elegantes in-memory computing mit apache ignite und kubernetes. @data2day
TRANSCRIPT

Mario-Leander Reimer
@LeanderReimer
Elegantes In-Memory Computing mit Apache Ignite und Kubernetes
Heidelberg, 27. September 2017

Mario-Leander ReimerCheftechnologe, QAware GmbH
Kontakt Details
Phone: +49 89 23 23 15 121
Mail: [email protected]
Twitter: @LeanderReimer
Github: https://github.com/lreimer
2
Developer && Architect
20+ Jahre Erfahrung
#CloudNativeNerd
Open Source Enthusiast
QAware

Exkurs:Cloud-native State

QAware 4
Microservices kennen per Definition keinen Zustand. Für Hello World Services ist das ein Kinderspiel.

QAware 5
Im Enterprise Umfeld ist die Realität oft eine Andere. Zustand ist hier nicht die Ausnahme sondern die Regel.
Wie aggregiere ich zusammenhängende Sensor-Daten?
Wie verarbeite ich einen kontinuierlichen Daten-Strom effizient?
Wie suche und analysiere ich Daten effizient?
Wie stelle ich zeitlich limitierte Auth-Tokens ausfallsicher im Cluster zur Verfügung?
Wie gehe ich mit Zustandsbehafteten Technologien um?
Wie greife ich auf performant auf langsame Legacy DBs zu?

QAware 6
Die Lösung: Der Zustand wird ausgelagert und selbst zu einem Service.
Zustandsverwaltung wird in einen dedizierten Service ausgelagert.
Einfacher Cache (mit PUT und GET)
Komplexe Abfragen und Analysen.
Persistent und Konsistent.
Skalierbar und Hochverfügbar.

Introduction

Was ist Ignite? Eine In-Memory Computing Plattform.
QAware 8
Apache Ignite is an in-memory computing platform that is durable, strongly consistent, and highly available with powerful SQL, key-value and processing APIs.
Key-Value: ein voll transaktionaler, verteilter Key/Value Store. Horizontal skalierbar.
Durable Memory: das RAM als voll funktionsfähige Storage-Layer (nicht nur Caching-Layer). Off-Heap. Integration mit Ignite Persistence für volle Datenkonsistenz und Resilienz bei kompletten Cluster-Failures.
Ignite Persistence: Optional. Verteilter Disk-Storage Layer für Daten und Indizes auf SSDs, Flash, …
ACID Compliance: der In-Memory und der Disk Store sind ACID-compliant und bieten Strong Consistency.
Collocated Processing: Berechnungen werden zu den Daten gesendet (und nicht umgekehrt). Minimierte Datenbewegungen sorgen für gute Skalierbarkeit.
Vollständige SQL Unterstützung: Ignite ist eine verteilte SQL Datenbank. Unterstützt SQL, DDL und DML. Nutzer können Ignite mittels reinem SQL nutzen (CREATE TABLE, INSERT, SELECT, DELETE, …).
Scalability und Durability: Ignite ist ein elastisches, horizontal skalierbares verteiltes System. Nodes können dynamisch hinzugefügt und entfernt werden. Ist resilient gegenüber teilweisen Cluster-Ausfällen.

Historie und Releases seit Feb 16, 2014.
QAware 9
2014-10-01
Project enters
incubation.
2014-02-16
First commit.
2015-04-04v1.0.0
2015-09-18
Project graduated
from incubation.
2017-07-27
v2.1.0
2017-05-04
v2.0.0
2016-09-28
v1.4.1
2016-12-05
v1.8.0-rc1

