논문에서발생하기쉬운 통계적오류hosting03.snu.ac.kr/~hokim/seminar/med20041028.pdf ·...
TRANSCRIPT

논문에서 발생하기 쉬운통계적 오류
김 호
서울대학교 보건대학원2004/10/28

Outline
♦ 의학논문 작성과 통계
♦ 일반 의학 연구방법론
♦ 통계비전공자를 위한 통계
♦ 통계의 오용과 체크 리스트

의학논문 작성과 통계

근거중심의학의 핵심단계
♦ 우리가 원하는 정보를 대답 가능한 질문으로 만든다
♦ 해답을 효율적으로 찾는다. (임상연구, 실험실, 문헌연구)
♦ 타당성 및 유용성 평가
♦ 환자에게 실천
♦ 실천결과를 평가

연구 영역의 종류 1
♦ 치료(Therapy): 약물치료, 수술적 처치, 대안적인환자교육법. 기타 처치들의 효율성을 검정하는 연구 영역. 이를 위한 바람직한 연구설계는 무작위화시험
♦ 진단(Diagnosis): 새 진단법이 타당하며(믿을 수있으며), 신뢰성이 있는지(늘 같은 결과를 보이는지)를 검정하는 연구 영역. 바람직한 연구설계는 새로운 진단법과 황금표준 진단법을 함께 실시하는 단면조사연구(cross sectional survey)
♦ 선별(Screening): 특정 검사가 큰 인구집단에 적용 가능하며 증상 발현 전에 질병을 발견할 수 있는지를 검정하는 연구 영역. 바람직한 연구설계는 단면조사연구

연구 영역의 종류 2
♦ 예후(Prognosis): 질병 발생 초기에 발견된 환자에게 향후 어떤 일이 나타날 것인지를 판단하기 위한 연구 영역. 바람직한 연구설계는 추적 코호트연구(longitudinal cohort study)
♦ 원인(Causation): 해로울 것으로 추정되는 요인(예: 환경오염)이 질병의 발생과 관련이 있는지를판단하기 위한 연구 영역. 바람직한 연구설계는 특정 질병의 유병률이 어느 정도냐에 따라 코호트 연구 또는 환자-대조군 연구(case-control study)중에서 선택. 그러나 증례 보고(case report)역시 중요한 정보를 제공

출판이 거절되는 논문들의 흔한 이유들 1
♦ 임상적으로 중요한 문제를 다룬 연구가 아니다
♦ 고유한 연구가 아니다-즉,이미 누군가가 동일/
유사한 연구를 하였다
♦ 실제로 저자의 가설을 검증한 연구가 아니다
♦ 다른 종류의 연구를 했어야만 했다
♦ 실행상의 어려움(예를 들어, 대상자 모집)으로 인
해 원래의 연구계획대로 하지 못하였다
♦ 표본의 크기가 너무 작았다
♦ 대조군이 없거나 대조군 선정에 문제가 있었다

출판이 거절되는 논문들의 흔한 이유들 2
♦ 잘못되거나 부적절한 통계분석을 하였다
♦ 데이터에 근거하지 않은 결론을 유도하였다
♦ 이해관계 상충이 의심된다(예를 들어, 저자나
연구의 후원자가 본 연구의 출판으로 인해 재정
적인 이익을 얻을 수 있는 상황이고 편견을 방지
할 만한 보호장치가 충분치 않을 때)
♦ 이해하기 힘들 정도로 글이 엉망이다

의학연구 방법론

연구방법론 평가(1)
♦ 독창적인 연구인가 ?
♦ 연구의 대상은 누구인가 ?– 어떻게 선정 ? Representative sample
– 포함, 제외 기준
– ‘현실적’ 치료 환경에서 진행되었나 ?
– Drop out rate
♦ 올바른 연구설계 ?– 연구 설계 시 고려점, 비교는 공정하게?
– 결과 측정 (Dose selection, outcome measure)

연구방법론 평가(2)
♦ 연구에서 통제가 잘 이루어 졌나?
– 무작위 과정
– 대조군 적절 ?
– 맹검법
♦ 연구의 규모, 충분한 추적기간, 추적조사 완결 ?

