end-to-end performance: issues and suggestions
TRANSCRIPT

End-to-end performance:issues and suggestions
TERENA 5th NRENs and Grids WorkshopParis, June 2007
Mark Leese

TERENA 5th NRENs & Grids Workshop, June 2007
2
Talk Emphasis
• monALISA = a monitoring tool/framework• DANTE = a network operator• EGEE-II = a Grid• Mark = a pseudo-Grid end user
• I’m not a real user, but I look at the issues from their viewpoint:– Large Hadron Collider in the UK (GridPP)– UK e-Science– OGF
• Aimed at a mixed audience (NRENs and Grid users) so some network/Grid things you will already….Zzzzzzzzzzzz :)

TERENA 5th NRENs & Grids Workshop, June 2007
3
Contents
Just two things:
1. What makes the Grid different to other network users, wrt performance?
2. What are the end-to-end performance (monitoring) issues? Any suggestions?
If the links in the presentation don’t work, they are listed again on the last three slides

1. What makes the Grid differentto other network users, wrt performance?

TERENA 5th NRENs & Grids Workshop, June 2007
5
The Grid
The Grid is all about:• Sharing resources:
– the obvious, e.g. databases– the specialised, e.g. remotely control telescopes– and new ideas, e.g. CPU time– co-allocate resources to a task to remove the
limitations of the individual resources– most basic analogy: you can move house faster if you
have two vans• Sharing resources which are geographically
distributed• Sharing resources efficiently
– optimisation: selecting the “best” resources for the job

TERENA 5th NRENs & Grids Workshop, June 2007
6
The GridGrid App: Process TBsof Particle Physics data from CERN detectors
Grid App: Analyse the human genome
Grid App: Obtain radio astronomy images from
remote telescopes
Middleware: sits between the OS of the resources (below) and the
applications that run on the Grid
Storage Element
Chemical DB
Compute Elements Image courtesy
of NRAO/AUI
Network(s)

TERENA 5th NRENs & Grids Workshop, June 2007
7
The GridGrid App: Process TBsof Particle Physics data from CERN detectors
Grid App: Analyse the human genome
Grid App: Obtain radio astronomy images from
remote telescopes
Middleware: sits between the OS of the resources (below) and the
applications that run on the Grid
Storage Element
Chemical DB
Compute Elements Image courtesy
of NRAO/AUI
• Get apps running on the “right” resources (wherever they are)• Make disparate compute resources into a coherent whole
Network(s)

TERENA 5th NRENs & Grids Workshop, June 2007
8
Optimisation
It’s a little like the checkout counters in a supermarket:• There is a line of 10 checkouts to which you can take your big
shopping basket• Two checkouts you cannot use. They are for people with “five items
or less” – caisse express• Another two checkouts cannot be used. They are reserved for
something else (the staff’s lunch break)• Six left: how big is each queue and how long will it take each person
to exit the queue (how many items in each basket)?
If you choose wrong, you get delayed!You miss the train, you get home late,
your partner has given your dinner to the dog
• To take the analogy to extremes: hopefully your basket does not have a broken wheel :)

TERENA 5th NRENs & Grids Workshop, June 2007
9
Scheduling
• Grid job = the basic unit of work• SEs provide storage resources and access to mass storage systems• CEs provide processing power, e.g. cluster of Worker Nodes (PC farm)
• Scheduling = deciding when a job will run, and with which resources
• Typically there will be many CEs capable of running a job• If a CE already has lots of jobs queued, you would like to use another
• File replication = proven technique for improving data access• Distribute multiple copies of the same file across a Grid• Increases number of CEs with good network connectivity to the data• Extreme example: Pisa Roma or Pisa Fermilab?• So, typically there may also be several SEs holding the required data

TERENA 5th NRENs & Grids Workshop, June 2007
10
Network Aware Scheduling (i)
• So we have a set of CEs {a,b,c,…} and SEs {x,y,z,…} capable of running a job
• We want a node from each list such that the job will complete the fastest
• Take account of:– capability of CEs– size and number of jobs already waiting (queued) at CEs– performance of network link for each CE-SE combination
• Further complicated by the compute/data intensity of the job:– computationally intensive job: lots of maths– data intensive job: lots and lots and lots of data– do we pull the data to the job or push the job to the data?