Die wesentlichen Apache Ignite Bausteine im Überblick.
QAware 10

Data Grid & SQL

Implementierung der JCache (JSR 107) Spec
Unterstützt verschiedene Cache Modes: REPLICATED, PARTITIONED, NEAR und LOCAL
Affinity basierte Kollokation von Daten mit Daten und Daten mit Compute.
Unterstützt Cache Abfragen per API, SQL und Lucene Text Queries
Kontinuierliche Queries für Echtzeit Abfrage und Streaming der Ergebnisse
Atomic oder Transactional Cache Mode
Pessimistic und Optimistic Transaktionen
Cross-Cache Transaktionen sind möglich
Data Rebalancing wenn sich die Topologie ändert
Der Data Grid Baustein ist ein Distributed Key/Value Store und Cache.
QAware 12

Partitioned Caches im Detail.
QAware 13
Cache Mode mit bester Skalierbarkeit.
Ideal für große Datenmengen. == Total Memory (RAM + Disk)
Mehr Nodes bedeutet mehr Daten.
Ideal bei häufigen Updates, da nur Primary Nodeund optional Backups aktualisiet werden.
Affinity Collocation sollte genutzt werden um Daten performant zu verarbeiten.
Jeder Schlüssel wird genau einem Primary Node zugeordnet.
Near Cache für den performanten Zugriff auf Daten in Remote Client JVMs.

Replicated Caches im Detail.
QAware 14
Cache Mode mit bester Verfügbarkeit der Daten auch im Fehlerfall
Alle Daten sind auf jedem Node.
Aber Updates müssen an alle Nodes propagiert werden, das hat Einfluss auf die Skalierbarkeit.
Replicated Caches sind als Partitioned Caches realisiert. Jeder Key hat eine Backup Copy auf jedem Node.
Near Cache für den performanten Zugriff auf Daten in Remote Client JVMs.