무작위화시험 연구설계의 장점
♦ 정밀하게 정의된 환자군(예:50-60대의 폐경기
여성)에서 단일변수(예: 약물 대 위약의 치료효과)
를 대상으로 엄격한 평가가 가능하다
♦ 전향적인 연구설계(결과에 대한 자료가 연구 시
작 후에 얻어짐)이다
♦ 가설연역적 추론, 즉 가설을 확인하는 것보다는
반증을 찾으려고 시도한다
♦ 치료 여부를 제외하고는 동질적인 두 군을 비교
하므로 편견의 소지를 없애기 용이하다
♦ 몇몇 유사한 임상시험 결과를 통합하여 고찰할
수 있는 메타 분석을 가능하게 해준다

무작위화시험 연구설계의 단점♦ 비용과 시간이 많이 든다
♦ 대상자 수가 너무 적거나 추적기간이 너무 짧은 연구가 많다
♦ 연구내용에 간섭하는 주체가 될 수 있는 대학, 정부, 제약회
사 등의 재정지원을 받는 경우가 많다
♦ 임상적인 결과를 측정하는 데 있어 대리종료점의 사용을 선호
하는 경우가 흔히 있다
다음과 같은 과정을 통해 미처 인지하지 못한 편견이 개입될 소
지가 있다.
♦ 완벽하지 않은 무작위화 (block의 처리 등)
♦ 의사가 처치에 잘 반응할 것으로 예상되는 환자들만을 참여시
킴으로써 참여 자격을 갖춘 환자들 중 일부만이 무작위 배정에
참여
♦ 환자가 어느 처치군에 배정되어 있는지를 평가자가 알고 있을
때

Outcome measures
- Primary Outcome -
♦ 유무기준
– 질환증상, 징후, 병변
♦ 등급기준
– 5점척도 등
♦ 상대적 변화
– 혈압의 변화

Surrogate endpoint
Tumor response
Time to disease
progression
Blood glucose
Intraocular pressure
Score on psychological test
Survival
Survival
Loss of vision
Mental status
Cancer
DM
Glaucoma
Mental illness
Surrogate endpoint True endpointDisease

통계비전공자를 위한 통계♦ 모집단과 표본
♦ 모수적 방법과 비모수적 방법
♦ 정규성 검정
♦ 변수의 종류에 따른 분석법
♦ p-value
♦ 통계적 가설 검정

통계적 사고
• <-> 결정론적 사고
• 모집단과 표본
• 정규분포를 결정하는 모수 (평균과분산)
• 평균 : 위치
• 분산 : 산포 (정밀도)

모집단과 표본
• 모집단 : 연구자가 최종적으로 관심을 가지는 집단
• 표본 : 모집단에 대한 통계적 결정을하기 위하여 모집단으로부터 대표성있게 뽑은 집단
• 표본이 대표성이 있게 모집단을 반영하여야 함

모수적 방법과 비모수적 방법 (1)
3.5191,2,3,4,5,100
331,2,3,4,5
중앙값평균자료
• 중앙값(median)은 평균에 비하여 이상치에 대해서 둔감(robust)하다.
• 자료의 정규성 분포가정을 하면 평균과분산을 통하여 모집단의 성질을 완전히파악할 수 있다. (모수적 방법)

모수적 방법과 비모수적 방법 (2)
• 비모수적 방법은 자료의 (정규성) 분포가정을 하지 않는다
• 자료의 평균과 분산이 아닌 순위를 이용한 방법을 사용한다.
• 자료의 분포가정 (eg 정규성)이 만족되면 효율이 떨어진다.
•Robust 한 결과를 준다. (outlier에 둔감)

