feature-based opinion mining through ontologies
TRANSCRIPT

Accepted Manuscript
Feature-Based Opinion Mining through ontologies
Isidro Peñalver-Martinez, Francisco Garcia-Sanchez, Rafael Valencia-Garcia,Miguel Ángel Rodríguez-García, Valentín Moreno, Anabel Fraga, Jose LuisSánchez-Cervantes
PII: S0957-4174(14)00151-1DOI: http://dx.doi.org/10.1016/j.eswa.2014.03.022Reference: ESWA 9235
To appear in: Expert Systems with Applications
Please cite this article as: Peñalver-Martinez, I., Garcia-Sanchez, F., Valencia-Garcia, R., Rodríguez-García, M.,Moreno, V., Fraga, A., Sánchez-Cervantes, J.L., Feature-Based Opinion Mining through ontologies, Expert Systems
with Applications (2014), doi: http://dx.doi.org/10.1016/j.eswa.2014.03.022
This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customerswe are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, andreview of the resulting proof before it is published in its final form. Please note that during the production processerrors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.

Feature-Based Opinion Mining through ontologies
Isidro Peñalver-Martinez1, Francisco Garcia-Sanchez1, Rafael Valencia-Garcia1, Miguel Ángel Rodríguez-García1, Valentín Moreno2, Anabel Fraga2 and Jose Luis
Sánchez-Cervantes2
1Departamento de Informática y Sistemas. Facultad de Informática. Universidad de Murcia Campus de Espinardo 30100 Murcia
{[email protected], [email protected], [email protected], [email protected] }
2Computer Science Department. Universidad Carlos III de Madrid.
Av. Universidad 30, Leganés, 28911, Madrid, SPAIN {[email protected] , [email protected],[email protected]}
Abstract. The idiosyncrasy of the Web has, in the last few years, been altered by Web 2.0 technologies and applications and the advent of the so-called Social Web. While users were merely information consumers in the traditional Web, they play a much more active role in the Social Web since they are now also data providers. The mass involved in the process of creating Web content has led many public and private organizations to focus their attention on analyzing this content in order to ascertain the general public’s opinions as regards a number of topics. Given the current Web size and growth rate, automated techniques are essential if practical and scalable solutions are to be obtained. Opinion mining is a highly active research field that comprises natural language processing, computational linguistics and text analysis techniques with the aim of extracting various kinds of added-value and informational elements from users’ opinions. However, current opinion mining approaches are hampered by a number of drawbacks such as the absence of semantic relations between concepts in feature search processes or the lack of advanced mathematical methods in sentiment analysis processes. In this paper we propose an innovative opinion mining methodology that takes advantage of new Semantic Web-guided solutions to enhance the results obtained with traditional natural language processing techniques and sentiment analysis processes. The main goals of the proposed methodology are: (1) to improve feature-based opinion mining by using ontologies at the feature selection stage, and (2) to provide a new vector analysis-based method for sentiment analysis. The methodology has been implemented and thoroughly tested in a real-world movie review-themed scenario, yielding very promising results when compared with other conventional approaches.
Keywords: Opinion mining, Ontology, Sentiment Analysis, Feature extraction, Part of speech tagging, Polarity identification.

1 Introduction
User participation is the primary value driver in Web 2.0 applications. Such a simple idea has had a tremendous impact on the way in which users interact with the Web. While on traditional Web 1.0 sites, companies published content and users were merely information consumers, in the Web 2.0 era users play a more active role in Web interactions, and have become not only consumers but also producers of information and media. In this new context, namely the Social Web, the number of online reviews in which people freely express their opinions with regard to a whole variety of topics is constantly increasingly. The content that is produced as a direct consequence of this user participation on Websites such as Amazon (http://www.amazon.com), booking (http://www.booking.com) or IMDB (http://www.imdb.com) is useful for both information providers and readers. Opinion mining is a recent sub-discipline at the crossroads of information retrieval and computational linguistics. The focus of opinion mining does not concern the topic that a text is about, but rather what opinion that text expresses (Esuli & Sebastiani, 2005). It determines whether the comments in online forums, blogs or comments relating to a particular topic (product, book, movie, etc.) are positive, negative or neutral. Opinions are very important when someone wishes to hear another’s views before making a decision.
Although various approaches have been applied to opinion mining, two major methodologies can be distinguished. On the one hand, there are approaches for opinion mining that aim to classify entire documents as having a positive or negative polarity, while on the other there are segment level opinion analysis approaches whose aim is to distinguish sentimental from non-sentimental sections. Both methodologies have some drawbacks because an entire document or a single sentence could contain different opinions about different features of the same product or service (Cambria et al., 2013). In fact, classifying opinions at the document or sentence level does not indicate what the user likes and dislikes. A positive document on an object does not mean that the user has positive opinions on all aspects or features of that object. Likewise, it is impossible to ensure that a negative document signifies that the user dislikes everything about the object. In a document (e.g., a product review), the user typically writes about both the positive and negative aspects of the object, although the general sentiment toward that object may be positive or negative (Ahmad & Doja, 2012). To obtain such detailed aspects, it is necessary to perform feature-based opinion mining in an attempt to identify the features in the opinion and classify the sentiments of the opinion for each of these features (Feldman, 2013). The feature-based opinion mining of product reviews is a difficult task, owing to both the high semantic variability of the opinions expressed, and the diversity of the characteristics and sub-characteristics that describe the products and the multitude of opinion words used to depict them (Balahur & Montoyo, 2010).
In this context, new approaches based on both domain-dependent corpora and semantic web technologies for feature-based opinion mining have therefore appeared in the last few years (Cambria et al., 2013).
Semantic Web technologies are currently achieving a certain degree of maturity (Shadbolt et al., 2006). The semantic Web was conceived with the aim of adding semantics to the data published on the Web (i.e., establish the meaning of the data), thus allowing machines to be able to process these data in a way similar to that of

humans (Berners-Lee & Hendler, 2001). Semantic technologies have been successfully applied in several natural language processing tasks such as information retrieval (Gladun et al., 2013), knowledge acquisition from texts (Ochoa et al., 2013) or semantic annotation (Rodriguez-García et al., 2014). In this context, we believe that the already mature Semantic Web technology may be a valuable addition to traditional opinion mining approaches. More concretely, ontologies constitute the standard knowledge representation mechanism for the Semantic Web and can be used to structure information. The formal semantics underlying ontology languages enables the automatic processing of the information in ontologies and allows the use of semantic reasoners to infer new knowledge. In this work, an ontology is viewed as “a formal and explicit specification of a shared conceptualization” (Studer et al., 1998). Ontologies provide a formal, structured knowledge representation, with the advantage of their being reusable and shareable. They also provide a common vocabulary for a domain and define, with different levels of formality, the meaning of the terms’ attributes and the relations between them. In this work, the Web Ontology Language (OWL), the W3C standard used to represent ontologies in the Semantic Web, has been used to represent the concepts and features of the application domain. Knowledge in OWL ontologies is mainly formalized by using five kinds of components: classes, datatype properties, object properties, axioms and individuals.
However, most of the studies on opinion mining deal exclusively with English documents, perhaps owing to the lack of resources in other languages (Martin-Valdivia et al., 2013). Since the Spanish language has a much more complex syntax than many other languages, and is currently the third most spoken language in the world, we are of the firm belief that the computerization of Internet domains in this language is of great importance.
The work presented herein is principally motivated by the need to develop new feature-based opinion mining approaches which leverage knowledge technologies that can be applied to different languages (such as Spanish) and different domains while operating in an automated fashion. During the first stage of the proposed methodology, Semantic Web techniques are used to identify features from a domain ontology. Once these features have been identified, new polarity identification and opinion mining approaches are used to obtain an effective and efficient sentiment classification. The proposed approach has been validated with a use case scenario in the movie review domain.
The remainder of the paper is organized as follows: related work is expounded in Section 2; the proposed method is explained in Section 3; a validation of this ontology-guided approach in the movie review domain is performed in Section 4; and finally, conclusions and future work are put forward in Section 5.
2 Related Work
Opinion mining (aka sentiment analysis or sentiment classification) is gaining momentum in the current Social Web landscape. Quite a number of researchers from both the information retrieval and computational linguistics fields have focused their investigations on this particular subject. Some of the most prominent research works on this topic are reviewed in this section.

Most current opinion mining approaches classify words into two categories (positive or negative) and provide an overall positive or negative score for the text. If a document contains more positive than negative terms, it is assumed to be a positive document, and is otherwise considered to be negative. These classification mechanisms are useful and improve the effectiveness of a sentiment classification but are not sufficiently precise to help determine what the opinion holder liked and disliked about each particular product feature/aspect.
There are also studies that not only determine the polarity of a text (positive or negative) but also indicate the level of polarity as being high/medium/low positive/negative, such as the work presented in (Baccianella et al., 2009) in which several aspects of the problem in the product domain are explored, with special emphasis on how to generate vectorial representations of the text by means of POS tagging, sentiment analysis, and feature selection for ordinal regression learning.
Other approaches, such as that of (Gamon, 2005), make use of a complete set of statistical feature selection methods and also apply machine learning techniques. The experiments conducted by the aforementioned researchers demonstrate that machine learning techniques do not achieve an overall satisfactory performance level in sentiment classification.
The application of Semantic Web technology, and more concretely ontologies, to feature-based opinion mining has been introduced in some recent works (Zhou & Chaovalit, 2008; Zhao & Li, 2009; Kontopoulos et al., 2013). The main goal of these works is to calculate the polarity by taking into consideration the features of a concept. In these works the authors propose that the domain ontologies which model the content of the texts in the corpus should first be built, and that the adjectives appertaining to the features in the texts from these ontologies should then be extracted. In (Zhou & Chaovalit, 2008), the polarity of a text is calculated on the basis of feature weights, and the value of each feature’s polarity is estimated using the “maximum likelihood estimate” approach. In (Zhao & Li, 2009), the authors obtain the text’s semantic orientation from the ontology hierarchy. The method proposed is also capable of obtaining the positive, negative and neutral orientation of the text.
Finally, several opinion mining methods have been proposed in the last few years. Most of the current opinion mining techniques are focused on either Chinese or English. Table 1 shows some of the most recent sentiment classification systems that have been applied to different domains. This classification includes some of the most relevant works in opinion mining from 2011 to 2014. The heterogeneity of this field is also highlighted in the table. In fact, given that this field is open to various research subdisciplines, the goal of these works is markedly different and they aim to attain different results. The principal opinion-mining related parameters (i.e., Initial Requirements, Opinion Classification Approach, Degree of automation, Featured-Based, Domain, Language and Sentiment Classification Level) are thoroughly analyzed in the following subsections.
2.1. Initial Requirements.
With regard to the initial requirements, namely resources or background knowledge, most of the approaches make use of lexicons of sentiment words. For example, the approaches presented in (Cruz et al., 2013; Martín-Valdivia et al., 2013; Singh et al., 2013) use SentiWordNet (Baccianella et al., 2010), while those presented

