face: fast and customizable sorting accelerator for heterogeneous many-core systems
TRANSCRIPT

FACE: Fast and Customizable Sorting Accelerator for Heterogeneous Many-core Systems
Ryohei Kobayashi, Kenji Kise Tokyo Institute of Technology, Japan
MCSoC-15@Turin, Italy Embedded Multicore/Many-core Architectures 13:40-14:10, September 23, 2015

1
Introduction

l Multi-core and many-core processors have been mainstream to accelerate applications by parallel processing
l # of cores has been increased depending on Moore’s Law
Multi-core and Many-core Processor
2
2006 Core 2 Duo Conroe (65nm)
2 Cores
2008 Core 2 Quad Yorkfield (45nm)
4 Cores
2010 Xeon 7500 Nehalem EX
(32nm)
8 Cores
2012 Xeon Phi
Knights Corner (22nm)
50+ Cores

l The end of Moore’s Law means that approaches relying on the following points are hopeless... Ø The increase in # of cores (especially) Ø Implementation of rich features Ø Etc...
Will Moore’s Law Continue?
3

Will Moore’s Law Continue?
4
Yes. But we have motivation for accelerators [1].
That’s why we bought Altera
[1] Cupta et al, Xeon+FPGA Platform for the Data Center, CARL 2015 (Co-located with ISCA 2015)

Will Moore’s Law Continue?
5
Microsoft is a trademark of the Microsoft group of companies
Yes. But we have motivation for accelerators [1].
That’s why we bought Altera
[1] Cupta et al, Xeon+FPGA Platform for the Data Center, CARL 2015 (Co-located with ISCA 2015)

Will Moore’s Law Continue?
6
Microsoft is a trademark of the Microsoft group of companies
Yes. But we have motivation for accelerators [1].
That’s why we bought Altera
No, Moore’s Law is ending. That’s why hardware
specialization will be critical [2]
[1] Cupta et al, Xeon+FPGA Platform for the Data Center, CARL 2015 (Co-located with ISCA 2015) [2] Putnam et al, A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA2014

Will Moore’s Law Continue?
7
Microsoft is a trademark of the Microsoft group of companies
Yes. But we have motivation for accelerators [1].
That’s why we bought Altera
No, Moore’s Law is ending. That’s why hardware
specialization will be critical [2]
[1] Cupta et al, Xeon+FPGA Platform for the Data Center, CARL 2015 (Co-located with ISCA 2015) [2] Putnam et al, A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA2014
Dedicated hardware era is coming!!!

l Sorting is a fundamental computation kernel
This work: Sorting Accelerator
8
Databases[1] Image Processing[2] Data Compression[3]
[1] Rene Mueller et al, Sorting Networks on FPGAs, The VLDB Journal 2012 [2] Ratnayake, K et al, An FPGA Architecture of Stable-Sorting on a Large Data Volume : Application to Video Signals, CISS 2007 [3] Martinez, J et al, An FPGA-based parallel sorting architecture for the Burrows Wheeler transform, ReConFig 2005

l Sorting is a fundamental computation kernel
This work: Sorting Accelerator
9
[1] Rene Mueller et al, Sorting Networks on FPGAs, The VLDB Journal 2012 [2] Ratnayake, K et al, An FPGA Architecture of Stable-Sorting on a Large Data Volume : Application to Video Signals, CISS 2007 [3] Martinez, J et al, An FPGA-based parallel sorting architecture for the Burrows Wheeler transform, ReConFig 2005
Databases[1] Image Processing[2] Data Compression[3]
! Sorting accelerators fulfilling the following requirements do not exist...
Problem
ü High Performance ü Customizable ü Open sourced

10
Our Proposed Sorting Accelerator

l Using the following sorting architectures Ø The sorting network Ø The merge sorter tree
Our Proposed Sorting Accelerator
11
1
4
3
2
4
3
2
1 >
> >
The sorting network
Proposed Sorting Accelerator
The merge sorter tree

l A sorting architecture composed of wires and comparators
l Example: Sorting 4 values in the network Ø Smaller and larger values are carried to the top and bottom
The Sorting Network*
12
1
4
3
2
4
3
2
1
Bubble sort network with 4-inputs and 4-outputs
* Donald E. Knuth. The Art of Computer Programming. 1998.

