evolution of p2p systems - tut
TRANSCRIPT

Searching for Shared Resources:
DHT in General
Mathieu Devos
Tampere University of Technology
Department of Electronics and Communications Engineering
1
ELT-53206 09.09.2015
Based on the original slides provided by A. Surak (TUT), K. Wehrle, S. Götz, S. Rieche (University of Tübingen),
Jani Peltotalo (TTY), Olivier Lamotte (TTY) and the OSDI team 2006
ELT-53206 Peer-to-Peer Networks
2
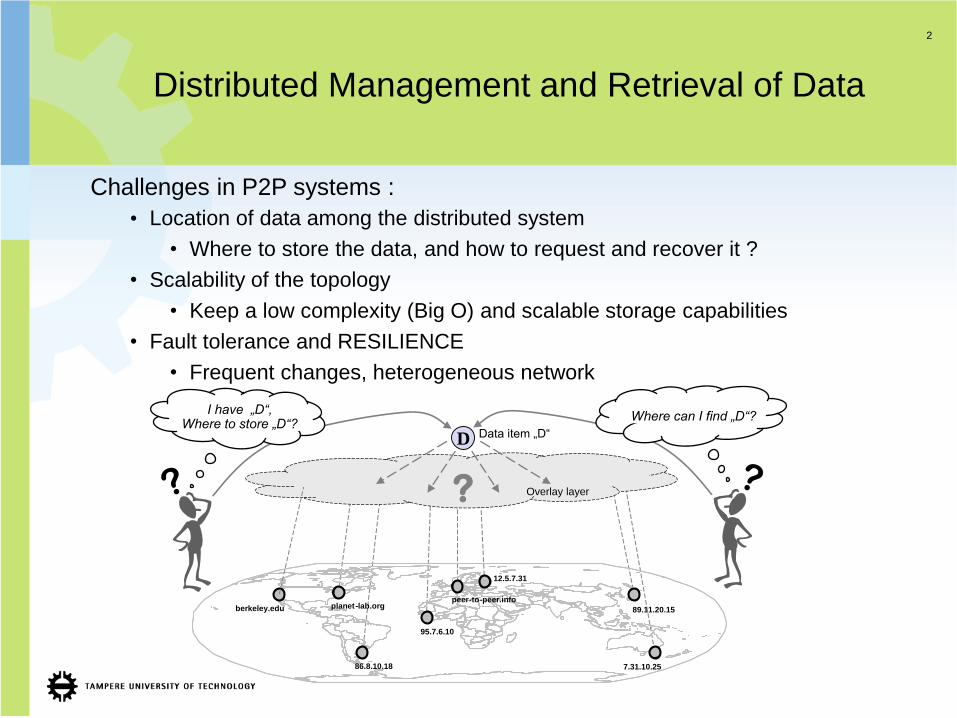
Distributed Management and Retrieval of Data
Challenges in P2P systems :
• Location of data among the distributed system
• Where to store the data, and how to request and recover it ?
• Scalability of the topology
• Keep a low complexity (Big O) and scalable storage capabilities
• Fault tolerance and RESILIENCE
• Frequent changes, heterogeneous network
D
?
Data item „D“
Overlay layer
7.31.10.25
peer-to-peer.info
12.5.7.31
95.7.6.10
86.8.10.18
planet-lab.orgberkeley.edu 89.11.20.15
I have „D“,Where to store „D“?
Where can I find „D“?

Big O Notation
• Big O notation is widely used by computer scientists to concisely describe
the behavior of algorithms
• Specifically describes the worst-case scenario, and can be used to
describe the execution time required or the space used by an algorithm
• Common types of orders
• O(1) – constant
• O(log n) – logarithmic
• O(n) – linear
• O(n2) – quadratic
3

4
Comparison of strategies for data retrieval
Strategies for storage and retrieval of data items scattered over distributed
systems
• Central server (Napster)
• Flooding search (GNUTELLA, unstructured overlays)
• Distributed indexing (CHORD, PASTRY)

