event extraction using distant supervision kevin reschke, mihai surdeanu, martin jankowiak, david...
TRANSCRIPT

Event Extraction Using Distant Supervision
Kevin Reschke, Mihai Surdeanu, Martin Jankowiak, David McClosky, Christopher Manning
Nov 15, 2012

2
Event Extraction
• Slot filling for event templates.
Plane Crashes<Crash Site><Operator/Airline><Aircraft Type><#Fatalities><#Injuries><#Survivors><#Crew><#Passengers>
Terrorist Attacks<Location><Perpetrator><Instrument><Target><Victim>
Corporate Joint Ventures<Entity><Ownership><Activity><Name><Aliases><Location><Nationality><Type>

3
Event Extraction: High Level
• Candidate Generation
• Mention Classification
• Label Merging

4
Mention Classification
US Airways Flight 133 crashed in Toronto.
• “crashed in,” NEType=Location, syntactic dependency (crashed, Toronto).
• Training a classifier:• Supervised (See ACE and MUC tasks).• Unsupervised (See Chambers and Jurafsky ACL2011)• Distantly Supervised

5
Distant Supervision (High Level)
• Begin with set of known events.
• Use this set to automatically label mentions.
• Train and classify (handle noise)

6
Distant Supervision for Relation Extraction
• KBP-TAC 2011: Slot filling for named entity relations.• E.g.:
• Company: <ceo of>, <founder of>, <founding date>, <city of headquarters>, etc.
• Known relations: founder_of(Steve Jobs, Apple)
• Noisy Labeling Rule: Slot value and entity name must be in same sentence.• Apple co-founder Steve Jobs passed away yesterday.• Steve Jobs delivered the Stanford commencement
address.• Steve Jobs was fired from Apple in 1985.

7
Distant Supervision for Event Extraction
• E.g., Known events: <CrashSite = Bermuda>• Noisy Labeling Rule: slot value and event name must be in same
sentence.• Doesn’t work!
1. What is the name of an event? (“The crash of USAir Flight 11”)2. Slots values occur separate from names.
• The plane went down in central Texas.• 10 died and 30 were injured in yesterday’s tragic incident.
• Solution: Document Level Noisy Labeling Rule.

8
Task: Plane Crash Event Extraction
• 80 plane crashes from Wikipedia.• 32 train; 8 dev; 40 test

9
Infoboxes to Event Templates
<Flight Number = Flight 3272><Site = Monroe, Michigan, USA><Passengers = 26><Crew = 3><Fatalities = 29><Survivors = 0><Aircraft Type = Embraer 120 RT Brasilia><Operator = Comair, Delta Connection>
Labels for mention classification: <NIL>, Site, Passenger, Crew, Fatalities, Survivors, Aircraft Type, Operator, Injuries

10
Newswire Corpus
• Corpus: newswire docs from 1988 to present.
• Preprocessing: POS, Dependencies and NER with Stanford NLP Pipeline.

11
Automatic Labeling
• Use Flight Number as proxy for event name.• Rule: if doc contains Flight Number, it is relevant to event.• Noise:
• Hand check 50 per label• 39% are bad.• E.g., Good: At least 52 people survived the crash of the Boeing 767. Bad: First envisioned in 1964, the Boeing 737 entered service in 1968.• Bad labels are concentrated on common words: two, Brazil, etc.• Future work: reduce noise by avoiding common words in training set.

12
Label Merging
• Exhaustive Aggregation
Four <NIL>Four <Crew>Four <Crew>Four <Fatalities>Four <NIL>Four <NIL>
<Crew> <Fatalities>
Shanghai <NIL>Shanghai <NIL>Shanghai <NIL>Shanghai <NIL>Shanghai <NIL>
<NIL>

13
Test Time
• Task: Given a Flight Number, fill remaining slots.
• Metric: Multiclass Precision and Recall• Precision: # correct (non-NIL) guesses / total (non-NIL) guesses• Recall: # slots correctly filled / # slots possibly filled

14
Experiment 1: Simple Local Classifier
• Multiclass Logistic Regression• Features: unigrams, POS, NETypes, part of doc, dependencies
• E.g.: US Airways Flight 133 crashed in TorontoLexIncEdge-prep_in-crash-VBDUnLexIncEdge-prep_in-VBDPREV_WORD-in2ndPREV_WORD-crashNEType-LOCATIONSent-NEType-ORGANIZATIONetc.

