estudio del rendimiento de sistemas de gestión de bases de...
TRANSCRIPT

UNIVERSIDAD POLITÉCNICA DE MADRID
TRABAJO FIN DE MÁSTER
Estudio del rendimiento de sistemas degestión de bases de datos New SQL
Autor:Claudiu BARZU
Supervisor:Marta PATIÑO MARTÍNEZ
7 de julio de 2017


III
Muchas gracias a mi novia por apoyarme en los momentosmás duros, a mi tutora por supervisarme en el desarrollo deeste trabajo y sobretodo a mis familia por la incesante ayuda
proporcionada durante toda mi vida académica.. . .


V
UNIVERSIDAD POLITÉCNICA DE MADRID
ResumenFacultad de Informática
Máster Universitario en Ingeniería Informática
Estudio del rendimiento de sistemas de gestión de bases de datos New SQL
by Claudiu BARZU
El volumen de datos generados en los últimos años ha impulsado el desarrollode nuevas tecnologías diseñadas para este entorno. A pesar de las grandes ventajasque poseen estos sistemas, han dejado de lado funcionalidades como las transac-ciones o el lenguaje SQL.
El presente trabajo se centra en el estudio de rendimiento de dos nuevos sistemasadaptados a los requerimientos actuales que pretenden ofrecer las funcionalidadesde los sistemas tradicionales, como las transacciones y el lenguaje SQL por su faci-lidad y popularidad.
Las pruebas realizadas miden el rendimiento de ambos sistemas en situaciones condistintos tipos de operaciones, algunas con alta carga de escritura y otras con altade lectura. Asimismo, se ha variado el tamaño de la base de datos para observar laescalabilidad de ambos sistemas.
Por último, en base a los datos obtenidos se puede concluir que ambos sistemasofrecen una capa de compatibilidad completa con el lenguaje SQL y un rendimien-to similar en situaciones con alta carga de datos. Sin embargo, el comportamientoentre ambos sistemas es muy diferente, ya que Apache Phoenix necesita más tiem-po en operaciones de lectura mientras que Splice Machine lo emplea en operacionesde escritura.


VII
UNIVERSIDAD POLITÉCNICA DE MADRID
ResumenFacultad de Informática
Máster Universitario en Ingeniería Informática
Estudio del rendimiento de sistemas de gestión de bases de datos New SQL
by Claudiu BARZU
The volume of new data generated in last years has forced the development of newsystems adapted to this new environment. Although the new developed systemshas caracteristics adapted to the current requirements, functionalities like transac-tions or SQL language are not available for this systems.
The current study is focused on the performance of two recently-developed sys-tems, Apache Phoenix and Splice Machine, which tries to offer the best of bothworlds: escalabilty and performance of new systems, but integrity of data and easyof use with SQL.
The developed benchmark is designed to measure the performance of these sys-tems on situations with heavy read load or with heavy write load. In addition,several database sizes are used to check the behavior of the systems.
Finally, based on the results we can conclude that both systems offer the same th-roughput when the database is big enough but the behavoir of each system is diffe-rent. Apache Phoenix needs more time to do read operations while Splice Machineuses more time on write operations.


IX
Índice general
Resumen V
Abstract VII
1. Introducción y objetivos 11.1. Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2. Objetivos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2. Estado del arte 32.1. Historia del benchmarking . . . . . . . . . . . . . . . . . . . . . . . . . 32.2. Beneficios de realizar un benchmark . . . . . . . . . . . . . . . . . . . 42.3. Tipos de benchmark . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52.4. Herramientas actuales . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3. Evaluación de riesgos 73.1. Plan de gestión de riesgos . . . . . . . . . . . . . . . . . . . . . . . . . 7
4. Desarrollo 94.1. Descripción de las herramientas utilizadas . . . . . . . . . . . . . . . 9
4.1.1. Descripción de Apache Hadoop . . . . . . . . . . . . . . . . . 94.1.2. Descripción de HBase . . . . . . . . . . . . . . . . . . . . . . . 94.1.3. Descripción de Apache Phoenix . . . . . . . . . . . . . . . . . 114.1.4. Descripción de Splice Machine . . . . . . . . . . . . . . . . . . 13
4.2. Elección del cliente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 144.2.1. Pruebas empíricas . . . . . . . . . . . . . . . . . . . . . . . . . 15
4.3. Introducción al benchmark definido . . . . . . . . . . . . . . . . . . . 174.4. Especificación del plan de pruebas . . . . . . . . . . . . . . . . . . . . 174.5. Instalación y configuración del entorno . . . . . . . . . . . . . . . . . 19
4.5.1. Descripción de la infraestructura . . . . . . . . . . . . . . . . . 194.5.2. Instalación y configuración de herramientas comunes . . . . . 194.5.3. Arquitectura del cluster . . . . . . . . . . . . . . . . . . . . . . 204.5.4. Instalación de Apache Phoenix . . . . . . . . . . . . . . . . . . 214.5.5. Instalación de Splice Machine . . . . . . . . . . . . . . . . . . . 224.5.6. Preparación de las pruebas . . . . . . . . . . . . . . . . . . . . 23
Carga de datos . . . . . . . . . . . . . . . . . . . . . . . . . . . 23Ejecución de las pruebas . . . . . . . . . . . . . . . . . . . . . . 24
4.5.7. Monitorización del proceso e identificación de cuellos de botella 25
5. Resultados 275.1. Resultado benchmark de Apache Phoenix . . . . . . . . . . . . . . . . 27
5.1.1. Benchmarking de la base de datos pequeña con alto porcen-taje de escritura . . . . . . . . . . . . . . . . . . . . . . . . . . . 27

X
Resultado elección del número de clientes . . . . . . . . . . . 27Resultados benchmarking . . . . . . . . . . . . . . . . . . . . 28
5.1.2. Benchmarking de la base de datos pequeña con alto porcen-taje de lectura . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28Resultado elección del número de clientes . . . . . . . . . . . 29Resultados benchmarking . . . . . . . . . . . . . . . . . . . . . 29
5.1.3. Benchmarking de la base de datos grande con alto porcentajede escritura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30Resultados elección del número de clientes . . . . . . . . . . . 30Resultados benchmarking . . . . . . . . . . . . . . . . . . . . . 31
5.1.4. Benchmarking de la base de datos grande con alto porcentajede lectura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31Resultado elección del número de clientes . . . . . . . . . . . 32Resultados benchmarking . . . . . . . . . . . . . . . . . . . . . 32
5.1.5. Discusión de resultados Apache Phoenix . . . . . . . . . . . . 335.2. Benchmark de Splice Machine . . . . . . . . . . . . . . . . . . . . . . . 35
5.2.1. Benchmarking de la base de datos pequeña con alto porcen-taje de escritura . . . . . . . . . . . . . . . . . . . . . . . . . . . 35Resultado elección del número de clientes . . . . . . . . . . . 35Resultados benchmarking . . . . . . . . . . . . . . . . . . . . . 36
5.2.2. Benchmarking de la base de datos pequeña con alto porcen-taje de lectura . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37Resultado elección del número de clientes . . . . . . . . . . . 37Resultados benchmarking . . . . . . . . . . . . . . . . . . . . . 37
5.2.3. Benchmarking de la base de datos grande con alto porcentajede escritura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38Resultado elección del número de clientes . . . . . . . . . . . 38Resultados benchmarking . . . . . . . . . . . . . . . . . . . . . 39
5.2.4. Benchmarking de la base de datos grande con alto porcentajede lectura . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39Resultado elección del número de clientes . . . . . . . . . . . 39Resultados benchmarking . . . . . . . . . . . . . . . . . . . . . 40
5.2.5. Discusión de resultados Splice Machine . . . . . . . . . . . . . 405.3. Comparación de Apache Phoenix y Splice Machine . . . . . . . . . . 43
5.3.1. Comparación de las técnologias . . . . . . . . . . . . . . . . . 435.3.2. Comparación de resultados . . . . . . . . . . . . . . . . . . . . 44
6. Conclusiones 47
7. Líneas futuras 49
A. Distribuciones 51
Bibliografía 53

XI
Índice de figuras
4.1. Arquitectura de HBase . . . . . . . . . . . . . . . . . . . . . . . . . . . 104.2. Apache Phoenix en el ecosistema Hadoop . . . . . . . . . . . . . . . . 124.3. Arquitectura Apache Phoenix y HBase . . . . . . . . . . . . . . . . . . 124.4. Apache Phoenix modelo de datos . . . . . . . . . . . . . . . . . . . . . 134.5. Splice Machine motores de búsqueda . . . . . . . . . . . . . . . . . . 134.6. Splice Machine arquitectura . . . . . . . . . . . . . . . . . . . . . . . . 144.7. Tpcc esquema de base de datos . . . . . . . . . . . . . . . . . . . . . . 154.8. Monitorización con Apache Ambari . . . . . . . . . . . . . . . . . . . 204.9. Distribución de componentes . . . . . . . . . . . . . . . . . . . . . . . 214.10. Distribución de componentes con Apache Phoenix . . . . . . . . . . . 224.11. Distribución de componentes con Apache Phoenix . . . . . . . . . . . 234.12. Monitorización plataforma con Apache Ambari . . . . . . . . . . . . 254.13. Resultado IOTOP en un nodo . . . . . . . . . . . . . . . . . . . . . . . 264.14. Resultado HTOP en un nodo . . . . . . . . . . . . . . . . . . . . . . . 26
5.1. Resultados número de clientes base de datos pequeña alta escritura . 275.2. Resultados con gran carga escritura base de datos pequeña . . . . . . 285.3. Resultados número de clientes base de datos grande alta escritura . . 295.4. Resultados con gran carga escritura base de datos pequeña . . . . . . 305.5. Resultados número de clientes base de datos grande alta escritura . . 315.6. Resultados con gran carga escritura base de datos grande . . . . . . . 315.7. Resultados número de clientes base de datos grande alta escritura . . 325.8. Resultados con gran carga de lectura base de datos grande . . . . . . 335.9. Tiempos de escritura en función del throughput . . . . . . . . . . . . 345.10. Tiempos de lectura en función del throughput . . . . . . . . . . . . . 345.11. Throughput en función del tamaño de la base de datos y el tipo de
carga . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 355.12. Resultados número de clientes base de datos pequeña alta escritura . 365.13. Resultados con gran carga escritura base de datos pequeña . . . . . . 365.14. Resultados número de clientes base de datos pequeña alta escritura . 375.15. Resultados con gran carga escritura base de datos pequeña . . . . . . 385.16. Resultados número de clientes base de datos pequeña alta escritura . 385.17. Resultados con gran carga escritura base de datos pequeña . . . . . . 395.18. Resultados número de clientes base de datos pequeña alta escritura . 405.19. Resultados con gran carga escritura base de datos pequeña . . . . . . 405.20. Tiempos de escritura Splice Machine en función del throughput . . . 425.21. Tiempos de lectura Splice Machine en función del throughput . . . . 425.22. Throughput en función del tamaño de la base de datos y el tipo de
carga . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 435.23. Phoenix y Splice máximo throughput . . . . . . . . . . . . . . . . . . 455.24. Tiempo medio de respuesta por tecnología . . . . . . . . . . . . . . . 45


XIII
Índice de cuadros
3.1. Riesgos identificados . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
4.1. Descripción de las máquinas . . . . . . . . . . . . . . . . . . . . . . . . 19


