einführung in data mining mit weka - dbis: dbis · temperature humidity windy. 9 ... naive bayes...
TRANSCRIPT

Einführung in Data Mining mit Weka
Philippe ThomasUlf Leser

2
Data Mining
Drowning in data yet starving for knowledge
Computers have promised us a fountain of wisdom but delivered a flood of data
The non trivial extraction of implicit, previously unknown, and potentially useful information from data
Practical machine learning

3
Beispiele
Banken Kreditwürdigkeit / Schufa Wertbapierhandel
Bildklassifikation Synthetic Aperture Radar Ölausbreitung im Golf von Mexiko Porträtfinder
Intrusion detection Kaufgewohnheiten (Payback)

4
Beispiele
Männlich / Weibliche Authoren: Männlich:
Bestimmte/Unbestimmte Artikel Eigennamen
Weiblich: Pronomen
S. Argamon, M. Koppel, J. Fine, A. R. Shimoni, 2003. “Gender, Genre, and Writing Style in Formal Written Texts,”Text, volume 23, number 3, pp. 321–346

5
Erfolge
Netflix Start: Oktober 2006 Daten: 100 Millionen (personenbezogene) ratings
Filme Postleitzahlen Datum
Ziel: 10% Verbesserung über das Netflix eigene Empfehlungssystem
21 September 2009: BellKor’s Pragmatic Chaos
How to Break Anonymity of the Netflix Prize Dataset? (Arvind Narayanan, Vitaly Shmatikov)

6
Erfolge
Erkrankungen von Soya Bohnen Regeln waren besser als die der Experten
Raynaud-Syndrom (Swanson 1986) Fish-Öl → Blut Viskosität,
Gefäßaktivität → verbessert Blutzirkulation
Verkauf von Bier und Windeln
Wikipedia Raynaud-Syndrom

7
Konkretes Beispiel

8
Aufgabe
Vorhersage von ”play” anhand der vier Attribute Outlook Temperature Humidity Windy

9
Erster Versuch

10
K-Nearest Neighbors
Instanz basierter Algorithmus Kein Training Langsame Vorhersage (Clevere Datenstruktur)
Benötigt eine Distanzfunktion Hintergrundwissen (Sunny → Overcast → Rainy) Attribute gleich wichtig
Welcher k-Wert ist am besten? Empfindlich für Rauschen Ungeeignet für Hochdimensionale Daten

11
Data Representation
Feature vector / Merkmalsvektor Reduktion des Problems auf Eigenschaften
Bildverarbeitung → Fourierkoeffizienten Spamklassifikation → Rich, Viagra, million $
Häufig ”sparse” features Nur bedingt großer Überlap zwischen Training/Test
Example Weather Temperature Play
1 Sunny Cold Yes
2 Rain Worm No

12
Statistical Modeling
Play = 2/9 * 3/9 * 3/9 * 3/9 *9/14 = 0.0053 = 20.5%
Play = 3/5 * 1/5 * 4/5 * 3/5 *5/14 = 0.0206 = 79.5%

13
Naïve Bayes
P [H∣E ]=P [E∣H ]∗P [H ]
P [E ]
P [ yes∣E ]=P [E1∣yes ]∗P [E2∣yes ]∗P [E3∣yes ]∗...∗P [ yes ]
P [E ]
P [ yes∣X ]=
29∗39∗39∗39∗914
P [E ]
Konstant

14
Naïve Bayes
Benutzt alle verfügbaren Attribute Attribute sind gleich wichtig und unabhängig
Annahme oft verletzt (Temperatur) Feature Selektion kann hilfreich sein
Kann mit fehlenden Attributen umgehen Wahrscheinlichkeiten können 0 werden
Pseudocounts
Kann in der Grundvariante nur mit Nominalen Daten umgehen
”There is nothing naïve in using Naïve Bayes”

15
Evaluation – Kreuzvalidierung
Daten sind nur begrenzt verfügbar Training und Test müssen getrennt sein
Quelle: http://genome.tugraz.at

16
Evaluation – Kreuzvalidierung
10 fold CV ist üblich Verteilung der Klassen sollte gleich sein
Straitifiziertes Sampling
Leave one out CV ist ein Spezialfall LOOCV liefert immer das selbe Ergebnis Per se nicht stratifiziert Rechenintensiv
Intrinsische Evaluation...

17
Evaluation – Vierfeldertrafel
Binäre Klassifikation hat vier mögliche Ergebnisse
Rp, Fp, Fn, Rn
Accuracy/Vertrauenswahrscheinlichkeit RMS für numerische Variablen
Quelle: Wikipedia

18
Weka
Sourceforge Projekt (GPL v2) Java
GUI und API Sammlung an Algorithmen für pre-processing,
maschinelles lernen und Visualisierung Gefördert seit 1993

19
Weka

20
Explorer

21
Attribute-Relation File Format
Andrew's Ridiculous File Format

22
Explorer

23
Klassifizierung – 10 x CV

24
Naïve Bayes

25
Entscheidungsbaum

26
Feature Selection
Attribute können irrelevant (Haarfarbe) oder redundant (Kelvin, Celcius, Fahrenheit) sein
Entscheidungsbaum hat Probleme mit irrelevanten features
Naive Bayes vor allem mit redundanten Deshalb Feature Selection Aber, das Ergebnis muss nicht zwingend besser
sein!