15
Experiment 1: Simple Local Classifier
• Baseline: Majority Class Classifier (Maj)• Distribution of test set labels:
• <NIL> 19196 (with subsampling)• Site 10365 LOCATION• Operator 4869 ORGANIZATION• Fatalities 2241 NUMBER• Aircraft_Type 1028 ORGANIZATION• Crew 470 NUMBER• Survivors 143 NUMBER• Passengers 121 NUMBER• Injuries 0 NUMBER

16
Experiment 1: Simple Local Classifier
• Results• vary <NIL> class priors to maximize F1-score on dev-set.
Maj 0.11 0.17
Local 0.26 0.30
Maj 0.026 0.237
Local 0.159 0.407
Dev Set prec/recall (8 events; 23 findable slots)
Test Set prec/recall (40 events; 135 findable slots)

17
Experiment 1: Simple Local Classifier
• Accuracy of Local, by slot type.
Site 8/50 0.16
Operator 5/25 0.20
Fatalities 7/35 0.20
Aircraft_Type 4/19 0.21
Crew 15/170 0.09
Survivors 1/1 1.0
Passengers 11/42 0.26
Injuries 0/0 NA

18
Experiment 2: Training Set Bias
• Number of relevant documents per event
Series1
1
10
100
1000
10000
Pan Am Flight 103(a.k.a. The Lockerbie Bombing)

19
Experiment 2: Training Set Bias
• Does a more balanced training set improve performance?• Train new model with only 200 documents for Flight 103.• Results On Dev (prec/rec):
LocalBalanced (0.30 / 0.13) Local (0.26 / 0.30)
• Is difference due to balance, or less data?• Train new model with all 3456 docs for Flight 103, but use 24
events instead of 32.• Results On Dev (prec/rec): (0.33 / 0.13)

20
Experiment 3: Sentence Relevance
• Problem: a lot of errors come from sentences that are irrelevant to event.• E.g.: Clay Foushee, vice president for flying operations for Northwest
Airlines, which also once suffered from a coalition of different pilot cultures, said the process is “long and involved and acrimonious.”
• Solution: Only extract values from “relevant” sentences.• Train binary relevance classifier (unigram/bigram features).• Noisly label training data: a training sentence is relevant iff it contains at
least one slot value from some event.

21
Experiment 3: Sentence Relevance
• New Mention Classifiers:• LocalWithHardSent: All mention from non-relevant sentences are <NIL>• LocalWithSoftSent: Use sentence relevance as a feature.
• Initial results; dev set; no tuning (prec/rec)Local (0.18/0.30) HardSent (0.21/0.17) SoftSent(0.22/0.17)
• Final results: with tuned <NIL> class priors: Dev Set
Local (0.26/0.30) HardSent (0.25/0.17) SoftSent(0.25/0.17)
Test SetLocal (0.16/0.40) HardSent (0.12/0.24) SoftSent(0.11/0.23)

22
Experiment 3: Sentence Relevance
• Why did sentence relevance hurt performance?
• Possibility: sentence relevance causes overfitting.• …But, Local outperforms others on training set.
• Other possibilities?

23
Experiment 4: Pipeline Model
• Intuition: There are dependencies between labels.E.g., Crew and Passenger go together: 4 crew and 200 passengers were on board. Site often follows Site: The plane crash landed in Beijing, China. Fatalities never follows Fatalities * 20 died and 30 were killed in last Wednesday’s crash.
• Solution: A Pipeline Model where previous label is a feature.

24
Experiment 4: Pipeline Model
• Results.• Dev Set (prec/rec)
• Test Set (prec/rec)
Local 0.26 0.30
Pipeline 0.24 0.30
Pipeline w/ SentRel 0.24 0.17
Local 0.159 0.407
Pipeline 0.154 0.422
Pipeline w/ SentRel 0.107 0.259

25
Experiment 5: Joint Model
• Problem: Pipeline Models propagate error.
20 dead, 15 injured in a USAirways Boeing 747 crash.Gold: Fat. Inj. Oper. A.Type.
Pred: Fat. Surv. ?? ??

26
Experiment 5: Joint Model
• Problem: Pipeline Models propagate error.
20 dead, 15 injured in a USAirways Boeing 747 crash.Gold: Fat. Inj. Oper. A.Type.
Pred: Fat. Surv. ?? ??
Gold: Fat. Fat. Oper. A.Type.
Pred: Fat. Inj. ?? ??

27
Experiment 5: Joint Model
• Solution: The Searn Algorithm (Daumé III et al., 2009)• Searn: Search-based Structured Prediction
20 15 USAir
Boe.747

28
Experiment 5: Joint Model
A Searn Iteration:For a mention m in sentence s: Step 1: Classify all mentions left of m using current hypothesis. Step 2: Use these decision as features for m. Step 3: Pick a label y for m. Step 4: Given m = y, classify all mentions right of m with current hypothesis Step 5: Compare whole sentence to gold labels. Step 6: Set cost for m = y to #errors Repeat 2-5 for all possible labels. Repeat 1-6 for all mentions and sentence. You now have a cost vector for each mention. Train a Cost Sensitive Classifier then interpolate with current hypothesis.
20 15 USAirBoe.747

29
Experiment 5: Joint Model
• Cost Sensitive Classifier.• We use a Passive-Aggressive Multiclass Perceptron (Cramer et al., 2006)
• Results• Dev Set (prec/rec) Local (0.26/0.30) Searn (0.35/0.35) SearnSent (0.30/0.30)
• TestSet (prec/rec) Local (0.159/0.407) Searn (0.213/0.422) SearnSent (0.182/0.407)