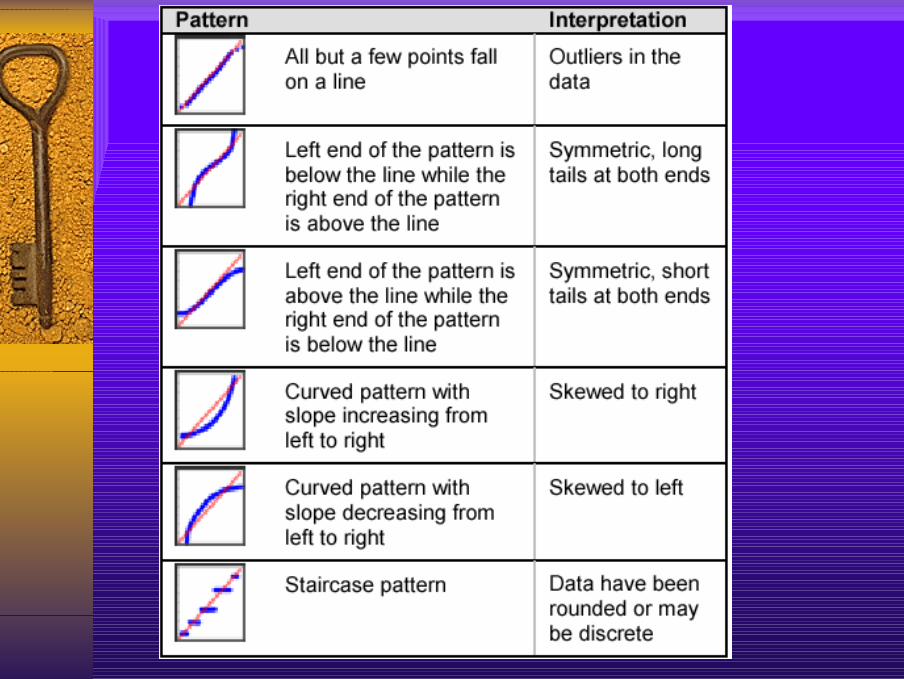
자료의 정규성 검정 (SAS 예제)
data ;input diameter @@;label diameter='Diameter in mm';datalines;5.501 5.251 5.404 5.366 5.4455.576 5.607 5.200 5.977 5.177...;run;proc univariate data=rods normal;histogram diameter /normal (mu=est sigma=est)midpoints = 5 to 6.30 by 0.15;run;


proc univariate data=rods noprint;probplot diameter /normal (mu=est sigma=est);run;
Skewed to the right

변수 종류에 따른 통계분석법
생존분석
연속형 + 범주형
나이 smoking 여부
생존시간 (연속형, >0)
공분산분석
(ANCOVA)
연속형 + 범주형
(재태기간 smoking 여부)
연속형 (출생 시 체중)
회귀분석연속형 (재태 임신기간)
연속형 (아기의 체중)
카이제곱검정 (하나의 독립변수)
로지스틱 회귀분석(둘 이상의 변수)
범주형 (투약여부)범주형 (병 발생 여부)
분산분석(ANOVA)범주형 (3개 이상)연속변수 (혈압)
T 검정, paired T검정
명목척도(2개 범주)연속변수 (혈압)
통계분석법독립변수종속변수

Spearman’s correlation
Kendall’s tau
Stuart’s tau
Pearson correlation
상관분석
Friedman’s 2-way ANOVA
2-way ANOVA제3의 변수의 영향고려
Kruscal-Wallis testANOVA세 개 이상의 집단
Wilcoxon signed rank test
Paired t-test두개의 짝 지은 집단
Wilcoxon rank sum test
Man-whitney median test
T-test종속변수가 연속형
두개의 독립된 집단
Fisher’s exact test
Ncnemar test
Cochran’s Q
카이제곱검정종속변수가 범주형
비모수적 방법모수적 방법자료의 성격

