高速化ワークショップ2018 2018-03-19 02openfoamの gpuによる高速化事例紹介...
TRANSCRIPT

OpenFOAMのGPUによる高速化事例紹介
平成29年度 高速化ワークショップ~「京」を中核とするHPCIにおけるメニーコアの活用を目指して~
2018年3月23日(金)赤坂インターシティコンファレンス
山岸孝輝 井上義昭 青柳哲雄 浅見曉(高度情報科学技術研究機構)
1ver 1.1

outlineGPU版OpenFOAM RapidCFDの最適化について
RapidCFDへのGPUDirect適用(TSUBAME 3.0)について
2

OpenFOAMとGPUGPU:NVIDIA GPU
実装に手間+性能出すのは大変RapidCFD: simFlow社によるGPU実装版
リリースは3年前、最後のbug fixは2年前単体CPUはCPU比で2倍程度の性能複数GPUで性能がスケールしない
3
Githubでソースコード公開https://github.com/Atizar/RapidCFD-dev
RapidCFD高速化@TSUBAME 3.0について紹介

TSUBAME 3.0 測定環境項目 内容
HW TSUBAME 3.0 SGI ICE XACPU Xeon E5-2680v4[426GF, 2.4GHz, 14core], 2socketGPU Tesla P100 with NVLink[5.3TF, 16GB], 4boardノード間接続 Intel Omni-Path 100Gb/s x4
SW C++ Icc 17.0.4MPI OpenMPI 2.1.1CUDA CUDA 8.0.61
AP OpenFOAM 2.3.0RapidCFD 2.3.1+ThrustライブラリによるGPU実装解析ソルバ pisoFoam/pimpleFoam
解析データ (1)弱スケーリング 128x128x128 cells/processor~(2)強スケーリング 240x130x96 cells/1-64processros
4
GPU向け汎用ライブラリC++のSTLと同様のインターフェースを持つ
アプリ最適化について
GPUDirect適用について

解析モデル 1(弱スケーリング)
16m 3m
2m風洞測定部
200万格子/GPU or CPU で一定(弱スケーリング)
GPU or CPU 格子数
1 128x128x128 200万
2 256x128x128 400万
4 512x128x128 800万
8 256x256x256 1600万
16 512x256x256 3200万
5理想的には性能(経過時間)はスケール(一定)
1プロセッサあたり200 or 300万格子を設定
200万格子での設定

CPU vs GPU(ASIS)
6同世代のCPUに比べて3.3倍高速
44.4
13.3 0
10
20
30
40
50
CPU GPU
300万格子/1GPU or 1CPU
CPUは12コアでflat MPI
プロセッサ単体での性能
3.3倍
[秒]
CPU:E5-2680v4GPU:P100

GPU 弱スケーリング性能(ASIS)
7GPUのノード内並列で性能劣化 4GPUで2倍低速
2種類のGPU配置方法で計測(1→4GPU)
10.6 14.9
23.2
0
5
10
15
20
25
1 2 4
10.6 11.5 12.1
0
5
10
15
20
25
1 2 4
X4ノード内並列
ノード間並列
200万格子/1GPU[秒] [秒]
GPU数 GPU数

ASIS 各処理プロセス毎のコスト
8
0.1 0.1 0.1
6.0 8.4
13.5 0.7
1.0
1.5
0.8
1.0
1.5
1.5
2.1
3.6
1.1
1.6
2.1
0.2
0.3
0.4
0
5
10
15
20
25
1 2 4
othersUEqn.2UEqn.3UEqn.4PISO.2pEqn.2pEqnpEqn.3pEqn.4
ノード内並列
GPU数
メインループでの分類pisoFoamソルバ
pEqn(圧力計算ソルバ)のコストをさらに分析した
[秒]
Ueqn.*(速度計算)

ソースコード解析 性能阻害箇所template<>scalar sumProd(const gpuList<scalar>& f1, constgpuList<scalar>& f2){
if (f1.size() && (f1.size() == f2.size())){
thrust::device_vector<scalar> t(f1.size());
thrust::transform(
f1.begin(),f1.end(),f2.begin(),t.begin(),multiplyOperatorFunctor<scalar,scalar,scalar>()
);
return thrust::reduce(t.begin(),t.end());}
else{
return 0.0;}
}総和計算
thrustライブラリによるGPU実装
本来ならライブラリが得意とする処理
9
総和計算処理にて性能が悪化と判明