1
Capítulo 1
Introducción y objetivos
En este apartado se comenta brevemente una introducción al entorno actual,incluyendo aspectos tecnológicos y la justificación del presente trabajo.
1.1. Introducción
En los últimos años la cantidad de datos generados se ha incrementado ex-ponencialmente y la explotación de estos recursos requiere de nuevas tecnologíasadaptadas al volumen de datos actuales.
El acceso a Internet desde cualquier sitio por parte de cualquier persona ha pro-vocado un aumento considerable de datos. En 2013 se estaban generando más de4.4 Zetabytes cada día[6] y se calcula que la cantidad se multiplicará por 10 hasta2020, llegando a los 44 Zetabytes de datos generados diariamente.
El tratamiento de estos datos ha provocado la aparición de nuevas tecnologíasorientadas al procesamiento y almacenamiento de grandes cantidades de informa-ción. Uno de los compromisos de estás tecnologías es ofrecer un tiempo de res-puesta adecuado en base a los datos presentes. Para ello se utilizan ordenadoresmás potentes, o por el contrario, un cluster de ordenadores que trabajan conjunta-mente para ofrecer resultados en menor tiempo.
Para satisfacer estas necesidades de procesamiento de datos han surgido las ba-ses de datos NoSQL(Not Only Structure Query Language), que no suelen tener unesquema sino que la información se obtiene mediante un sistema de clave-valor.Estas bases de datos NoSQL utilizan un sistema de ficheros distribuido, como porejemplo HDFS (Hadoop File System) que se encarga de la replicación y distribuciónde los datos por todo el cluster.
Una de estas bases NOSQL es HBase, una base de datos basada en clave-valor lacual ofrece buen rendimiento tanto en escritura como en accesos aleatorios.
Sin embargo, las bases de datos NOSQL no son la única forma de procesamiento yalmacenamiento de datos. Como alternativas, han surgido tecnologías que permi-ten en procesamiento en tiempo real de los datos de entrada. Spark es un ejemplode tecnología de procesamiento de datos en tiempo real.
Estas nuevas tecnologías no comparten un lenguaje común por lo que es necesario

2 Capítulo 1. Introducción y objetivos
estudiar detalladamente cada lenguaje en particular. Por ello, ha surgido la pregun-ta de si se puede utilizar el lenguaje SQL tradicional para interrogar estas nuevasbases de datos, dando lugar a NewSQL.
En este trabajo se estudiará el rendimiento de dos motores de bases de datos NewSQL,en concreto Splice Machine y Apache Phoenix.
1.2. Objetivos
El objetivo principal del trabajo se puede definir como la realización de un es-tudio acerca del rendimiento de varios sistemas de bases de datos no relacionales.
Dicho objetivo se compone de los siguientes subobjetivos:
(O1) Estudio de la arquitectura de Apache Phoenix y Splice Machine, indicando lasprincipales diferencias entre ambos sistemas, las ventajas e inconvenientes decada herramienta y casos de uso idóneos para cada uno.
(O2) Despliegue en una infraestructura distribuida con Hadoop, Hbase y los siste-mas objeto de análisis.
(O3) Definir un procedimiento teórico que cubra el análisis de rendimiento y esca-labilidad de los sistemas estudiados.
(O4) Adaptar los clientes utilizados para permitir su utilización con los sistemasevaluados.
(O5) Realizar en benchmarking de los sistemas en base a la especificación teóricadefinida
(O6) Realizar una comparación entre ambos sistemas, analizando las diferenciasentre los tiempos de respuesta y el número de operaciones máximo por se-gundo obtenido.

3
Capítulo 2
Estado del arte
En este capitulo se presenta que es el concepto de benchmarking con el fin deentender mejor el proceso y los resultados de las siguientes secciones.
2.1. Historia del benchmarking
Dentro del ámbito de la informática, se puede definir el concepto de benchmarkcomo el acto de medir y evaluar el rendimiento de los ordenadores, protocolos,componentes, dispositivos y software bajo unas condiciones de referencia[14].
El concepto de benchmark no es nada nuevo en la informática. En los años 1970,el concepto de benchmark se formó como un término técnico que significa "puntode referencia". Posteriormente este término migró al ámbito empresarial, donde sedefinió el benchmark como el proceso de medir para realizar comparaciones.
Uno de los grandes casos de éxito lo podemos encontrar en la empresa Xerox. Estaempresa es considerada una de las pioneras en el mundo del benchmark. Xeroxdefinió el benchmarking como el proceso continuo de comparación de nuestros procesos,productos y servicios, frente a los de los competidores o a los de aquellas compañías recono-cidas como líderes permitiendo identificar y adoptar prácticas exitosas[2].
Esta compañía gracias al estudio detectó muchas deficiencias respecto a sus com-petidores Japoneses, los cuales conseguían vender el mismo producto a un precionotablemente inferior.
Esta es la lista de defectos encontrados por parte de Xerox:
1. El número de personas involucradas desde la fabricación hasta el usuariofinal era más del doble que sus competidores
2. El número de proveedores era nueve veces superior
3. El time to market era el doble
4. La cadena de producción llevaba el doble de tiempo
5. El número de defectos por cada 100 productos es siete veces superior al de lacompetencia
Gracias al bencharmk realizado Xerox consiguió encontrar sus principales proble-mas, lo cual le ha permitido mejorar sus procesos y ofrecer así unos servicios y

4 Capítulo 2. Estado del arte
productos a un precio más competitivo.
Inicialmente los estudios del rendimiento se centraban en componentes hardwa-re, principalmente en CPU. El estudio de distintas CPUs con diferentes arquitec-tura dió lugar a la necesidad de establecer unas unidades que permitan realizardichas comparaciones. Para solventar esta necesidad, surgieron los MIPS ( millionsof instructions per second) y MFLOPS (milliones of floating point operations perseconds).
No obstante, la aparición de unas unidades de medición no resuelve el problemaya que las instrucciones de una arquitectura a otra no son equivalentes, y así pues,la ejecución de una instrucción en una arquitectura puede equivaler a dos o másinstrucciones en otra. A pesar de todo, a día de hoy, se sigue utilizando como unamedida discriminación entre procesadores.
Con el despegue de la informática pronto surgieron organizaciones y herramientaspara estandarizar el proceso y las medidas a la hora de realizar las comparativas.
Una de estás organizaciones es The Standard Performance Evaluation Corporation(SPEC), la cual fue fundada en 1988 por una asociación de vendedores de ordena-dores que vieron la necesidad urgente de tener unas pruebas realistas y estandari-zadas para realizar comparaciones. SPEC es una organización sin animo de lucrocuyo objetivo es establecer, mantener y proveer una lista de benchmarks actualiza-dos que pueden ser aplicados a los nuevos ordenadores de altas prestaciones. Estaorganización se centra principalmente en componentes hardware y software de ba-jo nivel, como kernel de los sistemas linux.
Sin embargo SPEC no es la única organización que realiza y provee estándares pararealizar un benchmark. The Transaction Processing Performance Council (TPC) esuna organización sin ánimo de lucro que propone benchmarks para procesamientode transacciones de bases de datos. Dispone de distintos modelos de referencia pe-ro sus principales benchmarks son TPC-C y TPC-D en los cuales se usan un clientepara generar las peticiones a un sistema servidor que las atiende, procesa y generalos resultados.
2.2. Beneficios de realizar un benchmark
Estudiar el rendimiento de los sistemas y el software utilizado se realizó históri-camente por las empresas para conocer el estado actual de sus sistemas y así poderrealizar una estrategia de futuro [13].
Asímismo, los resultados obtenidos permite dimensionar su infraestructura, tenerpresente hasta que punto se puede ofrecer servicio con la infraestructura actual, rea-lizar una estimación de costes en función de la carga necesaria a soportar o evaluarel riesgo . Para el presente trabajo los resultados obtenidos permitirían la elecciónde un sistema frente a otro en un entorno con las mismas capacidades.

2.3. Tipos de benchmark 5
2.3. Tipos de benchmark
Existen distintos tipos de herramientas para realizar un estudio del rendimien-to, y se pueden clasificar de la siguiente manera [4]:
1. Basado en el nivel del rendimiento
a) Herramientas de bajo nivel
b) Herramientas de alto nivel
2. Basado en su composición
a) Herramientas de medida sintéticas
b) Herramientas basadas en aplicaciones
Las herramientas de bajo nivel sirven para obtener métricas a muy bajo nivel de loscomponentes, por ejemplo, el reloj de la CPU, el tiempo medio de acceso al disco,los tiempos de acceso a la memoria RAM, etc. Estos tipos de herramientas puedenservir para comprobar el correcto funcionamiento de los componentes instaladosen el sistema.
Las herramientas de alto nivel sirven para medir combinación de componentes,pero generalmente no el sistema completo. De este modo, con un test de alto nivelse podría comprobar el rendimiento de una interfaz de red o el rendimiento delacceso a disco con unos determinados parámetros de configuración.
Los benchmarks sintéticos en general son usados para comprobar el rendimien-to de un solo componente llevándolo al limite, independientemente del resto decomponentes del sistema. El problema de este tipo de tests es que no son realistas,ya que el componente no está siendo probado en unas condiciones iguales a las deproducción.
Los benchmarks de aplicaciones son los más extendidos actualmente ya que mi-den el rendimiento global de un sistema (entiéndase por sistema el conjunto dehardware y software utilizado para llevar a cabo una tarea).
Para el presente trabajo se va realizar un benchmark de aplicación.
2.4. Herramientas actuales
Actualmente el bechmarking colaborativo es muy popular, tanto, que encontrarresultados de rendimiento de todas las herramientas opensource populares es posi-ble. A nivel de benchmarking de hardware, muchas veces suelen ser provistos porparte del propio fabricante.
A nivel hardware una de las herramientas más utilizadas profesionalmente es Si-Soft Sandra, con versión libre y de pago que permite realizar una prueba de cargade los distintos componentes hardware de nuestro sistema para ver su rendimientoante situaciones limite. Esta herramienta contiene una base de datos online que nospermite comparar nuestro sistema con otras alternativas del mercado.

6 Capítulo 2. Estado del arte
A nivel de aplicación se van a explicar brevemente los benchmarks destinados amedir los servidores de aplicaciones. La mayoría de estas herramientas utilizan elprotocolo HTTP estándar para realizar las pruebas de rendimiento de nuestro sis-tema. Asimismo, estas herramientas realizan una prueba de carga y nos informa dedel thoughput de nuestro sistema (número de operaciones por segundo, latencia,tiempo de respuesta, etc). Una de las herramientas más comunes para realizar estetipo de pruebas es JMeter. Otras alternativas opensource que se están popularizan-do son Vegeta y Taurus.
Para realizar benchmarks de sistemas de gestión de bases de datos SQL está la he-rramienta HammerDB, la cual nos permite ejecutar las pruebas definiendo nuestraspropias sentencias, consultas, actualizaciones o borrado. Esta herramienta soportalas principales bases de datos SQL del mercado, Oracle 11G, MYSQL, Oracle DB2,etc. Otra herramienta muy popular es Escada TPC-C, la cual implementa la espe-cificación tpc-c y por lo tanto los resultados nos permiten compararlos con otrosproductos del mercado sin necesidad de realizar nosotros mismo el estudio.
Por último, en el mundo del cloud han surgido nuevos sistemas de gestión de datosno estructurados, los conocidos como gestores NoSQL y NewSQL. Para realizar unbenchmark en este tipo de entorno, ha aparecido una herramienta que se ha im-puesto como un estándar en el mundo cloud. Se trata de YCSB, una herramientamuy simple que ofrece integraciones con sistemas de gestión de datos clásicos, co-mo bases de datos SQL, así como sistemas más modernos como HBASE, Cassandra,Mongodb, etc.