P-value (1)
♦ 연구목적 : 관심변수의 (모)평균이 두 집단에서 다르다.
♦ 첫 번째 집단에서의 표본 평균
♦ 두 번째 집단에서의 표본 평균
♦ 만약 두 집단에서의 모평균이 같다고 하면
♦ 두 표본 평균은 비슷할 것이다.
♦ 표본평균의 차이를 반복적으로 구해보면
1Y
2Y

P-value (2)
0
통계적으로 대단히 일어나기 어려운 사건

P-value (3)
♦ P-value = 두 집단의 평균이 같다고 가정했을때 우리의 자료, 혹은 더 차이가 나는 자료를얻을 확률
♦ 작은 p-value : 위의 확률이 작다
통계적으로 가능하지 않은 일이 일어났다.
두 집단의 평균이 같다는 가정에 문제가 있다.
두 집단의 평균은 같지 않다고 결론 내린다.

P-value (3)
♦ 작지 않은 p-value : 두 집단의 평균이같다고 가정하면 우리의 자료를 관측할확률이 작지 않다.
두 집단의 평균이 같다는 가정에 문제가없다.
양쪽검정, 한쪽검정

♦ A(얻은 자료) -> B (연구가설)
♦ -B -> -A
♦ 귀무가설 (-B) : 두 집단에 차이가 없다. (Ho)
♦ 대립가설 (B) : 두 집단에 차이가 있다. (Ha)
♦ 일종의 오류 : 옳은 귀무가설을 기각할 확률
= Pr (reject Ho | Ho is true)
♦ 이종의 오류 : 틀린 귀무가설을 받아들일 확
률 = Pr (Not reject Ho | Ha is true)
♦ Power = 1- (있는 차이를 발견할확률)
αβ
β

가설설정1) 귀무가설(null hypothesis, H0) : 시험의 효과가 없다
2) 대립가설(alternative hypothesis, Ha) 증명하고자
하는 가설.
예) 새로 개발된 항암제의 치료율(Pt)이 기존 약의 치
료율(Pc) 보다 높을 것이라는 연구목적을 실험하고
자 할 때
새로 개발된 소염제와 기존 소염제의 치료 후 관절
염의 재발율에 차이가 있는 지를 보고자 할 때
♦ 동일한 와 를 사용하였을 경우 단측보다도 양측
의 경우가 더 많은 연구대상수를 필요
α β
( ): , 0,a t c t cH P P P P≠ − ≠또는 양측가설
( ): , 0,a t c t cH P P P P> − >또는 단측가설

♦ 가설검정시 발생 가능한 4가지 상황
옮음(검정력=1- )
제1종 오류( )H0 기각
제2종 오류( )옳음(1- )
H0 채택
H0 거짓(Ha 참)
H0 참
모집단의 진실표본을 이용한가설검정결과
α
αβ
β

오류의 비교
♦ Ho : 두 약의 효과의 차이가 없다.
♦ Ha : 두 약의 효과에 차이가 있다.
♦ 제 1 종의 오류 = P(차이가 있다. |실제는 차이
가 없다)
♦ 제 2 종의 오류 = P(차이가 없다. |실제는 차이
가 있다)

ex) 한 test 에서 유의수준이 인 test가 있다고 하자.
일반적으로 를
multiple comparison을 한다면
overall 는 0.05가 아니라 0.1855가 되므로 type I error가
Inflate 되었다.
α
∴∴∴
01 1 01 01
02 2 02 02
0 0 0 01 02
01
Let : 0, Pr(do not reject H H is true) 1
: 0, Pr(do not reject H H is true) 1
then Pr(do not reject ) where and
Pr(do not reject H and do no
H
H
H H H H H
α αα α
= = −
= = −
=
= 02 0
2
t reject )
(1- ) (1- ) (1- )
H H
α α α= =
1 2 3 0kα α α α= = = ⋅⋅⋅⋅ = =
4
(1 ) (1 )1 0.1855 0.8145 ( .95) .95
kα α− ≤ −− = = ≤
∴ α
Multiple Comparisons (다중비교)