5
“A stores D”
Node A
Node B
Server S
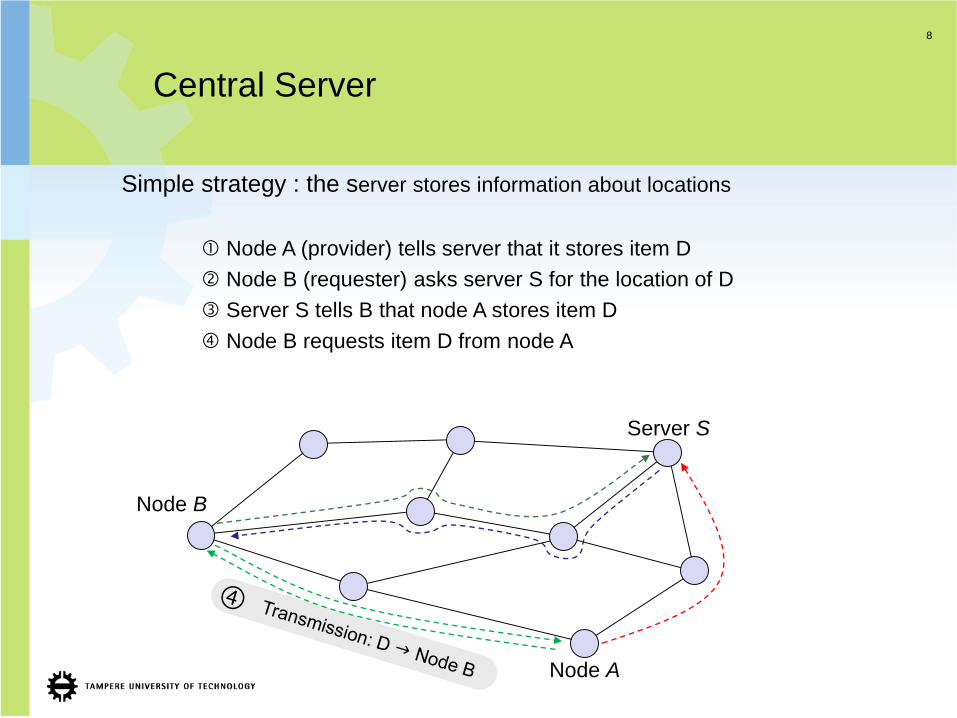
Simple strategy : the server stores information about locations
Node A (provider) tells server that it stores item D
Node B (requester) asks server S for the location of D
Server S tells B that node A stores item D
Node B requests item D from node A
Central Server

6
Node A
Node B
Server S
Simple strategy : the server stores information about locations
Node A (provider) tells server that it stores item D
Node B (requester) asks server S for the location of D
Server S tells B that node A stores item D
Node B requests item D from node A
Central Server

7
Node A
Node B
Server S
“A stores D”
Simple strategy : the server stores information about locations
Node A (provider) tells server that it stores item D
Node B (requester) asks server S for the location of D
Server S tells B that node A stores item D
Node B requests item D from node A
Central Server
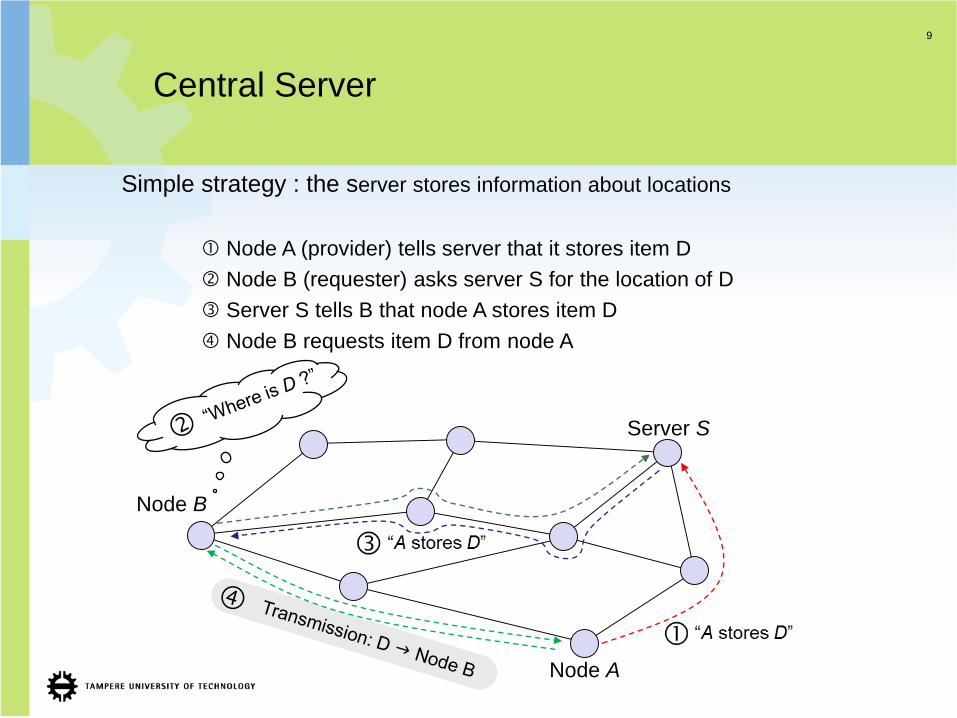
“A stores D”
8
Node A
Node B
Server S
Simple strategy : the server stores information about locations
Node A (provider) tells server that it stores item D
Node B (requester) asks server S for the location of D
Server S tells B that node A stores item D
Node B requests item D from node A
Central Server
9
Node A
Node B
Server S
Simple strategy : the server stores information about locations
Node A (provider) tells server that it stores item D
Node B (requester) asks server S for the location of D
Server S tells B that node A stores item D
Node B requests item D from node A
Central Server