TERENA 5th NRENs & Grids Workshop, June 2007
11
Network Aware Scheduling (ii)
• In Utopia we would know about the current state of the network, and any future reserved bandwidth
• In reality we could use monitored network performance to make an estimate
• It’s not perfect, but patterns (diurnal variation, chronic poor performance…) can be identified
• The following slides show iperf tests between dedicated test nodes at LHC sites in the UK (GridPP’s gridmon infrastructure)

TERENA 5th NRENs & Grids Workshop, June 2007
12
Network Aware Scheduling (iii.a)
• Transfer at 00:00, yes. Transfer at 12:00, no. There’s a big difference between 500 and 200 Mbps for data intensive jobs!

TERENA 5th NRENs & Grids Workshop, June 2007
13
Network Aware Scheduling (iii.b)
• RAL Tier-2 Tier-1: local transfers are likely the best performers
TERENA 5th NRENs & Grids Workshop, June 2007
14
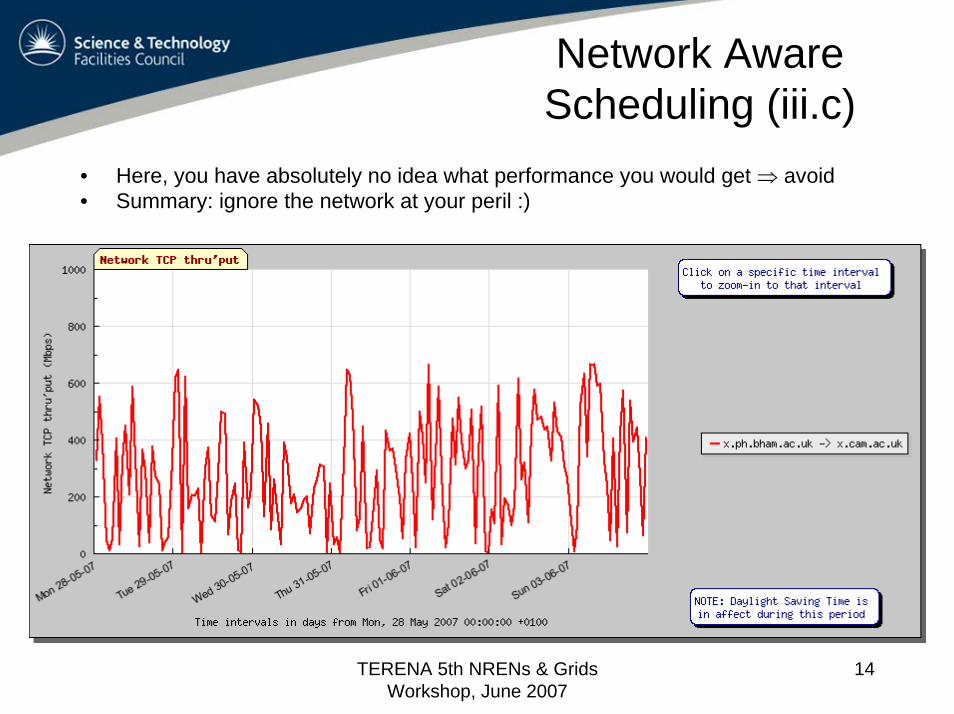
Network Aware Scheduling (iii.c)
• Here, you have absolutely no idea what performance you would get ⇒ avoid• Summary: ignore the network at your peril :)

TERENA 5th NRENs & Grids Workshop, June 2007
15
Network Aware Scheduling (iv)
• Two good papers to read:1. B. Volckaert, P. Thysebaert, M. De Leenheer, F. De Turck,
B. Dhoedt, P. DemeesterNetwork Aware Scheduling in Grids
2. Richard McClatchey, Ashiq Anjum, Heinz Stockinger, Arshad Ali, Ian Willers, Michael ThomasData Intensive and Network Aware (DIANA) Grid Scheduling
• We don’t consider potential uses in more detail (job placement, replica selection) because we don’t know if it will happen!