Bonferroni Correction : 만약 m개의 multiple comparison을 한다
면 각각의 유의수준을 로 하면 전체의 유의수준을 에 가
깝게 할 수 있다.
예)m이 4인 경우
응용) 10개의 mean을 비교하는 경우
p값의 기준을 0.05로 하면 overall p값을 유지할 수 없으므로 각각
의 경우 를 기준으로 test를 실시한다.
이를 “Bonferroni corrected p-value”라고 한다.
mα
40.05(1 ) 0.95 1 0.054
− ≅ = −
0.05 0.00510
=
Multiple Comparisons (다중비교)
α

T-test
♦ 관심 변수가 연속일 때 (정규분포를 따를 때) 두 집단 간에 평균의 차이를 보는 검정 : 두개의 독립적인 집단간의 차이
♦ Paired(짝지은) t-test : 한 개체에서 짝지은관찰치들의 동질성을 볼 때 : 처치 전의 값과후의 값을 비교할 때 (처치전과 후에 상관관계가 존재한다는 가정을 고려)
♦ 표본수가 적은 경우에는 정규분포 가정을 확인하기가 곤란하다. -> 비모수적 방법
♦ 두 개 이상의 집단 혹은 다른 변수로 보정을할 때 -> ANOVA (분산분석)




카이제곱 검정 (1)
3
15
Not
229 (36.4%)Drug B
3116
(45.2%)Drug A
TotalSatisfied

카이제곱 검정 (2)
22Drug B
28
Not
5325Total
3131/53 * 25/53 * 53=14.6
Drug A
TotalSatisfied
만약 약제와 반응이 독립이라면 기대값은

카이제곱 검정 (3)
• 카이제곱 통계량은 이 기대치와 실제값의 차이의 제곱의 함수이다.
• 카이제곱 통계량이 크다 (작은 p-value) -> 기대치와 실제값이 다르다-> 기대치를 계산하기 위한 가정 (귀무가설: 두 변수가 독립이다)이 틀리다 -> 두 변수간에 상관이 있다 (약품에 따라반응이 다르다)는 대립가설을 채택한다.



McNemar Test : Matched pairs

Frequency| Percent | Row Pct | Col Pct |yes |no | Total ---------+----------+----------+ yes | 20 | 5 | 25
| 44.44 | 11.11 | 55.56 | 80.00 | 20.00 | | 66.67 | 33.33 |
---------+----------+-----------+ no | 10 | 10 | 20
| 22.22 | 22.22 | 44.44 | 50.00 | 50.00 | | 33.33 | 66.67 |
---------+----------+----------+ Total 30 15 45
66.67 33.33 100.00
Statistics for Table of hus_resp by wif_resp
McNemar's Test -----------------------Statistic (S) 1.6667 DF 1
Pr > S 0.1967
“Ho : husband and wife 의 approval rates는 같다”를 기각하지 못함.

Simple Kappa Coefficient --------------------------------Kappa 0.3077 ASE 0.1402 95% Lower Conf Bound 0.0329 95% Upper Conf Bound 0.5825
Sample Size = 45
신뢰구간이 0을 포함하지 않으므로 =0 이라는귀무가설을 95% 신뢰수준에서 기각한다.
Kappa=1 >> perfect agreement, Kappa > 0.8 >> excellent agreement Kappa > 0.4 >> moderate agreement

통계의 오용과 체크 리스트

결과를 쓸 때 통계로 거짓말하는 열 가지 방법(1)
♦ 모든 자료를 무조건 컴퓨터에 넣고 돌리다가, p값이 0.05
에 미달하는 것은 모두 유의한 관련이 있다고 보고
♦ 비교군간의 기본특성 비교에서 치료군에 유의한 차이가
존재하는데도 이를 보정하지 않음
♦ 자료가 정규분포하고 있는지를 검정하지 않음. 비모수 검
정을 해야만 하는 상황이 발생할 수도 있음
♦ 모든 중도탈락자와 무응답자를 무시하고 분석함
♦ 어떤 경우에서도 두 자료간의 점도표(plot)를 그려서 “r값(피어슨 상관계수)”을 구할 수 있고, 유의한 r값을 인과관계
의 증명이라고 주장함
♦ 외딴값 때문에 분석결과를 망치게 될 염려가 있으면 이 값
을 없앰. 그러나 이런 값이 결론에 도움이 되는 것이라면 아
무리 이 값이 의심스러워도 남겨놓고 분석