in (Min & Park, 2012; Kontopoulos et al., 2013) use other less popular sentiment lexicons. Other approaches meanwhile leverage lexicons developed by their authors, such as the work presented in (Eirinaki et al., 2012) which creates a new sentiment lexicon formed of adjectives. In (Zhai et al., 2011), a sentiment lexicon in the Chinese language is used. The approaches presented in (Eirinaki et al., 2012) and in (Ghiassi et al., 2013) incorporate micro-blogging sentiment lexicons. Finally, in (Chen et al., 2012) an algorithm that combines manual and automatic sentiment tagging is presented.
Conversely, there are other approaches based on the calculation of term weighting. For example in (Zhai et al., 2011; Rushdi Saleh et al., 2011; Deng et al., 2014) several well known term weighting techniques such as TF or TFIDF are used.
Our approach also makes use of sentiment word lexicons and, more concretely, SentiWordNet.
2.2. Opinion Classification approach.
Sentiment classification techniques can be divided into machine-learning approaches and dictionary-based approaches. However, despite the fact that machine-learning approaches have made significant advances in sentiment classification, applying them to news comments requires the use of labeled training data sets. Dictionary-based approaches, on the other hand, can provide significant advantages, such as the fact that once they have been built, no training data are necessary.
Several opinion mining systems currently use machine learning techniques to carry out the sentiment classification process. More concretely, the Support Vector Marchines (SVM) are widely applied in a number of works (Zhai et al., 2011; Rushdi Saleh et al., 2011; Ghiassi et al., 2013; Deng et al., 2014). Other approaches combine two or more machine learning algorithms. For example, (Min & Park, 2012) combine SVM and stepwise rule decision trees, while (Martin-Valdivia et al., 2013) combine SVM with unsupervised learning approaches. Some other approaches, such as that of (Cruz et al., 2013), have been designed to be fully flexible in terms of the application of machine learning-based sentiment classification techniques, and any mining method is therefore feasible in these works. Other machine learning techniques, such as Conditional Random Fields (CRFs), have also been used for sentiment classification (Chen et al., 2012).
Other approaches, such as those of (Eirinaki et al., 2012; Singh et al., 2013), are based on dictionary-based algorithms. Finally, the system presented in (Kontopoulos et al., 2013) uses a third-party sentiment analysis service.
The methodology described in this paper combines the use of domain ontologies with a new technique based on vector calculation using spatial distances in R3 to improve the sentiment analysis process. Overall, our proposed architecture results in a more detailed analysis of user opinions in two dimensions: (i) the general user opinion and (ii) all the features identified in the user’s opinion. Our approach is not constrained to the use of a single very specific topic, since the proposed method is capable of analyzing and classifying the sentiments of each topic discussed by users in their opinion set.

2.3. Degree of automation.
Another parameter that can be used to classify the various opinion mining approaches is the degree of automation. As shown in Table 1, most opinion mining works, such as those of (Zhai et al., 2011; Min & Park, 2012; Chen et al., 2012; Cruz et al., 2013; Martín-Valdivia et al., 2013; Eirinaki et al., 2012; Kontopoulos et al., 2013), have a degree of automation that can be categorized as semi-automatic. This is mainly owing to the fact that the approaches usually require the intervention of an expert in order to obtain the results. For example, the system described in in (Kontopoulos et al., 2013) requires the creation of a domain ontology based on the users’ tweets. In order to confront this challenge, the authors resorted to a semi-automatic, data-driven ontology editor. Other methods are automatic, such as those of (Rushdi Saleh et al., 2011; Ghiassi et al., 2013; Singh et al., 2013; Deng et al., 2014).
Since our proposed methodology is based on a generic domain ontology and comprises the application of an automatic sentiment classification method for user opinions, this approach does not require human intervention and can be considered as fully automatic.
2.4. Featured-Based.
Opinion mining experts have traditionally focused on building sentiment analysis applications that handle user opinions as a whole. The latest trend in this field is, however, to identify a set of so-called features in the user opinions and to provide a separate detailed report on the polarity of each feature.
As is shown in Table 1, almost all the selected works on opinion mining incorporate a feature identification step as part of the sentiment analysis process (Zhai et al., 2011; Rushdi Saleh et al., 2011; Min & Park, 2012; Chen et al., 2012; Cruz et al., 2013; Martín-Valdivia et al., 2013; Eirinaki et al., 2012; Kontopoulos et al., 2013; Ghiassi et al., 2013; Singh et al., 2013). Over the last few years, this approach has successfully demonstrated its effectiveness in the opinion mining field.
Our proposed approach deals with feature identification by using domain ontologies. It identifies and associates each feature with one of the classes in the domain ontology. What is more, our feature selection can be applied to any domain by changing the ontology that models the domain.
2.5. Domain.
The experts in the opinion mining field have, to date, paid little attention to the domains in which opinion mining techniques are applied. The particularities of each application domain have consequently not been investigated until recently. In this respect, (Rushdi Saleh et al., 2011) empirically demonstrate that the accuracy of the sentiment analysis methods that they propose largely depends on the domain of interest. The movie domain is, for example, very challenging since a recommended movie often contains unpleasant parts which reduce the average semantic orientation. The product domain, on the other hand, usually results in the best sentiment analysis results in terms of accuracy.

With regard to the selected related work, the majority has been validated in product (Zhai et al., 2011; Rushdi Saleh et al., 2011; Min & Park, 2012; Chen et al., 2012; Cruz et al., 2013; Eirinaki et al., 2012; Kontopoulos et al., 2013), tourism (Zhai et al., 2011; Cruz et al., 2013) or movie (Rushdi Saleh et al., 2011; Martín-Valdivia et al., 2013; Singh et al., 2013; Deng et al., 2014) domains. Finally, the work presented in (Ghiassi et al., 2013) was validated in the music domain.
Our proposed sentiment analysis solution is domain-independent. It can be adapted to each specific domain by accessing a particular domain ontology and a corpus with user opinions in the same domain. In this work, the proposed approach has been validated in the movie domain. 2.6. Language.
Most sentiment analysis solutions have been designed to work properly with inputs in English (Rushdi Saleh et al., 2011; Min & Park, 2012; Chen et al., 2012; Cruz et al., 2013; Martín-Valdivia et al., 2013; Eirinaki et al., 2012; Kontopoulos et al., 2013; Ghiassi et al., 2013; Singh et al., 2013; Deng et al., 2014). There are, however, currently many ongoing research works whose aim is to apply opinion mining techniques to the Chinese (Zhai et al., 2011) and Spanish languages (Martín-Valdivia et al., 2013).
The sentiment analysis approach presented here is language-independent. It can be adapted to each specific language by accessing a domain ontology and a corpus with user opinions in the language in question, and has been validated in both English and Spanish.
2.7. Sentiment Classification Level.
Sentiment classification can be performed at word level, sentence level and document level. Few of the approaches studied are based on sentence-level sentiment analysis (Cruz et al., 2013; Kontopoulos et al., 2013; Ghiassi et al., 2013). For example, in (Kontopoulos et al., 2013) the authors present a sentiment analysis method conducted at the level of short sentences, since it aims to analyze opinions posted by users on Twitter. In this microblogging platform, users can send text messages called “tweets” which are limited to 140 characters. Since these messages are based on a very specific topic and users express their opinions about that topic in short sentences, the sentiment analysis process is facilitated.
Most of the existing approaches are, however, based on document-level sentiment classification (Zhai et al., 2011; Rushdi Saleh et al., 2011; Min & Park, 2012; Chen et al., 2012; Martín-Valdivia et al., 2013; Eirinaki et al., 2012; Singh et al., 2013; Deng et al., 2014).
In our work, document-level sentiment analysis takes place. Each user opinion may extend to an average of a 100 lines of text, so it is common for users to provide comments concerning several different topics within the same opinion. In this case the sentiment analysis method must therefore confront a number of additional challenges. Various strategies have been adopted in order to overcome these problems and these are detailed in the following section.

2.8 Conclusion.
To summarize, the opinion mining solution presented in this work: (i) makes use of the SentiWordNet sentiment word lexicon to help identify sentiment-related words in texts; (ii) applies an opinion classification approach based on the use of domain ontologies along with vector calculation; (iii) does not require human intervention (i.e., is fully automatic); (iv) leverages knowledge technologies for domain-independent feature identification; (v) can be applied to different domains by merely adjusting the domain ontology and the corpus; (vi) is likewise language-independent on the basis of the ontology and opinion corpus provided, and (vii) performs a challenging document-level sentiment analysis. The semantically-boosted feature-based opinion mining approach proposed here has a number of significant advantages in comparison to related work. Besides sharing the precision provided by feature-based techniques, knowledge technologies permit domain and language independence, a more detailed analysis of user opinions (both general and feature specific), and full automation. Both the application domain and the language can be customized by changing the domain ontology and the corpus. Moreover, the proposed new technique for opinion classification based on ontologies and vector calculation using spatial distances in R3 results in improved sentiment analysis. Finally, the automation of the methodology is achieved by using generic domain ontologies and an automatic sentiment classification method.

Approach Initial
requirements
Opinion
Classification
Approach
Degree of
automation
Featured-Based Domain Language Sentiment
Classification Level
(Chen et al., ,
2012)
Combination of
manual or self
tagging
Conditional
Random Fields
(CRFs)-
Semi-automatic Yes Products English Document
(Cruz et al., 2013) Sentiment words Different opinion
classifiers
Semi-automatic Yes Products
(Headphones)
Hotel
Cars
English Sentence
(Deng et al., 2014) Term weighting SVM Automatic No Movies English Document
(Eirinaki et al.,
2012)
Sentiment-
adjectives
Dictionary-based Semi-automatic Yes Products English Document
(Ghiassi et al.,
2013)
Sentiment Words,
Micro-blogging
lexicon
Neuronal networks
and SVM
Automatic Yes Music English Sentence
(Kontopoulos et
al., 2013)
Sentiment words Third-party
sentiment analysis
service
Semi-automatic Yes Products
(Smartphones)
English Sentence
(Martín-Valdivia
et al., 2013)
Sentiment words SVM and
unsupervised
approaches
Semi-automatic Yes Movies English and
Spanish
Document
(Min & Park,
2012)
Sentiment words,
Micro-blogging
lexicon
Stepwise Rules,
Decision Tree and
SVM
Semi-automatic Yes Products English Document
(Rushdi Saleh et
al., 2011)
Term weighting SVM Automatic Yes Products (Digital
cameras,
Computers)
Movies
English Document
(Singh et al.,
2013)
Sentiment words Dictionary-based Automatic Yes Movies English Document
(Zhai et al., 2011) Sentiment-words,
n-grams, term
weighting
SVM Semi-automatic Yes Hotel
Product
Chinese Document
Our approach Sentiment-words Ontology-based
Dictionary-based
Automatic Yes Domain
independent
English and
Spanish
Document
Table 1. Opinion Mining systems.