10
Central Server – Pros and Cons
• Search complexity O(1) :
just ask the server
• Complex and fuzzy queries possible
• Easy to implement

11
Central Server – Pros and Cons
• Search complexity O(1) :
just ask the server
• Complex and fuzzy queries possible
• Easy to implement
• No scalability since stateful
• O(n) node state in server
• O(n) network and server load
• Easy target (single point of failure) also for
law suites (Napster, TPB)
• Costs of maintenance, availability, scalability
• Not suitable for systems with massive
numbers of users
• No self sustainability, needs moderation

12
Central Server – Pros and Cons
• Search complexity O(1) :
just ask the server
• Complex and fuzzy queries possible
• Easy to implement
• No scalability since stateful
• O(n) node state in server
• O(n) network and server load
• Easy target (single point of failure) also for
law suites (TPB)
• Costs of maintenance, availability, scalability
• Not suitable for systems with massive
numbers of users
• No self sustainability, needs moderation
Fault tolerance and RESILIENCE ?
Scalability of the topology ?
Location of data among the distributed system ?

13
Central Server – Pros and Cons
YET : Best approach for small and simple applications!
• Search complexity O(1) :
just ask the server
• Complex and fuzzy queries possible
• Easy to implement
• No scalability since stateful
• O(n) node state in server
• O(n) network and server load
• Easy target (single point of failure) also for
law suites (TPB)
• Costs of maintenance, availability, scalability
• Not suitable for systems with massive
numbers of users

14
Flooding Search
Applied in UNSTRUCTURED P2P systems
•No information about the location of requested data in overlay
•Content is only stored in the node providing it
•Fully distributed approach
Retrieval of data
•No routing information for content
•Necessity to ask as much systems as possible/necessary
•Approaches
• Flooding: high traffic load on network, does not scale
• Highest degree search: (here degree = number of connections)
quick search through large areas – large number of messages
needed for unique identification using highly connected nodes
(nodeID)
Where is D?

15
Node A
Node B
Flooding Search
Ping
Pong
Query Hit
Connect
3 Messages
•No information about location of data in the intermediate systems
•Necessity for broad search (Graph theory)
Node B (requester) asks neighboring nodes for item D

16
Node A
Node B
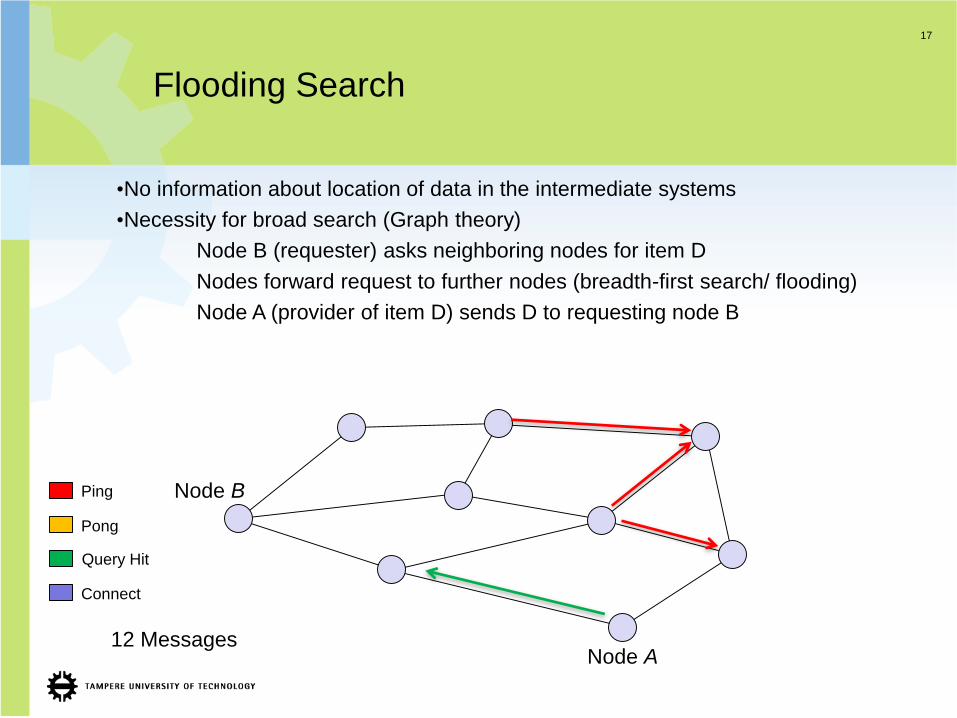
Flooding Search
Ping
Pong
Query Hit
Connect
8 Messages
Topology loop
detection
•No information about location of data in the intermediate systems
•Necessity for broad search (Graph theory)
Node B (requester) asks neighboring nodes for item D
Nodes forward request to further nodes (breadth-first search/ flooding)
17
Node A
Node B
Flooding Search
Ping
Pong
Query Hit
Connect
12 Messages
•No information about location of data in the intermediate systems
•Necessity for broad search (Graph theory)
Node B (requester) asks neighboring nodes for item D
Nodes forward request to further nodes (breadth-first search/ flooding)
Node A (provider of item D) sends D to requesting node B

