enabling e-business information retrieval, search engine and semantic web presenter: gautam kadaba,...
Post on 19-Dec-2015
217 views
TRANSCRIPT

Enabling e-BusinessInformation Retrieval, Search Engine and Semantic Web
Presenter: Gautam Kadaba, Jie Gao and Ming He

7 November 2005 CPSC 601.11 - Enabling e-Business 2
Scenario (1)
• You want to find a book from the UofC library

7 November 2005 CPSC 601.11 - Enabling e-Business 3
Scenario (2)
• You want to celebrate your anniversary with your wife. You want to find a nice restaurant through the Internet

7 November 2005 CPSC 601.11 - Enabling e-Business 4
Scenario (3)
• Looking for a condo near:– Your work location
– Schools
– Public transportation
– Shopping and restaurant
– Hospital
7 November 2005 CPSC 601.11 - Enabling e-Business 5
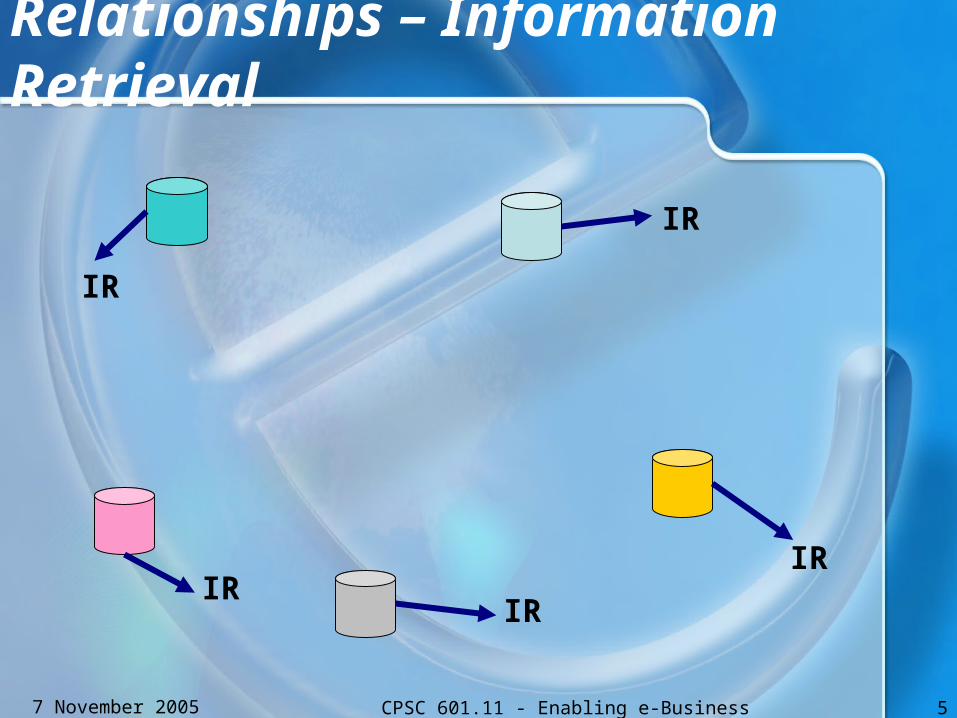
Relationships – Information Retrieval
IR
IR
IR
IRIR
7 November 2005 CPSC 601.11 - Enabling e-Business 6
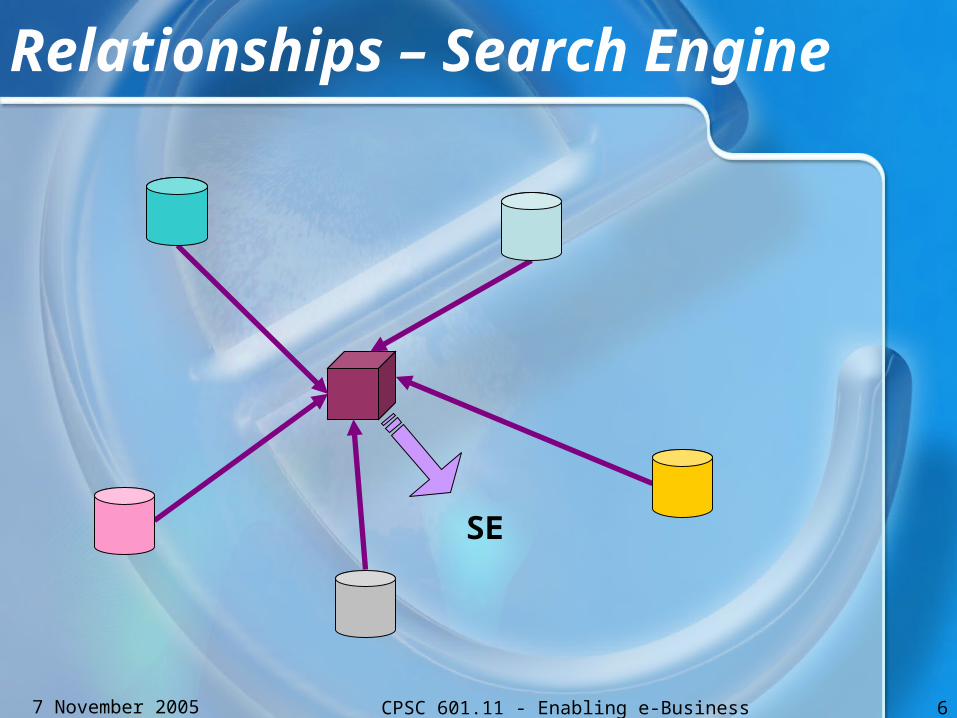
Relationships – Search Engine
SE
7 November 2005 CPSC 601.11 - Enabling e-Business 7
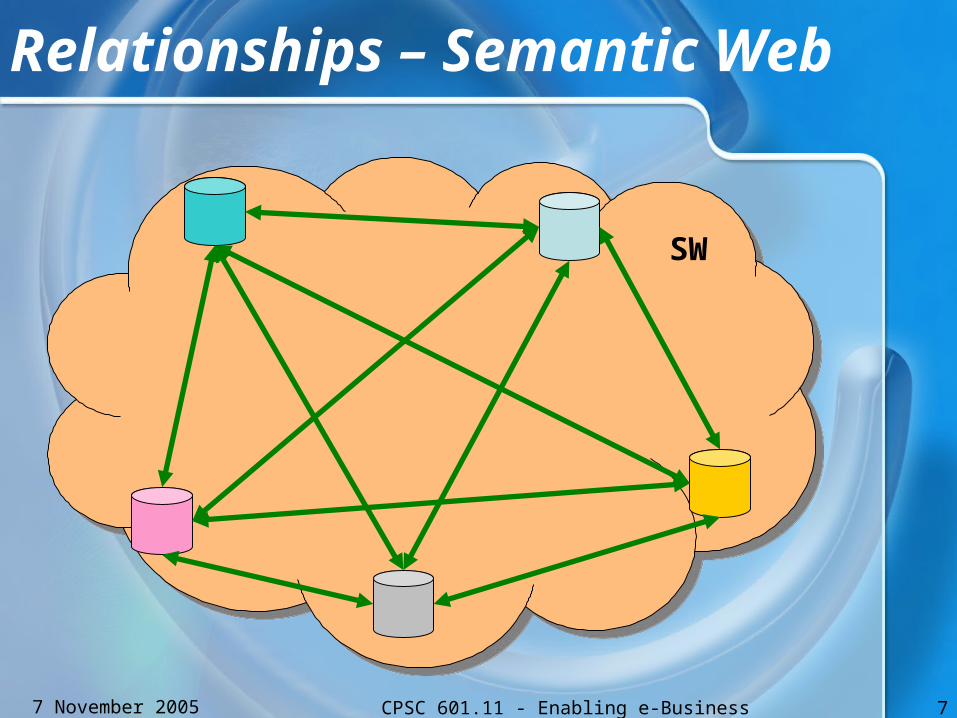
Relationships – Semantic Web
SW
7 November 2005 CPSC 601.11 - Enabling e-Business 8
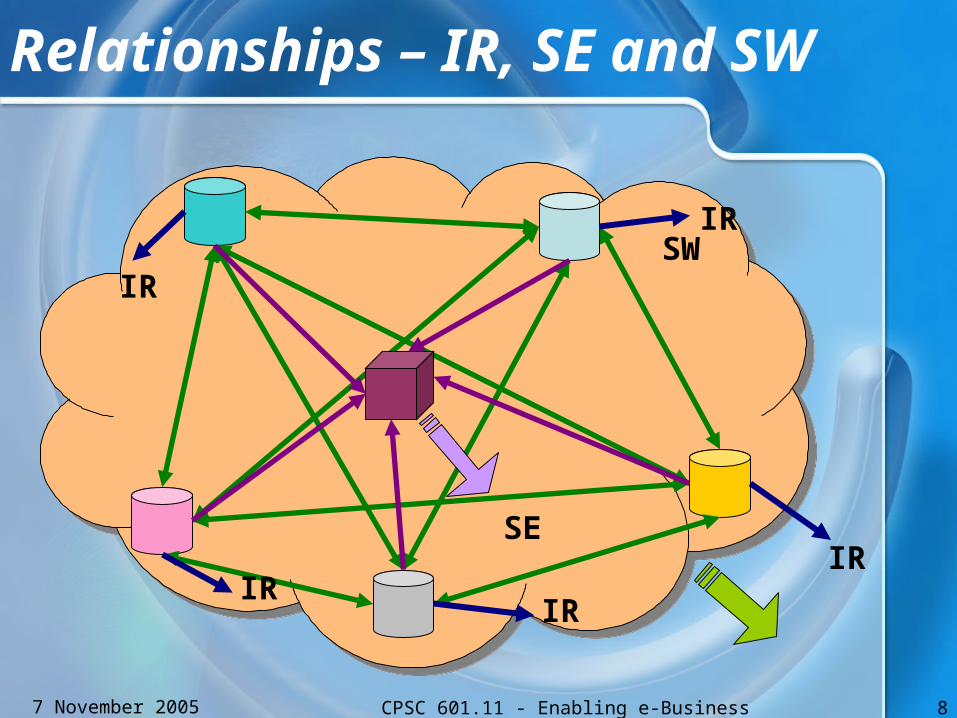
Relationships – IR, SE and SW
SW
SE
IR
IR
IR
IRIR