결과를 쓸 때 통계로 거짓말하는 열 가지 방법(2)
♦ 비교군간 결과 값의 신뢰구간이 서로 중첩되면 이 수치를
논문에서 삭제. 대신 본문에서 짧게 이 부분에 대한 언급만
하고 도표로 보여주지는 말고 결론을 내리는 데에도 이 결과
를 무시
♦ 만일 6개월을 예정으로 한 추적조사 기간 중 4개월 반째에
두 비교군간에 유의한 차이가 나타났다면, 연구를 중단하고
논문을 쓰기 시작. 또는 6개월째의 결과가 유의한 차이에 근
접하는 것으로 나타났다면, 추적조사 기간을 3주 더 연장
♦ 만일 흥미 있는 결과가 나오지 않았다면 다시 컴퓨터를 돌
려서 특정 세부군 내에서는 다른 결과가 나타나는지 찾아봄.
그러면 전체 대상군 중 52~61세의 중국계 여성에서는 당신
의 치료가 효과 있는 것으로 나타날지 모름
♦ 당신이 계획한 방법으로 자료를 분석한 결과, 원하는 결과
가 나오지 않았을 떄 다른 검정법을 선택하여 분석을 다시
진행.



통계 체크 리스트
♦ 대상연구군 간의 비교 확인
♦ 짝지은 자료의 처리, 독립성 여부 확인
♦ 이상치에 대한 처리
♦ 인과관계와 상관관계
♦ 인과성의 방향
♦ p-값의 해석
♦ 신뢰구간 계산 여부
♦ 논문의 결론이 바른 통계량에 기초하고 있는가 ?

표본수, Get Motivated
n++n+2n+1
n2+n22 52n21 48-
n1+n12 48n11 52+
Trt BTrt A
( )( )
( )( ) ( )
211 1 12 1 2 1 2
11 211
22
2
/,
1
52 100 100 / 2000.32, 0.05
100 100 100 100 / 200 199
n n n n n n n nvv n n
p
χ
χ
+ + ++ + + + +
++ ++
−= =
−
− ×= = >
× × × ×

♦ 라고 하고, 를 다시 계산하면
♦ 두 예에서 비율은 정확히 같음에도 불구하고 통계
적 유의성은 상당히 다르다. ???
♦ 전통적 통계적 가설 검정의 유의성은 표본수에 크
게 의존한다.
♦ 통계적 유의성이 없었던 경우라도 표본수를 크게
하면 유의성을 볼 수 있다.
♦ 표본수(실험의 비용)와 통계적 유의성(실험의 효
용성)의 균형을 맞추는 것이 요구됨
♦ 최소의 비용으로 효과를 증명하고 싶다.
100ij ijn n∗ = × 2χ
2 2 2100 /100 32.00, 0.01pχ χ∗ = × = <

연구대상수의 계산 시 고려할 사항♦ 어떠한 연구설계인가? (연구설계의 형태)♦ 처치 후 결과는 언제 나타나는가?
(처치효과의 지연기간)♦ 처치의 결과는 이산형인가 연속형인가?
(결과의 척도)♦ 연구기간을 얼마나 길게 할 것인가?
(예상되는 추적기간)♦ 중도에 탈락하는 사람은 얼마나 될 것인가?
(예상되는 추적손실)♦ 연구자의 지시대로 치료를 잘 받는가?
(예상되는 처치의 비순응율)♦ 할당비는 얼마로 할 것인가? (시험군 : 비교군)♦ 시험집단의 수는 몇 개로 할 것인가?