27
Feature Selection

28
Clustering
Unsupervised Suche nach natürlichen Gruppen Beispiel:
Outlier detection Unbekannte Subtypen von Krebs Social Networks (Personencluster)

29
Clustering

30
Clustering
31
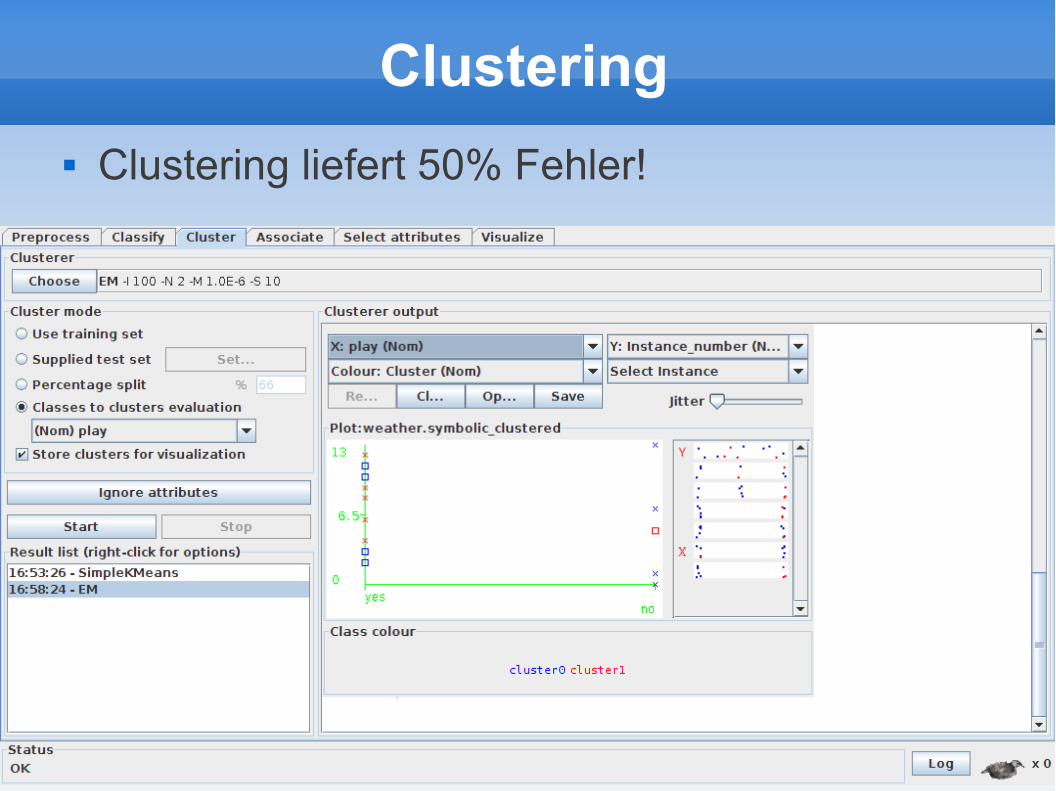
Clustering
Clustering liefert 50% Fehler!

32
Visualisierung

33
Probleme
Weka Speicherverbrauch und Rechenzeit
Lernverfahren Hochdimensionale Daten
Kein Inkrementelles Lernen im Experimenter möglich
Java Doc nur oberflächlich vorhanden Große Auswahl an verschiedenen Algorithmen,
aber weniger Möglichkeiten

34
Probleme
Data Mining Wenig Beispiele, viele Features Overfitting Semantischer Drift Wahl des passenden Algorithmus
Attribute Selection? Meta-Classifier?
Evaluierung allgemein schwer

35
Probleme
Concept drift Daten ändern sich über Zeit (sehr häufig)
Spam detection Maschine bekommt neue Parameter Erderwärmung Amazonkunden ”ändern” verhalten mit Alter
Regelmäßige Erneuerung der Daten Teuer (Rechenzeit, Kosten, Arbeitszeit)
So gut wie nie als Problem behandelt

36
Welche Methode?
Scaling to Very Very Large Corpora for Natural Language Disambiguation (Banko and Brill 2001)

37
Weitere Informationen
http://www.cs.waikato.ac.nz/ml/weka Weka Wiki Weka Manual (325 Seiten) Mailing Liste Youtube

38
Alternativen
RapidMiner (Weka mit hübscherer GUI) SPSS R Oracle Darwin

39
Java
http://weka.wikispaces.com/Use+WEKA+in+your+Java+code

40
Java (cont)

41
Java – Naïve Bayes

43
The End
Quele: flickr CMU G20 protests

44
Assoziationsregeln
Beschreiben Korrelationen zwischen auftretenden Ereignissen
Warenkorbanalyse Zahnbürste → Zahpasta

45
Assoziationsregeln