Information Retrieval

7 November 2005 CPSC 601.11 - Enabling e-Business 10
Information Retrieval - Definition
• Information Retrieval – deals with the representation, storage,
organization of, and access to information items
– Modern Information Retrieval
• General Objective: Minimize the overhead of a user locating needed information

7 November 2005 CPSC 601.11 - Enabling e-Business 11
Information Retrieval Is Not DatabaseInformation Retrieval• Process stored
documents• Search documents
relevant to user queries• No standard of how
queries should be• Query results are
permissive to errors or inaccurate items
Database• Normally no processing
of data• Search records
matching queries• Standard: SQL language
• Query results should have 100% accuracy. Zero tolerant to errors

7 November 2005 CPSC 601.11 - Enabling e-Business 12
Information Retrieval Is Not Data Mining
Information Retrieval• User target: Existing
relevant data entries
Data Mining• User target: Knowledge
(rules, etc.) implied by data (not the individual data entries themselves)
• Many techniques and models are shared and related
• E.g. classification of documents

7 November 2005 CPSC 601.11 - Enabling e-Business 13
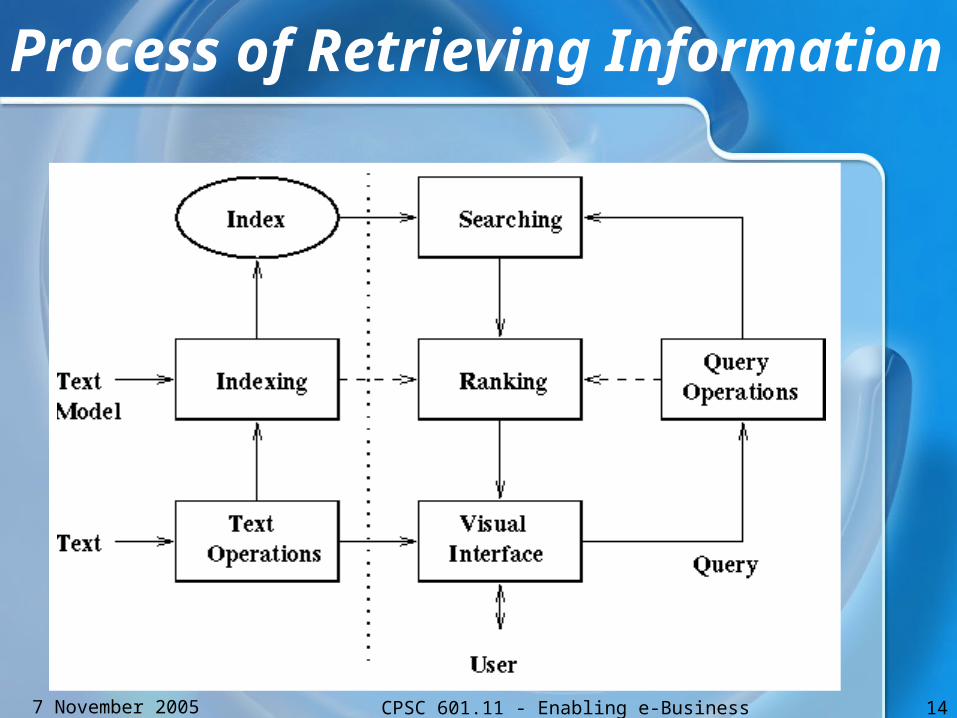
Elements in Information Retrieval
• Processing of documents
• Acceptance and processing of queries from users
• Modelling, searching and ranking of documents
• Presenting the search result
7 November 2005 CPSC 601.11 - Enabling e-Business 14
Process of Retrieving Information

7 November 2005 CPSC 601.11 - Enabling e-Business 15
Document Processing• Removing stopwords (appear
frequently but no much meaning, e.g. “the”, “of”)
• Stemming: recognize different words with the same grammar root
• Noun groups: common combination of words• Indexing: for fast locating documents

7 November 2005 CPSC 601.11 - Enabling e-Business 16
Processing Queries• Define a “language” for queries
– Syntax, operators, etc.
• Modify the queries for better search– Ignore meaningless parts: punctuations,
conjunctives, etc.– Append synonyms
e.g. e-business e-commerce
• Emerging technology– Natural language queries

7 November 2005 CPSC 601.11 - Enabling e-Business 17
Modelling/Ranking of Documents• Model the relevance (usefulness) of
documents against the user query Q• The model represents a function Rel(Q,D)
– D is a document, Q is a user query– Rel(Q,D) is the relevance of document D to query Q
• There are many models available– Algebraic models– Probabilistic models– Set-theoretic models
7 November 2005 CPSC 601.11 - Enabling e-Business 18
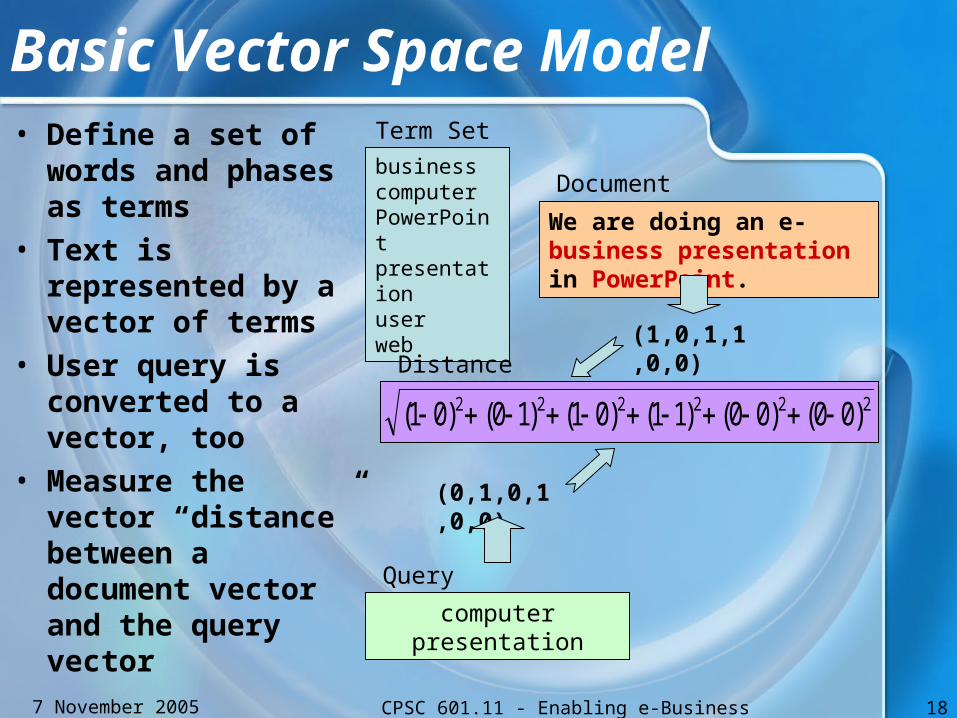
Basic Vector Space Model• Define a set of
words and phases as terms
• Text is represented by a vector of terms
• User query is converted to a vector, too
• Measure the vector “distance” between a document vector and the query vector
businesscomputerPowerPoint presentationuserweb
Term Set
We are doing an e-business presentation in PowerPoint.
Document
(1,0,1,1,0,0)
computer presentation
Query
(0,1,0,1,0,0)
222222 )00()00()11()01()10()01(
Distance

7 November 2005 CPSC 601.11 - Enabling e-Business 19
Probabilistic Models Overview• Probabilistic Models
– Ranking: the probability that a document is relevant to a query
– Often denoted as Pr(R|D,Q) – In actual measure, log-odds transformation is
used:
– Probability values are estimated in applications
),|Pr(
),|Pr(log
QDR
QDR

7 November 2005 CPSC 601.11 - Enabling e-Business 20
What is a Good IR System?• Minimize the overhead of a user
locating needed information– Fast, accurate, comprehensive, easy to use, …
• Objective measures– Precision
•
– Recall
•
retrieved documents all of No.
retrieved documentsrelevant of No.P
datain documentsrelevant all of No.
retrieved documentsrelevant of No.R