7
Capítulo 3
Evaluación de riesgos
Todos los proyectos sufren amenazas, ya sean internas o externas, independien-temente de su tamaño, duración o naturaleza. Identificar correctamente estás ame-nazas así como su impacto sobre el proyecto puede marcar la diferencia entre rea-lizarlo con éxito y a tiempo, o por el contrario realizarlo con retraso o, incluso,cancelarlo.
3.1. Plan de gestión de riesgos
Antes de hacer hincapié en la gestión de riesgos, con el fin de entender mejorde que trata esta sección se define primero qué es el riesgo
El riesgo se define como un evento o condición incierta que en caso de ocurrir puedetener un impacto positivo o negativo sobre cualquiera de los objetivos del proyecto (tiempo,costo, alcance, recursos, satisfacción del cliente) [12].
A continuación se muestra una lista con todos los riesgos identificados así como sudefinición. En la tabla 3.1 se presentan los riesgos identificados junto a una probabi-lidad de ocurrencia así como la estimación del impacto y un plan de contingencia.
(Rsk1) Indisponibilidad del cluster: Posibilidad de que el cluster no esté disponiblepara instalar y realizar las pruebas
(Rsk2) Planificación errónea: posibilidad de que la planificación no esté bien reali-zada, de modo que se dedique tiempo a tareas menos importantes y no elsuficiente a las tareas más grandes.
(Rsk3) Benchmark inadecuado: realizar un benchmark incompleto debido a la faltade experiencia en realizar este tipo de estudios

8 Capítulo 3. Evaluación de riesgos
Cód Riesgo Prob Impacto Plan de actuación
Rsk1 Indisponi-bilidad delcluster
Baja Alto Definir el trabajo y realizar las pruebasen un dispositivo local antes de reali-zarlas en un cluster, disminuyendo asíel tiempo necesario del mismo.
Rsk2 Planificaciónerrónea
Alta Media Revisar periódicamente el trabajo rea-lizado y pendiente para detectar cuan-to antes errores de planificación y re-ajustar
Rsk3 Benchmarkinadecuado
Medio Alto Consultar periódicamente los avancescon la tutora y rectificar
CUADRO 3.1: Riesgos identificados

9
Capítulo 4
Desarrollo
En el presente capitulo se va explicar el desarrollo del proyecto, desde la defi-nición del alcance hasta la realización del benchmarking y presentación de resulta-dos, pasando antes por diseño y configuración del cluster.
4.1. Descripción de las herramientas utilizadas
En esta sección se explican brevemente las herramientas utilizadas para la rea-lización del trabajo, dando una visión global de su arquitectura y funcionamiento,así como de sus funciones.
4.1.1. Descripción de Apache Hadoop
Apache Hadoop es un framework de código abierto que permite el almace-namiento distribuido y el procesamiento de grandes conjuntos de datos, utilizan-do largos clusters de ordenadores comerciales y el paradigma de programaciónMap/Reduce.
Apache Hadoop ha sido diseñado bajo la premisa de que el hardware puede fa-llar, y es por ello que el software debe detectar y manejar los fallos, resolviendo losproblemas de hardware en la capa de aplicación.
El proyecto Hadoop incluye los siguientes módulos:
1. Hadoop Common Las utilidades comunes entre todos los modulos de Ha-doop.
2. Hadoop Distributed File System(HDFS) Un sistema de ficheros distribuidoescalable y seguro que ofrece un alto rendimiendo a las aplicaciones.
3. Hadoop YARN Un framework que permite el manejo de tareas y recursosdentro del claster.
4. Hadoop MapReduce Un sistema basado en YARN para el procesamiento pa-ralelo de largos conjuntos de datos.
4.1.2. Descripción de HBase
HBase es un sistema de gestión de bases de datos disperso, distribuido, persis-tente, multimensional que se ejecuta encima de Hadoop Distributed File System.Se trata de un sistema de base de gestión de base de datos NOSQL diseñado para

10 Capítulo 4. Desarrollo
ofrecer acceso aleatorio a grandes cantidades de datos, con billones de filas o millo-nes de columnas, en tiempo casi real[1].
A continuación se presenta una lista con las principales características de HBase:
1. Tolerante a fallos
a) Replicación automática en el cluster
b) Alta disponibilidad gracias a la recuperación automática de fallos
c) Balanceo y distribución automática de las tablas
d) Operaciones consistentes a nivel de fila
2. Rápido
a) Acceso en tiempo real a los datos
b) Caché de los datos más recientes
c) Procesamiento de los datos en la parte del servidor
HBase consigue las ventajas enumaradas anteriormente gracias a su diseño y arqui-tectura. En HBase las tablas son distribuidas a lo largo de cluster automáticamentecuando son demasiado grandes para ser manejadas como un conjunto. La unidadde datos con la que trabaja HBase se llama región. Una región es un subconjuntode datos de una tabla, o lo que es lo mismo, un conjunto ordenado de filas alma-cenadas juntas en un determinado servidor. HBase contiene un único máster y unconjunto de “esclavos“ denominados regionservers, los cuales sirven varias regio-nes mientras que una región es servida únicamente por un regionserver.
En la figura 4.1 se presenta la arquitectura de HBase. En ella se puede observarlos tres elementos más importantes de HBase: el Máster, los Regionservers y Zoo-keeper.
FIGURA 4.1: Arquitectura de HBase

4.1. Descripción de las herramientas utilizadas 11
El HMáster es un proceso ligero encargado de distribuir las regiones entre losdistintos Regionservers con propósito de mejorar la escalabilidad. Entre sus princi-pales funciones se encuentra:
Manejar y monitorizar el cluster
Manejar las peticiones de creación, manipulación y borrado de tablas
Coordinar la recuperación en caso de un fallo
Atender las peticiones por partes de los clientes correspondientes al cambiode schema, manipulación de regiones . . .
Los Regionserver son los encargados de escuchar las peticiones de lectura, actua-lización e inserción de los datos a petición de los clientes. Se ejecutan en todos losnodos del cluster y sirven los datos guardados en los Datanodes de Hadoop. Loscomponentes más importantes de los regionserver son :
Block cache Los datos más leídos se guardan en memoria. Si no hay espacioen memoria para nuevos datos, los menos accedidos son eliminados de lamemoria para guardar los nuevos.
Memstore Esta es la caché de escritura y guarda los nuevos datos antes de serescritos todos juntos en disco.
Write Ahead Log Para asegurar la persistencia de los datos en caso de fallodel regionerver, por cada dato guardado en la memstore se guarda un regis-tro/log en el WAL para recuperar el dato en caso de fallo.
HFile Es la estructura de datos que guarda todos lo datos ordenados en disco.
Por último Zookeeper, un servicio de coordinación distribuido altamente fiable queguarda datos en formato clave-valor, en este caso se utiliza para guardar informa-ción acerca de los regionservers y el máster. Entre las funciones de Zookeeper seencuentran las siguientes:
Establecer la comunicación entre el cliente y los regionservers
Monitorizar fallos de particiones de red
Mantener la configuración del cluster
4.1.3. Descripción de Apache Phoenix
Apache Phoenix es un proyecto que ha surgido con el objetivo de ”poner elSQL de vuelta dentro del NOSQL”. Con esta finalidad presente, se puede decir queApache Phoenix es una capa de base de datos relacional para HBase, escuchandopeticiones SQL y transformándolas a peticiones nativas de HBase[11].
Existen varias razones por las que un proyecto como Apache Phoenix es necesa-rio. Para empezar, a pesar de su antigüedad, desde los años 1970, el SQL siguesiendo uno de los lenguajes más utilizados hoy en día a nivel empresarial. Su faci-lidad de uso, su popularidad, la cantidad de librerías y sistemas que actualmentelo utilizan, hacen que el lenguaje SQL siga siendo interesante para nuevas librerías

12 Capítulo 4. Desarrollo
o proyectos. Apache Phoenix pretende ofrecer todas las ventajas del lenguaje SQLcombinadas con las ventajas de un sistema de base de datos NOSQL, como porejemplo su capacidad para escalar y ofrecer un mayor throughput, pudiendo llegara millones de operaciones por segundo, en entornos donde un sistema relacionalno sería capaz, con petabytes de datos de distinta naturaleza.En la figura 4.2 se presenta dónde encaja Apache Phoenix dentro del ecosistemaHadoop. Como se puede observar, Phoenix es un sistema más junto a Hive, Pig,que se ejecutan encima de HDFS. Esta herramienta, se divide en dos partes, unaparte servidora que escucha y ejecuta las querys realizadas realizadas por la partecliente, que se instala como librerías adicionales en tu proyecto.
FIGURA 4.2: Apache Phoenix en el ecosistema Hadoop
La figura 4.3 presenta un esquema arquitectural más detallado, mostrando co-mo encaja los componentes de Apache Phoenix dentro de HBase.
FIGURA 4.3: Arquitectura Apache Phoenix y HBase
Por último, en la figura 4.4 se presenta como Apache Phoenix realiza la tra-ducción de tablas de Phoenix a las tablas de HBase. Como se puede observar, latraducción es bastante directa pero hay que tener presente que la clave primaria deuna tabla de HBase se forma mediante la concatenación de los valores de las co-lumnas que forman la primary key. Teniendo en cuenta está implementación, paraobtener un mayor rendimiendo hay que fijar como clave primaria aquellas tablasque sean utilizadas frecuentemente en las clasulas "where".

4.1. Descripción de las herramientas utilizadas 13
FIGURA 4.4: Apache Phoenix modelo de datos
4.1.4. Descripción de Splice Machine
Splice Machine es otro sistema que ha surgido con el crecimiento de las basesde datos NOSQL y que pretende ofrecer una capa compatible con SQL para acce-der a estos nuevos sistemas. Sin embargo, a diferencia de Apache Phoenix, SpliceMachine es mucho más que una herramienta o un framework, es toda una plata-forma de análisis de datos dónde la compatibilidad SQL y NOSQL es sólo una desus funciones.
Splice Machine contiene en su arquitectura dos motores de ejecución, uno especia-lizado en Procesamiento de Transacciones En Línea (OLTP) y otro On-Line Analy-tical Processing (OLAP). El primero, especializado en transacciones, utiliza HBasecomo sistema de gestión de los datos. Por el otro lado, cuando se trata de ejecu-ciones muy costosas que requieren de varias operaciones o de distinta naturaleza, como group by, joins, ordenar, etc, se utiliza Spark como motor de análisis de losdatos requeridos. Su filosofía se puede encontrar la figura 4.5, donde se observa ladistinción entre los distintos tipos de operaciones, su flujo de procesamiento y elproblema que se pretende evitar.
FIGURA 4.5: Splice Machine motores de búsqueda

14 Capítulo 4. Desarrollo
Los objetivos que persiguen tratan de conseguirlos con las herramientas pre-sentadas en la figura 4.6. En este diagrama de su arquitectura se puede ver comoen los nodos de computo además de HBase viene instalado Spark y unos compo-nentes adicionales propios de Splice Machine. Estos componentes, como el parser,el planner y el cost based optimizer son los encargados de analizar el mejor flujopara cada operación y enviarla por la "víaçorrecta.
FIGURA 4.6: Splice Machine arquitectura
4.2. Elección del cliente
Para realizar un benchmark es necesario elegir un cliente que se adapte a la in-fraestructura que se quiere analizar, o en su defecto, sea lo suficientemente flexiblecomo para adaptarlo a nuevos entornos. Dependiendo del tipo de cliente se haceénfasis en un determinado tipo de operaciones u otras, buscando el rendimientode una determinada operación. Por lo tanto, los resultados obtenidos con una he-rramienta no son comparables con los obtenidos por otra, y en consecuencia, laherramienta elegida se va utilizar para el test de ambos sistemas.
Las herramientas elegidas son YCSB y Escada TPC-C. Los dos clientes están desti-nados a probar el rendimiento de distintos sistemas, ambos son fácilmente adapta-bles y personalizables y ambos ofrecen un resumen con las estadísticas del estudio,como por ejemplo el thoughput, el tiempo medio de respuesta por tipo de opera-ción, percentil 95, percentil 99 etc. . .
Yahoo! Cloud Serving Benchmark (YCSB) es una herramienta que se ha impues-to como un estándar en el mundo cloud. Permite realizar pruebas de manera muyágil ya que únicamente se necesita Java instalado en la máquina cliente. Por defectonos permite especificar el número de clientes concurrentes a utilizar, la distribucióna la hora seleccionar los datos y ofrece distintas operaciones ( lectura, actualización,inserción, scan). El esquema de la base de datos es muy sencillo, consta únicamentede una tabla con una clave y 10 campos.
Por el contrario, el cliente Escada TPC-C es una implementación del estándartpcc-c, descrito en el apartado 2.1, y que por lo tanto ofrece unos resultados quese pueden comparar con otras bases de datos al tratarse de un estándar, indepen-dientemente de si se usó el mismo cliente o no para realizar la prueba. El estándardescribe exactamente como se debe realizar las pruebas, tamaño de datos, tiemposetc. A diferencia de YCSB, el esquema de la base de datos es más compleja, y por

4.2. Elección del cliente 15
lo tanto más completo al ofrecer distintos tipos de relaciones y distintos tipos detransacciones, algunas que involucra más tablas, columnas,etc. En la figura 4.7, sepuede observar el esquema relacional establecido por el estándar tpcc.
FIGURA 4.7: Tpcc esquema de base de datos
4.2.1. Pruebas empíricas
Para la prueba empírica se ha desarrollado las conectores que permiten la co-municación con Apache Phoenix y Splice Machine de ambos clientes.
La implementación de YCSB ha resultado muy sencilla ya que está bien documen-tada y únicamente hay que modificar las consultas a realizar. Al tratarse de unaherramienta creada con el fin de probar distintos sistemas, la flexibilidad formaparte de su arquitectura.
Por el contrario, Escada TPC-C es una implementación ad hoc, y aunque ofrezcauna manera de integrarse con otros sistemas se ha requerido de cierta ingenieríainversa para desarrollar el conector entre el cliente y los servidores. Además, cier-tas funcionalidades de las que se espera de una base de datos relacional, y que porlo tanto Escada TPC-C, no está disponible ni en Apache Phoenix ni en Splice Machi-ne, como por ejemplo el autoincrement. Esto ha complicado aún más el desarrollodel conector para Escada.
Durante el proceso de implementación se han utilizado las versiones Standalonede los sistemas objetos de prueba, o el cluster con un tamaño de base de datos ínfi-mo, suficiente para probar la correcta implementación, pero no el rendimiento delsistema.
La primera gran diferencia a la hora de evaluar los dos clientes nos las encontra-mos al cargar los datos. Las diferencia de tiempo entre YCSB y Escada TPC-C paracargar 10 GB de datos es de aproximadamente 3 horas, llevando 4 horas cargarloscon YCSB y más de 7 horas con ESCADA TPC-C. Esta diferencia podría deberse aque en el segundo cliente, se están utilizando indices, claves primarias, más tablasy columnas, aunque finalmente el tamaño de los datos sea similar.