연구설계의 형태
1) 고정형 연구설계 (Fixed sample size design)
임상시험을 시작하기 전에 연구자가 필요한 연구대상
수를 확정하는 방법.
2)연속형 연구설계(Sequential design)시험군과 비교군의 관찰된 결과의 차이가 미리 설정
된 유의한 범위를 벗어날 때까지 계속해서 연구대상
을 모집하여 진행하는 방법.

결과변수의 척도♦ 연속형 변수
– 비척도(Ratio Scale) : 혈당량, 혈압, 적혈구수, 무게(mg, Ib등),
부피(cc, m3 등), 비율, 시간의 길이
– 간격척도(Interval scale) : 온도(℃,℉), Circular scale(1년, 24시
간, 방위)
♦ 범주형변수
– 순위척도(Ordinal scale) : 암의 진행정도(제1기, 제2기, 제3기),
당뇨의 정도(+, ++, +++) 등
– 명목척도(Nominal scale): 생사여부, 질병발생여부, 종교의 종
류 등

이분형 결과에 대한 비교(비율을 비교하는 경우)♦ 두 비율의 비교
( )
0 1 2 1 2 1 2
2
1 1 2 2
2
: ( ) . :
2 ( )
aH P P P P vs H P P
Z pq Z PQ P Qn
dα β
= < >
+ +=

예) 신약의 부작용 발생률이 기존 약의 부작용 발생
률(30%로 알려져 있다고 하자)보다 5% 이상 작다
는 것을 증명하고자 하는 연구에서의 적절한 표본
수는 ? 6개월 동안 추적손실은 5%이며 환자의 순
응도는 90%라고 가정한다. 일종의 오류=5%, 검
정력=80%
2
1.645, 0.840( )
(0.30 0.25)/2 0.275
1.645 2 0.275 0.725 0.840 0.3 0.7 0.25 0.75 983.900.05
Z Z
Pα β= =
= + =
× × + × + × =
단측검정
이며

91215
101317
111418
111419
111419
111419
111418
101317
111419
121621
131722
141823
141824
141824
141823
131722
131722
151925
162128
172229
182330
182331
182330
172229
172128
192432
212735
232938
243040
243141
243141
243040
212735
253142
2873547
303851
324154
334256
334256
334256
273546
334356
384965
425472
455877
476080
486182
486182
384965
486282
577296
6481
108
6988
117
7393
124
7596
128
7697
129
5975
100
7899
133
95120161
108138184
119152203
128162217
133169226
136173231
110140187
156199266
197250334
231293392
258328439
280356476
295375502
305387518
342434581
539685916
7129041210
86010931462
98412491672
108313751840
115714691966
120615322050
.05
.10
.15
.20
.25
.30
.35
.40
0.500.450.400.350.300.250.200.150.100.05
Expected difference between P1 and P2Smaller of P1 and P2a
upper number : α = 0.05 (one-tailed) or α = 0.10 (two-tailed) ; β = 0.20middle number : α = 0.025 (one-tailed) or α = 0.05 (two-tailed) ; β = 0.20lower number : α = 0.005 (one-tailed) or α = 0.01 (two-tailed) ; β = 0.20
표. 두집단의 비율 비교시의 표본수표(단형할당의 경우 각 집단별 표본수)

91215
---
---
---
---
---
---
---
---
---
121621
111419
---
---
---
---
---
---
---
---
162128
151925
131722
---
---
---
---
---
---
---
232938
212735
192432
172128
---
---
---
---
---
---
324154
303851
283547
253142
212735
---
---
---
---
---
476080
455877
425472
384965
334356
273546
---
---
---
---
7596
128
7393
124
6988
117
6481
108
577296
486282
384965
---
---
---
136173231
133169226
128162217
119152203
108138184
95120161
7899
133
5975
100
---
---
308391523
305387518
295375502
280356476
258328439
231293392
197250334
156199266
110140187
---
123115632092
123115632092
120615322050
115714691966
108313751840
98412491672
86010931462
712904
1210
539685916
342434581
.45
.50
.55
.60
.65
.70
.75
.80
.85
.95
0.500.450.400.350.300.250.200.150.100.05