TERENA 5th NRENs & Grids Workshop, June 2007
16
Network Aware Scheduling (v)
• There are some –ve feelings:– “The network is not a problem. Over-provisioning will always keep us ahead. Either that
or fibre and GigE everywhere”– Report of the International Grid Performance Workshop 2005 concluded that
"Performance simply is not on the critical path for many application projects. Applications that struggle to get code to execute correctly simply do not consider whether they are using resources efficiently or achieving good performance“
– Personal experience suggests that there is so much to think about elsewhere, that the network is often the last thing to be considered
• Right now, Grid apps rely on the network being good, with no real checks
• And by way of real life indications…
• EDG WP7 developed “network cost function”:– Returned cost of variable size file transfers between source and dest Grid elements– Based on periodic (WP7) iperf measurements– Used by WP2 Replica Optimization Service:
• job placement: where to start a job so that it is as close as possible to the required data• replica selection: from where to fetch the closest replica once a job had started
• EDG was not a production Grid, and the work was not taken forward

TERENA 5th NRENs & Grids Workshop, June 2007
17
Network Aware Scheduling (vi)
• In EGEE…• Tommaso Coviello and Tiziana Ferrrari proposed to use network
performance data from EGEE-JRA4
CompletionTimeCEi = {JobExecutionTime+ max(InputDataTransferTime,QueueTime)}
• estimate file transfer times based on thruput• reject paths exhibiting packet loss• SEs selection refined based on SEs using low congestion links (jitter
the suggested test)
• Some prototype work, but not taken forward• QueueTime found to be unreliable• Data for 100 paths required within 0.2 seconds of receiving request
– Grid Information Service was not ready to hold the data– a problem for JRA4’s Web Service interface (WS, ∴ accessible but slow)

TERENA 5th NRENs & Grids Workshop, June 2007
18
Network Aware Scheduling (vii)
• In WLCG/EGEE (if I understand correctly)…
• The “close SE” approach is applied:– Each CE must have a “close” SE: the node with the “best” access for data
retrieval from that CE– These relationships are statically defined in the Grid’s Information Service,
which provides information about the Grid resources and their status
$ lcg-infosites --vo dteam closeSE
Name of the CE: g02.phy.bg.ac.yu:2119/blah-pbs-dteamse.phy.bg.ac.yu
Name of the CE: fangorn.man.poznan.pl:2119/jobmanager-lcgpbs-dteam
se1.egee.man.poznan.plse2.egee.man.poznan.pl

TERENA 5th NRENs & Grids Workshop, June 2007
19
Network Aware Scheduling (viii)
• To run a job the user submits a job description in JDL (Job Description Language) format
• It defines which executable to run, any parameters, input data (Grid files) etc.
• A match-making process then takes places to identify a CE to execute the job1. Identify all CEs which:
1. can run the job, i.e. match the user’s requirements (JDL)2. are “close” to an SE holding the required input Grid files
2. select CE with the highest rank– by default, rank = estimation of the time interval between the being job submitted and
execution actually beginning– a function of the number of running and queued jobs at each CE
• See gLite User Guide for more info
• As already stated, the presence of replicas of data increases the number of CEs“close” to the data which can potentially execute the job
• But decisions are still made on the static declaration of “close” SEs
• Users are able to re-write the site selection code themselves

TERENA 5th NRENs & Grids Workshop, June 2007
20
Difference 1
So, difference 1…The Grid may use network performance
data to improve its decision making

TERENA 5th NRENs & Grids Workshop, June 2007
21
Difference 2
Difference 2…The Grid will exercise the network

TERENA 5th NRENs & Grids Workshop, June 2007
22
Qualitative View
• By it’s very nature…– sharing lots of resources to build powerful “systems”…– to process complex, large data sets…– in geographically distributed teams– some in real-time, e.g. visualisation– so far there has been lots of “embarrassingly parallel” problems
(completely independent tasks which can be executed in parallel)but what about tasks requiring inter-processor communication (MPI, Message Passing Interface)?
• …= a lot of data moving across the network:– high bandwidth– low-latency– stable and guaranteed transmission rates

TERENA 5th NRENs & Grids Workshop, June 2007
23
Quantitative View (i)
• The Large Hadron Collideris a collection of four experiments based at CERN (ALICE, ATLAS, CMS and LHCb) that will monitor the collision of accelerated particles
• ≈ 15 Petabytes of data generated every year
• Around 100,000 standard CPUs required to process
• GridPP (UK) is contributing the equivalent of 10,000 PCs

TERENA 5th NRENs & Grids Workshop, June 2007
24
Quantitative View (ii)
• My understanding is that the LHC when operational, will be pushing out 700 Mbytes/s (≈ 5 Gbps) from the Tier-0 to each Tier-1
• 11 Tier-1s, linked to CERN with 10 Gbps Optical Private Network• So no problems there
• Additional variable flows ≤ 4 Gbps are expected between the Tier-1s
• What about Tier-1s to Tier-2s?• > 150 Tier-2s, 18 in UK• Tier-1s and Tier-2s currently linked by standard research networks• Are you going to commission dedicated fibres or lambdas for each?

