facebook's tao & unicorn data storage and search platforms
TRANSCRIPT



A Systems Perspective …
• How do you store Petabytes of graph data ?
• How to efficiently serve billion reads and millions of writes each second ?
• How to search trillions of edges between tens of billions of users with a search latency ranging maximum in tens of milliseconds (1 millisecond average) ?
• TAO : A read optimized graph data store to server Facebook’s “Social Graph”.
• Unicorn : Online, In-Memory social graph-aware search and indexing system.

PART 1 : TAO at Facebook

1. Aggregating & Filtering hundreds of items.2. Custom Tailored Page with extreme customization and privacy checks.

A walk down memory lane :Scaling Memcache in Facebook (NSDI’ 13)
• Originally Facebook was built by storing social graph in MySQL and aggressively cached with Memcache.
• Issues with the original architecture :• Inefficient Edge lists manipulation. ( Key Value semantics require the entire
edge lists to be reloaded)
• Expensive Read-After-Write consistency : Asynchronous Master/Slave replication poses a problem for caches in data centers using a replica.

Goals for TAO
• Providing access to nodes and edges of aconstantly changing graph in data centersacross multiple regions.
• Optimize on reads and favor availability overconsistency.
• TAO does not implement complete graphprimitives but provide sufficientexpressiveness to handle most applicationsneeds.
• Example: Rendering a check-in would querythis event’s underlying nodes and edges everytime. Different users might see differentversions of this check-in.

Data Models and APIs
• Objects and Associations :• Objects are nodes and Associations and edges.
• Objects are identified as 64-bit integer(id) and associations as (source, destination) and a association type.
• At most one association of a given type exists between any two objects.
• Both associations and objects may contain key->value pairs.
• Actions may be encoded either as objects or associations ( comments are objects).
• Although associations are directed, it is common for an association to be tightly coupled with an inverse edge.
• Discovering the check-in object, however, requires the inbound edges or that an id is stored in another Facebook system.

Object and Association APIs
• Object APIs :• Allocate a new object and id.
• Retrieve, Update or Delete the object.
• There is no Compare and Set (due to eventual updated semantics).
• Association APIs :• Edges could be bidirectional, either symmetrically like the example’s FRIEND
relationship or asymmetrically like AUTHORED and AUTHORED BY.
• Bidirectional edges are modeled as two separate associations. TAO providessupport for keeping associations in sync with their inverses, by allowingassociation types to be configured with an inverse type.
• For such associations, creations, updates, and deletions are automaticallycoupled with an operation on the inverse association.

Association Lists
• A characteristic of the social graph is that most of the data is old, butmany of the queries are for the newest subset. This creation-timelocality arises whenever an application focuses on recent items.
• For a famous celebrity ‘Justin’, then there might be thousands ofcomments attached to his check-in, but only the most recent oneswill be rendered by default.
• TAO’s Association queries are organized around Association Lists.They have associations, arranged in descending order by the timefield : (id1, type) → [anew ...aold]
• TAO enforces a per Association type upper bound (typically 6,000) onthe actual limit used for an association query. To enumerate theelements of a longer association list the client must issue multiplequeries.

TAO Architecture
Key Ideas behind TAO’s architecture
Storage :The data is persisted using MySQL.The API is mapped to a small number of SQL queries.Data is divided into logical shards. By default all object typesare stored in one table and association in others.Every “object_id” has a corresponding “shard_id”. Objects arebounded to a single shard throughout their lifetime.An association is stored on the shard of its id1, so that everyassociation query can be served from a single server.

TAO Architecture ( Continued … )
Caching :• A region / tier is made of multiple closely located Data centers.• Multiple Cache Serves make up a tier (set of databases in a region are also called a
tier) that can collectively capable of answering any TAO Request.• Each cache request maps to a server based on sharding scheme discussed.• The cache is filled based on a LRU policy.• Write operations on an association with an inverse may involve two shards, since the
forward edge is stored on the shard for id1 and the inverse edge is on the shard forid2.
• Handling writes with multiple shards involve : Issuing an RPC call to the memberhosting id2, which will contact the database to create the inverse association. Oncethe inverse write is complete, the caching server issues a write to the database forid1.
• TAO does not provide atomicity between the two updates. If a failure occurs theforward may exist without an inverse, these hanging associations are scheduled forrepair by an asynchronous job.