Ignition.setClientMode(true);Ignite ignite = Ignition.start("data-grid.xml");
CacheConfiguration<String, Company> cacheConfig = new CacheConfiguration<>("companyCache");IgniteCache<String, Company> cache = ignite.getOrCreateCache(cacheConfig);
Company qaware = new Company("1", "QAware GmbH", Long.MAX_VALUE);cache.putIfAbsent(qaware.getCompanyId(), qaware);
SqlQuery<String, Company> sql = new SqlQuery<>(Company.class, "revenue > ?");try (QueryCursor<Cache.Entry<String, Company>> cursor = cache.query(sql.setArgs(1_000_000))) {
List<Company> companies = cursor.getAll().stream().map(Cache.Entry::getValue).collect(Collectors.toList());...
}
ignite.compute().affinityRun("companyCache", "1", () -> {Company company = cache.get("1");
// we collocated employees with the company, so access to the employee objects is local.IgniteCache<EmployeeKey, Employee> employeeCache = ignite.cache("employeeCache“);Employee reimer = employeeCache.localPeek(new EmployeeKey("11", company.getCompanyId()));...
});
Data Grid Quellcode und Demo.
QAware 15https://github.com/lreimer/ignite-data2day
Ignite im Client Mode starten.
Beispiel für Caching von Daten und SQL Query.
Beispiel für Data Collocationund Affinity Run.
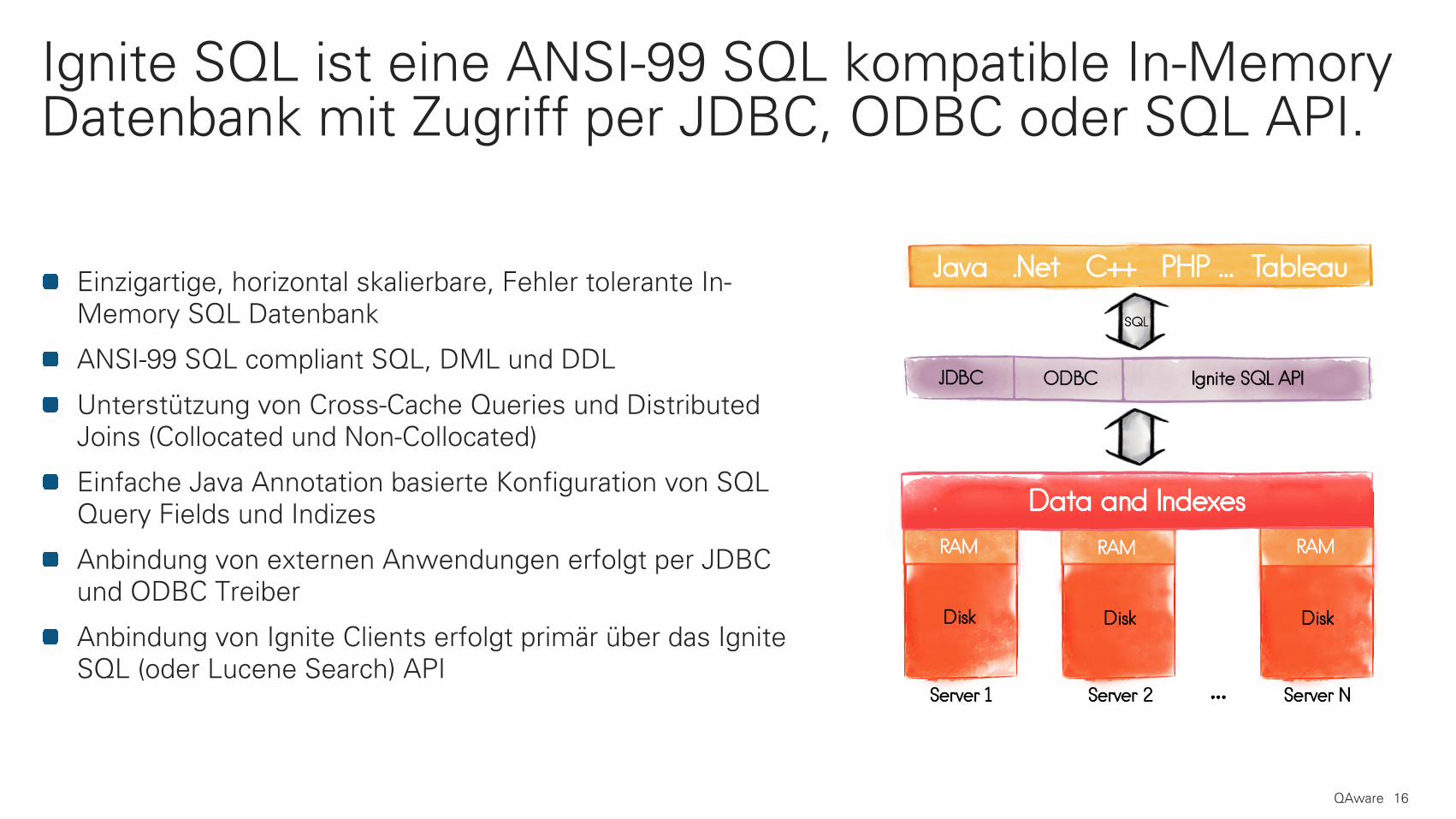
Einzigartige, horizontal skalierbare, Fehler tolerante In-Memory SQL Datenbank
ANSI-99 SQL compliant SQL, DML und DDL
Unterstützung von Cross-Cache Queries und Distributed Joins (Collocated und Non-Collocated)
Einfache Java Annotation basierte Konfiguration von SQL Query Fields und Indizes
Anbindung von externen Anwendungen erfolgt per JDBC und ODBC Treiber
Anbindung von Ignite Clients erfolgt primär über das IgniteSQL (oder Lucene Search) API
Ignite SQL ist eine ANSI-99 SQL kompatible In-Memory Datenbank mit Zugriff per JDBC, ODBC oder SQL API.
QAware 16