3 Ontology based opinion mining
The principal objectives of the approach proposed in this manuscript are to improve feature-based opinion mining by employing ontologies in the selection of features and to provide a new method for sentiment analysis based on vector analysis. In order to achieve these goals, we present a framework composed of four main modules (see Fig. 1), namely, the Natural Language Processing (NLP) module, the ontology-based feature identification module, the polarity identification module and the opinion mining module. A detailed description of these components is provided below.
Fig 1. Proposed system architecture
3.1. NLP module.
This component is responsible for obtaining the morphologic and syntactic structure of each sentence. To this end, a set of NLP tools including a sentence detection component, tokenizer, POS taggers, lemmatizers and syntactic parsers has been developed using the Stanford Log-linear Part-Of-Speech Tagger framework

(http://nlp.stanford.edu/software/tagger.shtml). The Stanford Log-linear Part-Of-Speech Tagger is an infrastructure which is used to develop and deploy software components that process human language. It helps scientists and developers in two ways: (i) by specifying an architecture or organizational structure for language processing software; and (ii) by providing a framework or class library that implements the architecture and can be used to embed language processing capabilities in diverse applications.
A Part-Of-Speech Tagger (POS Tagger) is a piece of software that reads text in a particular language and assigns parts of speech to each word (and other tokens), such as noun, verb, adjective, etc. In general, computational applications use more fine-grained POS tags like 'noun-plural'. The Stanford Log-linear Part-Of-Speech Tagger is a Java implementation for the log-linear part-of-speech (POS) taggers described in (Toutonova & Manning, 2000; Toutonova et al., 2003). The tagger was originally written by Kristina Toutanova. Since that time, various researchers have focused on improving its speed, performance, usability, and support for other languages.
The approach proposed here is primarily designed to work with user opinion texts written in English. The Stanford Log-linear Part-Of-Speech Tagger framework contains three trained tagger models for the English language (see Fig. 2).
bidirectional-distsim-wsj-0-18.tagger Trained on Wall Street Journal (WSJ, www.wsj.com) sections 0-18 using a bidirectional architecture and including word shape and distributional similarity features. Penn Treebank tagset. Performance: 97.28% correct with WSJ 19-21 (90.46% correct with unknown words) left3words-wsj-0-18.tagger Trained on WSJ sections 0-18 using the left3words architecture, and includes word shape features. Penn tagset. Performance: 96.97% correct with WSJ 19-21 (88.85% correct with unknown words) left3words-distsim-wsj-0-18.tagger Trained on WSJ sections 0-18 using the left3words architecture, and includes word shape and distributional similarity features. Penn tagset. Performance: 97.01% correct with WSJ 19-21 (89.81% correct with unknown words)
Fig 2. English taggers in Stanford Log-linear Part-Of-Speech Tagger.
Bidirectional taggers are slightly more accurate when used with the English language, but the tagging process is much slower, and it is thus necessary to choose the appropriate tagger based on the user’s speed/performance needs. In our work, the option chosen has been the left3words-wsj-0-18.tagger. The tagger could in fact be

retrained for any language, given a POS-annotated training text for the language. English taggers use the Penn Treebank tag set1.
An excerpt of a user’s opinion of a particular film is shown in Fig. 3. It constitutes an input model for the NLP module. The results of the morphological analysis that the NLP module carries out are shown in Fig. 4.
Fig 3. Excerpt of a user’s opinion.
3.2. Ontology-based feature Identification module.
A domain ontology is used in order to extract the features included in the opinions expressed by users. We only need a general domain ontology, and we do not need to create a specific domain ontology starting with the user opinions to build it. Once the features in the opinions have been identified, a score that represents the importance of a given feature is calculated for each of the features retrieved (see Fig. 5). This module receives both a corpus of opinions and the domain ontology as input. The sentences in the corpus that contain the classes, individuals, datatype and object properties of the domain ontology are then identified from this input. Once the features have been recognized, they are grouped in accordance with their semantic distance and are then attached to a main concept of the ontology.
Let us suppose, for demonstration purposes, that the domain ontology represents the movie domain (see Fig. 5). The movie ontology MO2, which is available at
1 Available at: http://www.computing.dcu.ie/~acahill/tagset.html 2 Amancio Bouza: “MO – the Movie Ontology”. MO – the Movie Ontology. 2010.
movieontology.org
“The actors are pretty good for the most part, although Wes Bentley just seemed to be playing the exact same character that he did in American Beauty, only in a new neighborhood. But my biggest kudos go out to Melissa Sagemiller, who holds her own throughout the entire film, and actually has you feeling her character's unraveling. Overall, the film doesn't stick because it doesn't entertain, it's confusing, it rarely excites and it feels pretty redundant for most of its runtime, despite a pretty cool ending and explanation to all of the craziness that came before it. Oh, and by the way, this is not a horror or teen slasher flick . . . it's just packaged to look that way because someone is apparently assuming that the genre is still hot with the kids. It also wrapped production two years ago and has been sitting on the shelves ever since. Whatever... skip it!”

http://www.movieontology.org, has been populated using the “Internet Movie Database” (IMDb) whose data are available at http://www.imdb.com.
Fig 4. Lemmatized words accompanied by their grammatical categories.
The features identified within the sentence shown in the previous section are
{“actors”, “Wes Bentley”, “American Beauty”, “Melissa Sagemiller”, “film”, “runtime”, “horror”, “flick”, “genre”, “kids”}. More concretely, “Wes Bentley” and “Melissa Sagemiller” are identified as individuals in the “Actor” class, and “actors” is the plural of the “Actor” class. “Film” and “flick” are identified as features because they are synonymous of the “Movie” class. Similarly, the words “kids” and “genre” are also features, because they represent the ontology classes “Kids” and “Genre”. At this point, thanks to the semantic structure of ontologies, the opinions that are concerned with the classes which are directly related to the "Movie” class, such as “Actor”, “Producer”, “Genre” and their individuals, would be taken into account in
The/DT actors/NNS are/VBP pretty/RB good/JJ for/IN the/DT most/JJS part/NN ,/, although/IN Wes/NNP Bentley/NNP just/RB seemed/VBD to/TO be/VB playing/VBG the/DT exact/JJ same/JJ character/NN that/IN he/PRP did/VBD in/IN American/JJ Beauty/NN ,/, only/RB in/IN a/DT new/JJ neighborhood/NN ./. But/CC my/PRP$ biggest/JJS kudos/NNS go/VBP out/RP to/TO Melissa/NNP Sagemiller/NNP ,/, who/WP holds/VBZ her/PRP$ own/JJ throughout/IN the/DT entire/JJ film/NN ,/, and/CC actually/RB has/VBZ you/PRP feeling/VBG her/PRP$ character/NN 's/POS unraveling/NN ./. Overall/RB ,/, the/DT film/NN does/VBZ n't/RB stick/VB because/IN it/PRP does/VBZ n't/RB entertain/VB ,/, it/PRP 's/VBZ confusing/JJ ,/, it/PRP rarely/RB excites/VBZ and/CC it/PRP feels/VBZ pretty/RB redundant/JJ for/IN most/JJS of/IN its/PRP$ runtime/NN ,/, despite/IN a/DT pretty/RB cool/JJ ending/VBG and/CC explanation/NN to/TO all/DT of/IN the/DT craziness/NN that/WDT came/VBD before/IN it/PRP ./. oh/UH ,/, and/CC by/IN the/DT way/NN ,/, this/DT is/VBZ not/RB a/DT horror/NN or/CC teen/JJ slasher/NN flick/NN .../: it/PRP 's/VBZ just/RB packaged/VBN to/TO look/VB that/DT way/NN because/IN someone/NN is/VBZ apparently/RB assuming/VBG that/IN the/DT genre/NN is/VBZ still/RB hot/JJ with/IN the/DT kids/NNS ./. It/PRP also/RB wrapped/VBD production/NN two/CD years/NNS ago/RB and/CC has/VBZ been/VBN sitting/VBG on/IN the/DT shelves/NNS ever/RB since/IN ./. Whatever/WDT .../: skip/VB it/PRP !/.

order to calculate the global polarity. For example, the word “horror” is identified as a new feature because it is an instance of the “Thrilling” class, which is a subclass of the “Imaginational_Entertainment” class, which is itself a subclass of the “Entertainment” class, a subclass of “Genre”. Lastly, the classes “Movie” and “Genre” are related by the property “belongsToGenre” (see Fig. 6). The same rationale is valid for the inclusion of the word “kids” as a new feature (see Fig. 6). Finally, the last feature identified is “runtime”, since there is a “DataPropertyDomain” called “runtime” in the “MovieOntology”.
Traditional feature identification methods assign the same importance to all the features identified in the text (Baccianella et al., 2009; Zhou & Chaovalit, 2008; Zhao & Li, 2009). In our approach, a separate score is calculated for each feature on the basis of the following assumptions: 1. Not all the features related to the same class have the same relevance. 2. The features that are most often cited by users in their opinions are more relevant. 3. From a journalistic discourse analysis viewpoint, the polarity of the last
paragraph coincides roughly with the global polarity of the text (Moreno et al., 2010). Starting and ending with positive or negative views enhances the positive or negative polarity. In this respect, the place in which a feature is written by users in their opinions should be considered in order to calculate the feature score for each opinion. For example, if the last sentence of a movie review is as follows: “undoubtedly a film with an amazing soundtrack”, then this enhances the positive polarity of the feature “soundtrack” in the user’s opinion, and this feature should therefore be given a higher score.
Fig 5. An excerpt of the MovieOntology
Once the features in the opinions have been identified, the score of the features in
each user’s opinion is calculated. In the formula used to calculate the score of a given feature in a user’s opinion, the position of the linguistic expression that represents the

feature within the text is taken into consideration. This is done by dividing the text into three equal parts: (1) the beginning, (2) the middle, and (3) the end of the opinion. This score is defined in the following equation (Equation 1):
Fig 6. Semantic structure for the the MovieOntology
||*||*||*),( 332211 OzOzOzuseropfscore i ++= (1)
where |Oj| is the number of occurrences of the feature f in the part of the text j of the useropi opinion, and Zj is a parameter that represents the importance of the occurrence of the feature in this part of the text. More specifically, Z1, Z2 and Z3 represent the importance of the features’ occurrences at the beginning, in the middle and at the end of the user’s opinion. The texts are segmented into three equal parts based on the number of words in the text.
The values for Z1, Z2 and Z3 will thus have an impact on the polarity of a feature in a user’s opinion and the global polarity of the user’s opinion. In the experimental results section (Section 4), the importance of these three parameters is proven by showing a comparison between the values of these three parameters and the accuracy of both the feature polarity and the global polarity of the user’s opinions.
For example, let us consider Z1 = 80, Z2 = 50 and Z3 = 100, where “useropX” is the user’s opinion, and the feature “movie” appears four times in the file (once at the beginning, once in the middle of the file, and twice at the end of the “useropX”).

