fast-matmul-ppopp2015
TRANSCRIPT

A FRAMEWORK FOR PRACTICAL
PARALLEL FAST MATRIX MULTIPLICATION
github.com/arbenson/fast-matmul
1
Austin Benson
Stanford UniversityJoint work with
Grey Ballard, Sandia
PPoPP 2015
San Francisco, CA 9000 10000 11000 12000 1300018
20
22
24
26
28
Dimension (N)E
ffe
ctive G
FL
OP
S /
core
Performance (6 cores) on N x N x N
MKL
STRASSEN
<3,2,2>
<3,2,4>
<4,2,3>
<3,4,2>
<3,3,3>
<4,2,4>
<2,3,4>

Fast matrix multiplication:
bridging theory and practice
• There are a number of Strassen-like algorithms for matrix
multiplication that have only been “discovered” recently. [Smirnov13], [Benson&Ballard14]
• We show that they can achieve higher performance with respect
to Intel Math Kernel Library (MKL).
• We use code generation for extensive prototyping.
2
32 2.81[Strassen79]
2.37[Williams12]
xxx xx xx xx

Strassen’s algorithm
3

Key ingredients of Strassen’s algorithm
• 1. Block partitioning of matrices (<2, 2, 2>)
• 2. Seven linear combinations of sub-blocks of A
• 3. Seven linear combinations of sub-blocks of B
• 4. Seven matrix multiplies to form Mr (recursive)
• 5. Linear combinations of Mr to form Cij
4

Key ingredients of fast matmul algorithms
• 1. Block partitioning of matrices (<M, K, N>)
• 2. R linear combinations of sub-blocks of A
• 3. R linear combinations of sub-blocks of B
• 4. R matrix multiplies to form Mr (recursive)
R < MKN faster than classical
• 5. Linear combinations of Mr to form Cij
5
Key idea: Trade N^3 computation (matmul) for more
N^2 computation (adding matrices together).

“Outer product” fast algorithm
• <4, 2, 4> partitioning
• R = 26 multiplies (< 4 * 2 * 4 = 32)
23% speedup per recursive step (if everything else free)
• Linear combinations of Aij to form Sr: 68 terms
• Linear combinations of Bij to form Tr: 52 terms
• Linear combinations of Mr to form Cij: 69 terms
6
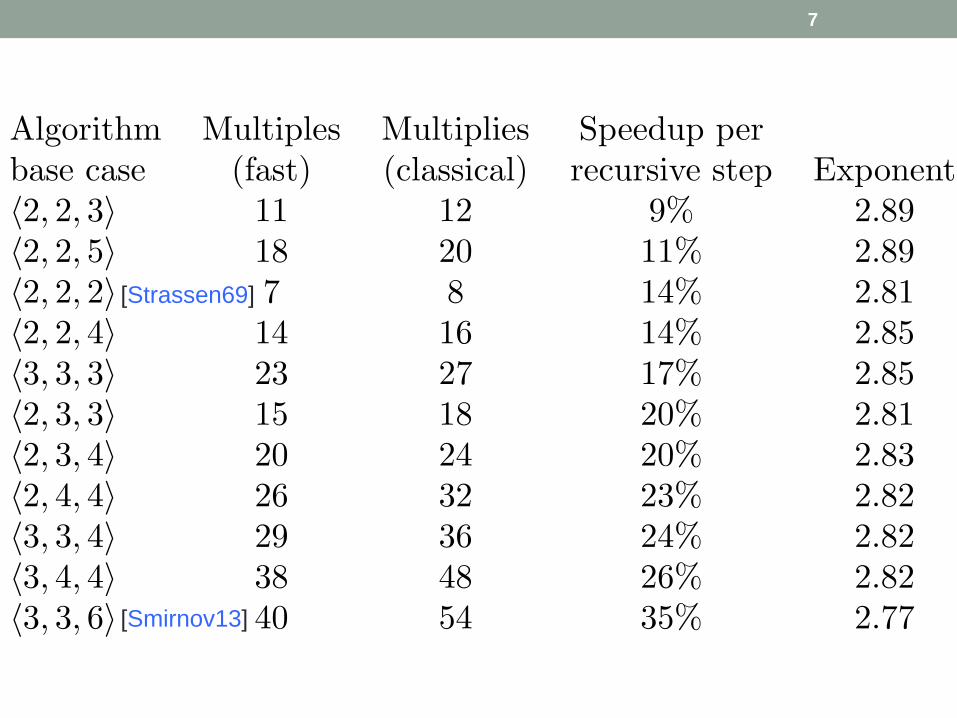
7
[Smirnov13]
[Strassen69]