Class.forName("org.apache.ignite.IgniteJdbcDriver");Connection connection = DriverManager.getConnection("jdbc:ignite:thin://127.0.0.1:10800?collocated=true");
Statement stmt = connection.createStatement());stmt.executeUpdate("CREATE TABLE city (id LONG PRIMARY KEY, name VARCHAR) WITH \"template=partitioned, backups=0\"");stmt.executeUpdate("CREATE INDEX idx_city_name ON city (name)");
PreparedStatement stmt = connection.prepareStatement("INSERT INTO city (id, name) VALUES (?, ?)")stmt.setLong(1, 1L);stmt.setString(2, “Heidelberg");stmt.executeUpdate();
Ignition.setClientMode(true);Ignite ignite = Ignition.start("ignite-sql.xml");IgniteCache<Long, String> cityCache = ignite.cache("SQL_PUBLIC_CITY");
SqlFieldsQuery query = new SqlFieldsQuery("SELECT p.name, c.name FROM Person p, City c WHERE p.city_id = c.id");FieldsQueryCursor<List<?>> cursor = cityCache.query(query);Iterator<List<?>> iterator = cursor.iterator();
SqlFieldsQuery query = new SqlFieldsQuery("DELETE FROM city");cityCache.query(query).getAll();
Ignite SQL Quellcode und Demo.
QAware 17https://github.com/lreimer/ignite-data2day
Nutzung von DDL und SQL per JDBC API.
SQL Queries über Ignite SQL API
Treiber registrieren & Verbindung öffnen.

<listener><listener-class>...startup.servlet.ServletContextListenerStartup</listener-class>
</listener>
<filter><filter-name>IgniteWebSessionsFilter</filter-name><filter-class>...cache.websession.WebSessionFilter</filter-class>
</filter><filter-mapping>
<filter-name>IgniteWebSessionsFilter</filter-name><url-pattern>/*</url-pattern>
</filter-mapping>
<context-param><param-name>IgniteConfigurationFilePath</param-name><param-value>config/websession-config.xml</param-value>
</context-param><context-param>
<param-name>IgniteWebSessionsCacheName</param-name><param-value>partitioned</param-value>
</context-param>
QAware 18
Elegantes Web Session Clustering zum Fehler-toleranten Caching von javax.servlet.http Sessions.
Cache Configurationfür Web Sessions
https://github.com/lreimer/ignite-data2day

<hibernate-configuration><session-factory>
<property name="cache.use_second_level_cache">true</property><property name="generate_statistics">true</property>
<property name="cache.region.factory_class">org.apache.ignite.cache.hibernate.HibernateRegionFactory
</property><property name="org.apache.ignite.hibernate.ignite_instance_name">
hibernate-ignite-grid</property><property name="org.apache.ignite.hibernate.default_access_type">
TRANSACTIONAL</property>
<mapping class="com.mycompany.MyEntity1"/><class-cache class="com.mycompany.MyEntity1" usage="read-only"/><collection-cache collection="com.mycompany.MyEntity1.children“
usage="read-only"/>
</session-factory></hibernate-configuration>
QAware 19
Auch der Einsatz von Ignite als 2nd Level Cache von ORM Frameworks ist einfach möglich.
Cache Configurationpro JAP Entity
2nd Level Cache Configuration
https://github.com/lreimer/ignite-data2day

Compute Grid

High Performance, Low Latency, Linear Scalability.
Einfaches API um Berechnungen und Daten-verarbeitungen im Cluster verteilt auszuführen.
Zero-Deployment für Jobs durch Peer Classloading.
Broadcast und Load-Balancing von Closures auf dem Cluster oder einer Cluster Node Gruppe.
Cluster-enabled ExecutorService Implementierung
Leichtgewichtige Abstraktion und APIs für In-Memory MapReduce (oder ForkJoin) Tasks.
Collocation von Berechnung und Daten.
Mit dem Compute Grid können Berechnungen auf den Ignite Cluster Nodes verteilt ausgeführt werden.
QAware 21