Under these conditions, the score of the feature “movie” is, in the user’s opinion “useropX”, as follows:
score(movie, useropX) = 80 * 1 + 50 * 1 + 100 * 2 = 330
3.3. Polarity Identification module.
The feature polarity is calculated using SentiWordNet 3.0 (Baccianella et al., 2010) (SWN). This tool provides the positive, negative and neutral values of nouns, adjectives and verbs. In our framework it is necessary to retrieve this value for all the words that are located near to the linguistic expressions that represent a given feature in the opinion. The neutral sense is calculated as shown in Equation 2:
ScoreNeu = 1 – ScorePos – ScoreNeg (2)
The most common sense of the word that SWN provides is used for this purpose.
The vector ‘V’, which represents the polarity of a feature f in the user’s opinion ‘useropX’, is then defined as shown in the following equation (Equation 3).
),,(*),(),( ScoreNeuScoreNegScorePosuseropfscoreuseropfV xx =�
(3)
‘ScorePos’, ‘ScoreNeg’ and ‘ScoreNeu’ of a given word are calculated as the
average of the positive and negative senses of the word in question in the SWN database. These values are always positive values or zero. In the implementation of our method, if a negative clause is found in a sentence, then the values for ‘ScorePos’ and ‘ScoreNeg’ are exchanged.
In order to calculate the values for ‘ScorePos’ and ‘ScoreNeg’ in Equation 3, it is necessary to obtain the words from around the linguistic expression of the feature f employed by the user in ‘useropX’ to describe this feature. The words that are close to the feature can be obtained in a number of different ways. The following four methods have been implemented to evaluate our solution:
- N_GRAM Before: this method obtains the N_GRAM words before the linguistic expression of the feature in the user’s opinion.
- N_GRAM After: this method obtains the N_GRAM words after the linguistic expression of the feature in the user’s opinion.
- N_GRAM Around: this method obtains the N_GRAM words before the linguistic expression of the feature in the user’s opinion and the N_GRAM words after the linguistic expression of the feature in the user’s opinion.
- All Phrase: this method obtains all the words in the same sentence as the linguistic expression of the feature in the user’s opinion.
These methods require the system parameter N_GRAM, which indicates the number of words near the feature that are to be considered in the polarity identification process.
To continue with the example presented in the previous sections, the polarity of the feature ‘actors’ in the user’s opinion ‘useropX ‘ can be calculated as follows:
- The relevant sentence in the user’s opinion ‘useropX’ is: “The actors are pretty good for the most part”; the feature identified is: “actors”; and the sentiment values of the words around the feature are:

- “The” has 0 senses in the SWN database. Therefore, both ScorePos and ScoreNeg are equal to 0. - “are” has 1sense in the SWN database with average values of 0 for both ScorePos and ScoreNeg. - “pretty” has 3 senses in the SWN database with average values of 0.333 for ScorePos, and 0.417 for ScoreNeg. - “good” has 27 senses in the SWN database with average values of 0.597 for ScorePos, and 0.0050 for ScoreNeg. - “most” has 5 senses in the SWN database with average values of 0 for both ScorePos and ScoreNeg. - “part” has 18 senses in the SWN database with average values of 0 for both ScorePos and ScoreNeg.
- Feature Polarity Identification: V (actors, useropX) = score (actors, useropX) * (0.465, 0.211, 0.162), where score
(actors, useropX) is a positive value as shown in section 3.2.
3.4. Opinion Mining module.
After analyzing the corpus by means of NLP techniques, extracting the relevant features and identifying the features polarity, the framework proposed here provides an innovative opinion mining mechanism. The opinion mining module described in this section is based on vector analysis and enables an effective feature sentiment classification. As described above, features are represented using three coordinates, that is, each feature is described by using its Euclidean vector (V) in R3. A Euclidean vector is represented by two points, namely, the origin and the target. Since the origin point is always (0, 0, 0), the expression of the position vector is reduced to express the target point. A position vector is therefore expressed by V = (x, y, z). A feature with a strictly positive sense is determined by the position vector (N, 0, 0), where ‘N’ is a positive number. By analogy, vectors (0, N, 0) and (0, 0, N) represent the strictly negative and neutral senses, respectively.
The polarity of a feature f in the user’s opinion ‘useropX’, Polarity (f, useropX), is calculated as follows (see Equation 4):
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
==−=+
=truePPinsideifneutral
truePPinsideifnegativey
truePPinsideifpositivex
useropfPolarity
O
N
P
x
);()(0
);()(
);()(
),( (4)
Where: - P=(x, y, z), is the target point of V(f, useropX).
- PP is the geometric pyramid whose volume is composed of all the target points of position vectors with a positive direction.
- PN is the geometric pyramid whose volume is composed of all the target points of position vectors with a negative direction.
- Po is the geometric pyramid whose volume is composed of all the target points of position vectors with a neutral direction.

- inside(P;PX) is a function that returns true if the point P is inside the geometric pyramid PX, and false otherwise.
In order to implement inside(P;PX), it is necessary to determine whether a point P = (x, y, z) is an interior point of PP, PN or Po. Elements of topology are therefore used on sets of point definitions (Apostol, 2006):
- Inside Point: let S be a subset of Rn and P be a point of Rn. Let us suppose that P Є S. Then P is called an interior point of S if there is an open n-ball centered at P, contained in S.
- N-ball: let P be a point of Rn and R be a given positive number. The set of all points X in Rn, such that || X – P|| < R, is called the open n-ball of radius R and center P. This set is denoted by B(P) or B(P;R).
In other words, each P inside the point of S may be surrounded by an n-ball B(P) � S. The set of all the interior points of S is called the interior of S. Fig. 7 depicts a representation of R3 in which PPOS, PNEG and PNEU pyramids are displayed.

Fig 7. Geometric Polarity Pyramids in R3
To continue with our example, if we have the next feature polarity identification for the feature ‘actors’ in the user opinion ‘useropX’: V(actors, useropX) = (139.5, 63.3, 48.6) then Polarity (actors, useropX) =139.5. This signifies that Polarity (actors, useropX) = positive, because the point P=(139.5, 63.3, 48.6) is inside the geometric pyramid whose volume is composed of all the target points of the position vectors with a positive direction (PP). Therefore, inside (P; PP)= true because the point P is an interior point of the positive pyramid PP. The global polarity of a user’s opinion “useropX” (i.e., the global sentiment analysis of the user’s opinion), called Polarity(useropx), is meanwhile determined by the position vector resulting from the sum of all the (scored) position vectors for every feature identified in the user’s opinion in question (see Equation 5):
∑=
=n
ii useropxfVuseropxPolarity
1
),()(�
(5)
The resulting Polarity value will be a Euclidean vector with three coordinates (x, y, z). Let P be the target point of the resulting position vector, P=(x, y, z). This results in (see Equation 6):
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
==−=+
=truePPinsideifneutral
truePPinsideifnegativey
truePPinsideifpositivex
useropPolarity
O
N
P
x
);()(0
);()(
);()(
)( (6)
So, for example, if we have a particular user opinion ‘useropX’ with the identified features: ‘actors’, ‘music’ and ‘movie’ with the following three associated Euclidean vectors: V1 (actors, useropX) = (139.5, 63.3, 48.6), V2 (music, useropX) = (83.4, 132.3, 26.2) and V3 (movie, useropX) = (36.5, 93.1, 14.2), then: Polarity (useropX) = V1 + V2

+ V3 = (259.4, 288.7, 89) = - 288.7. The global polarity of a user’s opinion “useropX” will thus be negative.
4 Use case scenario. Movie reviews
This section shows the experimental results obtained by the proposed method in the movie review domain.
4.1. Experiment.
The number of opinions concerning the cinema theme in general, and movies in particular, is constantly increasing. In order to manipulate the vast amount of data related to movie reviews, there is a growing need for automatic opinion mining tools which are capable of evaluating some of the features concerned with movies.
Bearing in mind the shortcomings as regards developing a new ontology from scratch, for the purposes of our research we have reused the MO movie ontology. This ontology aims to provide a controlled vocabulary with which to semantically describe movie related concepts such as Movie, Genre, Director or Actor. The Web Ontology Language (OWL) is used to specify the MO ontology. Several other ontologies that are available in the Linked Data cloud are considered and integrated in order to highly couple the MO ontology with the Linked Data cloud, and thus take advantage of synergy effects.
For experimental purposes, we have inserted a total number of 1000 different movies into the MO ontology as individuals. Moreover, the corpus of the experiment contains 48,822 words and comprises 200 opinions, half of which are negative and half of which are positive. This corpus has been extracted from the corpora used in (Pang & Lee, 2004)3. In this experiment, not all the corpus has been employed because there is a manual process that should be performed on every corpus file. This manual process allows us to gather the baseline results used to evaluate the outcome of the automated method proposed here.
The details of the manual process are described as follows. Once a user’s opinion has been read, all the features that are present in the file are identified. All the features identified are then classified into one of the three available categories: positive (POS), negative (NEG) and neutral (NEU). All this information is stored in the input file “label.txt” (see Fig. 8). In this example, the information in the file “label.txt” indicates that in the user’s opinion, which is located in the file “neg1.txt”, the actress “Melissa Sagemiller” has a negative evaluation but the music in the film is good. Moreover, the name of the user’s opinion file: “neg1.txt” indicates that the global sentiment analysis of the opinion is negative.
Finally, the manual results in the input file “label.txt” and the output results produced by our automatic tool are compared with each other in order to obtain the number of features correctly classified (feature polarity identification accuracy) and the file global polarity (sentiment analysis). It is worth pointing out that the global polarity of each file can be easily identified since the corpora referred to above (see
3 http://www.cs.cornell.edu/people/pabo/movie-review-data/

(Pang & Lee, 2004)) are organized in two folders: one for the positive user’s opinions and the other for the negative ones. * FILE: neg1.txt -- genre POS -- american_beauty NEU -- lost_highway NEG -- runtime NEG -- the_crow NEU -- fantasy NEG -- the_crow_:_salvation NEU -- wes_bentley NEG -- actors POS -- memento NEG -- music POS -- melissa_sagemiller NEG -- movie NEG -- kids NEU -- blair_witch_2 NEU -- the_others NEU -- thrilling NEG -- stir_of_echoes NEU -- a_nightmare_of_elm_street_3 NEU -- horror NEG * FILE: neg2.txt -- halloween_h20 NEG -- jamie_lee_curtis POS -- movie NEG -- stan_winston POS -- the_happy_bastard NEG -- baldwin NEG -- action NEG -- pink NEU -- donald_sutherland NEG -- y2k NEG -- schnazzy POS Fig 8. An excerpt of the “label.txt” input file.
In this experiment, the four methods used to calculate the sentiment classification of a feature in a user’s opinion are tested. The difference between these methods consists only of the way in which the words near each feature are retrieved in order to calculate their polarity. As pointed out in section 3.3, the positive, negative and neutral polarity of the nouns, adjectives and verbs that are located near to the linguistic expressions that represent a given feature in the opinion should be

