end to-end hadoop development using obiee, odi, oracle big data sql and oracle big data discovery
TRANSCRIPT

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
End-to-End Hadoop Development using OBIEE, ODI and Oracle Big Data Discovery Mark Rittman, CTO, Rittman Mead March 2015
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
About the Speaker
•Mark Rittman, Co-Founder of Rittman Mead •Oracle ACE Director, specialising in Oracle BI&DW •14 Years Experience with Oracle Technology •Regular columnist for Oracle Magazine •Author of two Oracle Press Oracle BI books •Oracle Business Intelligence Developers Guide •Oracle Exalytics Revealed •Writer for Rittman Mead Blog :http://www.rittmanmead.com/blog
•Email : [email protected] •Twitter : @markrittman

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
About Rittman Mead
•Oracle BI and DW Gold partner •Winner of five UKOUG Partner of the Year awards in 2013 - including BI •World leading specialist partner for technical excellence, solutions delivery and innovation in Oracle BI
•Approximately 80 consultants worldwide •All expert in Oracle BI and DW •Offices in US (Atlanta), Europe, Australia and India •Skills in broad range of supporting Oracle tools: ‣OBIEE, OBIA, ODIEE ‣Big Data, Hadoop, NoSQL & Big Data Discovery ‣Essbase, Oracle OLAP ‣GoldenGate ‣Endeca

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
End-to-End Oracle Big Data Example
•Rittman Mead want to understand drivers and audience for their website ‣What is our most popular content? Who are the most in-demand blog authors? ‣Who are the influencers? What do they read?
•Three data sources in scope:
RM Website Logs Twitter Stream Website Posts, Comments etc

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Two Analysis Scenarios : Reporting, and Data Discovery
• Initial task will be to ingest data from webserver logs, Twitter firehose, site content + ref data •Land in Hadoop cluster, basic transform, format, store; then, analyse the data:
1 Combine with Oracle Big Data SQL for structured OBIEE dashboard analysis 2 Combine with site content, semantics, text enrichment
Catalog and explore using Oracle Big Data Discovery
What pages are people visiting? Who is referring to us on Twitter? What content has the most reach?
Why is some content more popular? Does sentiment affect viewership? What content is popular, where?

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Step 1 Ingesting Basic Dataset into Hadoop

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Data Loading into Hadoop
•Default load type is real-time, streaming loads ‣Batch / bulk loads only typically used to seed system
•Variety of sources including web log activity, event streams •Target is typically HDFS (Hive) or HBase •Data typically lands in “raw state” ‣Lots of files and events, need to be filtered/aggregated ‣Typically semi-structured (JSON, logs etc) ‣High volume, high velocity
-Which is why we use Hadoop rather thanRBDMS (speed vs. ACID trade-off)
‣Economics of Hadoop means its often possible toarchive all incoming data at detail level
Loading Stage
Real-Time Logs / Events
File / UnstructuredImports
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
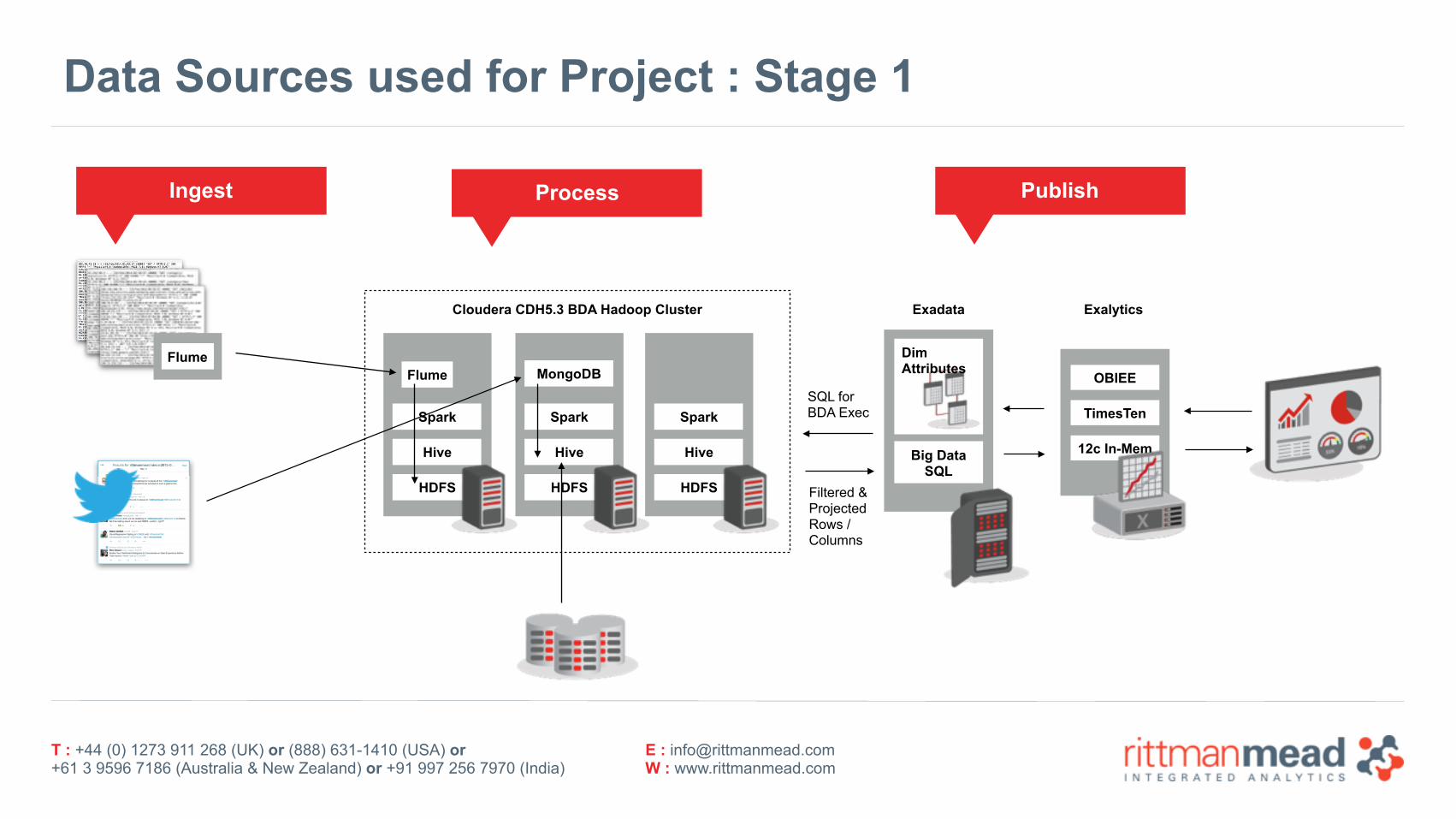
Data Sources used for Project : Stage 1
Spark
Hive
HDFS
Spark
Hive
HDFS
Spark
Hive
HDFS
Cloudera CDH5.3 BDA Hadoop Cluster
Big Data SQL
Exadata Exalytics
Flume Flume MongoDB
DimAttributes
SQL for BDA Exec
Filtered &Projected Rows / Columns
OBIEE
TimesTen
12c In-Mem
Ingest Process Publish
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
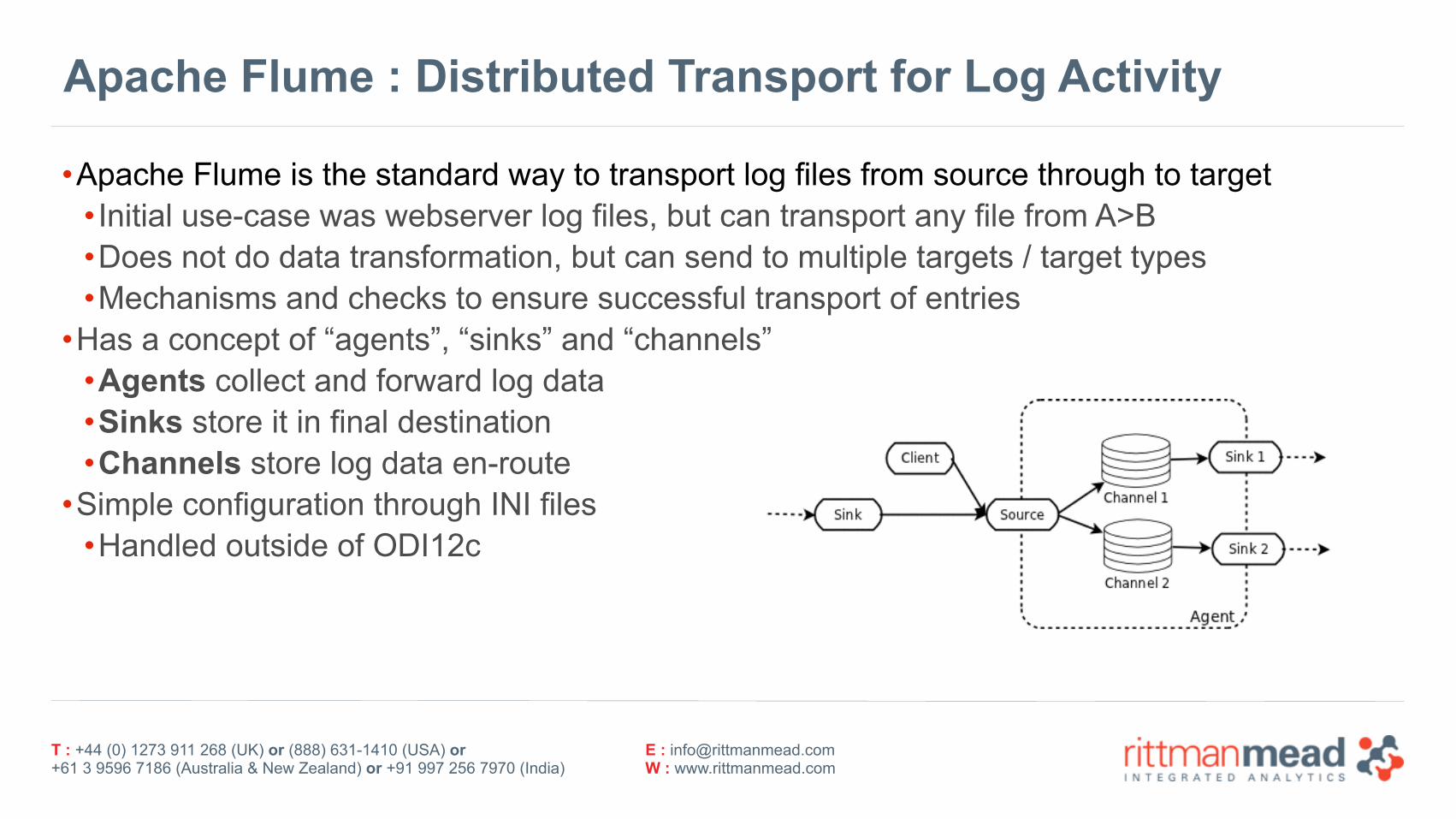
Apache Flume : Distributed Transport for Log Activity
•Apache Flume is the standard way to transport log files from source through to target • Initial use-case was webserver log files, but can transport any file from A>B •Does not do data transformation, but can send to multiple targets / target types •Mechanisms and checks to ensure successful transport of entries
•Has a concept of “agents”, “sinks” and “channels” •Agents collect and forward log data •Sinks store it in final destination •Channels store log data en-route
•Simple configuration through INI files •Handled outside of ODI12c

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Flume Source / Target Configuration
•Conf file for source system agent •TCP port, channel size+type, source type
•Conf file for target system agent •TCP port, channel size+type, sink type
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
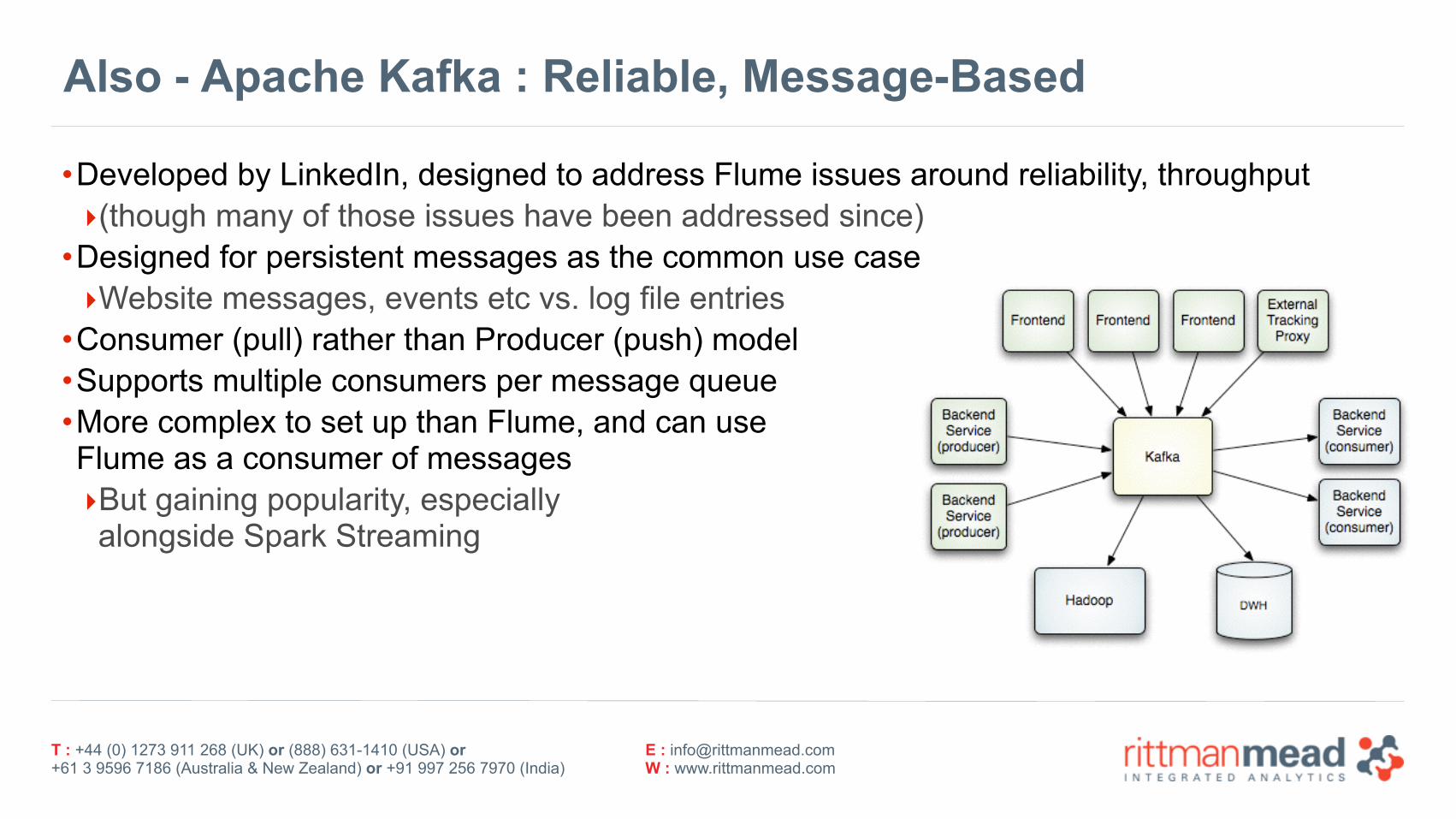
Also - Apache Kafka : Reliable, Message-Based
•Developed by LinkedIn, designed to address Flume issues around reliability, throughput ‣(though many of those issues have been addressed since)
•Designed for persistent messages as the common use case ‣Website messages, events etc vs. log file entries
•Consumer (pull) rather than Producer (push) model •Supports multiple consumers per message queue •More complex to set up than Flume, and can useFlume as a consumer of messages ‣But gaining popularity, especially alongside Spark Streaming

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Starting Flume Agents, Check Files Landing in HDFS Directory
•Start the Flume agents on source and target (BDA) servers •Check that incoming file data starts appearing in HDFS ‣Note - files will be continuously written-to as entries added to source log files ‣Channel size for source, target agentsdetermines max no. of events buffered ‣If buffer exceeded, new events droppeduntil buffer < channel size