TERENA 5th NRENs & Grids Workshop, June 2007
25
Quantitative View (iii)

TERENA 5th NRENs & Grids Workshop, June 2007
26
Rolls Royce Networks
• Lots of projects working on adding extra intelligence into the network, and/or interfacing Grid applications with network control plane for auto-provisioning of dedicated bandwidth:
– Cisco’s Network Based On-demand/Grid System (NBGS)– The NAREGI project– Enlightened Computing– http://www.g-lambda.net/
• These are still development projects• Can fibre/lambdas be provided for all that need it?• Even if £$€ provided, temptation to spend on CPU
power?• May still fall victim to end-system and “last mile”
(e.g. firewall) problems

TERENA 5th NRENs & Grids Workshop, June 2007
27
Is the Grid a lot of Hype?
• It’s good to be skeptical about things. Every four years people say England will win the World Cup/Coupe du Monde ;-)
• The Grid is ambitious…• …but so was the “World Wide Wait”• Now everyone loves the Web, and it has become important to
people:– Internet banking, online shopping (flights, holidays, music,
supermarket…), e-Government etc. etc.– MySpace, Facebook, YouTube
• The Web also drove investment in the Net infrastructure and as a result it can now support video conferencing, VoIP etc.

TERENA 5th NRENs & Grids Workshop, June 2007
28
Summary of Differences
1. Network Operations: We can safely say that greater demands will be placed on the network:– massive datasets, 1000’s of networked
“resources”– geographically distributed: Long Fat Networks– high bandwidth, high availability, low latency– networks will need to be debugged for efficiency
2. Network Intelligence: The Grid may want to consume network performance data to improve its decision making

2. What are the end-to-endperformance (monitoring) issues?

TERENA 5th NRENs & Grids Workshop, June 2007
30
The Overall Issue
• We have seen that the Grid could use network performance data for decision making…
• …but we don’t know whether it will• As a result, we concentrate on debugging the
network for Grid users

TERENA 5th NRENs & Grids Workshop, June 2007
31
End-to-End?
• When I say “end-to-end” I mean PC-PC, not PoP to PoP or similar
• Core and Metro Area are normally fine• Most problems are in the last mile:• End-system:
– NIC– disc– TCP config– poor cabling– the application itself (e.g. older versions of scp)– I could go on for ever (“no, please don’t!”)
• Site firewall• Off-site connections

TERENA 5th NRENs & Grids Workshop, June 2007
32
So Many Issues
• Beyond the basics of which tests to run, and how to control/schedule them, there are too many end-to-end performance issues to consider when monitoring. Here, I mention a few and make some suggestions.
• TCP performance• Parallel TCP streams• Different data transfer protocols (e.g. GridFTP vrs HTTP)• New protocols, e.g. DDCP• TCP-IP is ubiquitous so we stick with it - we can’t necessarily wait for
new protocols and network architectures• Measurement types
– active vrs passive– capture logs of real GridFTP transfers…is there Grid Information Service
support?– can we monitor Grid workflows in real-time?
• Too many test paths. Can we plug in to VO data to test only the required paths

TERENA 5th NRENs & Grids Workshop, June 2007
33
Over-Provisioning
Q: Okay, so why don’t we just throw some more bandwidth at the problem? Upgrade the links.
A: For want of a more interesting term to make sure you’re still paying attention, this is what I call the Heroin Effect…
– You start off with a little, but that’s not really doing it for you; it’s not solving the problem. So you keep increasing the dose, yet it’s never as good as you thought it would be.
– By analogy you keep buying more and more bandwidth to take you to new highs but it's never quite as good as you thought it would be
– Simple over-provisioning is not sufficient– Doesn’t address the key issue of end-to-end performance
• Network backbone in most cases is genuinely not the source of the problem• Last mile (campus network end-user system your app) often cause of the
problem: firewall, wiring, hard disc, application and many more potential culprits
• Also, If simple over-provisioning was a total solution, there would not be so much other work going on, e.g. protocol research (high speed TCPs)