l A data path that executes merge process
The Merge Sorter Tree*
13
>
> >
FIFO
Sorter Cell >
4-way merge sorter tree
* Dirk Koch et al, FPGASort, FPGA’11

l Sorting process in the merge sorter tree Ø The data sequences in the leftmost FIFOs must be sorted
The Merge Sorter Tree
14
>
> >
>
> >
>
> >
8 9 3 5
1 3 2 2 1
3
3 2 2
1 2
1
8 9 5
3 7 5
1 2
3
2
5
2 2 3 7 9 8
x
x: Invalid Value
Cycle N Cycle N+1 Cycle N+2

Data Path of the Proposed Sorting Accelerator
15
Debug HW
Host PC
DRAM
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
IN OUT
Stage

16
Example: Sorting 256 elements

l The generated initial data sequence is stored in the external memory
Sorting 256 Elements from 256 to 1
17
256 255 254 … 64 63 … 3 2 1
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
DRAM

l Initialization is done
Sorting 256 Elements from 256 to 1
18
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
256 255 254 253 252
1
DRAM

l The data is sent to Sorting Network
Sorting 256 Elements from 256 to 1
19
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
256 255 254
…
64 63 … 3 2 1
256 255 254 253 252
1
IN OUT
Stage
DRAM

l Sorting Network can sort 16 elements Ø The initial data sequence turns into 16 sorted data sequences by passed through this network
Sorting 256 Elements from 256 to 1
20
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA 16 … 3 2 1 32 … 19 18 17 256 … 243 242 241
This is sorted 256 255 254 253 252
1
DRAM

l The data passed through the network is stored in Input Buffer, and sent to Merge Sorter Tree
Sorting 256 Elements from 256 to 1
21
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA 241 242 243 256… 225 226 240…
224… 208…
227 210 211 194 195
209 193
256 255 254 253 252
1
DRAM

l The root of the tree emits sorted data sequences
Sorting 256 Elements from 256 to 1
22
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA 241 242 243 256… 226 227 240…
224… 208…
228 210 211 209
193 194 195
…
196 201
202
225
203
256 255 254 253 252
1
DRAM
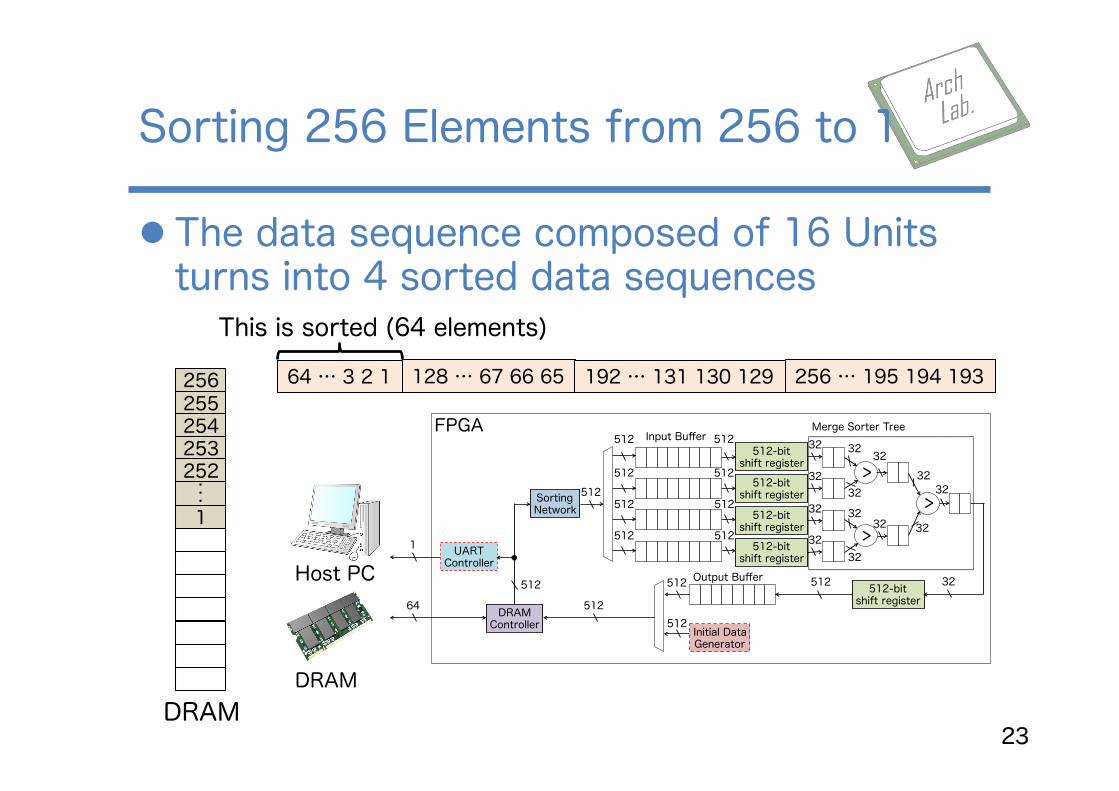
l The data sequence composed of 16 Units turns into 4 sorted data sequences
Sorting 256 Elements from 256 to 1
23
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
64 … 3 2 1 128 … 67 66 65 256 … 195 194 193
This is sorted (64 elements)
192 … 131 130 129 256 255 254 253 252
1
DRAM