Code generation lets us prototype
algorithms quickly
• We have compact representation of many fast algorithms:
1. dimensions of block partitioning (<M, K, N>)
2. linear combinations of sub-blocks (Sr, Tr)
3. linear combinations of Mr to form Cij
• We use code generation to rapidly prototype fast algorithms
• All code available github.com/arbenson/fast-matmul
8

Sequential performance =
9
Effective GFLOPS for M x K x N multiplies
= 1e-9 * 2 * MKN / time in seconds
Classical
peak
0 2000 4000 6000 800016
18
20
22
24
26
28
Dimension (N)
Eff
ective
GF
LO
PS
Sequential performance on N x N x N
MKL
STRASSEN
<4,2,2>
<3,2,3>
<3,3,2>
<5,2,2>
S<4,3,3>

2000 4000 6000 8000 10000 1200020
22
24
26
28
dimension (N)
Eff
ective
GF
LO
PS
Sequential performance on N x 1600 x N
MKL
<4,2,4>
<4,3,3>
<3,2,3>
<4,2,3>
STRASSEN
Sequential performance =
• Almost all algorithms beat MKL
• <4, 2, 4> and <3, 2, 3> tend to perform the best
10

10000 12000 14000 16000 18000 10000 12000 14000 1600022
23
24
25
26
27
28
dimension (N)
Effe
ctive
GF
LO
PS
Sequential performance on N x 2400 x 2400
MKL
<4,2,4>
<4,3,3>
<3,2,3>
<4,2,3>
STRASSEN
S<4,3,3>
Sequential performance=
• Almost all algorithms beat MKL
• <4, 3, 3> and <4, 2, 3> tend to perform the best
11

Parallelization
C
M1 M7
+
M2…
M1 M7
+
M2…
M1 M7
+
M2…
12

DFS Parallelization
C
M1 M7
+
M2…
M1 M7
+
M2…
All threads
Use parallel MKL
+ Easy to implement
+ Load balanced
+ Same memory
footprint as sequential
- Need large base
cases for high
performance
13

BFS Parallelization
C
M1 M7
+
M2…
M1 M7
+
M2 …
omp taskwait
omp taskwait
1 thread
+ High performance for smaller base cases
- Sometimes harder to load balance: 24 threads, 49 subproblems
- More memory
1 thread 1 thread
14

HYBRID parallelization
C
M1 M7
+
M2…
M1 M7
+
M2…
omp taskwait
omp taskwait
1 thread 1 thread all threads
+ Better load balancing
- Explicit synchronization or else we can over-subscribe threads
15