Leaders and Followers
• Builds a two level cache hierarchy (L1->L2). (All to All connections inSingle layer cache is susceptible to Hot Spots)
• Clients communicate with the closest followers directly.
• Each shard is hosted by one leader, and all writes to the shard gothrough that leader, so it is naturally consistent. Followers, on theother hand, must be explicitly notified of updates made via otherfollower tiers.
• An object update in the leader enqueues invalidation messages toeach corresponding follower.
• Leaders serialize concurrent writes that arrive from followers. Leaderprotects databases from “Thundering herds” by not issuingconcurrent writes and limiting maximum number of queries.

TAO’s Stack

Scaling Geographically
• High read workload scales with total number of follower servers.
• The assumption is that latency between followers and leaders is low.
• Followers behave identically in all regions, forwarding read misses andwrites to the local region’s leader tier. Leaders query the local region’sdatabase regardless of whether it is the master or slave. This meansthat read latency is independent of inter-region latency.
• Writes are forwarded by the local leader to the leader that is in theregion with the master database. Read misses by followers are 25X asfrequent as writes in the workload thus read misses are served locally.
• Facebook chooses data center locations that are clustered into only afew regions, where the intra-region latency is small (typically less than1 millisecond). It is then sufficient to store one complete copy of thesocial graph per region.

Scaling Geographically …
• Since each cache hosts multiple shards, a server may be both a master and aslave at the same time. It is preferred to locate all of the master databases in asingle region.
• When an inverse association is mastered in a different region, TAO must traversean extra inter-region link to forward the inverse write.
• TAO embeds invalidation and refill messages in the database replication stream.These messages are delivered in a region immediately after a transaction hasbeen replicated to a slave database. Delivering such messages earlier wouldcreate cache inconsistencies, as reading from the local database would providestale data.
• If a forwarded write is successful then the local leader will update its cache withthe fresh value, even though the local slave database probably has not yet beenupdated by the asynchronous replication stream. In this case followers willreceive two invalidates or refills from the write, one that is sent when the writesucceeds and one that is sent when the write’s transaction is replicated to thelocal slave database.

TAO’s STACK (Multiple Region)

Consistency Matters
• In the end consistency is The KEY !
• Imagine a scenario : Likes on your Facebook post magically increasing or decreasing ?
• TAO’s master/slave design ensures that all reads can be satisfiedwithin a single region, at the expense of potentially returning staledata to clients. As long as a user consistently queries the samefollower tier, the user will typically have a consistent view of TAOstate.

Implementation
• All the data related to objects are serialized into a single ‘data’ column( supporting flexible schema).
• Shards are mapped to cache servers using Consistent Hashing. TAOrebalances load among followers with shard cloning, in which readsto a shard are served by multiple followers in a tier.
• Versioning is used to omit replies if data has not changed.
• The master database is a consistent source of truth. We can markcertain requests as critical and proxy them to master (authentication)

Failure Detection and Handling
• TAO servers employ aggressive network timeouts so as not to continuewaiting on responses that may never arrive.
• Databases are marked down in a global configuration if they crash / takenoffline for maintenance or if they get too far behind. When a masterdatabase is down, one of its slaves is automatically promoted to be thenew master.
• Followers Failure• Followers in other tier (Backup) share the responsibility of the shard.
• Leader Failure• Followers route read requests around it directly to database.• Write requests are rerouted to a random member of leader’s tier.
• Invalidation Message Failure• Leaders queue message to disk if followers are unreachable.• If a leader failure occurs and is replaced : All shards that map to it must be
invalidated in the followers, to restore consistency.

Some Performance Metrics
Replication: TAO’s slave storage servers lag their master byless than 1 second during 85% of the tracing window, byless than 3 seconds 99% of the time, and by less than 10seconds 99.8% of the time.