l The data is stored in the external memory
Sorting 256 Elements from 256 to 1
24
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
193 194 195 196 197 198
199 200 201 202 203 204 ……
Store Area 256 255 254 253 252
1
DRAM

l This data is not fully sorted yet... Ø This data has to be sent to Merge Sorter Tree again
Sorting 256 Elements from 256 to 1
25
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
256 255 254 253 252
1 193 194 195
62 63 64
DRAM

l The data is read form DRAM and sent to Sorting Network
Sorting 256 Elements from 256 to 1
26
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
193 194 195
…
129 130 … 62 63 64
Load Area 256 255 254 253 252
1 193 194 195
62 63 64
DRAM
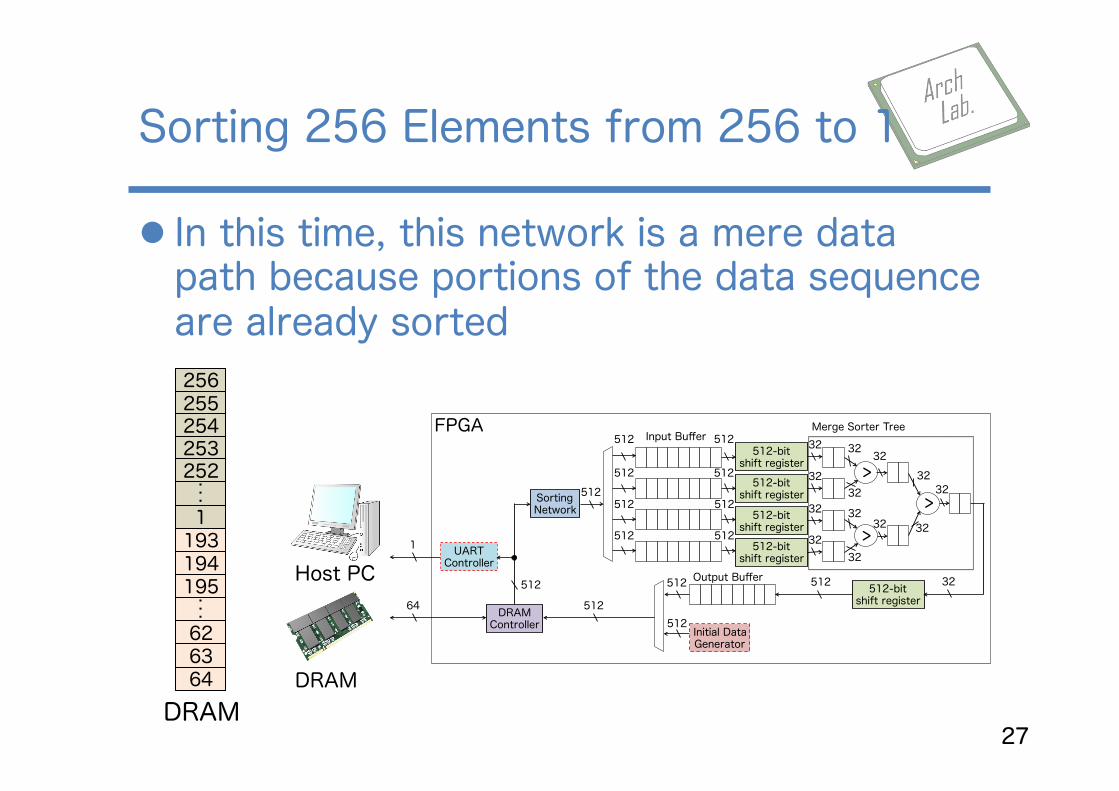
l In this time, this network is a mere data path because portions of the data sequence are already sorted
Sorting 256 Elements from 256 to 1
27
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
256 255 254 253 252
1 193 194 195
62 63 64
DRAM

