eth zurich – distributed computing group jasmin smula 1eth zurich – distributed computing – ...
Post on 20-Dec-2015
225 views
TRANSCRIPT

ETH Zurich – Distributed Computing Group Jasmin Smula 1ETH Zurich – Distributed Computing – www.disco.ethz.ch
Stephan HolzerYvonne Anne Pignolet
Jasmin SmulaRoger Wattenhofer
Monitoring Churn in Wireless Networks

ETH Zurich – Distributed Computing Group Jasmin Smula 2
Motivation / Intro
Network of sensor nodes:
Nodes might fail / nodes may be added
All nodes should be aware of all present nodes
• with small delay
• with little energy consumption
• using few channels for communication
• wireless, communicating on several channels
• battery powered
• measuring certain properties of their environment
ETH Zurich – Distributed Computing Group Jasmin Smula 3
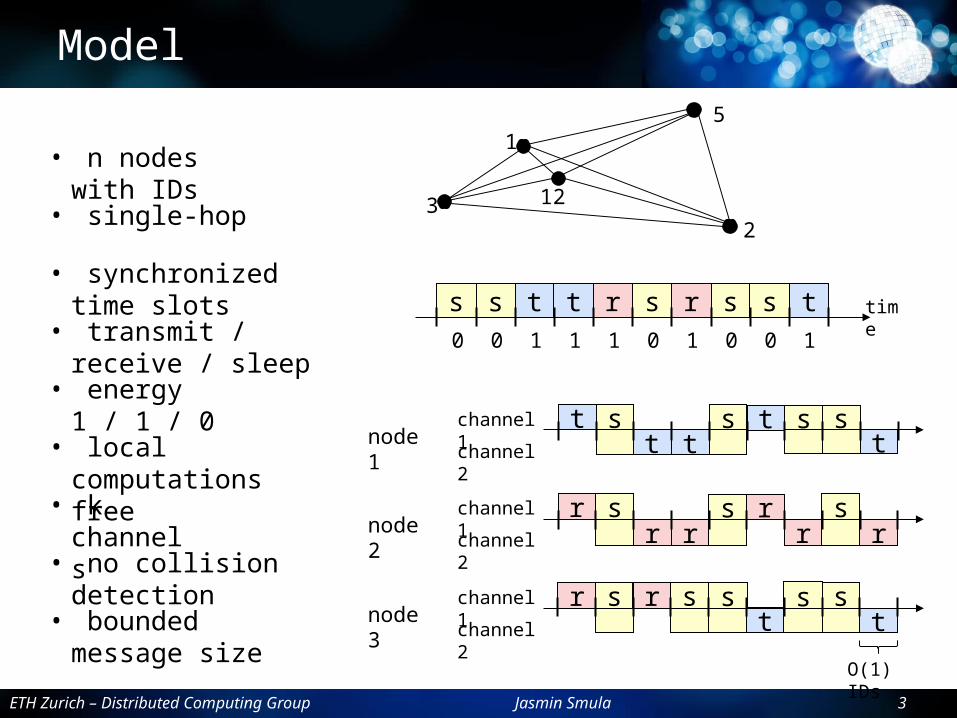
Model
• n nodes with IDs
• single-hop
• synchronized time slots
• transmit / receive / sleep
• k channels
• no collision detection
• energy 1 / 1 / 0
10 1 100 0 101
3
15
12
2
tssttss r s r time
tt
st
s tt
ssnode 1
node 2
node 3
channel 1
channel 2
channel 1
channel 2
channel 1
channel 2
O(1) IDs
rr s
r rs r
rs
r s r st
st
s s• bounded message
size
• local computations free

ETH Zurich – Distributed Computing Group Jasmin Smula 4
7
Model cont’d
Nodes may join or crash at any time
Adversary:May let nodes crash or join in order to make an algorithm fail
3
15
12
23
15
2churn = joins and crashes
burst = large number of joins and crashes in short time

ETH Zurich – Distributed Computing Group Jasmin Smula 5
Goal
Every node must know the IDs of all nodes currently in the network
1 2 3 5 7 12