PART 2 : Unicorn at Facebook

What is Graph Search ?

What is Unicorn?
• Online, In-Memory “social graph aware” indexing system serving billions of query a day.
• The idea is to promote social proximity.
• Serves as the backend infrastructure for graph search.
• Searching all basic structured information on the social graph and perform complex set of operations on the results.
• Why a big deal ?
Facebook engineer’s joked that – much like the mythical quadruped—this system would solve all of our problems and heal our woes if only it existed.

Core Technical Ideas
• Applying common information retrieval architectural concepts in the domain of social graph search.
• How do you promote socially relevant search results ?
• Building rich operators ( apply & extract ) that allow rich semantic graph queries that allow multiple round trip algorithms for serving complicated queries.
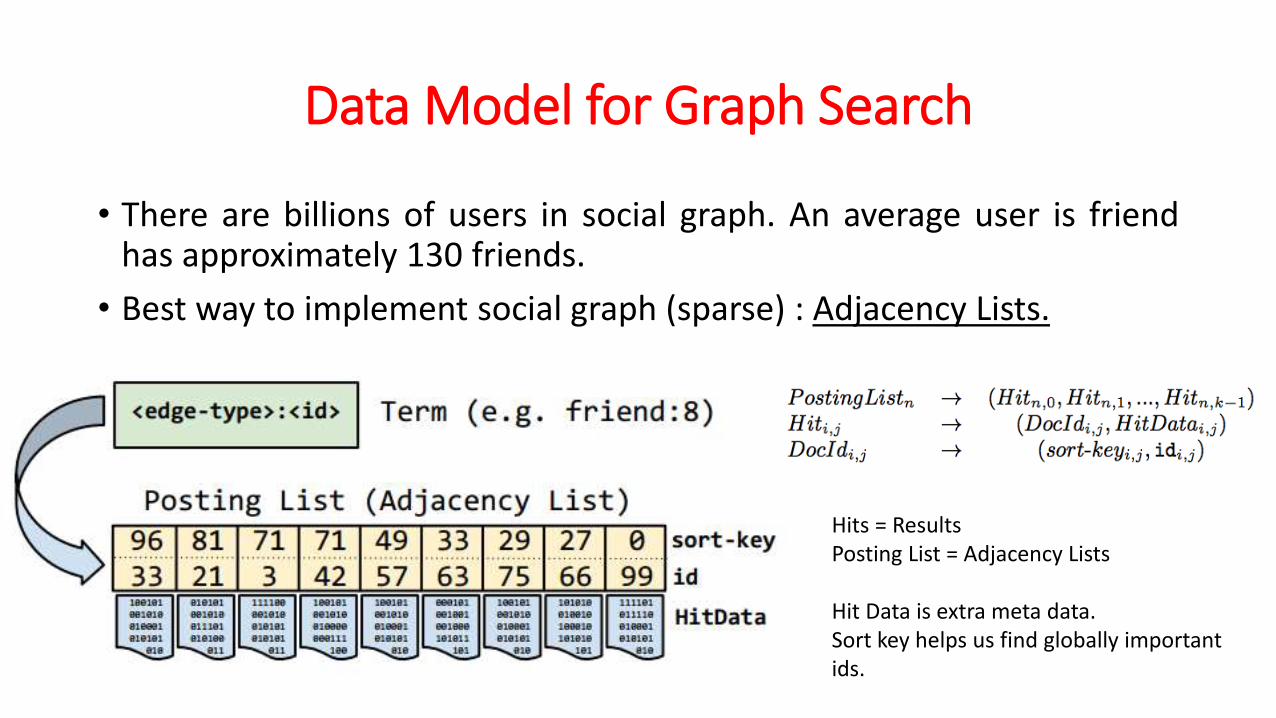
Data Model for Graph Search
• There are billions of users in social graph. An average user is friendhas approximately 130 friends.
• Best way to implement social graph (sparse) : Adjacency Lists.
Hits = ResultsPosting List = Adjacency Lists
Hit Data is extra meta data.Sort key helps us find globally important ids.