TERENA 5th NRENs & Grids Workshop, June 2007
34
Lets Puts Fibre Everywhere (1)
• Fibre is cheaper than it was, but for large deployments, it’s still expensive
• We can see the benefits of fibre with the UKLight infrastructure and the ESLEA exploitation project, but it still doesn’t address the end-to-end issue. Take a real-life ESLEA example (thanks to ESLEA for the figures)…
• The UK wanted to transfer data from FermiLab (Chicago) to UCL for analysis by physicists, before returning the results
• datasets currently 1-50TB• 50TB would take > 6 mths on production net, or one week at
700Mbps• So a 1Gbps circuit-switched light path was provisioned• Result = disc-to-disc transfers @ 250Mbps, just 1/4 of
theoretical max• Tests revealed a problem at an end site

TERENA 5th NRENs & Grids Workshop, June 2007
35
Lets Puts Fibre Everywhere (2)
• UCL: RealityGrid, for modelling complex condensed matter systems: computational steering, visualisation.
• Test node: 2 * 1.8GHz Athlon, 4 GB, GigE, CentOS
• DL: HPCx super computer• Test node: 3 GHz P4, 2
GB, GigE, Scientific Linux
• RTT is always 9mS• TCP bandwidth is, errr....

TERENA 5th NRENs & Grids Workshop, June 2007
36
Mark’s Tips
• There are lots of tools, frameworks, infrastructures out there.• Massive list at http://www.slac.stanford.edu/xorg/nmtf/nmtf-tools.html• Pick something that works for you - it’s a balance of:
– ongoing administration– deployment effort (e.g. persuading remote sites to install tools and allow
you to run tests)– how intrusive the tests are
• Start your investigations in the last mile• Do put real data over the network
– you can send 1 ping a second forever and see 10-8 loss– you then run an iperf test and the performance is terrible
• Keep historic data: things change– you will want to look back, and you will want points of reference
• When you see a problem, follow it up and get information– Not only is the problem fixed, but you get to demonstrate why this is useful
which helps with deployment, support, growing user base…• Remember the social aspects - persistent but patient :)

TERENA 5th NRENs & Grids Workshop, June 2007
37
Suggestions: Tools and Techniques
• Start with the local host:– As you would expect:
• uname• netstat• ifconfig (watch error counters etc.)
– LISA (Localhost Information Service Agent)• a component of MonALISA• almost complete system monitoring (load, CPU, memory, disk, disk I/O,
paging, processes, network traffic and connectivity...)– Check everything:
• TCP configuration• machine load• disc (sas, sata, nasty old ide?)
– If TCP is the problem, what UDP rates can you achieve?

TERENA 5th NRENs & Grids Workshop, June 2007
38
Suggestions: Tools and Techniques
• ping still useful but need to send much faster than 1 per second, and for a long time….10-8 loss
– “back of envelope” calculation: on Saturday I ran a 10 sec iperf test which transferred 624MB in 480,000 packets. So ≈ 1.3KB per packet
– 1 loss every 100,000,000 packets ≈ 128GB transferred before a loss causes your transfer rate to drop
• can use Synack tool (sparingly) if icmp is blocked
• traceroute and reverse traceroutes: regularly measuring the routes to your most important collaborators is very useful
• dedicated monitoring boxes are useful here because they may be allowed (firewalls etc.) for icmp

TERENA 5th NRENs & Grids Workshop, June 2007
39
Suggestions: Tools and Techniques
• As we will see, time series data is probably the most useful
• When did your problems start? When did things change?
• Unfortunately, relies on there being proximity between your paths/devices and ones for which there is available data
• If you suspect the problem is in the core you may be able to find the problem router (or rough location) through a so called "looking glass" servers: statistics of network operator performance
• ping and iperf very useful here…but be wary:• In May 2004, Les Cottrell (SLAC) said… “As measured by NetFlow,
25% of the traffic on Abilene is iperf and ping type traffic”

TERENA 5th NRENs & Grids Workshop, June 2007
40
Suggestions: Tools and Techniques
• Thrulay is an iperf-like tool for measuring TCP and UDP bandwidth– useful because it also gives you the RTT seen by the transfer, not
ping/traceroute’s estimate
• Two “detective” type tools:1. Tom Dunnigan and Rich Carlson's Network Diagnostic Tool (NDT)
– client-server– useful because client can be lightweight: Java applet, runs in a Web
browser on most systems– command line client (compile and install) also available– public servers (linux boxes with Web100 kernels) although I think only
one outside US (thank you SWITCH)– detects problems, makes suggestions: duplex problems, TCP tuning
amongst others2. The SURFnet Detective