16 Capítulo 4. Desarrollo
Las primeras pruebas con YCSB dieron resultados muy satisfactorias, llegando amás de 1000 operaciones por segundo y tiempos de respuesta muy contenidos, pordebajo de los 50 milisegundos en lectura y 10 milisegundos en escritura. Teniendoen cuenta que hay 3 máquinas bastante pequeñas, ofrecer más de 1000 operacionespor segundo, aunque sea unas operaciones muy sencillas, es un resultado satisfac-torio.
Con Escada TPC-C se encontraron problemas de rendimiendo cuando se aumentael tamaño de la base de datos, incluso con unos pocos GB que caben en la memoria.Mirando las trazas de log se ha observado que es debido al tipo de operaciones quese realizan. Las operaciones de lectura en lugar de realizar un Get hacen una ope-ración Scan, la cual es mucho más lenta y costosa. Durante la realización de estasoperaciones la CPU de todos los nodos está al 100 %.

4.3. Introducción al benchmark definido 17
4.3. Introducción al benchmark definido
En el presente apartado se explica el plan de pruebas a realizar, incluyendo tan-to la parte software como de infraestructura, para analizar el rendimiento de lossistemas objeto de estudio, Apache Phoenix y Splice Machine.
La primera etapa es la definición de las pruebas a realizar. Esta fase incluye el di-seño de un plan de pruebas que cubra un amplio caso de pruebas y que nos permitaobtener conclusiones útiles. Este plan debe establecer tanto el tipo de operacionesa realizar, número de clientes, tamaños de bases de datos así como la duración decada prueba.
La segunda fase del presente proyecto, incluye la instalación y configuración delentorno. También se incluye en este apartado la instalación de herramientas de mo-nitorización de las máquinas de modo que se pueda detectar cuellos de botella odeficiencias de nuestras máquinas. El resultado de esta fase es un cluster de ApachePhoenix y Splice Machine plenamente funcional.
La tercera fase corresponde a la ejecución. El objetivo principal en estos momentoses la ejecución de los scripts anteriormente mencionados y la monitorización de laplataforma para asegurar su integridad operacional de modo que los resultados dela prueba sean válidos.
Por último, queda la frase de análisis de resultados, etapa en la que se analizanlos datos obtenidos para transformarlos en información. El resultado de esta etapaes un informe con los resultados y conclusiones extraídas.
4.4. Especificación del plan de pruebas
Las pruebas definidas deben cubrir un amplio rango de casos que nos permi-tan extraer conclusiones objetivas. Para ello es necesario definir un procedimientoestándar a seguir durante todas las pruebas.
En primer lugar se debe encontrar el número óptimo de clientes, que nos permi-tan realizar el máximo número de operaciones por segundo teniendo en cuenta lalatencia de escritura y lectura.
Para ello hay que probar diferentes combinaciones de los parámetros de los clien-tes, siendo de los más importantes cuantos clientes se utilizan. Un número dema-siado elevado de clientes puede saturar el sistema dando lugar a peores tiemposo número de operaciones por segundo (throughput). Utilizar pocos clientes puedeprovocar poco tráfico y peticiones,y por lo tanto, no llegar a la capacidad máximadel cluster. Cada prueba debe durar al menos dos horas, y cada aumento de clien-tes será de 50 en 50 hasta alcanzar el máximo que el cluster pueda atender.
Para obtener el valor óptimo para el número de clientes, se va a ir aumentandopoco a poco el número de clientes y se va ejecutar una prueba, con el fin de obtenerel máximo throughput y observar como varía los tiempos de respuesta. El cliente

18 Capítulo 4. Desarrollo
"óptimo.es subjetivo, ya que para algunos casos de uso el objetivo es conseguir elmayor número de operaciones, mientras que para otros el objetivo es conseguir lamejor latencia. Para el presente trabajo se va a usar aquel que ofrezca el mayor nú-mero de operaciones sin penalizar demasiado los tiempos de respuesta.
Una vez se obtenga el número de clientes óptimo se pasa a realizar las pruebasde rendimiento. El objetivo es ver como varía el tiempo de respuesta con respectoal número de operaciones por segundo. Para ello, se va a comenzar con un númerobajo de operaciones por segundo para posteriormente aumentarlo y volver a rea-lizar la prueba. Se van a realizar un total de cuatro pruebas, siendo cada aumentocalculado como el máximo throughput obtenido en el paso anterior dividido paracuatro. Cada prueba, va a durar cuatro horas para minimizar el impacto de los pi-cos de latencia puntuales, y obtener así un resultado más robusto y real.
Con el fin de minimizar/eliminar la interferencia de una prueba anterior en la si-guiente, los datos deben restaurarse quedando siempre en un estado consistente ysin ninguna modificación realizada después de la carga de datos. El cluster se vareiniciar después de cada prueba, eliminando así los datos residentes en memoria,y por lo tanto, restos de ejecuciones anteriores.
Con todas las pruebas, se puede obtener un gráfico comparando como varía laslatencias con respecto al número de operaciones, así como la capacidad máximadel cluster.
Por último, con el fin de probar la escalabilidad del sistema, las pruebas anterio-res se van a realizar con distintos tamaños de la base de datos, los cuales de definena continuación.
tam_base_de_datos_normal = no_regionservers ∗memoria_regionserver
Un tamaño de base de datos "normal.es lo suficientemente grande como para nocaber en memoria, siendo necesario de este modo frecuentes accesos a disco aun-que haya ocasiones que los datos se sirvan directamente de memoria.
tam_base_de_datos_grande = no_regionservers ∗memoria_regionserver ∗ 3
Para probar la escalabilidad del sistema, triplicamos el tamaño de base de datosdel paso anterior. El objetivo es probar si la cantidad de datos influye en el sistema,y si lo hace, hasta que punto. Obviamente, el sistema tendrá un limite a partir delcual no escalará, pero el objetivo es observar si hay grandes diferencias entre tenerpocos datos que prácticamente caben en memoria, o una cantidad que impliquesiempre el acceso a disco.
Las pruebas anteriores se van a realizar para ambos sistemas objetos de estudio,Apache Phoenix y Splice Machine.

4.5. Instalación y configuración del entorno 19
4.5. Instalación y configuración del entorno
En esta sección se explica el proceso de instalación y configuración del clusterpara la prueba, indicando las características de la infraestructura así como la arqui-tectura del sistema.
4.5.1. Descripción de la infraestructura
La infraestructura para la prueba se ha montado en un cluster de Openstackcon cuatro máquinas virtuales. En la tabla 4.1 se muestra una lista con las distintasmaquinas con sus características hardware y sofware.
FQDN Disk Memory Cores SOblade39 300GB SSD/1TB HDD 8GB 4 Ubuntu 14blade40 300GB SSD/1TB HDD 8GB 4 Ubuntu 12blade41 300GB SSD/1TB HDD 8GB 4 Ubuntu 12blade83 300GB SSD/1TB HDD 8GB 4 Ubuntu 14
CUADRO 4.1: Descripción de las máquinas
Se destaca la igualdad de las especificaciones físicas de las siguientes máquinasy la diferencia a nivel de sistema operativo. Tener diferentes versiones del sistemaoperativo en un mismo cluster nunca es buena idea debido a posibles incompatibi-lidades.
4.5.2. Instalación y configuración de herramientas comunes
Apache Phoenix y Splice Machine se ejecutan encima de HBASE el cual necesitaHadoop para su funcionamiento. Por ello el primer paso consiste en la instalaciónde un cluster de Hadoop. Inicialmente se ha optado por la instalación y configura-ción manual de cada una de las máquinas, sin embargo pronto se han encontradodificultades a la hora de mantener el cluster, detectar componentes caídos o modi-ficar de parámetros de configuración.
Debido a los problemas encontrados, se ha visto la necesidad de instalar sistemasque permitan la gestión integral del cluster de una manera más sencilla y sobretodoágil, empleando así más tiempo en las pruebas y menos en mantenimiento.
La instalación de clusters de Hadoop y HBase es una tarea frecuente entre los profe-sionales del sector, y es por ello que han surgido algunos proyectos, como Clouderay Apache Ambari, que automatizan esta tarea. Ambos proyectos ofrecen medianteun servidor gráfico la posibilidad de configurar e instalar las herramientas necesa-rias en todas las máquinas que componen el cluster. Para el presente proyecto se haseleccionado Apache Ambari al ser opensource.
Apache Ambari ofrece la posibilidad de asignar de manera gráfica los distintosroles, como por ejemplo Namenode en el caso de Hadoop, o Regionservers a cadauna de máquinas del cluster. Por defecto, Ambari nos sugiere una configuración demodo que los distintos servicios se distribuyen a lo largo de todo el cluster, aunque

20 Capítulo 4. Desarrollo
ha sido necesario modificarla.
Además de la instalación de Hadoop y Hbase, Apache Ambarí ofrece serviciosagregados que aportan valor al cluster, tales como la posibilidad de añadir o quitarnodos de manera visual así como la monitorización de la plataforma. Así mismo,ofrece una interfaz que nos permite modificar las configuraciones del cluster deuna manera rápida y consistente para todas los nodos. Por último, cuando ocurreuna anomalía en la plataforma, una alerta es disparada para poder actuar en con-secuencia.
En la figura 4.8 podemos observar la plataforma Apache Ambari instalada y fun-cionando.
FIGURA 4.8: Monitorización con Apache Ambari
4.5.3. Arquitectura del cluster
En esta apartado se comenta brevemente la distribución de los distintos com-ponentes en los distintos nodos del cluster.
En la figura 4.9 se puede observar los componentes del principales de HDFS y HBa-se y su distribución entre los distintos nodos. Se destaca el hecho de que el nodoblade39 no se está utilizando para guardar datos, sino que se encuentra únicamenteel cliente que realiza las peticiones y unos pocos componentes que no requierendemasiados recursos, y por lo tanto, no provoca que el cliente se convierta en elcuello de botella.
Se han omitido los flujos entre los distintos componentes ya que se trata del están-dar de HBase, no hay nada adicional, y restaría claridad al presentar la distribuciónde los componentes.

