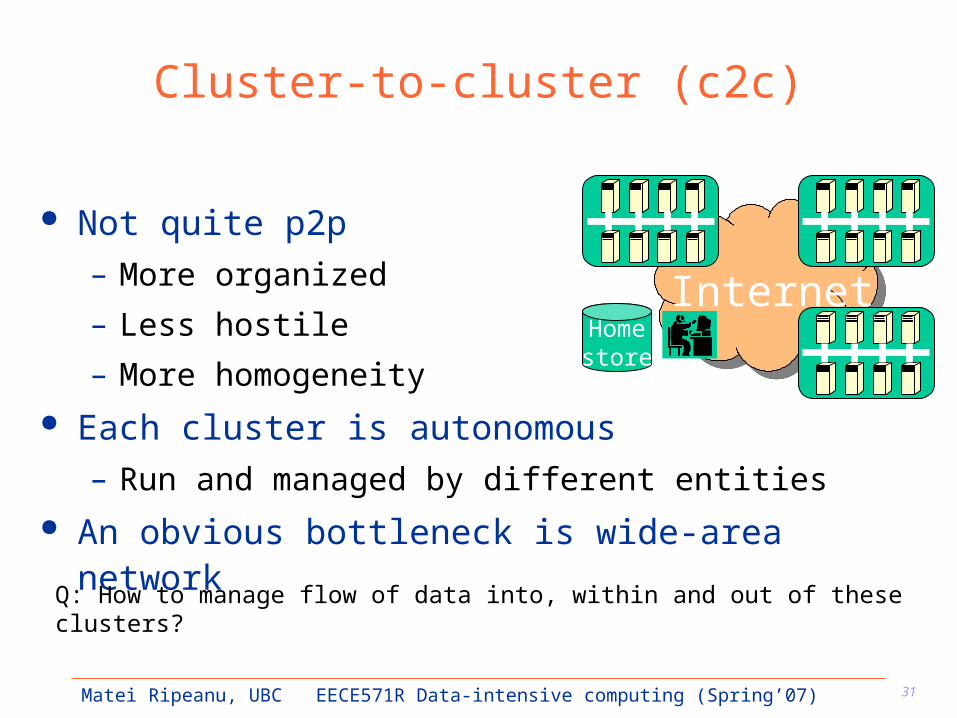
Cluster-to-cluster (c2c)
Not quite p2p– More organized
– Less hostile
– More homogeneity Each cluster is autonomous
– Run and managed by different entities An obvious bottleneck is wide-area network
Q: How to manage flow of data into, within and out of these clusters?
InternetHomestore

32Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Why not a traditional Distributed File System ?
Distributed file system (DFS) would be ideal– Easy to use
– Uniform name space
But . . . – Designed for wide-area networks
– Not practical
– Embedded decisions are wrong
InternetHomestore

33Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Distributed file systems make ‘bad’ decisions
Caching – Must guess what and how to cache
Consistency – Output: Must guess when to commit
– Input: Needs mechanism to invalidate cache Replication
– Must guess what to replicate

34Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
BAD-FS makes ‘good’ (i.e. informed) decisions
Removes the guesswork– Scheduler has detailed workload knowledge
– Storage layer designed to allow external control
– Scheduler makes informed storage decisions> Manages data as well as computations
Retains simplicity of distributed file systems Practical and deployable

35Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Outline
Introduction Batch computing
– Systems– Workloads– Environment– Why not DFS?
One solution: BAD-FS– Design– Experimental evaluation
36Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
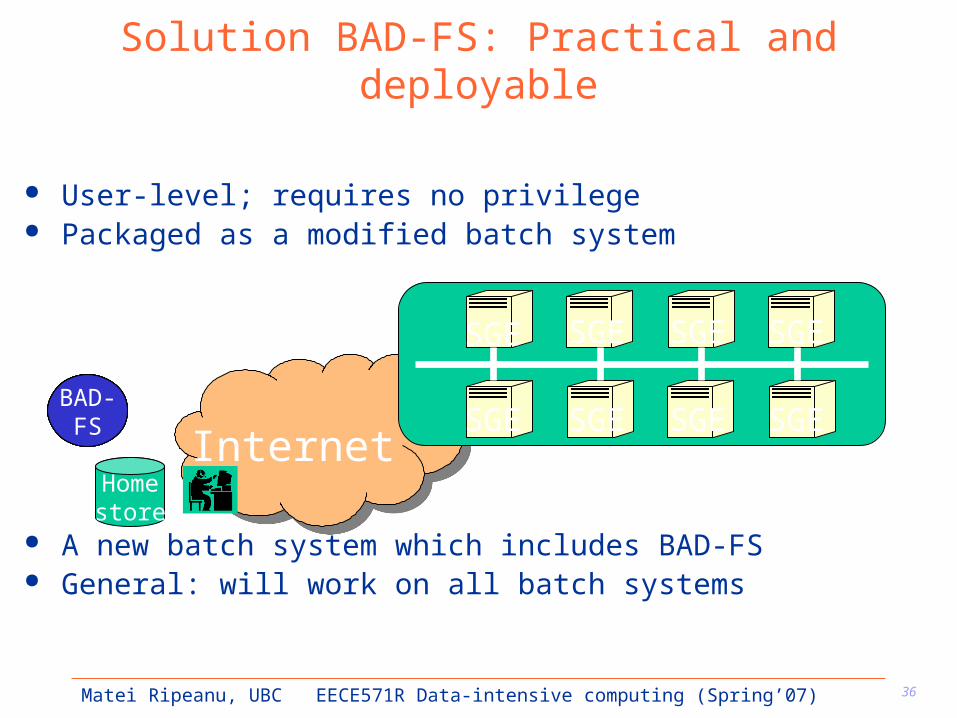
User-level; requires no privilege Packaged as a modified batch system
A new batch system which includes BAD-FS General: will work on all batch systems
Solution BAD-FS: Practical and deployable
Internet
SGE SGE
SGE SGE SGE
SGE SGE
SGEBAD-
FSBAD-
FSBAD-
FSBAD-
FSBAD-
FSBAD-
FSBAD-
FSBAD-
FS
Homestore
37Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
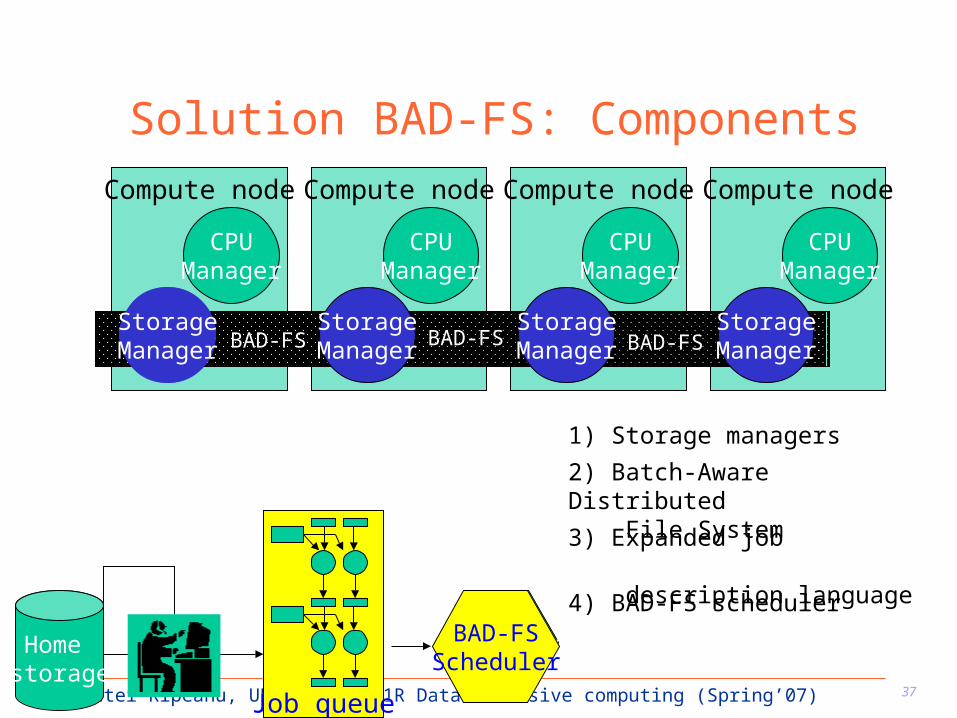
Solution BAD-FS: Components
Scheduler
Compute node
CPUManager
Compute node
CPUManager
Compute node
CPUManager
Compute node
CPUManager
Job queue
1 2
3 4Home storage
Job queue
3) Expanded job description language
BAD-FSScheduler
4) BAD-FS scheduler
1) Storage managers
2) Batch-Aware Distributed File System
StorageManager
StorageManager
StorageManager
StorageManager BAD-FS BAD-FS BAD-FS

38Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Information used
Remote cluster knowledge– Storage availability
– Failure rates Workload knowledge
– Data type (batch, pipeline, or endpoint)
– Data quantity
– Job dependencies

39Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Control through volumes
Guaranteed storage allocations– Containers for job I/O
Scheduler– Creates volumes to cache input data
> Subsequent jobs can reuse this data
– Creates volumes to buffer output data> Destroys pipeline, copies endpoint
– Configures workload to access containers

40Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Knowledge plus control
Enhanced performance– I/O scoping
– Capacity-aware scheduling Improved failure handling
– Cost-benefit replication Simplified implementation
– No cache consistency protocol
41Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
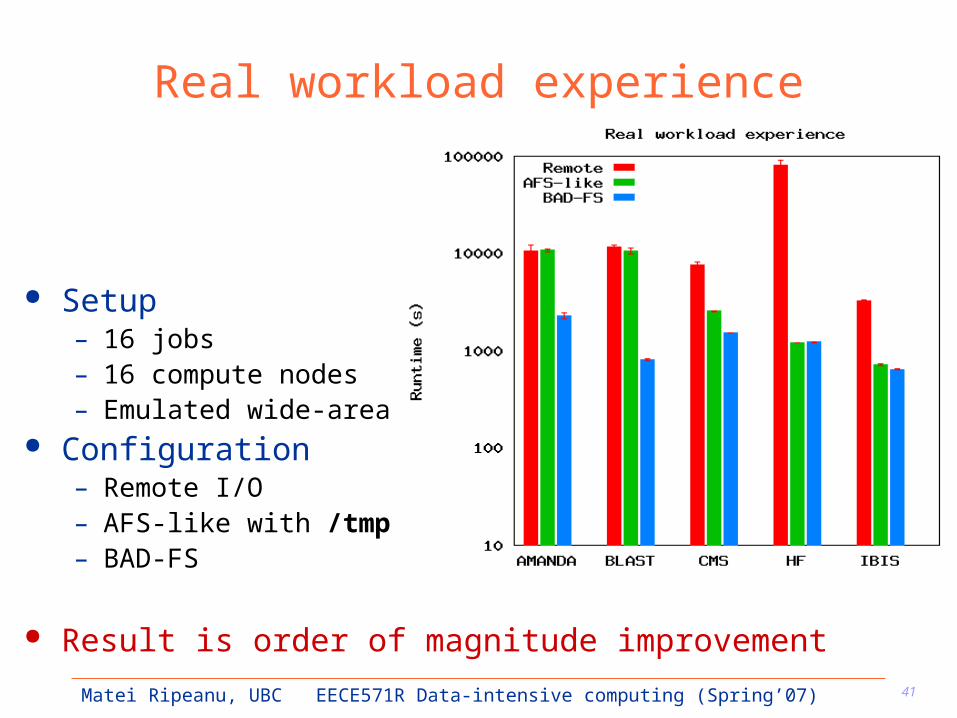
Real workload experience
Setup– 16 jobs– 16 compute nodes– Emulated wide-area
Configuration– Remote I/O– AFS-like with /tmp– BAD-FS
Result is order of magnitude improvement

42Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
BAD-FS Lessons
Generic solutions may be inefficient– Often designed with specific tradeoffs in
mind (e.g., most common workloads) Fix:
– Redesign for new workload
– Use explicit information available at runtime to optimize the execution of lower layers

43Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Course Organization/Syllabus/etc.

44Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia: Course structure
Lectures – About 1/3 of all classes
Student projects – Aim high! Have fun! It’s a class project, not
your PhD!
– Teams of up to 3 students
– Project presentations at the end of the term Paper discussion
– The other classes

45Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia: Weekly schedule (tentative)1. Introduction. Overview of current research problems, technologies, and
applications.2. File system semantics, data durability and availability, replication and
consistency, fault-tolerance. 3. Data storage technologies. Storage hierarchies. Capacity management.4. Scientific applications: data access patterns, workload characterization. 5. Integration with compute systems. Grids and Virtual Data6. Performance focus: caching, parallel access, striping. 7. Structured overlays. Distributed hash tables. Data systems harnessing
structured overlays.8. Security. 9. Applications I: Experience with deployed systems. (NFS, AFS, Google File
System)10. Applications II: Data archival. Cooperative internet proxy caches.
Content distribution networks.11. Applications III: Peer-to-peer file-sharing (BitTorrent, FreeLoader)12. Project presentations

46Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia: Grading
Paper reviewing:35% Discussion leading: 15%
Project: 50%

47Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia:Paper Reviewing (1)
Goals:– Think of what you read– Expand your knowledge beyond the papers that are
assigned– Get used to writing paper reviews
Reviews due by midnight the day before the class Be professional in your writing Have an eye on the writing style:
– Clarity– Beware of traps: learn to use them in writing and detect
them in reading– Detect (and stay away from) trivial claims. E.g., 1st sentence in the Introduction: “The tremendous/unprecedented/phenomenal
growth/scale/ubiquity of the Internet…”

48Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia:Paper Reviewing (2)
Follow the form provided when relevant. State the main contribution of the paper Critique the main contribution: Rate the significance of the paper on a scale of 5 (breakthrough), 4
(significant contribution), 3 (modest contribution), 2 (incremental contribution), 1 (no contribution or negative contribution).
Explain your rating in a sentence or two. Rate how convincing the methodology is. Do the claims and conclusions follow from the experiments? Are the assumptions realistic? Are the experiments well designed? Are there different experiments that would be more convincing? Are there other alternatives the authors should have considered? (And, of course, is the paper free of methodological errors?)

49Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia:Paper Reviewing (3)
What is the most important limitation of the approach? What are the three strongest and/or most interesting ideas in
the paper? What are the three most striking weaknesses in the paper? Name three questions that you would like to ask the authors. Detail an interesting extension to the work not mentioned in
the future work section. Optional comments on the paper that you’d like to see
discussed in class.

50Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia:Discussion leading
Come prepared!– Prepare discussion outline– Prepare questions:
> “What if”s> Unclear aspects of the solution proposed> …
– Similar ideas in different contexts– Initiate short brainstorming sessions
Leaders do NOT need to submit paper reviews Main goals:
– Keep discussion flowing – Keep discussion relevant– Engage everybody (I’ll have an eye on this, too)

51Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia:Projects
Combine with your research if relevant to the class Get approval from all instructors if you overlap final
projects:– Don’t sell the same piece of work twice
– You can get more than twice as many results with less than twice as much work
Aim high!– Put one extra month and get a publication out of it
– It is doable! Try ideas that you postponed out of fear: it’s just a
class, not your PhD.

52Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Administravia:Project deadlines (tentative)
3rd week (Tue): 1-page project proposal 5th week (Tue): 3-page literature survey
– Know relevant work in your problem area– If implementation project, list tools, similar projects– Expand proposal
7th week (Tue): 5-page Midterm project due– Have a clear image of what’s possible/doable– Report preliminary results
First week of exam session: In-class project presentation– Demo, if appropriate
Last week of exam session:– 10-page write-up

53Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Next Class (Thu, 11/01)
Note room change: KAIS Discussion of some project ideas Presentation by Matei
To do: Subscribe to mailing list Volunteers for discussion leaders for class
next week

54Matei Ripeanu, UBC EECE571R Data-intensive computing (Spring’07)
Questions?