ETH Zurich – Distributed Computing Group Jasmin Smula 6
Simple Lower Bounds
What time / energy is at least necessary in this model?
• every node can only receive one message per time slot containing at most a constant number of IDs
Ω(b) time slots necessary to learn about b joins / crashes
every node needs Ω(b) energy units to learn about b joins / crashes
on average only constant rate of churn tolerable per time slot

ETH Zurich – Distributed Computing Group Jasmin Smula 7
Results
• tolerates churn bursts in any order of magnitude
Our Monitoring Algorithm:
• handles asymptotically maximum average rate of churn tolerable in this model
• needs Θ(n/log n) channels
• after each burst of size b it takes• O(b + log n) time slots and• O(b + log n) energy per node
until all nodes have updated their ID table (optimal up to additive logarithmic term)
• is deterministic except for detection of joining nodes

ETH Zurich – Distributed Computing Group Jasmin Smula 8
Results cont‘d
Our Monitoring Algorithm:
• can get by with less than Θ(n/log n) channels:
• k channels available time .
n
b
k
nbO
loglog
ETH Zurich – Distributed Computing Group Jasmin Smula 9
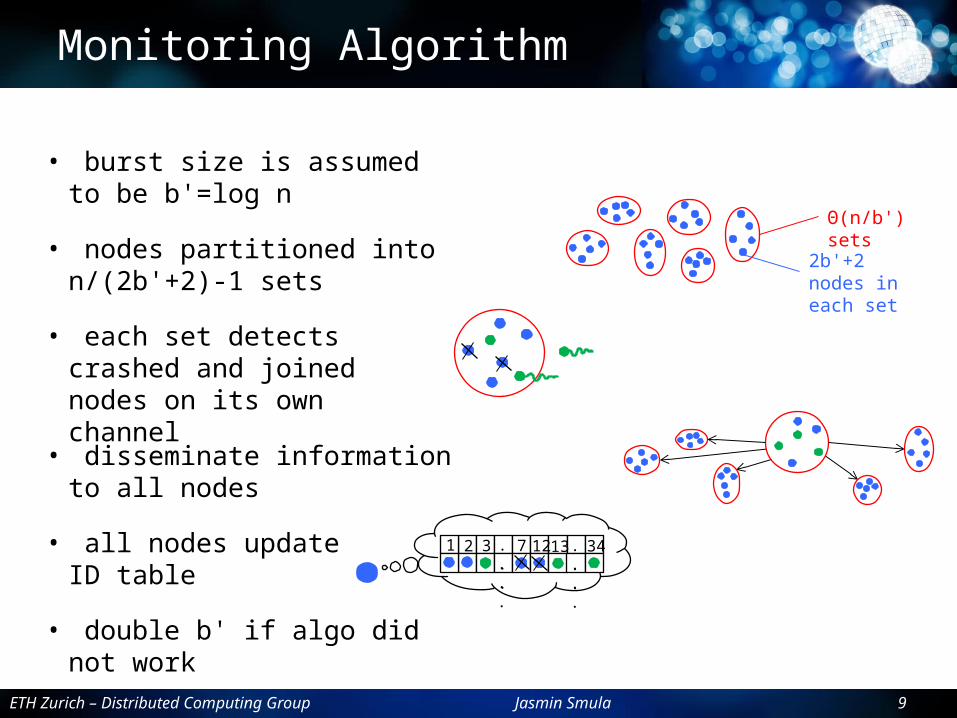
Monitoring Algorithm
• burst size is assumed to be b'=log n
• nodes partitioned into n/(2b'+2)-1 sets
• each set detects crashed and joined nodes on its own channel
• disseminate information to all nodes
• all nodes update ID table
• double b' if algo did not work
2b'+2 nodes in each set
Θ(n/b') sets
1 2 ......
7 12 ......
3 13 34
ETH Zurich – Distributed Computing Group Jasmin Smula 10
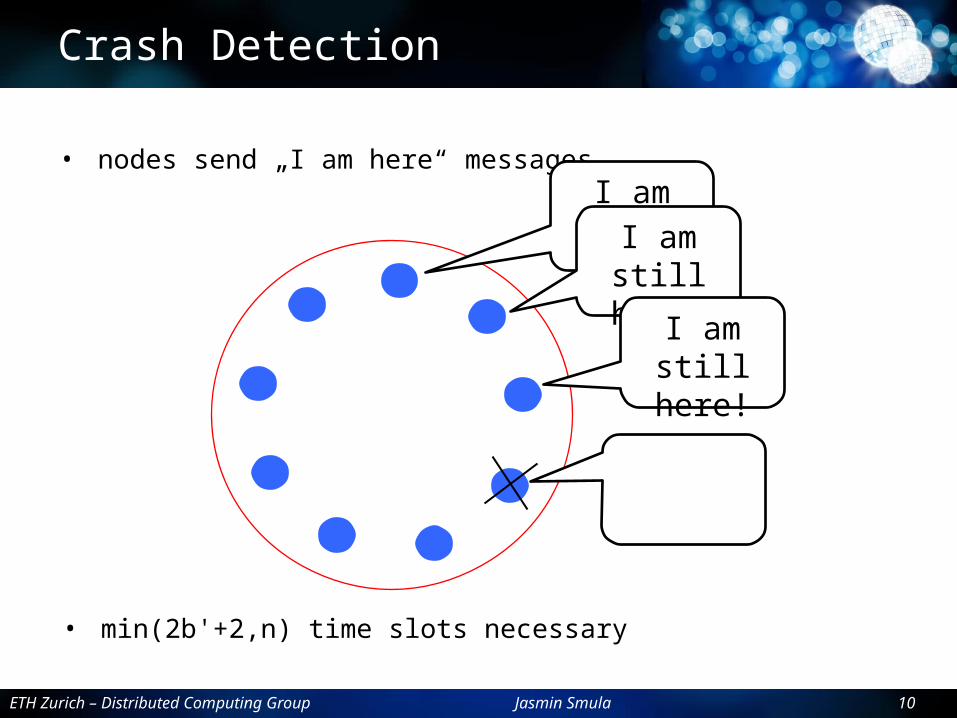
Crash Detection
• nodes send „I am here“ messagesI am still
here!I am still here!
I am still here!
• min(2b'+2,n) time slots necessary