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Adding Social Media Datasources to the Hadoop Dataset
•The log activity from the Rittman Mead website tells us what happened, but not “why” •Common customer requirement now is to get a “360 degree view” of their activity ‣Understand what’s being said about them ‣External drivers for interest, activity ‣Understand more about customer intent, opinions
•One example is to add details of social media mentions,likes, tweets and retweets etc to the transactional dataset ‣Correlate twitter activity with sales increases, drops ‣Measure impact of social media strategy ‣Gather and include textual, sentiment, contextualdata from surveys, media etc
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
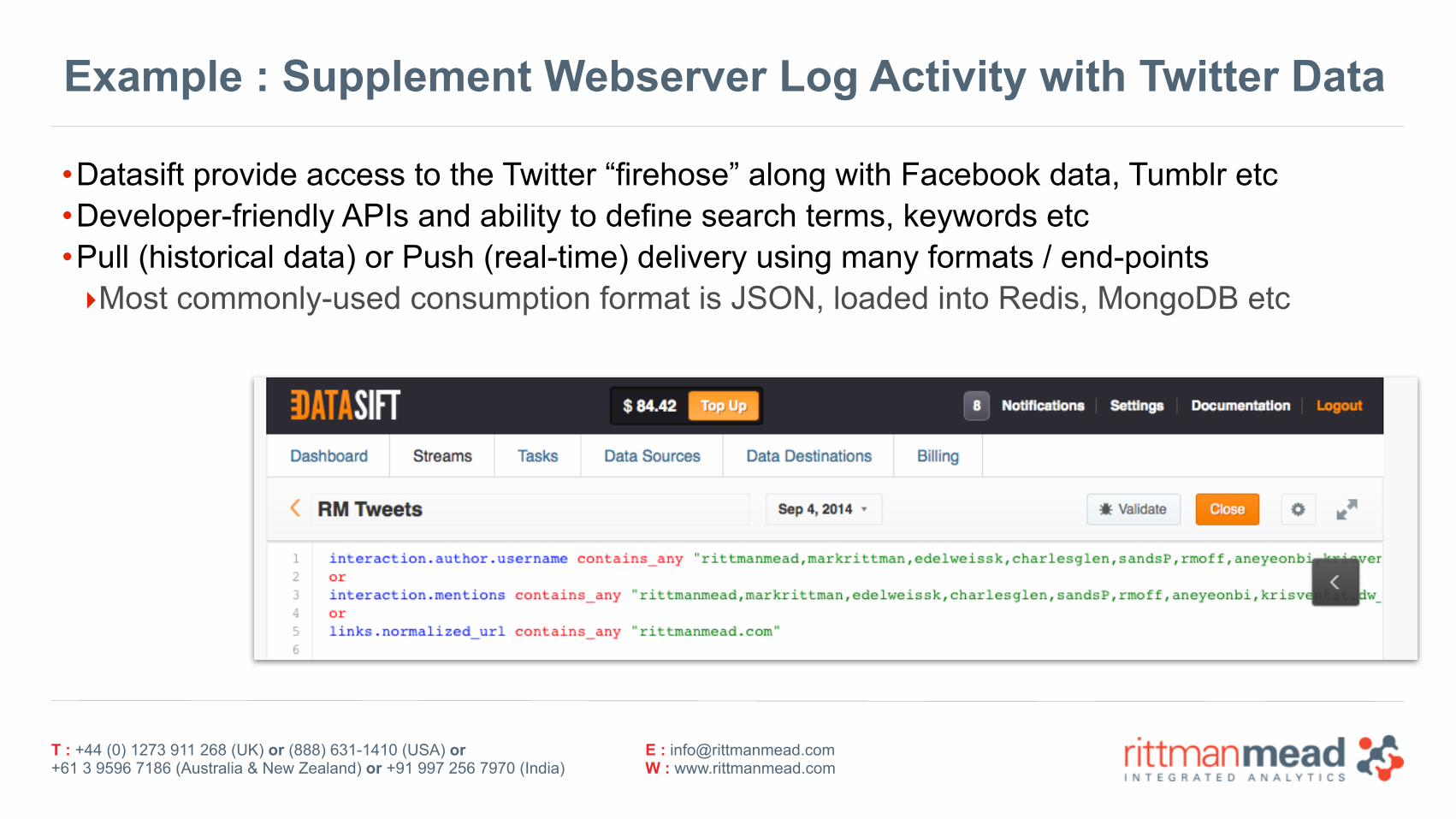
Example : Supplement Webserver Log Activity with Twitter Data
•Datasift provide access to the Twitter “firehose” along with Facebook data, Tumblr etc •Developer-friendly APIs and ability to define search terms, keywords etc •Pull (historical data) or Push (real-time) delivery using many formats / end-points ‣Most commonly-used consumption format is JSON, loaded into Redis, MongoDB etc
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
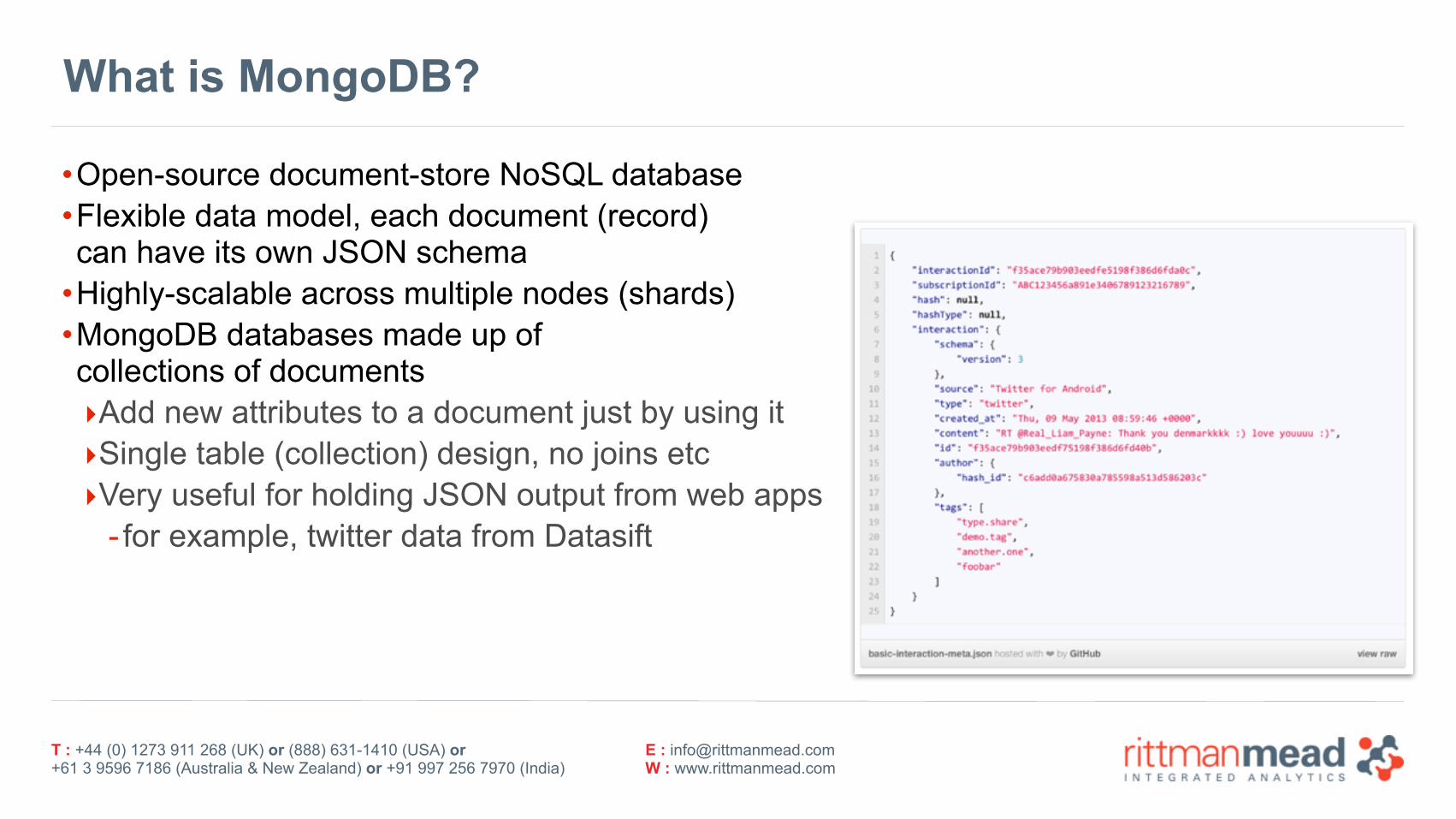
What is MongoDB?
•Open-source document-store NoSQL database •Flexible data model, each document (record) can have its own JSON schema
•Highly-scalable across multiple nodes (shards) •MongoDB databases made up of collections of documents ‣Add new attributes to a document just by using it ‣Single table (collection) design, no joins etc ‣Very useful for holding JSON output from web apps
- for example, twitter data from Datasift
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Where Are We Now : Data Ingestion Phase
•Log data streamed into HDFS via Flume collector / sink •Twitter data pushed into MongoDB collection •Data is in raw form •Now it needs to be refined, combined,transformed and processed intouseful data…

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Step 2 Processing, Enhancing & Transforming Data
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Core Apache Hadoop Tools
•Apache Hadoop, including MapReduce and HDFS ‣Scaleable, fault-tolerant file storage for Hadoop ‣Parallel programming framework for Hadoop
•Apache Hive ‣SQL abstraction layer over HDFS ‣Perform set-based ETL within Hadoop
•Apache Pig, Spark ‣Dataflow-type languages over HDFS, Hive etc ‣Extensible through UDFs, streaming etc
•Apache Flume, Apache Sqoop, Apache Kafka ‣Real-time and batch loading into HDFS ‣Modular, fault-tolerant, wide source/target coverage

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Other Tools Typically Used…
•Python, Scala, Java and other programming languages ‣For more complex and procedural transformations
•Shell scripts, sed, awk, regexes etc •R and R-on-Hadoop ‣Typically at the “discovery” phase
•And down the line - ETL tools to automate the process ‣ODI, Pentaho Data Integrator etc
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
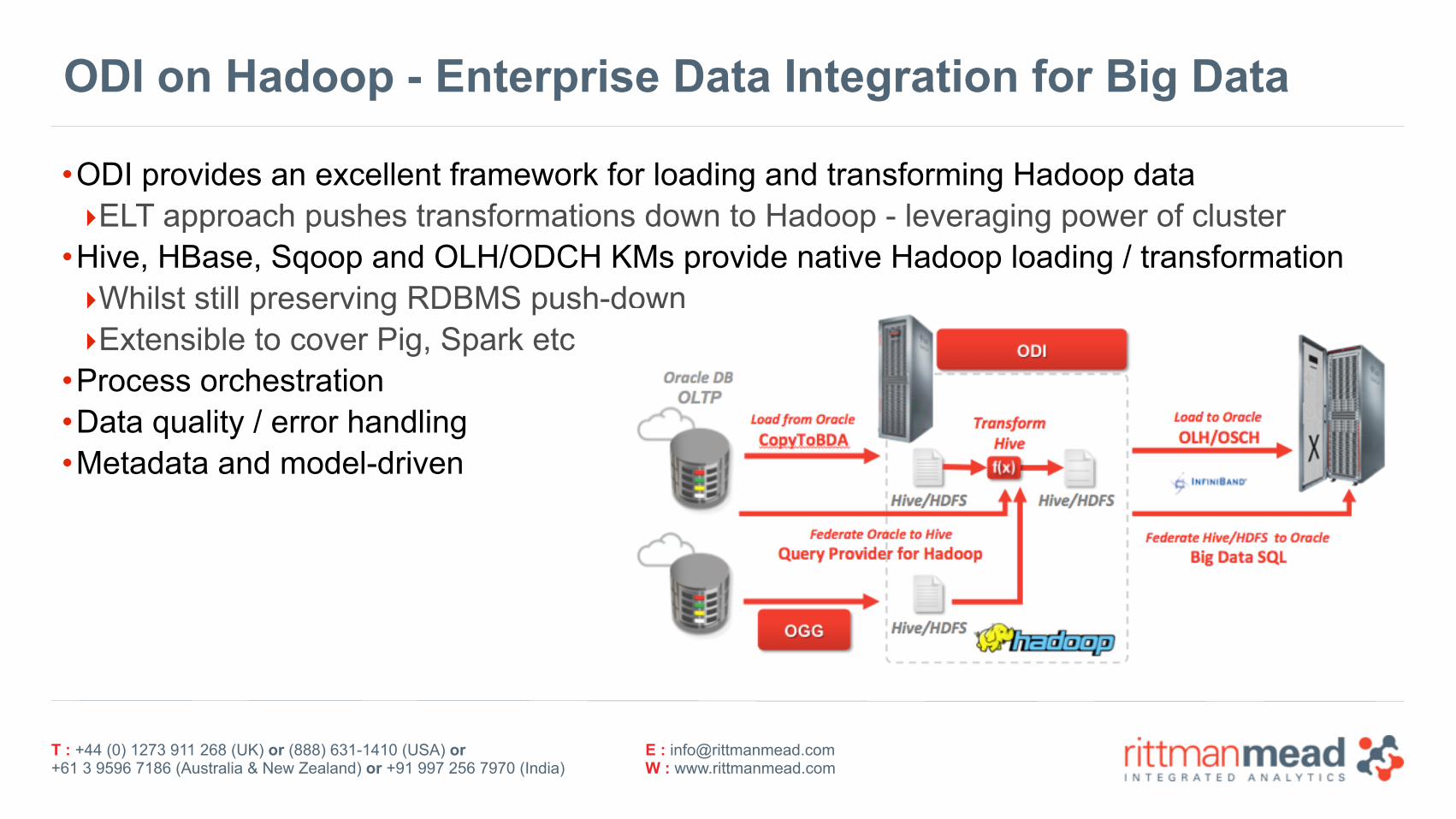
ODI on Hadoop - Enterprise Data Integration for Big Data
•ODI provides an excellent framework for loading and transforming Hadoop data ‣ELT approach pushes transformations down to Hadoop - leveraging power of cluster
•Hive, HBase, Sqoop and OLH/ODCH KMs provide native Hadoop loading / transformation ‣Whilst still preserving RDBMS push-down ‣Extensible to cover Pig, Spark etc
•Process orchestration •Data quality / error handling •Metadata and model-driven
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
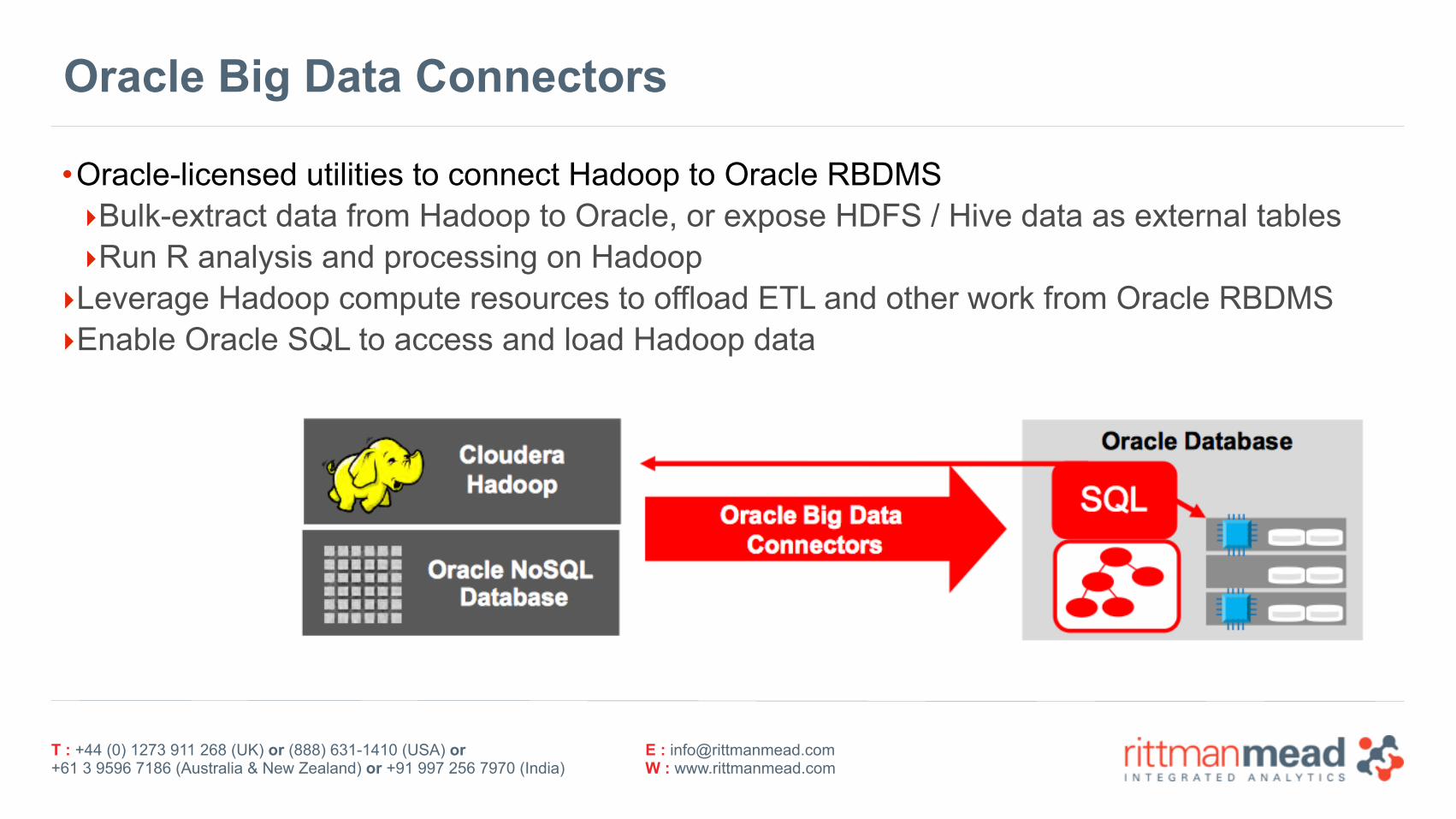
Oracle Big Data Connectors
•Oracle-licensed utilities to connect Hadoop to Oracle RBDMS ‣Bulk-extract data from Hadoop to Oracle, or expose HDFS / Hive data as external tables ‣Run R analysis and processing on Hadoop ‣Leverage Hadoop compute resources to offload ETL and other work from Oracle RBDMS ‣Enable Oracle SQL to access and load Hadoop data

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Hive SerDes & Storage Handlers
•Plug-in technologies that extend Hive to handle new data formats and semi-structured sources •Typically distributed as JAR files, hosted on sites such as GitHub •Can be used to parse log files, access data in NoSQL databases, Amazon S3 etc
CREATE EXTERNAL TABLE apachelog ( host STRING, identity STRING, user STRING, time STRING, request STRING, status STRING, size STRING, referer STRING, agent STRING) ROW FORMAT SERDE 'org.apache.hadoop.hive.contrib.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) (-|\\[[^\\]]*\\]) ([^ \"]*|\"[^\"]*\") (-|[0-9]*) (-|[0-9]*)(?: ([^ \"]*|\"[^\"]*\") ([^ \"]*|\"[^\"]*\"))?", "output.format.string" = "%1$s %2$s %3$s %4$s %5$s %6$s %7$s %8$s %9$s" ) STORED AS TEXTFILE LOCATION '/user/root/logs';
CREATE TABLE tweet_data( interactionId string, username string, content string, author_followers int) ROW FORMAT SERDE 'com.mongodb.hadoop.hive.BSONSerDe' STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler' WITH SERDEPROPERTIES ( 'mongo.columns.mapping'='{"interactionId":"interactionId", "username":"interaction.interaction.author.username", "content":\"interaction.interaction.content", "author_followers_count":"interaction.twitter.user.followers_count"}' ) TBLPROPERTIES ( 'mongo.uri'='mongodb://cdh51-node1:27017/datasiftmongodb.rm_tweets' )
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
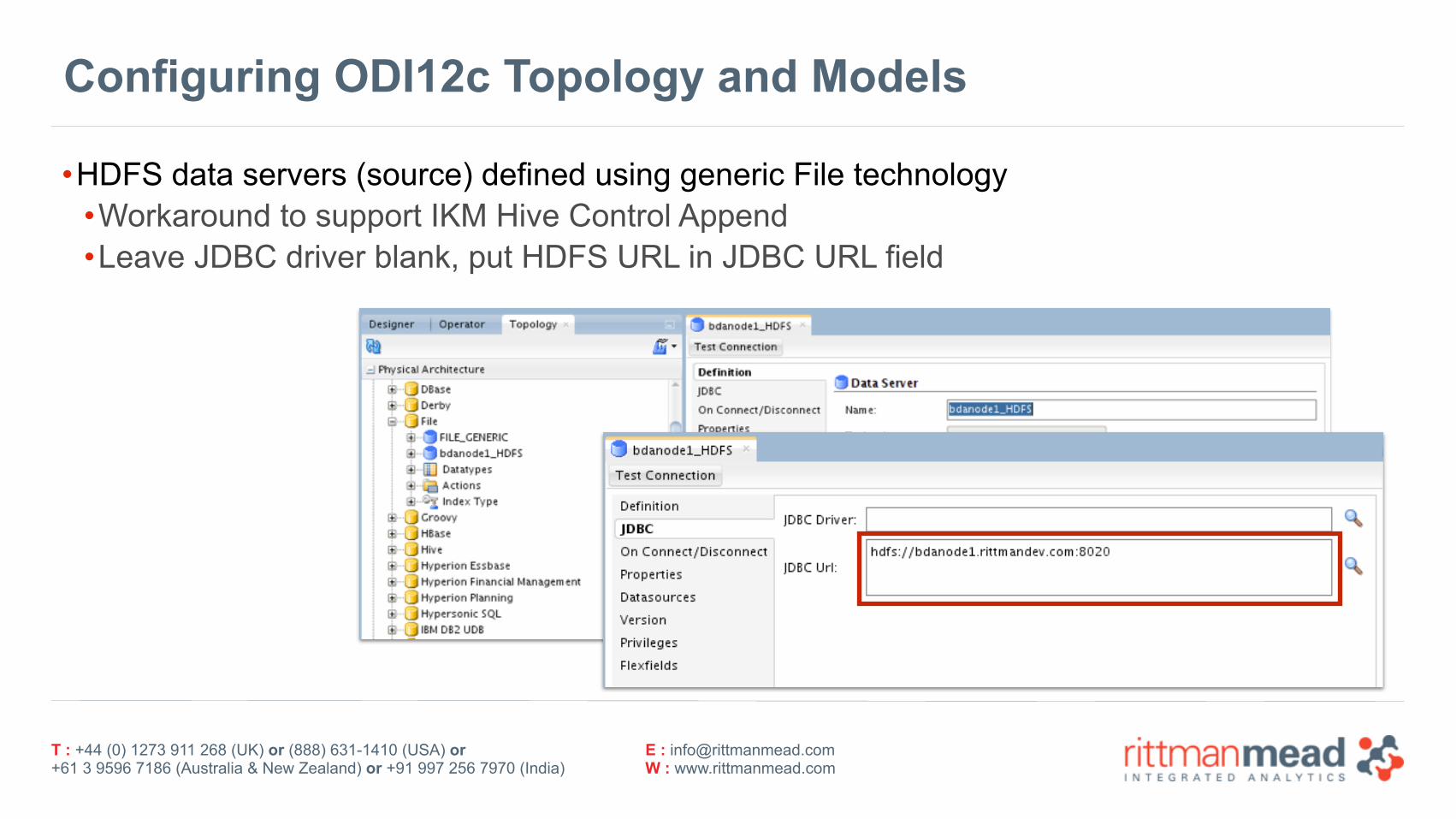
Configuring ODI12c Topology and Models
•HDFS data servers (source) defined using generic File technology •Workaround to support IKM Hive Control Append •Leave JDBC driver blank, put HDFS URL in JDBC URL field