TERENA 5th NRENs & Grids Workshop, June 2007
41
Suggestions: Tools and Techniques
NDT’s suggestion

TERENA 5th NRENs & Grids Workshop, June 2007
42
Suggestions: Tools and Techniques
We could do these but don’t because there’s too much data to process/correlate:• Cisco NetFlow data – routers record details of all traffic “flows” which they see:
– src and dest IP addresses and ports– start and end time– amount of traffic transferred
• Parsing firewall logs:– [root@gridmon2 ~]# iperf -c hepgrid7.ph.liv.ac.uk
------------------------------------------------------------Client connecting to hepgrid7.ph.liv.ac.uk, TCP port 5001TCP window size: 16.0 KByte (default)------------------------------------------------------------[ 3] local 193.62.125.96 port 58316 connected with 138.253.178.107 port 5001[ 3] 0.0-10.0 sec 873 MBytes 732 Mbits/sec
– Jun 10 22:12:58: NetScreen device_id=gw-fw system-notification-00257(traffic): start_time="2007-06-10 22:15:55" duration=22service=tcp/port:5001 src zone=ESC-DMZ dst zone=Untrustaction=Permit sent=948533470 rcvd=40793960 src=<hidden> dst=<hidden> src_port=58316 dst_port=5001 session_id=995619
– Not wholly accurate (22 secs not 10) and ignores overheads but can be used relative

TERENA 5th NRENs & Grids Workshop, June 2007
43
Suggestions: Tools and Techniques
• SNMP data is (understandably) impossible to obtain for non-networkers• Sharing data with the OGF NM-WG XML schemas may improve things
• And now some quick examples from gridmon:– Dedicated boxes– Same spec, OS, configuration - makes life a lot easier (comparing like-for
like)– If running regular tests, get the results in an SQL data – fast, repeatable
queries– If no dedicated boxes available, deploy a box for:
• either the best performance possible• Something representative of systems at that end-site
– Sorry, no-end system examples here – we configured the boxes ourselves ;-)

TERENA 5th NRENs & Grids Workshop, June 2007
44
Example 1
• Glasgow running transfer tests to Edinburgh over weekend 28-29th October• Experiencing poor rates (80Mbps)• 1st thing: despite transferring just 80Mbps, residual TCP bandwidth drops by ≈ 400Mbps• Warning bells

TERENA 5th NRENs & Grids Workshop, June 2007
45
Example 1
• Traceroute data reveals suspect router…
traceroute to gridmon.epcc.ed.ac.uk (129.215.175.71), 30 hops max, 38 byte packets
1 194.36.1.1 (194.36.1.1) 0.941 ms 0.882 ms 0.815 ms2 130.209.2.1 (130.209.2.1) 0.875 ms 0.831 ms 0.830 ms3 130.209.2.118 (130.209.2.118) 60.415 ms 55.453 ms 31.327 ms4 glasgowpop-ge1-2-glasgowuni-ge1-1-v152.clyde.net.uk (194.81.62.153)
32.420 ms 34.404 ms 29.424 ms5 glasgow-bar.ja.net (146.97.40.57) 43.467 ms 52.298 ms 39.349 ms6 po9-0.glas-scr.ja.net (146.97.35.53) 45.856 ms 44.445 ms 41.388
ms7 po3-0.edin-scr.ja.net (146.97.33.62) 51.509 ms 63.493 ms 31.435
ms8 po0-0.edinburgh-bar.ja.net (146.97.35.62) 22.454 ms 25.412 ms
31.381 ms9 146.97.40.122 (146.97.40.122) 44.602 ms 42.494 ms 35.492 ms10 gridmon.epcc.ed.ac.uk (129.215.175.71) 33.515 ms 34.623 ms
37.694 ms