Unicorn API & Popular Edge Types
• Client sends ‘Thrift’ requests to server. (Facebook’s own Protocol –Buffer)
• Request is routed to closest Unicorn server.
• Several operators supported : Or, And, Difference.
• Meta-Data : ‘graduation year’ and ‘major’ for attended.
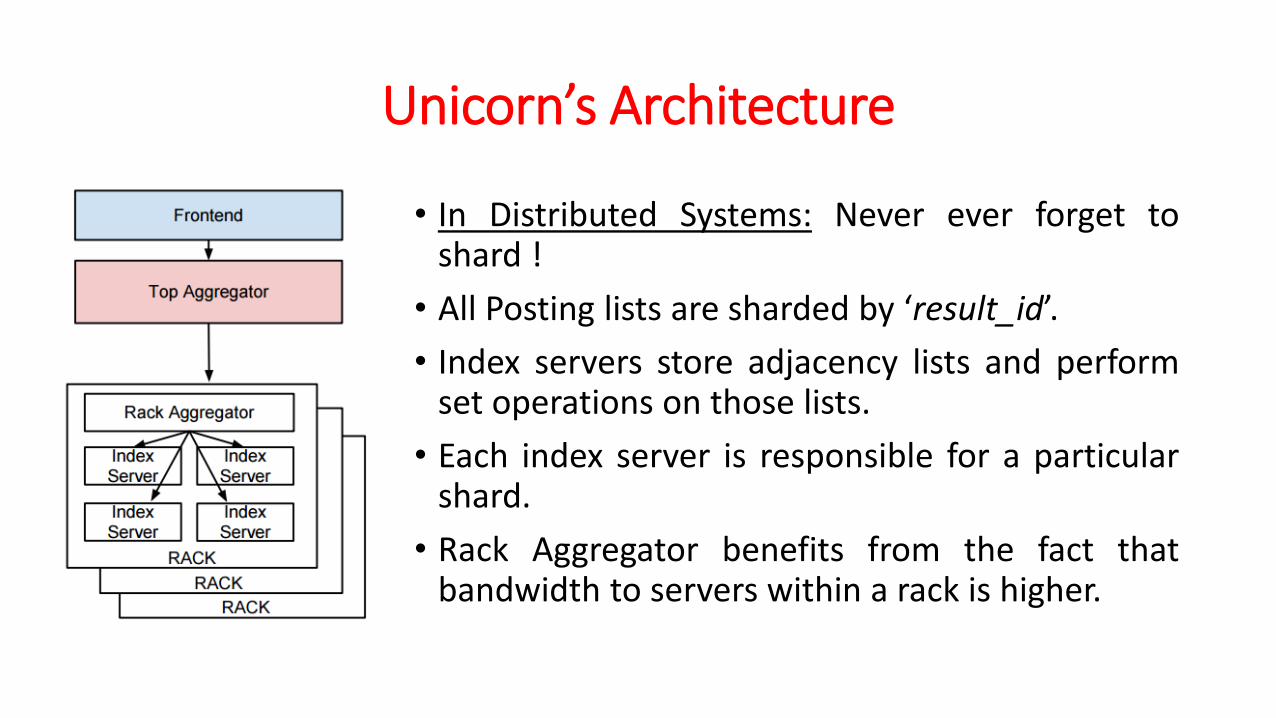
Unicorn’s Architecture
• In Distributed Systems: Never ever forget toshard !
• All Posting lists are sharded by ‘result_id’.
• Index servers store adjacency lists and performset operations on those lists.
• Each index server is responsible for a particularshard.
• Rack Aggregator benefits from the fact thatbandwidth to servers within a rack is higher.

Search across Verticals

Building and Updating Index
• Raw data is scraped from MySQL and indexes are built with Hadoop.
• The data is accessible via Hive.
• To avoid lag (common in batch processing). For pushing latest minute data : Facebook uses Scribe.
• Each index server keep tracks of the last updated timestamp.