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Defining Topology and Model for Hive Sources
•Hive supported “out-of-the-box” with ODI12c (but requires ODIAAH license for KMs) •Most recent Hadoop distributions use HiveServer2 rather than HiveServer
•Need to ensure JDBC drivers support Hive version •Use correct JDBC URL format (jdbc:hive2//…)

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
HDFS & Hive Model and Datastore Definitions
•HDFS files for incoming log data, and any other input data •Hive tables for ETL targets and downstream processing •Use RKM Hive to reverse-engineer column definition from Hive

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Hive and MongoDB
•MongoDB Hadoop connector provides a storage handler for Hive tables •Rather than store its data in HDFS, the Hive table uses MongoDB for storage instead •Define in SerDe properties the Collection elements you want to access, using dot notation •https://github.com/mongodb/mongo-hadoop
CREATE TABLE tweet_data( interactionId string, username string, content string, author_followers int) ROW FORMAT SERDE 'com.mongodb.hadoop.hive.BSONSerDe' STORED BY 'com.mongodb.hadoop.hive.MongoStorageHandler' WITH SERDEPROPERTIES ( 'mongo.columns.mapping'='{"interactionId":"interactionId", "username":"interaction.interaction.author.username", "content":\"interaction.interaction.content", "author_followers_count":"interaction.twitter.user.followers_count"}' ) TBLPROPERTIES ( 'mongo.uri'='mongodb://cdh51-node1:27017/datasiftmongodb.rm_tweets' )

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Adding MongoDB Datasets into the ODI Repository
•Define Hive table outside of ODI, using MongoDB storage handler •Select the document elements of interest, project into Hive columns •Add Hive source to Topology if needed, then use Hive RKM to bring in column metadata

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Load Incoming Log Files into Hive Table
•First step in process is to load the incoming log files into a Hive table ‣Also need to parse the log entries to extract request, date, IP address etc columns ‣Hive table can then easily be used in downstream transformations
•Use IKM File to Hive (LOAD DATA) KM ‣Source can be local files or HDFS ‣Either load file into Hive HDFS area,or leave as external Hive table ‣Ability to use SerDe to parse file data
1

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Specifying a SerDe to Parse Incoming Hive Data
•SerDe (Serializer-Deserializer) interfaces give Hive the ability to process new file formats •Distributed as JAR file, gives Hive ability to parse semi-structured formats •We can use the RegEx SerDe to parse the Apache CombinedLogFormat file into columns •Enabled through OVERRIDE_ROW_FORMAT IKM File to Hive (LOAD DATA) KM option

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Join to Additional Hive Tables, Transform using HiveQL
• IKM Hive to Hive Control Append can be used to perform Hive table joins, filtering, agg. etc. • INSERT only, no DELETE, UPDATE etc •Not all ODI12c mapping operators supported, but basic functionality works OK •Use this KM to join to other Hive tables,adding more details on post, title etc
•Perform DISTINCT on join output, loadinto summary Hive table
2
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
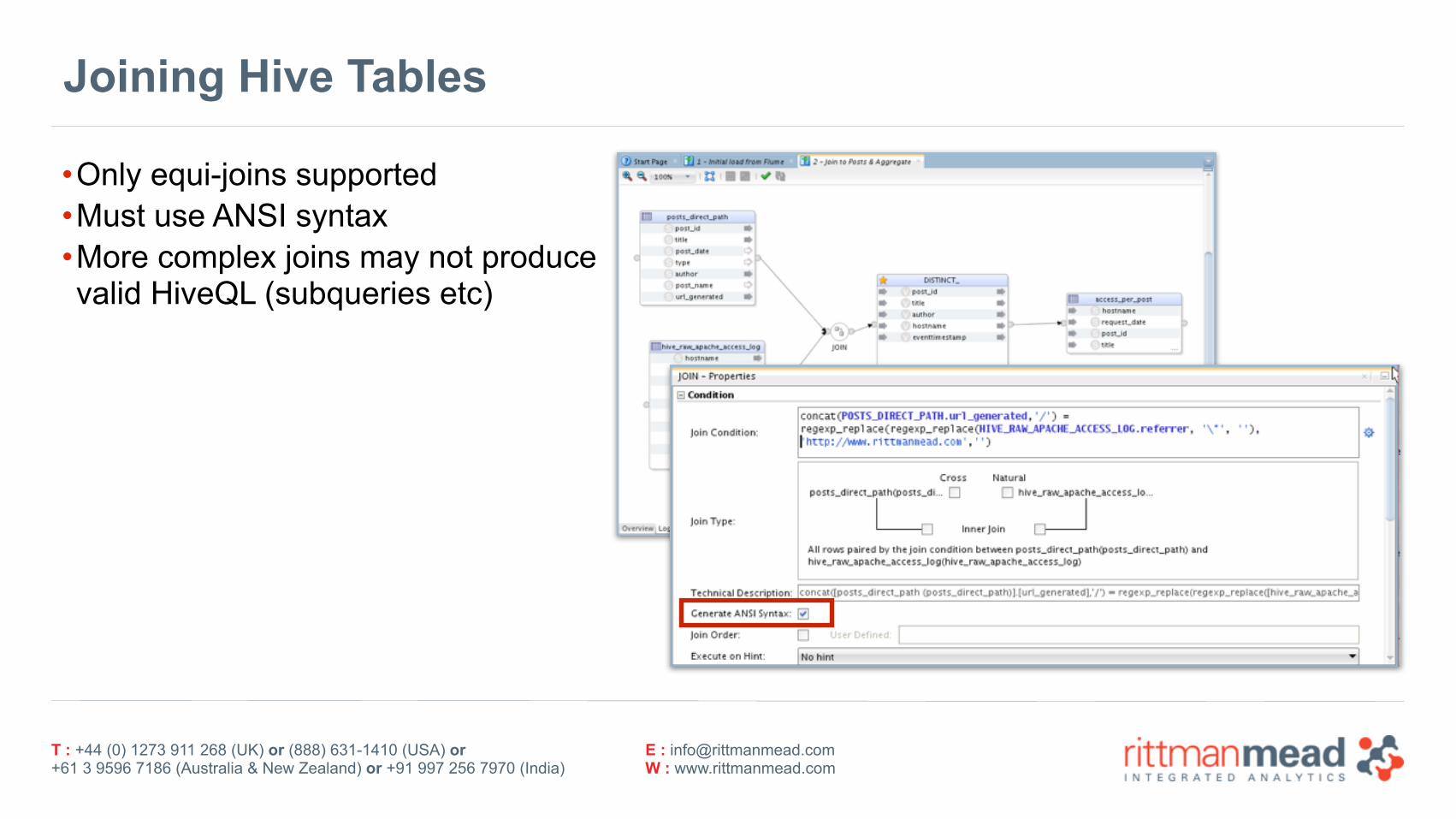
Joining Hive Tables
•Only equi-joins supported •Must use ANSI syntax •More complex joins may not producevalid HiveQL (subqueries etc)
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
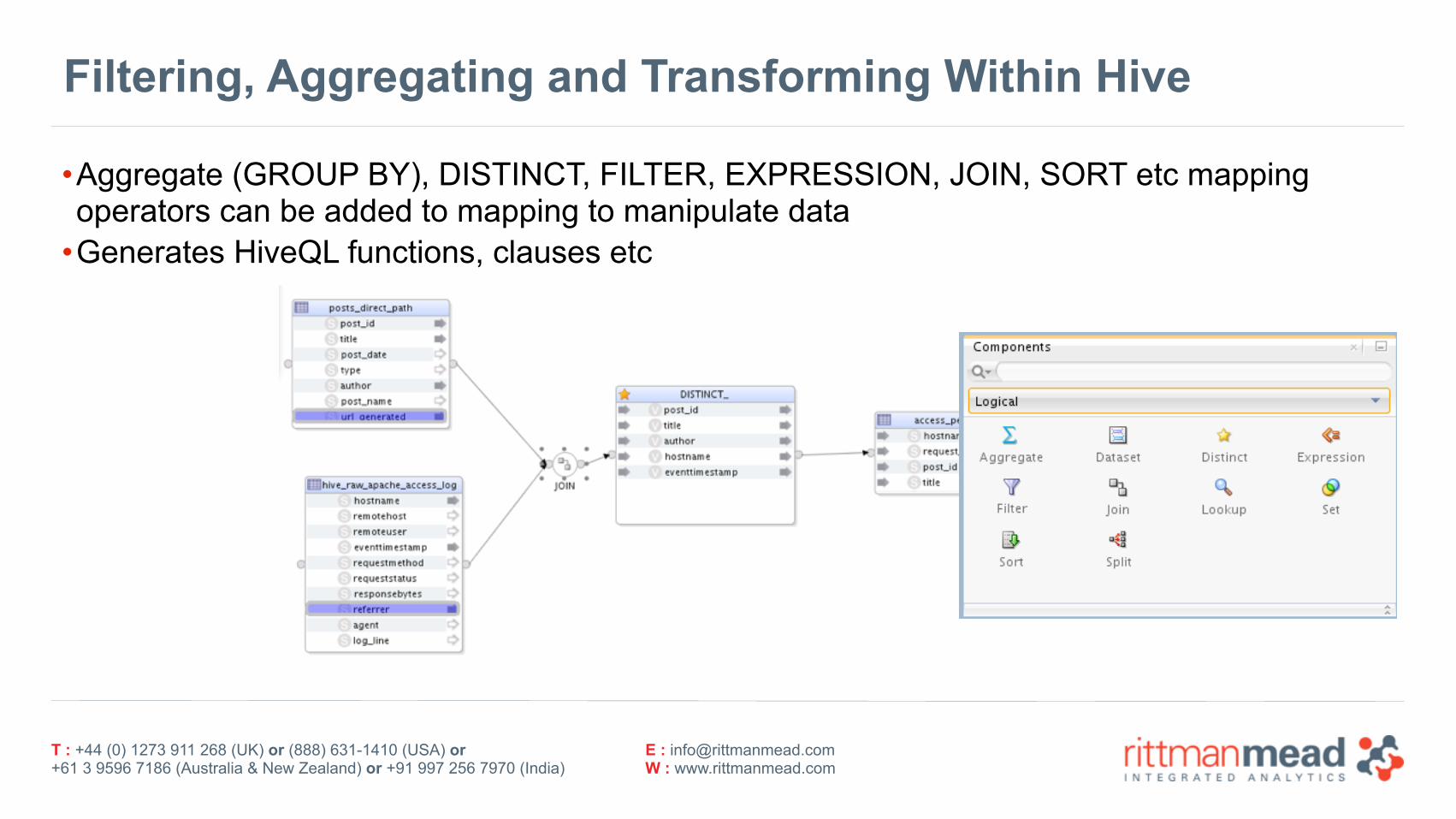
Filtering, Aggregating and Transforming Within Hive
•Aggregate (GROUP BY), DISTINCT, FILTER, EXPRESSION, JOIN, SORT etc mapping operators can be added to mapping to manipulate data
•Generates HiveQL functions, clauses etc
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
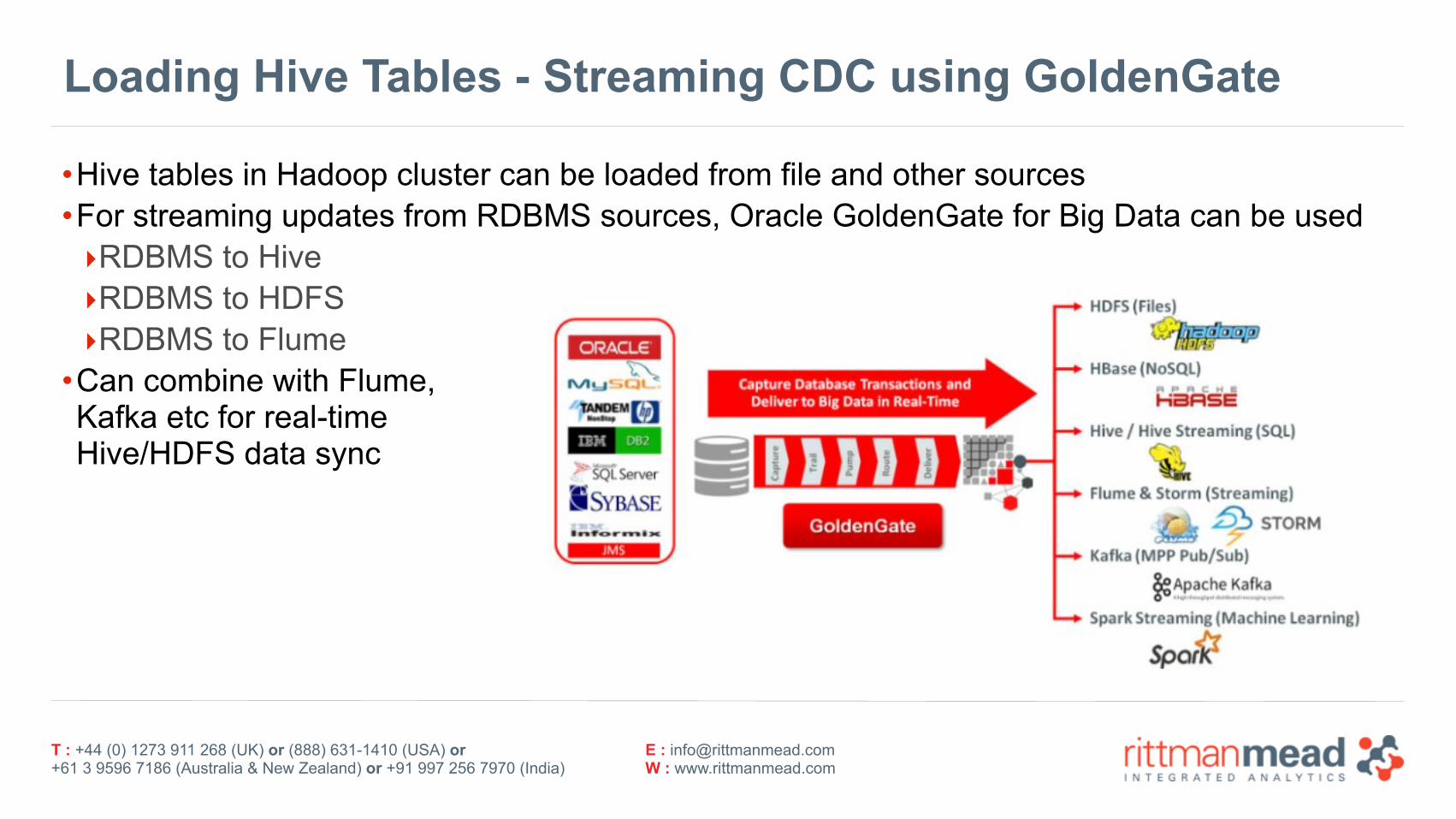
Loading Hive Tables - Streaming CDC using GoldenGate
•Hive tables in Hadoop cluster can be loaded from file and other sources •For streaming updates from RDBMS sources, Oracle GoldenGate for Big Data can be used ‣RDBMS to Hive ‣RDBMS to HDFS ‣RDBMS to Flume
•Can combine with Flume,Kafka etc for real-time Hive/HDFS data sync

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Bring in Reference Data from Oracle Database
• In this third step, additional reference data from Oracle Database needs to be added • In theory, should be able to add Oracle-sourced datastores to mapping and join as usual •But … Oracle / JDBC-generic LKMs don’t get work with Hive
3

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Options for Importing Oracle / RDBMS Data into Hadoop
•Could export RBDMS data to file, and load using IKM File to Hive •Oracle Big Data Connectors only export to Oracle, not import to Hadoop •Best option is to use Apache Sqoop, and new IKM SQL to Hive-HBase-File knowledge module •Hadoop-native, automatically runs in parallel •Uses native JDBC drivers, or OraOop (for example) •Bi-directional in-and-out of Hadoop to RDBMS •Run from OS command-line