Visual Profilerによる詳細分析
10
マイクロ秒単位
切り出して計測
カーネル・APIレベル
タイムラインを追う
4GPU時
1GPU時
cudaMalloc reduce
cudaMalloc cudaFreereduce
GPU上のメモリ確保・解放のコストがGPU数につれて増大GPU上のメモリ確保・解放のコストがGPU数につれて増大
cudaFree

総和計算 CUDAによるGPU実装
目的GPU上の無駄なメモリ確保・解放の除去総和計算の高速化
実装についてインタリーブ方式最初の足し込みステップでスレッドの削減ウォープダイバージェンスの回避低データ並列性からのCPUへの切り替え
11

ASIS 各処理プロセス毎のコスト
12
0.1 0.1 0.1
6.0 8.4
13.5 0.7
1.0
1.5
0.8
1.0
1.5
1.5
2.1
3.6
1.1
1.6
2.1
0.2
0.3
0.4
0
5
10
15
20
25
1 2 4
othersUEqn.2UEqn.3UEqn.4PISO.2pEqn.2pEqnpEqn.3pEqn.4
ノード内並列
GPU数
メインループでの分類pisoFoamソルバ
pEqn(圧力計算ソルバ)のコストをさらに分析した
[秒]
Ueqn.*(速度計算)
再掲載

TUNED 処理プロセス毎のコスト
13
pisoFoamソルバノード内
並列
GPU数
メインループでの分類
0.1 0.1 0.1 3.0 3.3 3.6 0.7 1.0 1.5 0.8 1.0
1.5 1.1
1.4 2.3
1.1 1.6
2.1
0.2 0.3
0.4
0
5
10
15
20
25
1 2 4
othersUEqn.2UEqn.3UEqn.4PISO.2pEqn.2pEqnpEqn.3pEqn.4
pEqnのスケーリング性能改善さらなる性能向上にはUeqn(速度場)の分析が必要
[秒]
ノード内並列

44.4
13.3 10.1 05
101520253035404550
CPU GPU ASIS GPU TUNED
CPU vs GPU(TUNED)
14
プロセッサ単体での性能
3.3倍 → 4.4倍 高速に
4.4倍
300万格子/1GPU or 1CPU
CPUは12コアでflat MPI
3.3倍
1.3倍
[秒]

GPU 弱スケーリング性能(TUNED)
多数GPU設定(4, 8, 16)にて2倍改善15
1ノード4GPU30.7 31.2 31.6
34.0 32.2
10.6
14.9
23.2 24.4 24.9
7.2 9.0
12.0 13.1 13.2
0
5
10
15
20
25
30
35
40
1 2 4 8 16
CPUGPU ASISGPUTUNED
200万格子/1GPU
[秒]
GPU数

RapidCFD最適化のまとめGPU対応OpenFOAM, RapidCFDの性能評価と最適化を行った
圧力計算に含まれる総和計算をCUDAで実装→無駄なメモリ確保・解放のコストを削減GPU単体では3.3→4.4倍高速に(CPU比較)複数GPUでのスケーリング性能は最大で2倍改善さらなる性能向上には速度計算の分析が必須
16

解析モデル2(強スケーリング)GPUDirect適用事例
今野雅氏 第4回OpenFOAMワークショップ 発表資料から引用http://www.hpci-office.jp/materials/ws_openfoam_161216_imano
https://github.com/opencae/OpenFOAM-BenchmarkTest
17
240x130x96 300万格子/1-64 CPU or GPUで分割
理想的にはGPUの増加に比例して高速化
1, 2, 4, 8, 16, 32, 64

GPU 強スケーリング性能
18
GPU数
[秒]
GPU数増加につれて通信を含む処理のコスト割合が増加
0
10
20
30
40
50
60
1 2 4 8 16 32 64通信を含む処理 演算処理
TUNED版
PCG-DIC
16並列から飽和64並列からは逆スケーリング

GPUDirect RDMA転送
NIC
GPU1
GPU2
GPUGPUメモリ
GPUGPUメモリ
CPU
CPUCPUメモリ
NIC
GPU1
GPU2
GPUGPUメモリ
GPUGPUメモリ
CPU
CPUCPUメモリ
network
ノード 0 ノード 1
異なるノード間でGPUメモリが直接転送/やりとりできる
19
東大Reedbush, 東工大TSUBAME 3.0などで採用
ホスト↔デバイス間転送コストを削減