18
Node A
Node B
•No information about location of data in the intermediate systems
•Necessity for broad search (Graph theory)
Node B (requester) asks neighboring nodes for item D
Nodes forward request to further nodes (breadth-first search/ flooding)
Node A (provider of item D) sends D to requesting node B
Flooding Search
Ping
Pong
Query Hit
Connect
16 Messages

19
Node A
Node B
•No information about location of data in the intermediate systems
•Necessity for broad search (Graph theory)
Node B (requester) asks neighboring nodes for item D
Nodes forward request to further nodes (breadth-first search/ flooding)
Node A (provider of item D) sends D to requesting node B
Flooding Search
Ping
Pong
Query Hit
Connect
16 Messages + Too many pongs !
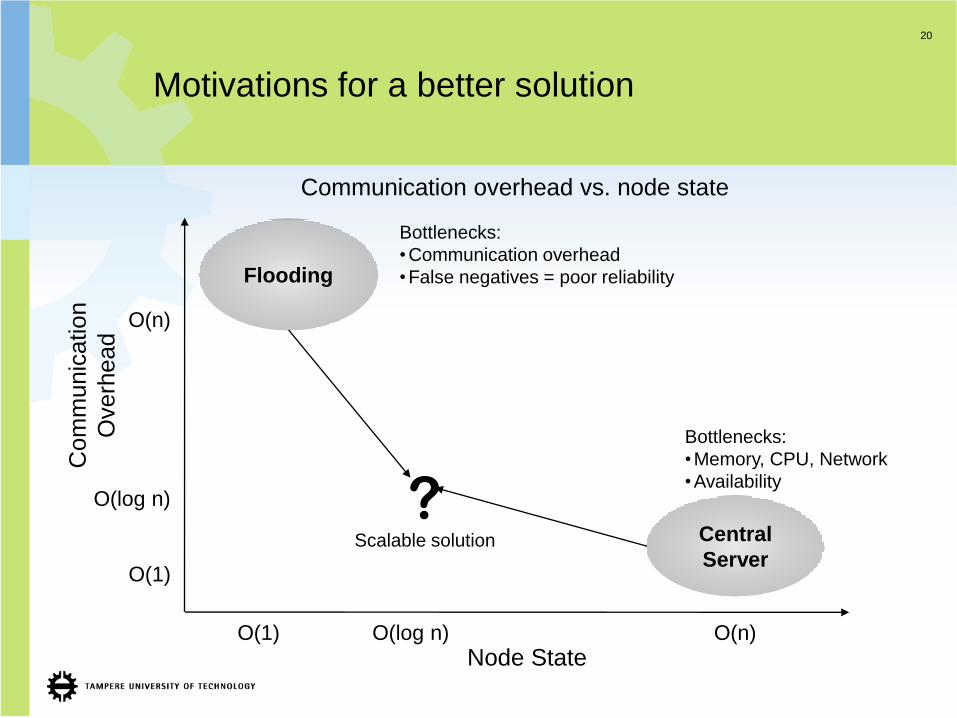
20
Motivations for a better solution
Communication overhead vs. node state
Com
munic
ation
Overh
ead
Node State
Flooding
Central
Server
O(n)
O(n)O(1)
O(1)
O(log n)
O(log n)
Bottlenecks:
•Communication overhead
•False negatives = poor reliability
Bottlenecks:
•Memory, CPU, Network
•Availability
?Scalable solution

21
Motivations for a better solutionC
om
munic
ation
Overh
ead
Node State
Flooding
Central
Server
O(n)
O(n)O(1)
O(1)
O(log n)
O(log n)Distributed
Hash Table
Communication overhead vs. node state
DHT
Scalability in O(log n)
No false negatives
Resistant against changes
• Failures, attacks
• Short time users (freeriders)

22
Distributed Indexing
Approach of distributed indexing schemes
• Data and nodes are mapped into same address space
• Intermediate nodes maintain routing information to target nodes
• Efficient forwarding to destination
• Definitive statement of existence of content
Issues
• How to join the topology ?
• Maintenance of routing information required
• Network events : join, leave, failures, attacks !
• Fuzzy queries (e.g., wildcard searches) not primarily supported

23
Distributed Indexing
Goal is scalable complexity for
• Communication effort: O(log n) hops
• Node state: O(log n) routing entries
H(„my data“)
= 3107
2207
7.31.10.25
peer-to-peer.info
12.5.7.31
95.7.6.10
86.8.10.18
planet-lab.orgberkeley.edu
29063485
201116221008
709
611
89.11.20.15
?
n Nodes
Routing in O(log n) steps