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Loading RDBMS Data into Hive using Sqoop
•First step is to stage Oracle data into equivalent Hive table •Use special LKM SQL Multi-Connect Global load knowledge module for Oracle source ‣Passes responsibility for load (extract) to following IKM
•Then use IKM SQL to Hive-HBase-File (Sqoop) to load the Hive table
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
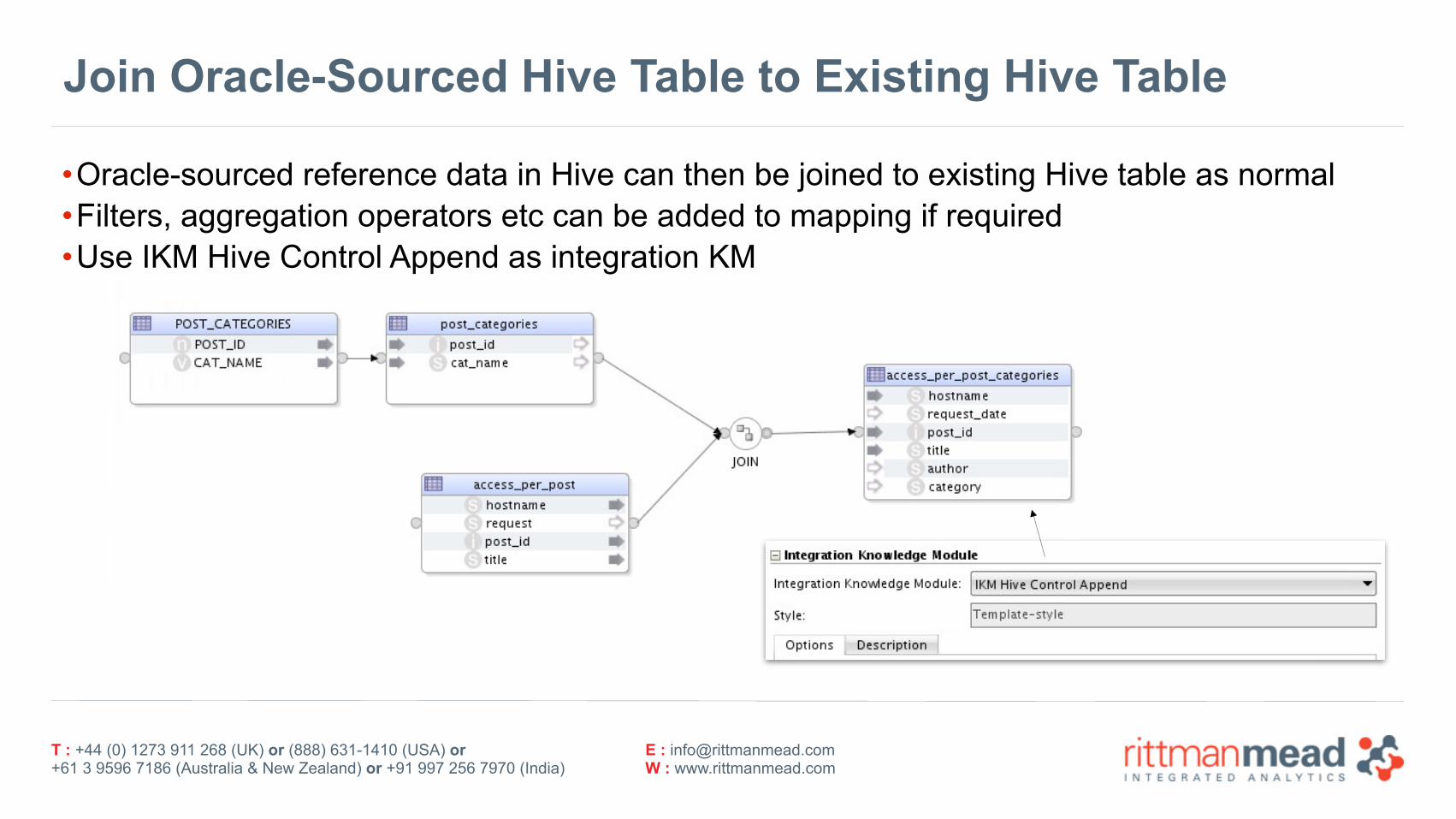
Join Oracle-Sourced Hive Table to Existing Hive Table
•Oracle-sourced reference data in Hive can then be joined to existing Hive table as normal •Filters, aggregation operators etc can be added to mapping if required •Use IKM Hive Control Append as integration KM
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
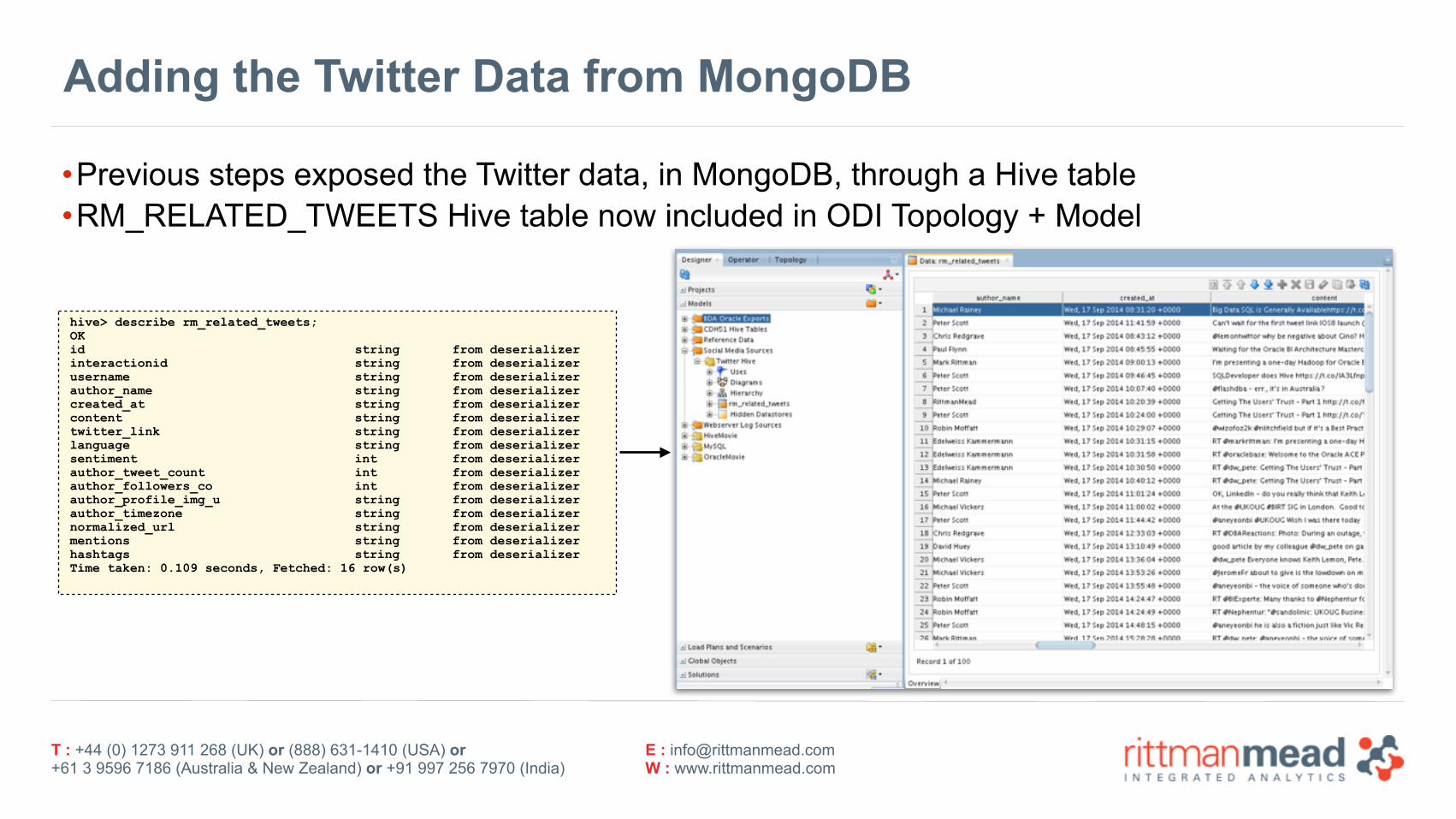
Adding the Twitter Data from MongoDB
•Previous steps exposed the Twitter data, in MongoDB, through a Hive table •RM_RELATED_TWEETS Hive table now included in ODI Topology + Model
hive> describe rm_related_tweets; OK id string from deserializer interactionid string from deserializer username string from deserializer author_name string from deserializer created_at string from deserializer content string from deserializer twitter_link string from deserializer language string from deserializer sentiment int from deserializer author_tweet_count int from deserializer author_followers_co int from deserializer author_profile_img_u string from deserializer author_timezone string from deserializer normalized_url string from deserializer mentions string from deserializer hashtags string from deserializer Time taken: 0.109 seconds, Fetched: 16 row(s)
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
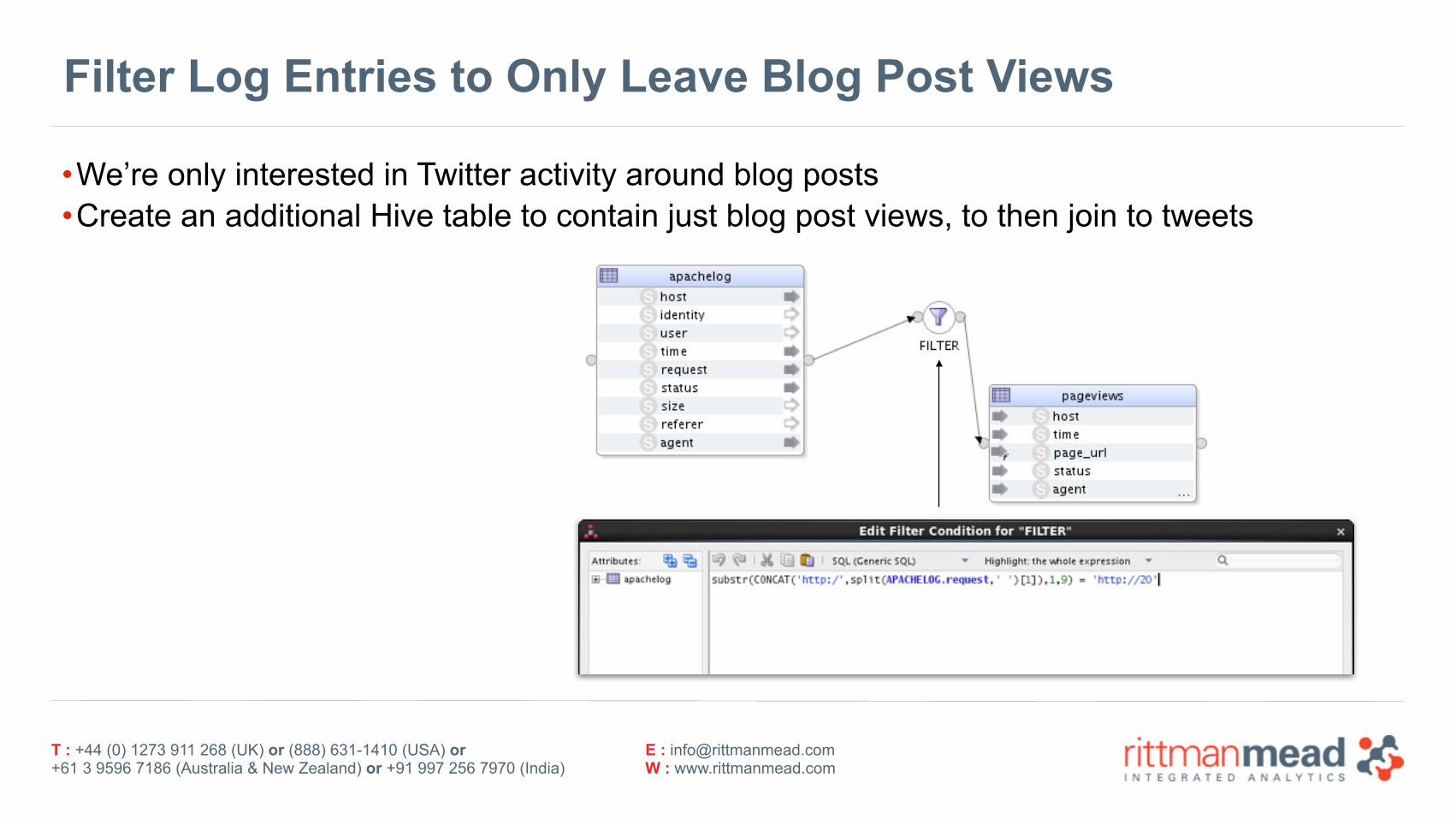
Filter Log Entries to Only Leave Blog Post Views
•We’re only interested in Twitter activity around blog posts •Create an additional Hive table to contain just blog post views, to then join to tweets
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
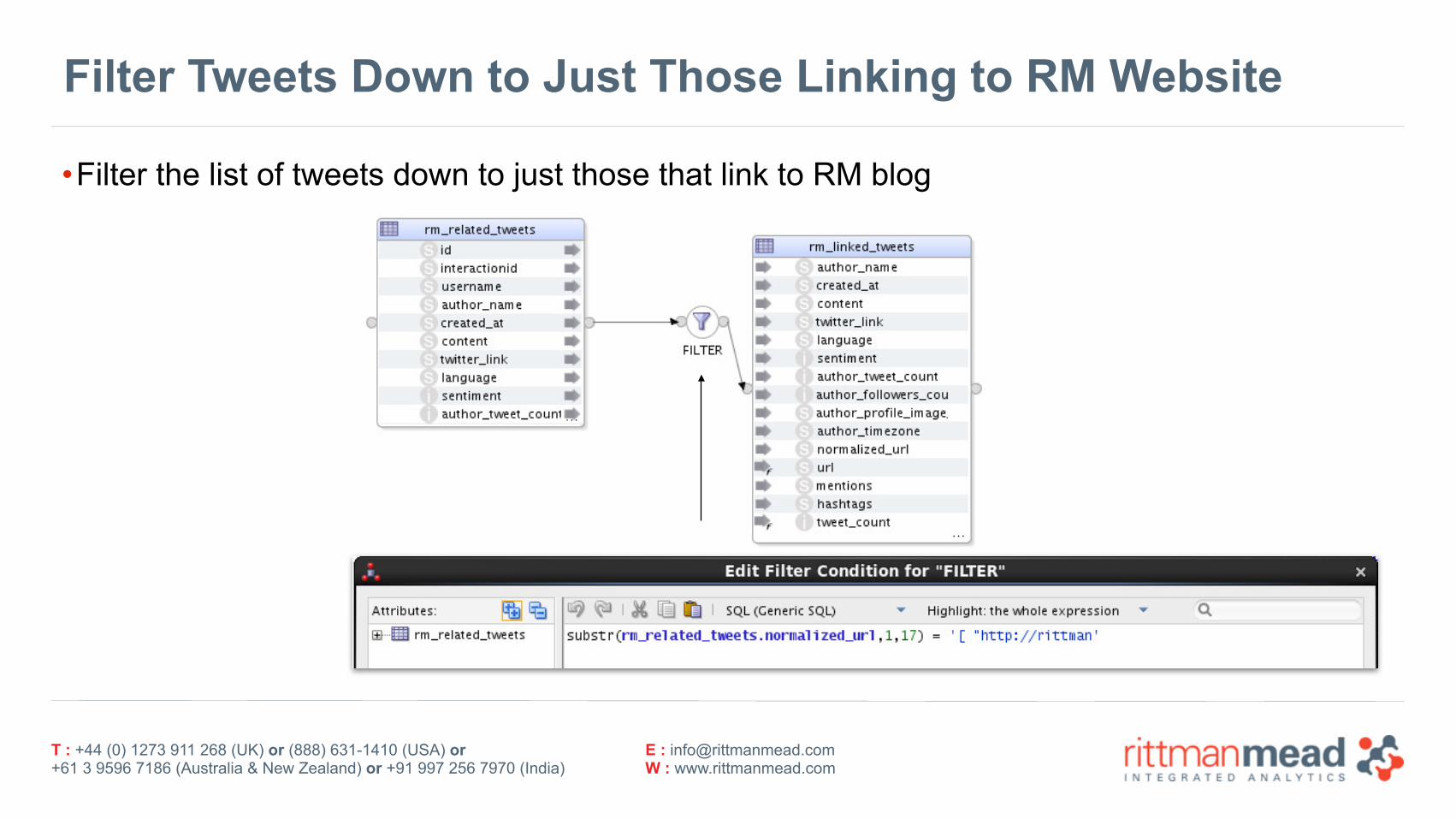
Filter Tweets Down to Just Those Linking to RM Website
•Filter the list of tweets down to just those that link to RM blog
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
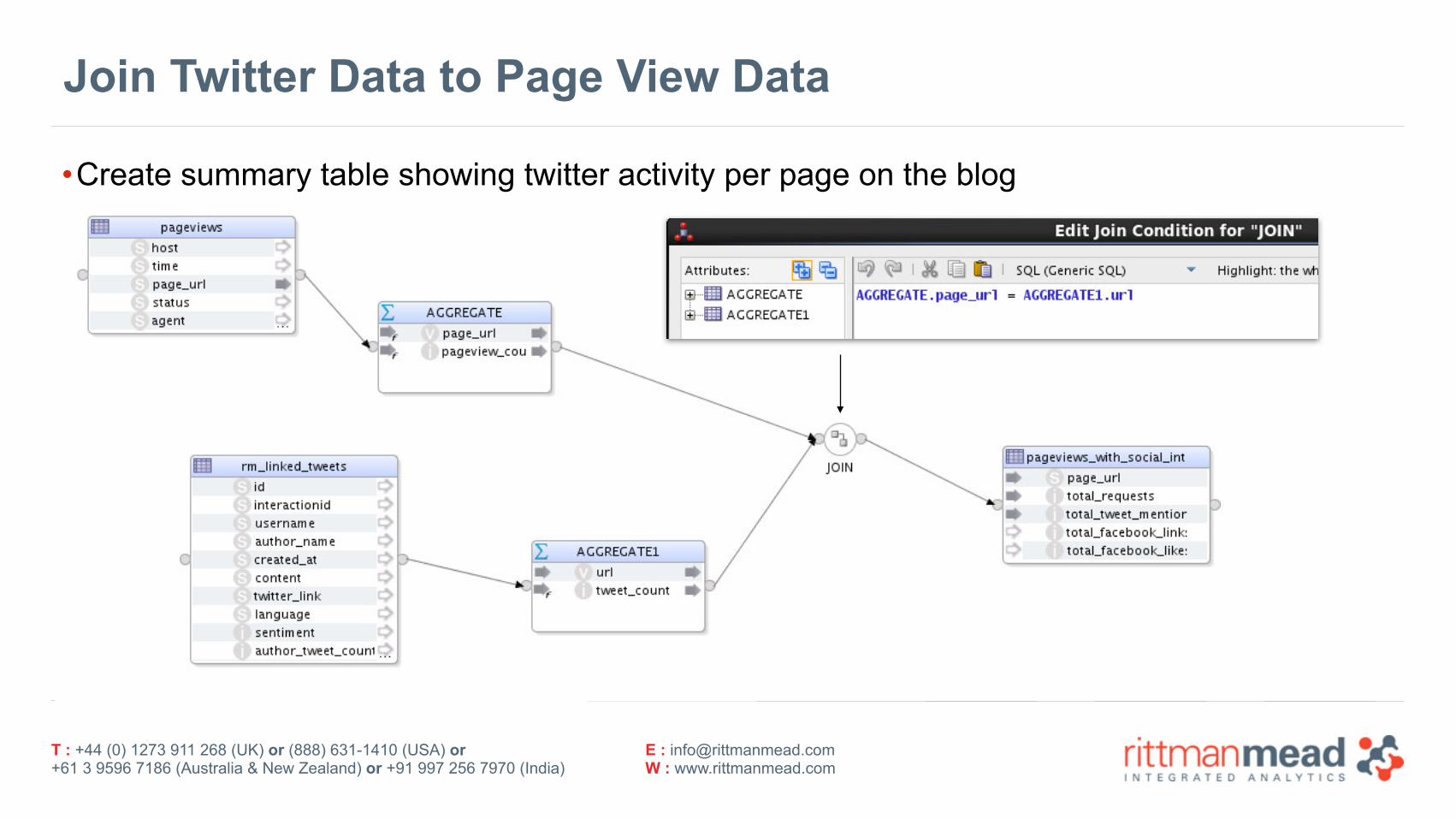
Join Twitter Data to Page View Data
•Create summary table showing twitter activity per page on the blog
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
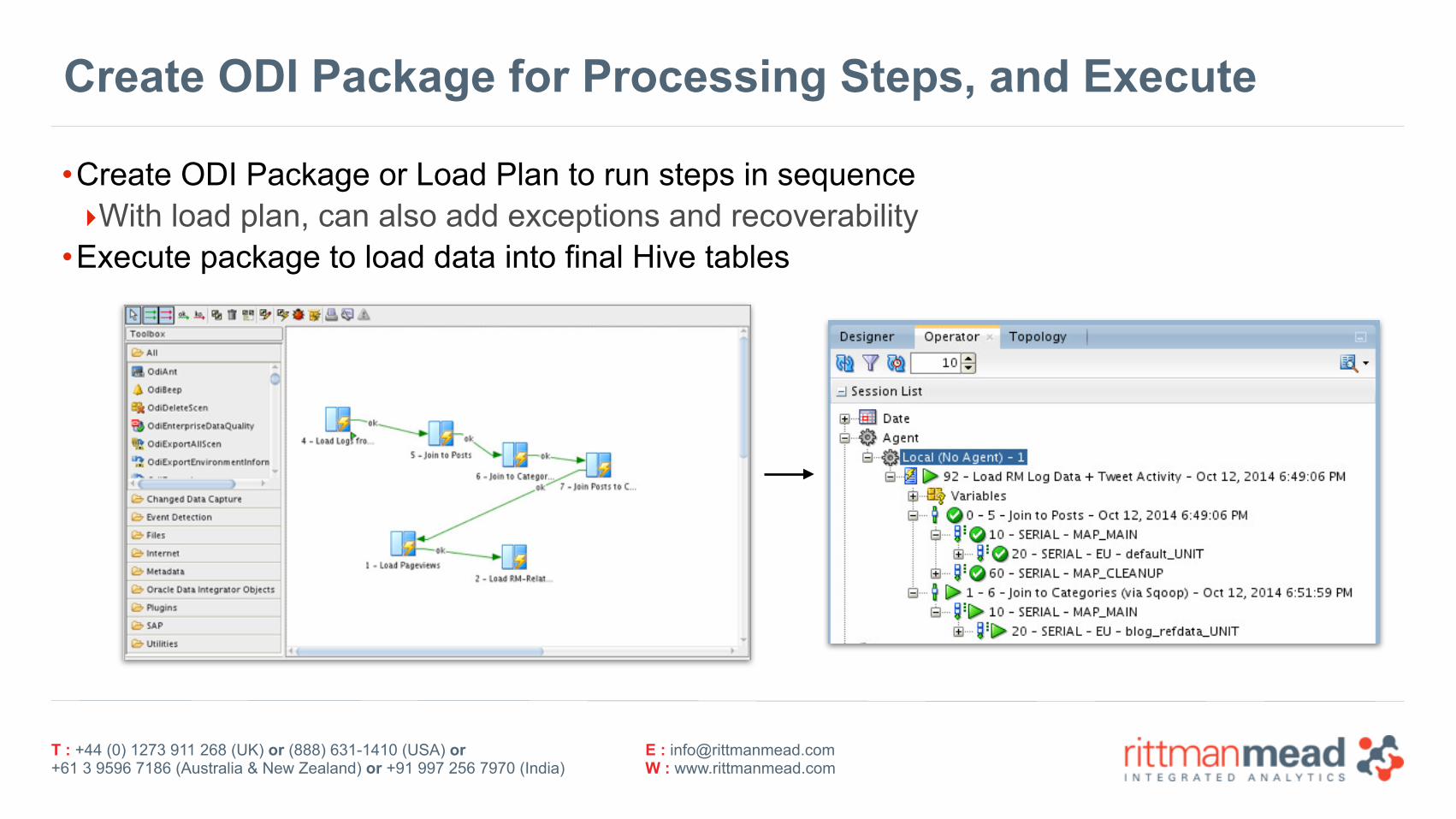
Create ODI Package for Processing Steps, and Execute
•Create ODI Package or Load Plan to run steps in sequence ‣With load plan, can also add exceptions and recoverability
•Execute package to load data into final Hive tables
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
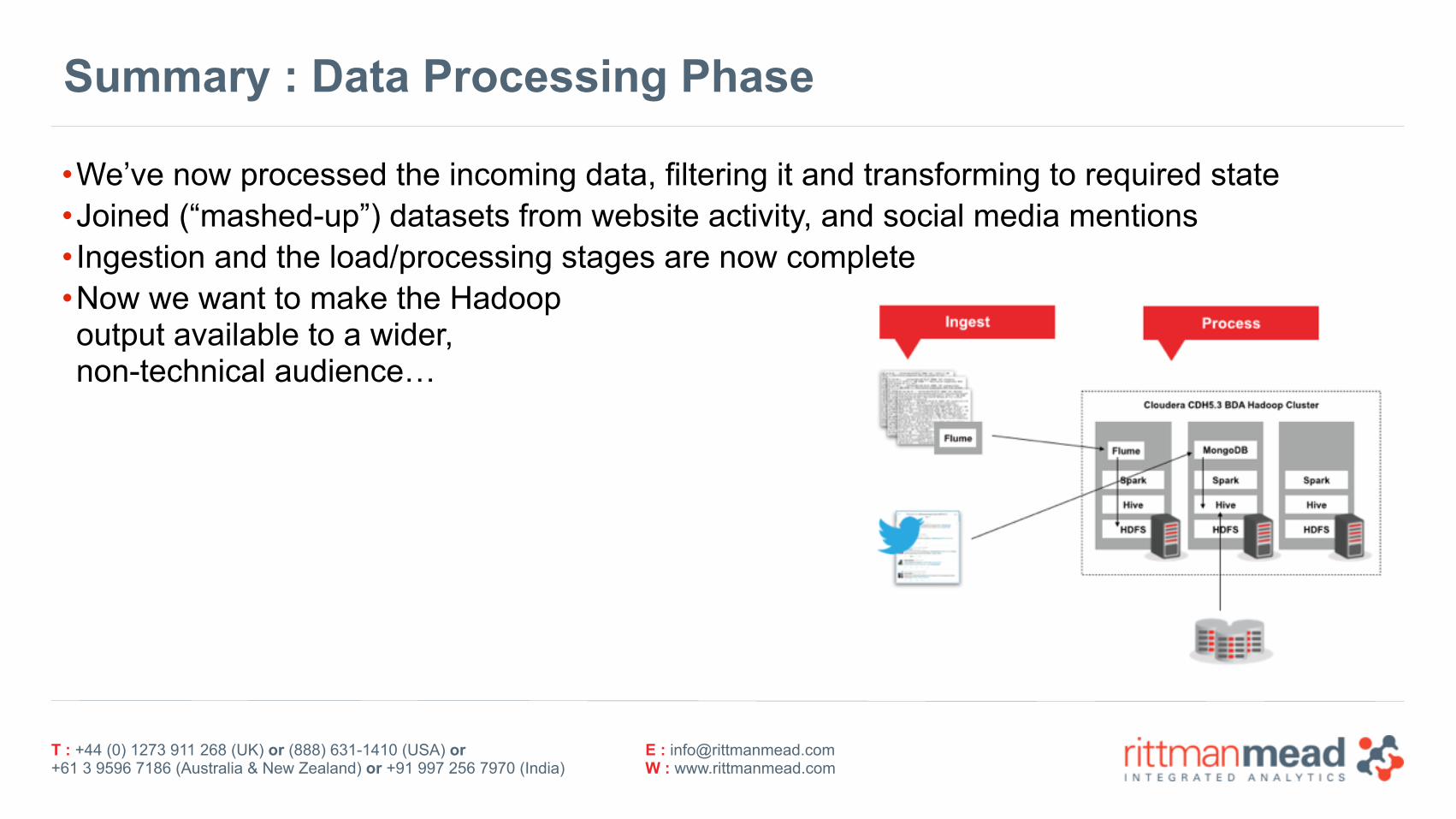
Summary : Data Processing Phase
•We’ve now processed the incoming data, filtering it and transforming to required state •Joined (“mashed-up”) datasets from website activity, and social media mentions • Ingestion and the load/processing stages are now complete •Now we want to make the Hadoop output available to a wider, non-technical audience…