l The data passed through the network is stored in Input Buffer, and sent to Merge Sorter Tree
Sorting 256 Elements from 256 to 1
28
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
256 255 254 253 252
1 193 194 195
62 63 64
193 194 195 256… 129 130 192…
128… 64…
131 66 67 2 3
65 1
DRAM
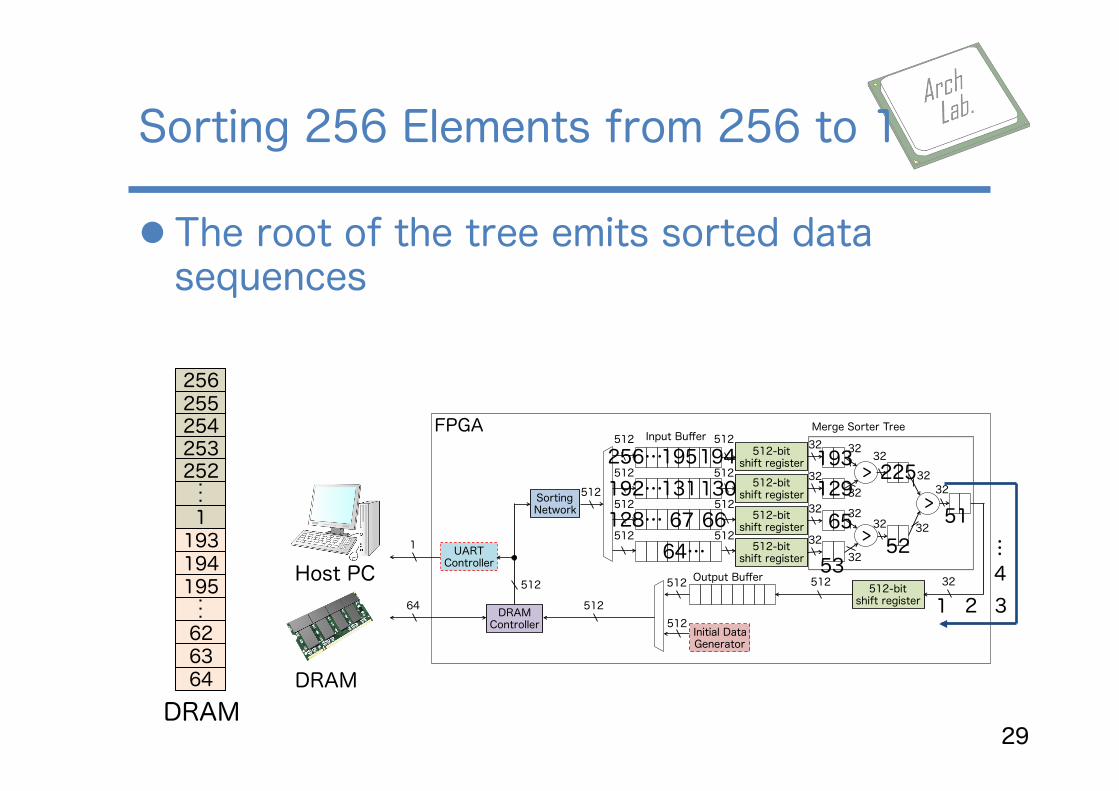
l The root of the tree emits sorted data sequences
Sorting 256 Elements from 256 to 1
29
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
256 255 254 253 252
1 193 194 195
62 63 64
64…
1 2 3
…
4
51 52
225
53
193 194 195 256… 129 130 192…
128… 131
66 67 65
DRAM