4.5. Instalación y configuración del entorno 21
FIGURA 4.9: Distribución de componentes
Se remarca que la figura 4.9 presenta el cluster base, a partir del cual es necesarioinstalar los gestores NoSQL adicionales, Apache Phoenix o Splice Machine.
4.5.4. Instalación de Apache Phoenix
La instalación de Apache Phoenix se realiza mediante la interfaz de ApacheAmbari, ya que la plataforma ofrece una integración nativa con Apache Phoenix.Esta versión es un poco antigua al tratarse de una versión de hace aproximadamen-te dos años, finales de 2015. Sin embargo, Apache Ambari no permite ni aconsejala actualización de un componente individual, por lo que las pruebas se han tenidoque realizar con la versión Apache Phoenix 4.7.1. Se ha intentado actualizar a laversión 4.10.0 sin éxito.
La instalación consiste en añadir a las librerías de HBase unas adicionales, las deApache Phoenix, que levantan un servidor escuchando las peticiones SQL que tra-duce a peticiones de HBase.
Se ha instalado el servidor de Apache Phoenix en cada uno de los nodos dondeestá presente HBase, quedando la arquitectura como se presenta en la figura 4.10.

22 Capítulo 4. Desarrollo
FIGURA 4.10: Distribución de componentes con Apache Phoenix
4.5.5. Instalación de Splice Machine
Apache Ambari no ofrece la posibilidad de instalar Splice Machine, por lo quees necesario realizar una instalación por manual. No obstante, debido a la popu-laridad de Apache Ambari , existe una guía adaptada donde se indica los pasosnecesarios para instalar Splice Machine, incluyendo las modificaciones que se de-ben realizar a nivel de Ambari o a nivel de sistema operativo.
La primera parte del proceso de instalación consiste en descargarse los ficherosy ejecutar unos scripts de instalación, los cuales copian unos ficheros en las carpe-tas de la instalación de HBase.
La segunda parte consiste en modificar las configuraciones de Hadoop, Zookeper yHBase con optimizaciones o modificaciones necesarias para utilizar las librerías deSplice Machine. Entre dichas modificaciones se destaca a nivel de Hadoop el nivelde replicación de los datos así como la memoria de los distintos componentes deHadoop.
A nivel de Zookeper es necesario modificar las conexiones máximas permitidasdesde un determinado cliente, ya que por defecto se permiten 20 concurrentes y enel caso de Splice puede resultar insuficiente.
Las principales modificaciones se tienen que realizar a nivel de HBase, donde Spli-ce Machine requiere unos modificaciones profundas de algunos parámetros. Entreellas se destaca la modificación de la memoria máxima de todos los componentes,número de conexiones permitidas, timeouts, etc. Aparte de dichas configuraciones,es necesario ajustar los coprocesadores de las peticiones de las regiones de HBase,para que en lugar de utilizar los establecidos por defecto, utilice los de Splice Ma-chine. Otra configuración destacable a nivel de HBase es que se modifica el Garbage

4.5. Instalación y configuración del entorno 23
Collector utilizado, marcando el Current Mark Sweep como el garbage collector autilizar en lugar del establecido por defecto.
Por último, los parámetros sugeridos por Splice Machine referentes a la memo-ria han sido necesarios adaptarlos, ya que entre sus requisitos Splice requiere quetodas las máquinas tengan 64GB de RAM, cantidad muy superior a los 8GB de losque se dispone en el cluster actual.
En la figura 4.11 se muestra la distribución de los componentes una vez instaladoy configurado el cluster. Todo lo que hay en color naranja, está relacionado con lainstalación de Splice Machine. Como se puede observar se añaden nuevos compo-nentes a HBase, añadiendo funciones a los regionservers que no están por defecto.
FIGURA 4.11: Distribución de componentes con Apache Phoenix
4.5.6. Preparación de las pruebas
Carga de datos
Tras instalar y configurar Hadoop, Hbase, Phoenix y otros componentes la me-moria disponible para los regionservers de 4Gb.
Aplicando el procedimiento descrito en la sección 4.4,calculamos los tamaños delas dos bases de datos, dando como resultado 12 Gb ( 3nodos∗4Gb/nodo) en el casode la base de datos normal y de 36Gb ( 3nodos ∗ 4Gb/nodo) en el caso de la base dedatos grande. Cada registro ocupa unos 110Kb, por lo tanto hacen falta alrededorde 11 millones de registros para la base de datos normal y unos 30 millones de re-gistros para la base de datos grande.
Se destaca que a pesar de que la memoria de los regionservers sea de 4gb y el ta-maño de la base de datos sea de 12Gb, no caben todos los datos en memoria. Hbasereserva memoria para buffers de escritura y buffers de lectura. Dependiendo delporcentaje que se le dé a cada tipo de operación, el tamaño del heap de los region-servers varía entre los 2gb y los 3gb. Por lo tanto, incluso con una base de datos

24 Capítulo 4. Desarrollo
tan pequeña es necesario frecuentes accesos a disco. Además, se tiene configuradoa nivel de hdfs un factor de replicación de 3, por lo que los datos están triplicadosen disco.
En el caso de la base de datos grande, los accesos al disco serán continuos porlo que los tiempos de respuesta, a priori, deberían ser superiores y el disco se con-vierta en cuello de botella.
Por defecto, se ha dejado la responsabilidad de distribuir los datos a HBase, sinembargo el resultado no ha sido del todo satisfactorios. Aparte de la tabla, USER-TABLE, utilizada para las pruebas, en HBase existen otras para los procesos inter-nos. Debido a esto, ha ocurrido que algunos regionservers tuvieran más regionesde la table USERTABLE que otros. Para solucionarlo, se ha realizado una interven-ción manual para mover algunas regiones a otros regionservers, distribuyendo asílas regiones con los datos de USERTABLE de una manera más equilibrada.
Esto aplica tanto a la base de datos creada con Apache Phoenix como con SpliceMachine.
Ejecución de las pruebas
Una vez instalada la plataforma, configurada y cargados los datos queda reali-zar las pruebas definidas. En una primera instancia se ha considerado la posibilidadde automatizar el proceso para que no haga falta intervención humana, sin embar-go se ha descartado debido al esfuerzo que supone en comparación con las ventajas.
La intervención humana necesaria es bastante limitada, únicamente se intervienepara restaurar la base de datos a un estado inicial, reiniciar el cluster y lanzar laprueba. El principal problema cuando se reinicia un cluster de HBase es que la dis-tribución de las regiones no quede uniforme entre todos los servidores, por lo quees necesario moverlas manualmente. Con el fin de asegurar la correcta distribuciónde los datos se ha optado por la realización manual de estos pasos.
Cada caso de prueba tiene un fichero con configuración propio, que es pasado alcliente YCSB en el momento de lanzar la ejecución del proceso. Crear un ficherode configuración diferente para cada prueba nos permite obtener una mejor traza-bilidad de las pruebas, así como la posibilidad de realizar más interaciones con lamisma configuración.
nohup ./ycsb -p workload_heavy_read_50t_475ops.properties-cp $CLASSPATH > workload_heavy_read_50t_475ops.out &
nohup ./ycsb -p workload_heavy_read_50t_950ops.properties-cp $CLASSPATH > workload_heavy_read_50t_950ops.out &
Nohup nos permite ejecutar en segundo plano la prueba sin necesidad de mantenerla conexión ssh activa, por lo que la comunicación con el cluster se limita a realizarlas operaciones anterior.

4.5. Instalación y configuración del entorno 25
Los resultados obtenidos son recogidos y guardados en una hoja de calculo queposteriormente permite realizar el análisis de los resultados.
4.5.7. Monitorización del proceso e identificación de cuellos de botella
Durante la ejecución de las pruebas se ha monitorizado el sistema con el ob-jetivo de encontrar qué componente se satura antes. Apache Ambari ofrece estafuncionalidad de caja ya que trae varios componentes que nos permiten monitori-zar tanto los sistemas como los componentes en sí. Aunque cumple su función, lasgráficas resultantes se muestran agrupando las métricas de todos los nodos, por loque si un nodo está muy saturado mientras que los otros están más liberados, losresultados conjuntos mostrarán que el cluster está liberado a pesar de que puedahaber un problema.
En la figura 4.12 se presenta un ejemplo de monitorización de una prueba de cargade HBase . Se puede observar como la velocidad de acceso a disco está alrededorde los 100Mbs por segundo. Sin embargo, aunque este dato es real no representacon suficiente detalle dónde está el problema en concreto.
FIGURA 4.12: Monitorización plataforma con Apache Ambari
Según la figura anterior el cluster no tiene ningún problema, sin embargo si ac-cedemos a los nodos podemos observar que algunos se encuentran sobresaturadosmientras que otros no tienen prácticamente carga. La figura 4.13 representa la si-tuación de los nodos cuando se llega al máximo throughput del sistema. Se puedeobservar como los procesos de los regionservers son los que más iowait tienen. ElIOWAIT indica cuanto por ciento del tiempo de ejecución de un determinado pro-ceso ha estado esperando por una operación de entrada o salida. En este caso, eliowait del 99 % indica que el cuello de botella se encuentra en el acceso a disco, enconcreto, acceso de lectura.
Esta situación se presenta en prácticamente todas las pruebas realizadas, siendomás acentuada en las pruebas con Apache Phoenix mientras que con Splice Machi-ne, aunque también se da la situación, ocurre en menor medida.

26 Capítulo 4. Desarrollo
FIGURA 4.13: Resultado IOTOP en un nodo
Por el otro lado, la memoria se utiliza prácticamente al máximo en todos losnodos, mientras que la CPU en las pruebas realizadas no resulta un problema. Lafigura 4.14 muestra el uso de recursos típico durante una prueba. Se puede observarcomo la memoria sí que llega ocuparse mientras que la CPU se mantiene en nivelesmuy bajos y estables.
FIGURA 4.14: Resultado HTOP en un nodo

27
Capítulo 5
Resultados
5.1. Resultado benchmark de Apache Phoenix
En esta sección se presenta y discute el resultado del benchmark de ApachePhoenix, tras aplicar el procedimiento especificado en la sección 4.4.
5.1.1. Benchmarking de la base de datos pequeña con alto porcentaje deescritura
En este apartado se explica las pruebas con un tamaño de base de datos pe-queño. En este caso de prueba, las operaciones realizadas son de tipo get y write,siendo un 50 % operaciones de lectura y un 50 % operaciones de escritura. Al haberun gran porcentaje de escritura, se ha configurado HBase para que asigne un 50 %de la memoria a los buffers y un 50 % a los buffers de lectura.
Resultado elección del número de clientes
Para la elección del número de clientes se han realizado las pruebas especifica-das en la sección 4.4. En la figura 5.1 se puede observar los resultados obtenidos dedichas pruebas. Se observa que a partir de los 100 clientes el número de operacio-nes se mantiene estable, incluso decae ligeramente, pero los tiempos de respuestaaumentan notablemente. Es por ello, que para el caso de pruebas con 50 % lectura,50 % escritura y un tamaño de base de datos 12Gb, se han elegido 100 clientes paraacceder a la base de datos concurrentemente.
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.1: Resultados número de clientes base de datos pequeñaalta escritura

28 Capítulo 5. Resultados
Resultados benchmarking
En la sección anterior se determinó que 100 es número de clientes óptimo pararealizar la prueba, al ser el número de clientes que mejor balance ofrece entre lalatencia y el número de operaciones.
En las pruebas realizadas para obtener el número de clientes óptimo, se ha obser-vado que el throughput máximo es de 2640 operaciones por segundo. De acuerdoa la especificación del plan de pruebas, sección 4.4, se van a realizar las pruebas conlos siguientes throughputs prefijados:
incremento = max_throughput/4; incremento = 2640/4 � 655
Se va a utilizar un incremento de 655 para calcular los valores intermedios de th-roughput para los cuales se va a medir la latencia. Los valores resultantes son [655,1310, 1965, 2650]. Para el último valor en lugar de utilizar un salto de 655 se haaumentado a 685, ya que puede ocurrir que en la prueba de selección de clienteshaya dado un valor ligeramente menor que en la prueba final.
En la figura 5.2 se presenta el resultado de las pruebas realizadas. Se puede ob-servar como el tiempo de escritura y lectura son bastante similares hasta prácti-camente llegar al máximo throughput del sistema, donde el tiempo de lectura sedispara mientras que el de escritura tiene un aumento más lineal.
FIGURA 5.2: Resultados con gran carga escritura base de datos pe-queña
5.1.2. Benchmarking de la base de datos pequeña con alto porcentaje delectura
En esta sección se presenta las pruebas realizadas con una base de datos peque-ña pero con alto porcentaje de lectura, en este caso, un 95 % de lectura y un 5 % deescritura.