7 November 2005 CPSC 601.11 - Enabling e-Business 21
Precision/Recall Example
• Data entries: D1, …, D10
• User query: Q
• Returned entries: D3, D9, D10
• Actual relevant entries: D1, D3, D4, D9
• Measure calculation:– Precision: 2/3=66.67%– Recall: 2/4=50%

7 November 2005 CPSC 601.11 - Enabling e-Business 22
Applications of Information Retrieval• Classic application
– Library cataloguee.g. The UofC library catalogue
• Current applications– Digital library
e.g. http://www.acm.org/dl– WWW search engines
e.g. http://www.google.com

Search Engines

7 November 2005 CPSC 601.11 - Enabling e-Business 24
How many people use the Internet?• 15% are Internet users• 68% internet penetration in N.America, which
is just 5% of world population (Source: Internetworld Stats, 2005)
• 5 billion searches across approx. 65 search engines in Aug, 2005. Avg. user did 42 searches in that month (Source: Nielsen Net Ratings)
• Top 3 search engines ranked by search share in Aug, 05 – Google, Yahoo and MSN

7 November 2005 CPSC 601.11 - Enabling e-Business 25
Tipping point• Boom started in the post 9/11 era
• Mainstream advertisers forced to stretch their ad dollars
• New ways of targeting consumers – Search Engine marketing (SEM)
7 November 2005 CPSC 601.11 - Enabling e-Business 26
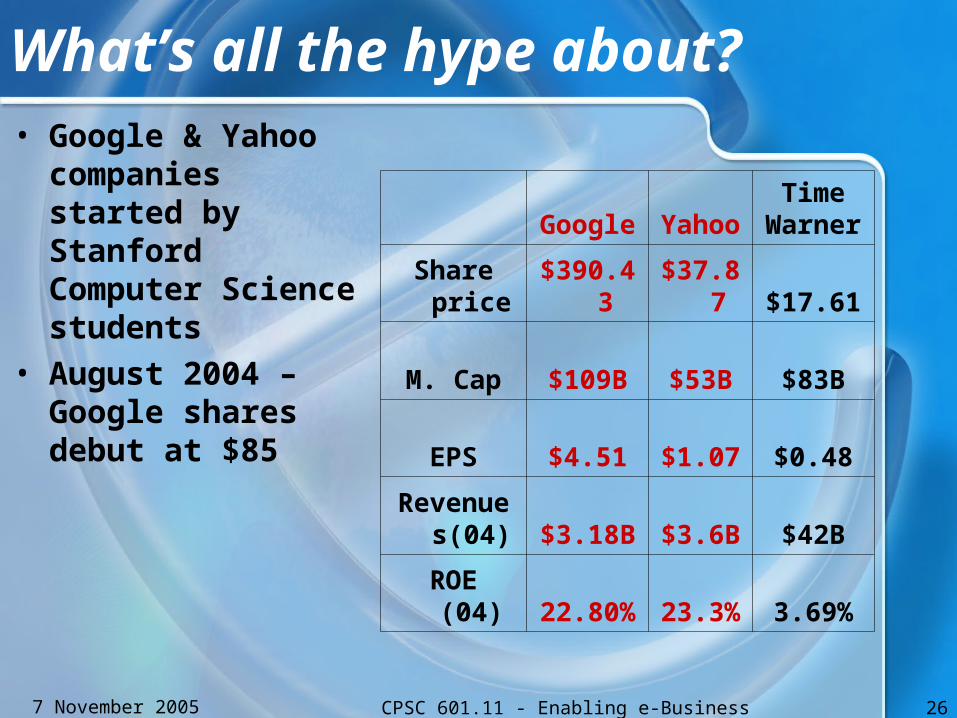
What’s all the hype about?• Google & Yahoo
companies started by Stanford Computer Science students
• August 2004 – Google shares debut at $85
Google YahooTime
Warner
Share price $390.43 $37.87 $17.61
M. Cap $109B $53B $83B
EPS $4.51 $1.07 $0.48
Revenues(04) $3.18B $3.6B $42B
ROE (04) 22.80% 23.3% 3.69%

7 November 2005 CPSC 601.11 - Enabling e-Business 27
Founders - Google• Larry
Page
• Sergey
Brin

7 November 2005 CPSC 601.11 - Enabling e-Business 28
Founders - Yahoo• David
Filo
• Jerry
Yang

7 November 2005 CPSC 601.11 - Enabling e-Business 29
Search Engine - Origins• Wandex – first Perl based search engine
developed at MIT by Matthew Gray in 1993
• Excerpt of an email written by Matthew to his fellow student Joe:
“I have written a perl script that wanders the WWW collecting URLs, keeping track of where it's been and new hosts that it finds. Eventually, after hacking up the code to return some slightly more useful information (currently it just returns URLs), I will produce a searchable index of this. I'll announce here when we get this index properly running, however it probably won't be until sometime in August, as I am going on vacation.” – Matthew Gray

7 November 2005 CPSC 601.11 - Enabling e-Business 30
The Pioneers• 1993 : Lycos, first commercial
endeavour.
• 1994 – 97 : Altavista, Excite, Inktomi, Ask Jeeves, Northern Light
• 1998 : Google
• 2004 : Yahoo (was using Google until this time)
• 2005 : MSN

7 November 2005 CPSC 601.11 - Enabling e-Business 31
What are Search Engines?• Is a program designed to help find information
stored on a computer system such as the World Wide Web, or a personal computer.
• Other kinds of search engine
– Enterprise search engines: search on intranets
– Personal search engines: search individual personal computers

7 November 2005 CPSC 601.11 - Enabling e-Business 32
How it works?
• Basically is an information retrieval system
• In addition to an Information Retrieval system, Search Engines:
– Obtain documents over the web
– Consider the special characteristics of web contents, e.g. hyperlinks, meta-data