l The data is stored in the external memory
Sorting 256 Elements from 256 to 1
30
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
1 2 3 4 5 6
7 8 9 10 11 12 ……
Store Area 256 255 254 253 252
1 193 194 195
62 63 64
DRAM
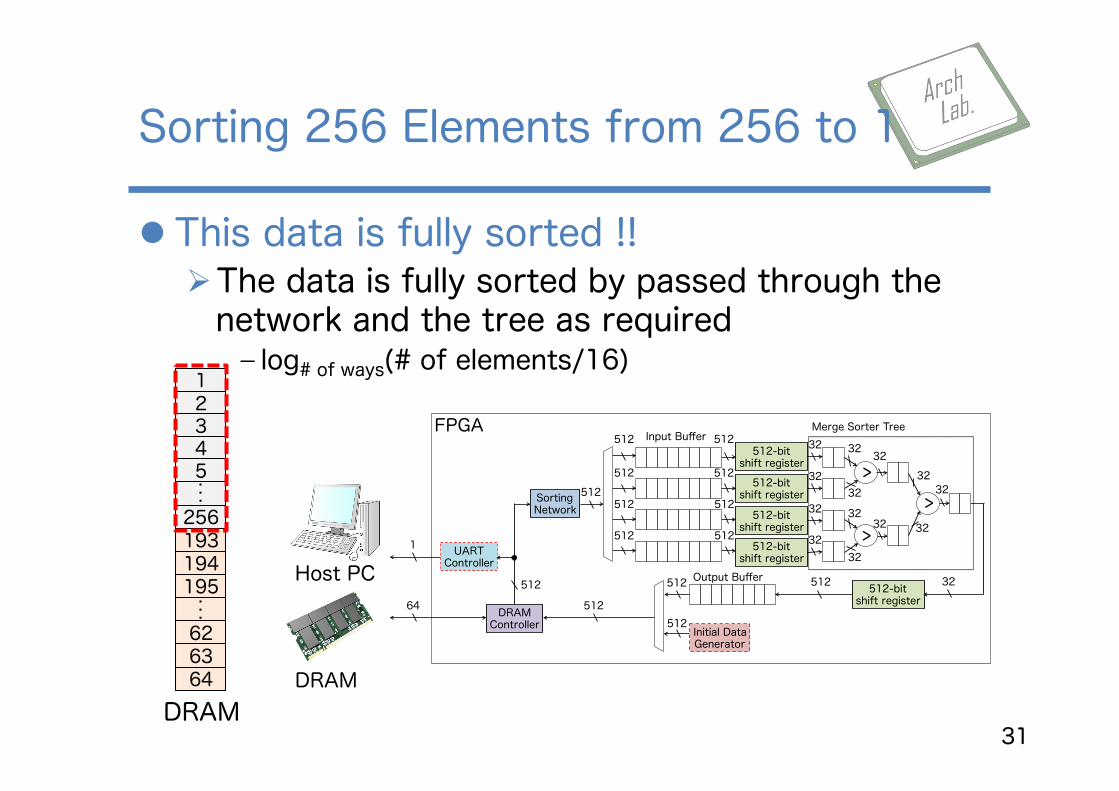
l This data is fully sorted !! Ø The data is fully sorted by passed through the network and the tree as required ﹣ log# of ways(# of elements/16)
Sorting 256 Elements from 256 to 1
31
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
1 2 3 4 5
256 193 194 195
62 63 64
DRAM
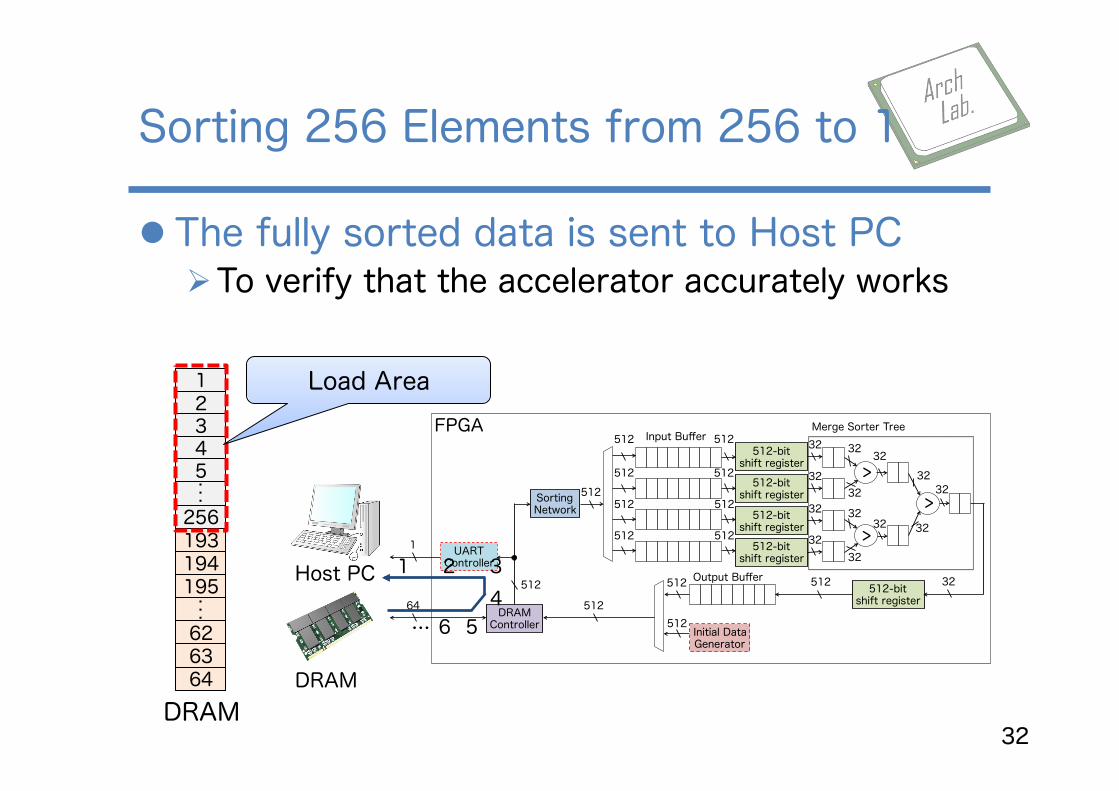
l The fully sorted data is sent to Host PC Ø To verify that the accelerator accurately works
Sorting 256 Elements from 256 to 1
32
DRAM
Host PC
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
512-bit shift register
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
1 2 3 4 5
256 193 194 195
62 63 64
Load Area
1 2 3 4
5 6 …
DRAM