5.1. Resultado benchmark de Apache Phoenix 29
Resultado elección del número de clientes
Al igual que en el apartado anterior, y según se especificó en la sección 4.4 con elplan de pruebas teórico, el primer paso es encontrar en número de clientes óptimo.
En la figura 5.3 se presenta los resultados de la prueba. De nuevo, se puede ob-servar como con los 100 clientes se alcanza prácticamente el máximo throughputofrecido y a pesar de aumentar el tiempo de respuesta con respecto a los 50 clientesconcurrentes, se asume debido al aumento de throughput en más de 100 operacio-nes por segundo.
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.3: Resultados número de clientes base de datos grandealta escritura
Resultados benchmarking
Con los 100 clientes seleccionados como número de clientes óptimo en la sec-ción anterior, se han obtenido 1574 operaciones por segundo. Con estos datos po-demos calcular los throughputs intermedios con los que se van a realizar las prue-bas. En este caso dan lugar a un incremento de 395 ( 1574/4) y los throughputs[395,790,1185,1600]. De nuevo se aumenta ligeramente el último umbral se poneun poquito por encima por si el sistema pudiera dar más de si.
En la figura 5.4 se presenta los resultados obtenidos con los datos mencionados.Se observa que el throughput máximo es inferior al obtenido en la sección anterior,debido principalmente a que el número de operaciones mayoritarias, en este casode lectura, cuesta más tiempo realizarlas.

30 Capítulo 5. Resultados
FIGURA 5.4: Resultados con gran carga escritura base de datos pe-queña
De nuevo se puede observar que el tiempo de escritura no varía mucho conrespecto al throughput, aunque aumenta, no es tan acelerado como en el caso delectura. Por el contrario, el tiempo de respuesta cuando se realizan pocas peticioneses muy bajo y prácticamente igual tanto para lectura como para escritura. A pesarde todo, se sigue tratando de tiempos bajos.
5.1.3. Benchmarking de la base de datos grande con alto porcentaje deescritura
En esta sección se realiza la prueba de rendimiento de la base de datos despuésde haber triplicado su tamaño, ocupando 36GB. En esta sección se va probar elrendimiento con una alta carga de escritura, siendo el 50 % de las operaciones deescritura y el 50 % de lectura.
Resultados elección del número de clientes
Para la elección del número de clientes se han realizadas las pruebas especifi-cadas en la sección 4.4. En la figura 5.7 se puede observar los resultados obtenidosen las pruebas realizadas. A partir de los 100 clientes el número de operacionesaumenta ligeramente, sin embargo el tiempo de lectura se incrementa en mayorcantidad. Es por ello, que para el caso de pruebas con 50 % lectura, 50 % escrituray un tamaño de base de datos 36GB, se han elegido 100 clientes para acceder a labase de datos concurrentemente.

5.1. Resultado benchmark de Apache Phoenix 31
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.5: Resultados número de clientes base de datos grandealta escritura
Resultados benchmarking
Con los 100 clientes seleccionado como número de clientes óptimo en la secciónanterior se han obtenido 2250 operaciones por segundo. Con estos datos podemoscalcular los throughputs intermedios con los que se van a realizar las pruebas. Eneste caso dan lugar a un incremento de 565 (2250/4) y los throughputs [565, 1130,1695 y 2260].
FIGURA 5.6: Resultados con gran carga escritura base de datos gran-de
De nuevo el resultado es parecido a todas las pruebas realizadas anteriormente;tiempos muy parecidos con pocas operaciones por segundo y un aumento conside-rable al llegar al limite del sistema. Con este tamaño de la base de datos el tiempode respuesta en el caso de escritura aumentó más que en las pruebas anteriores, conuna base de datos más pequeña, al alcanzar el máximo throughput.
5.1.4. Benchmarking de la base de datos grande con alto porcentaje delectura
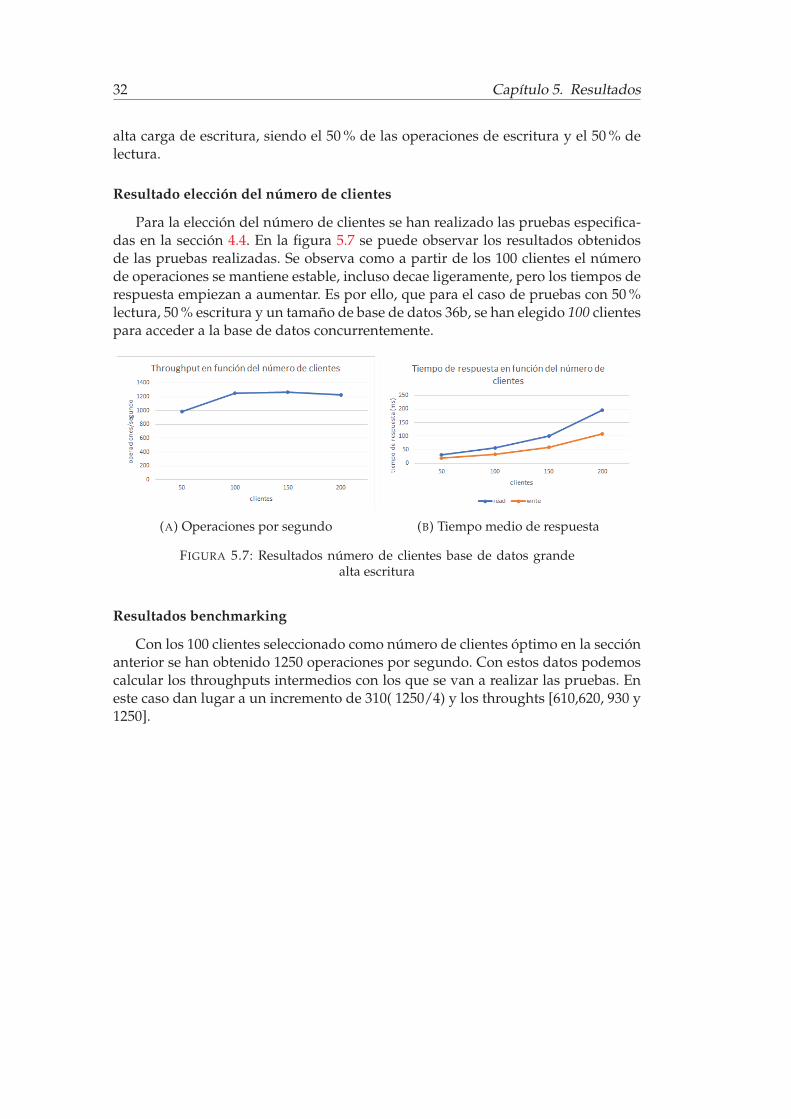
En esta sección se realiza la prueba de rendimiento de la base de datos despuésde haber triplicado su tamaño. En esta sección se va probar el rendimiento con una
32 Capítulo 5. Resultados
alta carga de escritura, siendo el 50 % de las operaciones de escritura y el 50 % delectura.
Resultado elección del número de clientes
Para la elección del número de clientes se han realizado las pruebas especifica-das en la sección 4.4. En la figura 5.7 se puede observar los resultados obtenidosde las pruebas realizadas. Se observa como a partir de los 100 clientes el númerode operaciones se mantiene estable, incluso decae ligeramente, pero los tiempos derespuesta empiezan a aumentar. Es por ello, que para el caso de pruebas con 50 %lectura, 50 % escritura y un tamaño de base de datos 36b, se han elegido 100 clientespara acceder a la base de datos concurrentemente.
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.7: Resultados número de clientes base de datos grandealta escritura
Resultados benchmarking
Con los 100 clientes seleccionado como número de clientes óptimo en la secciónanterior se han obtenido 1250 operaciones por segundo. Con estos datos podemoscalcular los throughputs intermedios con los que se van a realizar las pruebas. Eneste caso dan lugar a un incremento de 310( 1250/4) y los throughts [610,620, 930 y1250].

5.1. Resultado benchmark de Apache Phoenix 33
FIGURA 5.8: Resultados con gran carga de lectura base de datosgrande
Este es el caso en los que más altos se han obtenido los tiempos de respuesta,tanto para escritura como para lectura. Debido a ello, el thoughput máximo tam-bién es bastante inferior a todos los demás casos.
5.1.5. Discusión de resultados Apache Phoenix
En este apartado se discute los resultados obtenidos en las subsecciones ante-riores, analizando la diferencia de tiempos y de thoughput obtenido.
La primera observación es que los tiempos de escritura se mantienen siempre muypor debajo de los tiempos de lectura, al menos al alcanzar el máximo throughput.Esto se debe a que HBase está optimizado para escritura, guardando en memorialos datos escritos hasta que haya un número suficiente de datos como para ser or-denado y escrito a disco. Por lo tanto, la escritura siempre va ser más rápida quela lectura al no necesitar acceso a disco tan frecuente, y al hacerlo, es una escriturasecuencial lo cual contribuye a mejorar a rendimiento [10].
Un comportamiento similar se puede observar en un benchmark realizado porYahoo, dónde se medía el rendimiento de distintos sistemas no relacionales, entreellos HBase [3]. En ese estudio los tiempos de escritura igualmente se manteníanpor debajo de los de lectura, sin embargo había una diferencia mucho mayor queen el presente estudio dónde las diferencias, sobretodo en los throughputs bajos,son mínimas. Este comportamiento no es debido a Apache Phoenix, que en prue-bas sin transacciones, no presentes en este informe, se han obtenido tiempos muysimilares a HBase. El incremento de tiempo se debe al componente que maneja lastransacciones, Apache Tephra. Este componente es el que añade un incremente altiempo de escritura.
En la figura 5.9 se representa los tiempo de escritura en función del throughputmáximo obtenido en cada caso de prueba. Se puede observar como los tiemposson muy similares en un entorno con pocas operaciones por segundo, sin embargo,

34 Capítulo 5. Resultados
cuando se llaga al límite del sistema el tiempo de escritura se incremente cerca de50 % con un tamaño de base de datos grande.
FIGURA 5.9: Tiempos de escritura en función del throughput
Con respecto a los tiempos de lectura, en la figura 5.10 se puede observar comoel tiempo de lectura no aumenta tanto al variar el tamaño de la base de datos, perosí se ve un incremento entre el tipo de carga alto en lectura comparado con el deescritura. Se destaca que el comportamiento es muy similar en todos los casos, conpocas operaciones por segundo en todos los casos el tiempo de respuesta es muycontenido pero aumenta considerablemente al llegar a la máxima capacidad.
FIGURA 5.10: Tiempos de lectura en función del throughput
Por último, queda por analizar el número máximo de operaciones que se ob-tiene en cada prueba. En la figura 5.11 se puede observar claramente que aquellaspruebas con una alta carga de escritura obtiene un mayor número de operacionespor segundo. Esto se debe principalmente a que hay un mayor número de opera-ciones de escritura que, como se ha visto anteriormente, son más rápidas.

5.2. Benchmark de Splice Machine 35
Con respecto al tamaño de la base de datos, con un tamaño de base de datos pe-queño y una alta carga de escritura ( columnas small-50r y big-50r de la figura 5.11)se obtiene un 17 % más de operaciones por segundo que con un tamaño de base dedatos grande. En el caso de tener una alta carga de lectura, se obtiene un 25 % másde operaciones con una base de datos pequeña que con una grande.
FIGURA 5.11: Throughput en función del tamaño de la base de datosy el tipo de carga
5.2. Benchmark de Splice Machine
En esta sección se presenta todos los resultados obtenidos durante las pruebasde rendimiendo del sistema gestor de base de datos Splice Machine.
5.2.1. Benchmarking de la base de datos pequeña con alto porcentaje deescritura
En esta sección se presenta las pruebas realizadas con una base de datos peque-ña pero con alto porcentaje de escritura, en este caso, un 50 % de lectura y un 50 %de escritura.
Resultado elección del número de clientes
El procedimiendo seguido es el especificado en la sección 4.4 con el plan depruebas teórico. Por lo tanto el primer paso es encontrar el número de clientes óp-timo.
En la figura 5.14 se presenta los resultados de la prueba. Se puede observar co-mo con los 50 clientes se obtiene el throughput máximo, así como los tiempos derespuesta más bajos de todas las pruebas. Por lo tanto, el mejor número clientespara esta prueba es de 50.