30
Experiment 5: Joint Model
• Problem: Pipeline Models propagate error.
20 dead, 15 injured in a USAirways Boeing 747 crash.Gold: Fat. Inj. Oper. A.Type.
Pred: Fat. Surv. ?? ??
Let’s try a CRF model…
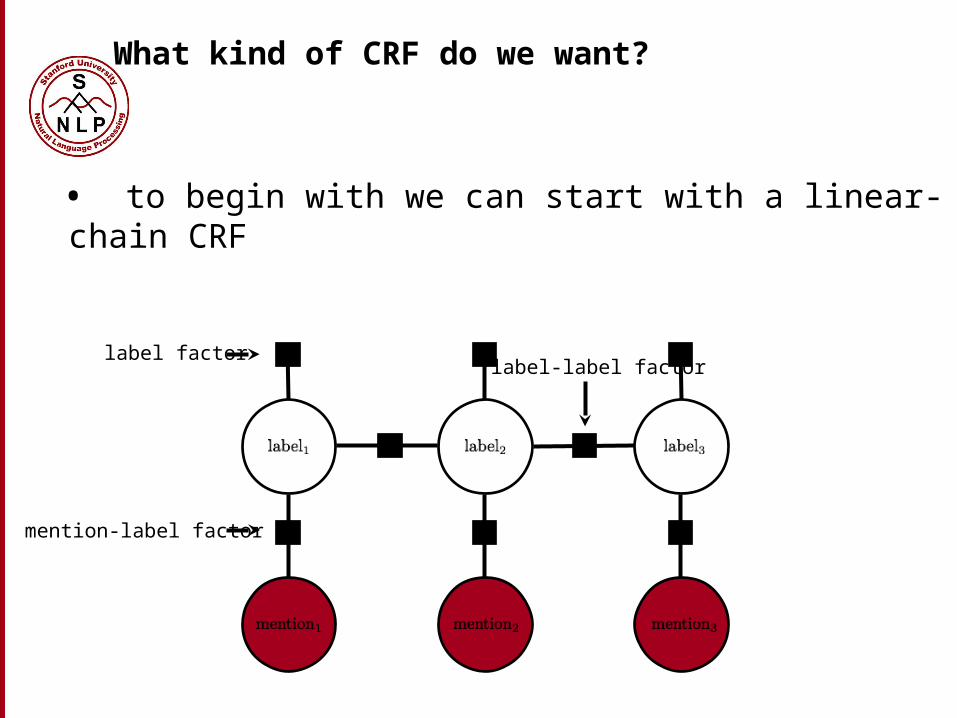
• to begin with we can start with a linear-chain CRF
What kind of CRF do we want?
mention-label factor
label-label factorlabel factor

• we can add a sentence-level relevance variable • (e.g.)
What kind of CRF do we want?

• we can imagine joining neighboring sentences
What kind of CRF do we want?

• we can add “skip-chains” connecting identical mentions (possibly in different sentences)
What kind of CRF do we want?

• for implementation, we’re lucky to have FACTORIE:• a probabilistic modeling toolkit written in Scala• allows for general graphical structures, which can be defined imperatively• supports various inference methods• ... and much much more ...
Implementation
see http://factorie.cs.umass.edu/ and Andrew McCallum, Karl Schultz, Sameer Singh. “FACTORIE: Probabilistic Programming via Imperatively Defined Factor Graphs.”

36
Experiment 5: Joint Model
• Preliminary Results (Just in this morning!)• Linear Chain CRF:
• Large Positive Label-Label weights:• <Crew,Passengers> <Passengers,Crew> <Operator,Aircraft_Type>
• Large Negative Label-Label weights:• <Fatalities,Fatalities> <Survivors,Survivors> <Passengers, Passengers >
• Results on Dev Set (prec/recall)• CRF: (0.25/0.39)• Searn: (0.35/0.35)• Local: (0.26/0.30)

37
Experiment 6: Label Merging
Exhaustive Aggregation Max Aggregation
Four <NIL>Four <Crew>Four <Crew>Four <Fatalities>Four <NIL>Four <NIL>
<Crew> <Fatalities>
Four <NIL>Four <Crew>Four <Crew>Four <Fatalities>Four <NIL>Four <NIL>
<Crew>
Results:• Max Aggregation gives small (0.01) improvement to test set precision.

38
Experiment 6: Label Merging
• Noisy-OR Aggregation• Key idea: Classifier gives us distribution over labels:
• Stockholm <NIL:0.8; Site: 0.1, Crew:0.01, etc.>• Stockholm <Site: 0.5; NIL: 0.3, Crew:0.1, etc.>
• Compute Noisy-OR for each label.
• If Noisy-Or > threshold, use label. (tune threshold on dev set).• Results for Local model (prec/recall):Dev (threshold = 0.9): ExhaustAgg (0.26/0.30) NoisyORAgg(0.35/0.30)Test: ExhaustAgg (0.16/0.41) NoisyORAgg(0.19/0.39)

39
Summary
• Tried 3 things to cope with noisy training data for distantly supervised event extraction.• Sentence Relevance FAIL• Searn Joint Model SUCCESS• Noisy-OR label aggregation SUCCESS
• Future work:• Better doc selection.• Make Sentence Relevance work.• Apply technique to ACE or MUC tasks.

40
Thanks!