identified. The four methods implemented are “N_GRAM Before”, “N_GRAM After”, “N_GRAM Around” and “All Phrase” (see section 3.3 for a detailed description of each method). The first three methods require a system parameter, namely, N_GRAM.
In order to evaluate the methods’ accuracy with regard to the “average features polarity” and the “global polarity” of the user’s opinions, it is necessary to study their efficiency in the sentiment classification process. Different values for the N_GRAM parameter (between 2 and 6) have been tested to discover the best setup. However, it is also necessary to evaluate what values to assign to the Z1, Z2 and Z3 parameters. Zi is a parameter that represents the importance of the occurrence of a given feature in one part of the text (see section 3.2). Thus, similar to the above case concerning the N_GRAM parameter, different values for the Z1, Z2 and Z3 parameters (“High”, “Medium” and “Low”, which have been mapped onto 100, 50 and 25, respectively) have been tested to discover the best setup.
To summarize, it is necessary to conduct the experiment in order to test all the possibilities for the Z1, Z2, Z3 and N_GRAM parameters with the four aforementioned methods. This leads to a total of 27 study cases and 135 different values for all the possible combinations. The results for the “average of the feature polarity identification accuracy” and the “sentiment analysis” (global polarity of the file with the text of the user’s opinion) with the four methods cited previously are explained below. In the results tables (see Table 2, Table3, Table 4 and Table 5), the abbreviations “H”, “M” and “L” represent the “High”, “Medium” and “Low” values of the Z1, Z2 and Z3 parameters, while the abbreviation “NG = x” indicates that the value ‘x’ has been assigned to the N_GRAM parameter.
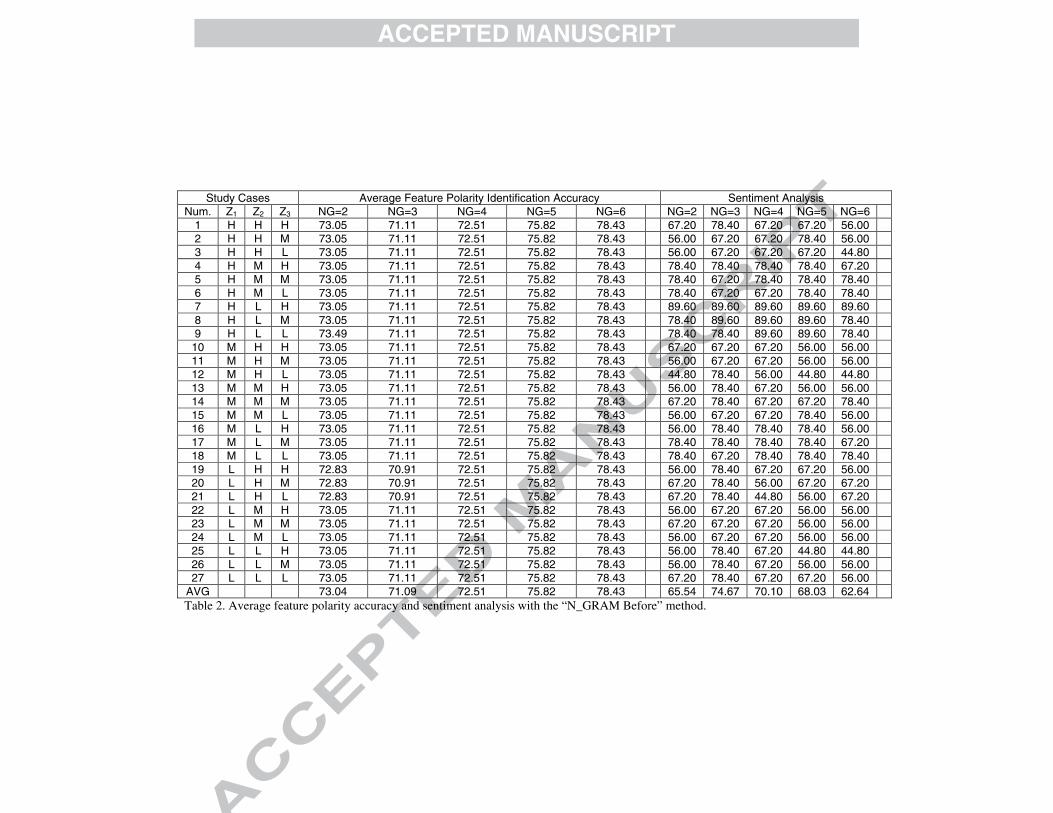
Study Cases Average Feature Polarity Identification Accuracy Sentiment Analysis Num. Z1 Z2 Z3 NG=2 NG=3 NG=4 NG=5 NG=6 NG=2 NG=3 NG=4 NG=5 NG=6
1 H H H 73.05 71.11 72.51 75.82 78.43 67.20 78.40 67.20 67.20 56.00 2 H H M 73.05 71.11 72.51 75.82 78.43 56.00 67.20 67.20 78.40 56.00 3 H H L 73.05 71.11 72.51 75.82 78.43 56.00 67.20 67.20 67.20 44.80 4 H M H 73.05 71.11 72.51 75.82 78.43 78.40 78.40 78.40 78.40 67.20 5 H M M 73.05 71.11 72.51 75.82 78.43 78.40 67.20 78.40 78.40 78.40 6 H M L 73.05 71.11 72.51 75.82 78.43 78.40 67.20 67.20 78.40 78.40 7 H L H 73.05 71.11 72.51 75.82 78.43 89.60 89.60 89.60 89.60 89.60 8 H L M 73.05 71.11 72.51 75.82 78.43 78.40 89.60 89.60 89.60 78.40 9 H L L 73.49 71.11 72.51 75.82 78.43 78.40 78.40 89.60 89.60 78.40 10 M H H 73.05 71.11 72.51 75.82 78.43 67.20 67.20 67.20 56.00 56.00 11 M H M 73.05 71.11 72.51 75.82 78.43 56.00 67.20 67.20 56.00 56.00 12 M H L 73.05 71.11 72.51 75.82 78.43 44.80 78.40 56.00 44.80 44.80 13 M M H 73.05 71.11 72.51 75.82 78.43 56.00 78.40 67.20 56.00 56.00 14 M M M 73.05 71.11 72.51 75.82 78.43 67.20 78.40 67.20 67.20 78.40 15 M M L 73.05 71.11 72.51 75.82 78.43 56.00 67.20 67.20 78.40 56.00 16 M L H 73.05 71.11 72.51 75.82 78.43 56.00 78.40 78.40 78.40 56.00 17 M L M 73.05 71.11 72.51 75.82 78.43 78.40 78.40 78.40 78.40 67.20 18 M L L 73.05 71.11 72.51 75.82 78.43 78.40 67.20 78.40 78.40 78.40 19 L H H 72.83 70.91 72.51 75.82 78.43 56.00 78.40 67.20 67.20 56.00 20 L H M 72.83 70.91 72.51 75.82 78.43 67.20 78.40 56.00 67.20 67.20 21 L H L 72.83 70.91 72.51 75.82 78.43 67.20 78.40 44.80 56.00 67.20 22 L M H 73.05 71.11 72.51 75.82 78.43 56.00 67.20 67.20 56.00 56.00 23 L M M 73.05 71.11 72.51 75.82 78.43 67.20 67.20 67.20 56.00 56.00 24 L M L 73.05 71.11 72.51 75.82 78.43 56.00 67.20 67.20 56.00 56.00 25 L L H 73.05 71.11 72.51 75.82 78.43 56.00 78.40 67.20 44.80 44.80 26 L L M 73.05 71.11 72.51 75.82 78.43 56.00 78.40 67.20 56.00 56.00 27 L L L 73.05 71.11 72.51 75.82 78.43 67.20 78.40 67.20 67.20 56.00
AVG 73.04 71.09 72.51 75.82 78.43 65.54 74.67 70.10 68.03 62.64 Table 2. Average feature polarity accuracy and sentiment analysis with the “N_GRAM Before” method.
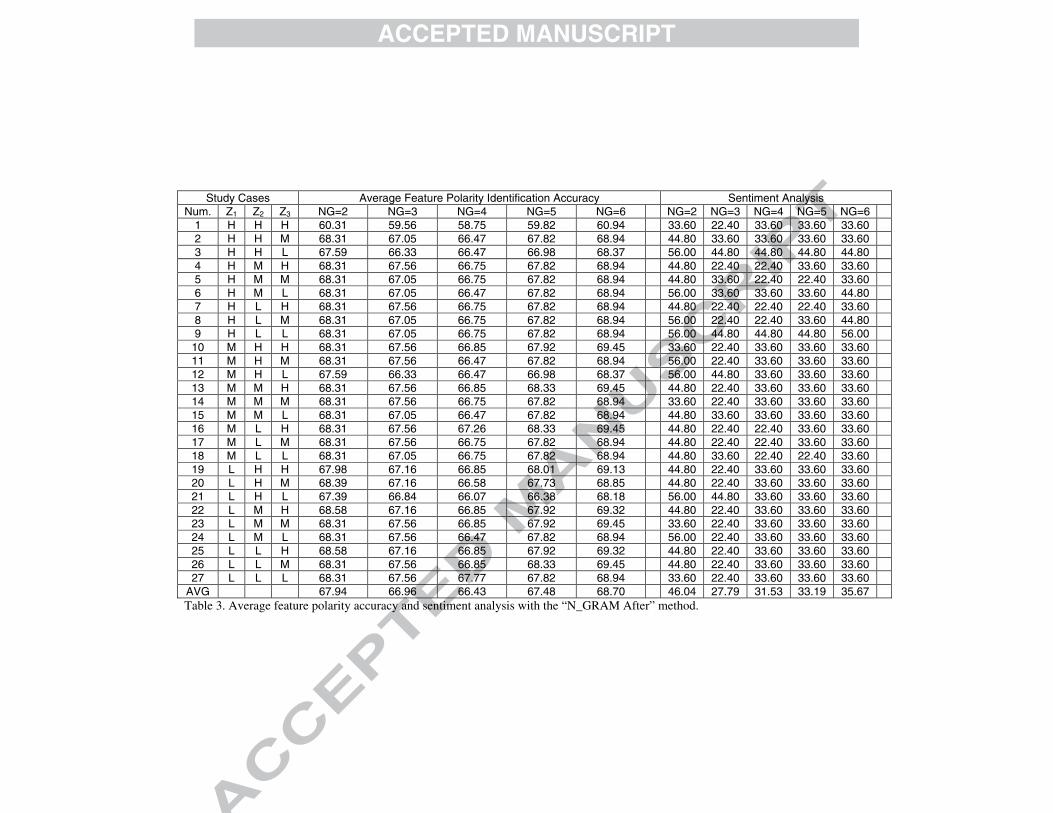
Study Cases Average Feature Polarity Identification Accuracy Sentiment Analysis Num. Z1 Z2 Z3 NG=2 NG=3 NG=4 NG=5 NG=6 NG=2 NG=3 NG=4 NG=5 NG=6
1 H H H 60.31 59.56 58.75 59.82 60.94 33.60 22.40 33.60 33.60 33.60 2 H H M 68.31 67.05 66.47 67.82 68.94 44.80 33.60 33.60 33.60 33.60 3 H H L 67.59 66.33 66.47 66.98 68.37 56.00 44.80 44.80 44.80 44.80 4 H M H 68.31 67.56 66.75 67.82 68.94 44.80 22.40 22.40 33.60 33.60 5 H M M 68.31 67.05 66.75 67.82 68.94 44.80 33.60 22.40 22.40 33.60 6 H M L 68.31 67.05 66.47 67.82 68.94 56.00 33.60 33.60 33.60 44.80 7 H L H 68.31 67.56 66.75 67.82 68.94 44.80 22.40 22.40 22.40 33.60 8 H L M 68.31 67.05 66.75 67.82 68.94 56.00 22.40 22.40 33.60 44.80 9 H L L 68.31 67.05 66.75 67.82 68.94 56.00 44.80 44.80 44.80 56.00 10 M H H 68.31 67.56 66.85 67.92 69.45 33.60 22.40 33.60 33.60 33.60 11 M H M 68.31 67.56 66.47 67.82 68.94 56.00 22.40 33.60 33.60 33.60 12 M H L 67.59 66.33 66.47 66.98 68.37 56.00 44.80 33.60 33.60 33.60 13 M M H 68.31 67.56 66.85 68.33 69.45 44.80 22.40 33.60 33.60 33.60 14 M M M 68.31 67.56 66.75 67.82 68.94 33.60 22.40 33.60 33.60 33.60 15 M M L 68.31 67.05 66.47 67.82 68.94 44.80 33.60 33.60 33.60 33.60 16 M L H 68.31 67.56 67.26 68.33 69.45 44.80 22.40 22.40 33.60 33.60 17 M L M 68.31 67.56 66.75 67.82 68.94 44.80 22.40 22.40 33.60 33.60 18 M L L 68.31 67.05 66.75 67.82 68.94 44.80 33.60 22.40 22.40 33.60 19 L H H 67.98 67.16 66.85 68.01 69.13 44.80 22.40 33.60 33.60 33.60 20 L H M 68.39 67.16 66.58 67.73 68.85 44.80 22.40 33.60 33.60 33.60 21 L H L 67.39 66.84 66.07 66.38 68.18 56.00 44.80 33.60 33.60 33.60 22 L M H 68.58 67.16 66.85 67.92 69.32 44.80 22.40 33.60 33.60 33.60 23 L M M 68.31 67.56 66.85 67.92 69.45 33.60 22.40 33.60 33.60 33.60 24 L M L 68.31 67.56 66.47 67.82 68.94 56.00 22.40 33.60 33.60 33.60 25 L L H 68.58 67.16 66.85 67.92 69.32 44.80 22.40 33.60 33.60 33.60 26 L L M 68.31 67.56 66.85 68.33 69.45 44.80 22.40 33.60 33.60 33.60 27 L L L 68.31 67.56 67.77 67.82 68.94 33.60 22.40 33.60 33.60 33.60
AVG 67.94 66.96 66.43 67.48 68.70 46.04 27.79 31.53 33.19 35.67 Table 3. Average feature polarity accuracy and sentiment analysis with the “N_GRAM After” method.
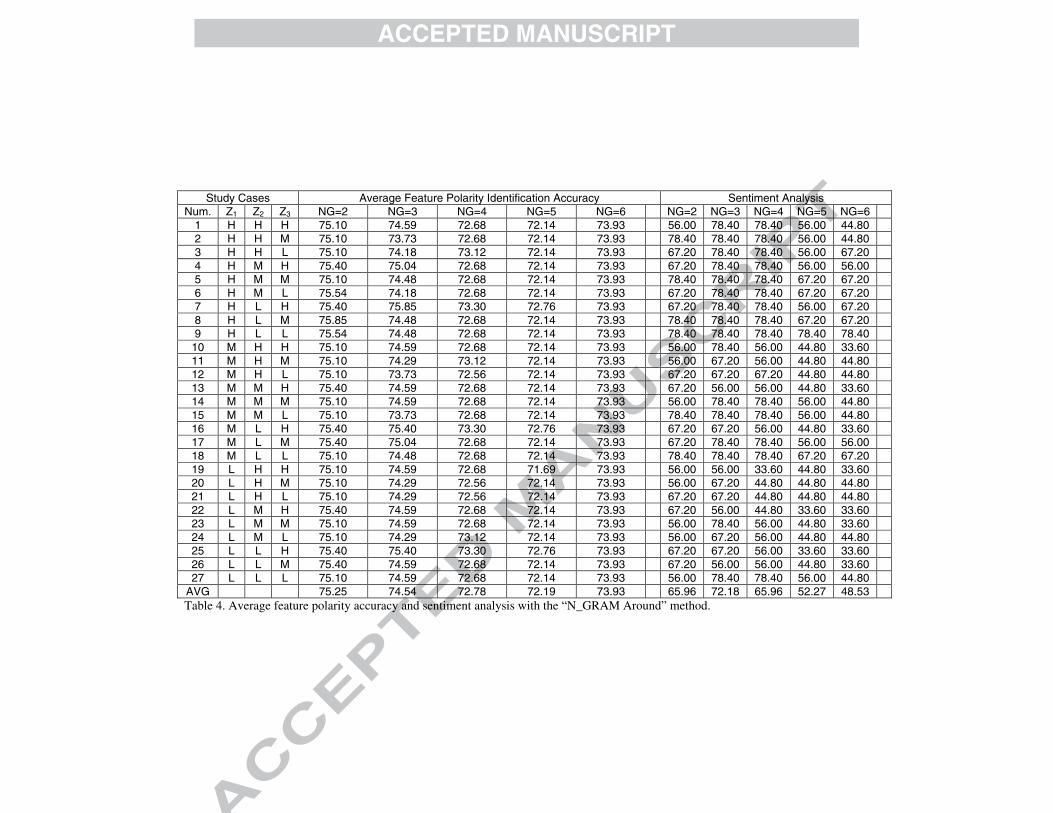
Study Cases Average Feature Polarity Identification Accuracy Sentiment Analysis Num. Z1 Z2 Z3 NG=2 NG=3 NG=4 NG=5 NG=6 NG=2 NG=3 NG=4 NG=5 NG=6
1 H H H 75.10 74.59 72.68 72.14 73.93 56.00 78.40 78.40 56.00 44.80 2 H H M 75.10 73.73 72.68 72.14 73.93 78.40 78.40 78.40 56.00 44.80 3 H H L 75.10 74.18 73.12 72.14 73.93 67.20 78.40 78.40 56.00 67.20 4 H M H 75.40 75.04 72.68 72.14 73.93 67.20 78.40 78.40 56.00 56.00 5 H M M 75.10 74.48 72.68 72.14 73.93 78.40 78.40 78.40 67.20 67.20 6 H M L 75.54 74.18 72.68 72.14 73.93 67.20 78.40 78.40 67.20 67.20 7 H L H 75.40 75.85 73.30 72.76 73.93 67.20 78.40 78.40 56.00 67.20 8 H L M 75.85 74.48 72.68 72.14 73.93 78.40 78.40 78.40 67.20 67.20 9 H L L 75.54 74.48 72.68 72.14 73.93 78.40 78.40 78.40 78.40 78.40 10 M H H 75.10 74.59 72.68 72.14 73.93 56.00 78.40 56.00 44.80 33.60 11 M H M 75.10 74.29 73.12 72.14 73.93 56.00 67.20 56.00 44.80 44.80 12 M H L 75.10 73.73 72.56 72.14 73.93 67.20 67.20 67.20 44.80 44.80 13 M M H 75.40 74.59 72.68 72.14 73.93 67.20 56.00 56.00 44.80 33.60 14 M M M 75.10 74.59 72.68 72.14 73.93 56.00 78.40 78.40 56.00 44.80 15 M M L 75.10 73.73 72.68 72.14 73.93 78.40 78.40 78.40 56.00 44.80 16 M L H 75.40 75.40 73.30 72.76 73.93 67.20 67.20 56.00 44.80 33.60 17 M L M 75.40 75.04 72.68 72.14 73.93 67.20 78.40 78.40 56.00 56.00 18 M L L 75.10 74.48 72.68 72.14 73.93 78.40 78.40 78.40 67.20 67.20 19 L H H 75.10 74.59 72.68 71.69 73.93 56.00 56.00 33.60 44.80 33.60 20 L H M 75.10 74.29 72.56 72.14 73.93 56.00 67.20 44.80 44.80 44.80 21 L H L 75.10 74.29 72.56 72.14 73.93 67.20 67.20 44.80 44.80 44.80 22 L M H 75.40 74.59 72.68 72.14 73.93 67.20 56.00 44.80 33.60 33.60 23 L M M 75.10 74.59 72.68 72.14 73.93 56.00 78.40 56.00 44.80 33.60 24 L M L 75.10 74.29 73.12 72.14 73.93 56.00 67.20 56.00 44.80 44.80 25 L L H 75.40 75.40 73.30 72.76 73.93 67.20 67.20 56.00 33.60 33.60 26 L L M 75.40 74.59 72.68 72.14 73.93 67.20 56.00 56.00 44.80 33.60 27 L L L 75.10 74.59 72.68 72.14 73.93 56.00 78.40 78.40 56.00 44.80
AVG 75.25 74.54 72.78 72.19 73.93 65.96 72.18 65.96 52.27 48.53 Table 4. Average feature polarity accuracy and sentiment analysis with the “N_GRAM Around” method.
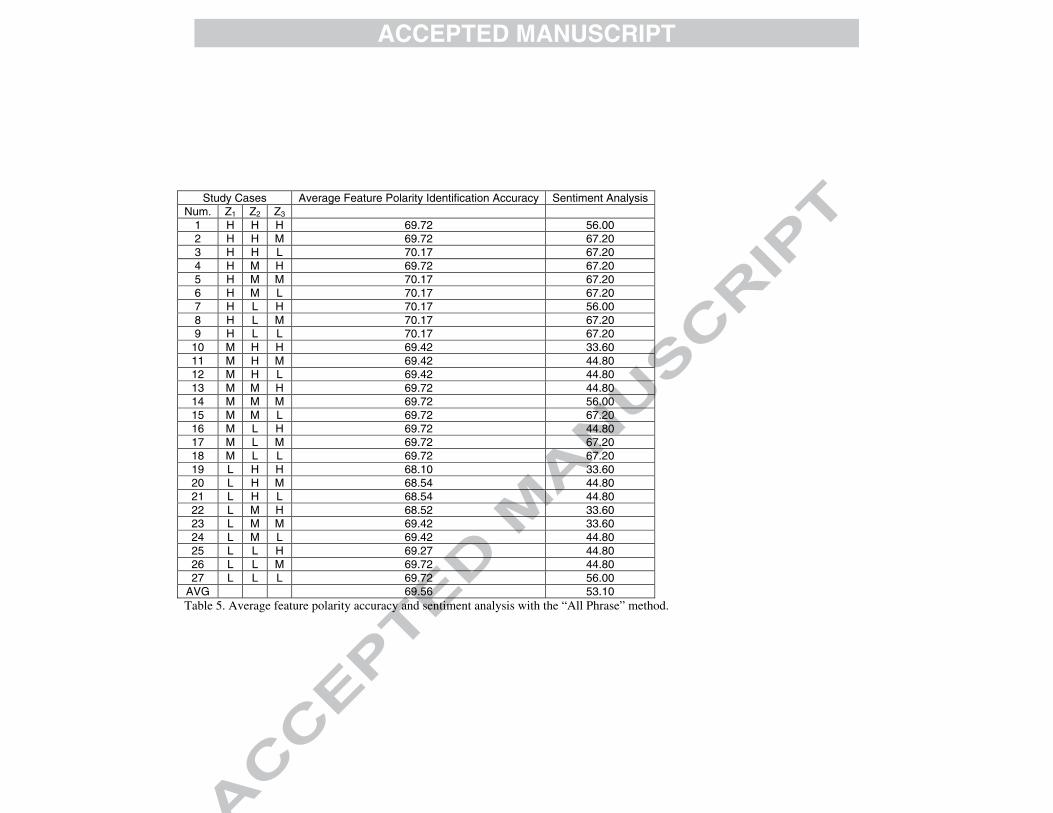
Study Cases Average Feature Polarity Identification Accuracy Sentiment Analysis Num. Z1 Z2 Z3
1 H H H 69.72 56.00 2 H H M 69.72 67.20 3 H H L 70.17 67.20 4 H M H 69.72 67.20 5 H M M 70.17 67.20 6 H M L 70.17 67.20 7 H L H 70.17 56.00 8 H L M 70.17 67.20 9 H L L 70.17 67.20 10 M H H 69.42 33.60 11 M H M 69.42 44.80 12 M H L 69.42 44.80 13 M M H 69.72 44.80 14 M M M 69.72 56.00 15 M M L 69.72 67.20 16 M L H 69.72 44.80 17 M L M 69.72 67.20 18 M L L 69.72 67.20 19 L H H 68.10 33.60 20 L H M 68.54 44.80 21 L H L 68.54 44.80 22 L M H 68.52 33.60 23 L M M 69.42 33.60 24 L M L 69.42 44.80 25 L L H 69.27 44.80 26 L L M 69.72 44.80 27 L L L 69.72 56.00
AVG 69.56 53.10 Table 5. Average feature polarity accuracy and sentiment analysis with the “All Phrase” method.