36 Capítulo 5. Resultados
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.12: Resultados número de clientes base de datos pequeñaalta escritura
Se destaca que el tiempo de escritura es notablemente superior al de lectura,siendo el doble con pocos clientes y cuatro veces más con un número de clientesmuy elevado.
Resultados benchmarking
Con los 50 clientes seleccionado como número de clientes óptimo en la sec-ción anterior se han obtenido 1275 operaciones por segundo. Con estos datos po-demos calcular los throughputs intermedios con los que se van a realizar las prue-bas. En este caso dan lugar a un incremento de 320 ( 1275/4) y los throughputs[320,640,960,1280].
En la figura 5.13 se presenta los resultados obtenidos con el número de clientesseleccionado en el apartado anterior. Se observa como en todo momento el tiem-po de escritura es superior al tiempo de lectura, incluso en situaciones con pocasoperaciones por segundo.
FIGURA 5.13: Resultados con gran carga escritura base de datos pe-queña

5.2. Benchmark de Splice Machine 37
5.2.2. Benchmarking de la base de datos pequeña con alto porcentaje delectura
En esta sección se presenta las pruebas realizadas con una base de datos peque-ña pero con alto porcentaje de escritura, en este caso, un 95 % de lectura y un 5 %de escritura.
Resultado elección del número de clientes
En la figura 5.14 se presenta los resultados de la prueba. Se puede observar co-mo con los 50 clientes se obtiene más de 1410 operaciones por segundo, bastantecerca del máximo 1475 obtenido con 100 clientes. Sin embargo, con 100 clientes sepuede observar como el tiempo de escritura se duplica con respecto a 50 clientes.Por esta razón, para la prueba de rendimiento se van a utilizar 50 clientes concu-rrentes accediendo a la base de datos.
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.14: Resultados número de clientes base de datos pequeñaalta escritura
Resultados benchmarking
Con los 50 clientes seleccionados como número de clientes óptimo, en la sec-ción anterior se han obtenido 1418 operaciones por segundo. Con estos datos po-demos calcular los throughputs intermedios con los que se van a realizar las prue-bas. En este caso dan lugar a un incremento de 360 ( 1418/4) y los throughputs[360,720,1080,1440].
En la figura 5.15 se presenta los resultados obtenidos con el número de clientesobtenidos en el apartado anterior. En situaciones con pocas operaciones por segun-do, los tiempos están bastante controlados, por debajo de los 10-15 milisegundos.Sin embargo, cuando se llega al máximo throughput ofrecido por el sistema en es-tas condiciones, los tiempos de respuesta aumentan hasta los 50 y 15 milisegundos,para escritura y lectura respectivamente.

38 Capítulo 5. Resultados
FIGURA 5.15: Resultados con gran carga escritura base de datos pe-queña
5.2.3. Benchmarking de la base de datos grande con alto porcentaje deescritura
En esta sección se presenta las pruebas realizadas con una base de datos grandepero con alto porcentaje de escritura, en este caso, un 50 % de lectura y un 50 % deescritura.
Resultado elección del número de clientes
En la figura 5.16 se presenta los resultados de la prueba. Se puede observarcomo con los 50 clientes se obtiene alrededor de 1000 operaciones por segundo,cantidad que apenas es superada por los 100 clientes. Con 50 clientes se obtienenunos tiempos de respuesta, tanto en escritura como lectura, notablemente inferioresque con otros casos de prueba.
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.16: Resultados número de clientes base de datos pequeñaalta escritura

5.2. Benchmark de Splice Machine 39
Resultados benchmarking
Con los 50 clientes seleccionados como número de clientes óptimo en la sec-ción anterior se han obtenido 1418 operaciones por segundo. Con estos datos po-demos calcular los throughputs intermedios con los que se van a realizar las prue-bas. En este caso dan lugar a un incremento de 250 ( 1006/4) y los throughputs[250,500,750,1025].
En la figura 5.17 se presenta los resultados obtenidos con el número de clientesobtenido en el apartado anterior y los intervalos calculados previamente.
FIGURA 5.17: Resultados con gran carga escritura base de datos pe-queña
5.2.4. Benchmarking de la base de datos grande con alto porcentaje delectura
En esta sección se presenta las pruebas realizadas con una base de datos grandepero con alto porcentaje de escritura, en este caso, un 95 % de lectura y un 5 % deescritura.
Resultado elección del número de clientes
En la figura 5.18 se presenta los resultados de la prueba. Se puede observarcomo con los 50 clientes se obtiene alrededor de 1300 operaciones por segundo,cantidad superada con 100 clientes que llega a los 1375 operaciones por segundo.De nuevo, se opta por realizar la prueba con los 50 clientes ya que los tiempos derespuesta son notablemente inferiores.

40 Capítulo 5. Resultados
(A) Operaciones por segundo (B) Tiempo medio de respuesta
FIGURA 5.18: Resultados número de clientes base de datos pequeñaalta escritura
Resultados benchmarking
Con los 50 clientes seleccionados como número de clientes óptimo en la sec-ción anterior se han obtenido 1418 operaciones por segundo. Con estos datos po-demos calcular los throughputs intermedios con los que se van a realizar las prue-bas. En este caso dan lugar a un incremento de 335 ( 1300/4) y los throughputs[335,670,1005,1350].
En la figura 5.19 se presenta los resultados obtenidos con el número de clientesobtenido en el apartado anterior y los intervalos calculados previamente.
FIGURA 5.19: Resultados con gran carga escritura base de datos pe-queña
5.2.5. Discusión de resultados Splice Machine
En esta sección se van a discutir los resultados obtenidos en los apartados an-teriores, haciendo hincapié en las las diferencias obtenidas entre los distintos tiposde carga así como la influencia del tamaño de la base de datos en los tiempos obte-nidos.

5.2. Benchmark de Splice Machine 41
El primer dato que se destaca, es que el tiempo de escritura es superior al tiem-po de lectura. Teniendo en cuenta que HBase está optimizado para escritura, estecomportamiento implica perder el punto fuerte de HBase. Además, se observa quecuantas más operaciones concurrentes se realizan, los tiempos aumentan hasta lle-gar a limites inadmisibles.
Esto puede tener varias explicaciones, la primera puede ser debida a la implemen-tación que añade un cierto overload a las operaciones y que las situaciones comolas de la prueba, con muchas operaciones muy cortas y simples no sean las ópti-mas para este gestor. De hecho, en todas las presentaciones oficiales del productose hace hincapié en la lectura y en operaciones costosas, tales como operaciones deanalítica donde se involucran muchas tablas.
Otro motivo por el cual puede ocurrir que el tiempo de escritura sea considera-blemente más alto que usando HBase, es debido a la escasa memoria de la que dis-pone el sistema una vez instalado. En sus recomendaciones oficiales se recomiendanodos de 64GB de ram, de la cual hay que dedicar un 25 % a la escritura. En laconfiguración del cluster usado para el estudio, la memoria dedicada a la escrituraapenas llega a 1GB.
En la figura 5.20 se presenta los resultados conjuntos de escritura de las distintaspruebas realizadas. Se puede observar como los tiempos obtenidos son similares ensituaciones con pocas peticiones por segundo, pero los tiempos aumentan de ma-nera muy diferente cuando se llega al limite del sistema. El factor más influyenteen los tiempos de respuesta es el tamaño de la base de datos. Se puede observarque independientemente del tipo de carga, con un tamaño de base de datos grandelos tiempos obtenidos son peores que con una base de datos pequeña. De la mismafigura se puede deducir que el tipo de carga influye en los tiempos de respuesta,siendo las situaciones donde más número de operaciones de escritura hay la quemejor resultados ofrece.
Calculado los datos reales, se observa que con el máximo throughput el tiempode respuesta con una base de datos grande, independientemente del tipo de carga,se tarda alrededor de 50 % más en realizar una escritura, pasando de los 33 ms a los53ms en el caso de una base de datos pequeña y de 47 ms a los 69 ms en el caso dela base de datos grande.
Con respecto a los tiempos de lectura, en la figura 5.21 se presenta un gráfico conlos datos obtenidos. Se observa como los tiempos aumentan ligeramente, de mane-ra casi lineal en todos los casos hasta llegar al máximo throughput ofrecido por elsistema, momento en el cual los tiempos se disparan hasta 10 veces más, en el casode alta carga de lectura con una base de datos grande.

42 Capítulo 5. Resultados
FIGURA 5.20: Tiempos de escritura Splice Machine en función delthroughput
Los tiempos de lectura con un tamaño de base de datos grande, sin importar eltipo de carga ( alta en lectura o en escritura), superan en 100 % los obtenidos conun tamaño de base de datos pequeño.
FIGURA 5.21: Tiempos de lectura Splice Machine en función del th-roughput
Por último queda comparar las diferencias de throughput obtenidas en las dis-tintas pruebas realizadas. En la figura 5.22 se presentan las diferencias de through-put obtenidas en las distintas pruebas. Con un tamaño de base de datos pequeño,los resultados reflejan que el throughput es un 23 % mayor que con un tamaño debase de datos grande con una carga alta de escritura. Sin embargo, dicha diferenciase reduce a apenas un 5 % cuando el tipo de carga es alta en lectura.

5.3. Comparación de Apache Phoenix y Splice Machine 43
FIGURA 5.22: Throughput en función del tamaño de la base de datosy el tipo de carga
Un estudio similar [15] comparado distintas bases de datos NoSQL, muestraunos resultados parecidos a Apache Phoenix sobre HBase. El comportamiento deHBase del estudio mencionado, es similar al de Apache Phoenix dando lugar atiempos de respuesta muy parecidos, un thoughput máximo similar y un compor-tamiento con respecto al throughput muy parecido al del estudio. La única diferen-cia remarcable es el menor tiempo de respuesta de las operaciones de actualizaciónde HBase. Esto se justifica por la presencia de transacciones en Apache Phoenix,funcionalidad que aumenta el tiempo de respuesta en 10 ms.
5.3. Comparación de Apache Phoenix y Splice Machine
En esta sección se va comentar las diferencias obtenidas en el análisis del rendi-miento de ambos sistemas objeto de estudio, comparando los tiempos de respuesta,el throughput máximo así como otras diferencias en cuestiones de implementacióno configuración de ambos sistemas.
5.3.1. Comparación de las técnologias
La primera diferencia que nos encontramos entre ambos sistemas es la imposi-ción de unos requerimientos hardware mínimos por parte de Splice Machine y queen Apache Phoenix no existen. Splice Machine en su configuración recomendadaindica que las máquinas deben tener 64GB de memoria RAM y 16-32 hilos de eje-cución para su óptimo funcionamiento. HBase está pensado para ser ejecutado engrandes clusters de máquinas pequeñas y baratas ( commodity computing [5], porlo que estos requerimientos contradice la filosofía de HBase y reduce la posibilidadde su uso a empresas que no disponen de grandes recursos para la adquisición declusters con grandes máquinas.
En cuanto al proceso de instalación, aunque Apache Phoenix proviene de caja conplataformas como Hortonworks o Cloudera y por lo tanto no hay que realizar nin-guna acción, Splice Machine provee una guía didáctica bien explicada para todoslos entornos, lo cual permite la instalación por parte del personal sin demasiada