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Step 3 Publishing & Analyzing Data

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
New in OBIEE 11.1.1.7 : Hadoop Connectivity through Hive
•MapReduce jobs are typically written in Java, but Hive can make this simpler •Hive is a query environment over Hadoop/MapReduce to support SQL-like queries •Hive server accepts HiveQL queries via HiveODBC or HiveJDBC, automaticallycreates MapReduce jobs against data previously loaded into the Hive HDFS tables
•Approach used by ODI and OBIEE to gain access to Hadoop data •Allows Hadoop data to be accessed just like any other data source
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
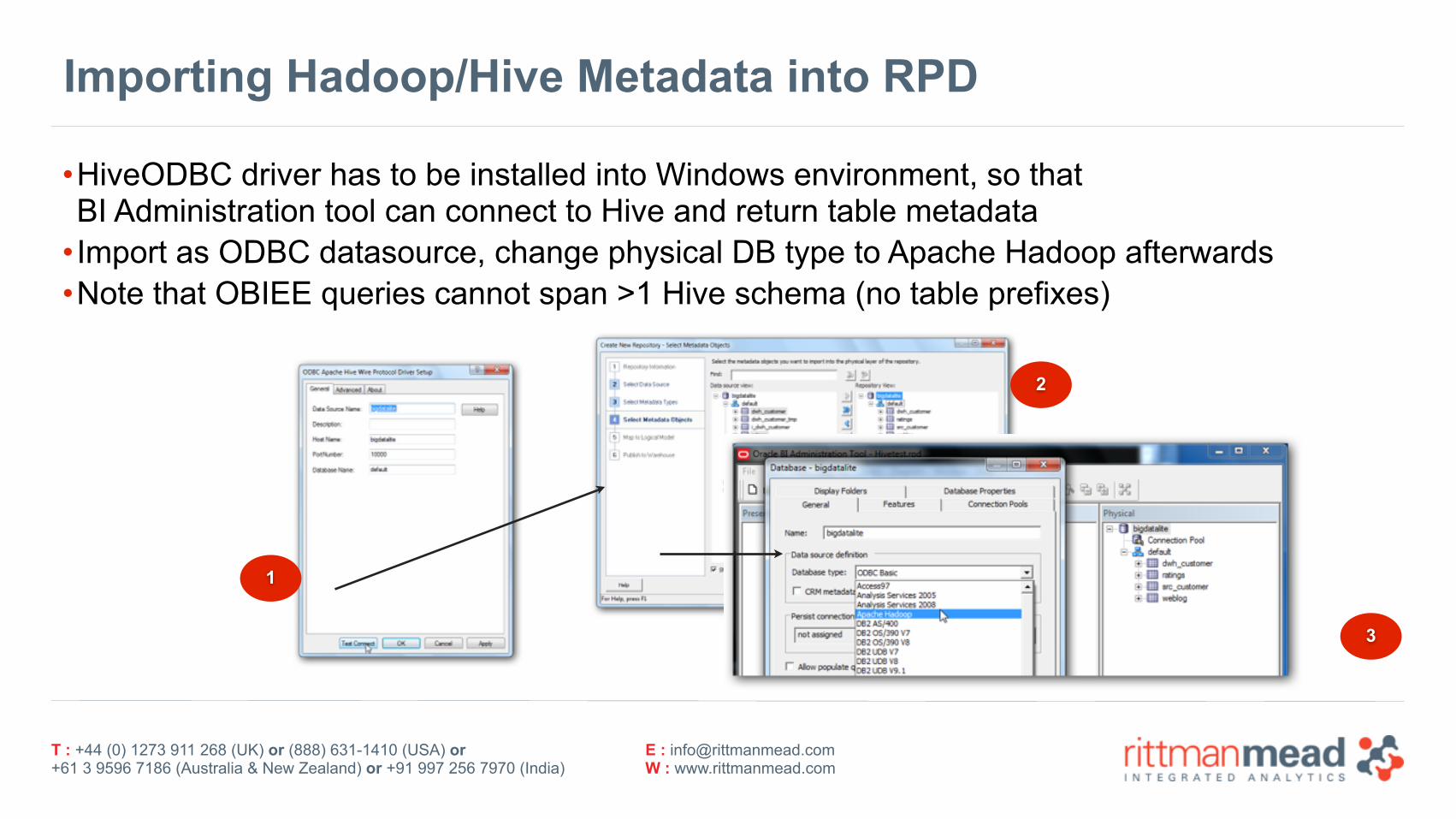
Importing Hadoop/Hive Metadata into RPD
•HiveODBC driver has to be installed into Windows environment, so that BI Administration tool can connect to Hive and return table metadata
• Import as ODBC datasource, change physical DB type to Apache Hadoop afterwards •Note that OBIEE queries cannot span >1 Hive schema (no table prefixes)
1
2
3

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Set up ODBC Connection at the OBIEE Server
•OBIEE 11.1.1.7+ ships with HiveODBC drivers, need to use 7.x versions though (only Linux supported)
•Configure the ODBC connection in odbc.ini, name needs to match RPD ODBC name •BI Server should then be able to connect to the Hive server, and Hadoop/MapReduce
[ODBC Data Sources] AnalyticsWeb=Oracle BI Server Cluster=Oracle BI Server SSL_Sample=Oracle BI Server bigdatalite=Oracle 7.1 Apache Hive Wire Protocol
[bigdatalite] Driver=/u01/app/Middleware/Oracle_BI1/common/ODBC/ Merant/7.0.1/lib/ARhive27.so Description=Oracle 7.1 Apache Hive Wire ProtocolArraySize=16384 Database=default DefaultLongDataBuffLen=1024 EnableLongDataBuffLen=1024 EnableDescribeParam=0 Hostname=bigdatalite LoginTimeout=30 MaxVarcharSize=2000 PortNumber=10000 RemoveColumnQualifiers=0 StringDescribeType=12 TransactionMode=0 UseCurrentSchema=0

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
OBIEE 11.1.1.7 / HiveServer2 ODBC Driver Issue
•Most customers using BDAs are using CDH4 or CDH5 - which uses HiveServer2 •OBIEE 11.1.1.7 only ships/supports HiveServer1 ODBC drivers •But … OBIEE 11.1.1.7 on Windows can use the Cloudera HiveServer2 ODBC drivers ‣which isn’t supported by Oracle ‣but works!

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Using Big Data SQL with OBIEE11g
•Preferred Hadoop access path for customers with Oracle Big Data Appliance is Big Data SQL •Oracle SQL Access to both relational, and Hive/NoSQL data sources •Exadata-type SmartScan against Hadoop datasets
•Response-time equivalent to Impala or Hive on Tez •No issues around HiveQL limitations • Insulates end-users around differencesbetween Oracle and Hive datasets
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
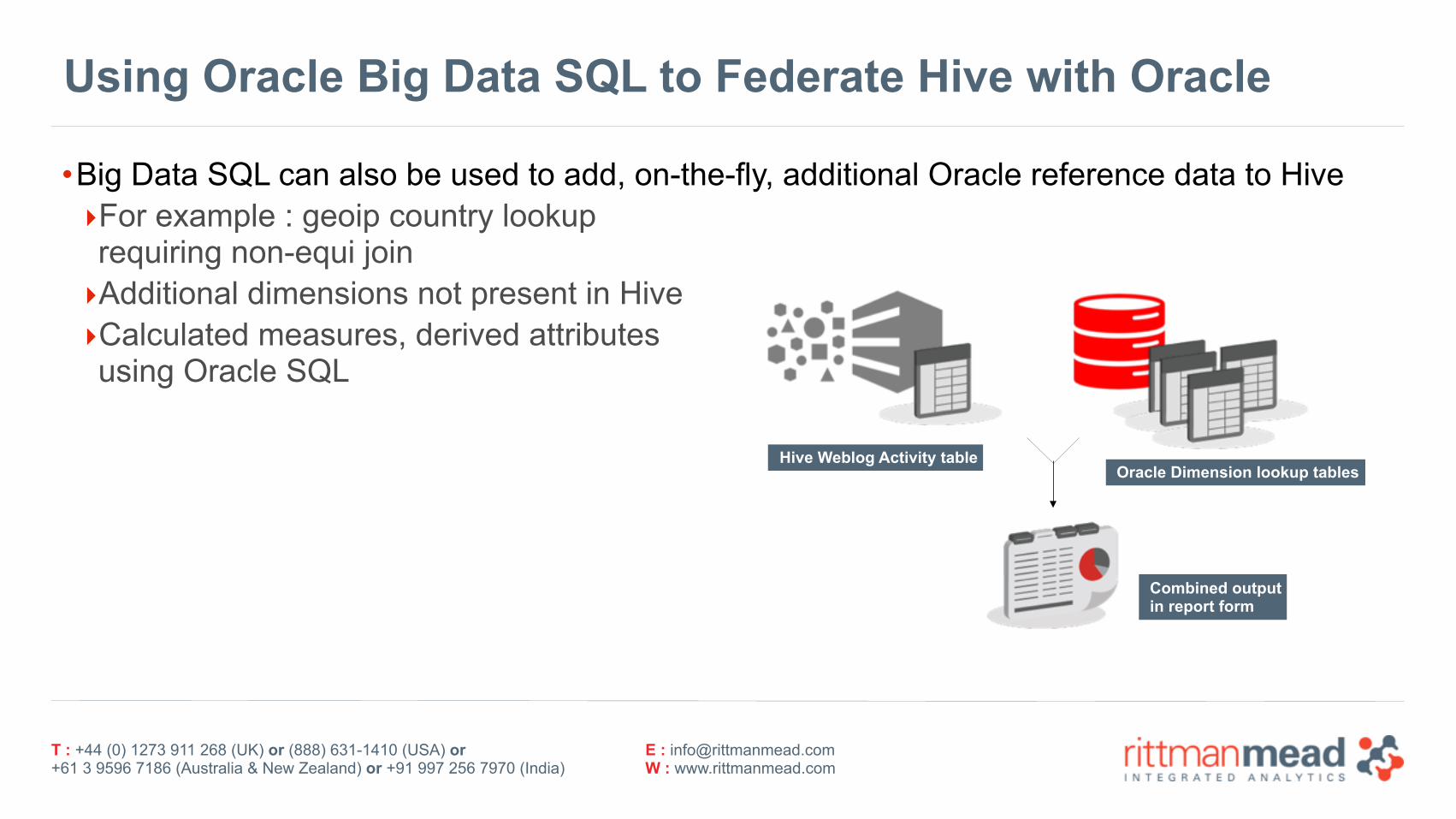
Using Oracle Big Data SQL to Federate Hive with Oracle
•Big Data SQL can also be used to add, on-the-fly, additional Oracle reference data to Hive ‣For example : geoip country lookuprequiring non-equi join ‣Additional dimensions not present in Hive ‣Calculated measures, derived attributesusing Oracle SQL
Hive Weblog Activity tableOracle Dimension lookup tables
Combined output in report form

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Big Data SQL Example : Add Geolookup Data to Hive
•Hive ACCESS_PER_POST_CATEGORIES table contains Host IP addresses • Ideally would like to translate into country, city etc ‣See readership by country ‣Match topics of interest to country, city