TERENA 5th NRENs & Grids Workshop, June 2007
46
Example 1
• Reverse route confirms. Traceroutes are normal until we hit suspect router…
traceroute to gppmon-gla.scotgrid.ac.uk (194.36.1.56), 30 hops max, 38 byte packets
1 vlan175.srif-kb1.net.ed.ac.uk (129.215.175.126) 0.435 ms 0.387 ms 0.380 ms
2 edinburgh-bar.ja.net (146.97.40.121) 0.357 ms 0.329 ms 0.322 ms3 po9-0.edin-scr.ja.net (146.97.35.61) 0.564 ms 0.485 ms 0.485 ms4 po3-0.glas-scr.ja.net (146.97.33.61) 1.656 ms 1.511 ms 1.499 ms5 po0-0.glasgow-bar.ja.net (146.97.35.54) 1.850 ms 1.352 ms 1.422
ms6 146.97.40.58 (146.97.40.58) 1.679 ms 1.661 ms 1.569 ms7 glasgowuni-ge1-1-glasgowpop-ge1-2-v152.clyde.net.uk (194.81.62.154)
1.796 ms 1.677 ms 1.646 ms8 130.209.2.117 (130.209.2.117) 31.197 ms 34.615 ms 29.121 ms9 130.209.2.2 (130.209.2.2) 32.814 ms 32.158 ms 32.145 ms10 gppmon-gla.scotgrid.ac.uk (194.36.1.56) 41.634 ms 37.555 ms
24.635 ms
• Graphs and traceroutes provide evidence for further investigation

TERENA 5th NRENs & Grids Workshop, June 2007
47
Example 1
• Further investigation revealed that the router had exhausted itsCAM space
• <see next slide if you want to know what this is>
• In simple terms, the router was forced to switch in software• Because a particular lookup in a routing/switching/access
table was not being hardware accelerated, problems were caused under certain flow conditions
• The solution: the CAM dynamic database was re-optimised (to free up CAM space) and the unit began switching in hardware again

TERENA 5th NRENs & Grids Workshop, June 2007
48
Example 1
• CAM = Content-Addressable Memory• Hardware (fast) implementation of an associative area
– a data word (not memory address!) is used to access it– the CAM searches its entire contents to see if the data word is stored– if the word is found, the CAM returns a list of one or more corresponding storage
addresses, or other data associated with those storage addresses• CAM memory is used for switching and routing, e.g. Ethernet switches store
learned MAC addresses and their associated switch port in CAMMAC Address Located on Port------------- ---------------000039-0643f5 26
000089-01af9a 5000102-162346 16
• When an Ethernet frame arrives at the switch with a destination address of 000089-01af9a the switch searches its CAM for that address.
• The CAM will return “5” so the switch sends this Ethernet frame out on port 5

TERENA 5th NRENs & Grids Workshop, June 2007
49
Example 2
• Local departmental firewall reconfigured to switch off strict checking of TCP sequence numbers
• Potential minefield: SACK etc.

TERENA 5th NRENs & Grids Workshop, June 2007
50
Example 3
• Almost constant 33% UDP packet loss• Fatal to most/all applications using UDP• Occasional dip to 0%

TERENA 5th NRENs & Grids Workshop, June 2007
51
Example 3
• Zooming into a particular day shows a period of 0% loss• Site firewall limits UDP to 1,000 packets per second, per endpoint pair• Temporarily raised to 20,000 pps for Video Conferences

TERENA 5th NRENs & Grids Workshop, June 2007
52
The Answer• Blair (vintage 1996) before he game to power…
Ask me my three main priorities for Government and I tell you: education, education, education.
• Education, education, education; became a mantra for his party• NRENs are ideally placed to provide this

TERENA 5th NRENs & Grids Workshop, June 2007
53
The Answer• Blair (vintage 1996) before he game to power…
Yes, why don’t you stupid English learn some French?
Ask me my three main priorities for Government and I tell you: education, education, education.
• Education, education, education; became a mantra for his party• NRENs are ideally placed to provide this

TERENA 5th NRENs & Grids Workshop, June 2007
54
The Answer• Blair (vintage 1996) before he game to power…
Yes, why don’t you stupid English learn some French?
Ask me my three main priorities for Government and I tell you: education, education, education.
French? What’s French?
• Education, education, education; became a mantra for his party• NRENs are ideally placed to provide this

TERENA 5th NRENs & Grids Workshop, June 2007
55
NFNN
As an example:• Networks for non-Networkers
workshops• Aimed at people working at the
technical level in high-bandwidth dependant science
• Talks on TCP, LAN, diagnostic steps, security…
• http://gridmon.dl.ac.uk/nfnn/