CUDA対応MPIライブラリ
cudaMemcpy(send_h, send_d)
MPI_Irecv(send_h)MPI_Isend(recv_h)MPI_Waitall()
cudaMemcpy(recv_d, recv_h)
MPI_Irecv(send_h)MPI_Isend(recv_h)MPI_Waitall()
CPU間通信
ホストデバイス転送を伴うGPU間通信 Device to Host
Host to Device
MPI_Irecv(send_d)MPI_Isend(recv_d)MPI_Waitall()
CUDA対応MPIライブラリ
Deviceのポインタを直接渡す
対応するMPIにてこの記述が可能
MVAPICH, OpenMPIがCUDA対応版をリリース
CPUを介さないGPUDirect転送※対応ハードウェアであることが必要

GPUDirectの効果
それほど大きな効果は得られない結果
0
10
20
30
40
50
60
1 2 4 8 16 32 64GPUDirect OFF GPUDirect ON
メインループ全体
[秒]
GPU数
TUNED版
PCG-DIC

pEqn(圧力計算)コスト内訳
0
5
10
15
20
25
30
35
40
45
50
1 2 4 8 16 32 64
PrcdSum.1PCG.1MatVecSum.2PCG.2Sum.0
通信を含む処理で性能がスケールしていないMatVec(行列ベクトル積), Sum.1/2/0(総和計算)
演算処理(Prcd(前処理)、PCG.1(探索ベクトル更新)、PCG.2(解と誤差更新))はPE数増加に伴い性能がスケール
GPUDirect OFF
[秒]
GPU数
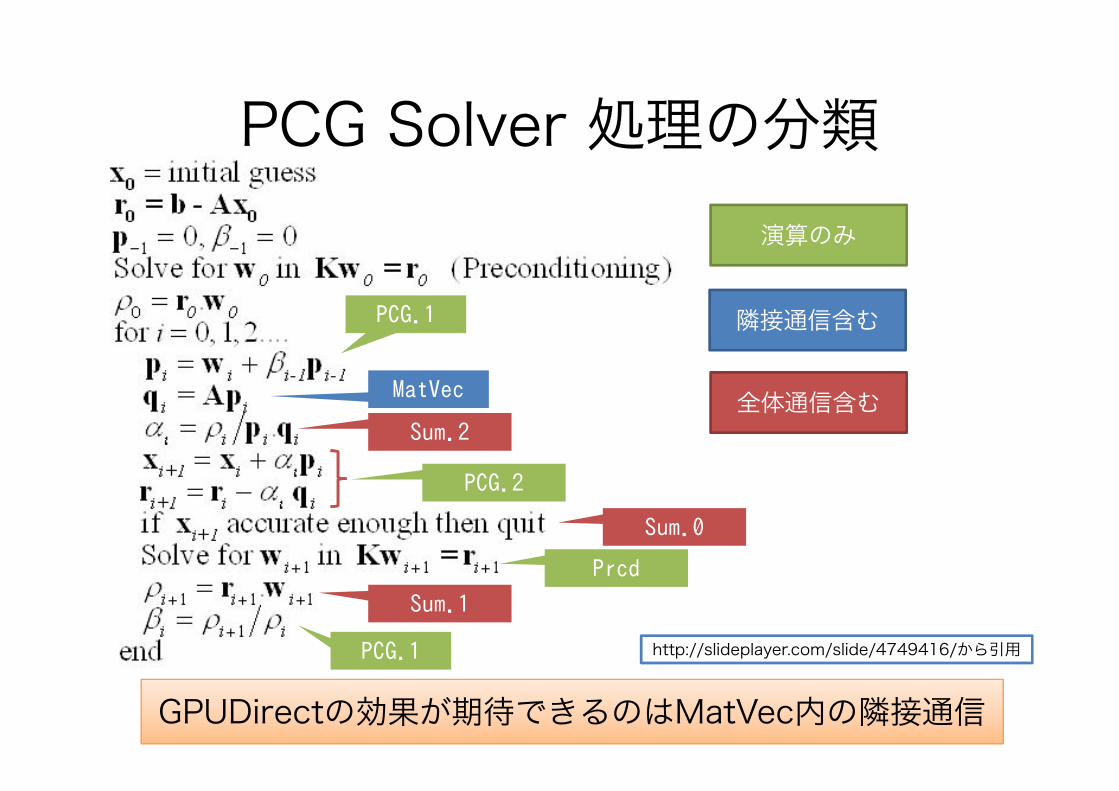
PCG Solver 処理の分類
PCG.1
MatVec
Sum.2
PCG.2
Sum.0
PrcdSum.1
PCG.1
演算のみ
隣接通信含む
全体通信含む
http://slideplayer.com/slide/4749416/から引用
GPUDirectの効果が期待できるのはMatVec内の隣接通信