7 November 2005 CPSC 601.11 - Enabling e-Business 33
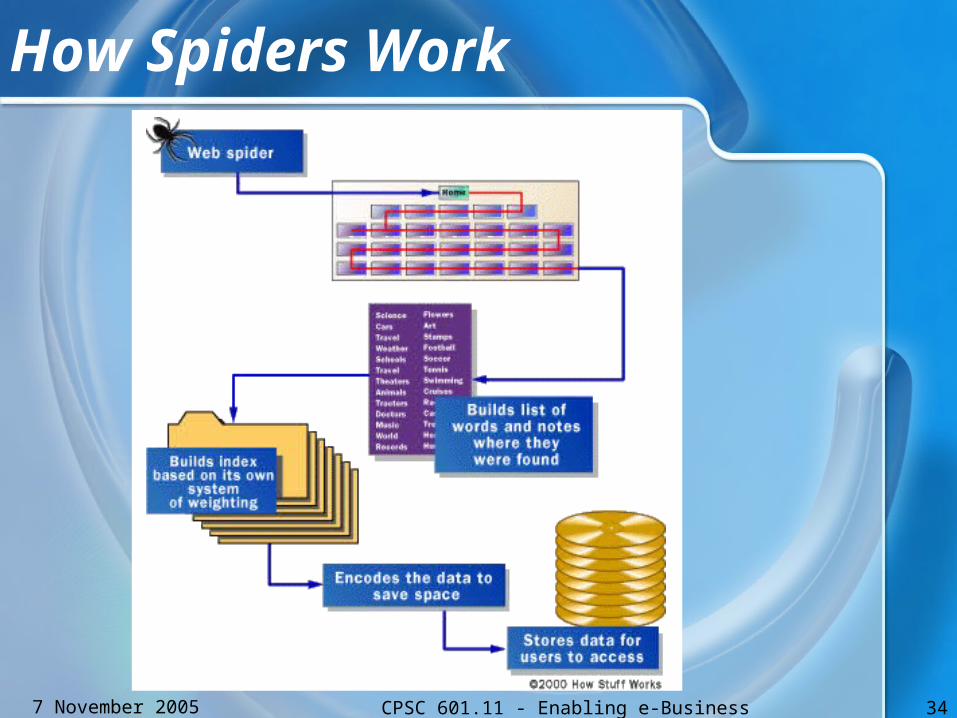
Obtaining Web Documents• Spiders
– Special computer program that crawls on the Internet
– Collect information of web pages it visits, and indexes it into the search engine’s database
– Start from a URL, and follow the links found on each of the web documents
• User submission– User manually add entries of their web sites into
search engine directories
7 November 2005 CPSC 601.11 - Enabling e-Business 34
How Spiders Work

7 November 2005 CPSC 601.11 - Enabling e-Business 35
Search Engine Example: Google• Patented “Page Rank” technology
• Page Rank relies on the uniquely democratic nature of the web by using its vast link structure as an indicator of an individual page's value. – Google interprets a link from page A to page B as a
vote, by page A, for page B. – Also analyzes the page that casts the vote– Votes cast by pages that are themselves
"important" weigh more heavily and help to make other pages "important"

7 November 2005 CPSC 601.11 - Enabling e-Business 36
Search Engine Example: Google• Webmasters built an increased
number of inbound links to increase rankings. Google realized this and now employs – More than 150 criteria to determine relevancy of
results– Thousands of servers and hundreds of algorithms
to calculate rankings and relevancy: weight the pages, and assign their values for later use
• Results are then outputted to the users browser.

7 November 2005 CPSC 601.11 - Enabling e-Business 37
MSN - How it works?• Works on Neural networks. A series
of computers which are supposed to learn based on input provided.
• For example, if the search engine is told that Ebay is considered an authoritative site on online auctions, then when a person performs such a search they should see Ebay.com at the top of the search results.

Business Applications – Search Engine Marketing (SEM)
7 November 2005 CPSC 601.11 - Enabling e-Business 39
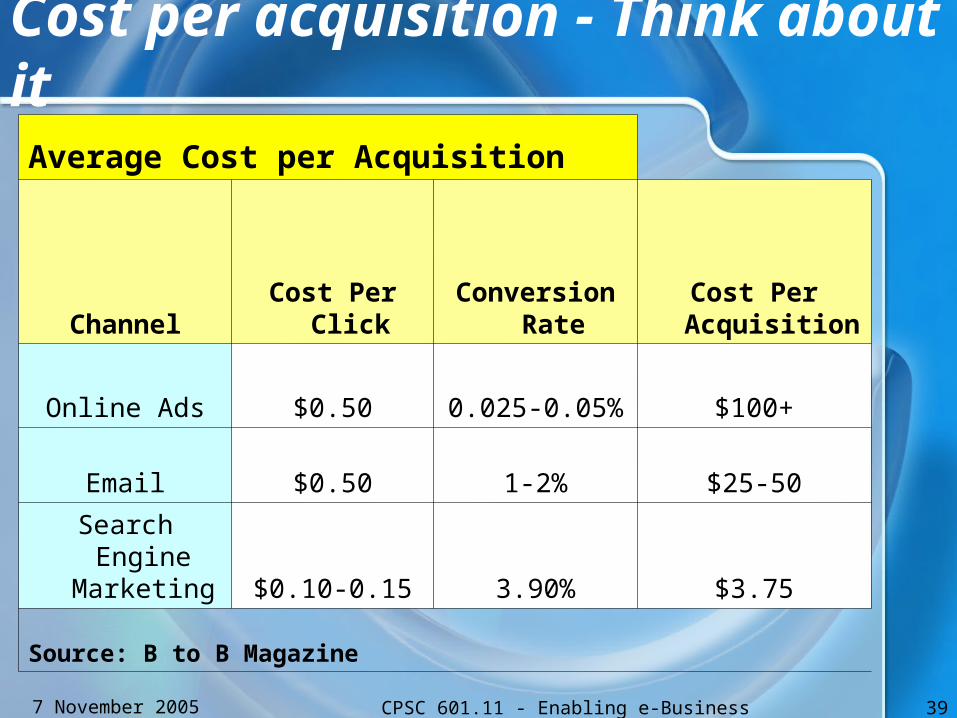
Cost per acquisition - Think about it
Average Cost per Acquisition
ChannelCost Per
ClickConversion
RateCost Per Acquisition
Online Ads $0.50 0.025-0.05% $100+
Email $0.50 1-2% $25-50
Search Engine Marketing $0.10-0.15 3.90% $3.75
Source: B to B Magazine

7 November 2005 CPSC 601.11 - Enabling e-Business 40
SEM Strategies - 1• Paid Placement
– Proving to be very effective for SME’s
– Is it really that effective?
– Great for search engine companies!
– Is it good for business enterprises?
– Is it good for users? You decide!