4.2. Discussion.
The results shown in Table 3, Table 4, Table 5 and Table 6 have been divided into two different categories: the average feature polarity identification and sentiment classification of the entire document accuracies.
The results of the “N_GRAM Before” method for the sentiment analysis are shown in Table 2. As will be observed, the best average success rate for the feature polarity identification process is obtained with N_GRAM = 6 with an accuracy of 78.4%. This means that the feature based polarity calculated using the previous 6 words of the feature identified obtains very good results. In fact, the worst results are obtained with N_GRAM = 3 with an accuracy of 71.11%. The average success rate does not differ with the 27 different configurations of Z1, Z2 and Z3 parameters, and almost the same results are always obtained. Finally, the average success rate of all the combinations of the feature polarity identification process is 74.18%.
The sentiment classification of the entire document meanwhile obtains the best results with the different N_GRAM. This is the case of the configuration with Z1 = H, Z2 = L and Z3 = H, in which the average success rate for sentiment analysis is always equal to 89.6%. The best results for sentiment analysis are therefore obtained when the features at the beginning and at the end of the user’s opinions are given the higher weights. In fact, this accuracy is obtained on 10 occasions. In the case of this method, ‘3’ is the best value for the N_GRAM parameter. With this value, the system achieves an average success rate of 74.67% for the sentiment analysis. Therefore, with the remaining values in the N_GRAM parameter (values 2, 4, 5 and 6), this method always obtains an average success rate that is above 66.5%. The worse sentiment analysis average success rate is obtained for N_GRAM = 6, with an average success rate of 62.64%. Only in 7 out of 135 cases does the system provide an average success rate that is below 50% in the sentiment analysis. Finally, when considering all the Z1, Z2 and Z3 value combinations, and all the N_GRAM values, the proposed tool obtains an average success rate of 67.2% for the sentiment analysis.
When considering all the Z1, Z2 and Z3 value combinations, both the best feature polarity identification and the best sentiment analysis average success rate are achieved with Z1 = H, Z2 = L and Z3 = H. This means that the most important parts of the opinion are at the beginning and at the end of the document.
Table 3 shows the results obtained when using the “N_GRAM After” method. At
first sight it will be noted that these results are worse than those obtained with the “N_GRAM Before” method. Here, the best average success rate for the feature polarity identification process is also obtained with N_GRAM = 6 with an accuracy of 68.94%. This means that the feature based polarity calculated using the next 6 words of the feature identified obtains good results. In fact, the other results obtained with different values for N_GRAM are quite similar, with a total average of 67.80%. The average success rate of this method does not differ with the 27 different configurations of the Z1, Z2 and Z3 parameters.
With regard to the sentiment analysis results obtained using the “N_GRAM After” method, the results are quite bad because in all possible cases the success rate of the “N_GRAM After” method for sentiment analysis is equal to or below 56%. With this method, ‘2’ is the best value for the N_GRAM parameter. With this value, the system