44 Capítulo 5. Resultados
trayectoria profesional en el sector. El mayor inconveniente de dichas guías es queestán adaptadas para un cluster que cumple los requerimientos expuestos ante-riormente, por lo que adaptarlos a unas máquinas diferentes requiere de bastantetiempo, sobretodo, si no se conoce como optimizar la JVM.
Apache Phoenix reside en Apache Tephra para ofrecer transacciones. En el mo-mento de creación de la tabla/s con Phoenix, es necesario indicar si dicha tabla estransaccional o no, pudiendo de esta manera con una único cluster de HBase y lamisma instalación de Phoenix tener tanto tablas transaccionales como no transac-cionales sin necesidad de modificar el cliente. De esta manera, en situaciones dondese puede vivir sin transacciones se puede obtener un mayor rendimiendo, alrede-dor del 30 % más se ha podido observar en unas pruebas anteriores a la instalaciónde Tephra. Por el contrario, en Splice Machine, la transaccionalidad está habilitadaa nivel de gestor afectando de esta manera a todas las tablas.
Como ya se comentó en la sección 4.1, descripción de las herramientas utilizadas,Apache Phoenix utiliza HBase para todas las operaciones, por ello el rendimien-to debería estar cercano al ofrecido directamente por HBase sin la intervención dePhoenix. Por el otro lado, Splice Machine delega gran parte del trabajo a Spark elcual realiza la operacion de escaneado y filtrado de los datos. Esto es especialmenteútil en operaciones complejas con joins implicados dónde es necesario realizar mu-chas operaciones de tipo scan. En este tipo de operaciones Splice Machine ofrece unrendimiento muy superior a Apache Phoenix, al menos eso indica Daniel Gómez,arquitecto de Splice Machine , en su publicación “Splice Machine: Architecture ofan Open Source RDMS powered by HBase and Spark” [7].
5.3.2. Comparación de resultados
En esta sección se explica las diferencias encontradas entre los resultados obte-nidos con Apache Phoenix y Splice Machine, tratando de dar una explicación a lasposibles causas del comportamiento obtenido.
La primera gran diferencia que reflejan los resultados es el número de clientes óp-timo para las pruebas. Como se ha visto en apartados anteriores, sección 5.1 paraApache Phoenix, sección 5.2 para Splice Machine, el número de clientes óptimo va-ria considerablemente entre los dos sistemas. Con Apache Phoenix el mejor balanceentre operaciones por segundo y tiempos de respuesta se obtiene con 100 clientesaccediendo concurrentemente, mientras que con Splice Machine a partir de los 50clientes los tiempos de respuesta se degradan considerablemente. En las pruebasrealizadas, con transacciones cortas y simples, poder atender más clientes concu-rrentemente es punto importante.
La figura 5.23 muestra las diferencias en los throughputs máximos obtenidos enfunción de la tecnología y los tipos de carga. Se puede observar como el número deoperaciones por segundo obtenido de Apache Phoenix es notablemente superior( 2637 ops/seg vs 1262 ops/seg de Splice Machine con un tamaño pequeño) conuna alta carga de escritura (50 % de las operaciones), mientras que en situacionescon una alta carga de lectura ( 95 % de las operaciones) los resultados son similares

5.3. Comparación de Apache Phoenix y Splice Machine 45
(1574 ops/seg vs 1410 ops/seg de Splice Machine con un tamaño de bases de da-tos pequeño). Este comportamiento se debe a que las operaciones de escritura enApache Phoenix son mucho más rápidas que las de Splice Machine(35 ms vs 54 mstamaño base de datos grande), por lo que nos permite realizar más operaciones enun determinado tiempo. Por el contrario, cuando la carga de trabajo es intensiva enlectura, el rendimiento obtenido es similar independientemente del tamaño de labase de datos.
FIGURA 5.23: Phoenix y Splice máximo throughput
Los tiempos obtenidos en las dos tecnologías son totalmente opuestos, tal ycomo se puede observar en la figura 5.24. Apache Phoenix requiere de un mayortiempo para realizar una operación de lectura mientras que en Splice Machine lasoperaciones más costosas son las de escritura. Con un tamaño de base de datosgrande, las operaciones de lectura de Phoenix incrementan su tiempo de respuestaen mayor proporción que Splice Machine dando lugar a un throughput medio simi-lar con ambas tecnologías. Los peores tiempos de lectura de Phoenix “compensan”los peores tiempo de escritura de Splice, dando así una media parecida en amboscasos.
(A) Tiempo medio de escritura (B) Tiempo medio de lectura
FIGURA 5.24: Tiempo medio de respuesta por tecnología
La razón del menor incremento en el tiempo medio de lectura en el caso de Spli-ce Machine puede encontrarse en el número de clientes, un menor número de clien-tes requiere menos uso de disco concurrente. Durante la realización de las pruebas

46 Capítulo 5. Resultados
las máquinas estaban siendo monitorizadas tratando de identificar el cuello de bo-tella. Durante la prueba de Apache Phoenix con un tamaño de base de datos grandese alcanza la máxima velocidad de lectura de disco, provocando colas en los pro-cesos que necesitaban leer. Este comportamiento no se ha observado en el caso deSplice Machine, donde el iowait de los procesos se encontraba alrededor del 20 %frente al 99 % de Apache Phoenix.

47
Capítulo 6
Conclusiones
El presente trabajo ha permitido realizar el estudio y comparación de dos delas tecnologías emergentes más prometedoras en el mundo de las bases de datos,Apache Phoenix y Splice Machine, centrándose principalmente en aspectos relacio-nados con el rendimiento.
La primera gran diferencia entre las dos tecnologías la podemos encontrar en lainstalación y configuración de las mismas. La facilidad y rapidez de instalación eintegración de Apache Phoenix con respecto a Splice Machine abre la puerta a unarápida prueba de concepto con el producto sin necesidad de una grande infraes-tructura o conocimientos.
El número máximo de operaciones ofrecidas por cada sistema varían considera-blemente en un entorno con pocos datos, dónde Apache Phoenix ofrece un rendi-miento muy superior a Splice Machine. En situaciones con grandes cantidades dedatos, el rendimiento obtenido es similar.
Los tiempos de respuesta entre los dos sistemas manifiestan un comportamientocontrario, siendo en Apache Phoenix las operaciones de lectura las más costosasmientras que en Splice Machine esta situación se encuentra en las peticiones de es-critura.
En un entorno con operaciones simples, cortas y rápidas Apache Phoenix es laelección más acertada, aunque ambos sistemas se pueden utilizar en este tipo decontexto. En situaciones con operaciones complejas, incluyendo varias operacionesde tipo join, Splice Machine teóricamente ofrece mejores resultados. Las pruebas deelección del cliente para realizar el estudio sugiere este comportamiento.
El comportamiento de ambos sistemas se ve muy influenciado por el tamaño dela base de datos. A pesar de que en ninguna prueba los datos entraban en su totali-dad en memoria, el rendimiento es notablemente superior con un tamaño de basede datos pequeño.


49
Capítulo 7
Líneas futuras
En esta sección se exponen las futuras líneas de investigación en base al proyec-to realizado.
El presente proyecto se ha realizado usando como cliente la herramienta YCSB, lacual es muy potente pero a la vez sencilla, tanto que no se ajusta a los casos de usosreales de una empresa. Por ello, una línea de investigación interesante sería realizareste proyecto con el otro cliente evaluado, Escada TPC-C, y analizar su rendimien-to. No obstante, el trabajo debería estar enfocado en optimizar Apache Phoenixy/o Splice Machine para realizar consultas relaciones y utilizar Escada TPC-C paravalidar los resultados. Está línea de investigación es tan compleja que podría darlugar a un trabajo fin de máster completo.
Otro análisis interesante sería realizar el mismo estudio con distinto número deservidores, empezando con un número pequeño y una base de datos pequeña paraposteriormente aumentar máquinas, cargas, y clientes. Esto nos permitiría medir laescalabilidad y la elasticidad del sistema, parámetros que en el presente trabajo nose ha podido realizar debido al reducido número de máquinas.
En el presente estudio se han analizado los sistemas Apache Phoenix y Splice Ma-chine, dos sistemas que se añaden por encima de Hbase y que realizan unas ope-raciones antes de enviar la consulta definitiva a Hbase. Será interesante medir eloverhead que supone utilizar estos sistemas en lugar de Hbase directamente, oen otras palabras, cuanto se realiza una consulta por realizarla con Apache Phoe-nix/Splice Machine con respecto a realizarla directamente sobre Hbase.
Otro aspecto a destacar y que merece ser investigado es si el comportamiento deSplice Machine varía al cumplir los requisitos mínimos expuestos por la compañía.En ellos, se indica que las máquinas deben ser de al menos 64Gb de ram con unmínimo de 4 máquinas. Dichos requisitos no los hemos podido cumplir por lo queel rendimiento ofrecido por Splice Machine puede no ser proporcional, sino muchopeor.


51
Apéndice A
Distribuciones
El cliente necesita realizar operaciones constantemente que nos permitan ana-lizar el rendimiento del sistema. Las operaciones a realizar(Lectura, Inserción, Ac-tualización o Escaneo) deben ser elegidas de manera aleatoria así como los datos aleer o insertar, longitud del escaneo, etc.
YCSB contiene varias distribuciones "de caja":
Uniforme: Sigue una distribución uniforme a la hora de elegir los elementos,es decir, cada elemento tiene la misma probabilidad de ser elegido.
Zipf: La elección de un elemento se realiza según la distribución Zipf, dondeunos elementos son muy populares, y por lo tanto serán leídos muchas veces,mientras que otros tendrán una probabilidad muy baja de ser elegidos.
Latest: Es lo mismo que la distribución Zipf salvo que los elementos elegidosson los últimos insertados.
Multinomial: Distribución especificada por el usuario, por ejemplo, especifi-cando un 90 % a la lectura y un 10 % a actualización de datos, dando de estamanera a una prueba de carga principalmente de lectura.


53
Bibliografía
[1] Apache HBase overview. URL: https://es.hortonworks.com/apache/hbase/.
[2] Joseph Blakeman. Benchmarking: Definitions and Overview. 2002. URL: https://www4.uwm.edu/cuts/bench/bm-desc.htm (visitado 15-01-2017).
[3] Erwin Tam Raghu Ramakrishnan Russell Sears Brian F. Cooper Adam Sil-berstein. Benchmarking Cloud Serving Systems with YCSB. 2010. URL: https://www.cs.duke.edu/courses/fall13/cps296.4/838-CloudPapers/ycsb.pdf.
[4] Different Types of Benchmarks. URL: https://www.cs.umd.edu/class/fall2001/cmsc411/projects/morebenchmarks/types.html.
[5] John E. Dorband. Commodity Computing Clusters at Goddard Space Flight Cen-ter. 2002. URL: https://spacejournal.ohio.edu/pdf/Dorband.pdf(visitado 21-06-2017).
[6] EMC. The Digital Universe of Opportunities: Rich Data and the Increasing Va-lue of the Internet of Things. Sep. de 2014. URL: http://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm (visitado 16-01-2017).
[7] Daniel Gómez Ferro. Splice Machine: Architecture of an Open Source RDMS po-wered by HBase and Spark. Ene. de 2017. URL: https://es.slideshare.net/DanielGmezFerro/splice-machine-architecture-of-an-open-source-rdms-powered-by-hbase-and-spark.
[8] Mikal Khoso. How Much Data is Produced Every Day? Mayo de 2016. URL:http://www.northeastern.edu/levelblog/2016/05/13/how-much-data-produced-every-day/.
[9] John Leach. Spark as part of a Hybrid RDBMS Architecture. 2016. URL: https://es.slideshare.net/sawjd/spark-as-part-of-a-hybrid-rdbms- architecturejohn- leach- cofounder- splice- machine(visitado 16-06-2017).
[10] Carol McDonald. An In-Depth Look At the HBase Architecture. Ago. de 2015.URL: https://mapr.com/blog/in-depth-look-hbase-architecture/(visitado 21-06-2017).
[11] Apache Phoenix Organization. Transforming HBase into a Relational Database.2014. URL: https://phoenix.apache.org/presentations/OC-HUG-2014-10-4x3.pdf.
[12] PMI. A Guide to the Project Management Body of Knowledge. 2013. URL: http://www.pmi.org/PMBOK- Guide- and- Standards.aspx (visitado08-11-2016).

54 BIBLIOGRAFÍA
[13] J. Scott Slater. Why You Should Benchmark, and Tips for Effective Benchmarking.Feb. de 2012. URL: http://www.thinkadvisor.com/2012/02/24/why-you-should-benchmark-and-tips-for-effective-be (visita-do 02-03-2017).
[14] Van Gerwen Ingrid Moerman Stefan Bouckaert Jono Vanhie. Benchmarkingcomputers and computer networks. 2007. URL: https://www.ict-fire.eu/wp- content/uploads/Whitepaperonbenchmarking_V2.pdf(visitado 15-12-2016).
[15] Sergey Sverchkov. Feb. de 2014. URL: https://jaxenter.com/evaluating-nosql - performance - which - database - is - right - for - your -data-107481.html (visitado 27-06-2017).