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
How GeoIP Geocoding Works
•Uses free Geocoding API and database from Maxmind •Convert IP address to an integer •Find which integer range our IP address sits within •But Hive can’t use BETWEEN in a join…
•Solution : Expose ACCESS_PER_POST_CATEGORIES using Big Data SQL, then join
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
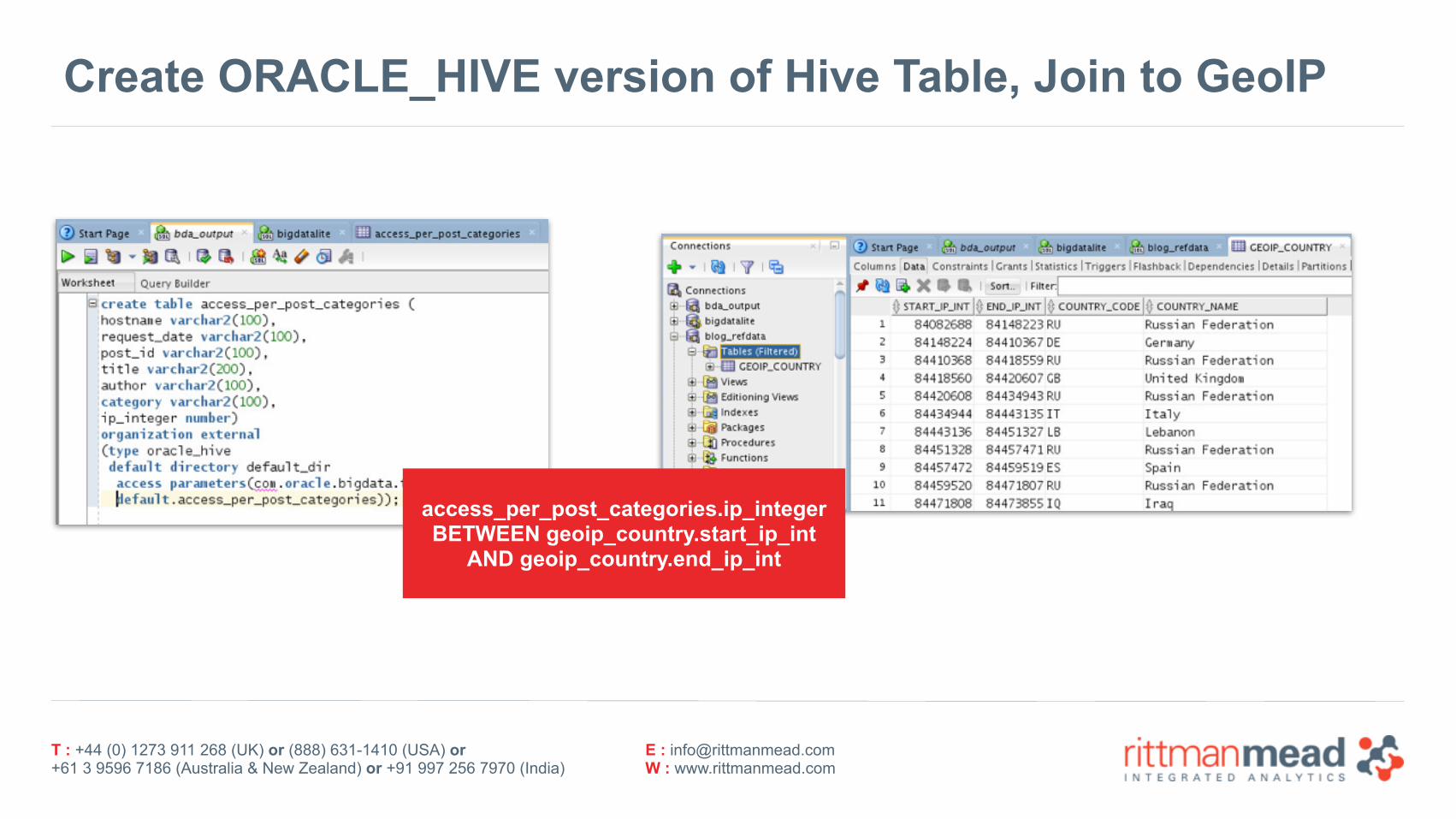
Create ORACLE_HIVE version of Hive Table, Join to GeoIP
access_per_post_categories.ip_integerBETWEEN geoip_country.start_ip_int
AND geoip_country.end_ip_int
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
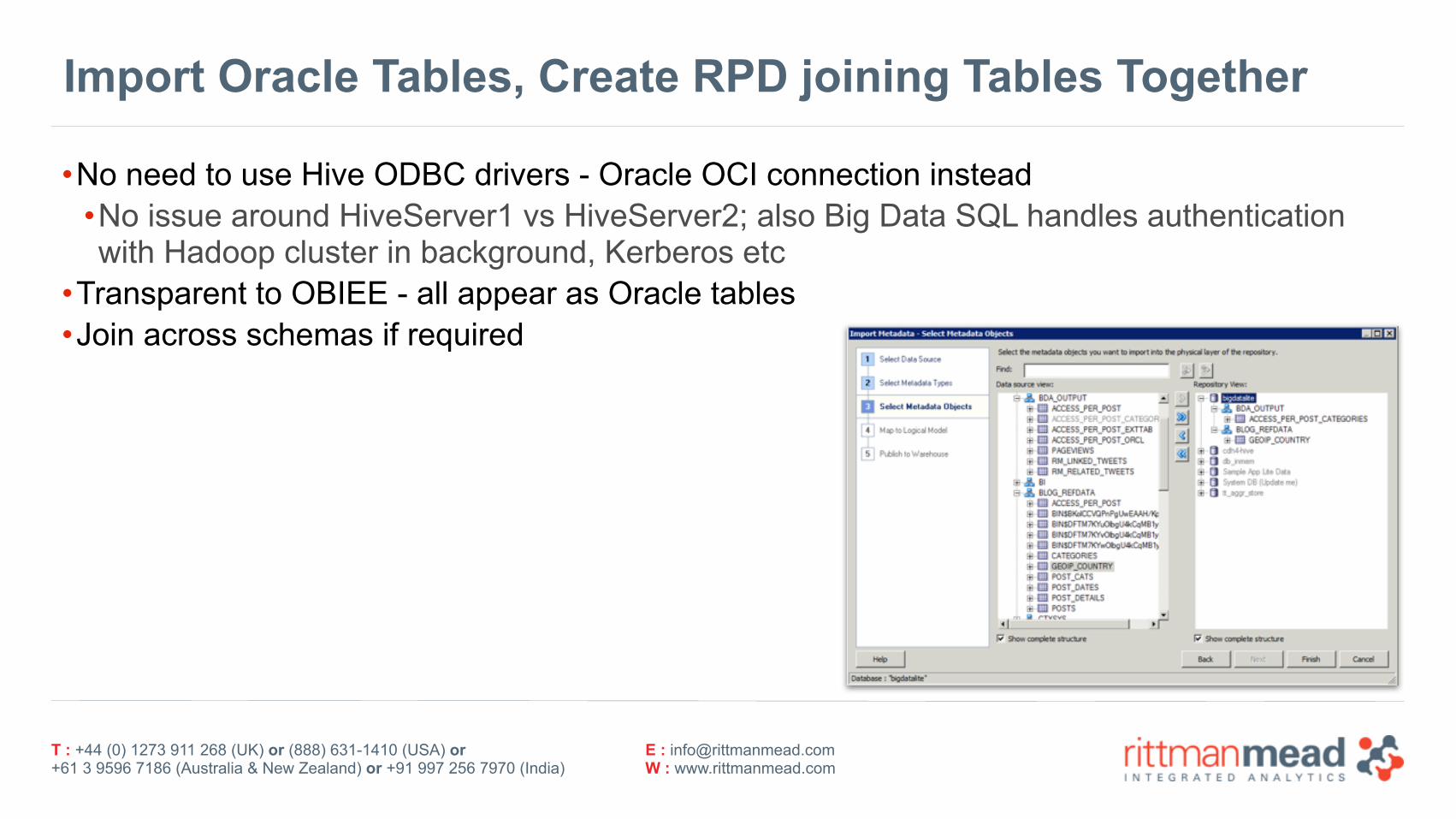
Import Oracle Tables, Create RPD joining Tables Together
•No need to use Hive ODBC drivers - Oracle OCI connection instead •No issue around HiveServer1 vs HiveServer2; also Big Data SQL handles authenticationwith Hadoop cluster in background, Kerberos etc
•Transparent to OBIEE - all appear as Oracle tables •Join across schemas if required

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Create Physical Data Model from Imported Table Metadata
•Join ORACLE_HIVE external table containing log data, to reference tables from Oracle DB

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Create Business Model and Presentation Layers
•Map incoming physical tables into a star schema •Add aggregation method for fact measures •Add logical keys for logical dimension tables •Aggregate (Count) on page ID fact column •Remove columns from fact table that aren’t measures

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Create Initial Analyses Against Combined Dataset
•Create analyses usingfull SQL features
•Access to Oracle RDBMSAdvanced Analytics functionsthrough EVALUATE,EVALUATE_AGGR etc
•Big Data SQL SmartScan featureprovides fast, ad-hoc accessto Hive data, avoiding MapReduce

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
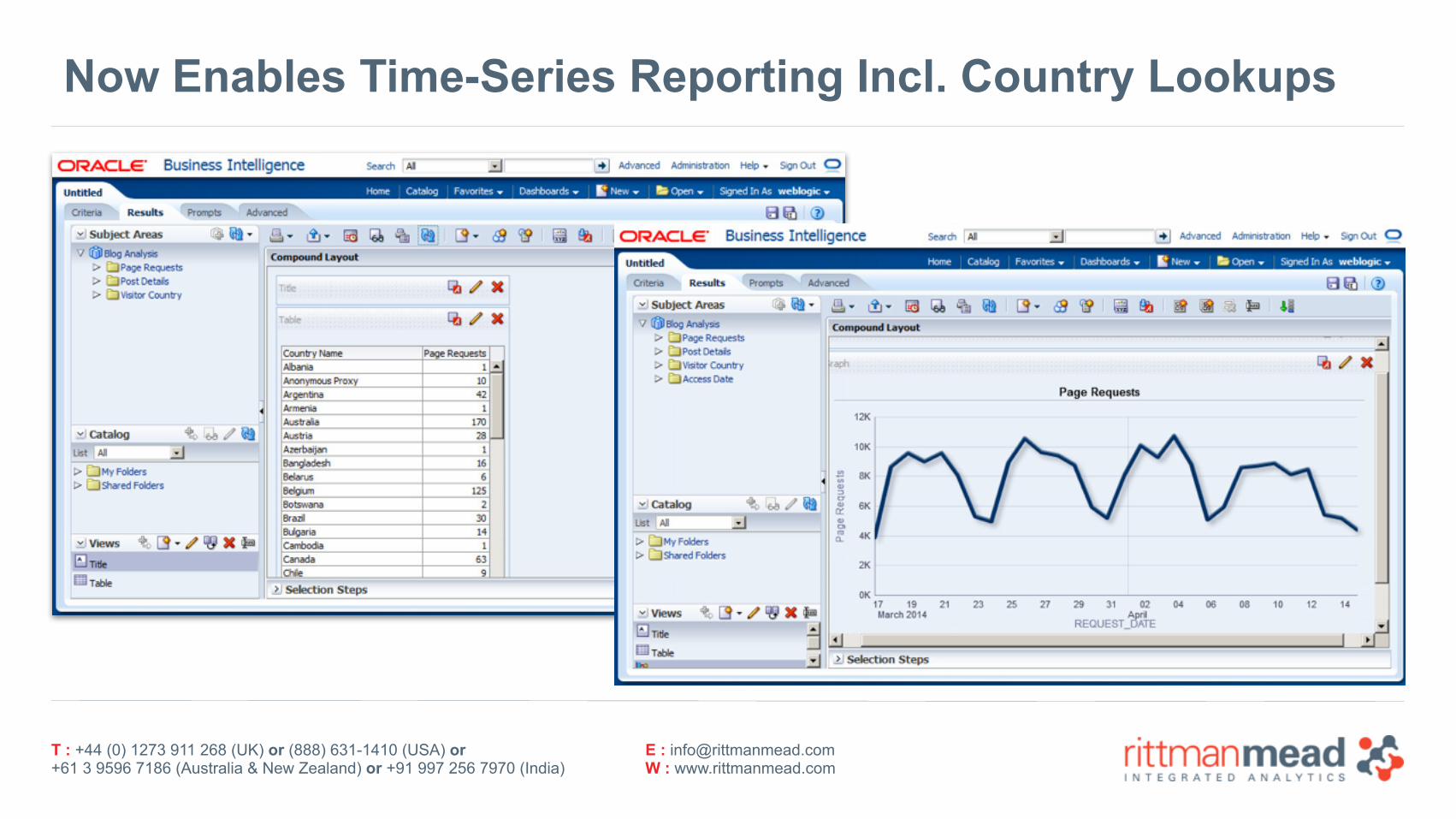
Create Views over Fact Table To Support Time-Series Analysis
•Time field comes in from Hive as string (date and time, plus timezone) •Create view over base ORACLE_HIVE external table to break-out date, time etc • Import time dimension table from Oracle to support date/time analysis, forward forecasting
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Now Enables Time-Series Reporting Incl. Country Lookups

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Use Exalytics In-Memory Aggregate Cache if Required
• If further query acceleration is required, Exalytics In-Memory Cache can be used •Enabled through Summary Advisor, caches commonly-used aggregates in in-memory cache •Options for TimesTen or Oracle Database 12c In-Memory Option •Returns aggregated data “at the speed of thought”

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Step 4 Enabling for Data Discovery

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Enable Incoming Site Activity Data for Data Discovery
•Another use-case for Hadoop data is “data discovery” ‣Load data into the data reservoir ‣Catalog and understand separate datasets ‣Enrich data using graphical tools ‣Join separate datasets together ‣Present textual data alongside measuresand key attributes ‣Explore and analyse using faceted search
2 Combine with site content, semantics, text enrichment Catalog and explore using Oracle Big Data Discovery
Why is some content more popular? Does sentiment affect viewership? What content is popular, where?