7 November 2005 CPSC 601.11 - Enabling e-Business 41
SEM Strategies - 2• Contextual Advertising
– Great for search engine network and content cos.
– Relevancy determined by algorithm. Extremely beneficial is user is actively seeking product while reading content
– Is it really contextual? You decide!

7 November 2005 CPSC 601.11 - Enabling e-Business 42
SEM Strategies - 3• Search Engine Optimization
– Improve the ranking of website in free search results (Non-paid results)
– Several factors go into high ranking
– However continuous optimization to website is required

7 November 2005 CPSC 601.11 - Enabling e-Business 43
SME Case Study – WarrantyDirect.com
• Sells automobile warranty
• Increased sales by 55% by using paid placement
• Bids on 40 different keywords on search sites
• Successful paid placement strategy!
• Will it work for other SME’s?– High involvement– Cost paid to consultant– How differentiated is your product/service?

7 November 2005 CPSC 601.11 - Enabling e-Business 44
More information
How Search Engines Work?• http://en.wikipedia.org/wiki/
Search_engine#How_search_engines_work• http://www.searchenginejournal.com/index.php?p=2267• http://www.lib.berkeley.edu/TeachingLib/Guides/Internet/
SearchEngines.html
Search engine marketing• http://www.webreference.com/programming/search/• http://www.google.com/ads/• http://tools.search.yahoo.com/about/

Semantic Web

7 November 2005 CPSC 601.11 - Enabling e-Business 46
Semantic Web• WWW and Semantic Web• Why Semantic Web• The Goals of Semantic Web• Semantics• What is Semantic Web• Applications of Semantic Web • Technology foundations of Semantic Web• Challenges• Future of Semantic Web

7 November 2005 CPSC 601.11 - Enabling e-Business 47
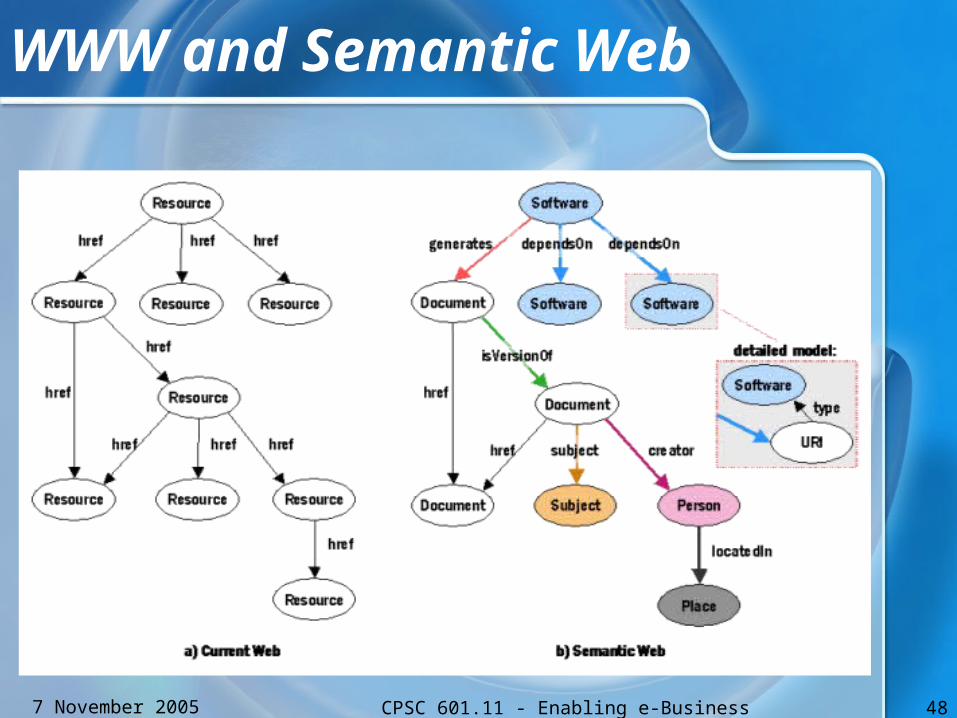
WWW and Semantic Web
• WWW– human-readable information– A framework for ‘pointing’– Pointing has no meaning without human
interpretation
• Semantic Web– Machine-Understandable information– Linkages among the web resources– Good for agents and automation
7 November 2005 CPSC 601.11 - Enabling e-Business 48
WWW and Semantic Web

7 November 2005 CPSC 601.11 - Enabling e-Business 49
Why Semantic Web?• Human interpretation needed to
understand content.• Data that is generally hidden away in HTML files is
often useful in some contexts, but not in others.• There is no global system for publishing data in such
a way as it can be easily processed by anyone.• Automation is difficult, especially for unforeseen
situations.• Semantic Web, via ontologies and reasoning, will
improve interoperability of information systems.
7 November 2005 CPSC 601.11 - Enabling e-Business 50
The Goals of Semantic Web
Search Information
Integration
Navigation
Automation

7 November 2005 CPSC 601.11 - Enabling e-Business 51
Semantics• Semantics (from the Greek
semantikos, or "significant meaning," derived from sema, sign) is the study of meaning, in some sense of that term.
• Semantics is often opposed to syntax, in which case the former pertains to what something means while the latter pertains to the formal structure/patterns in which something is expressed (for example written or spoken). en.wikipedia.org/wiki/Semantic

7 November 2005 CPSC 601.11 - Enabling e-Business 52
What is Semantic Web• "The Semantic Web is an extension of the
current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation." - Tim Berners-Lee, James Hendler, Ora Lassila, The Semantic Web, Scientific American, May 2001
• The Semantic Web provides a common framework that allows data to be shared and reused across application, enterprise, and community boundaries. It is based on the Resource Description Framework (RDF), which integrates a variety of applications using XML for syntax and URIs for naming. (http://www.w3.org/2001/sw/)