24
Fundamentals of Distributed Hash Tables
Design challenges :
• Desired characteristics
• Flexibility
• Reliability
• Scalability
• Equal distribution of content among nodes
• Crucial for efficient lookup of content
• Consistent hashing function (advantages and disadvantages)
• Permanent adaptation to faults, joins and departures of nodes
• Assignment of responsibilities to new nodes
• Re-assignment and re-distribution of responsibilities
in case of node failure or departure
Hashtables use a hash function to map identifying values,
known as keys (e.g., a person's name), to their
associated values (number)

Distributed Management of Data
Nodes and Keys of the hashtable share the same address space
• Using IDs
• Nodes are responsible for data in certain parts of the address space
• The data a node is in charge of may change since there are changes
Looking for data means :
• Finding the responsible node via intermediate nodes
• The query is routed to the node responsible, which returns the key/value pair
• Mathematical ”closeness” of comparing hashes
→ Node in China might be next to Node in USA (hashing!)
Target node is not necessarily known in advance – is it even available?
This is a very deterministic statement about availability of data
25

26
Addressing in Distributed Hash Tables
Step 1: Mapping of content/nodes into linear space : consistent hashing
• m bit identifier space for both keys and nodes
• The hash function result has to fit in the space : mod 2m, here m=6
• [ 0, …, 2m-1 ] number of objects to be stored, 64 IDs
• E.g., Hash(“ELT-53206-lec4.pdf”) mod 2m: 54
• E.g., Hash(“129.100.16.93”) mod 2m: 21
The address space is
commonly viewed as a
circle

27
Addressing in Distributed Hash Tables
Step 2: Association of address ranges to the nodes
