exploiting reducibility in unsupervised dependency parsing
DESCRIPTION
Exploiting Reducibility in Unsupervised Dependency Parsing. David Mare ček and Zden ěk Žabokrtský Institute of Formal and Applied Linguistics Charles University in Prague EMNLP conference July 12, 2012, Jeju Island, Korea. Outline. Unsupervised Dependency Parsing Motivations Reducibility - PowerPoint PPT PresentationTRANSCRIPT

Exploiting Reducibility in Unsupervised DependencyParsing
David Mareček and Zdeněk Žabokrtský
Institute of Formal and Applied LinguisticsCharles University in Prague
EMNLP conferenceJuly 12, 2012, Jeju Island, Korea

Outline
Unsupervised Dependency Parsing Motivations
Reducibility What is reducibility? Computing reducibility scores
Employing reducibility in unsupervised dependency parsing Dependency model Inference: Gibbs sampling of projective dependency trees Results

Motivations for Unsupervised dependeny parsing
Parsing without using aby treebank or any language-specific rules
For under-resourced languages or domains? Every new treebank is expensive and time-consuming However, semi-supervised methods are probably more useful than
completely unsupervised methods
Universality across languages Linguistic theory independent parser Treebanks differ in a ways of capturing various linguistic phenomena
Unsupervised parser might find more suitable structures than we have in treebanks It might work better in final applications (MT, QA, ... ) GIZA++ is also unsupervised and it is universal and widely used Dependency parsing is similar to the word alignment task

REDUCIBILITY

Reducibility
Definition: A word (or a sequence of words) is reducible if we can remove it from the sentence without violating the grammaticality of the rest of the sentence.
Some conference participants missed the last bus yesterday.
Some participants missed the last bus yesterday.
Some conference participants the last bus yesterday.
REDUCIBLE NOT REDUCIBLE

Hypothesis
If a word (or sequence of words) is reducible in a particular sentence, it is a leaf (or a subtree) in the dependency structure.
Some conference
participants
missed
the last
bus yesterday

It mostly holds across languages Problems occur mainly with function words
PREPOSITIONAL PHRASES: They are at the conference.
DETERMINERS: I am in the pub.
AUXILIARY VERBS: I have been sitting there.
Let’s try to recognize reducibile words automatically...
Hypothesis
If a word (or sequence of words) is reducible in a particular sentence, it is a leaf (or a subtree) in the dependency structure.

Recognition of reducible words
We remove the word from the sentence.
But how can we automatically recognize whether the rest of the sentence is grammatical or not? Hardly... (we don’t have any grammar yet)
If we have a large corpus, we can search for the needed sentence. it is in the corpus -> it is (possibly) grammatical it is not in the corpus -> we do not know
We will find only a few words reducible... very low recall

Other possibilities?
Could we take a smaller context than the whole sentence? Does not work at all for free word-order languages.
Why don’t use part-of-speech tags instead of words? DT NN VBS IN DT NN . DT NN VBS DT NN . ... but the preposition IN should not be reducible
Solution: We use a very sparse reducible words in the corpus for estimating
“reducibility scores” for PoS tags (or PoS tag sequence)

Computing reducibility scores
For each possible PoS unigram, bigram and trigram: Find all its occurrences in the corpus For each such occurence, remove the respective words and search for the rest of
the sentence in the corpus. If it occurs at least once elsewhere in the corpus, the occurence is proclaimed as
reducible. Reducibility of PoS n-gram = relative number of reducible occurences
PRP VBD PRP IN DT NN .
I saw her .
She was sitting on the balcony and wearing a blue dress .
I saw her in the theater .
PRP VBD VBG IN DT NN CC VBG DT JJ NN .
PRP VBD PRP .
R(“IN DT NN”) =1
2

Computing reducibility scores
• r(g) ... number of reducible occurences
• c(g) ... number of all the occurences
For each possible PoS unigram, bigram and trigram: Find all its occurrences in the corpus For each such occurence, remove the respective words and search for the rest of
the sentence in the corpus. If it occurs at least once elsewhere in the corpus, the occurence is proclaimed as
reducible. Reducibility of PoS n-gram = relative number of reducible occurences

Examples of reducibility scores
Reducibility scores of the English PoS tags induced from the English Wikipedia corpus

DEPENDENCY TREE MODEL

Dependency tree model
Consists of four submodels edge model fertility model distance model reducibility model
Simplification we use only PoS tags, we don’t use word forms we induce projective trees only

Edge model
P(dependent tag | edge direction, parent tag) “Rich get richer” principle on dependency edges

Fertility model
P(number left and right children | parent tag) “Rich get richer” principle

Distance model
Longer edges are less probable.