7 November 2005 CPSC 601.11 - Enabling e-Business 53
What is Semantic Web
• The Semantic Web is a Web that includes documents, or portions of documents, describing explicit relationships between things and containing semantic information intended for automated processing by our machines. (http://swag.webns.net/whatIsSW)

7 November 2005 CPSC 601.11 - Enabling e-Business 54
Applications of Semantic Web
• In Semantic Web we not only provide URIs for documents as we have done in the past, but to people, concepts and relationships. – Knowledge Management– Personal Agent– Verification Service

7 November 2005 CPSC 601.11 - Enabling e-Business 55
Knowledge Management• British Telecom Call
Center
OntoShareOntoShare
7 November 2005 CPSC 601.11 - Enabling e-Business 56
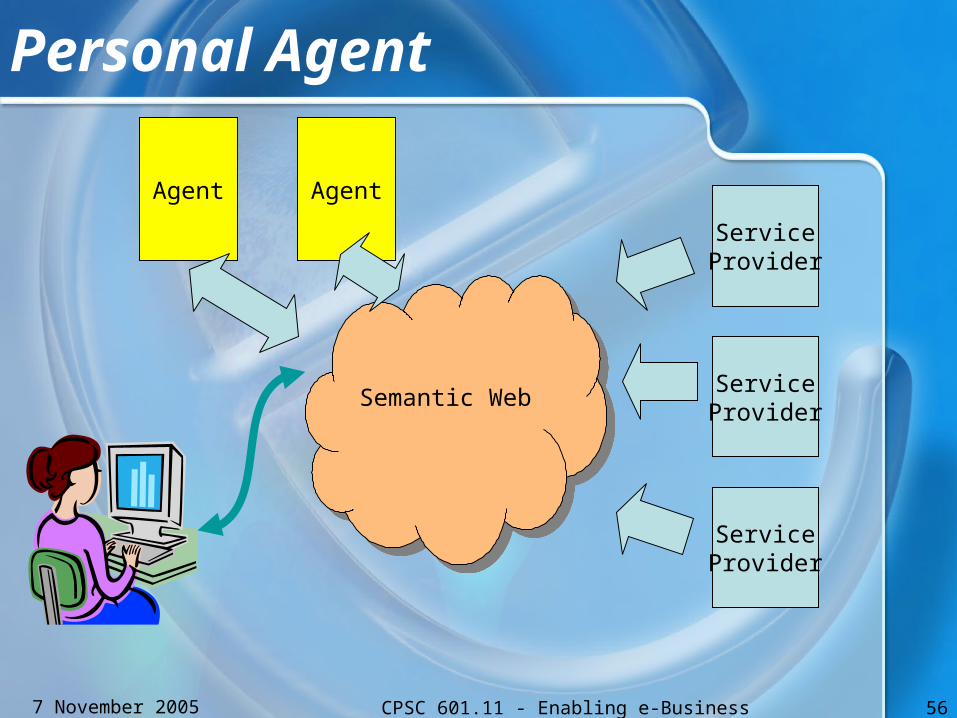
Personal Agent
ServiceProvider
Semantic WebSemantic WebServiceProvider
ServiceProvider
Agent Agent

7 November 2005 CPSC 601.11 - Enabling e-Business 57
Verification Service• Web of Trust• Offering verification and rating service
7 November 2005 CPSC 601.11 - Enabling e-Business 58
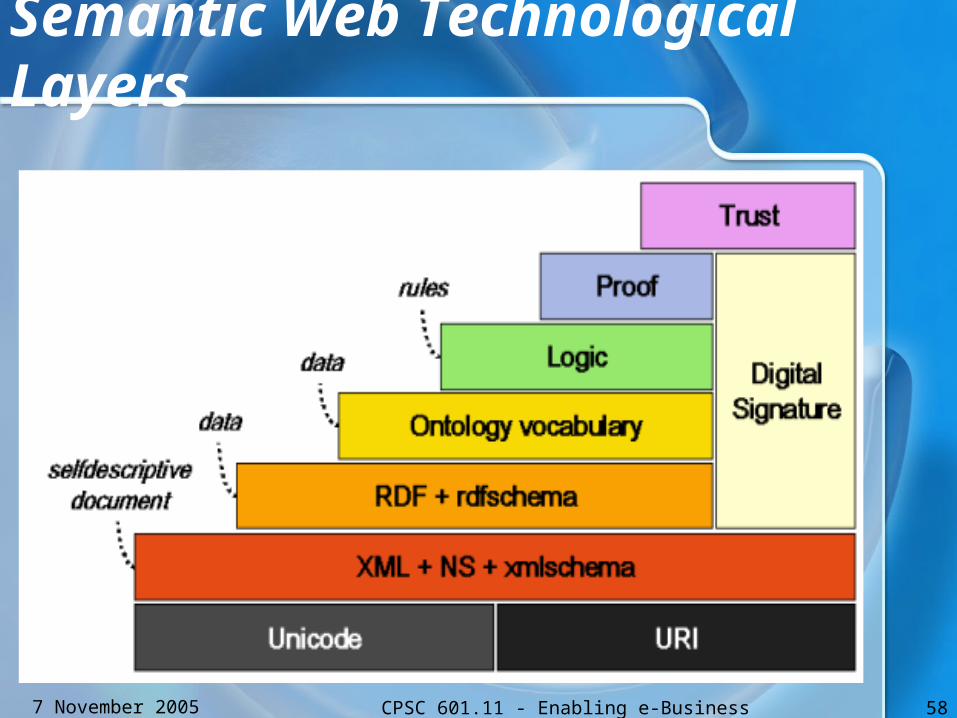
Semantic Web Technological Layers

7 November 2005 CPSC 601.11 - Enabling e-Business 59
URI and Unicode• The URI is the foundation of the Web.• One form of URI: the URL or Uniform
Resource Locator. URIs are decentralized. • A common practice for creating URIs is to
begin with a Web page. The page describes the object to be identified and explains that the URL of the page is the URI for that object.
• Unicode: International characters sets.