• Often with small redundancy (overlapping of parts)
• Continuous adaptation due to changes
• Real (underlay) and logical (overlay) topology are unlikely correlated
(consistent hashing)
• Keys are assigned to their successor node in the identifier circle the node
with next higher ID (remember the circular namespace)
• N1 ?

28
Association of Address Space with Nodes
Logical view of the
Distributed Hash Table
(Overlay layer)
Mapping on the
real topology
(Physical layer)
2207
29063485
201116221008709
611

29
Addressing in Distributed Hash Tables
Step 3: Locating the data (content-based routing)
• Minimum overhead with distributed hash tables
• O(1) with centralized hash table (aka expensive server)
• O(n) DHT hops without finger table (left)
• O(log n): DHT hops to locate object, and n keys and routing
information to store at a node (right)
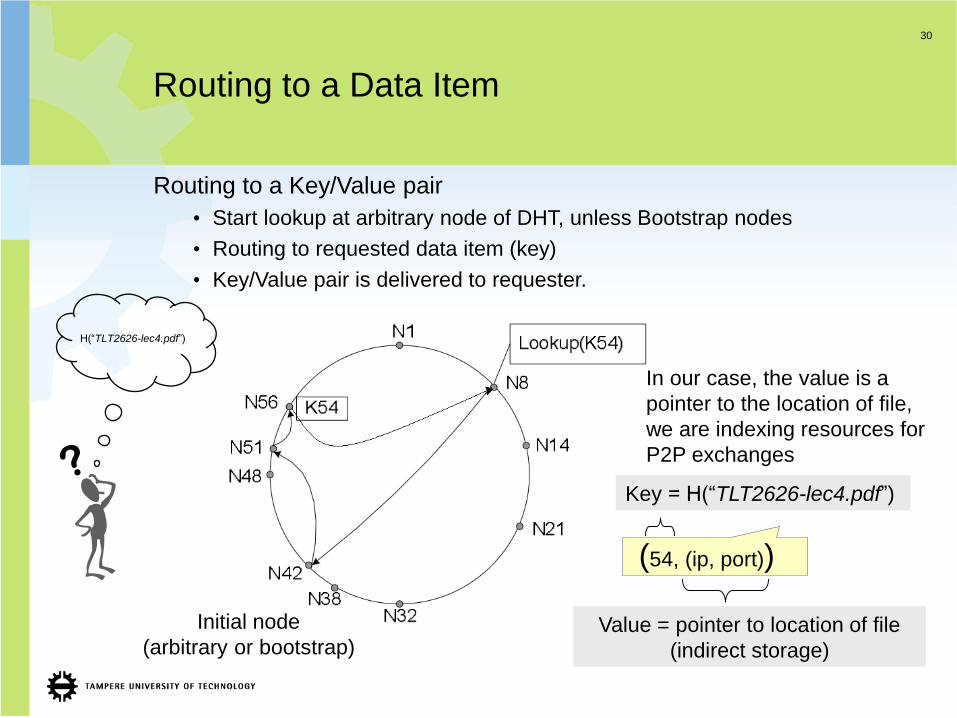
30
Routing to a Data Item
Routing to a Key/Value pair
• Start lookup at arbitrary node of DHT, unless Bootstrap nodes
• Routing to requested data item (key)
• Key/Value pair is delivered to requester.
(54, (ip, port))
Value = pointer to location of file
(indirect storage)
Key = H(“TLT2626-lec4.pdf”)
Initial node
(arbitrary or bootstrap)
H(“TLT2626-lec4.pdf”)
In our case, the value is a
pointer to the location of file,
we are indexing resources for
P2P exchanges
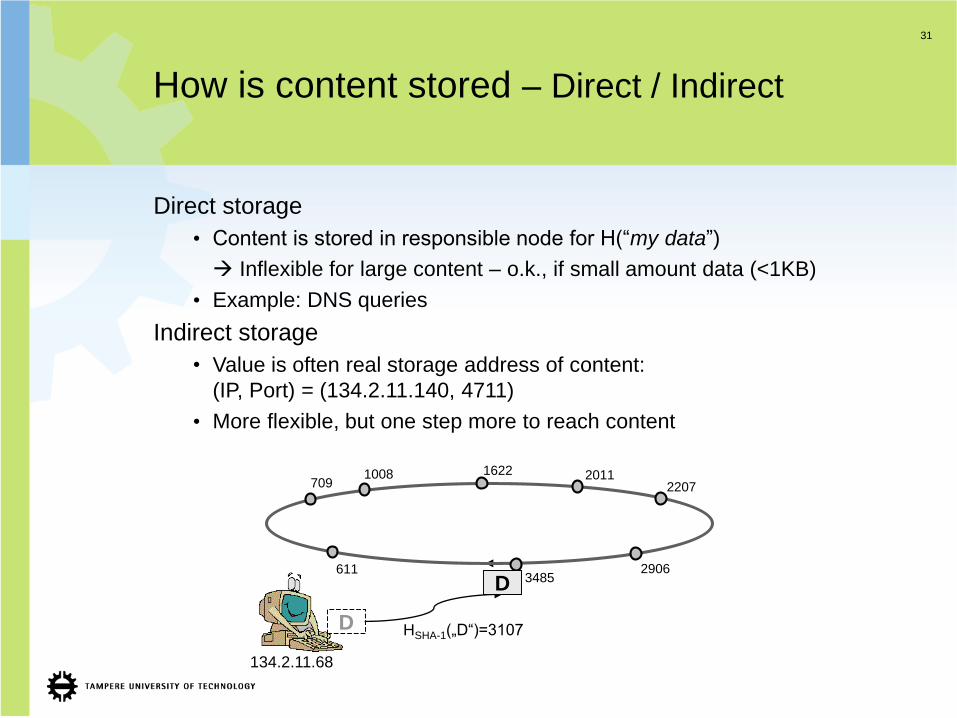
31
How is content stored – Direct / Indirect
Direct storage
• Content is stored in responsible node for H(“my data”)
Inflexible for large content – o.k., if small amount data (<1KB)
• Example: DNS queries
Indirect storage
• Value is often real storage address of content:
(IP, Port) = (134.2.11.140, 4711)
• More flexible, but one step more to reach content
D
D
134.2.11.68
2207
29063485
201116221008709
611
HSHA-1(„D“)=3107
D