TERENA 5th NRENs & Grids Workshop, June 2007
56
Your Application
• Is your application making effective use of the network?
• Consider using multiple TCP sockets (i.e. multiple streams) for your data transfers
• One thread per socket• Keep your “pipe” full of data
– use asynchronous I/O, i.e. run computation and I/O in parallel
– pre-fetch data you know you are going to need, again in parallel with other computation or I/O
– when possible, read/write large blocks of data at a time: better to infrequently r/w ≥ 1MB than frequently r/w 4K

TERENA 5th NRENs & Grids Workshop, June 2007
57
What Is Your Application Doing?
• Instrument your code, e.g. Netlogger, a “Networked Application Logger”
• Methodology and set of tools• Low overhead: can generate up to 5000/500
events/sec using the C/Java APIs with negligible impact on the app
• Simple and sensible methodology, e.g.– Rule 3: Log all of the following events: Entering
and exiting any program or software component, and begin/end of all I/O (disk and network).

TERENA 5th NRENs & Grids Workshop, June 2007
58
Netlogger
initial handshaking
• client side GridFTP• note the large
overhead (≈ 8s) of initial handshaking before real writing begins

TERENA 5th NRENs & Grids Workshop, June 2007
59
Conclusion
• The Grid could use network performance data• The reality is that it doesn’t• The Grid will exercise networks• Core = fine. Metro = mostly fine. Most problems in the last mile.• Not every Grid app wants, needs or can afford dedicated λ’s• Education, education, education. But please, no wars!• Tune your end systems and applications• Instrument you application so you can see what’s happening
• For more information: [email protected]

TERENA 5th NRENs & Grids Workshop, June 2007
60
Links (1)
• The GridPP (LHC in the UK) "gridmon" network monitoring infrastructure: http://gridmon3.dl.ac.uk/gridmon/
• Network Aware Scheduling in Grids:– "Network Aware Scheduling in Grids" paper:
http://users.atlantis.ugent.be/bvolckae/papers/NOC2004.pdf– "Data Intensive and Network Aware (DIANA) Grid Scheduling" paper:
http://hst.web.cern.ch/hst/publications/diana-JoGC.pdf– Report of the International Grid Performance Workshop 2005: http://www-
unix.mcs.anl.gov/~schopf/GPW2005/report.pdf– EDG WP7 Final Report: https://edms.cern.ch/file/414132/2.1/DataGrid-07-
D7-4-0206-2.0.pdf– EGEE-JRA4: http://egee-jra4.web.cern.ch/EGEE-JRA4/– gLite User Guide: https://edms.cern.ch/file/722398/gLite-3-UserGuide.html

TERENA 5th NRENs & Grids Workshop, June 2007
61
Links (2)
• Rolls Royce Networks:– Cisco’s Network Based On-demand/Grid System:
http://www.terena.org/activities/nrens-n-grids/workshop-03/NBGS-Terena.pdf
– The NAREGI project: http://www.naregi.org/index_e.html– Enlightened Computing:
http://www.mcnc.org/index.cfm?fuseaction=page&filename=enlightened_computing.html
– G-Lambda: http://www.g-lambda.net
• Monitoring Grid workflows in real-time: http://www.di.unipi.it/~augusto/seminars/200705_OGF20/2007-04-09_OGF-Slides.pdf
• Exploiting fibre infrastructures, UK ESLEA project closing conference: http://www.eslea.uklight.ac.uk/conf.html
• UCL Reality Grid project: http://www.realitygrid.org• Daresbury Laboratory HPCx super computer: http://www.hpcx.ac.uk

TERENA 5th NRENs & Grids Workshop, June 2007
62
Links (3)
• End host monitoring, LISA (Localhost Information Service Agent): http://monalisa.cacr.caltech.edu
• Synack, alternative ping tool: http://www-iepm.slac.stanford.edu/tools/synack/
• Thrulay, iperf-like tool: http://www.internet2.edu/~shalunov/thrulay/• Network Diagnostic Tool: http://e2epi.internet2.edu/ndt/• SURFnet Detective: http://detective.surfnet.nl/en/index_en.html
• Sharing network performance data, OGF Network Measurements Working Group: http://nmwg.internet2.edu/
• TCP Selective Acknowledgements (SACK): http://www.ietf.org/rfc/rfc2018.txt
• Netlogger (Networked Application Logger): http://dsd.lbl.gov/NetLogger/