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Oracle Big Data Discovery
• “The Visual Face of Hadoop” - cataloging, analysis and discovery for the data reservoir •Runs on Cloudera CDH5.3+ (Hortonworks support coming soon) •Combines Endeca Server + Studio technology with Hadoop-native (Spark) transformations
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
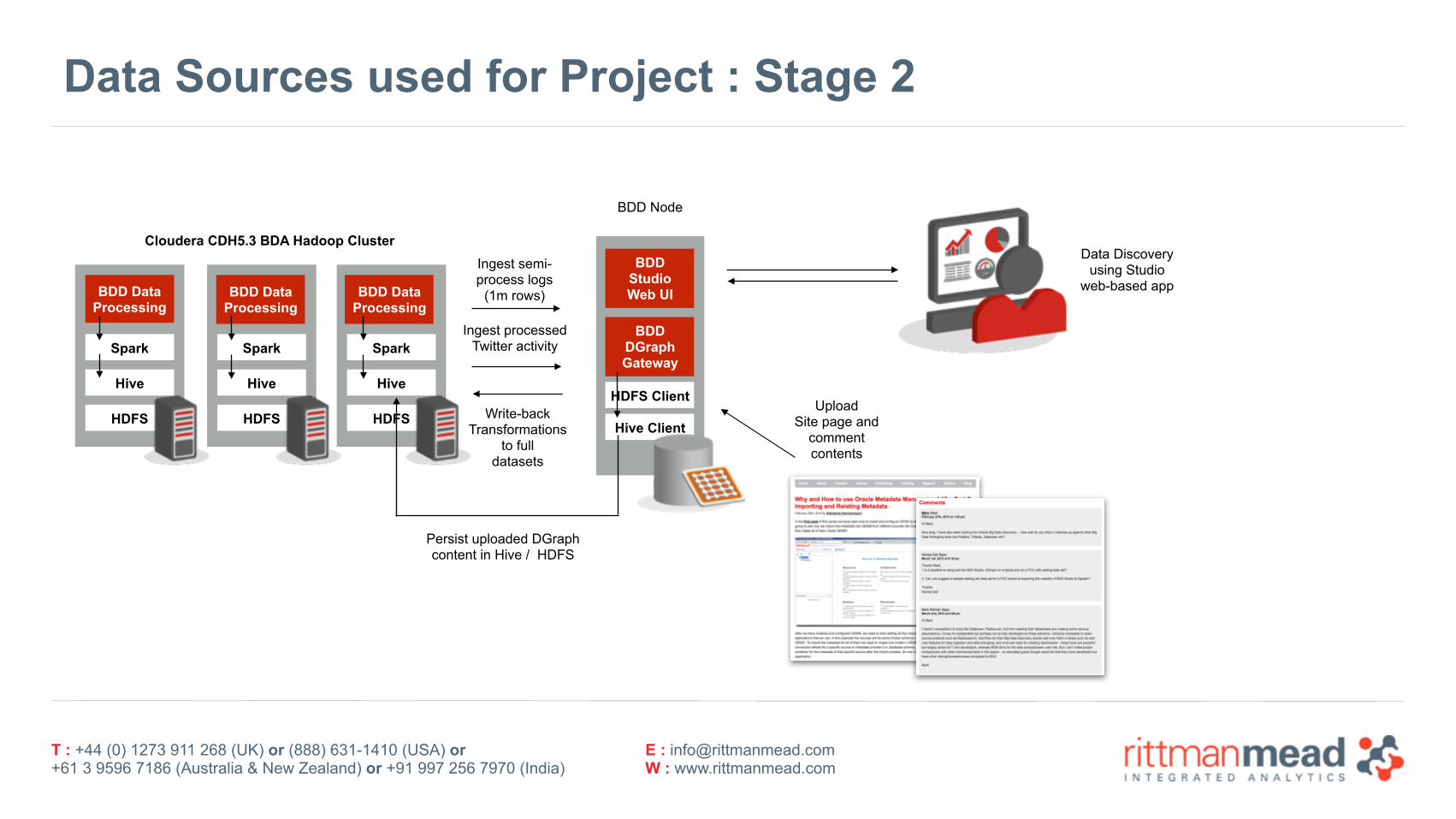
Data Sources used for Project : Stage 2
Spark
Hive
HDFS
Spark
Hive
HDFS
Spark
Hive
HDFS
Cloudera CDH5.3 BDA Hadoop Cluster
Hive Client
HDFS Client
BDD DGraphGateway
Hive Client
BDD StudioWeb UI
BDD Node
BDD Data Processing
BDD Data Processing
BDD Data Processing
Ingest semi-process logs
(1m rows)
Ingest processedTwitter activity
Write-backTransformations
to full datasets
UploadSite page and
comment contents
Persist uploaded DGraphcontent in Hive / HDFS
Data Discovery using Studio
web-based app
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
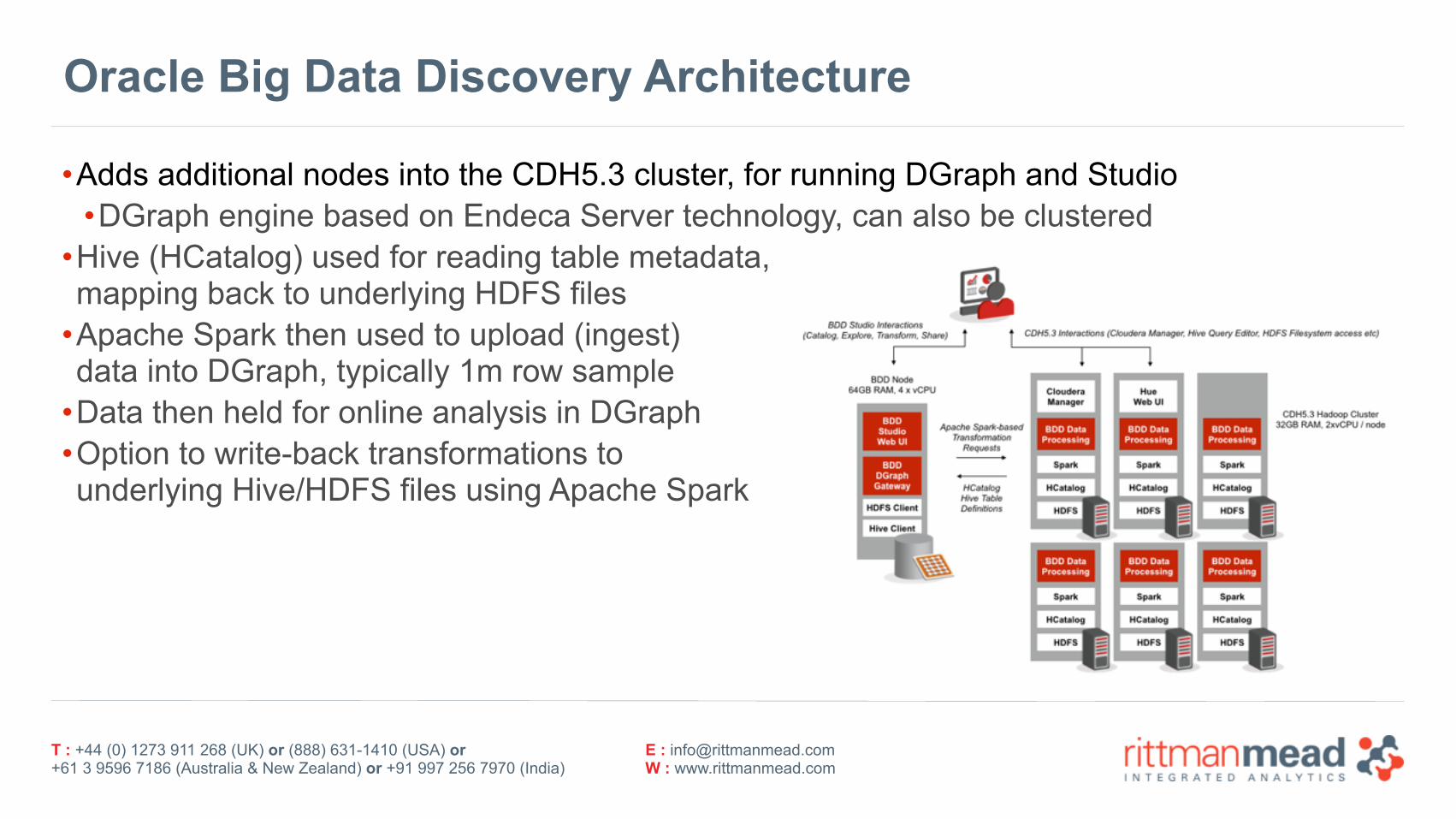
Oracle Big Data Discovery Architecture
•Adds additional nodes into the CDH5.3 cluster, for running DGraph and Studio •DGraph engine based on Endeca Server technology, can also be clustered
•Hive (HCatalog) used for reading table metadata,mapping back to underlying HDFS files
•Apache Spark then used to upload (ingest)data into DGraph, typically 1m row sample
•Data then held for online analysis in DGraph •Option to write-back transformations tounderlying Hive/HDFS files using Apache Spark
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
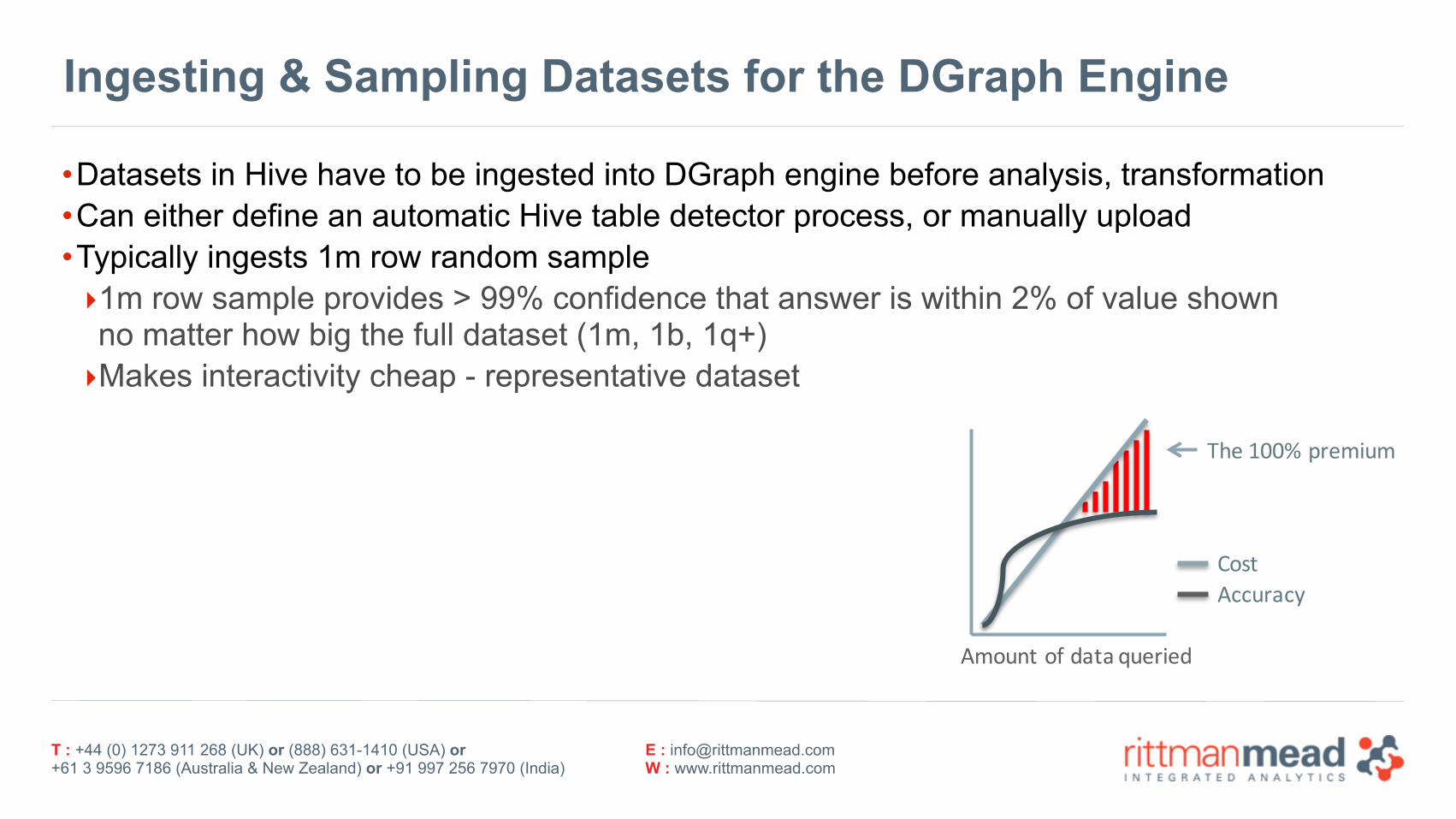
Ingesting & Sampling Datasets for the DGraph Engine
•Datasets in Hive have to be ingested into DGraph engine before analysis, transformation •Can either define an automatic Hive table detector process, or manually upload •Typically ingests 1m row random sample ‣1m row sample provides > 99% confidence that answer is within 2% of value shownno matter how big the full dataset (1m, 1b, 1q+) ‣Makes interactivity cheap - representative dataset
Amount'of'data'queried
The'100%'premium
CostAccuracy

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Ingesting Site Activity and Tweet Data into DGraph
•Two output datasets from ODI process have to be ingested into DGraph engine •Upload triggered by manual call to BDD Data Processing CLI ‣Runs Oozie job in the background to profile,enrich and then ingest data into DGraph
[oracle@bddnode1 ~]$ cd /home/oracle/Middleware/BDD1.0/dataprocessing/edp_cli [oracle@bddnode1 edp_cli]$ ./data_processing_CLI -t pageviews [oracle@bddnode1 edp_cli]$ ./data_processing_CLI -t rm_linked_tweets
Hive
Apache Spark
pageviews X rows
pageviews >1m rows
Profiling pageviews >1m rows
Enrichment pageviews >1m rows
BDD
pageviews >1m rows
{ "@class" : "com.oracle.endeca.pdi.client.config.workflow. ProvisionDataSetFromHiveConfig", "hiveTableName" : "rm_linked_tweets", "hiveDatabaseName" : "default", "newCollectionName" : “edp_cli_edp_a5dbdb38-b065…”, "runEnrichment" : true, "maxRecordsForNewDataSet" : 1000000, "languageOverride" : "unknown" }
1
23
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
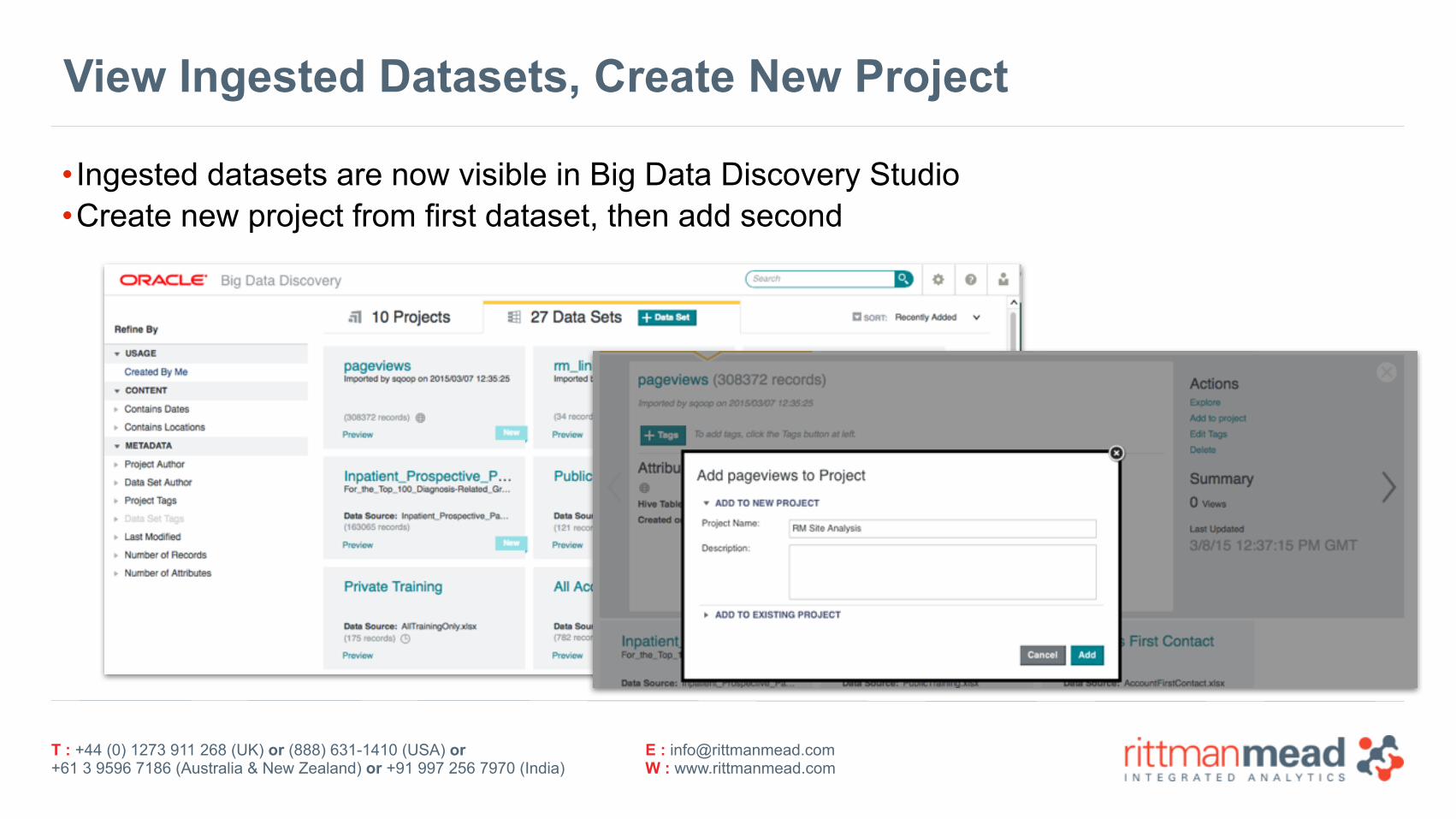
View Ingested Datasets, Create New Project
• Ingested datasets are now visible in Big Data Discovery Studio •Create new project from first dataset, then add second
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
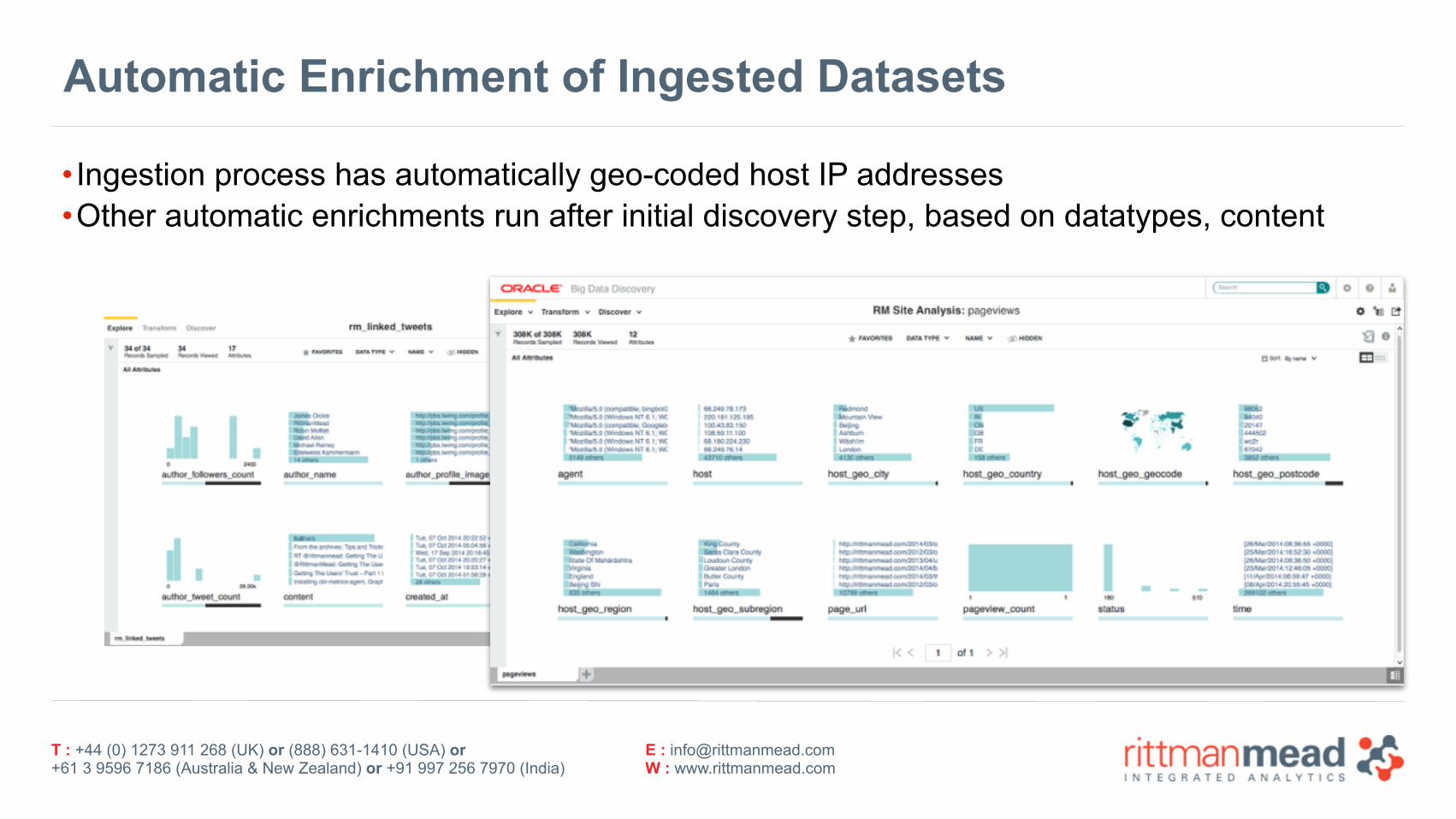
Automatic Enrichment of Ingested Datasets
• Ingestion process has automatically geo-coded host IP addresses •Other automatic enrichments run after initial discovery step, based on datatypes, content
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
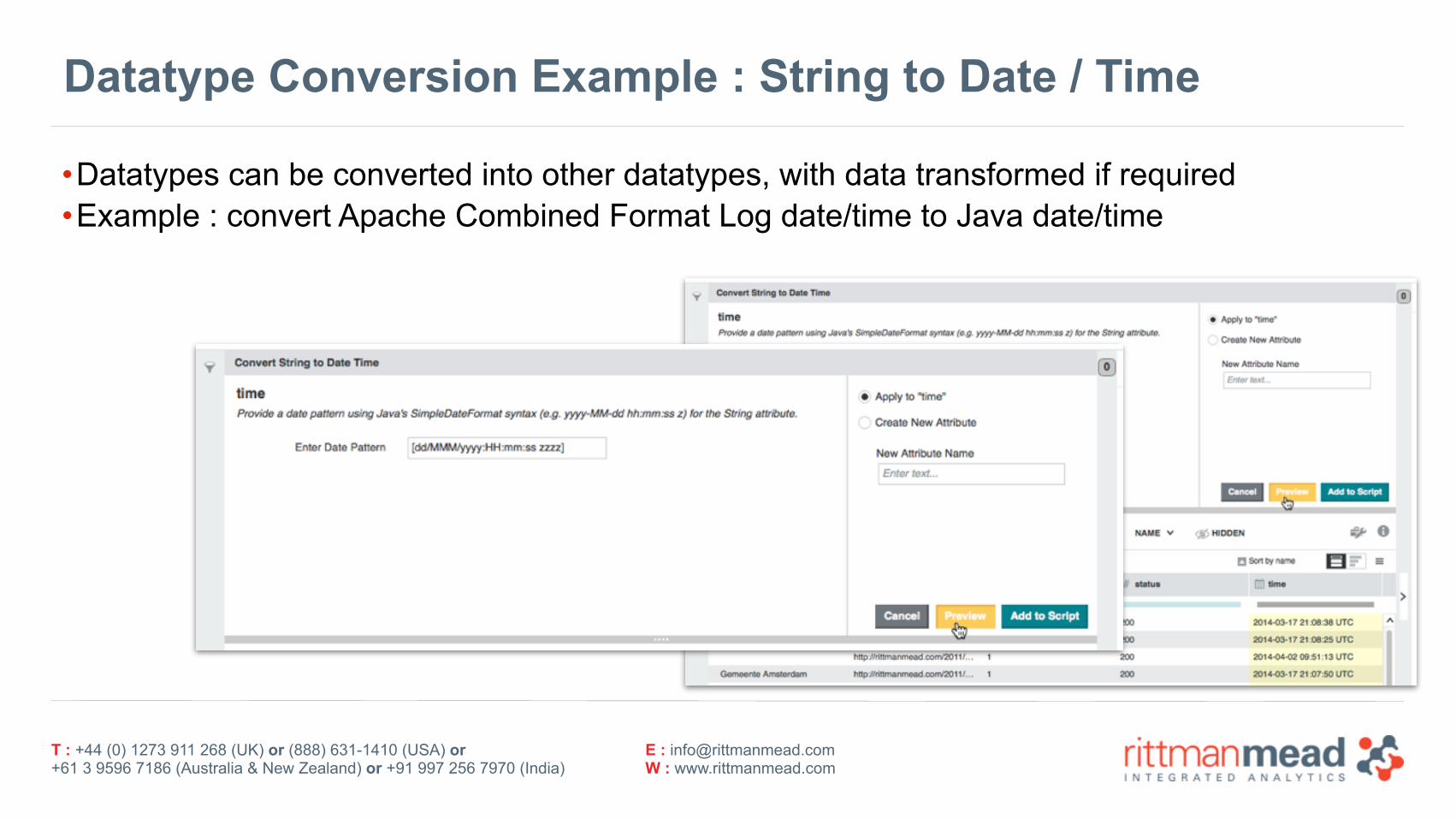
Datatype Conversion Example : String to Date / Time
•Datatypes can be converted into other datatypes, with data transformed if required •Example : convert Apache Combined Format Log date/time to Java date/time
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
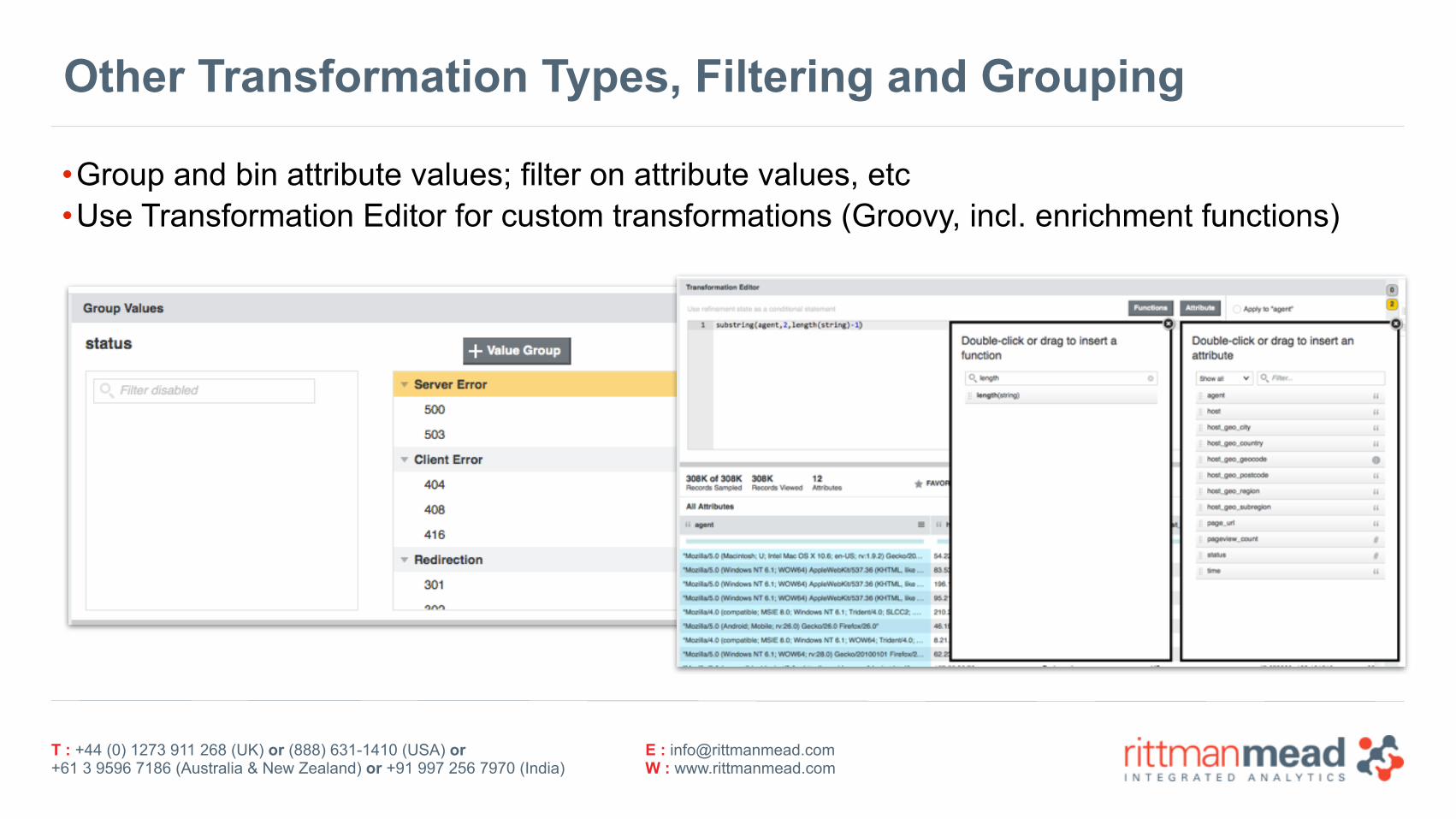
Other Transformation Types, Filtering and Grouping
•Group and bin attribute values; filter on attribute values, etc •Use Transformation Editor for custom transformations (Groovy, incl. enrichment functions)