32
Node Arrival
Joining of a new node
Calculation of node ID
New node contacts DHT via arbitrary bootstrap node
Assignment of a particular hash range
Binding into routing environment
Copying of Key/Value pairs of hash range
2207
29063485
201116221008709
611
ID: 3485
134.2.11.68
TLT-2626, Lecture 4 03.10.2012

33
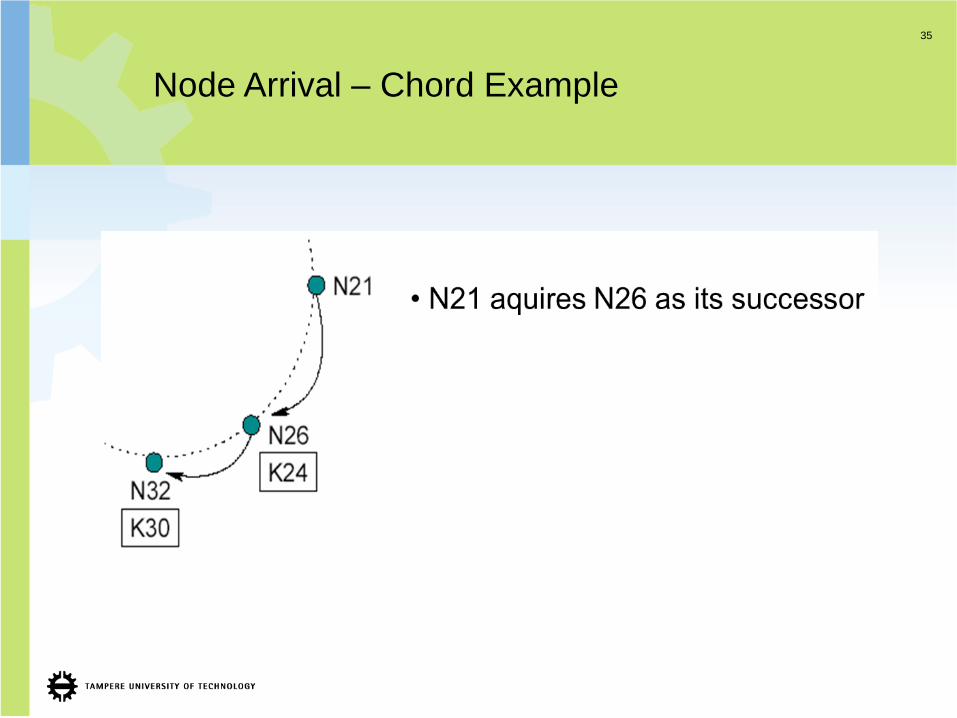
Node Arrival – Chord Example
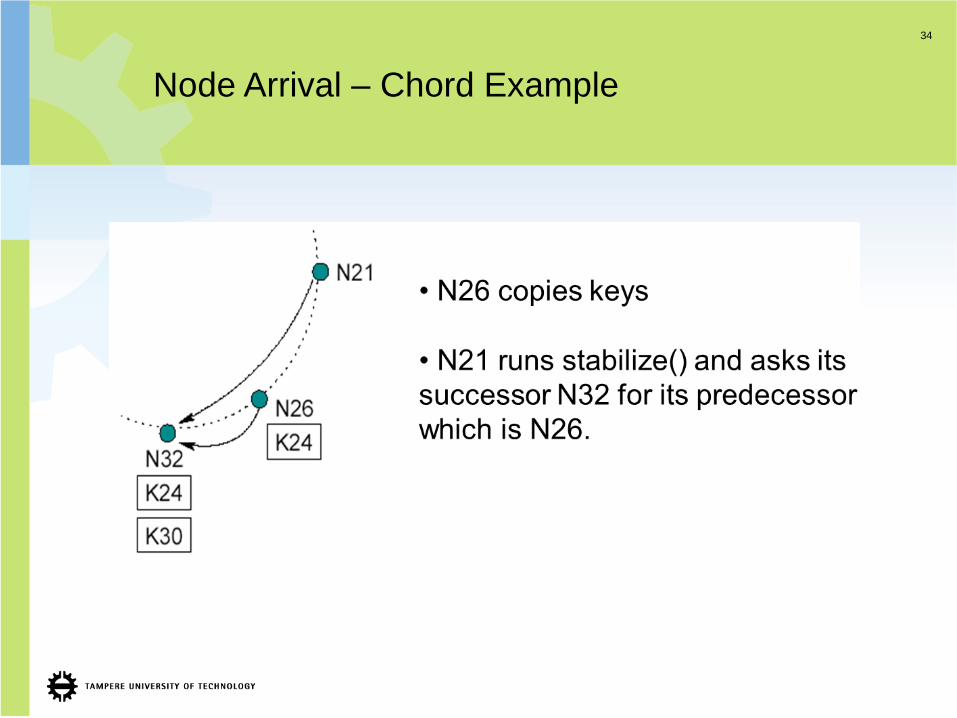
34
Node Arrival – Chord Example
35
Node Arrival – Chord Example

Node Failure and Departure
Failure of a node
• Use of redundant/replicated data if node fails
• Use of redundant/alternative routing paths if routing environment fails
Departure of a node
• Partitioning of hash range to neighbor nodes
• Copying of Key/Value pairs to corresponding nodes
• Unbinding from routing environment

37
Reliability in Distributed Hash Tables
Erasure codes and
redundancy• Erasure code transform a message
of k symbols into a longer message (code
word) with n symbols such that the
original message can be recovered from
a subset of the n symbols
• Every time a node crashes, a piece of the
data is destroyed, and after some time,
the data may no longer be computable
• Therefore, the idea of redundancy also
needs replication of the data
Form of Forward Error Correction
(future of storage ?)
Replication
• Several nodes should manage the
same range of keys
Introduces new possibilities for
underlay aware routing

Replication Example: Multiple Nodes in One Interval
Each interval of the DHT may be maintained by several nodes at the same time
• Fixed positive number K indicates how many nodes have to at least act within one
interval
• Each data item is therefore replicated at least K times
…
…
…
…
9
10
1
2
3
4
5
6
7
8
Node

Load Balancing in Distributed Hash Tables
• Initial assumption: uniform key distribution
• Hash function
• Every node with equal load
• Load balancing is not needed
• Equal distribution
• Nodes across address space
• Data across nodes
• Is this assumption justifiable?
• Example: Analysis of distribution
• 4096 Chord nodes
• 500000 documents
• Optimum ~122 documents per node
• Distribution could benefit from load
balancing
Optimal distribution of
documents across nodes
Frequency distribution of DHT nodes storing a certain number of documents