l Duplication of the merge sorter tree
Data Path of the Accelerator with the Duplicated Merge Sorter Tree
33
512-bit shift register 512-bit
shift register 512-bit
shift register
>
> >
32 32 32 32
32 32
32 32
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512-bit shift register
32
512
512
512
512
Input Buffer Merge Sorter Tree
Initial Data Generator
Sorting Network
512
512
512
512
DRAM Controller
UART Controller
Output Buffer 32 512 512
512 512
512
512
1
64
FPGA
Duplicated Logics
512-bit shift register

l Effectiveness Ø To sort data sequences in parallel ﹣ The sorting logic throughput is improved
Duplication of the Merge Sorter Tree
34 The accelerator with four 4-way trees sorts the initial data sequence
193 194 … 256 129 130 … 192 65 66 … 128 1 2 … 64
256 … 194 193 192 … 130 129 128 … 66 65 64 … 2 1 Initial Data Sequence
Sorting the data in parallel Tree 0 Tree 1 Tree 2 Tree 3
Executing merge process in a tree
1 2 3 4 5 6 7 8 … … … … 253 254 255 256 Sorting is done!!!

l This accelerator is customizable by tuning # of ways and duplicated trees
l This accelerator performance can be formulated Ø Designer can estimate accelerator performance in advance and implement the best one fulfilling hardware resource constraints
Characteristics of the Accelerator
35
# of required cycles to finish sorting (k: # of ways, P: # of trees, N: # of elements)