Reducibility model
Probability of a subtree is proportinal to its reducibility score.

Probability of treebank
The probability of the whole treebank, which we want to maximize Multiplication over all models and words in the corpus

Gibbs sampling – bracketing notation
Each projective dependency tree can be expressed by a unique bracketing. Each bracket pair belongs to one node and delimits its descendants from
the rest of the sentence. Each bracketed segment contains just one word that is not embedded
deeper; this node is the head of the segment.
root
NN IN
VB
NNDT
DT JJ
RB
(((DT) NN) VB (RB) (IN ((DT) (JJ) NN)))

Gibbs sampling – small change
Choose one non-root node and remove its bracket Add another bracket which does not violate the projectivity
( ((DT) NN) VB (RB) IN ((DT) (JJ) NN))( )
(IN ((DT) (JJ) NN))
((RB) IN ((DT) (JJ) NN))
((RB) IN)
(((DT) NN) VB (RB))
(((DT) NN) VB)
(VB (RB))
(VB)
0.0012
0.0009
0.0011
0.0023
0.0018
0.0004
0.0016
(IN) 0.0006

Gibbs sampling - decoding
After 200 iterations We run MST algorithm Edge weights = occurrences of individual edges in the treebank during
the last 100 sampling iterations The output trees may be possibly non-projective
Evaluation
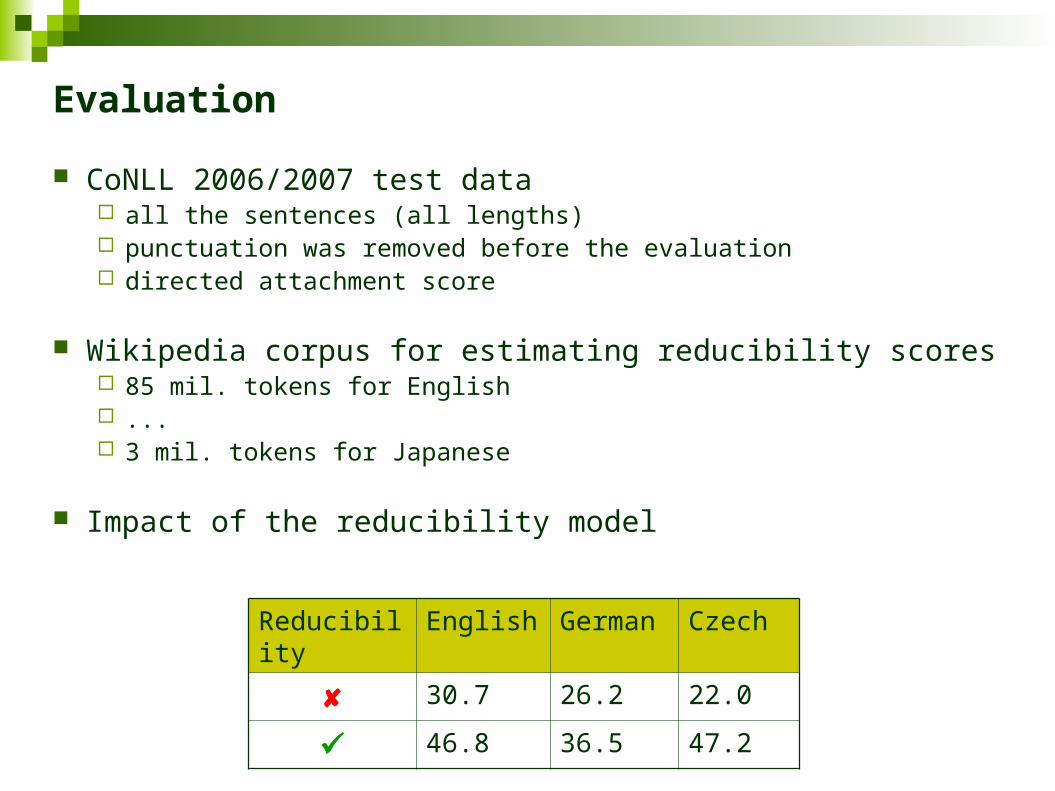
CoNLL 2006/2007 test data all the sentences (all lengths) punctuation was removed before the evaluation directed attachment score