TYPEAHEAD Search
• It all started with a Type Ahead Search.
• Users are shown a list of possible match for the query as they aretyping.
• Index servers for Type Ahead contain posting lists for every nameprefix up to a predefined character limit.
• These posting lists contain the ids of users whose first or last namematches the prefix.
• A simple Type ahead implementation would merely map inputprefixes to the posting lists for those prefixes and return the resultantids.
• How do you make this socially relevant ?

Serving Socially Relevant Results• How do you ensure that search results are
socially relevant ?• Can we “AND” the solution with the friend list
of user ? ( Ignores results for users who might be relevant but are not friends with the user performing the search).
• We actually want a way to force some fraction of the final results to possess a trait, while not requiring this trait from all results.
• The answer is WeakAnd operator.• The WeakAnd operator is a modification of
And that allows operands to be missing from some fraction of the results within an index shard.
• Implementation : Allow only finite number of hits to be non-friends.
Priscilla Chan (3), looking for : “Melanie Mars” ….

Strong OR
• Requires certain operands to be present in some fraction of the matches.
• Enforces diversity in the set.
• Example : Fetching geographically diversity in the result set.
• At least 20% from San Francisco.
• An optional weight parameter as well.

Scoring Search Results
• We might want to prioritize results for individuals who are in close in age to the user typing the query.
• This requires that we store the age (or birth date) of users with the index.
• For storing per-entity metadata, Unicorn provides a forward index, which is simply a map of id to a blob that contains metadata for the id. The forward index for an index shard only contains entries for the ids that reside on that shard.
• Based on Thrift parameters included with the client’s request, the client can select a scoring function in the index server that scores each result.
• Aggregators give priority to documents with higher score.

Graph Search
• Our discussion of graph search spans : users, pages, apps, events etc.
• Imagine a scenario : We might want to know the pages liked by friends ofBill who likes Trekking :
1. First execute the query (and friend:7 likers:42)2. Collecting the results, and create a new query that produces the union of the
pages liked by any of these individuals.
• Inefficient due to multiple round trips involved between index servers andtop aggregator.
• The ability to use the results of previous executions as seeds for futureexecutions creates new applications for a search system, and was theinspiration for Facebook’s Graph Search consumer product. The idea was tobuild a general-purpose, online system for users to find entities in thesocial graph that matched a set of user-defined constraints.

Apply Operator
• A graph traversal operator that allowsclient to query a set of ids and then use theresultant ids to construct and execute anew query.
• Apply is a ‘syntactic sugar’ to allow asystem to perform expensive operationslower in the hardware stack. However, byallowing clients to show semantic intent,optimizations are possible to preservesearch time.

Extract Operator• Say you want to look up people tagged in
photos of “Jon Jones”.
• Solution: ‘Apply’ operator to look up photosof Jon Jones in the photos vertical and thento query the users vertical for peopletagged in these photos.
• Now you need hundred of billions of newterms in users vertical.
• Billions of “one to few” mapping.
• Better way: Store the ids of people taggedin a photo in the forward index data for thatphoto in the photos vertical. This is a casewhere partially de-normalizing. We thusstore the result ids in the forward index ofthe secondary vertical and do the lookupinline.
• This is exactly what Extract operatoraccomplishes.

Preserving Privacy
• Privacy is crucial !
• Certain graph edges cannot be shown to all users but rather only tousers who are friends with or in the same network as a particularperson.
• Unicorn itself does not have privacy information incorporated into itsindex : Strict consistency and durability guarantees are absent thatare needed for a full privacy solution.
• Facebook PHP frontend makes a proper privacy check on the result.This design decision imposes a modest efficiency penalty on theoverall system.
• However it also keeps privacy logic separate from Unicorn with theDRY (“Don’t Repeat Yourself”) principle of software development

Lineage : Preserving Privacy To enable clients to make privacy decisions, a string of metadata is attached to each search result to describe its lineage. Lineage is a structured representation of the edges that were traversed in order to yield a result.

Questions?