emotions and voice quality: experiments with sinusoidal modeling authors: carlo drioli, graziano...
TRANSCRIPT

Emotions and Voice Quality: Experiments with Sinusoidal Modeling
Authors: Carlo Drioli, Graziano Tisato, Piero Cosi, Fabio Tesser
Institute of Cognitive Sciences and Technologies - CNR
Department of Phonetics and Dialectology - Padova
Voice quality: functions, analysis and synthesisVOQUAL’03
Geneva, August 27-29, 2003

Outline
Objectives and motivations
Voice material
Acoustic indexes and statistical analysis
Neutral to emotive utterance mapping
Experimental results

Objectives and motivations
Long-term goals: - emotive speech analysis/synthesis - improvement of ASR/TTS systems
Short-term goal: - preliminary evaluation of processing tools for the reproduction of different voice qualities
Focus of talk: - analysis/synthesis of different voice qualities corresponding to different emotive intentions
Method: - analysis of voice quality acoustic correlates
- definition of a sinusoidal modeling framework to control voice timbre and phonation quality

An emotive voice corpus was recorded with the following characteristics:
two phonological structures ’VCV: /’aba/ and /’ava/.
neutral (N) plus six emotional states:
1 speaker, 7 recordings for each emotive intention, for each word.
anger (A),
joy (J),
fear (F),
sadness (SA),
disgust (D),
surprise (SU).
Voice material

Analysis of emotive speech: acoustic correlates
Cue extraction and analysis: •Intensity, duration, pitch, pitch range, formants.
•F0 stressed vowel mean and F0 mid values are strongly correlated.
F0 mean (global and for stressed vowel), F0 “mid”, and F0 range
anger (A)joy (J)fear (F)sadness (SA)
disgust (D)surprise (SU)neutral (N)

Analysis of emotive speech: acoustic correlates
Cue extraction and analysis (acoustic correlates of voice quality):
•Shimmer, Jitter
•HNR
•Hammarberg’s index (HammI) difference between energy max in the 0-2000 Hz and 2000-5000 Hz frequency bands
•Spectral flatness (SFM) ratio of the geometric to the arithmetic mean
•Drop-off of spectral energy above 1000 Hz (Do1000) LS approx. of the spectral tilt above 1000 Hz
•High- versus low-frequency range relative energy amount (Pe1000)
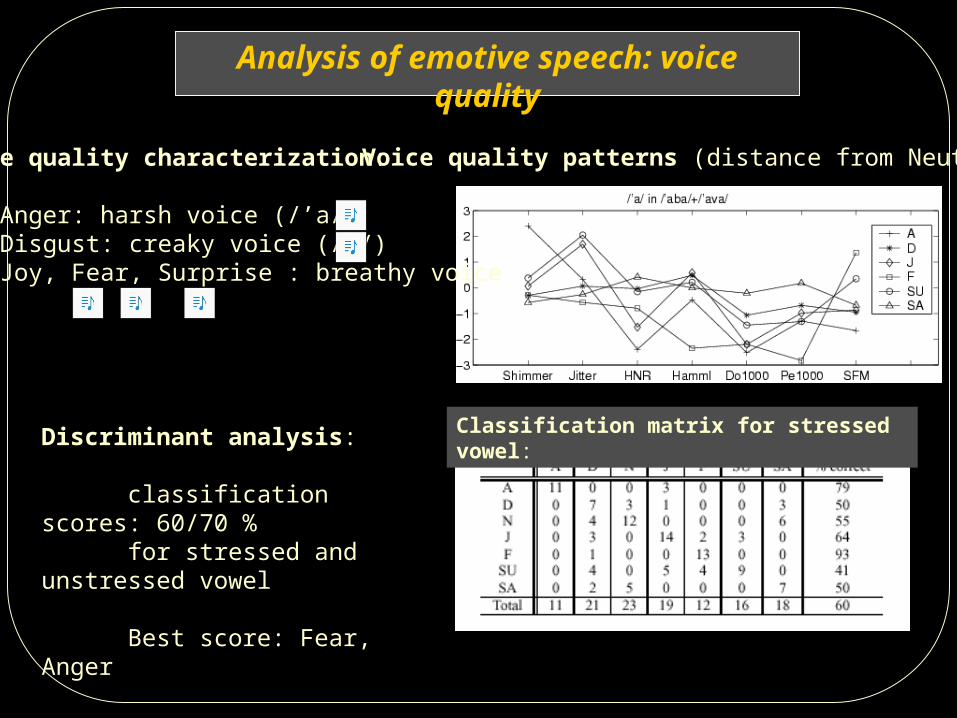
Analysis of emotive speech: voice quality
Voice quality patterns (distance from Neutral):
Discriminant analysis:
classification scores: 60/70 % for stressed and unstressed vowel
Best score: Fear, Anger
Voice quality characterization:
Anger: harsh voice (/’a/) Disgust: creaky voice (/a/) Joy, Fear, Surprise : breathy voice
Classification matrix for stressed vowel:

Processing of emotive speech: method
Neutral Emotive transformation based on sinusoidal modeling and spectral processing
Neutral sinus. spectral envelope after pitch shift
Emotive sinus. spectral envelope after Ts
Spectral envelope conversion function ( : mfcc from )
NeutralSpectral conversion model
Emotion j
Spectral conversion function design:
Neutral sinus. spectral envelope
Spectral conversion model (Stylianou et Al., 1998)gaussian mixture model
conversion parameters

Processing of emotive speech: method
Neutral Emotive transformation based on trained model
Neutral Target Disgust
Target Sadness
Disgust
Sadness
Disgust (Ps+Ts)
Sadness (Ps+Ts)

Processing of emotive speech: results
Neutral Emotive transformation based on sinusoidal modeling:
Neutral
Anger
Disgust
Joy
Fear
Surprise
Sadness
Ps+Ts Ps+Ts+Sc Target

Processing of emotive speech: results
Results: • Time-stretch and (formant preserving) pitch shift alone can’t account for the principal emotion related cues •Spectral conversion can account for some of the emotion cues
•In general, the method can’t account for cues related to period-to-period variability (i.e., Shimmer, Jitter)
•The inclusion of a noise model is required to evaluate the effect on HNR
Neutral

Conclusions
Future work
Refinements of the model (i.e., noise model) Adaptation to TTS system Search for the existence of speaker-independent transformation
patterns (using multi-speaker corpora).
Sinusoidal framework was found adequate to process emotive information
Need refinements (e.g. noise model, harshness model) to account forall the acoustic correlates of emotions
Results of processing are perceptually good