Ignite ignite = Ignition.start("compute-grid.xml");IgniteCompute compute = ignite.compute(ignite.cluster().forRemotes());
compute.run(() -> System.out.println("Running distributed closure (1) on " + ignite.cluster().localNode().id()));compute.broadcast(() -> System.out.println("Broadcasting distributed closure on " + ignite.cluster().localNode().id()));
final String question = "How many characters has this sentence?";Collection<Integer> res = compute.apply(String::length, Arrays.asList(question.split(" ")));int total = res.stream().mapToInt(Integer::intValue).sum();
IgniteCache<Integer, String> cache = ignite.cache("someCache");compute.affinityRun("someCache", key, () -> {
System.out.println("Co-located processing [key= " + key + ", value= " + someCache.localPeek(key) + ']');});
ExecutorService executorService = ignite.executorService(ignite.cluster().forRemotes());executorService.submit(new IgniteRunnable() {
@IgniteInstanceResource private Ignite ignite;
@Overridepublic void run() {
System.out.println("Processing runnable on " + ignite.cluster().localNode().id() + " from grid job.");}
});
Compute Grid Quellcode und Demo.
QAware 22https://github.com/lreimer/ignite-data2day
Ausführung einfacher Closuresauf einem oder allen Nodes
Collocated Compute and Data
ExecutorService API von Ignite

Service Grid

Das Service Grid kann als Backbone für eine Microservice-basierte Applikation verwendet werden.
Kontinuierliche Verfügbarkeit der Dienste im Cluster unabhängig von Änderungen der Topologie.
Load-Balancing der Anfragen auf Service Instanzen.
Singleton Pattern: Cluster-Singletons, Node Singletons und Key Affinity Singletons sind möglich.
Deploy/Undeploy von Diensten zur Laufzeit.
Deployment von Diensten beim Start von neuen Nodes.
Programmatischer Zugriff auf Service Katalog + Metadaten.
Nutzung von Remote Services erfolgt über einen Interface-basierten Proxy Mechanismus (Access Transparency)
Mit dem Service Grid können beliebige Dienste in Igniteausfallsicher betrieben und aufgerufen werden.
QAware 24

Ignite ignite = Ignition.start("service-grid.xml");IgniteServices services = ignite.services();
PingService pingService = services.serviceProxy("PingService", PingService.class, true);String pong = pingService.ping();
services.deployClusterSingleton("RandomUuidService", new DefaultRandomUuidService());
RandomUuidService randomUuidService = services.serviceProxy("RandomUuidService", RandomUuidService.class, false);String response = randomUuidService.randomUUID();
public class DefaultPingPongService implements PingService, Service {@IgniteInstanceResource private Ignite ignite;
@Overridepublic void init(ServiceContext ctx) throws Exception {...}@Overridepublic void cancel(ServiceContext ctx) {...}@Overridepublic void execute(ServiceContext ctx) throws Exception {...} @Overridepublic String ping() { return "pong“; }
}
Service Grid Quellcode und Demo.
QAware 25https://github.com/lreimer/ignite-data2day
Proxy-based PingServiceNutzung mit Stickyness
Deployment eines Cluster Singleton
PingService Implementierung mit Resource Injection

Messaging

Topic-basierte, Cluster-weite Kommunikation zwischen allen Cluster Nodes.
Das Data Grid bietet zusätzlich eine schnelle, verteilte Blocking Queue Implementierung.
Topic Nachrichten können Ordered oder Unordered publiziert werden.
Nachrichten können an alle oder an eine Gruppe von Cluster Nodes zugestellt werden.
Nachrichten können einen Timeout haben.
Neue Cluster Nodes werden automatisch für alle Topics registriert.
Listener können nur auf dem lokalen Node oder auf allen Nodes registriert werden.
Ignite ermöglicht einfaches Queue und Topic basiertes Messaging ohne zusätzliche Middleware.
QAware 27