36
Evaluation
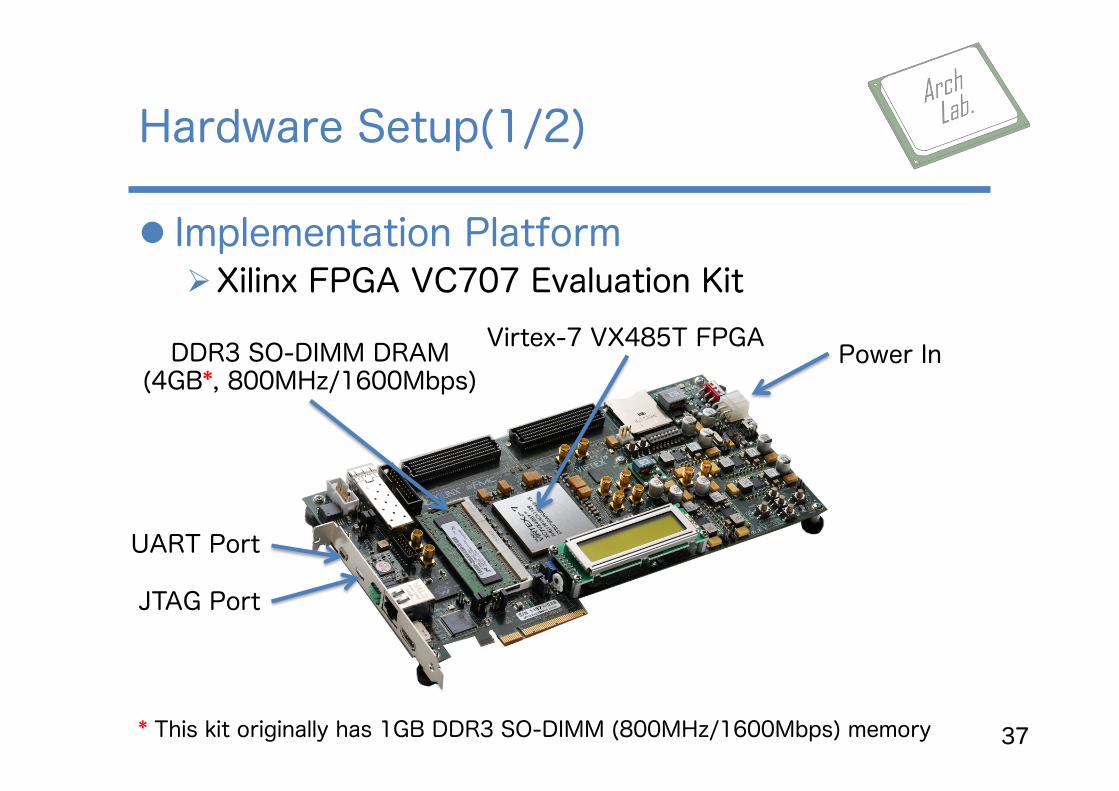
l Implementation Platform Ø Xilinx FPGA VC707 Evaluation Kit
Hardware Setup(1/2)
37
Power In
UART Port
JTAG Port
DDR3 SO-DIMM DRAM (4GB*, 800MHz/1600Mbps)
* This kit originally has 1GB DDR3 SO-DIMM (800MHz/1600Mbps) memory
Virtex-7 VX485T FPGA

l All logics are implemented in Verilog HDL l Design Tool: Vivado2014.4 l Operating frequency
Ø Logic: 200MHz,Memory bus: 800MHz l Initial Data Generator
Ø Supporting the following data-generation types ﹣ A random data sequence using Xorshift* ﹣ A sorted data sequence ﹣ A reverse-order sorted data sequence
Hardware Setup(2/2)
38 * George Marsaglia, Xorshift RNGs, Journal of Statistical Software 2003.

l Point: Sorting Process Time and hardware resource usage Ø Dataset: 256M 32-bits integer values
l Opponent: Intel Corei7-4770 @ 3.4GHz Ø A single thread Ø gcc 4.8.2 (-O3 optimization) Ø Sorting algorithm ﹣ Merge sort ﹣ Quick sort
l How to measure the execution time Ø FPGA -> to get execution cycles Ø CPU -> to use gettimeofday
Evaluation
39

l Sorting performance Ø It is improved as # of ways and trees is larger Ø It is independent of data-sequence types Ø It is almost same as estimated one
Evaluation: Sorting Performance
40
0
10
20
30
40
50
60
merge sort
quick sort 4-way
4-way/2-parallel
4-way/4-parallel
8-way
8-way/2-parallel
8-way/4-parallel
8-way/8-parallel
16-way
16-way/2-parallel
16-way/4-parallel
Sorting Process Time[sec]
xorshift sorted reverse Estimated