7 November 2005 CPSC 601.11 - Enabling e-Business 60
XML and Namespace• XML was designed to be a simple way to
send documents across the Web. • Allows anyone to design their own document format
and then write a document in that format. • These document formats can include markup to
enhance the meaning of the document's content. • This markup is "machine-readable," that is, programs
can read and understand it. By including machine-readable meaning in our documents, we make them much more powerful.

7 November 2005 CPSC 601.11 - Enabling e-Business 61
RDF (Resource Descriptive Framework)
• RDF makes statements that are machine-processable.
• Each RDF statement has three parts: a subject, a predicate and an object.
• This design has a number of interesting features.– Rules to allow for decentralized extensions– Descriptive rather than prescriptive (contrast with XML)– RDF vocabularies document claims about the world (not
about documents)– RDF is designed for data merging (easy when things have
agreed IDs)

7 November 2005 CPSC 601.11 - Enabling e-Business 62
An Example of RDF<?xml version="1.0"?>
<RDF>
<Description about="http://www.w3schools.com/RDF"> <author>Jan Egil Refsnes</author> <homepage>http://www.w3schools.com</homepage>
</Description>
</RDF>

7 November 2005 CPSC 601.11 - Enabling e-Business 63
RDF Schema• A basic vocabulary definition
language• The use of all these URIs is useless if we
never describe what they mean. • This is where schemas and ontologies come
in. A schema and an ontology are ways to describe the meaning and relationships of terms.

7 November 2005 CPSC 601.11 - Enabling e-Business 64
Ontology Vocabulary
• OWL (W3C Web Ontology Language) extends our vocabulary description, allowing us to express claims such as...– Nothing can be both a Document and a Person– Grandparent and grandchild are inverses– Homepage, NASDAQ Code and mbox are uniquely
identifying properties– A W3CTeamPerson is a Person whose workplace
homepage is http://www.w3.org/– As well as the formally specified interactions
amongst all these features.

7 November 2005 CPSC 601.11 - Enabling e-Business 65
Characteristics of OWL
OWL adds value to the Semantic Web through– Bringing machine-checkable precision to
vocabulary design– Allowing new data to be inferred– Allowing automatic detection of contradictory
claims– Exploiting existing tools from Description Logic
community– Providing principles for complex data merging

7 November 2005 CPSC 601.11 - Enabling e-Business 66
Logic Frameworks
• State any logical principle and permit the computer to reason

7 November 2005 CPSC 601.11 - Enabling e-Business 67
Proof
• Proof is a form of evidence which proves something is correct.
• People all around the world could write logic statements. Your machine could follow these Semantic "links" to construct proofs.

7 November 2005 CPSC 601.11 - Enabling e-Business 68
Trust• All statements on the Web occur in
some context. • Applications need this context in order to
evaluate the trustworthiness of the statements.
• The machinery of the SW does not assert that all statements found on the Web are "true".
• Trustworthiness is evaluated by each application.
• Very flexible language can express existing systems

7 November 2005 CPSC 601.11 - Enabling e-Business 69
Challenges - Technology Challenges• According to TimBL, there will be
many layers to the Semantic Web, which could take around ten years to complete:– Unicode and XML– RDF and other Basic Assertion Languages– Schema Languages– Conversion Language– The Logical Layer– A Proof Language– An Evolution Rules Language– Query Languages For Proof Validation
(http://swag.webns.net/whatIsSW)

7 November 2005 CPSC 601.11 - Enabling e-Business 70
More Challenges• Trust, security• Filtering, child protection, PICS-mobile?• Policy issues: privacy, social impact• Deployment, Best Practice and other support
activities
7 November 2005 CPSC 601.11 - Enabling e-Business 71
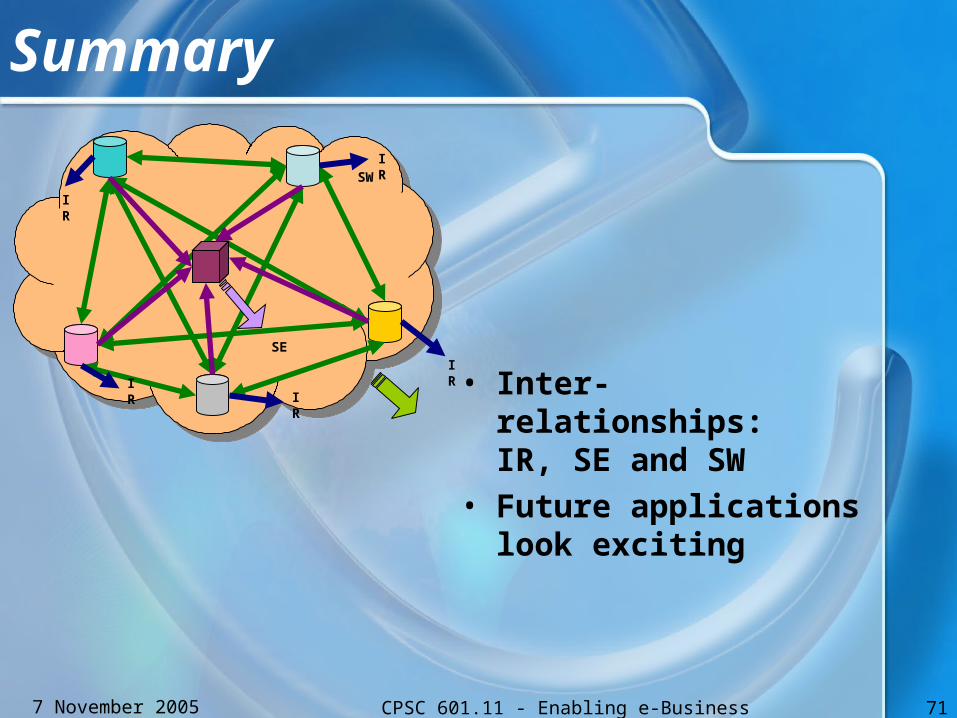
Summary
• Inter-relationships:IR, SE and SW
• Future applications look exciting
SW
SE
IR
IR
IR
IRIR

Thank you