achieves an average success rate of 46.04% for the sentiment analysis. However, with the remaining values for the N_GRAM parameter (values 3, 4, 5 and 6), this method obtains an average success rate of 32.04%. More specifically, the average success rate of the sentiment analysis is 27.79% for N_GRAM = 3, 31.53% for N_GRAM = 4, 33.19% for N_GRAM = 5 and 35.67% for N_GRAM = 6. In fact, only in 9 out of 135 cases does the system provide an average success rate that is greater than or equal to 50% in the sentiment analysis. Of these cases, 8 correspond to N_GRAM = 2 and 1 corresponds to N_GRAM = 6.
It is also worth to noting that, considering all the Z1, Z2 and Z3 value combinations, and all the N_GRAM values, the proposed tool obtains an average success rate of 34.84% for sentiment analysis with this method. More concretely, when considering the Z1 = H, Z2 = L and Z3 = L value combinations, the best average success rates for both the feature polarity identification and the sentiment analysis are achieved. Therefore, in this case, the average success rate for the sentiment analysis is always higher than 48%. This means that for the "N_GRAM After” methods, the best results for the sentiment analysis are therefore obtained when the features at the beginning of the text are given the higher weights.
The results of the “N_GRAM Around” method for the sentiment analysis are
shown in Table 4. The results obtained with this method are quite a lot higher than those obtained with the “N_GRAM After” method and slightly worse than those obtained with the "N_GRAM Before" method. More concretely, the best average success rate for the feature polarity identification process is obtained with N_GRAM = 2 with a maximum accuracy of 75.54%. This means that the feature based polarity calculated using 2 words before the linguistic expression of the feature in the user’s opinion and 2 words after the linguistic expression of the feature in the user’s opinion achieves good scores. As occurs with the previous methods, the results obtained with different values for N_GRAM are quite high, with a total average of 73.74%. The average success rate of this method does not differ with the 27 different configurations of the Z1, Z2 and Z3 parameters.
The success rate of the sentiment analysis obtained with the “N_GRAM Around” method reaches 78.4% on 38 occasions. ‘3’ is the best value for the N_GRAM parameter in the case of this method. With this value, the system achieves an average success rate of 72.18% for the sentiment analysis. The average success rate for the remaining N_GRAM possible values (i.e., 2, 4, 5 and 6) is as follows: 65.96% for N_GRAM = 2, 65.96% for N_GRAM = 4, 52.27% for N_GRAM = 5 and 48.53% for N_GRAM = 6. As will be observed, the system obtains worse results with a higher N_GRAM value. In fact, only in 32 out of 135 cases does the system provide an average success rate that is below 50% for the sentiment analysis. Finally, when considering all the Z1, Z2 and Z3 value combinations, and all the N_GRAM values, the proposed tool obtains an average success rate of 60.98% for the sentiment analysis with this method. More concretely, the best average success rate for the feature polarity identification and the sentiment analysis are achieved with Z1 = H, Z2 = L and Z3 = L. More specifically, the average success rate for the sentiment analysis is always equal to 78.4%. The best results for the sentiment analysis are therefore obtained when the features at the beginning of the text are given a higher weight. Therefore, in this case, the average success rate for the sentiment analysis is always higher than 48%. This means that for the "N_GRAM After” methods, the best results for the

sentiment analysis are therefore obtained when the features at the beginning of the text are given higher weights.
Finally, Table 5 shows the results of the “All Phrase” method. As explained
previously, in this method all the words in the same sentence of the linguistic expression of the feature in the user’s opinion are used to classify this opinion. Here, the results are worse than those obtained with the “N_GRAM Before” and “N_GRAM Around” methods, but better than those obtained with the "N_GRAM After" method. More concretely, the average success rate for the feature polarity identification process is 69.56%. As occurs with the previous methods, the average success rate of this method does not differ with the 27 different configurations of the Z1, Z2 and Z3 parameters.
The success rate of the sentiment analysis with the “All Phrase” method reaches 67.2% on 10 (out of 27) occasions, which is the best value. However, in 13 out of 27 cases, the success rate for the sentiment analysis is below 50%. What is more, when considering all the Z1, Z2 and Z3 value combinations, the proposed tool obtains an average success rate of 53.1% for the sentiment analysis. In fact, with Z1 = H, in 7 out of 9 cases the success rate of the sentiment analysis is 67.2%. The best results for the sentiment analysis are therefore obtained when the features at the beginning of the user’s opinions are given higher weights (regardless of the values for Z2 and Z3).
To sum up, given the poor outcomes of both the “N_GRAM After” and the “All
Phrase” methods, it would appear that they are not appropriate when carrying out sentiment analyses of users’ opinions in the English language. More concretely, the sentiment classification results of the entire document into positive, negative and neutral obtain very bad results in the “N_GRAM After" method, with an average of 34.84%.
Of the four proposed methods, the “N_GRAM Before” method is that which achieves the best results for both the feature polarity identification process and the sentiment analysis of users’ opinions in the English language, obtaining accuracies of 75.82 and 89.60 %, respectively. These results are obtained with Z1 = H, Z2 = L and Z3 = L, which are the best values for these parameters according to the average rate for the sentiment analysis of user’s opinions. That is, the best results in the sentiment analysis of users’ opinions are obtained when the features placed at the beginning and at the end of a user’s opinion are given higher weights. This fact experimentally demonstrates the correctness of the statement made in section 3.2.
Finally, it is worth to noting that all the methods (i.e., “N_GRAM Before”, “N_GRAM After”, “N_GRAM Around” and “All Phrase”) generally achieve better results in the features polarity identification process than in the sentiment analysis of the entire document. This means that the approach presented in this paper performs better for the feature polarity identification.
4.3. Comparison with other approaches.
It is difficult to compare the proposed approach and the various approaches described in Section 2 because neither the software applications nor the textual resources used in the experiments are available. The results of the respective

experiments are not conclusive either, given that (1) the corpora and resources used differ significantly in content, size and language, and (2) the application domains are quite different.
For instance, the works presented in (Min & Park, 2012; Chen et al., 2012; Kontopoulos et al., 2013; Ghiassi et al., 2013) do not measure the effectiveness of the methods presented using the accuracy measure. Moreover, these methods were validated in the product (Min & Park, 2012; Chen et al., 2012; Kontopoulos et al., 2013) and music (Ghiassi et al., 2013) domains.
Almost all of these approaches only provide a validation for the sentiment classification of the entire document in positive or negative opinions, as occurs in the works presented in (Zhai et al., 2011; Rushdi Saleh et al., 2011; Cruz et al., 2013; Martín-Valdivia et al., 2013; Eirinaki et al., 2012; Singh et al., 2013; Deng et al., 2014). For example, in (Zhai et al., 2011) the best result in terms of accuracy was 94.1%, which was obtained for Chinese reviews of products. In the works presented in (Rushdi Saleh et al., 2011; Eirinaki et al., 2012) accuracies of 91.51% and 87% were obtained in English reviews about cameras. The best results of the related approaches is obtained in (Cruz et al., 2013) where an accuracy of 95% is attained for opinions about cars. Other works were validated in the movie domain in English, such as those presented in (Martín-Valdivia et al., 2013; Singh et al., 2013; Deng et al., 2014), and obtained accuracies of 88.57%, 82,9% and 88.50%, respectively.
Our approach, when using the “N_GRAM Before” method, has achieved an accuracy of 89.6% for the sentiment classification of all the opinions as regards positive, negative and neutral opinions. The best results of our approach are therefore comparable to the results obtained in previous works for the classification of positive and negative opinions.
5 Conclusions and future work
The boom of the Social Web has had a tremendous impact on a number of different research topics. In particular, the possibility of extracting various kinds of added-value, informational elements from users’ opinions has attracted researchers from the information retrieval and computational linguistics fields. This process is called opinion mining and is currently one of the most challenging research topics in this area. More specifically, opinion mining is concerned with analyzing the opinions of a particular matter expressed by users in the form of natural language that appear in a series of texts. The opinion mining process makes it possible to figure out whether a user’s opinion is positive, negative or neutral, and how strong it is (Zhao & Li, 2009). After examining the current state-of-the-art opinion mining approaches it is possible to identify a number of drawbacks that should be overcome.
In this paper, we propose an innovative methodology for feature-based opinion mining that unites traditional natural language processing techniques with sentiment analysis processes and semantic Web technologies. More concretely, the proposed approach is based on three different stages: i) an ontology-based mechanism for feature identification; ii) a technique to assign a polarity to each feature based on SentiWordNet and the relative position in each user’s opinion; and (iii) a new approach for opinion mining based on vector analysis.