Load Balancing Algorithms
Several techniques have been proposed to ensure an equal data distribution
Possible subject for Paper assignment
1. Power of Two Choices
• John Byers, Jeffrey Considine, and Michael Mitzenmacher
• “Simple Load Balancing for Distributed Hash Tables"
2. Virtual Servers
• Ananth Rao, Karthik Lakshminarayanan, Sonesh Surana, Richard Karp, and Ion Stoica
• "Load Balancing in Structured P2P Systems"
3. Thermal-Dissipation-based Approach
• Simon Rieche, Leo Petrak, and Klaus Wehrle
• "A Thermal-Dissipation-based Approach for Balancing Data Load in Distributed Hash
Tables"
4. A Simple Address-Space and Item Balancing
• David Karger, and Matthias Ruhl
• "Simple, Efficient Load Balancing Algorithms for Peer-to-Peer Systems"

41
DHT Interfaces
Generic interface of Distributed Hash Tables
• Provisioning of information
• Put(key, value)
• Requesting of information (search for content)
• Get(key)
• Reply
• Value
DHT approaches are interchangeable (with respect to interface)
Put(Key,Value) Get(Key)
Value
Distributed Application
Node 1 Node NNode 2 . . . .Node 3
Distributed Hash Table (CAN, Chord, Pastry, Tapestry, …)

Comparison: DHT vs. DNS
• Traditional name services follow fixed mapping
• DNS maps a logical node name to an IP address
• DHTs offer flat/generic mapping of addresses
• Not bound to particular applications or services
• value in (key, value) may be
• an address
• a document
• or other data …

Comparison: DHT vs. DNS
Domain Name System
• Mapping:
Symbolic name IP address
• Is built on a hierarchical structure
with root servers
• Names refer to administrative
domains
• Specialized to search for
computer names and services
Distributed Hash Table
• Mapping: key value
can easily realize DNS
• Does not need a special
server
• Does not require special
name space
• Can find data that are
independently located of
computers
44
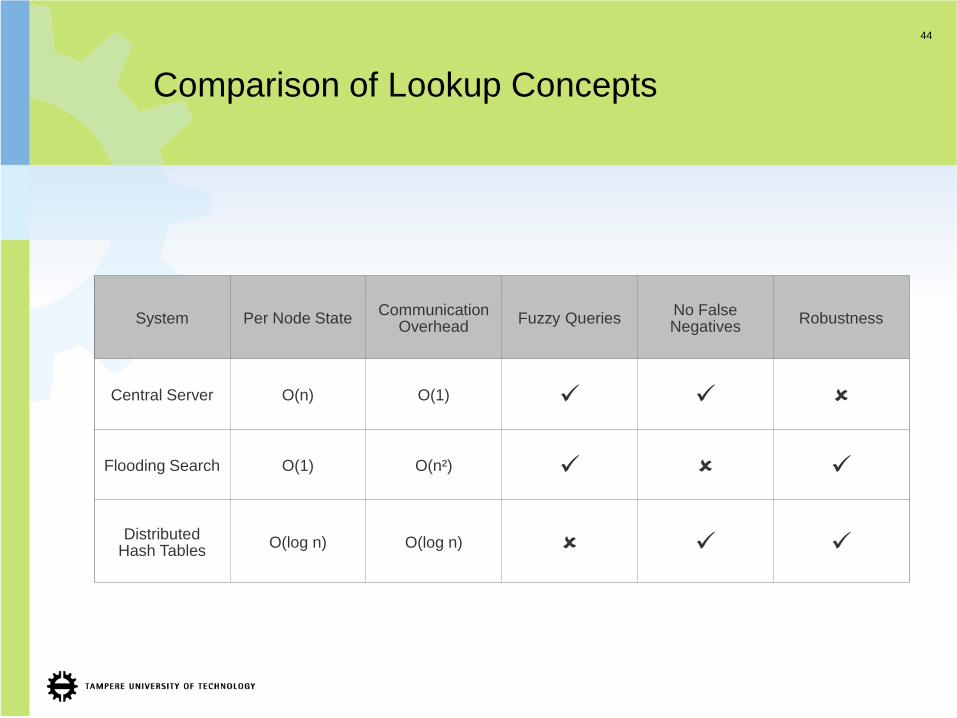
Comparison of Lookup Concepts
System Per Node StateCommunication
OverheadFuzzy Queries
No False Negatives
Robustness
Central Server O(n) O(1)
Flooding Search O(1) O(n²)
Distributed Hash Tables
O(log n) O(log n)

45
Properties of DHTs
• Use of routing information for efficient search for content
• Keys are evenly (or not?) distributed across nodes of DHT
• No bottlenecks
• A continuous increase in number of stored keys is admissible
• Failure of nodes can be tolerated
• Survival of attacks possible
• Self-organizing system
• Simple and efficient realization
• Supporting a wide spectrum of applications
• Flat (hash) key without semantic meaning
• Value depends on application

Learning Outcomes
• Things to know
• Differences between lookup concepts
• Fundamentals of DHTs
• How DHT works
• Be ready for specific examples of DHT algorithms
• Try some yourself !
• Simulation using Python here : http://bit.ly/SZAZxT
46