通信を含む処理 GPUDirectの効果
02468
1012141618
1 2 4 8 16 32 64
0
1
2
3
4
1 2 4 8 16 32 64
0
1
2
3
4
1 2 4 8 16 32 64
0
1
2
3
4
1 2 4 8 16 32 64
MatVec(行列ベクトル積+袖通信)はコスト減(GPUDirectの効果)Sum.1/2/0(総和処理、同期あり)ではコスト増加
MatVec Sum.1
Sum.0Sum.2
縦軸:[秒]横軸:GPU数

MatVec処理void Foam::lduMatrix::Amul
initMatrixInterfaces(
);
if(fastPath){
callMultiply<true>(
);}else{
callMultiply<false>(
);}
updateMatrixInterfaces(
);
通信, SendRecvGPUからCPUへメモリ転送
通信, WaitCPUからGPUにメモリ転送
演算, 行列ベクトル積
MatVec処理抜粋

MatVec処理コスト
02468
10121416
1 2 4 8 16 32 64012345678
1 2 4 8 16 32 64
012345678
1 2 4 8 16 32 64
通信を含む処理はGPUDirectの効果あり
SendRecv 行列ベクトル積
Wait 縦軸:[秒]横軸:GPU数

MatVec処理 GPUDirect適用部分template<>void processorFvPatchField<scalar>::initInterfaceMatrixUpdate(…) const
std::streamsize nBytes = scalargpuSendBuf_.byteSize();scalar* receive; const scalar* send;if(Pstream::gpuDirectTransfer){
cudaDeviceSynchronize();scalargpuReceiveBuf_.setSize(scalargpuSendBuf_.size());
send = scalargpuSendBuf_.data();receive = scalargpuReceiveBuf_.data();
}else{
scalarSendBuf_.setSize(scalargpuSendBuf_.size());scalarReceiveBuf_.setSize(scalarSendBuf_.size());thrust::copy(
scalargpuSendBuf_.begin(),scalargpuSendBuf_.end(),scalarSendBuf_.begin()
);
send = scalarSendBuf_.begin();receive = scalarReceiveBuf_.begin();
}
GPUDirect ONデバイス上データを直接send, recv0.4[s](64PE)
GPUDicret OFFデバイス上データ一旦ホストに転送してからsend, recv3.2[s](64PE)
SendRecv

MatVec処理 GPUDirect適用部分void processorFvPatchField<scalar>::updateInterfaceMatrix(…) const{
if (commsType == Pstream::nonBlocking && !Pstream::floatTransfer){
// Recv finished so assume sending finished as well.outstandingSendRequest_ = -1;outstandingRecvRequest_ = -1;
if( ! Pstream::gpuDirectTransfer){
scalargpuReceiveBuf_ = scalarReceiveBuf_;}// Consume straight from scalargpuReceiveBuf_matrixPatchOperation(
this->patch().index(),result,this->patch().boundaryMesh().mesh().lduAddr(),matrixInterfaceFunctor<scalar>(
coeffs.data(),scalargpuReceiveBuf_.data()
));
}
GPUDicret OFF受信データ(ホスト上)をデバイスに転送2.2[s](64PE)
Wait
Direct転送による効果をソースコードレベルで確認

MatVec PEコスト分布
02468
101214
1 3 5 7 9 111315171921232527293133353739414345474951535557596163
MatVec
OFF ON
00.5
11.5
22.5
33.5
44.5
5
1 3 5 7 9 111315171921232527293133353739414345474951535557596163
MatVec GPUDirect OFF-ONGPUDirect効果
GPUDirect ONの効果はPEによってばらつきあり(Scotch分割故と考える)
PE間のばらつきが増大し、全体通信時の同期待ちコストが増加MatVecでの高速化を打ち消す結果に
縦軸:[秒]横軸:GPU数

強スケーリング事例解析(GPUDirect評価)のまとめ
実アプリによるGPUDirectの効果をベンチマークテストにて評価、調査したアプリ実行全体では数%程度の高速化
袖通信処理での高速化を、コストの分析・ソースコード解析により確認できた総和処理にてコスト増加し、GPUDirectの効果を打ち消す結果に(本ケースでは,通信インバランスが増加したため)
通信時にホストデバイス転送を多く含むアプリでの有効活用が期待できる

謝辞本発表の内容は,HPCIシステム利用研究課題「流体・粒子の大規模連成解析を用いた竜巻中飛散物による建物被害の検討(課題番号:hp170055),課題代表者:菊池浩利(清水建設(株)技術研究所)」の高度化支援に基づくものです.
31