0
10
20
30
40
50
60
merge sort quick sort 8-way/8-parallel
Sorting Process Time[sec]
xorshift sorted reverse
l In a case of random data sequence Ø 10.06x faster than merge sort Ø 8.01x faster than quick sort
Evaluation: Sorting Performance of 8-way/8-parallel
41
10.06x 8.01x
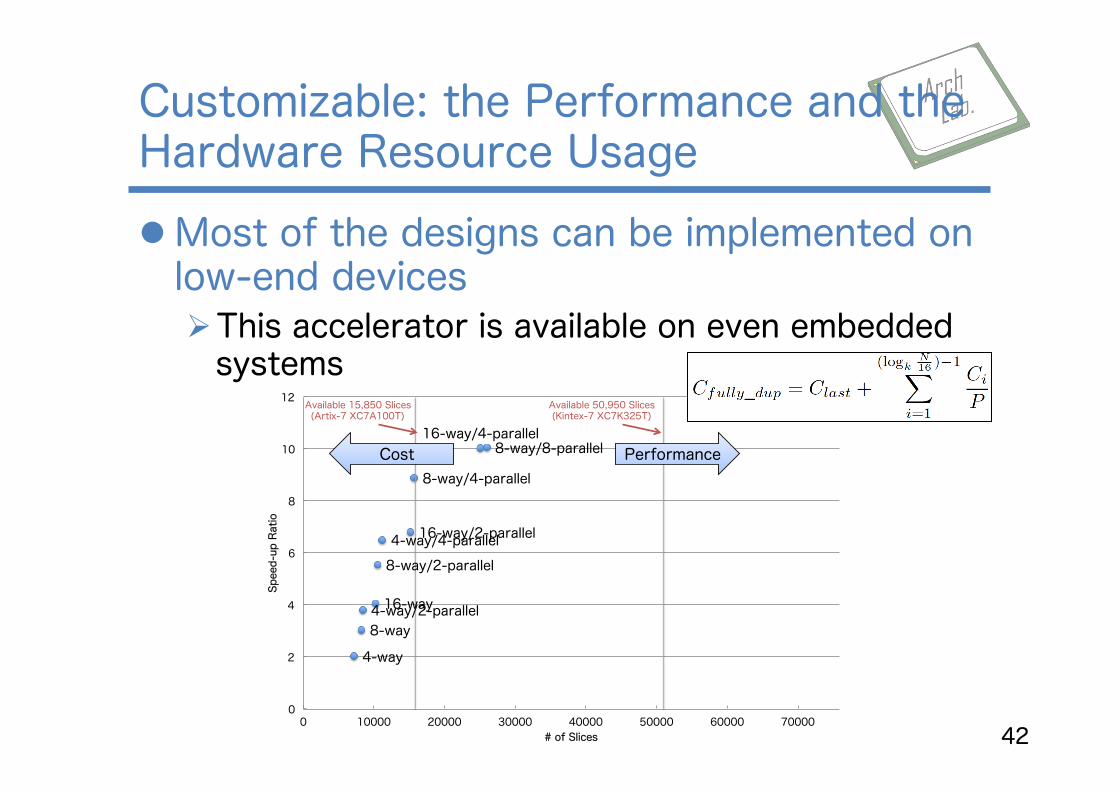
l Most of the designs can be implemented on low-end devices Ø This accelerator is available on even embedded systems
Customizable: the Performance and the Hardware Resource Usage
42
4-way
4-way/2-parallel
4-way/4-parallel
8-way
8-way/2-parallel
8-way/4-parallel
8-way/8-parallel
16-way
16-way/2-parallel
16-way/4-parallel
0
2
4
6
8
10
12
0 10000 20000 30000 40000 50000 60000 70000
Speed-up Ratio
# of Slices
Cost Performance
Available 15,850 Slices (Artix-7 XC7A100T)
Available 50,950 Slices (Kintex-7 XC7K325T)

l FACE is available on GitHub Ø https://github.com/monotone-RK/FACE
l Currently, FACE can work on Xilinx FPGA VC707 Evaluation Kit Ø We will try to port another environment if you have requests and if possible
Open Sourced
43 Xilinx FPGA VC707 Evaluation Kit

44

45
Conclusion

l FACE: Fast and Customizable Sorting Accelerator for Heterogeneous Many-core Systems Ø This accelerator is customizable by tuning # of ways and duplicated trees
Ø This accelerator performance can be formulated Ø Open sourced ﹣ Available on GitHub (https://github.com/monotone-RK/FACE)
l Future Work Ø Performance evaluation including data transfer ﹣ Bus system like AXI4 or Avalon, NoC, PCIe, etc...
Conclusion
46