Ignite ignite = Ignition.start("ignite-messaging.xml");
CollectionConfiguration colCfg = new CollectionConfiguration();colCfg.setCacheMode(CacheMode.PARTITIONED);colCfg.setBackups(1);
IgniteQueue<String> queue = ignite.queue("randomUuidQueue", 0, colCfg);queue.add(UUID.randomUUID().toString());String uuid = queue.poll(5, TimeUnit.SECONDS);
IgniteMessaging messaging = ignite.message();messaging.sendOrdered("OrderedTopic", message, 5000L);messaging.send("UnorderedTopic", message);
messaging.localListen("OrderedTopic", (nodeId, msg) -> {System.out.println("Received ordered message [msg=" + msg + ", from=" + nodeId + ']');return true; // Return true to continue listening.
});
messaging.localListen("UnorderedTopic", (nodeId, msg) -> {System.out.println("Received unordered message [msg=" + msg + ", from=" + nodeId + ']');return true; // Return true to continue listening.
});
Ignite Messaging Quellcode und Demo.
QAware 28https://github.com/lreimer/ignite-data2day
Topic-based Messaging
Queue-based Messaging

Streaming

Apache Ignite stellt etliche Möglichkeiten zum Einlesen und Streamen von großen Datenmengen bereit.
QAware 30

IgniteDataStreamer<Long, String> dataStreamer = ignite.dataStreamer("tweetCache");dataStreamer.allowOverwrite(true);dataStreamer.autoFlushFrequency(10);
OAuthSettings oAuthSettings = new OAuthSettings(“consumerKey", “consumerSecret", “accessToken", “acessTokenSecret");
TwitterStreamer<Long, String> streamer = new TwitterStreamer<>(oAuthSettings);streamer.setIgnite(ignite);streamer.setStreamer(dataStreamer);
final Gson gson = new Gson();streamer.setSingleTupleExtractor(msg -> {
Tweet tweet = gson.fromJson(msg, Tweet.class);return new GridMapEntry<>(tweet.id, tweet.text);
});
Map<String, String> params = new HashMap<>();params.put("track", "data2day,qaware,apache ignite,cloud");params.put("follow", "1346627546,32837461,2650574588");
streamer.setApiParams(params);streamer.setEndpointUrl("/statuses/filter.json");streamer.setThreadsCount(4);
streamer.start();
Ein einfacher TwitterStreamer in nur 20 LOC.
QAware 31
DataStreamer für einen Ignite Cache
Extract & Parse JSONErzeigt einen CacheEntry
Twitter API Parameter
StreamAdapter dient als Abstraktion.
https://github.com/lreimer/ignite-data2day

Deployment

Einfaches und schnelles Deployment on-premise oder in einer Cloud Umgebung.
Läuft auf Bare Metal aber auch auf virtualisierter Hardware.
Kann Stand-alone und auch als Docker Container betrieben werden.
Für GCE und AWS stehen entsprechende VM Images zur Verfügung.
Der Ignite Node Discovery-Mechanismus muss passend zur jeweiligen Umgebung konfiguriert werden.
Infrastructure-as-a-Service und Platform-as-a-Service Deployments von Apache Ignite werden unterstützt.
QAware 33

echo "- The default provider is GCE"export KUBERNETES_PROVIDER=gceexport KUBE_GCE_ZONE=europe-west1-dexport NUM_NODES=4
echo "- Another possible provider is AWS"export KUBERNETES_PROVIDER=awsexport KUBE_AWS_ZONE=eu-central-1aexport NODE_SIZE=t2.small
curl -sS https://get.k8s.io | bash
Easy K8s setup: Local, Bare Metal, Cloud or Managed.
34QAware