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Commit Transforms to DGraph, or Create New Hive Table
•Transformation changes have to be committed to DGraph sample of dataset ‣Project transformations kept separate from other project copies of dataset
•Transformations can also be applied to full dataset, using Apache Spark ‣Creates new Hive table of complete dataset

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Upload Additional Datasets
•Users can upload their own datasets into BDD, from MS Excel or CSV file •Uploaded data is first loaded into Hive table, then sampled/ingested as normal
12
3

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Join Datasets On Common Attributes
•Creates left-outer join between primary, and secondary dataset ‣Add metrics (sum of page visits, for example) to activity dataset (e.g. tweets) ‣Join more attributes to main dataset
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
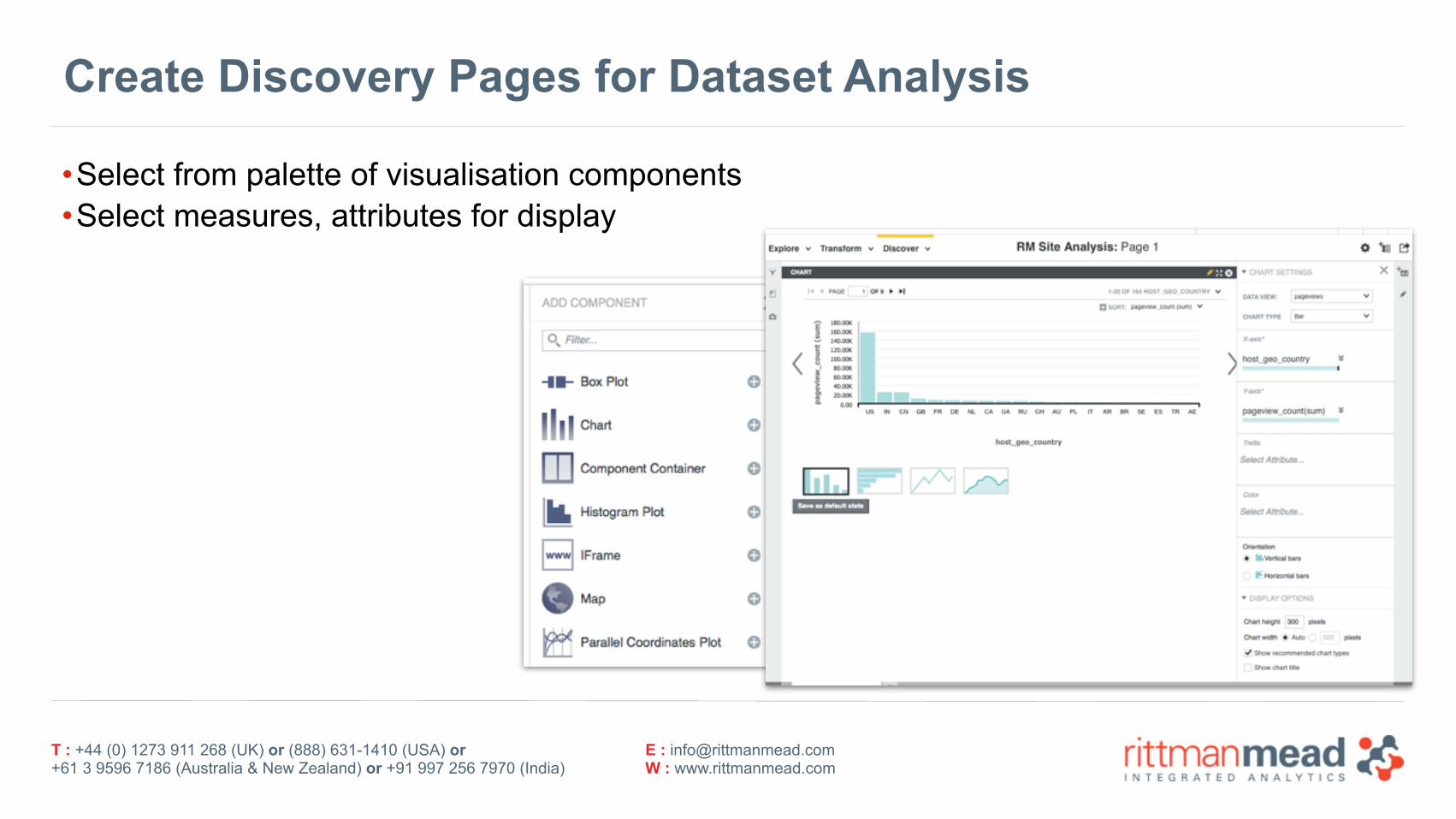
Create Discovery Pages for Dataset Analysis
•Select from palette of visualisation components •Select measures, attributes for display
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
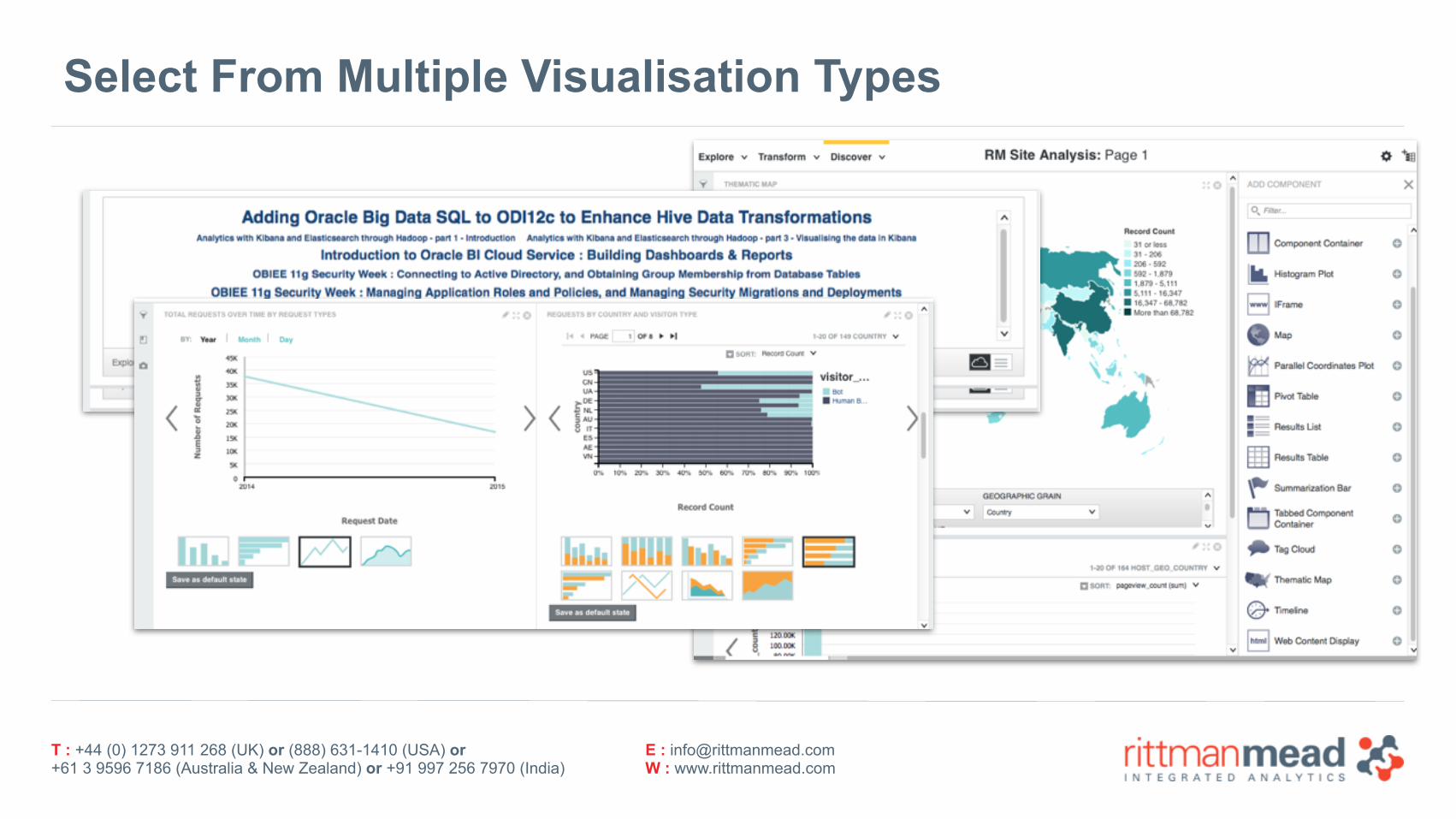
Select From Multiple Visualisation Types
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
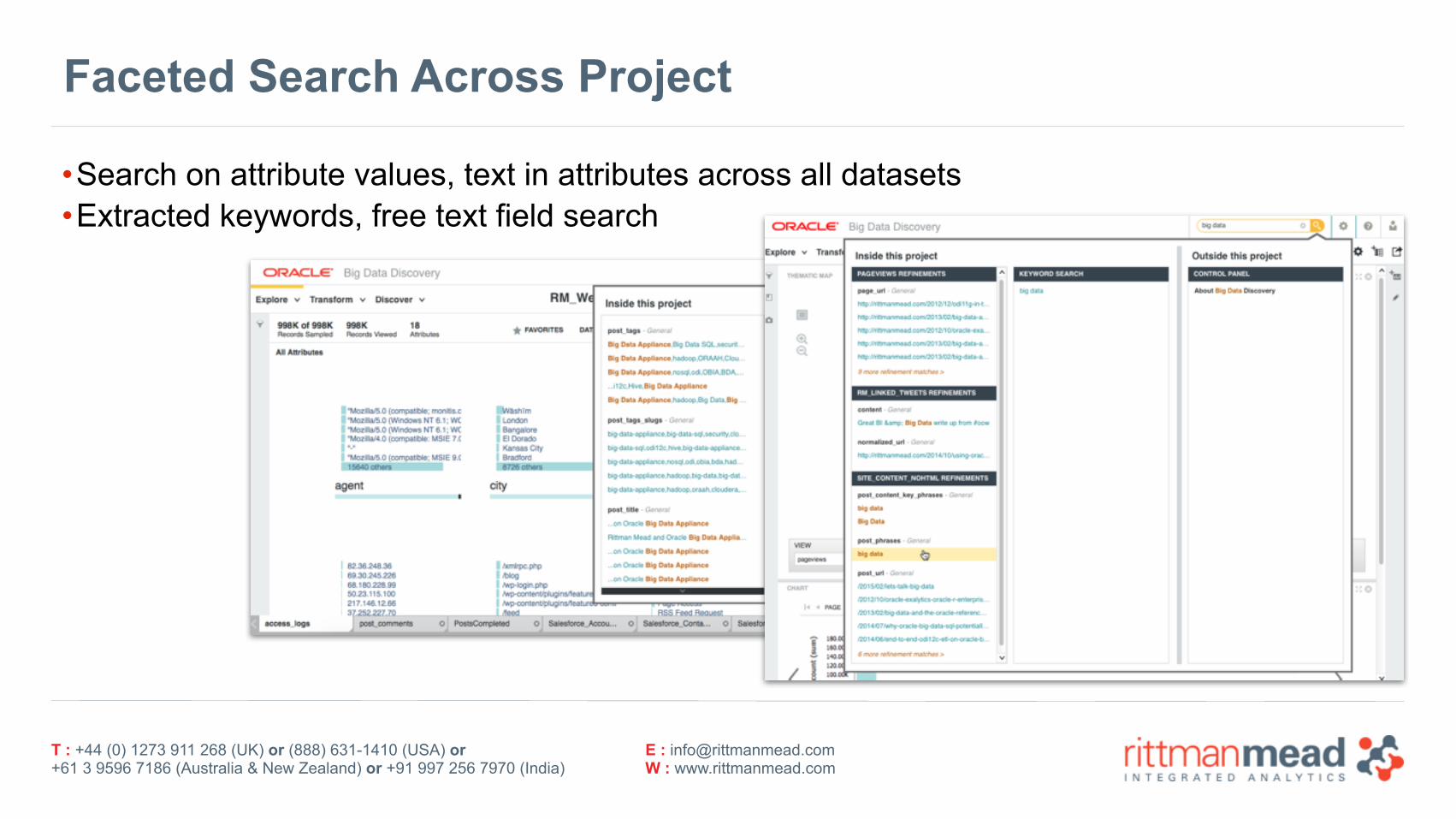
•Search on attribute values, text in attributes across all datasets •Extracted keywords, free text field search
Faceted Search Across Project

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Key BDD Studio Differentiator : Faceted Search Across Hadoop
•BDD Studio dashboards support faceted search across all attributes, refinements •Auto-filter dashboard contents on selected attribute values •Fast analysis and summarisation through Endeca Server technology
“Mark Rittman” selected from Post Authors Results filtered on
selected refinement
1 2

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Key BDD Studio Differentiator : Faceted Search Across Hadoop
•BDD Studio dashboards support faceted search across all attributes, refinements •Auto-filter dashboard contents on selected attribute values - for data discovery •Fast analysis and summarisation through Endeca Server technology
Further refinement on“OBIEE” in post keywords
3Results now filteredon two refinements
4

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Summary
•Oracle Big Data, together with OBIEE, ODI and Oracle Big Data Discovery •Complete end-to-end solution with engineered hardware, and Hadoop-native tooling
1 Combine with Oracle Big Data SQL for structured OBIEE dashboard analysis 2 Combine with site content, semantics, text enrichment
Catalog and explore using Oracle Big Data Discovery
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
Thank You for Attending!
•Thank you for attending this presentation, and more information can be found at http://www.rittmanmead.com
•Contact us at [email protected] or [email protected] •Look out for our book, “Oracle Business Intelligence Developers Guide” out now! •Follow-us on Twitter (@rittmanmead) or Facebook (facebook.com/rittmanmead)

T : +44 (0) 1273 911 268 (UK) or (888) 631-1410 (USA) or +61 3 9596 7186 (Australia & New Zealand) or +91 997 256 7970 (India)
E : [email protected] W : www.rittmanmead.com
End-to-End Hadoop Development using OBIEE, ODI and Oracle Big Data Discovery Mark Rittman, CTO, Rittman Mead March 2015