The domain ontology is used to enhance the process of feature identification. This ontology not only contains basic concepts but also includes specific concepts, attributes, relationship and instances. Moreover, all the information that is available to represent the relevant features in the domain in question is represented in the ontology. The results of an empirical case study based on movie reviews are presented to illustrate the effectiveness of the proposed approach. What is more, the results obtained outperform the approaches selected in the related work section and produce quite good accuracy. In this study, a populated ontology has been used to identify the features in the text.
The main contribution of this work is three-fold. First, an ontology-based feature identification permits the reuse of existing vocabularies and ontologies in order to extract feature related information from opinions in different domains. Second, four different configurable methods for feature polarity identification are proposed. These methods can be configured with different parameters to obtain the best polarity identification approach for different domains and languages. Finally, the vector analysis based opinion mining approach permits the sentiment classification of a document to be calculated, and no training phases are necessary.
Despite all the advantages and possibilities of the proposed approach, it has several limitations that could be improved in future research. First, this study has used basic sentiment analysis techniques based on SentiWordNet. The proposed approach therefore can and should be improved by incorporating more advanced sentiment analysis techniques based on machine learning. Second, the validation carried out is rather short, so future improvements to the proposed approach will involve a more large-scale validation of the system by applying it to other domains such as tourism and product reviews. These validations will use statistical methods to analyze the results obtained. We are also carrying out a major upgrade of the system to make it work with Spanish texts. Finally, the main drawback of our proposal is that an ontology has to be provided in order to model the features of a predefined domain. The manual construction of ontologies is a very difficult and time consuming task (Barforush & Rahnama, 2012). Moreover, the knowledge represented in the domain ontology is static and does not change over time by, for example, adding new classes, attributes or instances, modifying classes and instances or removing knowledge. Ontology evolution can be defined as the timely adaptation of an ontology to changed business requirements, in addition to the consistent management/propagation of these changes to dependent elements (Stojanovic et al., 2002). It would be interesting to explore the introduction a semi-automatic ontology evolution approach from the reviews that will permit the updating of the knowledge that represents the features and classes in the opinions.
Acknowledgments. This work has been supported by the Spanish Ministry of Economy and Competitiveness and the European Commission (FEDER / ERDF) through project SeCloud (TIN2010-18650).

References
Ahmad, T., & Doja, M. N. (2012). Rule Based System for Enhancing Recall for Feature Mining from Short Sentences in Customer Review Documents. International Journal on Computer Science & Engineering, 4(6).
Apostol, T. M. (2006). Mathematical Analysis, Addison-Wesley Publishing Company, Inc. Reading, Massachusetts, U.S.A. 2006.
Baccianella, S., Esuli, A., & Sebastiani, F. (2009). Multi-facet rating of product reviews, In ECIR ’09: Proceedings of the 31th European Conference on IR Research on Advances in Information Retrieval (pp. 461–472).
Baccianella, S., Esuli, A. & Sebastiani, F. (2010). SentiWordNet 3.0: An enhanced lexical resource for sentiment analysis and opinion mining. In Proceedings of the Seventh Conference on International Language Resources and Evaluation (pp. 2200–2204). European Language Resources Association.
Balahur, A., & Montoyo, A. (2010). Semantic approaches to fine and coarse-grained feature-based opinion mining. In Natural Language Processing and Information Systems (pp. 142-153). Springer Berlin Heidelberg.
Barforush, A. A., & Rahnama, A. (2012). Ontology learning: revisted. Journal of Web Engineering, 11(4), 269-289.
Berners-Lee, T. & Hendler, J. (2001). Publishing on the Semantic Web, Nature, April 26 2001 (pp. 1023-1025).
Cambria, E., Schuller, B., Liu, B., Wang, H., & Havasi, C. (2013a). Knowledge-Based Approaches to Concept-Level Sentiment Analysis. IEEE Intelligent Systems, 28(2), 12-14.
Chen, L., Qi, L. & Wang, F. (2012). Comparison of feature-level learning methods for mining online consumer reviews. Expert Systems with Applications, 39, 9588–9601.
Cruz, F. L., Troyano, J. A., Enríquez, F., Ortega, F. J. & Vallejo, C. G. (2013). ‘Long autonomy or long delay?’ The importance of domain in opinion mining. Expert Systems with Applications, 40, 3174–3184.
Deng, Z. H., Luo, K. H., & Yu, H. L. (2014). A study of supervised term weighting scheme for sentiment analysis. Expert Systems with Applications,41(7), 3506-3513.
Eirinaki, M., Pisal, S., & Singh, J. (2012). Feature-based opinion mining and ranking. Journal of Computer and System Sciences, 78(4), 1175-1184.
Esuli, A. & Sebastiani, F. (2005). Determining the semantic orientation of terms through gloss classification, In CIKM ’05: Proceedings of the 14th ACM international conference on Information and knowledge management (pp. 617–624).
Feldman, R. (2013). Techniques and applications for sentiment analysis. Communications of the ACM, 56(4), 82-89.
Gamon M. (2005). Sentiment classification on customer feedback data: noisy data, large feature vectors, and the role of linguistic analysis, In COLING 2005 (pp. 841—847).
Ghiassi, M., Skinner, J., & Zimbra, D. (2013). Twitter brand sentiment analysis: A hybrid system using n-gram analysis and dynamic artificial neural network.Expert Systems with Applications: An International Journal, 40(16), 6266-6282.

Gladun, A., Rogushina, J., Valencia-García, R., & Béjar, R. M. (2013). Semantics-driven modelling of user preferences for information retrieval in the biomedical domain. Informatics for Health and Social Care, 38(2), 150-170.
Kontopoulos, E., Berberidis, C., Dergiades, T. & Bassiliades, N. (2013) Ontology-based sentiment analysis of twitter posts. Expert Systems with Applications, 40, 4065–4074.
Martín-Valdivia, M. T., Martínez-Cámara, E., Perea-Ortega, J. M. & Ureña-López, L. A. (2013). Sentiment polarity detection in Spanish reviews combining supervised and unsupervised approaches. Expert Systems with Applications, 40, 3934–3942.
Min, H. J., & Park, J. C. (2012). Identifying helpful reviews based on customer’s mentions about experiences. Expert Systems with Applications, 39(15), 11830-11838.
Moreno, A., Pineda, F. & Hidalgo, R. (2010). Análisis de Valoraciones de Usuario de Hoteles con Sentitext: un sistema de análisis de sentimiento independiente del dominio, Procesamiento del Lenguaje Natural, 45, 31–39.
Ochoa, J. L., Valencia-García, R., Perez-Soltero, A., & Barceló-Valenzuela, M. (2013). A semantic role labelling-based framework for learning ontologies from Spanish documents. Expert Systems with Applications, 40(6), 2058-2068.
Pang B. & Lee L. (2004). A Sentiment Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. In Proceedings of the ACL, (pp. 271–278).
Rodríguez-García, M. Á., Valencia-García, R., García-Sánchez, F., & Samper-Zapater, J. J. (2014). Ontology-based annotation and retrieval of services in the cloud. Knowledge-Based Systems, 56, 15-25.
Rushdi Saleh, M., Martín-Validvia, M. T., Montejo-Ráez, A. & Ureña-López, L.A. (2011). Experiments with SVM to classify opinions in different domains. Expert Systems with Applications, 38, 14799–14804.
Shadbolt, N., Berners-Lee, T. and Hall, W. (2006) ‘The Semantic Web Revisited’. IEEE Intelligent Systems 21(3): 96-101 (2006).
Singh, V. K., Piryani, R., Uddin, A., & Waila, P. (2013, March). Sentiment analysis of movie reviews: A new feature-based heuristic for aspect-level sentiment classification. In Automation, Computing, Communication, Control and Compressed Sensing (iMac4s), 2013 International Multi-Conference on (pp. 712-717). IEEE
Stojanovic, L., Maedche, A., Motik, B., & Stojanovic, N. (2002). User-driven ontology evolution management. In Knowledge engineering and knowledge management: ontologies and the semantic web (pp. 285-300). Springer Berlin Heidelberg.
Studer, R., Benjamins, V. R. & Fensel D. (1998). Knowledge engineering: Principles and methods, Data Knowl. Eng., 25, 161–197.
Toutanova K. & Manning, C. (2000). Enriching the Knowledge Sources Used in a Maximum Entropy Part-of-Speech Tagger. In Proceedings of the Joint SIGDAT Conference on Empirical Methods in Natural Language Processing and Very Large Corpora EMNLP/VLC-2000 (pp. 63–70). Hong Kong.
Toutanova, K., Klein, D., Manning, C. & Singer, Y. (2003). Feature-Rich Part-of-Speech Tagging with a Cyclic Dependency Network. In Proceedings of HLT-NAACL 2003 (pp. 252–259).
Zhai, Z., Xu, H., Kang, B., & Jia, P. (2011). Exploiting effective features for chinese sentiment classification. Expert Systems with Applications, 38, 9139–9146.

Zhao, L. & Li, C. (2009). Ontology based opinion mining for movie reviews, In Proceedings of the 3rd International Conference on Knowledge Science, Engineering and Management (pp. 204–214).
Zhou, L. & Chaovalit, P. (2008). Ontology-supported polarity mining, Journal of the American Society for Information Science and Technology, 59, 1, 98–110.
Feature-Based Opinion Mining through ontologies
Highlights: Opinion mining is a highly active research field comprising natural language processing, computational linguistics• Current opinion mining Current opinion mining approaches are hampered by a number of drawbacks• We propose an innovative We propose an innovative opinion mining methodology that takes advantage of new Semantic Web-guided solutions •The methodology has been implemented and thoroughly The methodology has been implemented and thoroughly tested in a real-world movie review-themed scenario.