Konzeptioneller Aufbau eines Kubernetes Cluster.
35QAware

Services sind eine Abstraktion für eine logische Sammlung von Pods
Pods sind die kleinste deploybare ComputeEinheit in K8S
Deployments dienen der Deklaration von Pods, Volumes und RCs
Replica Sets stellen die geforderte Anzahl an Replicas sicher
Labels sind Key/Value Paare die zur Identifikation verwendet werden
Config Maps enthalten Umgebungsanhängige Konfigurationswerte, diese werden in Pods als Volumes oder per ENV verwendet.
Volumes sind Verzeichnisse auf die Container zugreifen können.
Die wichtigsten K8s Konzepte die man kennen muss.
QAware 36

apiVersion: v1
kind: Service
metadata:
# Name of Ignite Service used by Kubernetes IP finder.
# must be equal to TcpDiscoveryKubernetesIpFinder.serviceName.
name: ignite
spec:
clusterIP: None # custom value.
ports:
- port: 9042 # custom value.
selector:
# Must be equal to one of the labels set in Ignite pods'
# deployment configuration.
app: ignite
QAware 37
Ein Kubernetes Service übernimmt die Node Discovery für die Pods des Ignite Clusters.
$ kubectl create –f ignite-service.yaml
https://github.com/lreimer/ignite-data2day

apiVersion: v1kind: ConfigMapmetadata:name: kubernetes-ignite-xml
data:kubernetes-ignite.xml: |<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.springframework.org/schema/beans ...>
<bean id="ignite.cfg" class="org.apache.ignite.configuration.IgniteConfiguration">...<!-- Explicitly configure TCP discovery SPI to provide list of initial nodes. --><property name="discoverySpi">
<bean class="org.apache.ignite.spi.discovery.tcp.TcpDiscoverySpi"><property name="ipFinder"><bean
class="org.apache.ignite.spi.discovery.tcp.ipfinder.kubernetes.TcpDiscoveryKubernetesIpFinder"></bean>
</property></bean>
</property></bean>
</beans>
QAware 38
Über eine Kubernete ConfigMap werden die Ignite Podsmit der nötigen XML Konfiguration versorgt.
Ignite Node Discovery läuft über den definierten Kubernetes Service
$ kubectl create –f ignite-configmap.yaml
https://github.com/lreimer/ignite-data2day

apiVersion: extensions/v1beta1kind: Deploymentmetadata:
name: ignitespec:
replicas: 2template:
metadata:labels:
app: ignitespec:
containers:- name: ignite-node
image: apacheignite/ignite:2.1.0env:- name: CONFIG_URI
value: file:///opt/ignite/apache-ignite-fabric-2.1.0-bin/data2day/config/kubernetes-ignite.xml- name: OPTION_LIBS
value: ignite-kubernetesports: ... volumeMounts:- mountPath: /opt/ignite/apache-ignite-fabric-2.1.0-bin/data2day/config
name: ignite-configvolumes:
QAware 39
Die Ignite Data Nodes werden über ein KubernetesDeployment gestartet und skaliert.
$ kubectl create –f ignite-deployment.yaml$ kubectl scale deployment ignite --replicas=4
Label muss zum Selectorim Ignite Service passen
Die nötige Konfiguration wird per ENV an den IgniteContainer übergeben
Ignite XML Konfiguration per ConfigMap VolumeMount
https://github.com/lreimer/ignite-data2day

Summary

Apache Ignite ist eine mächtige In-Memory Computing Plattform die mit Kubernetes zur Hochform aufläuft.
41
Apache Ignite ist eine ausgereifte und stabile Plattform.
Das API fühlt sich gut an, es ist einfach zu programmieren.
Einfache Use Cases lassen sich sehr schnell umsetzen.
Mannigfaltige Deployment Optionen und schnelles Setup.
Die Dokumentation ist gut und ausreichend.
QAware

Quellcode und Lesestoff für Zuhause …
42
https://github.com/lreimer/ignite-data2day
https://apacheignite.readme.io/docs
Microservices on Top of an In-Memory Data Grid: Part I
https://goo.gl/2jqm1E
Microservices on Top of an In-Memory Data Grid: Part II
https://goo.gl/edNlUK
Microservices on Top of an In-Memory Data Grid: Part III
https://goo.gl/uAPoNw
QAware

QAware 43

Mario-Leander Reimer
@LeanderReimer github.com/lreimer
linkedin.com/qaware slideshare.net/qaware
twitter.com/qaware xing.com/qaware