ETH Zurich – Distributed Computing Group Jasmin Smula 11
Join Detection
Set S1
• joiners send join requests to with S1 with probability 1/b'
I want to join!
I want to join!
• b' in Ω(b) in constant number of rounds at least 1 joiner

ETH Zurich – Distributed Computing Group Jasmin Smula 12
Information Dissemination
• every set becomes vertex of balanced binary tree
• every set forwards information on node v with smallest ID first
• information on v disseminated after O(log n) time slots
depth log n
• all information disseminated after O(log n + b') time slots

ETH Zurich – Distributed Computing Group Jasmin Smula 13
Monitoring Algorithm
• b' = log n
• partitioning
• crash detection
• dissemination
• update ID table
• double b'
log(b/log n) times
runtimeO(b + log n)
Time
O(1)
O(1)
O(1)
O(1)
O(min(b', n))
O(b' + log n)
Step
1 2 ......
7 12 ...3 13 34...
• join detection O(b' + log n)

ETH Zurich – Distributed Computing Group Jasmin Smula 14
What if critical nodes crash?
• in each set node which is responsible for communication with other sets = representative
• all other nodes replacements
• replacements take over if representative does not send
• delay of at most b'
• still runtime of O(b' + log n) per round

ETH Zurich – Distributed Computing Group Jasmin Smula 15
Conclusions & Future Work
• Model tssttss r s r
• Lower Bounds
• Monitoring Algorithm
• Future Work: Multi-hop

ETH Zurich – Distributed Computing Group Jasmin Smula 16ETH Zurich – Distributed Computing – www.disco.ethz.ch
Stephan HolzerYvonne Anne Pignolet
Jasmin SmulaRoger Wattenhofer
Thank You!Questions & Comments?