추적 손실과 순응도를 고려하면 각 처리군 별로
984 1150.88 1151 .(1 0.05) 0.90
n = = ≅− ×
의 표본수를 얻는다

연속형 변수의 비교
예) 새로운 관절염 치료제의 치료효과에 대한 임상실
험을 실시한다고 하자.
치료효과는 2주간 치료 후 혈중 Prostag-landing 양
이 평균 10 , 표준편차 2 이면 치료가 된 것으로 간
주한다. 치료 후 두 집단의 혈중 Prostaglandin 양의
변동이 20% 미만이면 두 치료제의 효과는 동등한
것으로 간주한다. 단측 검정으로 연구 대상수를 구
하시오. 또 동일한 가정으로 양측검정의 결과와 비
교하시오.
결과의 척도 :Prostaglandin농도 (연속형)

( )2 2
2
1.645 , 1.282
2 1.645 1.282 2.017.13 18
2t c
Z Z
n n
α β= =
× + ×= = = ≅
2 2
2
2( )( )c
c t
Z Zn α β σ
µ µ+
=−
1 2 2 / (10 0.2) , 2.0 /A gm dl gm dlµ µ µ σ µ∆ = − = × =
Effective Size (=E/S)= 1 2( ) /µ µ σ−

♦ 표. 두 집단의 평균 비교시의 표본수표(단형할당의 경우 각 집단별 표본수)
1237550309
19813777
493425
191512
1713762428
274190107
694835
272117
2165962541
346241135
876044
342722
1570698393
25117498
634432
251916
2102934526
336234131
845843
332621
25991155650
416289162
1047253
413226
23771038584
374260146
936548
362923
29771323744
476331186
1198361
473730
35631584891
570396223
1439973
564436
.10.15.20
.25
.30
.40
.50
.60
.70
.80
.901.00
0.200.100.050.200.100.050.200.100.05β=
E/Sa
0.050.10
0.0250.05
0.0050.01
One-tailed α =Two-tailed α =

♦ 앞 표을 이용하면 E/S=2/2=1 , n=17한편 양측검정을 실시하면 이므로
앞 표를 이용하면 n=21
1.960Zα =
2 2
2
2 (1.960 1.282) 2.0 21.02 212t cn n × + ×= = = ≅

연구대상수를 최소화하는 방법
1) 연속변수를 사용한다.예를 들면 혈압을 연속형(mmHg) vs. 이분형(고혈압여부)
2) 변수를 보다 정밀하게 측정한다.분산 줄이기
3) 짝 측정치를 사용하라.4) 이형 할당법을 사용한다.5) 보다 일반적인 결과를 사용한다.

참고서적
1) Piantadosi, S. (1997), Clinical Trials, A methodological perspectives, John
Wiley & Sons, New York.
2) Machin, D. et al. (1987), Sample size tables for clinical studies, Blackwell
Sciences, London.
3) Schein-Chung Chow and Jen-pei Liu (1998), Design and analysis of clinical
trials: Concepts and methodologies, Wiley
4) Schuster, J.J. (1993), Practical handbook of sample size guidelines for
clinical trials, CRC Press, Florida.
5) 김 호 (2002), 적절한 연구대상수의 산출, 대한마취과학회지: 42(1), 1-10.
6) 트리샤 그린할프/신승수 옮김 (2003), 의학논문 제대로 읽기, 몸과 마음
7) Sackett DL et al (1996), Evidence based medicine: what it is and it isn’t. BMJ:
312, 71-2.
8) 이승욱 (2000), 통계학의 이해, 자유출판사
9) 민양기, 석명훈 (1997), 실용의학논문의 작성과 발표, 중앙문화사

감사합니다. !
http://plaza. snu.ac.kr/~hokim
열린 강의실 , 세미나 자료
논문에서 범하기 쉬운 통계적 오류 (2004/10/28)