0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8
x 104
0
5
10
15
20
25
Dimension (N)
Eff
ective
GF
LO
PS
/ c
ore
Parallel performance of <4,2,4> on <N,2800,N>
MKL, 6 cores
MKL, 24 cores
DFS, 6 cores
BFS, 6 cores
HYBRID, 6 cores
DFS, 24 cores
BFS, 24 cores
HYBRID, 24 cores
16
26 multiplies
24 cores
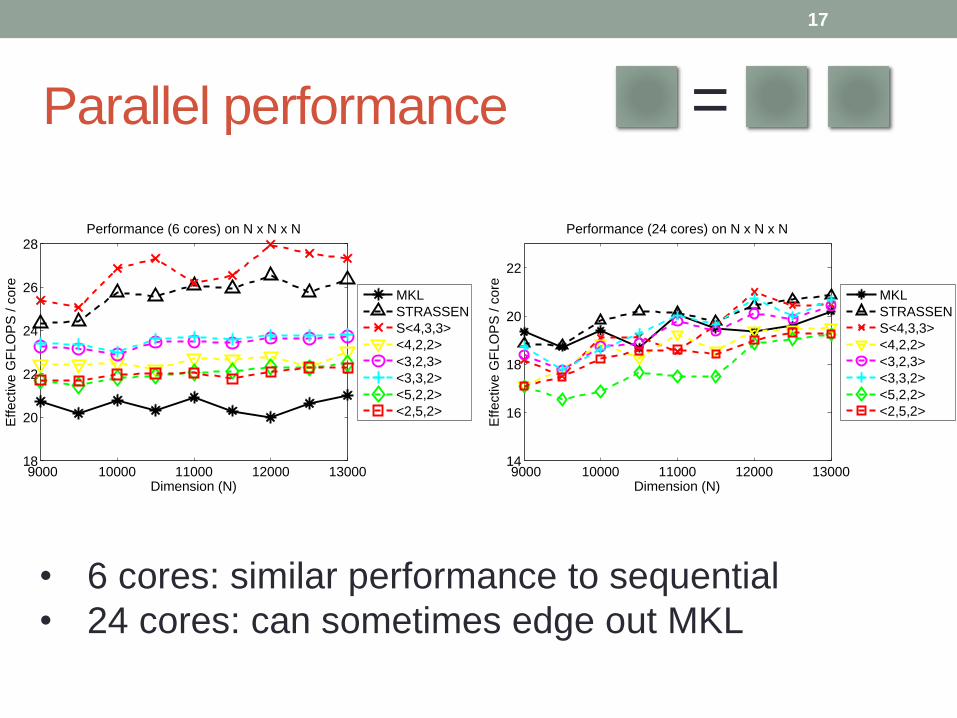
Parallel performance =
17
9000 10000 11000 12000 1300018
20
22
24
26
28
Dimension (N)
Eff
ective
GF
LO
PS
/ c
ore
Performance (6 cores) on N x N x N
MKL
STRASSEN
S<4,3,3>
<4,2,2>
<3,2,3>
<3,3,2>
<5,2,2>
<2,5,2>
9000 10000 11000 12000 1300014
16
18
20
22
Dimension (N)E
ffective
GF
LO
PS
/ c
ore
Performance (24 cores) on N x N x N
MKL
STRASSEN
S<4,3,3>
<4,2,2>
<3,2,3>
<3,3,2>
<5,2,2>
<2,5,2>
• 6 cores: similar performance to sequential
• 24 cores: can sometimes edge out MKL

10000 15000 20000 10000 1500018
19
20
21
22
23
24
dimension (N)
Eff
ective
GF
LO
PS
/ c
ore
Performance (6 cores) on N x 2800 x N
MKL
<4,2,4>
<4,3,3>
<3,2,3>
<4,2,3>
STRASSEN
5000 10000 15000 2000012
14
16
18
20
dimension (N)
Eff
ective
GF
LO
PS
/ c
ore
Performance (24 cores) on N x 2800 x N
MKL
<4,2,4>
<4,3,3>
<3,2,3>
<4,2,3>
STRASSEN
Parallel performance =Bad MKL
performance
• 6 cores: similar performance to sequential
• 24 cores: MKL best for large problems
18

Parallel performance =
• 6 cores: similar performance to sequential
• 24 cores: MKL usually the best
19
10000 15000 20000 10000 1500018
19
20
21
22
23
dimension (N)
Eff
ective
GF
LO
PS
/ c
ore
Performance (6 cores) on N x 3000 x 3000
MKL
<4,2,4>
<4,3,3>
<3,2,3>
<4,2,3>
STRASSEN
16000 18000 20000 22000 24000 2600012
13
14
15
16
17
18
dimension (N)
Eff
ective
GF
LO
PS
/ c
ore
Performance (24 cores) on N x 3000 x 3000
MKL
<4,2,4>
<4,3,3>
<3,2,3>
<4,2,3>
STRASSEN

Bandwidth problems• We rely on the cost of matrix multiplications to be much
more expensive than the cost of matrix additions
• Parallel dgemm on 24 cores: easily get 50-75% of peak
• STREAM benchmark: < 6x speedup in read/write
performance on 24 cores
C
M1 M7
+
M2…
20

High-level conclusions
• Sequential: match the shape of the algorithm to the shape of
the matrix. Straightforward to beat vendor implementation.
• Parallel: bandwidth limits performance
should be less of an issue in distributed memory
Future work:
• Distributed memory implementation
• Numerical stability (do not panic)
21

A FRAMEWORK FOR PRACTICAL
PARALLEL FAST MATRIX MULTIPLICATION
github.com/arbenson/fast-matmul
22
Austin Benson
Stanford UniversityJoint work with
Grey Ballard, Sandia
PPoPP 2015
San Francisco, CA 9000 10000 11000 12000 1300018
20
22
24
26
28
Dimension (N)E
ffe
ctive G
FL
OP
S /
core
Performance (6 cores) on N x N x N
MKL
STRASSEN
<3,2,2>
<3,2,4>
<4,2,3>
<3,4,2>
<3,3,3>
<4,2,4>
<2,3,4>