Wikipedia corpus for estimating reducibility scores 85 mil. tokens for English ... 3 mil. tokens for Japanese
Impact of the reducibility model
Reducibility English German Czech
30.7 26.2 22.0
46.8 36.5 47.2
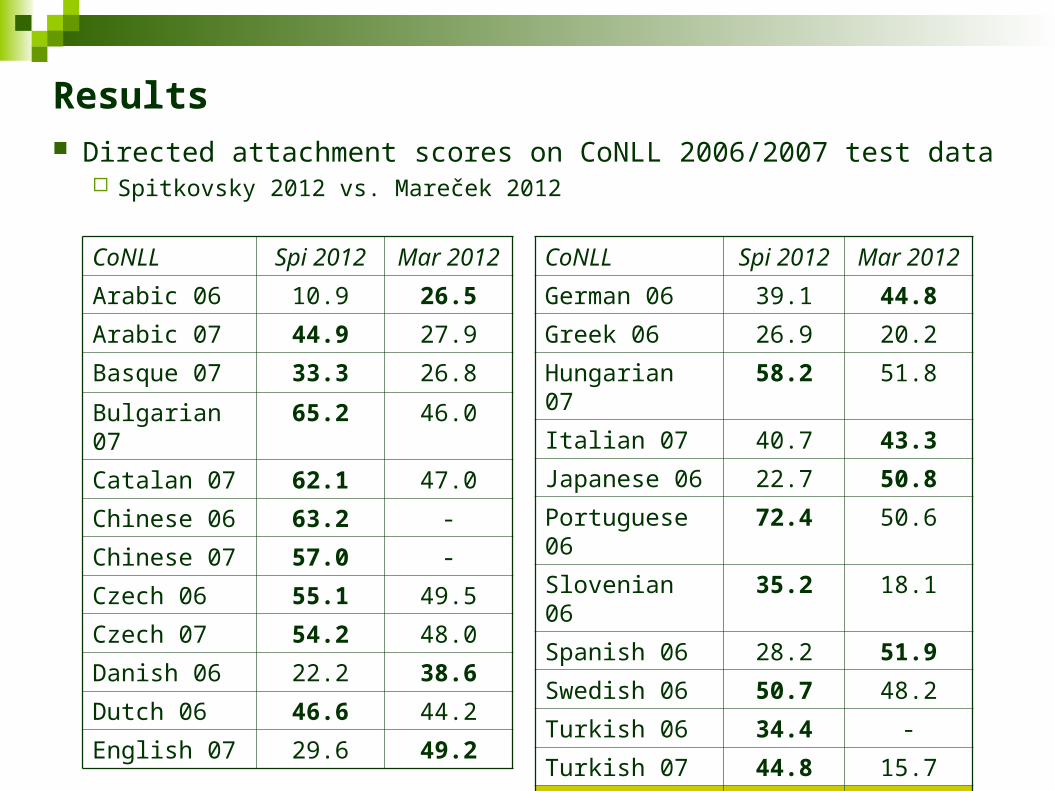
Results Directed attachment scores on CoNLL 2006/2007 test data
Spitkovsky 2012 vs. Mareček 2012
CoNLL Spi 2012 Mar 2012
Arabic 06 10.9 26.5
Arabic 07 44.9 27.9
Basque 07 33.3 26.8
Bulgarian 07 65.2 46.0
Catalan 07 62.1 47.0
Chinese 06 63.2 -
Chinese 07 57.0 -
Czech 06 55.1 49.5
Czech 07 54.2 48.0
Danish 06 22.2 38.6
Dutch 06 46.6 44.2
English 07 29.6 49.2
CoNLL Spi 2012 Mar 2012
German 06 39.1 44.8
Greek 06 26.9 20.2
Hungarian 07 58.2 51.8
Italian 07 40.7 43.3
Japanese 06 22.7 50.8
Portuguese 06 72.4 50.6
Slovenian 06 35.2 18.1
Spanish 06 28.2 51.9
Swedish 06 50.7 48.2
Turkish 06 34.4 -
Turkish 07 44.8 15.7
Average: 42.9 40.0

Conclusions
I have introduced reducibility feature, which is useful in unsupervised dependency parsing
The reducibility scores for individual PoS tag n-grams are computed on a large corpus and then used in the induction algorithm on a smaller corpus
State-of-the-art? It might have been in January 2012
Future work: Employ lexicalized models Improve reducibility – another dealing with function words

Thank you for your attention.